by William K. Dewey
Using Airtable to download and parse Digital Humanities Data
Airtable is a cloud-based, software-as-a-service platform for entering and storing data commonly used for academic research, including in the digital humanities. It is commercial subscription-based software, using a proprietary format but with the ability to export into open formats. It can best be compared with spreadsheets (like Google Sheets or Excel) and relational databases (like MariaDB), as it combines aspects of both types of applications (Airtable Platform [updated 2023])[1]. Although it is marketed to businesses, academic and in particular digital humanities projects are using Airtable for its combination of spreadsheet-style data entry with relational modeling capabilities. Airtable’s advantages include ease of use for students and project assistants, who can easily add information related to projects and link related records together.
Airtable Compared with Spreadsheets
At first glance, Airtable is quite like spreadsheet applications, as information can be entered into cells, rows, and columns. But its data model is not simply a flat text file like CSV. Fields can be populated with many data types, including dates, integers, rollup and lookup fields, and can include multiple values and controlled vocabularies (Supported Field Types… [updated 2023])[2]. Like Excel, Airtable provides programmatic functionality with formulas (Formula Field Reference [updated 2023])[3]. For more involved programming involving multiple records and tables, there are automations, which might look up records and create other records based on them. It is not necessary to know a programming language to do this, because Airtable provides a graphical interface to define the automation step by step (Airtable Automations [updated 2023])[4][5]. There are features more like a SQL relational database than a spreadsheet, including the ability to link related records together using foreign keys and join tables. Lookup fields provide the ability to transform data from linked records into more useful forms (Linking Records…[updated 2023])[6]. Like many database platforms, Airtable allows access privileges to be managed. The platform also provides the ability to create a workspace for an organization. Within an organization, one can create a project base (a set of related tables), and give users different access privileges to it. One can grant view privileges only, editing privileges, or ownership permission to do tasks like create and delete tables. Any collaborator can be given an API access token so that they can download Airtable data from the command line or with scripts (Airtable Base Collaboration…[updated 2023])[7].
Airtable Compared with Relational Databases
Airtable has advantages over relational databases. While sharing functionality like join tables, queries, defined data types, and programmatic capabilities, Airtable requires much less coding knowledge. Knowledge of SQL or other programming languages is not necessary to enter or query records, create join tables or even to create formulas. The online interface provides functionality for entering data, linking records together, and adding formulas, although formulas still require some knowledge of markup and syntax (Formula Field Reference [updated 2023])[8]. Array functions, for instance, are one way to use lookup fields to redisplay joined records, and Airtable’s GUI will provide guidance in this transformation (Using Array Functions… [updated 2023])[9].
UNL’s Center for Research in the Digital Humanities and its Technical Stack
Airtable is used at the Center for Research in the Digital Humanities (CDRH) to serve the Center’s unique needs in transforming data for the CDRH API. The CDRH is a digital humanities center based in the University of Nebraska-Lincoln Libraries that, in collaboration with researchers, assists professors in creating web applications for projects with humanistic content and data (About the CDRH [updated 2023])[10]. When the Center was developed, projects primarily involved working with XML documents, but the Center now works with more varied types of data including tables, images, and maps.
Airtable data was structured and used so that it would be compatible with the technical stack at the Center (see Figure 1). The Center’s local infrastructure is designed to ingest and store data so that it can be displayed in web applications. The first component of the stack is Orchid, a template for front end web applications, written in Ruby on Rails. It follows the standard model-view-controller pattern of Ruby on Rails, but instead of creating data models from a SQL database, Orchid pulls data from the CDRH API. Orchid sites provide faceted search and discovery, display API entries in a standardized way, organize data into sections, and allow for the creation of static HTML pages (Orchid [updated 2022])[11]. The CDRH’s API is based on Ruby on Rails, as well. It is a front end to an Elasticsearch index (a search engine based on Lucene) and provides methods to post and query data, and to view the raw data in a browser.
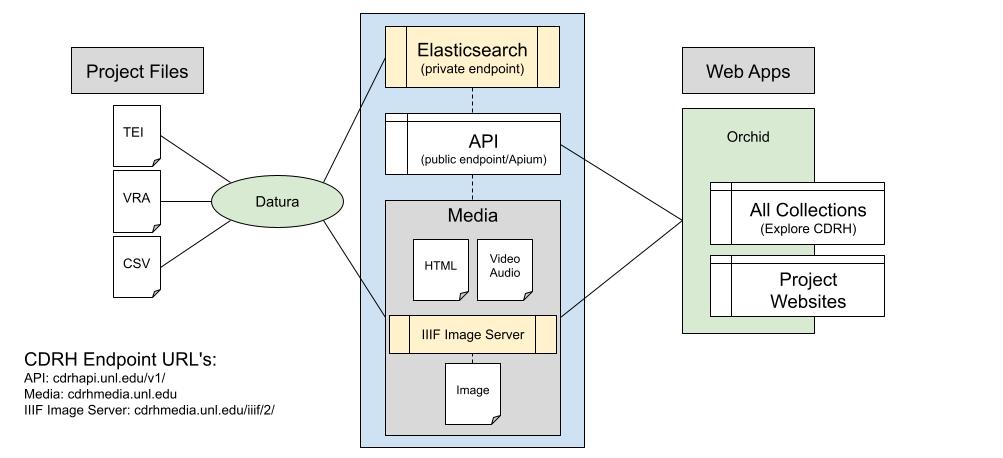
Figure 1. Technical stack of the Center (Dalziel [updated 2018][12].).
When a query is made through the search bar of an Orchid application, the API also queries Elasticsearch. The underlying data in Elasticsearch is in JSON format, so the API schema needs to be structured in a way to convert the data into JSON, with datatypes expected by the Elasticsearch index (api [updated 2022])[13]. Datura is the CDRH’s system for populating the API with data. It posts data into the Elasticsearch index via the API from source files that are in a variety of formats. Datura creates a JSON hash which is populated field-by-field with simple Ruby functions, which take data from the document being ingested. The values of nested fields must themselves be in JSON format. Ruby’s JSON libraries can help here but sometimes it is necessary to do more transformations to make sure data is parsable as JSON, such as removing illegal characters. An example of a nested field is “person”, which has subfields that include names (first, last, and alternate), birth and death date, and demographic information (sex, age, and race). Most of the formats Datura can ingest are XML based, commonly TEI (Text Encoding Initiative) documents. Datura also has the capacity to ingest CSV, a simple process of adding each row as a separate record into the API, with each column representing a field. Although it would appear simpler to directly use the JSON from Airtable directly (keeping in mind that it would still have to be converted to match the API schema), Datura does not currently have the capacity to ingest JSON (Datura [updated 2023])[14].
Projects using Airtable: Petitioning for Freedom and African Poetics
The first CDRH project in which Airtable was used was Petitioning for Freedom. This project, funded by an NSF grant, focuses on petitions for habeas corpus in the American West from 1785 to 1920, and how they were used to challenge often unjust situations of confinement or coercion. Although the principal investigator (Dr. Katrina Jagodinsky) has her own interests (including critical legal theory, race, slavery, immigration, gender, and family law), the project is intentionally designed so that it is useful to scholars with other interests. A wide variety of cases were included from the states of Iowa, Washington, Kansas, Missouri, and Nebraska (Jagodinsky et al. 2023; see Figure 2 for an example of a case page)[15]. Apart from some XML-encoded case documents, most of the data consists of summaries and metadata about the cases in spreadsheet form.
The first draft of Petitioning for Freedom involved a simple SQL database, linked to Ruby on Rails with Active Record (the part of Rails that creates Ruby objects from the database), and seeded in the `db/seeds.rb` file from a CSV file. Seeding the database manually via Ruby scripts is not a good model for data entry for even a relatively simple data set. Such a script lacks much of the basic functionality of a spreadsheet application, like the ability to view the data in tabular form, sort it and add formulas. For this reason, the project transitioned to storing data in Google Sheets, from which data could be exported in CSV format and then exported into the CDRH API (habeascorpus [updated 2023])[16] [17]. This solution made greater use of the CDRH’s existing functionality; in particular, using the existing API schema meant there was less of a need to customize the database and there was greater control over the data model. However, the CSV-exported spreadsheets were not rich enough for the data and relationships Dr. Jagodinsky wanted to model, and promised to model in the related project grant. Airtable provided much of the needed functionality like join tables, and it was an easy platform for data entry for both students and staff (see Figure 3 for part of the “cases” table, including the entry underlying Figure 2). Formulas were worked out to export join data in readable form, although this proved to be an unwieldy process.
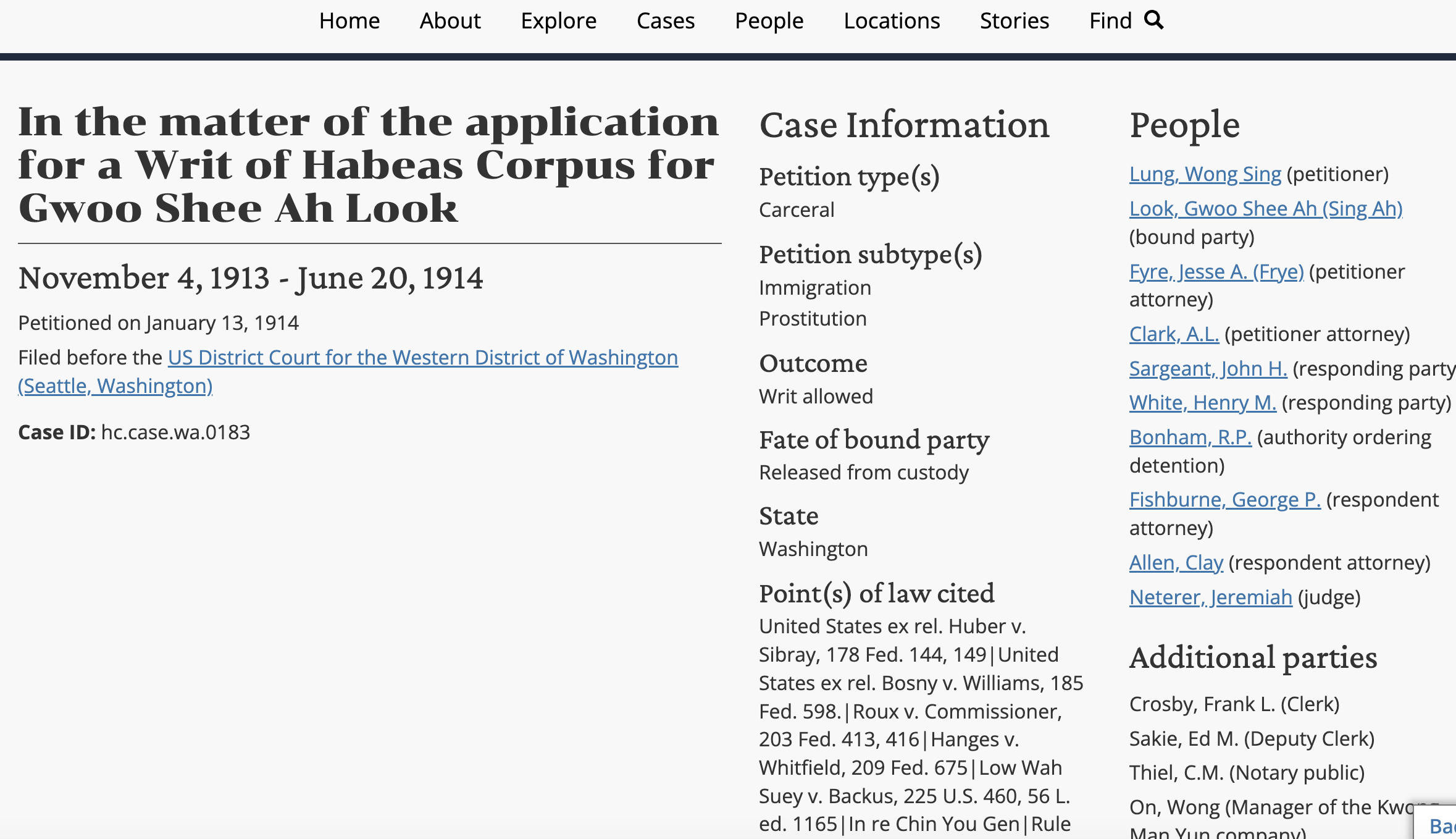
Figure 2 – Petitioning for Freedom front end, displaying information about a habeas corpus case. (In the matter of…[updated 2023])[18].
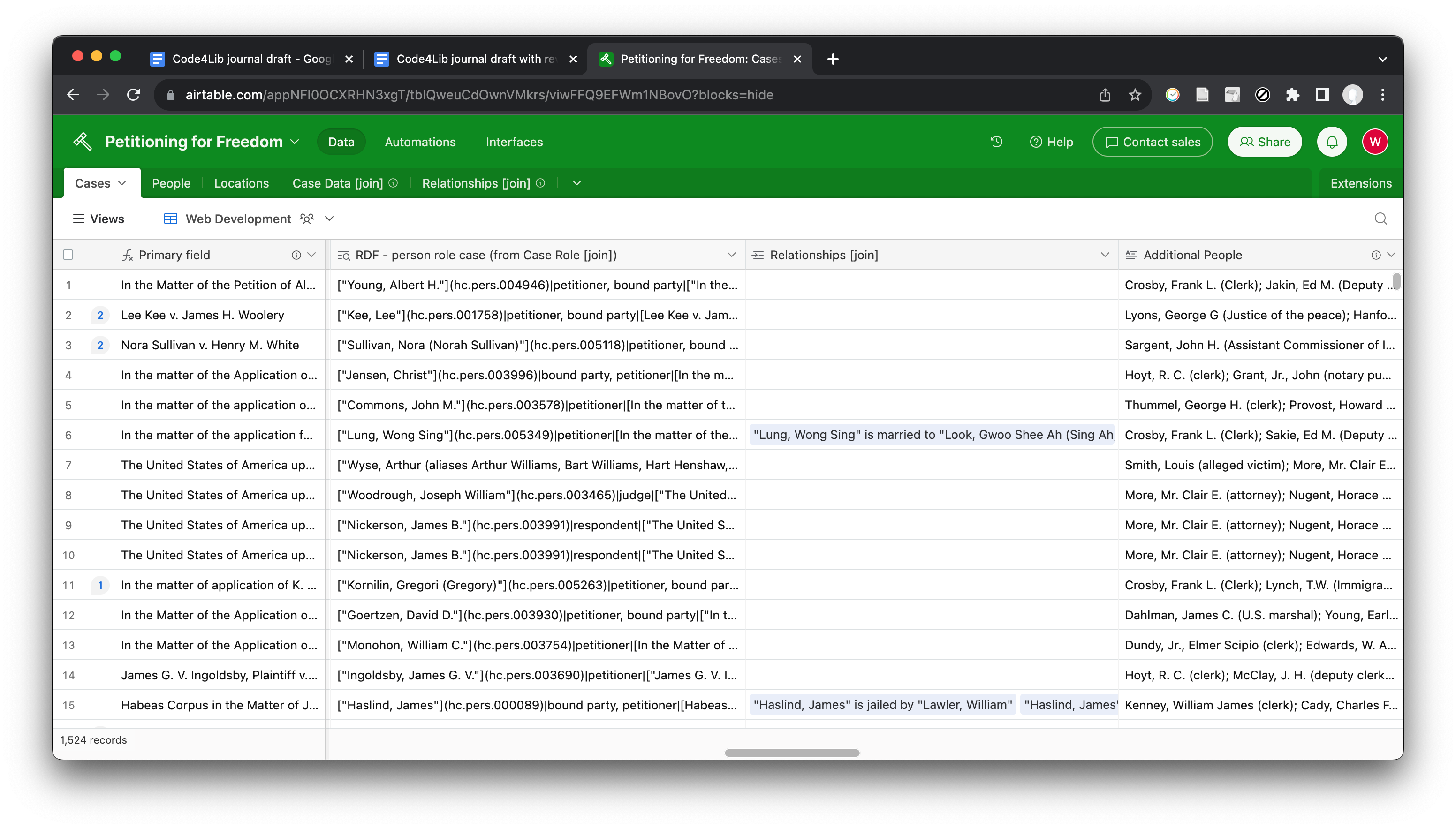
Figure 3 – Airtable back end, displaying the cases table, and information regarding individuals and the roles they played in cases, the underlying data behind Figure 2.
The second project for which Airtable was used for data storage was the African Poetics Digital Portal (ADPD), a project funded by the Ford and Mellon Foundations. The ADPD is the digital portion of Kwame and Lorna Dawes’ African Poetry Book Fund dedicated to promoting African poetry and related scholarship (Dawes 2023)[19]. Airtable was most extensively used for the African Poetics In The News project. It is a comprehensive account of coverage of African poets in British newspapers (most predominantly the Times of London and Sunday Times) from 1865 to 1985 (see Figure 4 for an example of a page on a poet). Most of the data, aside from newspaper images, was in tabular or textual form. The extensive dataset included news articles, events, poets, and works, and select critical commentaries written by students (Dawes et al., 2023)[20]. The data items are related to each other in complex ways, and the data model uses hidden tables containing data such as locations. Originally this data was in an even more complex set of SQL databases, and data entry was handled by a Rails application which was not intuitive for most users. It was decided to simplify the data model and move it into Airtable (Figure 5), handling join tables in similar fashion to Petitioning for Freedom. Scripts were written to download the data from Airtable, process it for the CDRH’s API, and the front end was revised to use the new data schema (african_poetics [updated 2023])[21].
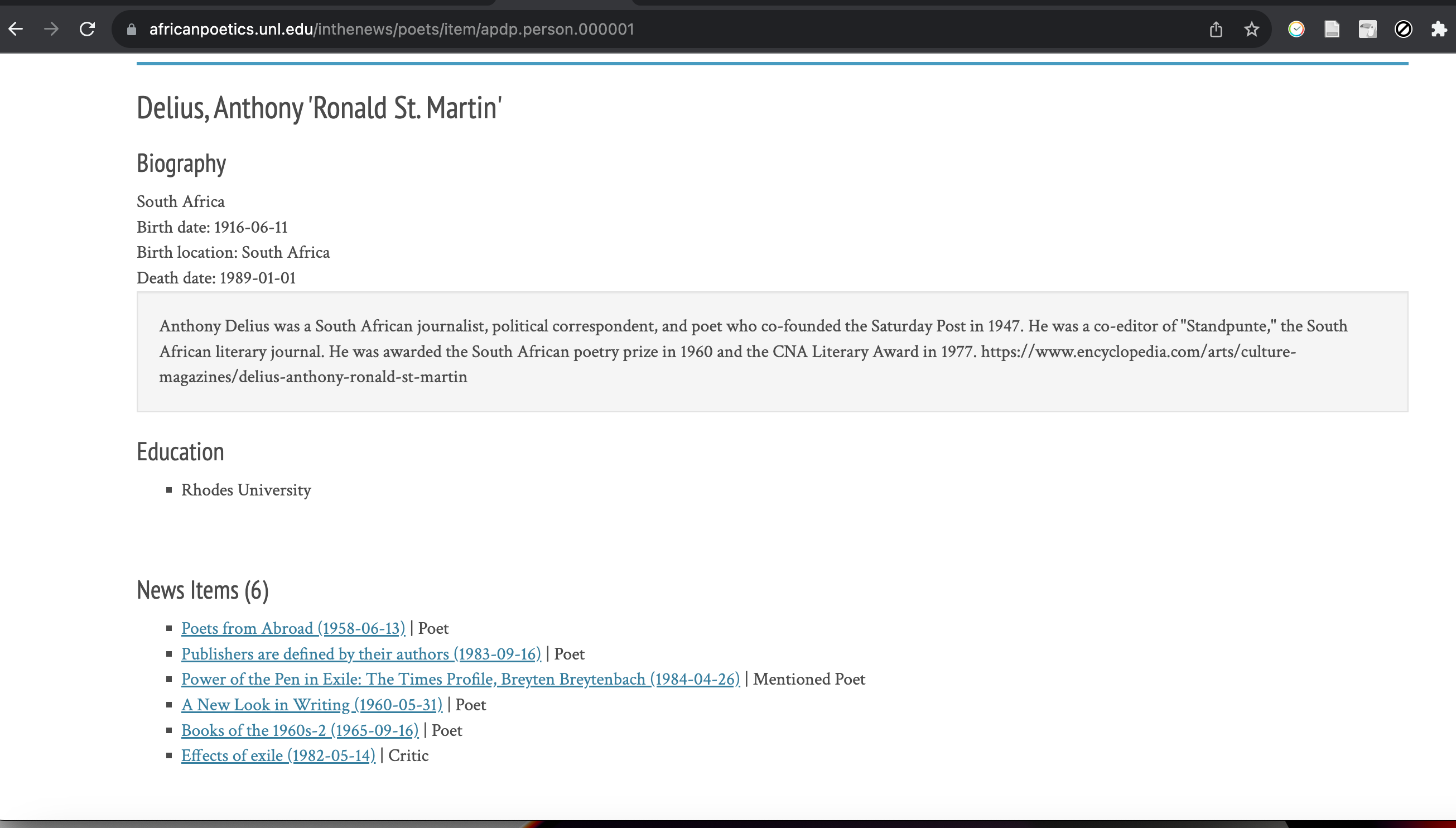
Figure 4 – African Poetics Digital Portal front end (Delius, Anthony ‘Ronald’…[updated 2023])[22].
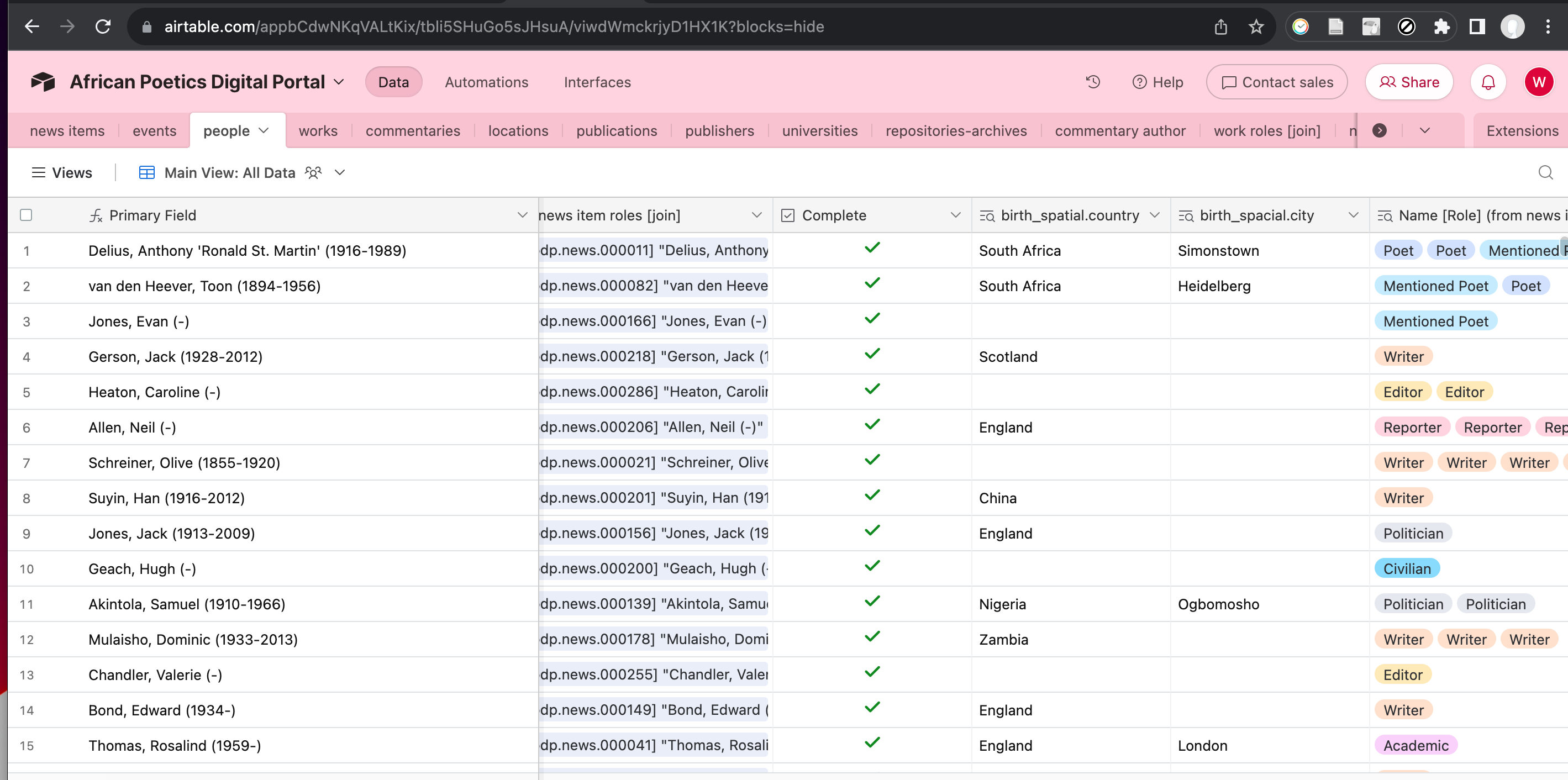
Figure 5 – Airtable back end for African Poetics, showing some of the data for people
Exporting data from Airtable
One may desire to export Airtable data offline. A goal of CDRH projects is to be able to distribute data publicly, and update project data in a way that is fully automated, consistent and reproducible. However, as a proprietary cloud-based format, one cannot download or save an “Airtable table” for offline use. The tables can only be viewed with an account or personal access token to Airtable’s API. Fortunately, it is possible to export Airtable tables into more common, open-source formats like CSV and JSON. The CSV format is generally better for sharing data, as it is more human-readable, and most spreadsheet software can open it. However, CSV can only be downloaded via the web interface and is not available programmatically (Airtable Views [updated 2023])[23]. Other CDRH projects have used processes that involve manually exporting spreadsheets from an application, but such a process proves to be unreliable. Downloading Airtable tables to JSON can be automated, as JSON can be downloaded via the Airtable API , either by making curl requests or using command line tools. JSON can also be transformed into the CSV format needed for the Datura scripts. For these reasons the CDRH preferred the JSON format for exporting from Airtable. The ‘airtable-export’ python module is one way to download tables as JSON from the command line, requiring an Airtable base id and a personal access token (Willison 2023)[24][25]. The token can be generated from the website, [26]replacing the deprecated API key (Zhao 2023)[27]. Access tokens work in the same way, so this change posed no difficulties in using the `airtable-export` script (Personal Access Tokens, updated 2023)[28]. The base id can be found after creating an account, by viewing the API documentation,[29] clicking on the name of the base, and finding the ID after “The ID of this base is.” (API Reference, updated 2023)[30]. This tool is incorporated into the Python scripts as shown below, [31] but it could also simply be used from a terminal command line.
command = f"airtable-export source/json {AIRTABLE_BASE_ID} Cases People --key={API_KEY} --json"
For the Petitioning for Freedom project, the base id and access token are stored as environment variables in a .env file (not committed to GitHub) using the module python-dotenv (Kumar 2023)[32]. Similar processes are used in other projects.
Despite the wide variety of data types in the Airtable table, the values of the cells in JSON generally come in one of three forms, a string, an array, or a coded reference to a linked record. Linked records appear as meaningful names in the table but are encoded as alphanumeric strings in the exported JSON, in a key that is not available in any exported data, making it difficult to use the data outside Airtable. For instance, the Case Roles column in the Cases table (linked to the Case Roles join table), displays information about what individuals played what role in the case, but it looks like this when downloaded as CSV:
"Case Role [join]": [ "rec1Gh0Qf5UM5q93J", "recvNHFC6ZgTkwCsD", "recmhnoslTa5rkzHz", "recTOeN7OtiENZiuQ", "recwTDz7ZpKwF7Ny1", "reclCNp4ebBRGlXqN", "recInBUVYVwvjvtUd" ]
It is possible, but not necessarily practical, to match up IDs manually with the linked table. As will be discussed later, a better way to get around this limitation of the download format is to create new Airtable fields based on the linked records.
Processing Airtable Data for the CDRH API
The scripts to download and preprocess the data prior to the API ingest vary in complexity. The data must be converted to CSV for the Datura scripts, which will convert them to a JSON format that can be consumed by Elasticsearch. In the case of African Poetics, a lot of preprocessing was done in a simple Python script, which constructed JSON and CSV files from Airtable API data [33]. Instead of downloading JSON directly it was built up step by step by API requests to Airtable.
records = {}
url = server+base_id+'/'+table
HEADERS = {'Authorization':'Bearer '+api_key}
PARAMS = {'view':'Grid view'}
res = requests.get(url, params = PARAMS, headers = HEADERS)
data = res.json()
for record in data['records']:
record['fields']['airtableID'] = record['id']
records[record['id']] = record
The JSON files were then written to CSVs with the CSV Python module, using the hash values as the header.
header = list(table_fields[table].keys())
if table in ["commentaries", "events", "news items", "people", "works", "contemporary poets"]:
csvfile = open('source/csv/'+table+'.csv', 'w')
else:
csvfile = open('scripts/airtableExport/csv/'+table+'.csv', 'w')
writer = csv.DictWriter(csvfile,fieldnames=header,extrasaction='ignore',quoting=csv.QUOTE_ALL)
The ingest into the API did not involve an especially complicated data model. At most the API expected nested fields like “person”, which took the shape { name: name, role: role, id: id }. On the Airtable side, it was necessary to use Airtable formulas to combine the join data into a field that was more easily readable, like
[Krog, Antjie](apdp.person.000980).
Data processing with Pandas Scripts
The Petitioning for Freedom project has a more complex data schema, so extensive data processing was needed to get the data into a shape that the CDRH API could consume. Python’s pandas module, which is one of the most common tools for data manipulation and analysis, turned out to be one of the best tools for that purpose. It has strengths in converting JSON to CSV and manipulating data frames [34]. After downloading the JSON files via ‘airtable-export,’ the files are read into a pandas dataframe, and, following all the necessary transformations, the dataframe is turned back into CSV. The scripts are intended to modify the CSV so that Datura scripts can post the data into the API, without causing errors or storing undesired values. There were a lot of columns that contained unwanted Airtable metadata and the script dropped them with cases_frame.drop(columns=[“Encoding Notes”, “Last Modified”,…]. Some columns need to be made parsable by Ruby’s JSON plugin. For instance, a list of values might appear as the string “[0, 1, 2, 3, 4, 5]” and Ruby can parse it as JSON and turn it back into an array. A challenge in this process was that Python introduces single quotes into such fields, which is not legal JSON. The solution is to apply JSON.dumps in the Python script on every field that needs to be parsed as JSON.
for label in ["Petition Type", "Site(s) of Significance", "Tags", "Petitioners", "RDF - person role case (from Case Role [join])", "Petition Outcome", "Fate of Bound Party(s)", "Court Name(s)", "Source Material(s)", "bound_party_age", "bound_party_race", "bound_party_sex", "Repository", "Case State"]:
cases_frame[label] = cases_frame[label].apply(json.dumps)
The conversion process creates blank and NaN values, which can cause parsing errors or unwanted values in the API, so it is necessary to strip them out.
cases_frame = cases_frame.fillna('')
This code replaces NaN values with an empty string, which will not be ingested into the API
Exporting Data from Join Tables
Linked records and join tables pose further challenges for those who want to reuse Airtable data, and additional data processing may be necessary to make the exported data usable. The Airtable application groups records together in a way that expresses more relationships than an ordinary flat file spreadsheet. For instance, Petitioning for Freedom uses lookup tables for people and locations associated with a case. There are two join tables, “cases data” for roles played by persons in cases (e.g. petitioning attorney, judge), and “relationships” for person-to-person relationships (e.g. lawyer for, mother of, etc.).
The cases data table also contains information on personal characteristics of petitioners (race, sex, and gender) from the original case records. The relationships table is linked to the people table twice to capture reciprocal relationships like mother and son. In African Poetics, much of the original complex array of SQL join tables, recording information like related works and associated locations, was made into Airtable join tables. The challenge for programmers is that the linked records when downloaded appear as a meaningless list of alphanumeric strings, as described above.
It is possible to download the join table itself and try to match records with ids, but such a process would be overly complex to script. A better solution is to create formulas to make new fields on the primary tables. Airtable does provide rollup fields, which perform a simple function on linked records to create a readable field (Rollup field overview [updated 2023])[35]. The Petitioning for Freedom and African Poetics tables use the rollup feature and custom formulas to make fields on the primary tables that represent the linked records [36]. They are structured with delimiting characters (like pipes, semicolons, and so forth), which can be parsed by Ruby and ingested into the API as arrays and hashes.
Two examples from African Poetics illustrate what this parsable data looks like in Airtable. A list of related people on the “people” table looks as follows:
[Campbell, Roy](apdp.person.000514);;;[Currey, Ralph Nixon 'R. N.'](apdp.person.000253);;;[Madge, Charles Henry](apdp.person.000235);;;[Plomer, William](apdp.person.000132);;;
On the “works” table, with the addition of a role, the field looks like this:
[Brutus, Dennis Vincent](apdp.person.000779)|Poet;;;[Okigbo, Christopher](apdp.person.001150)|Poet;;;[Peters, Lenrie](apdp.person.000030)|Poet;;;[Clark, John Pepper 'J. P.'](apdp.person.000828)|Poet;;;
Markdown syntax ‘[name](id)’ is used to represent ids from the API and corresponding names [37] Otherwise the strings are split on the characters “;;;” (for each person) and then “|” (separating the Markdown from the role). The parsing script might look like this, with the variable people representing the data from Airtable and the parse_ function being used to process the Markdown:
if people && people.length > 0
people = people.split(";;;")
people.each do |person|
data = person.split("|")
if data[0]
name = parse_brackets[data[0]]
id = parse_parentheses[data[0]]
role = data[1]
result << { name: name, role: role, id: id }
end
end
end<
Here are more examples from Petitioning for Freedom, showing relationships between individuals, and the role an individual played in a case:
"[\"Pickard, Aubrey\"](hc.pers.000945)|parent of|[\"Pickard, Leonard\"](hc.pers.000946)", [\"Pickard, Aubrey\"](hc.pers.000945)|Unindicated|[In the Matter of the Petition of Aubrey Pickard for a Writ of Habeas Corpus for Leonard Pickards](hc.case.ne.0735).
However, this was a complex field to parse. When Airtable formulas concatenate linked records as strings, they often put values in quotes and it is difficult to work around this behavior. The quotes also caused trouble at the stage of ingest into the CDRH API (where they were not desired in the data). The quotes were stripped out with pandas and Python prior to the ingest, although another possibility would be using regular expressions in the Ruby script.
Each of the fields with unwanted quotes was passed into a function to remove quotes:
people_frame = remove_quotes(people_frame), 'person_case_year')
The pandas function to remove the quotes was difficult to write, and some of the complexity arose from the fact that the values were nested within arrays such that they cannot readily be replaced. In the below pandas function, the arrays in the column are “exploded” (turning each array value into a separate row), and then quotes and NaN values are replaced in each string. Finally, the exploded arrays are aggregated again into their original places in the frame:
def remove_quotes
df[column]= df.explode(column)[column].astype(str).str.replace("\"", "").replace('nan', '').replace("None", '').groupby(level=0).agg(list)
The complexity of this process ultimately arose from limitations in how Airtable handles and exports data from join tables.
Assessing Airtable as a Data Platform
From the perspective of a backend developer, Airtable has numerous advantages and disadvantages for storing and processing digital humanities data. It can model complex associations and relationships, like a relational database does, giving it an advantage over traditional spreadsheets. Data entry does not require knowledge of SQL or any other programming language, and is simple enough to be handled by non-programmers (like many CDRH students). The data can be authored and edited by a team working in collaboration. Airtable makes it relatively easy to keep the data consistent, do deduplication, and so on. Airtable tables can also be exported into open-source formats like CSV and JSON, which can be imported into an API with simple data transformations. These advantages will mean that the Center for Research in Digital Humanities is likely to continue using it for its projects.
Airtable does have some disadvantages that might make a digital humanities center reconsider using it. It is a proprietary platform that can only be accessed through the website, by obtaining user permissions or an API key. Airtable requires a paid subscription to start and maintain a base and add collaborators, which may be beyond the means of some institutions. With any proprietary platform there is a chance that it may change its terms in the future and make the platform less accessible and more costly. References between tables are not represented adequately in the exported data formats but shown as a list of unreadable random numbers. This accounts for much of the processing that must be done on the Airtable side and backend scripts to make the data usable by APIs and human readable. In addition, Airtable does not have all the error checking/consistency checking features of a SQL database, and many tasks (especially using formulas for transforming records) do require some programming knowledge. For this reason, it is better to use spreadsheets for simple projects that do not need linked records, and traditional relational databases if data entry can be handled by skilled professionals with programming expertise. The CDRH is exploring open-source alternatives to Airtable including Baserow and NocoDB, although we have not yet ascertained to what degree they can replicate the functionality of Airtable. Future work will seek to discover and assess alternatives to Airtable that are more sustainable and accessible.
Acknowledgements
Other members of the CDRH development team who worked on the Petitioning for Freedom and African Poetics include Karin Dalziel (team lead and Digital Resources Designer, who designed the Airtable formulas and the schema for representing linked data), Sarita Garcia (who assisted with database design), Andrew Peterson (who managed the Airtable system), Greg Tunink, Erin Chambers, and Laura Weakley. Mike Litwa of Library IT assisted in creating the download scripts for Airtable. Cory Young served as project manager on Petitioning for Freedom. Credit must also be given to the many student assistants who helped with data entry on both African Poetics and Petitioning for Freedom.
Bibliography and Notes
[1] Airtable Platform [Internet]. [updated 2023]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://www.airtable.com/platform.
[2] Supported Field Types in Airtable Overview [Internet]. [updated 2023 Sep 18] San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/supported-field-types-in-airtable-overview
[3] [7] Formula Field Reference [Internet]. [updated 2023].https://support.airtable.com/docs/formula-field-reference
[4] However, formulas do require some knowledge of markup and programming, depending on their complexity.
[5]Getting Started with Airtable Automations [Internet]. [updated 2023 Aug 23]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/getting-started-with-airtable-automations.
[6] Linking Records in Airtable [Internet]. [updated 2023 Aug 23]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/linking-records-in-airtable.
[8]Airtable Base Collaboration Overview [Internet]. [updated 2023 Aug 23]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/airtable-collaboration-overview.
[9] Using Array Functions in Airtable [Internet]. [updated 2023 Sep 18]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/using-array-functions-in-airtable.
[10] About the CDRH [Internet]. [updated 2023 Jul 24]. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://cdrh.unl.edu/about/aboutcdrh
[11] Orchid [Internet]. [updated 2022 Dec 19]. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from <a href=”https://github.com/cdrh/orchid.”>https://github.com/cdrh/orchid.</a>
[12] Dalziel, Karin. 2018. A new way to publish: The CDRH API [Internet]. CDRH Development blog. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 20]. Available from https://cdrhdev.unl.edu/log/2018/api/.
[13] [30]API Reference [Internet]. [updated 2023]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://airtable.com/developers/web/api/introduction.
[14] Datura [Internet]. [updated 2023 Mar 23]. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://github.com/cdrh/orchid.
[15]Jagodinsky, Katrina, Cory Young, et al. 2023. Petitioning for Freedom. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://petitioningforfreedom.unl.edu/.
[16] habeascorpus. Github [Internet]. [updated 2023 Sep 25] University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://github.com/cdrh/african_poetics
[17] The Github files are under the name habeas_corpus because an earlier working title for the project was Habeas Corpus.
[18] In the matter of the application for a Writ of Habeas Corpus for Gwoo Shee Ah Look. Jagodinsky, Katrina, Cory Young, et al. Petitioning for Freedom [Internet]. [updated 2023 Oct 21] Lincoln, NE: University of Nebraska, Lincoln. [cited 2023 Oct 22] https://cdrhdev1.unl.edu/habeascorpus/cases/item/hc.case.wa.0183
[19] Dawes, Kwame, et al. 2023. African Poetry Book Fund [Internet]. Lincoln, NE: University of Nebraska, Lincoln. [cited 2023 Oct 1]. Available from africanpoetrybf.unl.edu.
[20] Dawes, Kwame, and Lorna Dawes, et al. 2023. African Poetry Digital Portal [Internet]. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://africanpoetics.unl.edu/.
[21] african_poetics. Github [Internet]. [updated 2023 Sep 25] University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 1]. Available from https://github.com/cdrh/african_poetics
[22] Delius, Anthony ‘Ronald St. Martin’. African Poetry Digital Portal [Internet]. [updated 2023]. Lincoln, NE: University of Nebraska, Lincoln. Center for Research in Digital Humanities. [cited 2023 Oct 22]. Available from https://africanpoetics.unl.edu/inthenews/poets/item/apdp.person.000001.
[23] Getting Started with Airtable Views [Internet]. [updated 2023 Aug 23]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/getting-started-with-airtable-views.
[24] Willison, Simon. 2023. airtable-export. Github [Internet]. [cited 2023 Oct 1] Available from https://github.com/simonw/airtable-export.
[25] https://github.com/simonw/airtable-export. The tool can be downloaded vi PIP
[26] Personal Access Tokens [Internet]. [updated 2023 Apr 20]. San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://airtable.com/create/tokens (login required). https://airtable.com/create/token
[27] Zhao, Frank. 2023. New API capabilities now in GA and upcoming API keys deprecation period. Airtable Community. [cited 2023 Oct 1]. Available from https://community.airtable.com/t5/announcements/new-api-capabilities-now-in-ga-and-upcoming-api-keys-deprecation/ba-p/141824?utm_ID=recdXE5vJZZ5vR0mh&utm_ID=recdXE5vJZZ5vR0mh
[28] Although the script references an “API token” which is now deprecated as a way of accessing Airtable, personal access tokens work in the same way, so this change posed no difficulties in using the `airtable-export` script (Personal Access Tokens, updated 2023).
[29] See https://airtable.com/developers/web/api/introduction after logging in.
[31] Although the script references an “API token” which is now deprecated as a way of accessing Airtable, personal access tokens work in the same way, so this change posed no difficulties in using the `airtable-export` script (Personal Access Tokens, updated 2023).
[32] Kumar, Saurabh. 2023. python-dotenv. Github [Internet]. Available from https://github.com/theskumar/python-dotenv.
[33] This script can be found at https://github.com/CDRH/data_african_poetics/tree/main/scripts/airtableExport
[34] The script can be found at https://github.com/CDRH/data_habeascorpus/tree/dev/scripts/python/json_to_csv.py
[35] Rollup Field Overview [Internet]. [updated 2023 Jul 24] San Francisco, CA: Airtable [cited 2023 Oct 1]. Available from https://support.airtable.com/docs/supported-field-types-in-airtable-overview
[36] The join table was not used directly in the ingest scripts, it is simpler to have each script parse a single table.
[37] Functions in Datura can parse this syntax with regular expressions. For instance, to extract the name between the brackets:
/\[(.*?)\]/.match(query)[1] if /\[(.*)\]/.match(query)
About the Author
Will Dewey is Programmer/Analyst II at the Center for Research in Digital Humanities in the University of Nebraska, Lincoln Libraries

Subscribe to comments: For this article | For all articles
Leave a Reply