By Jennifer D’Souza
Introduction
There is a growing mountain of research. But there is increased evidence that we are being bogged down today as specialization extends. The investigator is staggered by the findings and conclusions of thousands of other workers—conclusions which he cannot find time to grasp, much less to remember, as they appear. … A RECORD if it is to be useful to science, must be continuously extended, it must be stored, and above all it must be consulted. [1]
— Vannevar Bush, As We May Think (1945)
The sheer volume of scientific advancements poses significant challenges for researchers, who must sift through vast amounts of information to derive meaningful insights. This challenge is further compounded by the largely unstructured nature of current scientific communication, which hampers transparency, integration, peer review efficiency, and machine assistance. To overcome these limitations, research records must transition from traditional unstructured formats to machine-actionable, semantically structured representations, such as Knowledge Graphs (KGs), enabling smarter and more efficient research tools. This shift also aligns with the FAIR principles—Findable, Accessible, Interoperable, and Reusable [2] —ensuring usability for both humans and machines. The Open Research Knowledge Graph (ORKG), a flagship project of the TIB Leibniz Information Centre for Science & Technology and University Library, seeks to address these challenges by enabling the structured representation and comparison of scientific contributions based on their key properties. Much like e-commerce platforms that allow side-by-side product comparisons, the ORKG facilitates efficient exploration of scientific knowledge, opening new opportunities for researchers and digital libraries[3][4][5].
The ORKG is a web-based platform and infrastructure designed to structure and interlink scientific knowledge using semantic technologies. Unlike traditional text-based research publishing, the ORKG, in close adherence to the FAIR principles, represents research contributions as interconnected KGs, enabling more efficient comparison, discovery, review, and synthesis of scientific findings. Figure 1 depicts the structured machine-actionable scientific information published on the ORKG. In the ORKG, researchers and librarians can submit structured descriptions of research papers, making scientific knowledge more accessible for both humans and machines. The platform is available as a service with public community access (https://orkg.org/) and is implemented via open-source software (https://gitlab.com/TIBHannover/orkg/). It integrates with persistent identifier services such as DOIs and ORCIDs for improved scientific metadata management and fosters collaboration and Open Science by enabling interdisciplinary research contributions. Additionally, ORKG provides an API as a python package (https://orkg.readthedocs.io/) that allows developers to integrate its capabilities and data into external applications, enhancing knowledge discovery and research automation.

Figure 1. Machine-actionable scientific knowledge capture via semantic publishing in the ORKG (red) versus non-machine-actionable, article-based publishing (gray). This figure depicts the process by which a user fills out a template of key properties of research that generates structured paper descriptions, used by the ORKG to generate comparisons of multiple studies with similar properties.
Tracking the Rapid Advancements in Generative Artificial Intelligence (AI)
The development of Large Language Models (LLMs) began in 2018 with OpenAI’s GPT-1 and Google’s BERT, which pioneered transformer-based architectures for language understanding. Since then, the rapid evolution of LLMs has been characterized by a wave of innovative releases, each pushing the boundaries of performance, efficiency, and accessibility[6]. The year 2023 saw the release of models like Mistral 7B which introduced grouped-query attention for enhanced computational efficiency, while Mixtral 8x7B leveraged sparse mixture-of-experts architectures to optimize scalability without sacrificing performance. Other notable advancements include Meta AI’s LLaMA 2, which improved fine-tuning capabilities and context understanding, and OpenAI’s GPT-4, which significantly expanded multimodal capabilities, including image and text input. Additionally, Anthropic’s Claude series focused on safety and interpretability in alignment techniques, and Google’s Gemini models demonstrated cutting-edge integration of external tools, setting a new benchmark for task-oriented AI. There is a growing focus on open-source development, computational efficiency, extended context handling, and multimodal capabilities. These breakthroughs illustrate the relentless pace of innovation, driven by a combination of architectural refinements, expanded datasets, and collaborative efforts across the AI community. This continuous stream of innovations highlights the transformative potential of LLMs, as well as the increasing challenge of staying informed in such a rapidly evolving landscape.
The continuous influx of new models, techniques, and datasets demands constant vigilance and adaptability. Key information about LLMs is often scattered across scientific articles, organizational blog posts, and source code repositories, making it difficult to track developments efficiently. LLMs can be compared using key details such as model name, organization, release date, pretraining data, fine-tuning strategies, and carbon footprint. Modeling these consistent properties supports better comparison and searchability and is an excellent use case for the open research knowledge graph.
Background: The Open Research Knowledge Graph
Essential technical considerations when publishing KGs include defining salient entities, attributes, and relationships for generative AI models as standardized resources accessible on the web via Uniform Resource Identifiers (URIs). Informational statements about LLMs should also be serialized as structured triples conforming to the Resource Description Framework (RDF) syntax recommended by the World Wide Web Consortium (W3C) [7]. Standard vocabularies, metadata, and publishing data on the web using dereferenceable URIs are crucial for semantic interoperability and linking to external datasets, enabling a true linked data ecosystem.
These functionalities are fully supported by the ORKG, a next-generation scholarly publishing platform. In this vein, the ORKG is not just software but also a namespace for specifying scholarly vocabularies via URIs, intuitive interfaces for defining resources properties, classes, and templates, and backend technologies for representing the KG in RDF syntax. Additionally, its machine-actionable semantic structure supports advanced comparison views, akin to e-commerce product comparisons, and enables SPARQL queries for customized or aggregated views of structured scholarly knowledge.
The ORKG adopts a collaborative, dynamic knowledge creation model inspired by Wikipedia, where anyone can contribute data using vocabularies of their choice to represent entities interconnected via RDF links, forming a global, discoverable data graph. Its open-ended nature allows the content of research artifacts, such as papers and comparisons, to be edited, updated, and republished, with all versions stored for future reference. Persistent identifiers, such as DOIs, enable precise referencing of specific versions, while provenance metadata—capturing details like creator, creation date, and methods—ensures traceability, trustworthiness, and quality assessment.
DOIs assigned to graph components enhance discoverability through global scientific bibliometric infrastructures like DataCite and Crossref, while resources are also findable via search engines. Accessibility is ensured through HTTP protocols, REST APIs, and a user interface, with metadata accessible independently of graph data. The ORKG achieves interoperability using RDF, the W3C-recommended standard for machine-readable knowledge representation, and fosters reusability by automatically generating provenance metadata and publishing graph data under a CC BY-SA license. These features collectively support efficient, trustworthy, and FAIR-compliant scientific knowledge dissemination.
Taming the Generative AI Wild West: A Catalog of LLMs on the ORKG
Publishing information about LLMs on the ORKG begins with defining standard properties for their structured and comparable description. Drawing inspiration from Hugging Face, a central hub for open-source LLMs and their model cards, the author developed a standardized vocabulary and schema to support knowledge capture and semantic representation.
4.1. The LLM Specification ORKG Template
Standardized Nomenclature. To ensure consistency, we established a controlled vocabulary that forms the foundation of the LLM Specification Schema. Properties were derived from Hugging Face model cards, with additional LLM-specific predicates added to the ORKG web namespace to expand the vocabulary. To align these properties with external ontologies, the RDF same-as relation was employed to establish equivalences across predicates.
Use of ORKG Templates. For uniform recording of LLM information, we created a form-based template comprising predetermined properties. This template system leverages recurring subgraph property patterns in the ORKG, enabling the consistent specification of relevant attributes across multiple contributions. The template includes 27 structured properties that comprehensively describe LLMs, including:
- Identification: model name, model family, organization, and date created.
- Development Details: pretraining architecture, pretraining task, pretraining corpus, size of training corpus (in tokens in billions), knowledge cutoff date and innovation.
- Fine-Tuning: fine-tuning task and fine-tuning data for refinement.
- Technical Specifications: optimizer, tokenizer, number of parameters, maximum number of parameters (in million), and context length (in tokens).
- Language and Usage: supported language, extension, and application.
- Infrastructure and Impact: hardware used, hardware description, and carbon emitted (tCO2eq).
- Transparency and Licensing: Availability of the source code, blog post, license, and the research problem addressed.
These properties ensure a holistic representation of LLMs, enabling structured comparisons and detailed analysis. For example, transparency is supported by attributes such as source code availability, while environmental impact is captured through carbon emissions data.
The ORKG LLM Specification Schema, which encapsulates these 27 properties, is accessible on the ORKG platform. This schema empowers researchers to record, compare, and analyze LLMs with precision and consistency, fostering greater transparency and accessibility in the study of generative AI.
4.2. The ORKG Catalog of LLM-centric Papers, Comparisons, Visualizations, and Review
Different papers on LLMs are published as structured semantic descriptions in the ORKG using the ORKG papers module and then aggregated as ORKG Comparisons of research. Comparisons are the core type of ORKG content and give a condensed overview on the state-of-the-art for a particular research question. Contributions towards the problem are organized in a tabular view and can be compared and filtered along different properties. Here is a published comparison of 92 LLMs with respect to their structured, machine-actionable descriptions published as one research comparison on the ORKG. The comparison includes metadata such as a title, creator, and a short description paragraph. The unique aspect of ORKG Comparisons is that they can be published at any granularity. For instance, if there are structured descriptions of the early OpenAI LLMs, viz. GPT-1, 2, and 3, I can aggregate them as an ORKG Comparison. This is depicted in Figure 2 below.

Figure 2. A comparison of early OpenAI Large Language Models (LLMs), accessible on the ORKG platform.
Additionally, the machine-actionability afforded by this fine-grained semantic information in the ORKG supports dynamic interactions, such as computing visualizations from the data of any comparison. For instance, the author created another comparison titled “A Catalog of DeepMind’s LLMs including their seminal Chinchilla model” ( based on their early models—AlphaFold, Gopher, Chinchilla, GopherCite, Flamingo, Gato, and Sparrow. Figure 3 below depicts a column chart, comparing, for each model, the parameter size of the largest variant (measured in millions). This showcases how machine-actionable scientific knowledge in a structured digital library can provide quick insights into specific research questions. For instance, one could explore questions like “What was the largest model size released by DeepMind?” or “What was the maximum variation in LLM sizes across DeepMind’s models?”
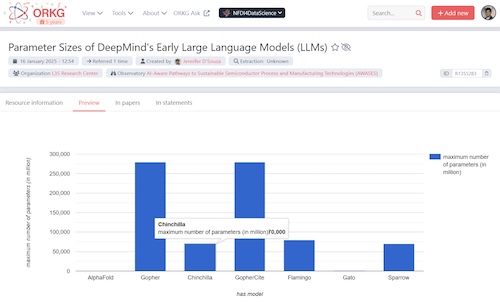
Figure 3. A column chart comparing the parameter sizes (in millions) of seven early DeepMind models—AlphaFold, Gopher, Chinchilla, GopherCite, Flamingo, Gato, and Sparrow—based on the ORKG comparison “A Catalog of DeepMind’s LLMs including their seminal Chinchilla model” (https://orkg.org/comparison/R1355351). The chart dynamically visualizes machine-actionable data from the ORKG platform and hovering over any bar in the chart shows the underlying data stored in the ORKG for that specific plot. The resource is published at https://orkg.org/resource/R1355283.
Finally, the ORKG offers Reviews, a tool designed for authoring and publishing review articles that facilitates community-based creation of dynamic, living articles by utilizing comparisons from the open research knowledge graph to deliver machine-actionable knowledge. For example, the review available at https://orkg.org/review/R640001 aggregates multiple LLM comparisons. It provides granular insights into the features of LLMs developed by various organizations while also integrating these into a broader comparison of all models. This approach is ideal for review articles, enabling detailed analyses of studies or, in this case, comparisons of the LLMs reviewed.
4.3. Queryability
SPARQL queries can be used to generate smaller, specific views of the data. For example, the query below might be translated into a natural language question as follows: which LLM models were created in 2023? This query returns a table (limited to the first 100 results) of paper titles, their accompanying LLM, and the LLM creation date. Natural extensions of this query would be to change the year, and even to be able to specify a range of dates in the form of yyyy-mm-dd within which to search. This is an open query endpoint available to any user of the web.
PREFIX orkgp: <http://orkg.org/orkg/predicate/>
PREFIX orkgc: <http://orkg.org/orkg/class/>
PREFIX orkgr: <http://orkg.org/orkg/resource/>
SELECT ?paper_label ?model_label ?date_created
WHERE {
orkgr:R609337 orkgp:compareContribution ?contribution .
?contribution orkgp:HAS_MODEL ?model .
?model rdfs:label ?model_label .
?paper orkgp:P31 ?contribution .
?paper rdfs:label ?paper_label .
?contribution orkgp:P49020 ?date_created .
FILTER(STRSTARTS(STR(?date_created), "2023"))
}
LIMIT 100
While this paper outlines the use case for LLM, the possibilities and opportunities for interlinking information on the web are substantial.
Related Work
The closest representation of the information captured via the Transformer model or LLM ORKG Template are model cards for these models released on HuggingFace Hub [8],. However, the model cards and fine-grained knowledge representation in KGs like ORKG differ significantly in terms of discoverability, reproducibility, and sharing. Model cards are again human-readable documents offering project explanations, but their discoverability is limited to keyword-based searches in repositories, and they often lack the semantic structure needed for precise, automated discovery. While recommendations for model cards involve filling out relevant values for model properties, this structured representation, while it might improve human readability to quickly gloss over the features of a model, lacks machine-actionability since they remain embedded within a document. In contrast, KGs provide machine-readable, structured, and semantically rich representations that enhance discoverability through advanced querying and metadata tagging. They excel in reproducibility by capturing detailed, standardized metadata, tracking updates, and linking methods and datasets transparently. Furthermore, KGs enable seamless sharing and integration within interconnected systems, promoting collaboration and interoperability, unlike the static and standalone nature of any text document regardless of which format it is prescribed to be written in for better human readability.
Despite its advantages, implementing a structured, KG-based approach for model representation presents challenges, particularly in ensuring the quality of articles authored from structured reviews. While ORKG enhances discoverability and reproducibility through machine-readable key aspects of the scientific content, expert oversight remains essential for translating structured data into high-quality narratives. Sustainability is another key factor—unlike volunteer-driven efforts, ORKG benefits from state funding as the flagship project of the TIB, ensuring long-term development. This support enables continuous improvements in automation and usability, reducing the effort required for researchers to contribute structured knowledge. By integrating machine-assisted extraction, incentivizing contributions, and aligning with scholarly publishing workflows, ORKG fosters broader adoption. Thus, it provides a sustainable and scalable framework for improving model discoverability, reproducibility, and knowledge sharing.
Conclusion
This article highlights the transformative potential of using knowledge graphs, specifically the Open Research Knowledge Graph (ORKG), to represent and manage information about generative AI technologies such as Large Language Models (LLMs). By adopting a structured, semantic, and machine-actionable approach, the ORKG ensures that the resulting knowledge adheres to FAIR principles—Findable, Accessible, Interoperable, and Reusable.
The KG-based representation demonstrated in this article is not only applicable to LLMs but is easily transferable to other scientific domains. The ORKG platform exemplifies the versatility of a modern digital library, offering generic infrastructure that enables users from any field to model their research as structured knowledge using templates, papers, comparisons, visualizations, and reviews. These living records can be edited and curated collaboratively, ensuring that the knowledge remains dynamic, up-to-date, and accessible to both humans and machines.
By addressing the challenges of fragmented, unstructured knowledge, this approach mitigates the creation of information silos and fosters greater transparency, reproducibility, and usability. Ultimately, leveraging the ORKG and similar platforms paves the way for a more interconnected and machine-actionable future in scientific knowledge dissemination and discovery.
References
[1] Bush, V. (1945). As We May Think. The Atlantic. Retrieved from https://www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
[2] Wilkinson MD, Dumontier M, Aalbersberg IJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten JW, da Silva Santos LB, Bourne PE, et al. 2016. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific Data. 3(1):1–9.
[3] Auer S, Oelen A, Haris M, Stocker M, D’Souza J, Farfar KE, Vogt L, Prinz M, Wiens V, Jaradeh MY. 2020. Improving Access to Scientific Literature with Knowledge Graphs. Bibliothek Forschung und Praxis. 44(3):516–529.
[4] Stocker M, Oelen A, Jaradeh MY, Haris M, Arab Oghli O, Heidari G, Hussein H, Lorenz AL, Kabenamualu S, Farfar KE, Prinz M, Karras O, D’Souza J, Vogt L, Auer S. 2023. FAIR scientific information with the Open Research Knowledge Graph. FAIR Connect. 1(1):19–21. https://doi.org/10.3233/fc-221513.
[5] D’Souza J, Hussein H, Evans J, Vogt L, Karras O, Ilangovan V, Lorenz AL, Auer S. 2024. Quality Assessment of Research Comparisons in the Open Research Knowledge Graph: A Case Study. JLIS.it. 15(1):126–143.
[6] Fourrier, C. (2023). 2023, Year of Open LLMs. Hugging Face. Retrieved from https://huggingface.co/blog/2023-in-llms
[7] Cyganiak, R., Wood, D., & Lanthaler, M. (2014). RDF 1.1 Concepts and Abstract Syntax. World Wide Web Consortium (W3C). Retrieved from https://www.w3.org/TR/rdf11-concepts/
[8] Hugging Face. (n.d.). Model Cards. Retrieved from https://huggingface.co/docs/hub/en/model-cards
About the Author
Dr. Jennifer D`Souza, TIB Leibniz Information Centre for Science and Technology, (M.Sc. in Computer Science, University of Texas at Dallas, 2010 and Ph.D. in Computer Science, University of Texas at Dallas, 2015). Dr. D’Souza is a senior postdoctoral researcher at TIB Leibniz Information Centre for Science and Technology, specializing in AI, NLP, and scientific knowledge extraction and organization. She leads the NLP-AI aspect of the Open Research Knowledge Graph (ORKG) and heads the SCINEXT project, advancing neuro-symbolic AI and NLP for scientific innovation extraction, funded by the German Ministry of Education and Research (BMBF). Her projects develop knowledge extraction and organization services, recently using generative AI, aimed at enhancing the strategic use of science and innovation to bolster societal R&D cycles.

Subscribe to comments: For this article | For all articles
Leave a Reply