By Aerith Y. Netzer
Background and Motivation
Northwestern University Libraries publishes two peer-reviewed journals, The Bulletin of Applied Transgender Studies, and Studies in Russian Philosophy, Literature, and Religious Thought. Northwestern’s journal publishing operates under tight economic constraints—direct and opportunity—and therefore must solve the same problems of corporate academic publishers with a fraction of the resources available [1][2]. One of these problems is reference metadata, i.e., machine-actionable references that are then used to count citations of articles. The act of capturing, counting, and using citations accurately enables funding agencies, universities, and publishers to make data-driven decisions for funding allocation, reviewers to validate the research of a manuscript, and faster literature review.
An Example
The workflow for our university—a medium-size, elite university in the Midwest United States—consists of receiving manuscripts from authors in a Microsoft Word file format. We then use pandoc [3] to transform this Word document to a markdown file format, from which we can build PDF and Web versions from a single source. But due to manuscript author’s primarily writing their manuscript in Microsoft Word, this meant looking up each source, adding them to a Zotero [4] library, and then exporting the BibTeX file for use as metadata in the web version of the article. As Northwestern Libraries’ journal-publishing operation is a one-woman show and quickly growing in complexity and scope, we found it necessary to find a way to find a faster way.
There have been many projects aimed to converting plain-text to BibTeX using programmatic means, but are often limited to certain languages [5] or are dependent upon external data [6]. As Northwestern’s journal submissions often use non-latin languages, such as sources in Studies in Russian Philosophy, this is a limitation that precludes many of the sources necessary for us to translate into machine-readable text [7]. As Large Language Models grew popular, we originally reached for the most popular option — the GPT-3 and 3.5 API. However, due to these popular options being paid, using this method would not be scalable to many journals with hundreds of citations to process per volume/issue. Further, we as an organization prefer transparency and replicability in our tools. As GPT is managed by OpenAI, access to the model can be closed at any time, forcing us to move to a new system. While with open-source systems, we can upgrade or downgrade as needs arise, and we need not pay. Thus, we reached for another, more open, tool—Ollama [8].
Limitations & Concerns
This analysis is limited to works that appear in the crossref API, creating a bias in the dataset against older works and academic monographs. While this limits the usefulness of this analysis to publishers whose specialty lies within fields where citations are limited to recent works (such as the physical sciences), future work can and should include plain-text citations of historical, non-digital, and non-academic works.
Along with the rapid growth in users of Large-Language models, so have concerns over the ecological sustainability of LLM technology [9][10]. Most of these concerns, however, can be alleviated with the use of “small” models such as those provided by Ollama. Further, there are concerns about the validity of Large-Language models, especially concerning their propensity to hallucinate. However, in combination with validity checkers such as bibtexparser and human review, we are confident enough in this system to be used in production of our journals [11]. Future work in this area should include building scalable, verifiable workflows that require less human oversight.
Methodology
Data [12] was collected via the CrossRef API. Using the sample function of the crossref API, we retrieved a random DOI. Then, using the Crossref content negotiation endpoint, we were able to retrieve a plain-text formatted citation from a randomly selected citation style from the following:
- Chicago Author-Date
- Elsevier-Harvard
- Ecoscience
- APA
- MLA
- IEEE
- Council of Science Editors
Using the CrossRef API, we pulled the BibTex Citation, the Plaintext Citation, and the DOI to create a dataset for our analysis. Table 1 presents the variables and their descriptions.
| Variable | Description |
|---|---|
| DOI | The Digital Object Identifier of the requisite work. |
| BibTeX Citation | Metadata about the work in BibTeX format. |
| Plain Text Citation | The cited work in a given citation style. |
| Plain Text Citation Style | The style in which the plain text citation is given. |
Using this random assignment of citation formats, we achieved a roughly even distribution of each citation style in the dataset (see Figure 1).
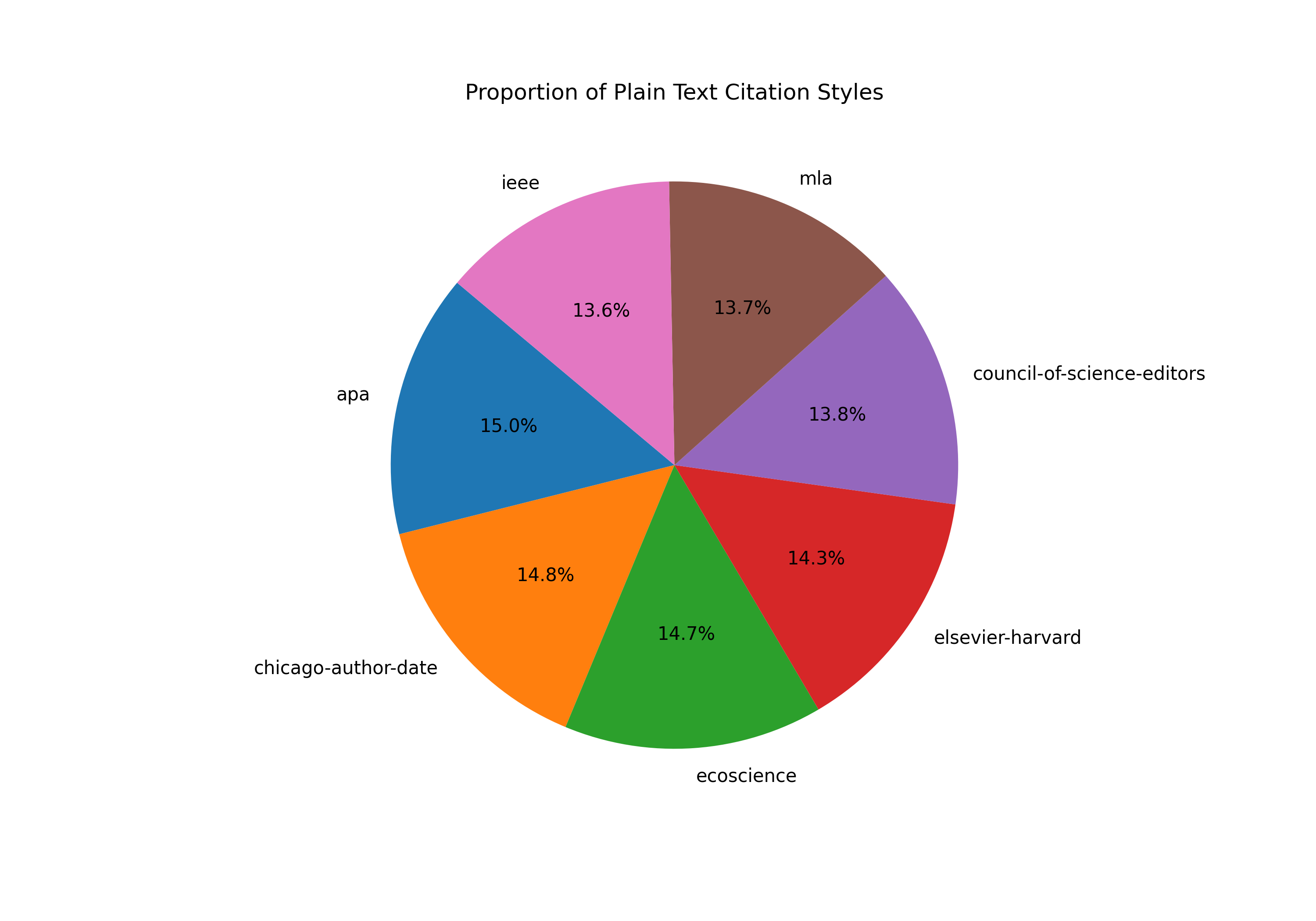
Figure 1. Pie Chart demonstrating the proportion of each citation style present in the dataset.
Analysis
All language models (see Table 2) were tested using the Ollama toolkit using the Quest [13] supercomputing cluster at Northwestern University, running in a singularity container [14][15]. Testing of all models took 14 hours to complete on two NVIDIA A100 Graphical Processing Units, one node with eight cores, and 128 gigabytes of memory[16][17]. All code was written in python using an Anaconda environment to aid in reproducible deployments of this code [18]. We used the plain text citation given by the CrossRef content negotiation API as a ground truth to which the model would aspire. We prompted each model with the same text:
You are a professional citation parser. Given the following plain text citation: {plain_text_citation} Please convert this citation into a structured BibTeX entry. Include all relevant fields such as author, title, journal, volume, pages, year, etc. Output only the BibTeX entry, and nothing else. Do not include any explanations, preambles, or additional text.
The following models were prompted in this analysis
These models were chosen to represent a range of model sizes and training methods. The following variables were saved to the output file of the model:
| Variable | Description |
|---|---|
| Model | The model being tested. One of the eight models listed above. |
| PlainTextCitation | Maps to plain text citation field table 1. |
| TimeToGeneration | Time taken to generate the entry. |
| ActualBibTeX | BibTeX entry retrieved from Crossref. |
| TotalFields | The number of BibTeX fields being compared in generated and “ground truth” entries. |
| Matching Fields | The number of fields that have a match in both the generated and “ground truth” entries. |
| Percentage Match (Overall Accuracy) | Matching Fields / Total Fields |
This generated 8 CSV files of approximately 3,000 lines each. Each row corresponds to a single DOI. These files were used for analyzing the efficiency and effectiveness of each model.
Model Effectiveness
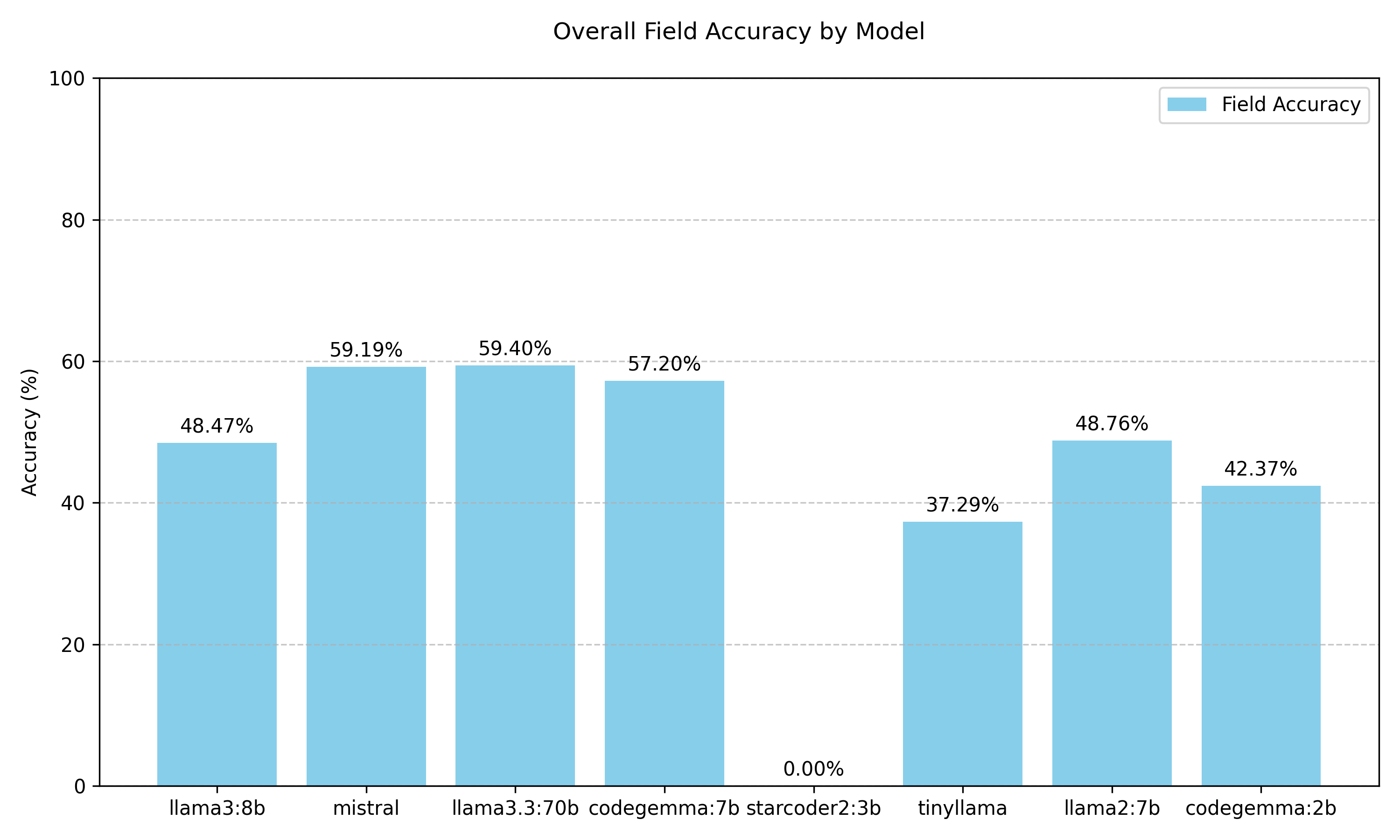
Figure 2. Per Field Accuracy and Valid BibTeX of the Model.
Unsurprisingly, llama3.3:70b, the most advanced and largest model of the chosen models, performed the best. Further, starcoder2:3b failed to create any valid BibTeX entries, whereas every other model created valid BibTeX for every citation.
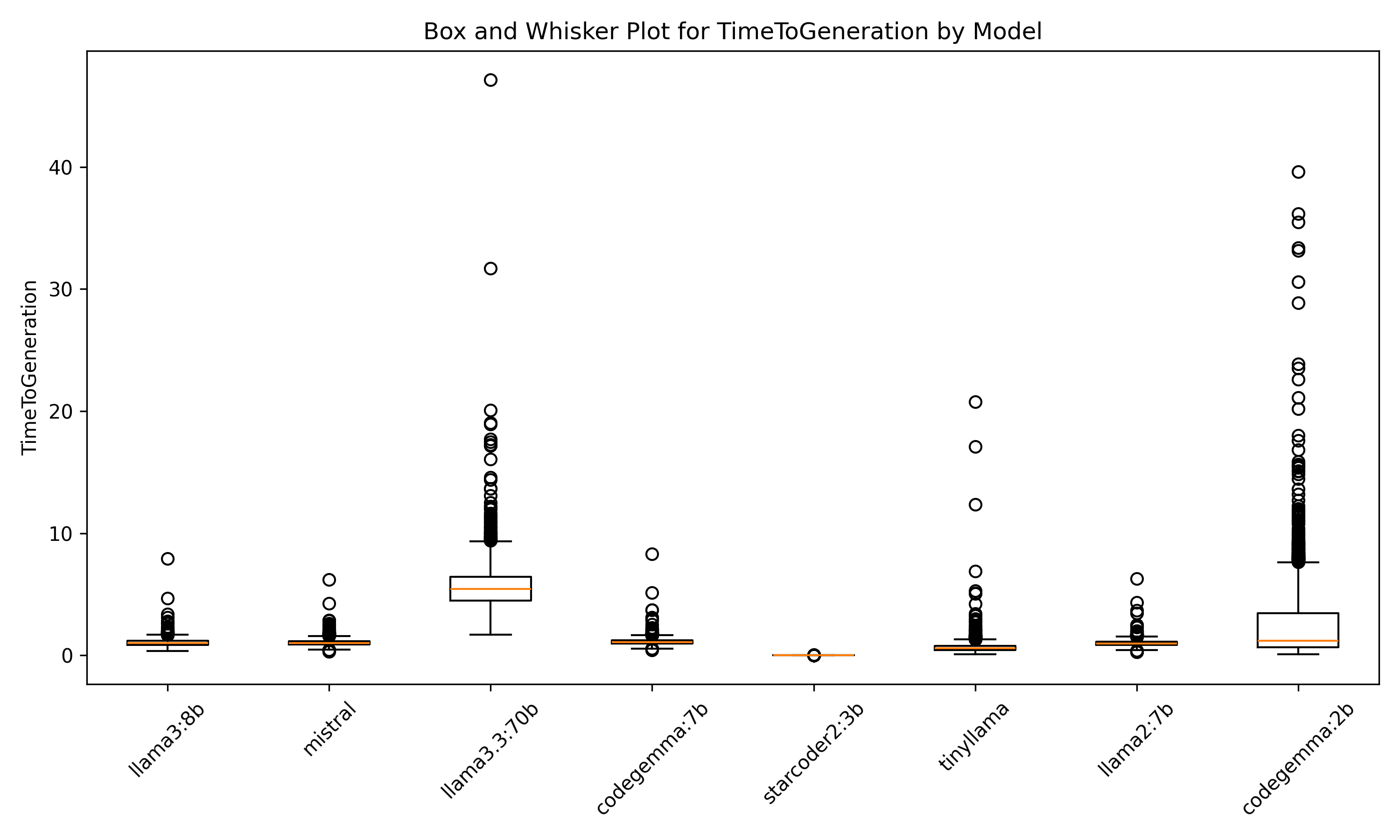
Figure 3.Box and Whisker Plot for TimeToGeneration by Model
| Model | Median Time to Generation (seconds) | Standard Deviation (seconds) |
|---|---|---|
| codegemma:2b | 1.18 | 3.24 |
| codegemma:7b | 1.08 | 0.29 |
| llama2:7b | 0.96 | 0.27 |
| llama3.3:70b | 5.45 | 1.90 |
| llama3:8b | 1.00 | 0.31 |
| mistral | 1.00 | 0.27 |
| starcoder2:3b | 0.00 | 0.00 |
| tinyllama | 0.57 | 0.64 |
As every model except for starcoder2:3b created valid BibTeX perfectly, we are primarily concerned with the accuracy of the fields. In this discussion, the validity of the BibTeX simply means that if the BibTeX can be parsed without errors, then the BibTeX is valid. However, a well-formed BibTeX entry can be valid but incorrect. Meaning that the entry can be parsed, but the data in the entry is wrong. llama3.3:70b generated the most accurate BibTeX entries. However, we should not assume that the model was necessarily incorrect, but was just different from how Crossref represented the field. Mistral and Codegemma, though, are very close behind, especially with their parameter sizes (and therefore cost of compute) much lower than llama3.3:70b, it may be economical for some publishing operations to use smaller models, decreasing their cost, while keeping parity with the accuracy of the model. Trading a .2% reduction in overall accuracy for, on average, a 5x faster computation is an effective strategy for this use case.
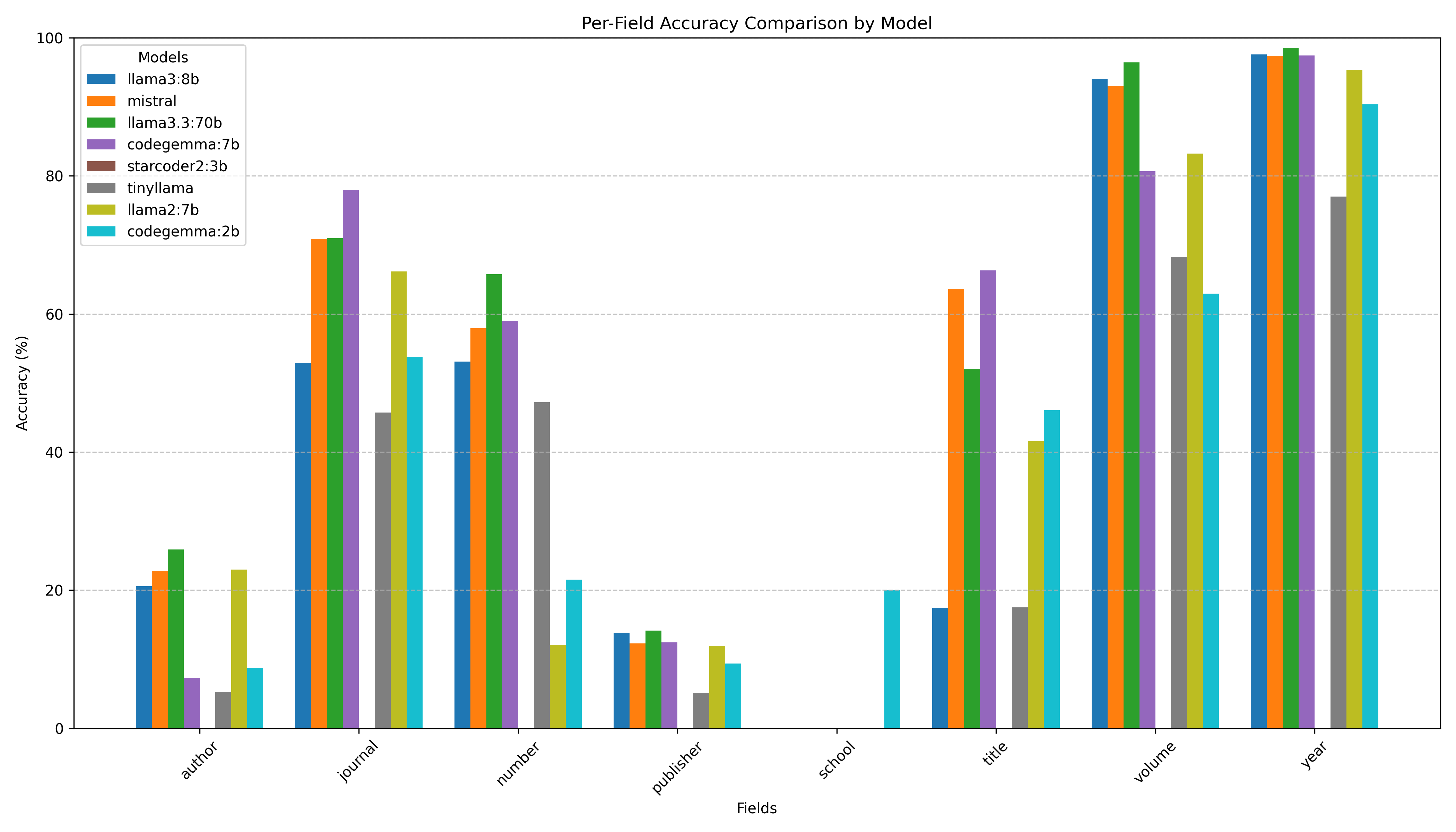
Figure 4.Per-field accuracy by model
All models were very accurate in producing volume, year, and journal entries in BibTeX, while author, publisher, and school were the least accurate fields. This is because there is greater freedom and flexibility in how these fields are entered, and thus a correct and valid generated BibTeX need not be exactly the same as Crossref’s representation of the same data. Future work should include creating a validator to identify equivalent author, publisher, and school names.
For example, consider the following BibTeX entries:
{National Academy of Sciences, The}
{The National Academy of Sciences}
While these entries refer to the same entity, they cannot be identified as the same programmatically, and are thus penalized as “inaccurate.” Thus, the results in Figure 2 should be interpreted as the models’ accuracy when using Crossref as the metric of accuracy. This analysis is useful because it shows which models are better-suited for this task, rather than the concluding 50% of the fields to be incorrect.
Recreating Results on Consumer Hardware
While we ran these models on a supercomputer to aid in analysis, models with parameter sizes of less than 10 billion can be run on current consumer hardware. We recommend a computer with a dedicated, modern GPU (verified to work on the author’s personal Nvidia 3080Ti, AMD Ryzen 6-core CPU, and 32 GB of RAM; and an Apple M3 Max with 36 GB of memory)
For UNIX Systems, use cURL to install Ollama with one command:
curl -fsSL https://ollama.com/install.sh | sh
Then pull the model (we recommend mistral):
ollama pull mistral
Then, start an Ollama server listening on port 11434:
def generate_text_with_ollama(model_name, prompt):
url = 'http://localhost:11434/api/generate'
payload = {
"model": model_name,
"prompt": prompt,
"temperature": 0, # Make output more deterministic
"stop": ["\n\n"]
}
headers = {
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers,
data=json.dumps(payload), stream=True)
# Handle streaming response
generated_text = ''
for line in response.iter_lines():
if line:
data = json.loads(line)
if data.get('done', False):
break
else:
generated_text += data.get('response', '')
return generated_text.strip()
You can then pass any input you like to this function and return a generated BibTex Key. Full code sample is in the author’s GitHub repo.
Conclusion
For university-owned publishers, small, locally-available LLMs are capable of producing well-formed BibTeX. These models can be used to create machine-actionable citation metadata, automating a step in the publishing process. As of the publication of this paper, 7 billion parameter models, especially mistral, are capable of running on the latest laptops, and provide acceptable performance at the least cost.
Data and Code Availability
The author strives to adhere to the FAIR guiding principles. Code and data used for this analysis is available on GitHub.
References and Notes
[1] Association of College & Research Libraries. “The State of U.S. Academic Libraries: Findings from the ACRL 2023 Annual Survey.” Chicago: Association of College & Research Libraries, 2024. Retrieved from https://www.ala.org/sites/default/files/2024-10/2023%20State%20of%20Academic%20Libraries%20Report.pdf
[2] RELX. 2023. “Market Segments.” RELX.
[3] “Pandoc – Index.” n.d. https://pandoc.org/. Accessed March 8, 2024.
[4] “Zotero Your Personal Research Assistant.” n.d. https://www.zotero.org/. Accessed December 31, 2024.
[5] “Makino Takaki’s Page – Writings – Technical Tips – Generate BiBTeX Entry from Plain Text (.en).” n.d. https://www.snowelm.com/~t/doc/tips/makebib.en.html. Accessed March 9, 2024.
[6] “Text2bib.” n.d. https://text2bib.economics.utoronto.ca/index.php/index. Accessed March 9, 2024.
[7] Williams, Rowan. 2024. “Sergeii Bulgakov, Socialism, and the Church.” Northwestern University Studies in Russian Philosophy, Literature, and Religious Thought.
[8] “Ollama/Ollama.” 2025. Ollama.
[9] Ding, Yi, and Tianyao Shi. 2024. “Sustainable LLM Serving: Environmental Implications, Challenges, and Opportunities : Invited Paper.” In 2024 IEEE 15th International Green and Sustainable Computing Conference (IGSC), 37–38. https://doi.org/10.1109/IGSC64514.2024.00016.
[10] (Chien, Andrew A, Liuzixuan Lin, Hai Nguyen, Varsha Rao, Tristan Sharma, and Rajini Wijayawardana. 2023. “Reducing the Carbon Impact of Generative AI Inference (Today and in 2035).” In Proceedings of the 2nd Workshop on Sustainable Computer Systems, 1–7. Boston MA USA: ACM. https://doi.org/10.1145/3604930.3605705.
[11] “About the Journal – Bulletin of Applied Transgender Studies.” n.d. https://bulletin.appliedtransstudies.org/about/. Accessed March 8, 2024.
[12] [18] Netzer, Aerith. “aerithnetzer/Biblatex-Transformer.” 2025. https://github.com/aerithnetzer/biblatex-transformer.
[13] “Quest High-Performance Computing Cluster: Information Technology – Northwestern University.” n.d. https://www.it.northwestern.edu/departments/it-services-support/research/computing/quest/. Accessed January 1, 2025
[14] Kurtzer, Gregory M., Vanessa Sochat, and Michael W. Bauer. 2017. “Singularity: Scientific Containers for Mobility of Compute.” PLOS ONE 12 (5): e0177459. https://doi.org/10.1371/journal.pone.0177459.
[15] Singularity containers allow for reproducible environments for analysis. The singularity definition file used in this analysis can be found in the GitHub repository. As LLMs are typically stochastic in nature, one can expect to have reasonably similar, but not exactly the same, results as presented in this paper. The singularity definition file primarily serves as a resource for readers to deploy this system in their home institution.
[16]The script used to create the SLURM job can be found in the GitHub repository https://github.com/aerithnetzer/biblatex-transformer.
[17] Thank you to Kat Nykiel at Purdue University for her assistance in building and deploying the singularity container.
About the Author
Aerith Y. Netzer is the Digital Publishing and Repository Librarian at Northwestern University in Evanston, Illinois.

Subscribe to comments: For this article | For all articles
Leave a Reply