By Hyung Wook Choi, Jonathan Wheeler, Weimao Ke, Lei Wang, Jane Greenberg, and Mat Kelly
Introduction
Data liberation is fundamental to enabling data reuse. The concepts of data reuse, data sharing, and open data have gained significant attention in academic and research communities, with the goal of making research outputs more widely accessible for purposes such as education, business, and further scientific inquiry [1][2]. By promoting open access, researchers can ensure that valuable data sets contribute well beyond their original scope of analysis [3]. However, several barriers hinder effective data reuse, including technical difficulties [4], the absence of standardized practices and supporting infrastructure [5], and concerns about privacy [6].
The advancement of Information Technology (IT) has significantly influenced the growth of e-learning systems, enabling more flexible and accessible opportunities for education across various domains. These systems have supported not only formal education but also cultural engagement and both professional and personal skill development, thereby shaping modern educational infrastructures [7]. Since much of the educational content has become available online, especially post-COVID [8], sharing and reusing educational content holds potential to enhance teaching and learning experiences, promote collaboration among educators, learners, and instructional designers, and ultimately improve educational outcomes. The reuse of educational resources can be adapted and customized into different contexts and strategies to meet specific needs in the fields. Despite the significant benefits, challenges such as copyright concerns, quality assurance, and technical interoperability continue to hinder the sharing and reuse of educational resources and must be systematically addressed [9]. For instance, Poole pointed out the short supply of faculty and the lack of shared and sustainable national infrastructure, including datasets, tools, techniques, and instructional demonstrations, for supporting data science education in the Library and Information Science (LIS) field [10]. The study emphasized that promoting a national digital platform requires coordinated tools and technologies across the educational lifecycle.
In this paper, we describe a preliminary process of liberating instructional material from the Blackboard learning management system (LMS), representative of efforts from grant-funded, multi-year boot camps that occurred in June of 2021, 2022, and 2023. These boot camps preceded 6-month internships by each fellow at institutions in the United States including university libraries, non-profit organizations, and data science-driven collectives, among others. The instructional material was developed and interactively presented by 10 teaching, tenure-track, and tenured professors at the lead university and attended by 68 fellows over three years of the project (24, 26, and 18 fellows in each of the respective years). The topics covered in the boot camp included Data Management, Cleaning, and Mining; Information Retrieval; Data Curation, Preservation, Metadata, and Ontologies Search, and Machine Learning and ChatGPT among others. The purpose of this data liberation effort is to both widely share the extensive, well-informed instructional material beyond the original cohorts of fellows but also to explore the nuances that need to be considered beyond the technical efforts, like those of privacy, rights restrictions, and the need to disseminate the material in an LMS-agnostic, sustainable, usable platform.
Related Work
Several studies have been conducted to associate digital archiving with learning management systems (LMS). Vitaglione et al. proposed a new software model for archiving slide-based presentations from the Internet, built around the Lecture Object format designed for storing lectures online [11]. This project was developed in collaboration with the CERN HR Division Training and the University of Michigan, aiming to respond to the growing integration of the World Wide Web in educational contexts. Building on this initiative, Bousdira et al. documented the Web Lecture Archiving Project (WLAP), which involved the implementation of web-based archiving technologies to record a series of content-rich presentations at CERN [12]. This was accomplished using Sync-O-Matic, a tool that generates slide-based web lectures viewable through a standard web browser. They introduced a new concept of Learning Object which refers to a standard format for archiving web lectures and for exchanging them between different archives. Herr et al. published another study on lecture archiving at CERN and the University of Michigan as a part of the University of Michigan ATLAS Collaboratory Project (UMACP) [13]. They updated the work that the new system adopting the Lecture Object architecture would be implemented with the goal of a very long-term archive of rich, high-quality media and associated metadata.
Chu et al. examined the advantages and disadvantages of learning management systems (LMS) and lecture capture (LC) technologies by introducing a blended learning model called the START program, which integrated e-learning with virtual mentorship and was implemented at Stanford University [14]. Moodle was selected as the LMS platform for this initiative. Developed by the Anesthesia Informatics and Media Laboratory in the Department of Anesthesia, the program aimed to enhance the preparedness of interns transitioning into anesthesia residency. Their findings indicated that online educational programs can be effective but require substantial technical expertise during the initial setup phase. Jamieson and Verhaart presented three case studies documenting the transition from Blackboard to Moodle [15]. Their analysis revealed that Moodle’s features were less specific compared to Blackboard, leading to issues such as errors during content import. More recently, Santoso et al. proposed an archival system, implemented using Docker, to store and manage historical course content and activities, with the goal of alleviating storage demands on the Moodle server [16]. Following implementation, they conducted three separate evaluation tests. The results demonstrated that variations in course size significantly impacted the time required to restore backup files.
Given that the primary goal of this effort is to archive content for future reuse, we draw on research in web archiving, particularly efforts related to preserving content behind authentication barriers. While Kelly et al. focused on archiving private and personal content [17], their earlier work explored tool development for ad hoc approaches to small-scale data extraction [18], which closely aligns with the scope of our project. More recent initiatives, such as the Webrecorder project [19], have further democratized personal web archiving, making it more accessible regardless of privacy constraints. This body of work has informed our data extraction methodology and will continue to guide our approach as the archiving project evolves.
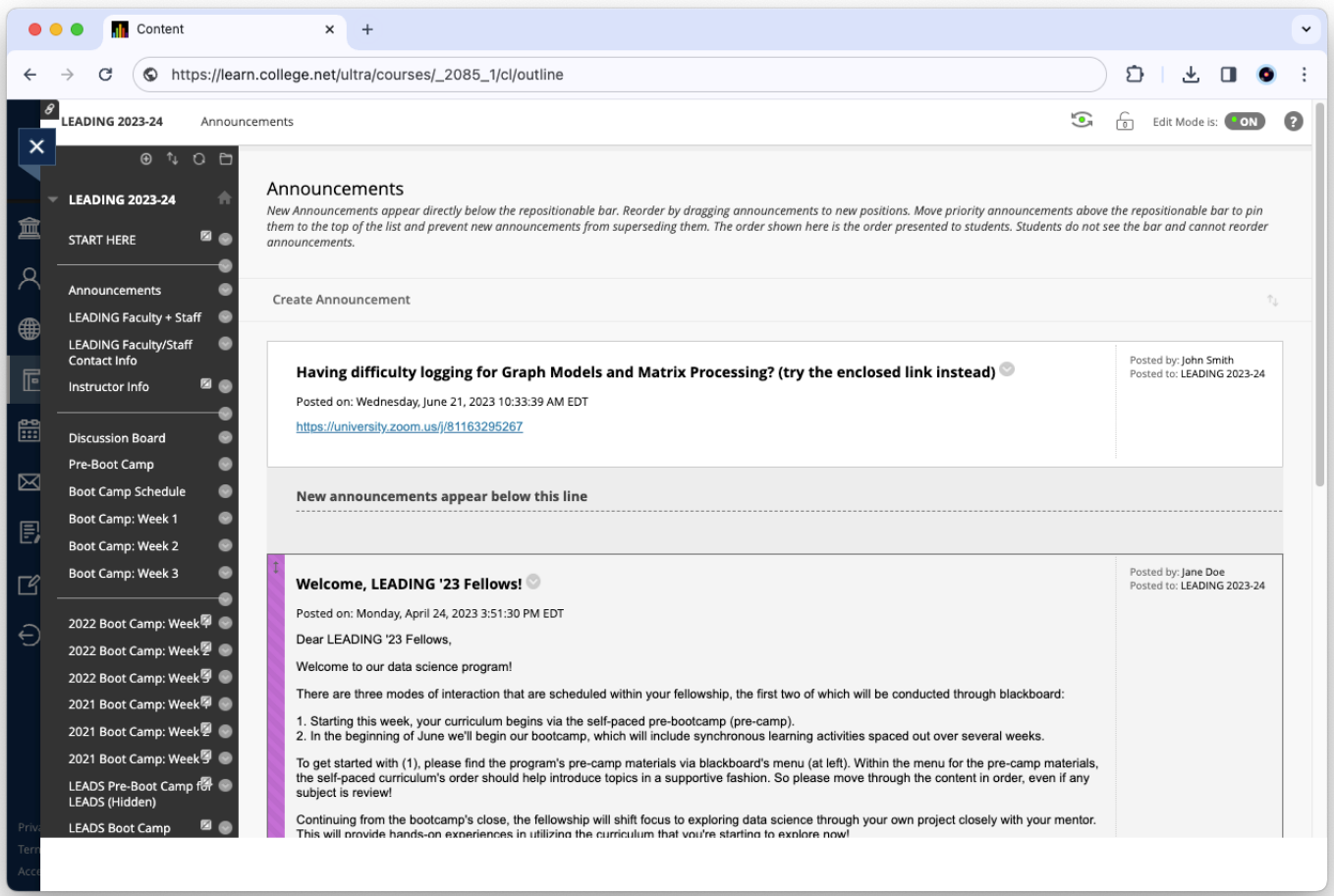
Figure 1. The Bootcamp data was organized in Blackboard by-day in the leftmost navigation. Within each day, the respective instructors posted their contents for the fellows. The contents of this image have been masked to remove identifying information.
Methodology
While we had direct, practical familiarity with the contents of the bootcamp Blackboard instance, we needed to liberate the contents from the authentically-protected system in a manner that maintained the file and course structure as well as the metadata to organize iteration of the bootcamp. This required a process of data extraction, inventory, and auditing for assurance of the process, which we describe in this section. We began this process in the Fall of 2023 and the effort is currently underway (see below timeline).
- November 2020-April 2021 Boot camp materials developed by instructors
- May 2021-August 2021 Boot camp
- June 2021 Boot camp (2021)
- July 2021-December 2021 Fellows’ internship at one of 21 different sites
- June 2022 Boot camp (2022)
- July 2022-December 2022 Fellows’ internship at one of 19 different sites
- June 2023 Boot camp (2023)
- July 2023-December 2023 Fellows’ internship at one of 13 different sites
- September 2023-December 2023 Boot camp dump and analysis begin
- January-February 2024 Preliminary Audit performed
- February-March 2024 Extraction and validation procedure performed and documented
Data Extraction and Inventory
We exported course data using the functionality built into Blackboard and took inventory of the contents of the export using the DROID file format identification tool from the UK National Archives [20]. We then parsed the CSV output of the scan using an R script to generate a count of files by type, with the intent of getting an overview of the number of scripts, notebooks, PDFs, and binary types. The export included files in PowerPoint and Word formats, as well as operating system specific but otherwise contextually unnecessary files like *_MACOS* directories. Given the large number of files in the export, the DROID report also served to confirm assumptions about the structure of the data: one top-level directory containing structural XML files and a small number of subdirectories, primarily used for Blackboard configuration. Among these was a single dedicated subdirectory serving as the content store, which contained all of the embedded course materials.
Since all files within the course export are named according to a schema that is internal to a single Blackboard course instance, with site-specific identifiers replacing human-readable file names, our next step was to mine the XML for filenames. Within the content store directory, each content file was represented by two files: the content in its original format and an XML file that included system information including the original file name. The shared identifier between the two files was the system-generated filename. We developed a Python script to read the XML files and output a lookup table with two columns, the system filename, and the corresponding original filename.
Traversing the Course Structure
The initial process produced a list of content files using their original filenames. However, conducting a thorough audit required matching these files with the corresponding lesson descriptions within each module. One potential method was to set up a sandboxed Blackboard instance, import the exported data, and compare it with the live version of the course while it remained accessible online.
Instead, a scripted solution was developed. This script parsed the XML files to generate a weekly overview of course content, aligning the schedule with specific XML data to map course materials to each week. To streamline this process, lookup tables were also used rather than relying solely on the raw XML files.
The institution running the Blackboard system uses Kaltura as a long-term video hosting solution, rather than relying on Zoom for video storage. While Zoom recordings are deleted after 18 weeks [21], an automated process transfers videos created through the institution’s Zoom account into Kaltura. These videos can then be embedded within Blackboard without being physically copied. Instructors reference the videos via Blackboard, but the actual files remain hosted on Kaltura.
Kaltura Caveat
In December 2023, the grant-funded institution hosting the Blackboard instance notified all instructors that the prior embedded instances of Kaltura videos would no longer function and need to be reset in Blackboard. Given all instances of the bootcamp had since completed, this meant that a manual process of adapting the embeds might need to be performed to allow the videos to be accessible and playable. We mitigate this effort by extracting the URLs of the videos in the import rather than relying on the embed markup itself to allow the video to be usable in its original form, i.e., within the Blackboard interface.
Discussion and Future Work
As the process of data extraction and migration progresses, it is essential to critically consider the broader implications associated with the dissemination of the resulting materials. Chief among these concerns is the issue of instructional authorization: the participation of instructors in the boot camp events does not inherently imply consent for public distribution of their contributions. Accordingly, explicit permission from each instructor must be obtained prior to dissemination.
Furthermore, a comprehensive review and analysis of the extracted content is required to ensure that copyrighted materials, whether included inadvertently or permitted within the credential-protected Blackboard environment, are not redistributed without proper authorization. For materials that are publicly available but still under copyright, our dissemination strategy includes verifying their presence in the Internet Archive’s repository and providing external links rather than hosting the content directly.
For resources for which reuse permissions have been granted, particularly interactive elements such as Jupyter notebooks, we intend to integrate and adapt these materials into existing Library Carpentry workshop formats. This will support their continued use and extension by broader audiences, contingent upon the prior acquisition of all necessary permissions from the original content creators.
Audit Redux
At the time of this writing, we have performed a preliminary audit of boot camp materials that includes instructional videos recordings of the instructors’ lectures, PowerPoint/PDF presentation files, and Python-based notebooks. While some of the notebooks are Jupyter-based and stored in the Blackboard shell itself, some instructors opted for notebooks on other platforms like Google Colab. While the offerings of these two mechanisms for executing Python scripts using notebooks is similar, there is no guarantee that one notebook will be portable to other systems due to the availability of modules and resources on each respective platform. We plan to evaluate both the notebooks and their linked versions (e.g., in Colab), and manually verify that the execution results match expectations.
Presentation Medium
Dissemination of the bootcamp material need not maintain the original web-based representation, that is, organized by structure and style of the Blackboard template. We are looking into effective means of organizing the content, both from the context of the multiple iterations of the boot camp to make the content available but also to facilitate accessibility. Our intention is for the content to be widely available and permissively licensed for reuse. We are considering using platforms like GitHub Pages to accomplish this with external linking to captures at Internet Archive for copyrighted, publicly accessible, web-based materials.
Evaluation of Our Approach cf. Web Archiving / Auto-crawling Tools
Our initial attempts at data liberation have been somewhat ad hoc, relying primarily on the built-in capabilities of the system. As we have seen with other web-based platforms, data exports (“dumps”) are often incomplete. While we continue to assess how comprehensive and representative the Blackboard data dump is in capturing the full content of the boot camps, we are also exploring practitioner-oriented web archiving tools and methods to extract data in a more portable and consistent manner. We plan to use the archiving tools in the near future to implement a more systematic approach and to benchmark their performance against our current baseline. These tools will be especially valuable for capturing hard-to-preserve resources and will also support the portability of the data in its original structure, such as the Blackboard course template.
Conclusion
This study aims to liberate educational content for reuse with Blackboard data from the Summers of 2021, 2022, and 2023. Making the liberated data into reusable content required multiple steps including obtaining permission for copyright, organizing the data dumps for consistency, and assuring the quality of contents. However, if the demonstrated methods could employ a more systematic process, it would bring tremendous potential to educational workers by sharing and reusing the quality of educational contents without concerns about license.
Acknowledgements
For support of the 3-year grant that made both the fellowships and boot camps possible, we would like to recognize support by the Institute of Museum and Library Services (IMLS), grant #RE-246450-OLS-20. We would also like to thank the instructors at Drexel University for their cooperation and willingness to make their valuable instructional data widely available.
References
[1] National Institutes of Health. (2023). Data Management & Sharing Policy Overview | Data Sharing. https://sharing.nih.gov/data-management-and-sharing-policy/about-data-management-and-sharing-policies/data-management-and-sharing-policy-overview#after
[2] National Science Foundation. (2023). Preparing Your Data Management Plan – Funding at NSF https://new.nsf.gov/funding/data-management-plan#nsfs-data-sharing-policy-1c8
[3] Piwowar, H. A., & Vision, T. J. (2013). Data reuse and the open data citation advantage. PeerJ, 1, e175. doi:10.7717/peerj.175
[4] Borgman, C. L. (2012). The conundrum of sharing research data. Journal of the American Society for Information Science and Technology, 63(6), 1059-1078. doi:10.1002/asi.22634
[5] Wicherts, J. M., Borsboom, D., Kats, J., & Molenaar, D. (2006). The poor availability of psychological research data for reanalysis. American psychologist, 61(7), 726. doi:10.1037/0003-066X.61.7.726
[6] El Emam, K., Rodgers, S., & Malin, B. (2015). Anonymising and sharing individual patient data. bmj, 350. doi:10.1136/bmj.h1139
[7] Oliveira, P. C. D., Cunha, C. J. C. D. A., & Nakayama, M. K. (2016). Learning Management Systems (LMS) and e-learning management: an integrative review and research agenda. JISTEM-Journal of Information Systems and Technology Management, 13, 157-180. doi:10.4301/S1807-17752016000200001
[8] Camilleri, M. A., & Camilleri, A. C. (2022). The acceptance of learning management systems and video conferencing technologies: Lessons learned from COVID-19. Technology, Knowledge and Learning, 27(4), 1311-1333. doi:10.1007/s10758-021-09561-y
[9] Hilton III, J., Wiley, D., Stein, J., & Johnson, A. (2010). The four ‘R’s of openness and ALMS analysis: frameworks for open educational resources. Open learning: The journal of open, distance and e-learning, 25(1), 37-44. doi:10.1080/02680510903482132
[10] Poole, A. H. (2021). LEADING the way: A new model for data science education. Proceedings of the Association for Information Science and Technology, 58(1), 525-531. doi:10.1002/pra2.491
[11] Vitaglione, G., Bousdira, N., Goldfarb, S., Neal, H. A., Severance, C., & Storr, M. (2001). Lecture Object: an architecture for archiving lectures on the Web. International Journal of Modern Physics C, 12(04), 533-547. doi:10.1142/S012918310100219X
[12] Bousdira, N., Storr, K. M., Myers, E., Goldfarb, S., Neal, H. A., Severance, C., & Vitaglione, G. (2001). WLAP the web lecture archive project: The development of a web-based archive of lectures, tutorials, meetings and events at CERN and at the University of Michigan (No. CERN-OPEN-2001-066). https://cds.cern.ch/record/516632
[13] Herr, J., Lougheed, R., & Neal, H. A. (2010, April). Lecture archiving on a larger scale at the University of Michigan and CERN. In Journal of Physics: Conference Series (Vol. 219, No. 8, p. 082003). IOP Publishing. doi:10.1088/1742-6596/219/8/082003
[14] Chu, L. F., Young, C. A., Ngai, L. K., Cun, T., Pearl, R. G., & Macario, A. (2010). Learning management systems and lecture capture in the medical academic environment. International Anesthesiology Clinics, 48(3), 27-51. doi:10.1097/AIA.0b013e3181e5c1d5
[15] Jamieson J., Verhaart M. Issues Surrounding Course Content Migration: Blackboard to Moodle. In: Proceedings of the 18th annual conference of the national advisory committee on computing qualifications (NACCQ), Tauranga, New Zealand, 2005. Available at: https://citrenz.org.nz/citrenz/conferences/2005/concise/jamieson_moodle.pdf
[16] Santoso, B. J., Ijtihadie, R. M., & Millah, Z. (2023, September). A Docker Container-Based Solution for Course Archival on Moodle: Implementation and Evaluation. In 2023 8th International Conference on Electrical, Electronics and Information Engineering (ICEEIE) (pp. 1-6). IEEE. doi:10.1109/ICEEIE59078.2023.10334688
[17] Kelly, M. and Weigle, M. C., “WARCreate – Create Wayback-Consumable WARC Files from Any Webpage,” In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries (JCDL). 2012, pp. 437–438. doi:10.1145/2232817.2232930
[18] Kelly, M., Nelson, M.L., and Weigle, M.C, “A Framework for Aggregating Private and Public Web Archives,” In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries (JCDL), 2018, pp. 273–282. doi:10.1145/3197026.3197045
[19] Webrecorder: web archiving for all. (n.d.). Webrecorder. Retrieved April 1, 2024, https://webrecorder.net/
[20] DROID: file format identification tool (n.d.), Retrieved April 4, 2024, https://www.nationalarchives.gov.uk/information-management/manage-information/preserving-digital-records/droid/
[21] Drexel University Information Technology, (n.d.), Frequently Asked Questions for Drexel Zoom Users, https://drexel.edu/it/help/a-z/zoom/zoomfaq/ Accessed: April 7, 2024
About the authors
Hyung Wook Choi is a PhD candidate at Drexel University’s College of Computing and Informatics. She holds Master degrees in Data Science and Library and Information Science from Drexel and Ewha Womans University. Her primary research is centered on detecting and tracking semantic shifts with NLP and Information Retrieval.
Jon Wheeler is a Data Curation Librarian within the University of New Mexico’s College of University Libraries and Learning Sciences. Jon’s role in the Libraries’ Data Services initiatives include the development of research data ingest, packaging and archiving work flows. Jon’s research interests include the requirements and usability of sustainable architectures for long term data preservation and the disposition of research data in response to funding requirements.
Weimao Ke is an Associate Professor in Information Science at Drexel University. His research is centered on information retrieval (IR), with emphasis on computational models that support effective and intelligent human-information interaction. His work explores the application of machine learning, multi-agent systems, and information-theoretic frameworks to the modeling and analysis of complex information environments. He is also interested in simulation-based approaches for studying emergent behavior and dynamics in distributed systems, as well as the design of scalable and adaptive AI systems in information networks.
Lei Wang is an Assistant Teaching Professor at Drexel University’s College of Computing and Informatics. Her work focuses on clinical data analysis, natural language processing with large language models, and biomedical optical imaging. At Drexel, she teaches graduate-level courses in data science and leads research initiatives at the intersection of healthcare and AI. Her research interests include pediatric concussion, neuroimaging, and the application of machine learning in clinical informatics. She actively contributes to academic publishing and peer review in neuroscience and biomedical engineering.
Jane Greenberg is the Alice B. Kroeger Professor and Director of the Metadata Research Center at the College of Computing & Informatics, Drexel University. Her research activities focus on metadata, knowledge organization/semantics, linked data, data science, and information economics. Her research has been funded by the NSF, NIH, IMLS, NEH, Microsoft Research, GlaxoSmithKline, Santander Bank, Library of Congress, as well as other agencies and organizations.
Mat Kelly is an Assistant Professor in the Department of Information Science at Drexel University’s College of Computing & Informatics. He earned his Ph.D. in Computer Science from Old Dominion University. Dr. Kelly’s research centers on digital preservation, with a particular emphasis on the archiving and retrieval of private web content. His work has been supported by the Institute of Museum and Library Services and the National Science Foundation.

Subscribe to comments: For this article | For all articles
Leave a Reply