By Eric C. Weig
Background
Since 2015, The University of Kentucky Libraries have uploaded historic newspaper issues to the Internet Archive. We are now changing our newspaper program to host newspapers locally, and expanding the collection scope to include not only issues scanned from analog sources but also born digital and web harvested HTML (HyperText Markup Language) newspaper content.
Gathering local copies of content we placed in the Internet Archive would have been cumbersome as it would have involved accessing long term tape based archival storage systems, which meant time and effort from multiple staff. Alternatively, an automated process might be utilized to pull files back down from the Internet Archive and AI could play a role to make needed development faster. I had some experience with Python and anticipated that AI would be more successful crafting small, narrowly focused scripts than more complex code. [1]. Curiosity played a role here as well. With so much interest growing around the use of AI, giving it a try on a small and well-defined coding project sounded like fun, with the option of abandoning it if results were not successful.
Initial research also uncovered that the Internet Archive encourages web crawling via its robots.txt file and offers access to an API to gather metadata and files. [7] [4]
Gathering Metadata for Objects
The first step in the process involved assembling all the metadata needed to gather the Internet Archive objects from the Kentucky Digital Newspaper collection (see Figure 1).
Figure 1. Collection landing page for Kentucky Digital Newspapers on the Internet Archive. Shows results for 86,819 items.
At a minimal level, this requires the Internet Archive specific identifiers that were assigned to the objects. When looking at a URL for an object, the identifier is located at the very end of the URL, following the last forward slash. For example, the following object URL https://archive.org/details/xt74qr4nm47j has an object identifier that is ‘xt74gr4nm47j’. In the Internet Archive, various URLs relate to an object and follow specific patterns that reference the identifier value. For example, to download a .zip file containing all of the files associated with the object, including what was originally uploaded, the following URL pattern is used [5]: https://archive.org/compress/xt74qr4nm47j.
Additional metadata was desirable to facilitate renaming and sorting the objects once they were downloaded as well as to calculate the total storage requirements for files prior to downloading. Specifically, four fields were retrieved: creator, identifier, date, and item_size. The ‘creator’ metadata values were useful in sorting downloaded content into directories organized by newspaper title. The ‘identifier’ metadata was used to construct the download URLs, and ‘date’ metadata was prepended to the downloaded .zip file names in order to add semantic information. The ‘item_size’ metadata was used to calculate how much local storage space we needed.
Another aspect of getting the metadata involved ensuring it was in a parsable format. Fortunately, the Internet Archive has several options for gathering metadata formatted as structured data. For collections with fewer than ten thousand items, a URL using /scrape/ will retrieve data (see Figure 2). [4]
https://archive.org/services/search/v1/scrape?fields=identifier,item_size,creator,date&q=collection%3Akentuckynewspapers
Figure 2. Sample Scrape API URL that gathers the first 10,000 metadata records the kentuckynewspapers collection.
Since our collection included far more than 10,000 items, this would not work for us. Instead, I used the advanced search web interface to search for what I needed, as the advanced search results page also provides the option to export results as structured data (see Figure 3). [6]
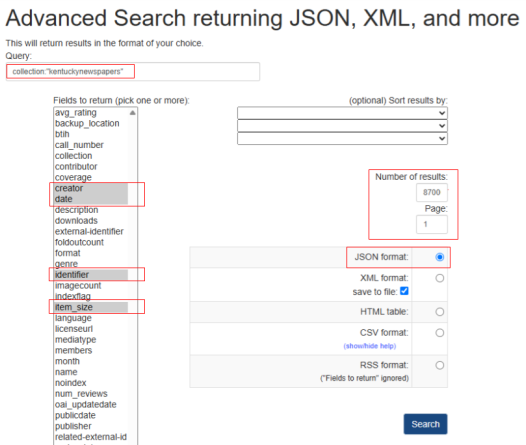
Figure 3. Internet Archive Web Interface Advanced Search GUI with field inputs used for generating the JSON formatted metadata output for all 86,819 items.
I chose to use JSON as the output format (see Figure 4).
callback({“responseHeader”:{“status”:0,”QTime”:469,”params”:{“query”:”collection:kentuckynewspapers”,”qin”:”collection:”kentuckynewspapers””,”fields”:”creator,date,identifier,item_size”,”wt”:”json”,”sort”:”creatorSorter asc”,”rows”:1000,”json.wrf”:”callback”,”start”:0}},”response”:{“numFound”:86819,”start”:0,”docs”:[{“creator”:”Adair County news.(The)”,”date”:”1917-11-14T00:00:00Z”,”identifier”:”xt744j09xt7p”,”item_size”:13630085},{“creator”:”Adair county community voice”,”date”:”2012-10-18T00:00:00Z”,”identifier”:”kd99882j6j5s”,”item_size”:91957159},{“creator”:”Adair county community voice”,”date”:”2012-09-20T00:00:00Z”,”identifier”:”kd9tm71v5w8w”,”item_size”:93942368},{“creator”:”Adair county community voice”,”date”:”2012-10-04T00:00:00Z”,”identifier”:”kd9dz02z1d9w”,”item_size”:92310777},{“creator”:”Adair county community voice”,”date”:”2012-09-27T00:00:00Z”,”identifier”:”kd9jq0sq9446″,”item_size”:95768429},{“creator”:”Adair county community voice”,”date”:”2012-09-20T00:00:00Z”,”identifier”:”kd9pg1hh6t91″,”item_size”:93942985},{“creator”:”Adair county community voice”,”date”:”2012-09-13T00:00:00Z”,”identifier”:”kd9610vq304m”,”item_size”:95027685},{“creator”:”Adair progress (The)”,”date”:”2015-06-11T00:00:00Z”,”identifier”:”kd91n7xk8900″,”item_size”:118977672},{“creator”:”Adair progress (The)”,”date”:”2012-08-16T00:00:00Z”,”identifier”:”kd90z70v8f74″,”item_size”:83747017},{“creator”:”Adair progress (The)”,”date”:”2014-02-06T00:00:00Z”,”identifier”:”kd9x34mk6r4d”,”item_size”:89747837},{“creator”:”Adair progress (The)”,”date”:”2012-07-26T00:00:00Z”,”identifier”:”kd9d79571k58″,”item_size”:107745767},[/text]
Figure 4. Sample JSON output generated from the Internet Archive Web Interface Advanced Search. Fields gathered included identifier, date, creator, and item_size.
Calculating Storage Needs
A calculation of storage requirements was essential for planning so that an automated process could run without encountering insufficient storage space.
Calculating the storage space needed was relatively simple as all the information needed was represented in the JSON output, in the item_size metadata element..
As I approached the use of AI for small script code generation, articles on effective prompt engineering were helpful. I chose to use the free ChatGPT (GPT-4o mini) for its ease of use and established accuracy with Python coding: A 2024 study published on Python code generation and AI found that “of all the models tested, GPT-4 exhibited the highest proficiency in code generation tasks, achieving a success rate of 86.23% on the small subset that was tested. GPT-based models performed the best compared to the other two models, Bard and Claude.” [2] My approach was to start very simple with prompts initially aimed at producing code to perform simple processing tasks, then branching out to create more sophisticated prompts that incorporated multiple processes. I also spent time experimenting with prompts and then reviewing the resulting code, using few-shot learning by providing example elements within the prompt while sometimes performing multiple iterations with different phrasing and level of granularity as well as striving to cover all necessary details with as few words as possible. See Figure 5 for the completed prompt used to generate code. [9] [3]
Write a Python script that runs from the commandline and processes a .json file at a full path specified in the code. The JSON file contains data wrapped in a JavaScript-style callback function, like callback({…}). The script should extract the JSON content, parse it, and sum the values of the item_size field found in the list located at response.docs. The script should print and write to a log file listing the total size in bytes, KB, MB, GB, and TB. The log file path should be specified in the code. Include error handling for if the file is malformed and print a message indicating when the process is completed successfully.
Figure 5. Figure 5. show the ChatGPT (Chat Generative Pre-trained Transformer) prompt that generated storage.py.[14] The italicized text indicates prompt content added after the initial prompt was conducted. The second prompt was then submitted in its entirety.
One quick fix I needed to make in the resulting code was to make sure that the file paths were set as raw strings in order to ignore escape character sequences. [10] I made this change directly to the code after it was generated.

Figure 6. Command-line output of the storage.py script. Shows calculated storage size in bytes, KB, MB, GB and TB.
Downloading Objects
Now that I had all the URLs to download the objects, I began considering a responsible approach to retrieving the data. I intended to heed the guidelines established in the Internet Archive’s robots.txt file. [2] Incorporating a 10 to 30 second pause between each download seemed reasonable. [11]
Initial Prompt:
Write a Python script that loads a JSON file located at a path specified in the code. The JSON file contains data wrapped in a JavaScript-style callback function, like callback({…}). The script should extract the JSON content, parse it, and read the values of identifier, creator, and date. for each identifier construct a download URL in the format https://archive.org/compress/{identifier}. Create a subdirectory under a base path specified in the code and named after the creator with characters that are invalid or problematic replaced with underscores and leading/trailing whitespace stripped. Download the ZIP file corresponding to the identifier and save it as {date}_{identifier}.zip in the appropriate subdirectory. Wait for a random interval between 10 and 30 seconds before proceeding to the next download. If a download fails, log the failed URL to a log file specified in the code.
Refining Prompt:
Add code that groups the downloads into sets of 1000 and creates subdirectories in the downloads directory that are named 0001, 0002, etc.
Refining Prompt:
Add Python code so that after each .zip file is downloaded, it is verified using zipfile.is_zipfile() to ensure it is a valid ZIP archive. If is_zipfile() returns False, an error message should be recorded in a log file (e.g., download.log) indicating that the file is not a valid ZIP. If the file passes this check, it should then be opened with zipfile.ZipFile() and tested using the testzip() method. If testzip() returns a file name, indicating a corrupted file inside the archive, this should also be logged with an appropriate warning or error message
Figure 7. ChatGPT prompt and refining prompts that generated download_zips.py.
Lessons learned from earlier prompts led me to including the example callback function—formatted like callback({…})— as a few-shot prompt so the script would parse the JSON effectively. Post code generation, I again set file paths as raw strings. Additionally, the prompt specified grouping downloads in manageable sets within sequentially ordered subdirectories and include validation for downloaded .zip files.
Tests were conducted utilizing small sections of the JSON file. One error that occurred during some downloads was that the Python script could not create a valid directory name. Values in the creator metadata contained characters not valid for directory naming. A quick manual adjustment to the Python code to sanitize the creator metadata, addressed this issue.
ORIGINAL CODE: # Subdirectory under group: creator name save_dir = os.path.join(group_dir, creator) UPDATED CODE: # Sanitize creator sanitized_creator = re.sub(r’[^A-Za-z0-9]’,’_’, creator) # Subdirectory under group: creator name save_dir = os.path.join(group_dir, sanitized_creator
Figure 8. Manual fix to AI generated code to sanitize text for use in naming Windows file system directories.
Additional tests with more small subsections of the JSON file were successful and the script was then run in earnest (see Figure 9).
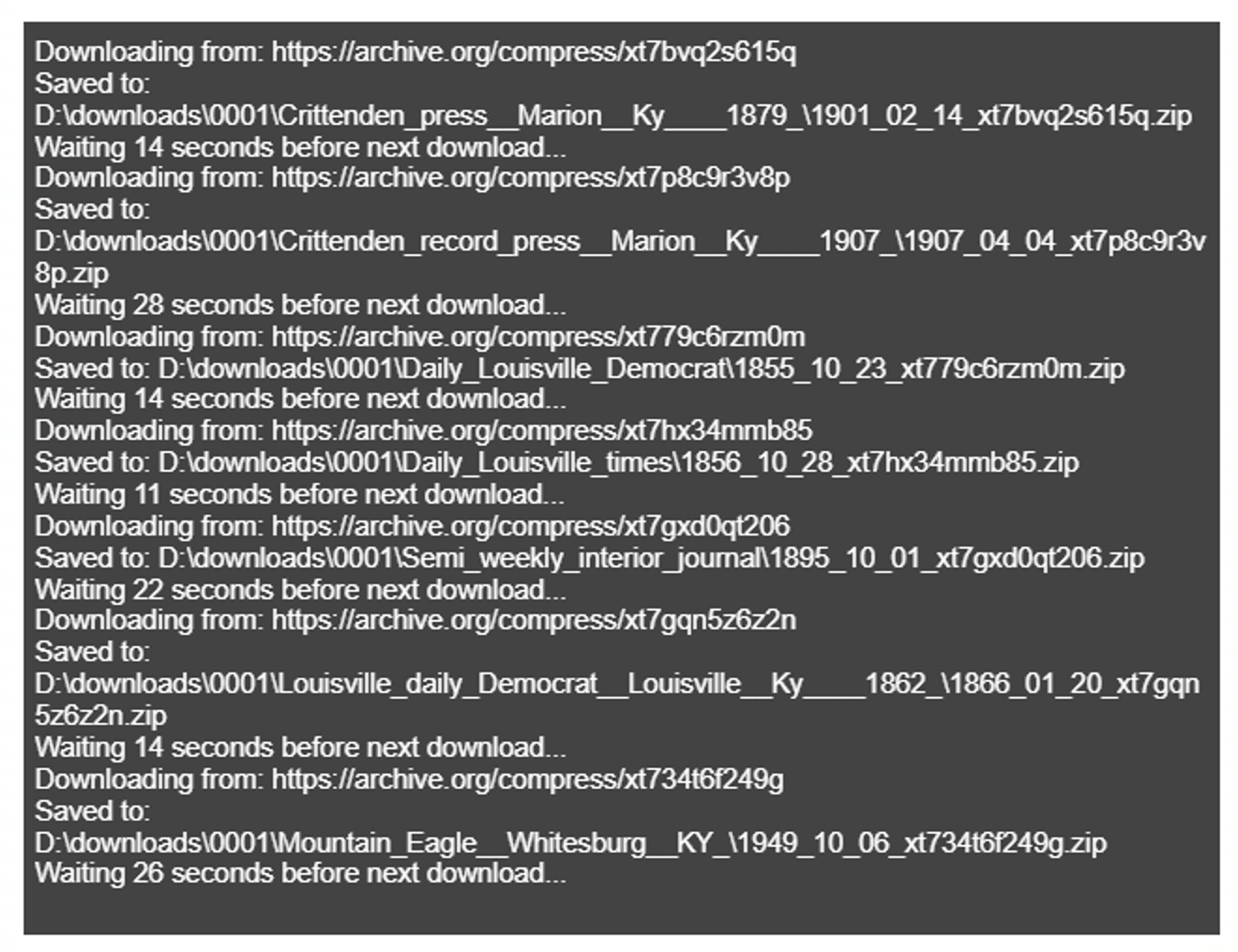
Figure 9. Command-line output from the download_zips.py script.
Results
The download_zips.py script ran intermittently for nearly two months. There were three interruptions due to local machine reboots for Windows updates. There were 6,489 failed downloads due to temporary network connection issues and what appeared to be corrupt files.
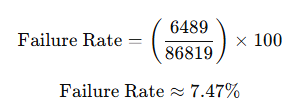
Figure 10. Calculation of failure rate for downloads.
Downloaded files are being reviewed one title at a time. Any items missing due to unsuccessful downloads are downloaded a second time. The Internet archive uses a file manifest that includes checksum values for all the files contained within the .zip archive, and this was useful for reviewing files and assessing whether or not they were corrupted.

Figure 11. An XML manifest file is present within each .zip download. This file includes checksum values for each file within the .zip archive.
Conclusion
Downloading our previously uploaded content from the Internet Archive via automation was straightforward and easy to accomplish with some careful planning. The Internet Archive is tailored to allow for harvesting content. URLs can be formulated using the Web interface advanced search options and these URLs gather results formatted as structured data such as JSON and XML. Utilizing AI to generate small Python scripts that were narrow in focus, ChatGPT yielded well-formed Python that accomplished development milestones, allowing for quick testing and only minor problems to fix via debugging or inputting refining prompts.
References
[1] Chang Y, et al. 2024. A survey on evaluation of large language models. ACM Trans Intell Syst Technol. 15(3):1–45. https://doi.org/10.1145/3641289
[2] Coello CEA, et al. 2024. Effectiveness of ChatGPT in coding: a comparative analysis of popular large language models. Digital. 4(1):114–125. https://doi.org/10.3390/digital4010005
[3] Cooper N, et al. 2024. Harnessing large language models for coding, teaching and inclusion to empower research in ecology and evolution. Methods Ecol Evol. 15(10):1757–1763. https://doi.org/10.1111/2041-210X.14325
[4] Internet Archive. Archive.org about search [Internet]. [accessed 2025 May 6]. https://archive.org/help/aboutsearch.htm
[5] Internet Archive. Downloading – a basic guide – Internet Archive Help Center [Internet]. [accessed 2025 May 6]. https://help.archive.org/help/downloading-a-basic-guide/
[6] Internet Archive. Search – a basic guide – Internet Archive Help Center [Internet]. [accessed 2025 May 6]. https://help.archive.org/help/search-a-basic-guide/
[7] Internet Archive. robots.txt [Internet]. [accessed 2025 May 6]. https://archive.org/robots.txt
[8] Internet Archive. Internet Archive: digital library of free & borrowable texts, movies, music & Wayback Machine [Internet]. [accessed 2025 May 6]. https://archive.org/about/
[9] Knoth N, et al. 2024. AI literacy and its implications for prompt engineering strategies. Comput Educ Artif Intell. 6:100225. https://doi.org/10.1016/j.caeai.2024.100225
[10] Real Python. What are Python raw strings? – Real Python [Internet]. [accessed 2025 May 6]. https://realpython.com/python-raw-strings/
[11] Infatica. 2021. Responsible web scraping: an ethical way of data collection [Internet]. [accessed 2025 May 6]. https://infatica.io/blog/responsible-web-scraping/
Notes
[14] Code referenced in this article is available at:
https://github.com/libmanuk/IADownload/
About the Author
Eric C. Weig (eweig@uky.edu) has been an academic librarian at the University of Kentucky Libraries since 1998. His current title is Web Development Librarian. Eric manages the University of Kentucky Libraries Drupal based website and intranet. He also assists with design and management of digital libraries for the University of Kentucky Special Collections Research Center.

Subscribe to comments: For this article | For all articles
Leave a Reply