by Andrew H. Bullen
The Pullman House History Project
The Pullman House History Project, a part of the Pullman State Historic Site’s virtual museum and web site (http://www.pullman-museum.org/) and henceforth referred to as the PHHP, links together census, city directory, and telephone directory information to describe the people who lived in the town of Pullman, Illinois between 1881 and 1940. This demographic data is linked through a database/XML record system to online maps and Perl programs that allow the data to be represented in various useful combinations.
Demographic data collection is particularly important for research into the Pullman factory and community because both were a major destination for immigrants throughout the 110 years of the company’s existence, allowing scholars to study 19th and 20th century migration and ethnographic trends. It has also revealed hidden facets of the Pullman story, allowing us to discover, for instance, the existence of a local militia extant between 1882 and 1890.
 A Pullman Family, mid 1890s
A Pullman Family, mid 1890sThe History of the Town of Pullman
In the mid-1870s, George Mortimer Pullman decided to expand his very successful rail passenger car service, as he had outgrown his Detroit shops and needed to dramatically expand his production facilities if he wanted to capitalize on the explosive demand for railroad car sales and service. He chose Chicago as a location for his new factory complex. Pullman had a fondness for Chicago as he had made an earlier fortune there in 1858. He also respected the wide open, entrepreneurial, winner-take-all aspect of the city. Pullman began acquiring land on the far south side of Chicago in 1880, setting up in secret the Pullman Land Association which was based in Massachusetts to avoid land speculation. Pullman purchased 3,600 acres of prime industrial property, located between the Rock Island railroad and Illinois Central railroad lines and near the natural harbor of Lake Calumet. He commissioned a young architect named Solon Beman, 26, to design his factory complex and surrounding town.
The Pullman area was much more than a rail car manufacturing facility. George Pullman wanted to create what he envisioned as a workers’ paradise, charging Beman to design and build what was eventually to become 32 blocks of row houses laid out in neat neighborhoods directly north and south of the factory complex. Almost unique in their day, each row house was equipped with running water, an indoor toilet, a spacious back yard, and lots of natural light and ventilation. The Pullman Company provided power, fixed the houses as needed, picked up garbage, and maintained the carefully designed landscaping. Pullman also provided shop spaces in a Market Hall and an indoor shopping Arcade; private entrepreneurs could rent from the Company and set up grocery stores, department stores, etc. in these spaces. George Pullman accepted numerous accolades for his “most perfect town” and made it a Chicago show piece during the 1892-1893 Columbian Exposition.
 Houses on Cottage Grove under construction, 1881
Houses on Cottage Grove under construction, 1881As a response to cancelled orders and business downturns during the 1894 economic panic, Pullman laid off many workers and slashed the wages of his remaining employees. He did not, however, similarly slash rents, waive fees, or in any way attempt to mitigate the dire economic circumstances faced by his employees. The effect of this disastrous decision was the greatest of the 19th century labor struggles, the Pullman strike of 1894. The strike, spread nationwide by Eugene Debs and his attempt to organize all railroad workers into one all-encompassing union, lasted throughout the summer. It was eventually broken with help from federal troops dispatched by President Grover Cleveland which were sent in to ensure that the mail trains would be kept running. Pullman viewed the strike as a personal affront and never forgave the striking workers. He died shortly thereafter in 1897.
As a result of a 1907 U.S. Supreme Court decision, the company was forced to sell the town to private owners, and the Great Experiment ended. The city of Chicago annexed the town of Pullman, renumbering the properties and renaming the streets. Today, Pullman still has 98 percent of its original housing stock. It is a thriving Chicago neighborhood, home to an economically, socially, and racially diverse mix of people who deeply love the community. It has been my honor and privilege to attempt to represent the rich history of this fascinating community.
Challenges in Representing Pullman History
As of this writing, we have identified three main sources of primary historical material that describe the town of Pullman: contemporary newspaper articles, images, and census and other demographic data. Melding together these disparate data sources into a useful research tool has proven to be challenging. My first step was to cast about for a common thread that could tie these sources together and discovered that they could all be categorized in one or more of three different ways: as people, places, or events. This core assumption provided the main design philosophy for the whole project, and guides the path of future developments.
I prefer to program in Perl (for no other reason than that is what I am most familiar with) and I am very comfortable working with databases. My approach to developing an online Pullman history research tool was, therefore, to use a MySQL database to hold the data, using the paradigm of “people/places/events” as the core design guideline, and Perl to access the data tables and dynamically build web pages from the results set. Information that is unique to a particular data set is housed in external (to the database) XML files, referred to by MySQL records and displayed dynamically using Perl programs.
Three classes or groups of tables for the Pullman database have emerged: images, demographic data, and newspaper clippings. This article will describe in detail the three demographic data tables, which together form the core of the Pullman House History Project, and describe how they relate to the image and (coming in the future) newspaper clippings tables.
Part I: Representing the People of the Town
In order to best represent Pullman demographic data in the PHHP, I created a database-based/XML record system containing the data from the 1883 and 1889 city directories, a 1916 telephone directory, and the small portion of the 1900 U.S. census that we have entered. Eventually, the 1900 census will be completed, as well as adding in data from the 1910, 1920, 1930 and 1940 censuses. The 1890 census was, of course, lost in a fire in New York City; the data in the 1883 and 1889 city directories has proven to be an adequate substitute, allowing us to at least see who lived in which house and what they did for a living.
A database/XML record system is an ideal way to maintain disparate and unique data sources and yet still be able to manipulate them in a useful manner. For instance, demographic data in the PHHP database consists of records from censuses, city directories and telephone directories, each of which has unique data representation requirements. In addition, each decennial census asked questions unique to that census. Gathering together such a seemingly unruly and disparate herd of data at first glance seemed to me to be an impossible chore. Upon reflection, I realized that all of these data sources share a few common elements such as names and addresses. A simple MySQL table, shown below, became the structure that ties together the common elements. XML files, pointed to from within the individual records, can be used to contain the unique data elements of the different data sources.
The main table itself is laid out in the following manner:
mysql> describe census; +------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+------------------+------+-----+---------+----------------+ | address | varchar(100) | YES | | NULL | | | aptNumber | varchar(50) | YES | | NULL | | | street | varchar(50) | YES | | NULL | | | lastName | varchar(100) | YES | | NULL | | | firstName | varchar(50) | YES | | NULL | | | occupation | varchar(255) | YES | | NULL | | | ownOrBoard | char(1) | YES | | NULL | | | source | varchar(50) | YES | | NULL | | | uid | int(10) unsigned | | PRI | NULL | auto_increment | +------------+------------------+------+-----+---------+----------------+
This MySQL database also consists of several image metadata management tables. Like the census table shown above they contain brief records that point to more extensive and descriptive corresponding XML files describing scanned images of Pullman. Our scanned images and their metadata may be viewed at http://www.pullman-museum.org/cgi-bin/pvm/objectsViewRecords.pl?letter=A. Description of these tables is, alas, a subject for another article.
Most of the fields are self-explanatory. The ownOrBoard field lets me distinguish between renters and sub-letters. The source field describes the source of the data. uid, present as a unique key in all tables, is the unique identifier for the record, which may also be used to point to any corresponding XML record(s). When a record is retrieved, its uid is then used to return the corresponding XML record from a file held on the server as 1900census.uid.xml.
As I mentioned, the data set from the 1900 census (and subsequent censuses) is much more complex, and must also be represented by a corresponding XML record. The DTD for the census information is:
<!ELEMENT houseDocumentation (houseDescription, physicalDescription)> <!ELEMENT census1900 (houseInformation, personalInformation, ancestry, immigrationStatus, educationAndOccupation, housingStatus, censusInformation)> <!ELEMENT houseInformation EMPTY> <!ATTLIST houseInformation recordID CDATA #REQUIRED address CDATA #REQUIRED aptNumber CDATA #IMPLIED street CDATA #REQUIRED dwellingNumber CDATA #REQUIRED> <!ELEMENT personalInformation EMPTY> <!ATTLIST personalInformation familiesNumber CDATA #IMPLIED lastName CDATA #REQUIRED firstName CDATA #REQUIRED relation CDATA #IMPLIED race CDATA #IMPLIED sex CDATA #IMPLIED dobMonth CDATA #IMPLIED dobYear CDATA #IMPLIED age CDATA #IMPLIED maritalStatus CDATA #IMPLIED yearsMarried CDATA #IMPLIED motherOf CDATA #IMPLIED childrenLiving CDATA #IMPLIED> <!ELEMENT ancestry EMPTY> <!ATTLIST ancestry placeOfBirth CDATA #IMPLIED placeOfBirthFather CDATA #IMPLIED placeOfBirthMother CDATA #IMPLIED> <!ELEMENT immigrationStatus EMPTY> <!ATTLIST immigrationStatus immigrated CDATA #IMPLIED yearsInUS CDATA #IMPLIED naturalized CDATA #IMPLIED> <!ELEMENT educationAndOccupation EMPTY> <!ATTLIST educationAndOccupation occupation CDATA #REQUIRED monthsUnemployed CDATA #IMPLIED monthsAtSchool CDATA #IMPLIED read CDATA #IMPLIED write CDATA #IMPLIED english CDATA #IMPLIED> <!ELEMENT housingStatus EMPTY> <!ATTLIST housingStatus ownOrRent CDATA #IMPLIED ownOrMortgage CDATA #IMPLIED> <!ELEMENT censusInformation EMPTY> <!ATTLIST censusInformation pageNumber CDATA #REQUIRED lineNumber CDATA #REQUIRED reelNumber CDATA #IMPLIED notes CDATA #IMPLIED>
The XML record itself:
<?xml version="1.0" ?> <Census1900> <houseInformation recordID="1405" address="100" aptNumber = "" street="Stephenson" dwellingNumber="69" /> <personalInformation familiesNumber = "124" lastName="Jeffery" firstName="William" relation="Head" race="White" sex="Male" dobMonth="Jan" dobYear="1841" age="59" maritalStatus="Married" yearsMarried="36" motherOf="" childrenLiving="" /> <ancestry placeOfBirth="England" placeOfBirthFather="England" placeOfBirthMother="England" /> <immigrationStatus immigrated="1871" yearsInUS="29" naturalized="Naturalized" /> <educationAndOccupation occupation="Police officer" monthsUnemployed="0" monthsAtSchool="" read="Yes" write="Yes" english="Yes" /> <housingStatus ownOrRent="R" ownOrMortgage="Unknown" /> <censusInformation pageNumber="111B7" lineNumber="72" reelNumber="290" notes="" /> </Census1900>
This approach-using tables to hold brief records of disparate data sources that share a common thread and “offloading” the unique part– has the added advantage of being able to collect any data from any source, as long as it can be tied back to a Pullman address and combine it with other disparate but related data. As long as a record contains the bare minimum of a numerical street number, street name, and data source type, the basic data can reside in the census table. The uid field can then point to an external XML record containing the additional information. For instance, we will eventually need to index newspaper articles that describe events that occurred in specific houses. By creating a census table record that contains the street address in question and by adding the value of article to the source field, I can successfully index the article (at least as it relates to one or more specific addresses) and can retrieve a more detailed external XML file when I retrieve any record which matches the specified address.
The data collected also varies among the different censuses and can also be dealt with in this manner. Each Federal census is slightly different; while all of them record respondents’ names, addresses, etc., each decennial census asks questions unique to it. Representing this data in a database can be a challenge. One could, for instance, create a separate table for each census year (“1900″,”1910”, etc.) and record the data from each decennial census into the appropriate table. Searching across the various tables would involve a fairly complex SQL join operation, resulting in a lot of unnecessary wear and tear on the SQL server. I have chosen, instead, to place the common information that all the censuses share in one table (creatively called census), offloading the unique information in the individual censuses into external XML files.
As I have described, this approach can accommodate a wide variety of disparate data. In addition, it allows the collection to be exposed to OAI harvesters. While I have not yet implemented the software necessary to expose the image and demographic XML records, it is being developed. Such a step will allow other institutions to make use of our data and-frankly-help us in securing grants, since we can quickly point to this facility as an indication of commitment to resource sharing.
Because the town was annexed and renumbered in 1907, I have had to create an “authority” table that translates between the old and new addresses, which leads us to the next demographic data table. The table is laid out as:
mysql> describe addressMaster; +-----------------+-----------------+-------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------------+------------------+------+-----+---------+----------------+ | oldStreetNumber | varchar(50) | YES | | NULL | | | newStreetNumber | varchar(50) | YES | | NULL | | | oldAddress | varchar(50) | YES | | NULL | | | newAddress | varchar(50) | YES | | NULL | | | uid | int(10) unsigned | | PRI | NULL | auto_increment | +-----------------+------------------+------+-----+---------+----------------+
Here is an example record, which indicates that the modern address of 100 Stephenson is 11114 S. Champlain Ave.:
mysql> select * from addressMaster where oldStreetNumber="100" and oldAddress="Stephenson"; +-----------------+-----------------+------------+------------+------|--------+------+ |oldStreetNumber | newStreetNumber | oldAddress | newAddress | uid | +-----------------+-----------------+------------+------------+------|--------+------+ | 100 | 11114 | Stephenson | Champlain | 3046 | +-----------------+-----------------+------------+------------|------|--------+------+
This particular record tells me that the modern address of 11114 S. Champlain Ave. was known before 1907 as 100 Stephenson Ave.
The Perl programs that make up the PHHP use this table to perform, essentially, an authority check on post-1907 addresses. I have decided to declare the pre-1907 address the “official” one simply because I had to pick one of the two to ensure data precision in my SELECT statements. When a Perl program needs to find information in the census table, it first sends a SELECT command to the addressMaster table requesting the old street number and street name of the address to ensure that all of the records pre- and post- 1907 are retrieved.
The last demographic information table in the database contains a housing survey, created in 2000 by Art Institute of Chicago students working in the Historic Preservation department. The students, as part of a massive year long project, collected data about each private structure in the neighborhood. We were then presented a copy of the resulting Excel spreadsheet data and accompanying photographs, which I promptly massaged into a table form. Like the census information, most of the data is resident in external XML files:
<?xml version="1.0" ?> <!DOCTYPE houseDocumentation SYSTEM "/XML/DTD/houseDocumentation.dtd"> <houseDocumentation> <houseInformation recordID="94" imageFileName="11114champlain.jpg" address="11114" street="Champlain" ownerName="Balderama / Stigler" nonPullmanAddress="Both owner- occupied as of 02/04" /> <houseDescription houseType="Workers Cottage" houseTypeOther="" buildingType="Rowhouse" buildingTypeOther="" dateOfConstruction="1880" dateOfSurvey="2002-04-28" /> <physicalDescription roofType="Hipped" roofTypeOther="" roofMaterial="Asphalt" roofMaterialOther="" porchType="Wooden" porchTypeOther="" railings="Wooden" railingsOther="" mortar="Brown" mortarOther="" trimMaterial="Wood" trimMaterialOther="" chimney="Corbelled" chimneyOther="" contDetails="Dormers" contDetailsOther="" windows="Wood" windowsOther="" windowLights="" storms="Aluminum" stormsOther="" windowSills="Limestone" gutters="Other" guttersOther="" mainDoor="Modern Wood" mainDoorOther="" screenDoor="Metal" screenDoorOther="" otherSalientFeatures="Replacement windows and doors, replacement porch, painted brick Lg. center dormer flanked by two smaller front gable dormers w/ decorative rafter tails Brick corbeling below cove and between 1st. & 2nd. stories." brick="Original" brickOther="" basementWindows="" basementWindowsOther="" /> </houseDocumentation>
For various internal rights and permissions issues, I chose to place the data in its own separate table. The table is fairly simple, like the census table:
mysql> describe houseDocumentation; +---------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------+------------------+------+-----+---------+----------------+ | fileName | varchar(100) | YES | | NULL | | | address | int(10) unsigned | YES | | NULL | | | street | varchar(50) | YES | | NULL | | | mapReference | varchar(100) | YES | | NULL | | | vistaRecordID | int(10) unsigned | YES | | NULL | | | uid | int(10) unsigned | | PRI | NULL | auto_increment | +---------------+------------------+------+-----+---------+----------------+
The fileName field points to an external JPEG house photograph file. address and street, of course, refer to the (post-1907) address of the property, which, as described above, is pointed to by the addressMaster table. uid, like its brethren in the census table, is used to point to an external XML file as houseDocumentation.uid.xml
The mapReference field is not currently used, but could be developed as a link to the online maps (see below). vistaRecordID is also not being used, but is meant to point to a historical streetscape photograph if one exists. Should I develop this feature, I would create another table whose records pointed to image files of streetscapes and landscape vistas. I could then view a streetscape image and click on a link in that image to view in more detail the individual houses that make up that streetscape. I have not developed this feature at all except for putting in place the linkages that would make it possible; such a feature would have to be a future development.
Part II: Joining the Real and the Representational
How do all of these tables and XML records work together? My first course of action was to create Perl programs that would connect to the database through the excellent DBI::DBD library. I created a Perl script that presented the names, addresses, and professions of the people represented in the main table in alphabetical name order.

Clicking on the More… link above for any of the 1900 census entries actually brings up that specific census record. The Perl code that actually does the work behind the scenes is in the census.pl file (comments designated by octothorpes [#]). A snippet is shown here:
# Pulls in the $str variable to fill in the limiting letter. This SELECT statement calls the records themselves from the census table.
$query = "SELECT * FROM census $str ORDER BY lastName, firstName";
my $sth = $dbh->prepare($query);
$sth->execute();
while (@ADDRESS = $sth->fetchrow()) {
$address = $ADDRESS[0]; $aptNumber = $ADDRESS[1];
$dispstreet = $street = $ADDRESS[2]; $lastName = $ADDRESS[3];
$firstName = $ADDRESS[4]; $occupation = $ADDRESS[5];
$ownOrBoard = $ADDRESS[6]; $recordID = $ADDRESS[7];
$source = $ADDRESS[8]; $uid = $ADDRESS[8];
}
if ($firstName ne "") { $nameOfPerson = $lastName . ", " . $firstName } else { $nameOfPerson = $lastName }
$count++;
$dispstreet =~ s/th//g;
if ($ownOrBoard eq "R") { $ownOrBoard = "Primary Renter." }
elsif ($ownOrBoard eq "B") { $ownOrBoard = "Boarder." }
elsif ($ownOrBoard eq "U") { $ownOrBoard = "" }
if ($source eq "1900 Census") { $recordID = "<a href=\"/cgi-bin/pvm/houseHistoryDisplay1900Census.pl?fileName=1900Census." . $recordID . ".xml\">More...</a>" }
else { $recordID = "" }
1910 Sanborn maps, useful in allowing a more visual, map-based approach to discovering the demographic data in the PHHP, connect to the demographic tables as well. These maps were created as part of this project. They have been hand colored using appropriate Pullman colors, and, by using HTML image mapping (ISMAP), mapped to individual address records to create clickable online maps. There is also a fairly extensive set of Pullman maps online at http://www.pullman-museum.org/phhp/maps/. To me, maps help users relate demographic data to the actual site being described, so I have scanned in and enhanced a number of maps.

Clicking on one of the icons takes one to the actual linked map, such as the example below:
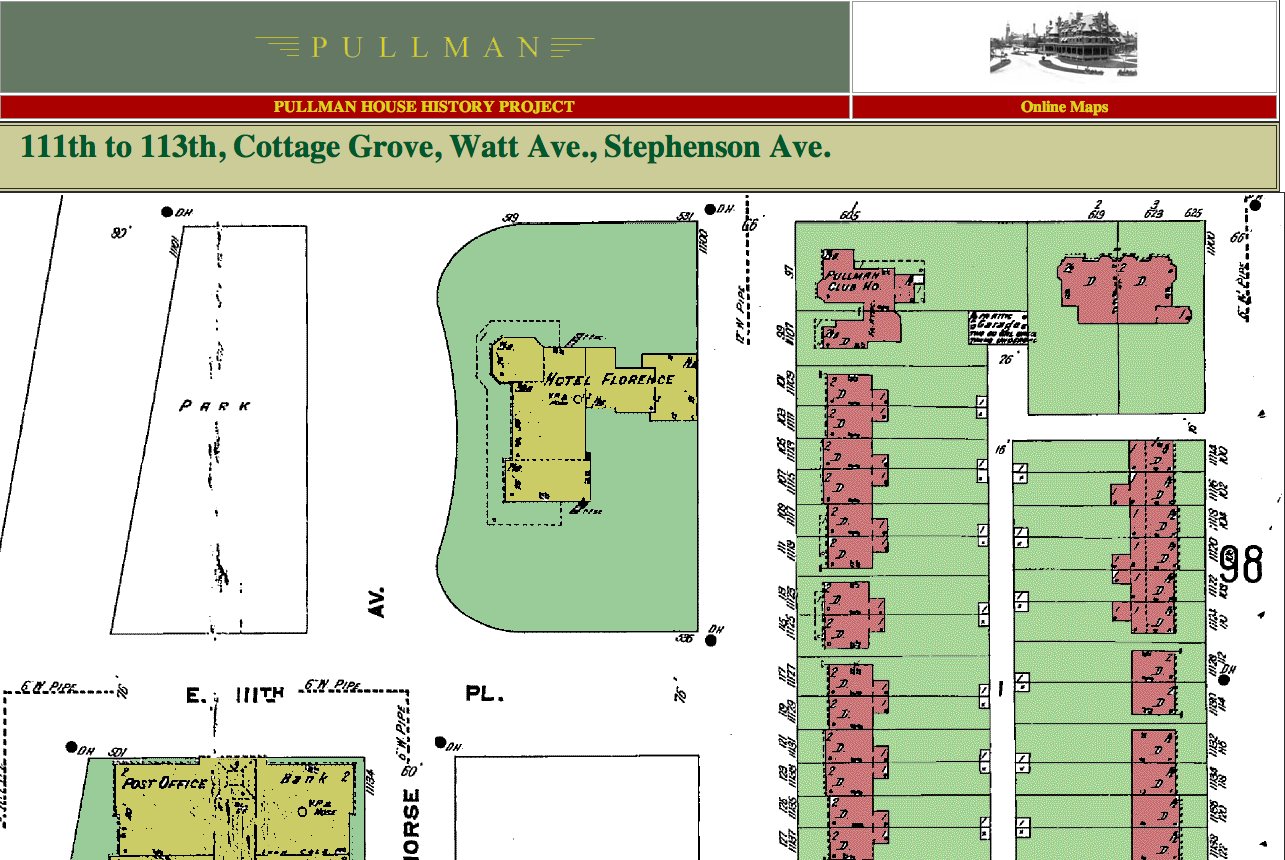
Notice that this 1910 map conveniently has both addresses on it for each property, reflecting the 1907 address changeover. Let us examine one property in detail, 100 Stephenson/11114 Champlain Avenue. Here is an 1882 photograph of this block of Stephenson, found as one of many images at the Pullman State Historic Site’s site:
 100 Stephenson is tinted blue and has a blue dot above it.
100 Stephenson is tinted blue and has a blue dot above it.[I have, of course, modified a copy of the image especially for this article, which leads me to an intriguing side discussion. A possible future development for the PHHP would be to make images of the town interactive, connecting them to the demographic tables in the much the same way as the Sanborn maps are connected. As I say, this remains a future development.]
The house history record for this property is retrieved using the Perl script houseHistoryGetAddress.pl.

Seen here is the snippet of code that actually retrieves the records (comments again designated by octothorpes):
if ($range eq "old") {
$addressField = "oldAddressSort"; $streetField = "oldAddress"; }
else { $addressField = "newAddressSort"; $streetField = "newAddress"; }
# Allows the user to switch back and forth between old address (pre-1907) and new address (post-address)
$queryaddress = "SELECT * FROM `addressMaster` WHERE $addressField = '$address' AND $streetField = '$street'";
my $sth = $dbh->prepare($queryaddress);
$sth->execute();
($oldStreetNumber,$newStreetNumber,$oldAddress,$newAddress,$oldAddressSort,$newAddressSort,$uida) = $sth->fetchrow();
# The above code simply finds the old and new street numbers and names for the indicated property
if ($oldStreetNumber eq "") {
$addressText = "No records found for this property.";
$oldAddress = $street;
$oldStreetNumber = $address;
}
else { $addressText = "Before 1907, this property was at $oldStreetNumber $oldAddress. It is now $newStreetNumber $newAddress." }
$imageFileName = $newAddressSort . $newAddress;
$imageFileName =~ tr/ //d;
$imageFileName = $imageFileName . ".jpg";
$imageFileName =~ tr/A-Z/a-z/;
# If we have a photo of the property from the 2000 AIC project, this will determine its name for subsequent display
$query = "SELECT recordID FROM houseDocumentation WHERE address='$newStreetNumber' AND street='$newAddress'";
my $sth = $dbh->prepare($query);
$sth->execute();
$xmlFile = $sth->fetchrow();
$sth->finish();
$housingSurveyStr = "";
if ($xmlFile) { $housingSurveyStr = "<a class=\"centeredObject\" href=\"/cgi-bin/pvm/housingSurveyMenuViews2.pl?address=$newStreetNumber&street=$newAddress\">2000 Survey</a>" }
# If we have a 2000 AIC survey for the property, then build a link to a CGI program that will display it
# I am skipping some code here, which simply builds up the headers to create a dynamic web page
# Now iterate through the 4 data sources for demographic data (1883 and 1889 city directories, 1900 census, and 1916 phone book
<h3 class="displayBanner">
1883 City Directory
</h3>
<p />
<table border="1">
EOF
# I will repeat this code as many times as necessary to retrieve all the names of the people who lived or worked at this address.
$querya = "SELECT * FROM `census` WHERE street = '$oldAddress' AND address = '$oldStreetNumber' AND source = '1883 City Directory' ORDER BY lastName, firstName";
my $sth = $dbh->prepare($querya);
$sth->execute();
while (@ADDRESS = $sth->fetchrow()) { &getValues }
print <<EOF;
</table>
<p />
<h3 class="displayBanner">
1889 City Directory
</h3>
<p />
<table border="1">
EOF
$querya = "SELECT * FROM `census` WHERE street = '$oldAddress' AND address = '$oldStreetNumber' AND source = '1889 City Directory' ORDER BY lastName, firstName";
my $sth = $dbh->prepare($querya);
$sth->execute();
while (@ADDRESS = $sth->fetchrow()) { &getValues }
print <<EOF;
</table>
<p />
<h3 class="displayBanner">
1900 Census
</h3>
<p />
<table border="1">
EOF
$querya = "SELECT * FROM `census` WHERE street = '$oldAddress' AND address = '$oldStreetNumber' AND source = '1900 Census' ORDER BY lastName, firstName";
my $sth = $dbh->prepare($querya);
$sth->execute();
while (@ADDRESS = $sth->fetchrow()) { &getValues }
print <<EOF;
</table>
<p />
<h3 class="displayBanner">
1916 Phone Book
</h3>
<p />
<table border="1">
EOF
$querya = "SELECT * FROM `census` WHERE street = '$oldAddress' AND address = '$oldStreetNumber' AND source = '1916 Phone Book' ORDER BY lastName, firstName";
my $sth = $dbh->prepare($querya);
$sth->execute();
while (@ADDRESS = $sth->fetchrow()) { &getValues }
print <<EOF;
<p />
</table>
EOF
getFooter();
print "</body>\n</html>\n";
$dbh->disconnect;
# The routine getValues retrieves individual records from the SQL SELECT statement above and formats them into HTML
sub getValues {
$address = $ADDRESS[0]; $aptNumber = $ADDRESS[1];
$street = $ADDRESS[2]; $lastName = $ADDRESS[3];
$firstName = $ADDRESS[4]; $occupation = $ADDRESS[5];
$ownOrBoard = $ADDRESS[6]; $recordID = $ADDRESS[7];
$source = $ADDRESS[8]; $uid = $ADDRESS[8];
if (($address ne "") and ($street ne $oldAddress)) {
$dispstreet = $street;
$street =~ s/th//g;
$street =~ s/ /%20/g;
$address = "<br />Lived at: <a href=\"/cgi-bin/pvm/houseHistoryGetAddress.pl?range=o
ld&street=" . $street . "&address=" . $address . "\">$address $dispstreet</a>";
}
else { $address = "" }
if ($firstName ne "") { $nameOfPerson = $lastName . ", " . $firstName }
else { $nameOfPerson = $lastName }
$aptNumber =~ s/Room//g;
if ($aptNumber ne "") { $nameOfPerson = $nameOfPerson . " Room " . $aptNumber }
if ($ownOrBoard eq "R") { $ownOrBoard = "Primary Renter." }
elsif ($ownOrBoard eq "B") { $ownOrBoard = "Boarder." }
elsif ($ownOrBoard eq "U") { $ownOrBoard = "" }
if ($source eq "1900 Census") { $recordID = "<a href=\"/cgi-bin/pvm/houseHistoryDisplay1900C
ensus.pl?fileName=1900Census." . $recordID . ".xml\">More...</a>" }
# Builds a More… link that points to an external XML file, 1900Census.$recordID.xml.
else { $recordID = "" }
print <<WOMBAT;
<tr>
<td width="20%"><span class="nameText">$nameOfPerson</span></td><td width="4
0%"><span class="italictext">$occupation</span></td><td class="40%"><span class="rentOrBoardText">$r
ecordID $address</span></td>
</tr>
WOMBAT
}
Officer William Jeffrey’s 1900 census record from the example above is retrieved using the Perl script houseHistoryDisplay1900Census.pl (snippet displayed further down):

# I am using the Perl module XML::Simple to reformat the XML file that contains the 1900 census data. The programs knows which file to retrieve because it was passed from the More… link above, and was determined by the getDefaults subroutine above.
use XML::Simple;
my $xmlref;
my $xmlref = XMLin("/home3/pullman/sites/pullman-museum.org/html/XML/$xmlFile");
# Is the actual file name and path
##### houseInformation #####
$aptNumber = $xmlref->{houseInformation}->{aptNumber};
$address = $xmlref->{houseInformation}->{address};
$street = $xmlref->{houseInformation}->{street};
$dwellingNumber = $xmlref->{houseInformation}->{dwellingNumber};
##### personalInformation #####
$familiesNumber = $xmlref->{personalInformation}->{familiesNumber};
$lastName = $xmlref->{personalInformation}->{lastName};
$firstName = $xmlref->{personalInformation}->{firstName};
$relation = $xmlref->{personalInformation}->{relation};
$race = $xmlref->{personalInformation}->{race};
$sex = $xmlref->{personalInformation}->{sex};
$dobMonth = $xmlref->{personalInformation}->{dobMonth};
$dobYear = $xmlref->{personalInformation}->{dobYear};
$dob = $dobMonth . " " . $dobYear;
$age = $xmlref->{personalInformation}->{age};
$maritalStatus = $xmlref->{personalInformation}->{maritalStatus};
$yearsMarried = $xmlref->{personalInformation}->{yearsMarried};
$motherOf = $xmlref->{personalInformation}->{motherOf};
$childrenLiving = $xmlref->{personalInformation}->{childrenLiving};
Challenges Ahead
In the future, we hope to make better use of sources that give the census entries life and breadth. The records representing people need to be expanded to have any meaning and context. Consider the case of Malcolm McQueen and his widow:

I have found two references to McQueen in the Chicago Tribune.
Malcolm McQueen, foreman of the repair shops at Pullman, went into the cellar of his residence at No. 124 Watt Avenue about 4 o’clock yesterday morning and hanged himself. In his pockets were found a note saying that his head pained him and a message to his wife bidding her goodbye.
Chicago Tribune, Sept. 23, 1888
and
Robert McQueen is a guest at the home of his sister in law, Mrs. Malcolm McQueen on Watt avenue… The funeral services of the late Malcolm McQueen were held at the Presbyterian Church Monday afternoon under the charge of the Masons. Before 2:30, the hour set for the funeral, the church was filled to its utmost capacity and it was with difficulty that the ushers kept the crowd from filling the aisles.
Chicago Tribune, Sept. 30, 1888
Mr. McQueen’s story is poignant and deserves to be highlighted. These accounts should be connected to McQueen’s demographic information, tying his name to the text of the article. The primary source for newspaper articles like these is the Pullman Company Scrapbooks. The Scrapbooks, held at the Newberry Library in Chicago, were kept by the Pullman Company from 1870 to 1925. They represent a priceless treasure of clippings concerning the Pullman town and company. There are over 100,000 individual clippings in the Scrapbooks, of which a few example pages can seen at http://www.pullman-museum.org/scans/. We are currently working on a grant that will allow us to digitize these articles as OCR’d PDF files which can then be keyword indexed. We use SWISH-E as our search engine and harvester, and we have been very happy with it.
I can easily connect the names contained in the census table and these newspaper clippings by writing a brute force program that searches for each name as selected in a SWISH-E-based clippings index. This is, however, a crude and imprecise solution. A better solution would be to employ a natural language processing program that will create a table more precisely linking the names in the census table and the records in the keyword index. The ideal solution, of course, would be to create item level metadata records for each article, a very expensive and time-consuming proposition. How we are going to properly handle the clippings records is a matter undergoing discussion.
Another major hurdle is simply completing the census data inputting. I have, to this point, relied on volunteer efforts to completely input the 1883 and 1889 city directories and the 1916 phone directory. Volunteer efforts, however, have only been able to enter 5% of the 1900 census. Clearly, volunteers will not be able to get the rest of the census data entered, so we are currently working on yet another grant that will allow us to engage a commercial firm to enter the rest of the 31,750 census entries.
In Conclusion
The Pullman State Historic Site’s virtual museum records an average of 212,854 hits a month. The use of the Pullman Virtual Museum increases on a monthly basis, and we look forward to expanding it to ever greater functionality by adding in the newspaper clippings and finally digitizing the remainder of the census records. It has been, so far, a rare opportunity to work on such an enjoyable and unique project. Please come visit us at http://www.pullman-museum.org/ and explore the world of Pullman.
Author Information:
Andrew Bullen is the Information Technology Coordinator for the Illinois State Library, and a proud resident of the Pullman community. He can be reached at abullen at ameritech dot net.

Subscribe to comments: For this article | For all articles
Leave a Reply