by Tomasz Neugebauer, Pamela Carson, and Stephen Krujelskis
Introduction
An important feature of a library website (and subject guides, in particular) is the listing of recommended resources created by librarians. These resources usually consist of links to a catalogue, database, or website. Each resource includes 3 parts: a title, a URL, and a brief description/annotation. Due to the changing nature of web-based resources, it is an ongoing challenge to maintain these lists, ensuring that links are active and appropriate, and editing, removing or adding resources. The same resources often appear on different webpages on the library’s website, so a centralized method of maintaining this content saves time and reduces errors. Delicious, the social bookmarking site, was suggested as way of managing lists of resources centrally, saving time and eliminating the need for duplicating content (Corrado 2008; Corrado and Frederick 2008; Darby and Gilmour 2009). Resources could be added to Delicious, tagged with subject terms, and RSS feeds could be created with tag combinations. Corrado (2008) stated that “Using a small amount of JavaScript, these bookmarked resources can be dynamically included in subject guides and other Web-based library resources.” Concordia University Libraries used this method to populate many of its web pages with lists of recommended resources for a number of years. However, in 2011, Delicious was sold by Yahoo! to AVOS (Karunamurthy 2011). In September 2011, Delicious was upgraded and the Libraries lost access to Delicious feeds for several weeks. Again, in March 2012, feeds were unavailable for several days. This prompted the Libraries to search for alternatives to Delicious for managing content on its website.
Method
SemanticScuttle was identified as the ideal replacement for Delicious. Locally hosted and open source, this PHP/MySQL social bookmarking application had all of the essential functionality of Delicious, including a user-friendly interface, but it also came with the stability and reliability required for use on a website that receives nearly 4 million page views annually.
 Figure 1. SemanticScuttle web interface
Figure 1. SemanticScuttle web interface
To add an item to SemanticScuttle, librarians log into the web application, click Add a Bookmark, enter the item’s URL, fill in the title and description, and tag the item with relevant keywords. The Tags form field includes an autocomplete feature, helping librarians maintain tag consistency (see Figure 2).
 Figure 2. Adding an item to SemanticScuttle
Figure 2. Adding an item to SemanticScuttle
To preview a feed before adding it to the website, tags can be added to the end of the URL, with multiple tags separated by plus signs (“+”), (see Figure 3). For example:
http://[scuttle host]/rss.php/all/videos+2014
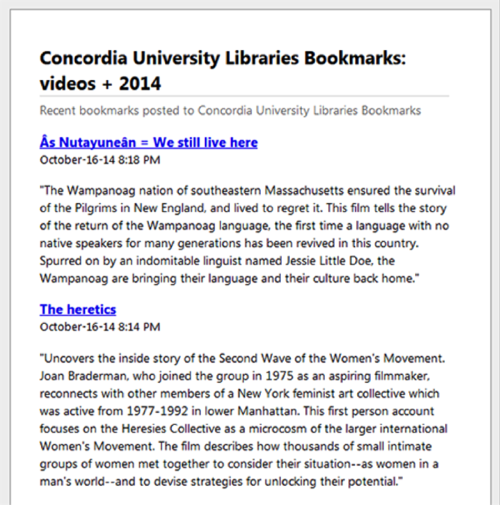 Figure 3. Previewing a feed
Figure 3. Previewing a feed
On the library website, a JavaScript function allows the librarian to specify the requested tags, define the sorting order (alphabetical or by date, ascending or descending) and limit the number of resources retrieved:
<script type="text/javascript"> scuttleFeed("videos+2014", "date_desc", "");</script>
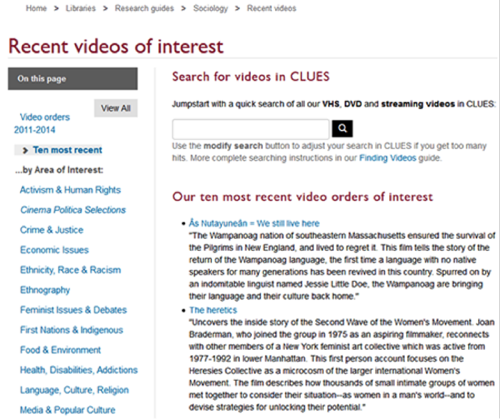 Figure 4. Feed populating the section on the webpage for “Our ten most recent video orders of interest” on http://library.concordia.ca/guides/sociology/newvideos.php?guid=ten
Figure 4. Feed populating the section on the webpage for “Our ten most recent video orders of interest” on http://library.concordia.ca/guides/sociology/newvideos.php?guid=ten
The source code for the scuttleFeed() function is included below. The list of resources then displays on the webpage as a bulleted list with the resource title hyperlinked to the URL and the description (see Figure 4).
In addition, a useful feature of SemanticScuttle is the ability to export all records from the web interface as an HTML, XML or CSV file, allowing for the links to be submitted to a link checker to identify broken links.
Displaying SemanticScuttle Content in Moodle
SemanticScuttle’s use is not limited to populating pages on the library’s website. We also developed a Moodle ‘library block’ in PHP that exposes course and discipline specific resources curated by subject librarians in SemanticScuttle (see Figure 5). The library block uses the Direct SQL query method described below. To display resources in the library block, a librarian assigns the appropriate course (e.g. moodle_phil201) or discipline (e.g. moodle_math) tag in SemanticScuttle. Discipline tags are assigned to resources of broad utility and display on all the courses in that discipline, for example, MathSciNet for mathematics. To toggle the display of each resource in the library block in Moodle, librarians add an additional tag that determines if the resource is to appear or not. This allows librarians to collect links for courses and disciplines without necessarily displaying them all.
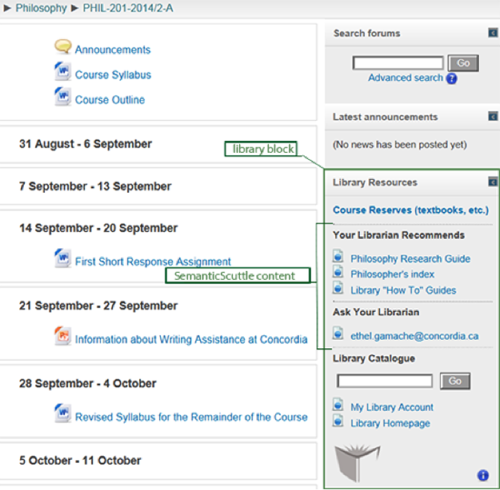 Figure 5. Moodle “library block” for Philosophy 201 course. The placement of the library block is controlled by the course instructor and “Your Librarian Recommends” links are controlled by librarians through SemanticScuttle tags
Figure 5. Moodle “library block” for Philosophy 201 course. The placement of the library block is controlled by the course instructor and “Your Librarian Recommends” links are controlled by librarians through SemanticScuttle tags
Implementation
The use of SemanticScuttle involves a combination of PHP, MySQL and JavaScript, and is summarized in Figure 6.
 Figure 6. Use of SemanticScuttle on the library website and Moodle-based course management system
Figure 6. Use of SemanticScuttle on the library website and Moodle-based course management system
Two implementations for displaying feed content from SemanticScuttle on the library’s website and Moodle were developed:
- Using Google Feed API: Asynchronous JavaScript call to construct a Google Feed API formatted HTML for display based on the RSS/XML from SemanticScuttle.
- Using Direct SQL Query: Asynchronous JavaScript call to a PHP script that constructs an SQL query to the back end of SemanticScuttle’s database and returns formatted HTML for display.
Google Feed API
The Google Feed API can be used to display any feed on a website. The main advantage of using this API over other methods is that it simplifies the local implementation while leveraging the robust Google servers in delivering content to the page. The existence of the Google Feed API includeHistoricalEntries() option confirms that Google is using caching on its servers to improve performance. Placing the Google Feed API as an intermediary to external RSS feeds (e.g., those from journal publishers) makes particular sense, but the fast performance of the API makes its use practical for locally hosted SemanticScuttle feeds as well.
The Google Feed API method uses both jQuery and the Google API, so the following two scripts need to be loaded in the head of the HTML document:
<script src="//code.jquery.com/jquery-1.8.3.min.js"></script> <script src="https://www.google.com/jsapi"></script>
The following JavaScript function takes the SemanticScuttle tags, sort, and count parameters, constructs the appropriate HTTP query string to SemanticScuttle, and generates the resulting feed display using Google Feed API:
function scuttleFeed(tags, sort, count){
var arrScripts = document.getElementsByTagName('script');
arrScripts[arrScripts.length - 1].id=makeid();
var strScriptTagId = arrScripts[arrScripts.length - 1].id;
if (sort == ""){sort="title_asc";}
if (count == ""){count=999;}
var container = $('#'+strScriptTagId).parent();
var imgID=makeid();
html='<img id="'+imgID+'" src="/images/loading.gif" />';
container.append(html);
//Scuttle does the sorting
var feedURL="http://[scuttle host]/rss.php/all/"+tags+"?sort="+sort;
google.load("feeds", "1");
function initialize() {
var feed = new google.feeds.Feed(feedURL);
if (count != ""){feed.setNumEntries(count);}
feed.load(function(result) {
if (!result.error) {
ulID=makeid();
html='<ul id="'+ulID+'">';
container.append(html);
containerUL=$('#'+ulID);
for (var i = 0; i < Math.min(count,result.feed.entries.length); i++) {
var entry = result.feed.entries[i];
html = '<li><a href="' + entry.link + '">' + entry.title + '</a>';
html += '<br />' + entry.content;
html += '</li>';
containerUL.append(html);
}
$('#'+imgID).hide();
}
});
}
google.setOnLoadCallback(initialize);
}
Asynchronous loading of RSS content into a page uses jQuery to append elements to the DOM of the page. A helper makeid JavaScript function is used to generate IDs for added DOM components such as a new <ul> tag with the content of the feed.
Making Google Feed API a dependency in this implementation carries with it some risk that Google may discontinue or begin charging for this service. The Google Feed API Terms of Service commit to backwards compatibility with the current state of the API only until April 20, 2015. How the interface and license will change after that is unknown. To mitigate this risk, we experimented with processing RSS feeds locally using PHP’s XML parser.
function scuttleLinks($tags,$sort,$count) {
// location of scuttle rss
$feedURL = "http://[scuttle host]/rss.php/all/$tags?count=$count&sort=$sort";
$feed_raw = file_get_contents($feedURL);
// remove colons from xml tags (i.e. namespaces) that can break SimpleXML
$feed = preg_replace("/(<\/?)(\w+):([^>]*>)/", "$1$2$3", $feed_raw);
// parse xml
$xml = simplexml_load_string($feed);
// start an unordered list
echo "<ul>";
// loop through bookmarks in rss feed
foreach ($xml->channel->item as $bookmark) {
// get properties
$title = $bookmark->title;
$link = $bookmark->link;
$desc = $bookmark->description;
// other interesting properties include pubDate and category
// there can be multiple category attributes
// write list items
echo "<li><a href=\"$link\">$title</a><br />$desc<br /></li>\n";
}
// end list
echo "</ul>";
}
Since this is a PHP function, an asynchronous JavaScript call to it would ensure that the page load is not held up by the processing of long RSS feeds. This would be done with jQuery’s ajax function which performs an asynchronous HTTP request to process the feed on the server with PHP. The following is the implementation of that function:
function scuttleFeed(tags, sort, count){
var arrScripts = document.getElementsByTagName('script');
arrScripts[arrScripts.length - 1].id=makeid();
var strScriptTagId = arrScripts[arrScripts.length - 1].id;
$.ajax({
url: '/scuttle-ajax.php',
type: "POST",
data: {tags : tags, sort: sort, count:count},
success: function(data, textStatus) {
$('#'+strScriptTagId).parent().append(data);
}
});
}
Alternatively, as long as SemanticScuttle resides on the same domain as the syndicating site, it should also be possible to implement an XML/RSS parser using jQuery’s parseXML function. This implementation option would keep the feed processing on the browser side without the use of the Google Feed API.
Direct SQL query
As mentioned above, SemanticScuttle is also used for displaying discipline and course specific links in the University’s Moodle course management system. In this context, the Google API component was replaced with a SQL connection and regular expression based query to the SemanticScuttle database. This avoided the need for jQuery, which was not being loaded by our Moodle system at the time of implementation.
The SemanticScuttle database describes bookmarks in table sc_bookmarks and relationships between bookmarks and tags in table sc_bookmarks2tags. The bookmark ID, bId, is the primary key only in sc_bookmarks, since there can be many tag relationships for one bookmark in sc_bookmarks2tags. For example, the following query retrieves a bookmark with bId 5 from the sc_bookmarks table:
SELECT bId, bTitle, bAddress, bDescription FROM sc_bookmarks WHERE bId =5
The result of the above query is shown in Table 1.
| bId | bTitle | bAddress | bDescription |
|---|---|---|---|
| 5 | Fortunate son | http://clues.concordia.ca/record=b3017339~S0 | Autobiographical documentary by the son of Greek immigrants living in Canada. […] |
Table 1. Item from sc_bookmarks table
Table sc_bookmarks2tags contains relationships between bookmarks and tags. For example, the following is a sample of some bookmark-to-tag relationships in the sc_bookmark2tags table.
The tags for the bookmark with bId 5 can be retrieved using the following query:
SELECT bId, tag FROM sc_bookmarks2tags WHERE bId =5
The result of this query is shown in Table 2.
| bId | tag |
|---|---|
| 5 | religion |
| 5 | canada |
| 5 | 2013 |
| 5 | family |
| 5 | videos |
| 5 | bronf |
| 5 | culture |
| 5 | system:imported |
Table 2. Item from sc_bookmarks2tags table
The system:imported tag indicates that this link was part of a bulk import from Delicious using SemanticScuttle’s import function.
To retrieve all bookmarks for a given tag, or a set of tags, the two tables above must be joined using the bId, concatenating and sorting all tags into one field. For example, the following is a sample SQL query that accomplishes this for a bookmark with bId 5:
SELECT sc_bookmarks.bId, bTitle, bAddress, bDescription, GROUP_CONCAT( tag ORDER BY tag ) AS tags FROM sc_bookmarks LEFT JOIN sc_bookmarks2tags ON sc_bookmarks.bId = sc_bookmarks2tags.bId WHERE sc_bookmarks.bId =5
The result of the above query is shown in Table 3.
| bId | bTitle | bAddress | bDescription | tags |
|---|---|---|---|---|
| 5 | Fortunate son | http://clues.concordia.ca/record=b3017339~S0 | Autobiographical documentary by the son of Greek immigrants living in Canada. […] | 2013, bronf, Canada, culture, family, religion, system:imported, videos |
Table 3. Example of join between sc_bookmarks and sc_bookmarks2tags showing a bookmark with all tags
Instead of searching for a particular bId, the result of this join can also be searched by tag using a regular expression. For example, to search for bookmarks with tags canada, culture, family and videos, the SQL query with the regular expression would be:
SELECT bDateTime, bTitle, bAddress, bDescription, GROUP_CONCAT( tag ORDER BY tag ) AS tags FROM sc_bookmarks LEFT JOIN sc_bookmarks2tags ON sc_bookmarks.bId = sc_bookmarks2tags.bId GROUP BY bTitle HAVING LOWER( tags ) RLIKE "(^|,)canada($|,.*)culture($|,.*)family($|,.*)videos($|,.*)"
The regular expression for a given set of tags is constructed using PHP as follows:
// $tags_in is sent in the function call as a string of format "tagA+tagB+tagC"
// explode this string on the + signs and normalize the tags to lowercase
$tags = explode('+',strtolower($tags_in));
// sort the array of tags
sort($tags);
$regex = '(^|,)'; // next word is beginning of string OR is preceded by a comma
foreach ($tags as $tag) {
// for each tag, include the tag and some punctuation for what comes next,
// which could be either the end of the string, or a comma and another tag
$regex .= $tag . '($|,|,.*,)';
}
Discussion
With support for LDAP, Delicious bookmark import and a Firefox plugin, SemanticScuttle is a robust open source (GPLv2 license) PHP/MySQL application for the management of bookmarks.
SemanticScuttle is also user friendly, as librarians were quick to adopt it for managing lists of resources on their subject guides. A combination of a presentation, a one-page “quick guide” and some in-person training was sufficient to get librarians using the system. As of November 2014, the Libraries’ SemanticScuttle holds over 2500 links, and 41 pages on the Libraries’ website display this content. Ten librarians are using SemanticScuttle feeds on their subject guides.
SemanticScuttle has proven to be a very useful tool for populating library blocks in the Moodle course management system. As of November 2014, there are 62 discipline specific feeds (e.g., general resources for political science) and 166 course specific feeds (e.g., specific resources for a political science course such as POLI 201).
With the exception of tags for courses and disciplines in Moodle, the tags in SemanticScuttle currently used by librarians are not controlled through a taxonomy or published vocabulary. The Libraries use more than 700 tags in total to describe items in SemanticScuttle. Future work could include increased control over tag vocabulary for feeds populating webpages.
SemanticScuttle’s bDescription field for each URL does not support HTML by default, so the addition of hypertext for this field is a functionality to consider for the future. RSS format allows for the possibility of CDATA HTML in the <description> field of each <item>. However, since SemanticScuttle content is pulled in for display on the university’s website, security is a key concern, and stripping markup (e.g.: JavaScript) in SemanticScuttle’s database is an important component of that security. Therefore, this feature would require the addition or development of a new sanitization function that would allow the basic HTML but nevertheless offer some level of protection.
Conclusion
SemanticScuttle is a relatively simple and powerful solution for managing web resources with the potential for adoption by other libraries. We have outlined multiple implementations for the syndication of web links in SemanticScuttle. An interesting question that emerges from this project is that of the extent to which library web links curated by university libraries are re-usable in the context of open data. Although the content in SemanticScuttle is accessible through RSS, an investigation into existing schemas and controlled vocabularies that could be applied to these resources would be a prerequisite to meaningful open distribution of this data.
Acknowledgements
The authors thank the editors of Code4Lib Journal for their comments and suggestions.
References
Corrado, EM. 2008. Delicious subject guides: Maintaining subject guides using a social bookmarking site. Partnership: the Canadian Journal of Library and Information Practice and Research [Internet]. [cited 2014 June 13]; 3(2): 1-19. Available from: https://journal.lib.uoguelph.ca/index.php/perj/article/view/328/1370
Corrado, EM, Frederick, KA. 2008. Free and open source options for creating database-driven subject guides. Code4Lib Journal [Internet]. [cited 2014 June 13]; 2. Available from: http://journal.code4lib.org/articles/47
Darby, A, Gilmour, R. 2009. Tutorial: Adding Delicious data to your library website. Information Technology and Libraries [Internet]. [cited 2014 June 13]; 28(2): 100-103. Available from: http://www.ala.org/lita/ital/files/28/2/darby.pdf
Karunamurthy, V. 2011 September 27. The first 20 hours. Delicious Blog [Internet]. [cited 2014 April 28]. Available from: http://blog.delicious.com/2011/09/the-first-20-hours/
Redden, CS. 2010. Social bookmarking in academic libraries: Trends and applications. The Journal of Academic Librarianship [Internet]. [cited 2014 June 13]; 36(3): 219-227. Available from: http://dx.doi.org/10.1016/j.acalib.2010.03.004
About the Authors
Tomasz Neugebauer is Digital Projects & Systems Development Librarian at Concordia University Libraries.
Pamela Carson is Web Services Librarian at Concordia University Libraries.
Stephen Krujelskis is Systems Administrator/Analyst at Concordia University Libraries.

Subscribe to comments: For this article | For all articles
Leave a Reply