By Bret Davidson and Jason Casden
”In the open source community there exists a tremendous need for exactly the skills librarians have always used in making information resources truly useful. In particular, systems testing, evaluation, and feedback to open source designers is welcome and even sought after; documentation for open source systems is always needing improvement; instructional materials for open source products are often lacking. These are all areas in which librarians excel.” From “Open Source Library Systems: Getting Started.” (Chudnov, 1999)
The Code4Lib community has produced an increasingly impressive collection of open source software over the last decade, but much of this creative work remains out of reach for large portions of the library community. To what extent has our community fulfilled the promise of free and open source software to improve service to our users, particularly as it concerns the vast swath of users served primarily by smaller institutions? Do relatively privileged institutions have a professional responsibility to support the adoption of their innovations?
“We hope the Code4Lib Journal can manifest the values that have been successful for the Code4Lib community, while providing increased access to the collective knowledge and experience held throughout our diverse professional networks and local organizations, increasing cross-pollination and collaboration among library technology innovators–and helping more people and organizations become innovators.” From “Editorial Introduction — Issue 1” in the Code4Lib Journal. (Rochkind, 2007).
Despite this stated goal, there are large segments of our broader community of cultural heritage institutions that are unable to implement even the most well documented open source software. These organizations, that represent unique and often marginalized user communities, often have extremely limited access to IT resources. We’ve seen firsthand, through our own experiences in supporting open source communities, the impact this has on the ability of organizations to adopt open source library software. In this article, we will present an initial set of performance indicators and technical guidelines to support those developers interested in moving beyond open source to genuinely available software.
Background
Early free software
“In the early days of computing, the need to generate massive adoption was strong and the compatibility threat was weak—open-source software reigned supreme.” (Campbell-Kelly & Garcia-Swartz, 2009).
In the 1950s and 1960s, software was often free, source code was available and modifiable, and major development projects were undertaken as a collaboration between vendors, user groups, and academics. One of the earliest examples is often cited as one of the first open source systems and also the first source code compiler. The prevailing idea at the time was that software sold systems, and that the computing industry was primarily a hardware business. Software was often collaboratively developed and bundled for free with modifiable source code. The distinction between source code access and technology availability, however, is evident in major software packages such as the IBM Airline Control Program (ACP), which was developed by IBM between 1965 and 1979:
“What makes ACP interesting to open source supporters is that, while technically I suppose IBM ‘owned’ it, the source code was completely available for any developer to change, fix, and enhance. You needed an IBM mainframe on which to run the code, which even the geekiest did not consider (those people were drooling over the DEC VAX back then), so availability is only a relative term. I don’t remember exactly how the code was contributed back to IBM, which served largely as a code repository (and also sold high-priced technical consultants to help these large enterprises install, support, and deploy the software on IBM hardware — some things don’t change). But I do know that it was done.” (Schindler, 2009).
It’s important to note that the computing landscape differed in profound ways from our current environment. Systems were huge and extremely expensive, and only a small number of extremely wealthy organizations could participate in these communities. Software generally was only compatible with one vendor’s platform, and huge technological challenges faced any independent vendor seeking to port an application to another vendor’s environment. This assumes, of course, that these vendors existed, although the independent software vendor (ISV) industry would not take off until the 1970s. (Philipson, 2004). This approach of bundling “free” source code with hardware was restrained by a long, but ultimately unsuccessful, federal antitrust lawsuit against IBM that was later echoed by the Microsoft antitrust case in the 1990s.
“Such practices allegedly included anticompetitive price discrimination such as giving away software services for ‘the purpose or with the effect of… enabling IBM to maintain or increase its market share… ‘ (Id. at 9.) The Government also alleged that IBM’s bundling of software with ‘related computer hardware equipment’ for a single price was anticompetitive. (Id. at 10.)” (Brown, et al., 1995).
The combination of more affordable computing hardware, legal challenges, and the emergence of independent software vendors led us into the emergence of a computing industry in which the notions of free and commercial software may be more recognizable to the reader.
Hacker culture and the opposition to free software
The hobbyist computer culture of the 1970s developed alongside the much wider availability of academic computing and the development of minicomputers and DIY kits. The increasing prominence of academic and hobbyist computing communities led to the integration of these communities’ ideals, such as intellectually, rather than commercially, driven code sharing, “hacking,” and open collaboration, into the computing field. At the same time, a nascent software industry was developing independently of the major hardware vendors. These vendors, heavily relying on software sales and licensing for revenue, began to resist the open and collaborative approaches to software development that academics and hobbyists value intellectually and hardware vendors and users value commercially. More closed development models allowed these vendors to compete not only based on advertised functionality, but also on the ability of these vendors to stitch together a wider base of platform support from a fragmented hardware industry. Among these newer independent vendors to emerge from hobbyist and academic communities is Microsoft.
“One thing you do do is prevent good software from being written. Who can afford to do professional work for nothing? What hobbyist can put 3-man years into programming, finding all bugs, documenting his product and distribute for free? The fact is, no one besides us has invested a lot of money in hobby software. We have written 6800 BASIC, and are writing 8080 APL and 6800 APL, but there is very little incentive to make this software available to hobbyists. Most directly, the thing you do is theft.” (Gates, 1976).
This quote, taken from Bill Gates’ legendary “Open Letter to Hobbyists,” aptly captures the moment in the history of software when independent software creators diverged into more formally managed free and commercial communities.
Emergence of free and open source software
In this environment of increasingly powerful independent software vendors, partnerships between hardware and software (such as the critical PC partnership between IBM and Microsoft), and complex inter-vendor software compatibility needs, ideological and academic free software movements and licenses began to formalize their organizations and policies. Examples of these included the Free Software Foundation and its GNU license, the “BSD” license, and the “MIT” license.
“By working on and using GNU rather than proprietary programs, we can be hospitable to everyone and obey the law. In addition, GNU serves as an example to inspire and a banner to rally others to join us in sharing. This can give us a feeling of harmony which is impossible if we use software that is not free. For about half the programmers I talk to, this is an important happiness that money cannot replace.” (Stallman, 1985).
These licenses helped to establish a software community that supported the revival and expansion of collaborative and distributed development for common systems handling functions such as email (sendmail), web service (Apache), and server operating systems (Linux). However, many of these licenses were designed either to foster scholarship or to pursue ideological ends. In 1998, partially in response to commercial experimentation with free distribution of application source code, the Open Source Initiative, and the descriptor “open source,” were born.
“The conferees believed the pragmatic, business-case grounds that had motivated Netscape to release their code illustrated a valuable way to engage with potential software users and developers, and convince them to create and improve source code by participating in an engaged community. The conferees also believed that it would be useful to have a single label that identified this approach and distinguished it from the philosophically- and politically-focused label ‘free software.’ Brainstorming for this new label eventually converged on the term ‘open source,’ originally suggested by Christine Peterson.” (History of the OSI…[updated 2015]).
This newer free software movement, which has helped to drive the commercial success of free software that is widely apparent today, has not proceeded without criticism (Stallman, [updated 2015]) for its business-friendly approach that explicitly distances itself from earlier “politically-focused” free software organizations. The “open source” moniker has since come to dominate discussions of pragmatic and even commercial free software efforts.
The reemergence of the single deployment platform
One thing that movements ranging from the Free Software Foundation to the Open Source Initiative seem to agree on, however, is the need to work collaboratively to develop a new common application infrastructure to recapture the benefits of the earlier period of vendor behemoths. Whether this is seen to encourage more productive competition or higher availability to independent developers is beyond the scope of this paper, but suffice it to say that both commercial and ideological motives were often aligned in this work.
“The more recent switch to hybrid strategies reveals (a) an attempt to recreate, via open-source software, the single-platform scenario that IBM achieved with System/360 (and that IBM failed to recreate, in a proprietary context, via SAA), and (b) an attempt to boost revenues from middleware and services while allowing the old cash cows (e.g. proprietary operating-system software) to peacefully die an unavoidable death.” (Campbell-Kelly & Garcia-Swartz,
2009).
”Unix is not my ideal system, but it is not too bad. The essential features of Unix seem to be good ones, and I think I can fill in what Unix lacks without spoiling them. And a system compatible with Unix would be convenient for many other people to adopt.” (Stallman, 1985).
The most critical factor within the context of this article is that a large and influential group of academics, hobbyists, and commercial organizations have moved beyond the dichotomy of developer freedom and revenue towards seeking a common infrastructure to reach more users with less work. Unix, and particularly Linux, began to be seen as a strong candidate for providing a layer of abstraction over extremely fragmented hardware and systems layers.
Our own experience
Unfortunately, we’ve found that library open source software has tended to favor the support for narrow (well-resourced) institutional and developer communities over this goal of widespread support for diverse user communities. We’ve seen this most clearly with our own open source releases. While we’ve been reasonably successful when it comes to promoting projects at conferences and journals, as well as supporting software adoption at similar (research) libraries, we’ve failed at enabling the adoption of our approaches at other cultural heritage institutions.
Suma
Suma (Suma … [updated 2015]) is an open-source mobile web-based assessment toolkit developed by NCSU Libraries for collecting and analyzing observational data about the usage of physical spaces and services. This software suite, used by dozens of libraries, is designed to provide easy and rapid analytics capabilities for spaces and service similar to that which is available for web services. The following quote is from an email from a librarian at a research university seeking to install Suma (used with permission).
“Who would be the best person on your team to talk with about the technical requirements and skills needed for us to install SUMA and get it up and running. For example, do we need a computer programmer with such and such skills. I’m sure you have good documentation available, however, we would like to talk with someone. We are also curious as to how much time it would take to get SUMA working for us. I am not sure we have the expertise in-house.”
And from a librarian at a research university (also used with permission) on canceling a pilot Suma evaluation:
“Ultimately, I didn’t want to get on our IT support’s bad side and because I’m not allowed to play with our development servers I can’t exactly go at the installation process alone.”
These librarians (and others who already have the fortune to work at relatively large research institutions) were struggling to find the IT resources necessary to deploy what we humbly feel is a fairly well-tested and documented web-based application. Of course, much of the community who could benefit from space and service usage data analytics has access to far fewer resources. No amount of testing and documentation will solve this problem.
Social media archives
In order to develop accurate historical assessments, researchers must have access to primary materials that represent a large and diverse set of participants. Social media platforms have become a venue where serious discourse and creation take place, but much of this critical and ephemeral content is lost to researchers as few institutions collect and preserve this content. In 2014, the NCSU Libraries was awarded an EZ Innovation Grant (2014-2015 LSTA Grant Programs … [updated 2014]) from the State Library of North Carolina (State Library of North Carolina … [updated 2015]) to develop a freely available web-based Social Media Archives Toolkit (Social Media Archives Toolkit … [updated 2015]) that publicly documents our own effort to develop a sophisticated social media archival program in a way that may help guide cultural heritage organizations that are interested in collecting and curating social media content.
As a part of this grant, NCSU Libraries conducted a survey of North Carolina cultural heritage organizations about the promise of social media data inclusion in archival collections. Among the responses was this discussion of the tension between interest and ability:
“Along with email, social media will probably provide the main source of information for researchers studying our current time. However, our institution just does not have the resources right now to collect and store the social media of other people or organizations.” (Social Media Archives Toolkit … [updated 2015])
This confirms our own anecdotal evidence from presentation questions and conference presentations: most institutions simply don’t have access to the resources necessary to pilot new initiatives with technical prerequisites. This is especially true for those cultural heritage organizations who could contribute the most to conversations addressing archival practices for social media community documentation, such as public libraries, historical societies, and community colleges.
The Future of Libraries
“I believe that building and maintaining library software is vitally important work and it’s too big a job to leave to a small group of people. We are creating the future of libraries here.” From “Creating a Commons.” (Sadler, 2013)
Library open source software has improved technical collaboration and sharing among large institutions, but it retains problems of obligatory collaboration by requiring a relatively costly common environment and skill set. The goals of library open source, if viewed through the lens of journal publications, conference presentations, project users, and project contributors, must be seen as more closely aligned to collaborative software development rather than representative project development. Unfortunately, since most developers are employed by institutions with the resources to foster specialized human resources, when developers vote with their code many categories of users may not be reflected in the development of the project. Community members who would help address many other types of users (serving many other types of institutional users) never have the opportunity to participate.
Library technology should be able to thrive in diverse organizational and technological environments. Within the library community, technical settings vary wildly. For example, the 2011-2012 ALA Public Library Funding & Technology Access Study showed that 88 percent of public libraries depend on “non-IT specialists” for their IT support services, with 59.5% of rural public libraries depending on their library director for IT support (American Library Association, 2012). We will never reach the bulk of our colleagues and users without dramatically reducing the cost of supporting individual software projects. In order to build more representative software communities, we need to ask more of the software that we produce. We need software that is conscientious.
“Our software is like children. … We expect that after a time the child will mature, will grow up, will be able to take care of itself, to solve problems, to cope, and perhaps to contribute something new. Initially selfish—for what other options are there?—the child becomes responsible. With luck or persistence or as the result of good upbringing, the child may become conscientious. Shall we hope similarly for our software?” (Gabriel and Goldman, 2006)
In the context of this challenging view of software as an entity that exists on some sort of maturation curve, open source software is not grown-up software. This software has left the house and begun to develop its own life outside of our influence, but it has not yet learned how to seek and maintain an environment in which it can thrive. It has a narrow, provincial view of the world which still must be expanded. This software is not yet fully realized in its role of providing utility to a large and diverse community. It is open but not available.
Software Availability
Our goal now is to find methods for measuring the maturity, or availability, of our software as well as techniques for improving those measures. Gabriel and Goldman provide some suggestions, some of which fall into the realm of technical speculation, and some of which are difficult to evaluate. We need a way to quickly and consistently identify gaps in the availability of our software and to measure improvement after changes are made. Most importantly, we need an evaluation tool that exclusively measures the ability to implement and use software. In other words, software does not need to be open source, easy to modify, or even free to be considered highly available to targeted user communities. These performance indicators must specifically target the goal of wide software adoption across all potential user groups.
Stopwatch technology availability performance indicators
We have developed an initial set of task performance indicators to measure software availability for a given user group, derived from the common practice in user experience design of developing Key Performance Indicators for tracking and evaluating progress toward strategic organizational goals (5 UX KPIs [accessed 2016]). By focusing on task performance rather than specific techniques such as documentation, we are attempting to provide indicators that are easy to measure, compare, and communicate for a wide variety of projects. These indicators are:
- Time to pilot on a laptop. Defined as the time needed to install and configure, at minimum, a demonstration instance of the application, particularly for use in organizational evaluation of software.
- Time to export data. Defined as the time needed to export unique data captured in the application, e.g. social media metadata and space assessment data.
- Time to update dependencies. Defined as the time needed to update the dependencies on which an application is built, e.g. Ruby on Rails gems.
- Time to upgrade application. Defined as the time needed to update the application itself, e.g. version updates, bug fixes, and database migrations.
- Time to migrate application. Defined as the time needed to transfer application to a new server environment, i.e. application portability.
- Time to new production deployment. Defined as the time needed to create a robust production instance of the application.
- Time to reasonable security. Defined as the time needed to secure the application relative to the sensitivity of the data being stored. This should consider the security policies of the adopting institution.
Guidelines
It’s important to follow a small set of guidelines when using these performance indicators in order to ensure that these measures are as consistent and reliable as possible. For each set of performance indicators, a targeted user group and rate of success should be defined before measurement. This will allow us to easily compare results across projects and to chart these results to measure the continual maturation of a particular project.
- Use the same user group within each set of performance indicators
- Use the same success rate within each set of performance indicators
- Assess all performance indicators in the set
Examples of measure definitions:
- Time to pilot for subject liaison librarians with 90% success, i.e. 9 out of 10 subject liaison librarians were able to pilot the application within the time listed.
- Time to pilot for assessment librarians with 50% success
- Time to pilot for systems administrators with 80% success
We can now not only identify gaps in the availability of our software to specific user communities, but begin to search for tools and techniques that can be applied to mitigate these issues.
Applying stopwatch technology availability performance indicators
Several approaches exist for improving the ease with which software projects can be adopted by users including usable documentation, packaged installers like those offered by WordPress (Installing WordPress … [accessed 2015]), vendor specific deployment scripts from companies like Google (Google Cloud Computing [accessed 2015]), Microsoft (Microsoft Azure [accessed 2015]), Amazon (AWS [accessed 2015]), and Heroku (Creating … [accessed 2015]), and hosted and managed services like Duracloud (Duracloud [accessed 2015]) and DSpace Direct (DSpace Direct [accessed 2015]). Another approach, and the one we have been exploring with our own software projects, is to take advantage of virtualization tools like Vagrant and Docker.
Vagrant (Vagrant [accessed 2015]) is a tool for building development environments by provisioning systems inside a variety of virtualization platforms like VirtualBox, VMWare, and others, providing developers with isolated, disposable, and consistent environments. Vagrant is easily installed on various operating systems including Linux, Windows, and OS X using a packaged installer. Applications are then provisioned using Vagrantfiles provided by the application maintainers. As of version 1.8, Vagrant will even install VirtualBox automatically to create a simpler initial provisioning process. With Vagrant, developers can be more confident that their code is running in the same environment as their team members, improving the reliability of code and easing the transition from development environments to staging and production environments. Vagrant also simplifies operations by providing a disposable environment and consistent workflow for developing and testing infrastructure management scripts.
Docker (Docker [accessed 2015]) is an open platform for building, shipping, and running distributed applications. It provides a common toolbox to take advantage of the distributed and networked nature of modern applications and enables the packaging of an application with all of its dependencies into a standardized unit for software development called a container. Containers have similar resource isolation and allocation benefits as virtual machines but a different architecture. Containers share the kernel with other containers, resulting in improved performance over virtual machines. Unlike virtual machines, which include the application plus the necessary binaries, libraries and the entire guest operating system, containers run as an isolated process in user space on the host operating system. They’re also not tied to any specific infrastructure; Docker containers can run on any computer, on any infrastructure, on any cloud.
Vagrant and Docker may be used together and often are. Vagrant supports Docker both as a provisioner and as a provider, meaning that Docker containers may be mounted to a guest virtual environment or directly to the host environment(Lowe 2015.) What this means is that end users of applications don’t need to be familiar with Docker at all in order to take advantage of it’s features since Vagrant can be configured by the application maintainer to automatically manage the provisioning of Docker containers. At the same time, these Docker containers can also be used for production deployments to hosting providers and in-house servers. Vagrant and Docker have become popular tools for simplifying the process of creating and maintaining software environments. John Fink wrote in 2014 that “For software development, when programmers check their code into git, a Dockerfile could be included in the source code, allowing for quick testing of code on remote servers or as a demonstration tool to let other quickly bring up their own version of an application without having to worry about specific building instructions or dependency management” (Fink 2014). Furthermore, these tools can also help reduce the costs associated with software adoption and create mutual benefit for both project maintainers and adopters.
As we have continued to develop and support open source software projects and communities, we have found that many cultural heritage organizations that might benefit from adopting our software were simply unable to do so based on budgetary constraints, staffing, or other institutional hurdles. We believe that integrating tools like Vagrant and Docker into our projects will not only improve internal development practices, but help lower the barrier to adopting our software and increase our score against our proposed stopwatch technology availability performance indicators. What follows are two case studies of our own open source software projects that demonstrate how these performance indicators might be used to evaluate the availability of library software projects.
Note:We are using estimates based on prior system support and user discussions and not on formal user testing. These performance indicators are most helpful as tools for identifying gaps in the software adoption process and are not meant as performance profiling tools.
Case study: Suma-Vagrant
Suma-Vagrant (Suma-Vagrant [accessed 2015]) is an experimental demonstration and development environment that utilizes Vagrant, VirtualBox and Ansible (Ansible [accessed 2015]) to create a reproducible, isolated virtual environment for Suma. Developers working with Suma-Vagrant can be more certain that code they develop will be compatible with the large collection of dependencies and libraries used in the Suma application. The Suma-Vagrant environment has allowed us to more easily test against consistent test data, explore integration with third party tools like Tableau Desktop, and on-board new developers to the project. Suma-Vagrant has also simplified the installation and configuration of Suma for less-technical users. Some of the installation issues (Figure 1) users have encountered when trying to install Suma at their home institutions include configuration file errors, environment issues, and database access. These issues are not only costly for us to support, but also impede the ability of potential users to evaluate Suma and to argue for its adoption at their institutions. Using Suma-Vagrant, users can quickly create a working, fully functional Suma environment in only four steps (Figure 2). Evaluating Suma (Figure 3) and Suma-Vagrant (Figure 4) against our stopwatch technology availability performance indicators shows that Suma-Vagrant greatly reduces the time and expertise required to install and configure a working demonstration and development environment for Suma, making the benefits and use cases of Suma easier to explore.
- mod_rewrite disabled
- cURL missing
- configuration errors
- symlink problems
- server hardening software
- db access
- installation method confusion
Figure 1. Selected List of Suma Install Issues
- Install Vagrant
- Clone or download the Suma-Vagrant repository on GitHub.
- Execute “vagrant up” from within the project directory using a terminal
- Visit http://localhost:19679 in a web browser on the host machine.
Figure 2. Suma-Vagrant Installation Steps
- Time to pilot on a laptop: days
- Time to export data: 4 hours
- Time to update dependencies: 4 hours
- Time to upgrade application: 1 hour
- Time to migrate application: unknown
- Time to new production deployment: days, if at all
- Time to reasonable security: unknown
Figure 3. Suma evaluation: Assessment Librarians at 80% success
- Time to pilot on a laptop: 40 minutes
- Time to export data: 10 minutes
- Time to update dependencies: 2 minutes
- Time to upgrade application: 2 minutes
- Time to migrate application: 20 minutes
- Time to new production deployment: under development
- Time to reasonable security: 10 minutes (pilot), under development
(production)
Figure 4. Suma-Vagrant evaluation: Assessment Librarians at 80% success
Case study: Social media combine
As part of the EZ Innovation grant from the State Library of North Carolina, the NCSU Libraries developed The Social Media Combine (Social Media Combine … [updated 2015]), a pre-configured collection of tools including Social Feed Manager (Social Feed Manager … [updated 2015]) and lentil (lentil .. [updated 2015]) for easily building Twitter and Instagram social media archives on your own computer. It pre-assembles lentil for Instagram data harvesting and Social Feed Manager for Twitter data harvesting, along with the web servers and databases needed for their use into a single package that can be deployed to desktop and laptop computers using Windows, OS X, or Linux.
Applying our “stopwatch technology performance indicators” to lentil before (Figure 5) and after (Figure 6) integration shows tasks that might take days for a standard installation take only minutes as part of the Social Media Combine. Potential users are not required to be familiar with application frameworks, server environments, or even the different programming languages used for the project (Figure 7). Once the Social Media Combine environment is installed, users are presented with an intuitive web configuration tool for managing the configuration of the system (Figure 8). The integration of lentil and Social Feed Manager into a single application that can be run on everyday hardware with usable web-based configuration makes the adoption of these archival tools much more viable for under resourced institutions.
- Time to pilot on a laptop: days
- Time to export data: automatic
- Time to update dependencies: 4 hours
- Time to upgrade application: 1 hour
- Time to migrate application: unknown
- Time to new production deployment: days, if at all
- Time to reasonable security: unknown
Figure 5. lentil evaluation: Archivists at 80% success
- Time to pilot on a laptop: 30 minutes
- Time to export data: automatic (lentil), variable (SFM)
- Time to update dependencies: 2 mins
- Time to upgrade application: 5 mins
- Time to migrate application: 20 minutes (under documented)
- Time to new production deployment: under development
- Time to reasonable security: 10 minutes (pilot), under development (production)
Figure 6. Social Media Combine (lentil + Social Feed Manager + Configuration) evaluation: Archivists at 80% success
- Install Git and Vagrant
- Clone or download the Social Media Combine repository on GitHub.
- Execute “vagrant up” from within the project directory using a terminal
- Enter configuration parameters in the web configuration form and click OK
- Visit Lentil: http://localhost:3001,
Social Feed Manager: http://localhost:8001,
or the Configuration tool: http://localhost:8081
Figure 7. Social Media Combine Installation Steps
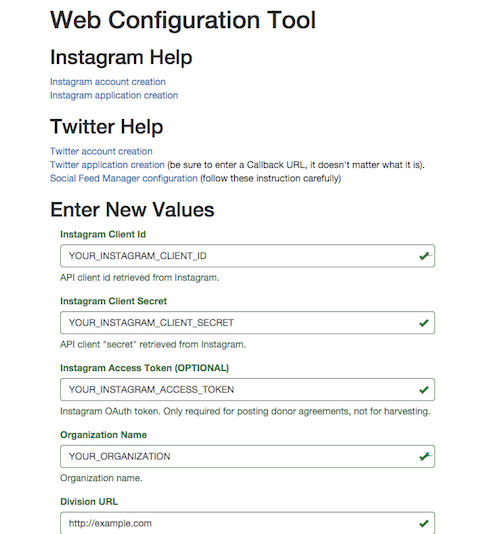
Figure 8. Screenshot of web configuration tool (attached)
Conclusion
By applying our stopwatch technology availability performance indicators to our own software projects, we have shown how approaches that help local practices and deployments, like consistent, repeatable virtual environments, can also be used to improve the availability of library technology. Holding ourselves accountable in this way is like testing; it’s good for you, it’s something you should be doing anyway, and will have a positive and significant impact on the total quality and usefulness of library software. These performance indicators might help us think more holistically about our software projects, focusing less on simply releasing code and more on what is required for users to actually adopt and use our software, especially when those users are under resourced. Open Source itself is not sufficient for distributing innovative library software. But, by taking the best parts of emerging devops tools and integrating them with the natural library mission of supporting the diffusion of innovation, perhaps we can ensure that institutions who might benefit from our software can install and apply it to their own needs.
We believe privileged institutions have a professional responsibility to support the adoption of their innovations. Our community has fulfilled the promise of free and open source software inasmuch as we have made our code freely available, created vibrant cross-institutional developer communities, and improved the level of service to our direct constituencies through truly innovative software. But, we have failed to fulfill the promise of promoting the diffusion of innovation in library technology to those smaller, less resourced institutions and their users. Genuine software availability should not be defined only as open source releases of freely available software in a code repository, but as a fully considered commitment to ensuring that software can be adopted by those institutions that stand to benefit the most from our collaborative efforts and, in turn, that our projects benefit from the participation of more representative communities across the spectrum of cultural heritage institutions.
References
5 UX KPIs You Need to Track. [accessed 2016 Jan 4]. http://designmodo.com/ux-kpi/
2014-2015 LSTA Grant Programs. [accessed 2015 Dec 6]. http://statelibrary.ncdcr.gov/ld/grants/lsta/2014-2015Grants.html
Ansible. [accessed 2015 Dec 6]. http://www.ansible.com/
AWS Marketplace Applications Now Available With 1-Click Deployment In Sydney.
[accessed 2015 Dec 6]. //http://aws.amazon.com/about-aws/whats-new/2013/04/24/aws-marketplace-applications-now-available-with-1-click-deployment-in-sydney/
Brown K, Adler SM, Irvine RL, Resnikoff DA, Simmons I, Tierney JJ. UNITED
STATES’ MEMORANDUM ON THE 1969 CASE. Washington, DC, USA; 1995.
Campbell-Kelly M, Garcia-Swartz DD. Pragmatism, not ideology: Historical perspectives on IBM’s adoption of open-source software. 2009;21(3):229–244.
Chudnov D. Open Source Library Systems: Getting Started | oss4lib. 1999 Feb 1
[accessed 2015 Jan 20]. http://www.oss4lib.org/readings/oss4lib-getting-started.php
Creating a “Deploy to Heroku” Button. [accessed 2015 Dec 6]. https://devcenter.heroku.com/articles/heroku-button
Docker. [accessed 2015 Dec 6]. http://www.docker.com/
DSpaceDirect. [accessed 2015 Dec 6]. http://dspacedirect.org/
DuraCloud. [accessed 2015 Dec 6]. http://www.duracloud.org/
Fink J. Docker: a Software as a Service, Operating System-Level Virtualization
Framework. 2014 [accessed 2015 Dec 6];(25). http://journal.code4lib.org/articles/9669
Gabriel RP, Goldman R. Conscientious Software. In: Proceedings of the 21st
Annual ACM SIGPLAN Conference on Object-oriented Programming Systems, Languages,
and Applications. New York, NY, USA: ACM; 2006 [accessed 2015 Jan 4]. p.
433–450. (OOPSLA ’06).
Gates B. An Open Letter to Hobbyists. 1976 [accessed 2015 Dec 6];2(1). https://commons.wikimedia.org/wiki/File:Bill_Gates_Letter_to_Hobbyists.jpg
Google Cloud Computing. [accessed 2015 Dec 6]. https://cloud.google.com/
History of the OSI | Open Source Initiative. [accessed 2015 Dec 6]. http://opensource.org/history
Hoffman J, Bertot JC, Davis DM. Libraries Connect Communities: Public Library
Funding & Technology Access Study 2011-2012. Digital supplement of American
Libraries magazine. American Library Association; 2012 [accessed 2015 Dec 6]. http://www.ala.org/research/plftas/2011_2012#final
report
Installing WordPress. [accessed 2015 Dec 6]. https://codex.wordpress.org/Installing_WordPress#Famous_5-Minute_Install
lentil. [accessed 2015 Dec 6]. https://github.com/NCSU-Libraries/lentil
Lowe S. Using Docker with Vagrant. [accessed 2015 Dec 6]. http://blog.scottlowe.org/2015/02/10/using-docker-with-vagrant/
Microsoft Azure. [accessed 2015 Dec 6]. https://azure.microsoft.com/en-us/
Philipson G. A short history of software. In: Barrett R, editor. Management,
Labour Process and Software Development: Reality Bites. 2004. p. 13.
Rochkind J, Editor C, Editorial Introduction — Issue 1. 2007 [accessed 2015
Dec 6];(1). http://journal.code4lib.org/articles/39
Sadler B. Creating a Commons. 2013 [accessed 2015 Dec 6]. http://www.ibiblio.org/bess/?p=302
Schindler E. An Abbreviated History of ACP, One of the Oldest Open Source Applications | ITworld. 2009 Aug 20 [accessed 2015 Jan 12]. http://www.itworld.com/article/2767585/open-source-tools/an-abbreviated-history-of-acp–one-of-the-oldest-open-source-applications.html
Social Feed Manager. [accessed 2015 Dec 6]. https://github.com/gwu-libraries/social-feed-manager
Social Media Archives Toolkit. [accessed 2015 Dec 6]. http://www.lib.ncsu.edu/social-media-archives-toolkit
Social Media Combine. [accessed 2015 Dec 6]. https://github.com/NCSU-Libraries/Social-Media-Combine
Stallman R. The GNU Manifesto. 1985 [accessed 2015 Dec 6]. http://www.gnu.org/gnu/manifesto.en.html
Stallman R. Why Open Source misses the point of Free Software. 2015 [accessed
2015 Dec 6]. http://www.gnu.org/philosophy/open-source-misses-the-point.en.html
State Library of North Carolina. [accessed 2015 Dec 6]. http://statelibrary.ncdcr.gov/index.html
Suma. [accessed 2015 Dec 6]. https://www.lib.ncsu.edu/reports/suma
Suma-Vagrant. [accessed 2015 Dec 6]. https://github.com/NCSU-Libraries/Suma-Vagrant
Vagrant. [accessed 2015 Dec 6]. https://www.vagrantup.com/about.html
Appendix A: Social Media Combine Sample Code
Social Media Combine Vagrant
file: https://github.com/NCSU-Libraries/Social-Media-Combine/blob/master/Vagrantfile
Social Media Combine Docker file: https://github.com/NCSU-Libraries/Social-Media-Combine/blob/master/docker-compose.yml
Appendix B: Suma-Vagrant Sample Code
Suma-Vagrant Vagrantfile: https://github.com/NCSU-Libraries/Suma-Vagrant/blob/master/Vagrantfile
Suma-Vagrant Ansible:https://github.com/NCSU-Libraries/Suma-Vagrant/blob/master/ansible_tasks/roles/demo/tasks/suma.yml
About the Authors
Bret Davidson is a Digital Technologies Development Librarian at North Carolina State University where he works to advance library services through applied research and application development. He provides technical leadership for the open-source space and service assessment toolkit “Suma” and contributes to a broad portfolio of library applications. Previously, he was an NCSU Libraries Fellow, a public school music educator, and a performing musician with the River City Brass Band in Pittsburgh, PA.
Jason Casden is the Interim Associate Head for the Digital Library Initiatives department at the North Carolina State University Libraries. Jason has served as a project or technical lead for several projects designed to help the NCSU and wider library communities interact with library resources, services, and spaces in new ways. These include the “My #HuntLibrary” community-driven photographic student documentation project and the supporting open source “Lentil” Instagram harvesting platform, the “Suma” space and services assessment system, and the “Social Media Combine” social media harvesting environment that pre-assembles social media data harvesting software into a single installable package.

{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply