by Ruth Kitchin Tillman
Introduction
This article documents a project undertaken to augment metadata within the NASA Goddard Library Repository.[1] The repository runs on a custom Fedora 3.3/Drupal 7 setup. It contains five collections spotlighting aspects of work produced by the Goddard Space Flight Center—Authors & Publications, Case Studies, Colloquia, Balloon Technology Documents, and the Goddard News.
The Fedora objects for each collection consist of metadata recorded in an appropriate language indexed in Fedora’s XML-based gSearch; a simple Dublin Core file indexed by both gSearch and Fedora’s RISearch [2]; a RELS-EXT file (Fedora’s RDF/XML language, used to create links between Fedora objects) indexed in RISearch; and PDFs or externally-hosted video files, depending on the collection. Fedora versions 1 to 3 use Permanent IDentifiers (PIDs) to identify objects. PIDs consist of a colon-separated prefix and suffix. The prefix may be used across a repository or vary based on collection within the repository. When combined with the suffix, it forms a unique object identifier.
This article focuses on two of the collections, Authors & Publications and Colloquia. The first documents the publication output of authors affiliated with NASA Goddard. It consists of two types of Fedora object, author objects and publication objects. Author objects include local MADS [3] authority records for each Goddard author. Publication objects use NISO JATS [4] to record article, book chapter, technical report, or book metadata. The second collection, Colloquia, documents the colloquia presented at NASA Goddard by scientists from around the world as well as local Goddard speakers. Its metadata is recorded in the Goddard Encoding Metadata Schema (GEMS), an extended version of Dublin Core. The Goddard repository uses different PID prefixes for each type of object, which will be referenced in code samples as authorPID, publicationPID, and colloquiaPID.
Historically, the two collections have remained separate. Because Authors & Publications collects publications by authors who have an affiliation at the time of publication, each publication must connect to at least one author object. This relationship is a core component of the collection. The collection is in the process of being back-dated to 2000, but will not extend earlier because of the challenges in gathering reliable author metadata from over 15 years ago.
In the Colloquia collection, on the other hand, only 710 of the over-5000 records (around 14%) have a Goddard presenter. Moreover, the collection includes metadata records for library-held colloquia recordings as far back as the 1970s, although digitized copies of older recordings are not yet available on the website. Because of the timespan of the collection and the high percentage of non-Goddard presenters, connecting presenters in the Colloquia collection to the Author records from the Authors & Publications collection was not considered suitable at the time. Instead, the Colloquia GEMS records include a speaker’s name and institutional affiliation. If the author is from Goddard, their organizational code is recorded as well. These fields may be used in searching the colloquia or in cross-site search, but there is no formal relation to an author’s Fedora object record or publications. Author names are taken from colloquia materials and not transformed into controlled forms (i.e. “Dave” vs. “David” or “Chip” vs. “Charles”).
When considering augmentations to the repository in preparation for its eventual upgrade to Fedora 4, I began exploring the possibility of reconciling these two collections for a more unified repository experience. This article outlines my step-by-step process, with scripts and screenshots, for extracting metadata from the Authors & Publications collection, transforming it into an RDF reconciliation service for OpenRefine, extracting appropriate Colloquia metadata from Fedora, using that OpenRefine service to augment the Colloquia metadata, and re-ingesting the augmented data back into Fedora. Because of the project’s timing, I explored methods for re-ingesting the augmented metadata in both Fedora 3 and Fedora 4 for comparative purposes.
Project Goal
The author and publication records are connected using Fedora 3’s built-in RDF/XML language, RELS-EXT. A publication would include the statement
<rel:isPartOf rdf:resource="authorPID"/>
for each Goddard author. In the Fedora 4 model for this collection, the relationship will be documented in the publication object itself (vs. an attached file) with the RDF Property dc:creator linking to the author’s Fedora object. At the end of this reconciliation project, I needed to have related colloquiaPID and authorPIDs in a format which could be used to update colloquia records with either an appropriate RELS-EXT statement or a dc:creator statement. I also needed to solve any complications in re-ingesting the augmented metadata.
Phase 1. Creating a Local Reconciliation Service
For the metadata reconciliation process, I chose to work in OpenRefine[5][6], a popular data manipulation and transformation tool. I added the RDF Refine plugin from DERI[7] (these services have also been combined to form LODRefine, but as I worked from OpenRefine with the plugin installation, that’s how I’ll discuss it), which allows one to both export OpenRefine projects as linked data and to use linked data services alongside other reconciliation services. Unlike cases where one might be drawing from established name authority services, I had to create my own service based on the Goddard authors and their URIs (PIDs). One can do this with the RDF Refine plugin, adding a reconciliation service from a file, whether locally-generated or downloaded from a major authorities site. I just needed to generate my own RDF file with author information. While many RDF vocabularies could have been used to describe authors, I chose the Friend of a Friend[8], or “foaf” schema because it’s one of the defaults in RDF Refine and all I needed was something to handle names. My choice of vocabulary would affect the process but not the end result.
First, I needed the names and object PIDs for all Goddard authors. I exported these through the RISearch interface by running a query against the brief Dublin Core files for author records. The resulting data set was a CSV. A sample excerpt:
"Atlas, David",authorPID:823462024 "Tilton, James C.",authorPID:411735411 "Esaias, Wayne E.",authorPID:868841903 "Lyon, Richard G.",authorPID:982601626 "Schnase, John L.",authorPID:580647414 "Esper, Jaime",authorPID:564921526
I considered importing the CSV into OpenRefine and using the RDF Refine plugin’s option to export data as an RDF skeleton[9], but soon realized I could create an RDF file more quickly using regular expressions. Additionally, I wanted to offer alternative names depending on whether or not the author used a middle initial, since colloquia metadata was never standardized to use the official form of the author’s name. Manipulating names could be done in Open Refine, but could also easily be done with regular expressions as a part of creating the RDF file.
In Sublime Text 2[10], the program I used for all non-OpenRefine data manipulation during this process, I searched for the following regular expression:
("(.+?),(\sDr.\s|\s{2}|\s))(.+?)(\s(\w\.)"|"|"),authorPID:(\d{9})
and replaced it with:
<http://gsfcir.gsfc.nasa.gov/authors/id/\7> a foaf:Person;\n foaf:name "\2, \4", "\2, \4 \6".\n\n
The initial search captures a surname, matches a comma, captures any initial “Dr.,” captures the first name that follows and any middle initial if it exists, and captures the unique suffix of the PID. The second query returns a URL to the author’s page (URLs derive from PID suffixes[11]), an RDF type statement that the entity belongs to the class foaf:Person, a line break, two forms of the author’s name, and two more line breaks to keep objects neatly separated. I then ran a second find for
foaf:name "(.+?)", "\1 ".
and replacement
foaf:name "\1".
to account for cases in which the author’s middle initial wasn’t recorded, leading to duplicate names.
A snippet from the result:
<http://gsfcir.gsfc.nasa.gov/authors/id/823462024> a foaf:Person; foaf:name "Atlas, David". <http://gsfcir.gsfc.nasa.gov/authors/id/411735411> a foaf:Person; foaf:name "Tilton, James", "Tilton, James C.". <http://gsfcir.gsfc.nasa.gov/authors/id/868841903> a foaf:Person; foaf:name "Esaias, Wayne", "Esaias, Wayne E.".
I then added the appropriate prefix declarations:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix foaf: <http://xmlns.com/foaf/0.1/> .
to the top of the file and saved it as an RDF/Turtle .ttl file. The author URLs were used instead of PIDs because, when reconciling, one may click on the link for a suggested match and preview the page. This functionality proved useful in cases where author names closely matched speaker names but there was some uncertainty. One could infer, for example, that a speaker primarily published on flight dynamics and trajectories would likely be giving a presentation about the interplanetary transport network.
To add the file-based reconciliation service, I selected RDF in the upper right hand corner of OpenRefine, chose to add a reconciliation service, and selected “Based on an RDF file.”
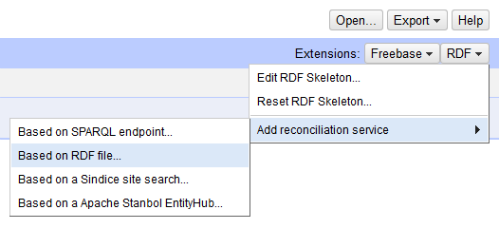
Figure 1. Adding a file-based reconciliation service
The process I used to upload the file and add the service is quite simple, as shown below. Note that RDF Refine includes built-in support for rdfs:label, skos:prefLabel, dcterms:title, dc:title, and foaf:name. Choosing the “Other” box allows one to add other vocabularies if desired.
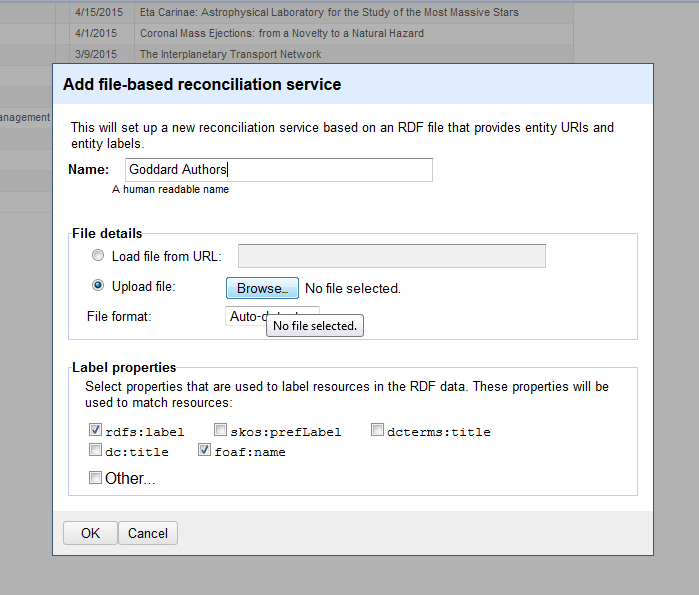
Figure 2. Defining a file-based reconciliation service (enlarge)
The service is now installed and ready to reconcile against any data which includes a column of Goddard author names.
Phase 2. Extracting Metadata to Reconcile
After the reconciliation service had been created and installed, the next step in the process was to extract appropriate metadata from the colloquia collection. First, I had to determine what metadata would be needed to complete the reconciliation process. I settled on the following fields:
colloquiaPID, speaker name, date, title
The only two fields actually needed to update records would be the colloquiaPID and the speaker’s authorPID, which I would be extracting based on the speaker’s name during the reconciliation process. However, the date and title seemed useful for settling edge cases without having to look up the individual colloquia. A colloquia’s PID gives no indication of the actual topic and no date context. As mentioned above, the author reconciliation service would link to a page with the author’s primary topical field. On a low-confidence match that seemed entirely outside the author’s field, it would be safer to discard the data. Similarly, if the colloquia were delivered in the 1980s and had a low-confidence match to an author who had only joined NASA in the 2000s, that possible match should be discarded.
To get this data, I would need to process information based on each speaker in a colloquia, not each colloquia record. I began by extracting colloquia records from Fedora using its gSearch output. Since the GEMS
<?xml version="1.0" encoding="UTF-8"?>
<resultPage xmlns:zs="http://www.loc.gov/zing/srw/" xmlns:foxml="info:fedora/fedora-system:def/foxml#" xmlns:dc="http://purl.org/dc/elements/1.1/">
<gfindObjects hitPageLast="6" hitPageEnd="200" hitPageStart="101" hitPageSize="100" hitTotal="591">
<objects>
<object score="73.88713" no="11">
<field name="PID">colloquiaPID:3827</field>
<field name="abstract">The Solar Dynamics Observatory (SDO) SDO launched on February 11, 2010, 10:23 am EST on an Atlas V from SLC 41 at Cape Canaveral. SDO's main goal is to understand the solar variations that influence life on Earth and humanity's technological systems. These variations are caused by the solar magnetic field. The SDO science investigations will determine how the Sun's magnetic field is generated and structured, how this stored magnetic energy is released into the heliosphere as the solar wind, ... </field>
<field name="accessRights">public</field>
<field name="affiliation">NASA/|!GSFC!|</field>
<field name="affiliation">NASA/|!GSFC!|</field>
<field name="browse">s</field>
<field name="callNumber">2011-0404 (ENG)</field>
<field name="code">671.0</field>
<field name="code">671.0</field>
<field name="date">2011</field>
<field name="dc.creator">Pesnell, W. Dean</field>
<field name="dc.creator">Chamberlin, Phillip</field>
<field name="dc.date">2011-04-04</field>
<field name="dc.format">dvd</field>
<field name="dc.format">webcast</field>
<field name="dc.identifier">2011-0404 (ENG)</field>
<field name="dc.identifier">colloquiaPID:3827</field>
<field name="dc.title">The solar dynamics observatory: your eye on the sun</field>
<field name="dc.type">video</field>
<field name="fgs.createdDate">2011-05-13T12:14:09.102Z</field>
<field name="fgs.label">colloquiaPID:3827</field>
<field name="fgs.lastModifiedDate">2012-11-01T14:47:05.745Z</field>
<field name="fgs.ownerId">fedoraAdmin</field>
<field name="fgs.state">Active</field>
<field name="isMemberOfCollection">|!!|collection:3</field>
<field name="mediachk">TRUE</field>
<field name="presentationDate">2011-04-04</field>
<field name="resourceType">video</field>
<field name="series">Engineering Colloquium</field>
</object>
</objects>
</gfindObjects>
</resultPage>
Using the following XSLT, I cross-walked the object results into a CSV in which each row contained the fields listed above. The XSLT matches an object’s dc:creator field, steps back one level in the XML tree to the object, and extracts the PID, dc:title, and dc:date to go along with that dc:creator. It applies to each dc:creator within an object, creating multiple rows as needed so each speaker will be in an individual row.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://www.openarchives.org/OAI/2.0/"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:zs="http://www.loc.gov/zing/srw/" xmlns:foxml="info:fedora/fedora-system:def/foxml#" xmlns:dc="http://purl.org/dc/elements/1.1/"
exclude-result-prefixes="xs foxml zs xsi"
version="2.0">
<xsl:output method="text" indent="no" media-type="string" />
<xsl:strip-space elements="*"/>
<xsl:template match="/resultPage/gfindObjects/objects">
<xsl:apply-templates select="object"/>
</xsl:template>
<xsl:template match="object">
<xsl:apply-templates select="field[@name='dc.creator']"/>
</xsl:template>
<xsl:template match="field[@name='dc.creator']">
<xsl:text>"</xsl:text><xsl:value-of select="../field[@name='PID']"/><xsl:text>","</xsl:text><xsl:value-of select="."/><xsl:text>","</xsl:text><xsl:value-of select="../field[@name='dc.date']"/><xsl:text>","</xsl:text><xsl:value-of select="../field[@name='dc.title']"/><xsl:text>"</xsl:text><xsl:call-template name="newline"/>
</xsl:template>
<xsl:template match="field">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="text()" />
<xsl:template name="newline">
<xsl:text>
</xsl:text>
</xsl:template>
</xsl:stylesheet>
A line from the resulting CSV:
"colloquiaPID:5088","McElwain, Michael","10/8/2014","See the Ball, Be the Ball: How to Find and Characterize Planets Beyond our Solar System"
I then ingested the resulting CSV into OpenRefine.
Phase 3. Reconciling Metadata in OpenRefine
Once I’d created and installed the local reconciliation service, derived the CSV of pertinent data, and ingested it into OpenRefine, I could begin the real work of reconciliation. Starting a reconciliation process in OpenRefine is fairly straightforward. From the column I wished to reconcile, Author, I selected the drop-down “Reconcile” and “Start reconciling.” This allowed me to choose from any services I’d already installed, but did not give me a chance to install a new service.
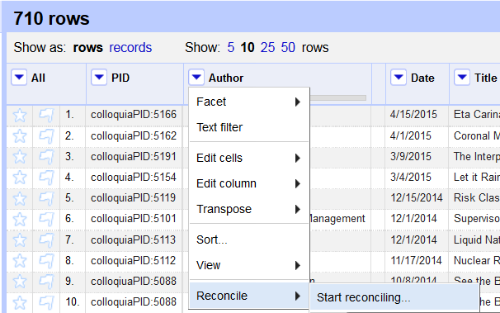
Figure 3. Selecting reconciliation from the column’s drop-down menu
Once I selected the service, OpenRefine spent several minutes parsing the service for the different types of data it contains so that it can offer options for reconciliation. From doing this several times, I discovered that, even if a file-based service has been installed and used already, it will need to re-parse each time.
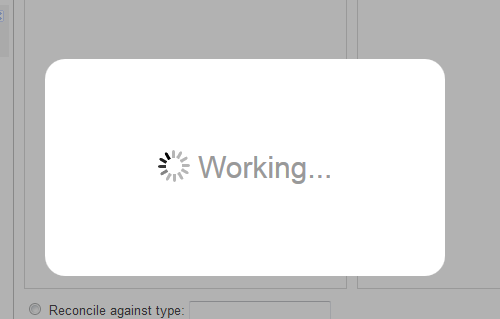
Figure 4. OpenRefine must re-parse the reconciliation service
Once OpenRefine has figured out what options are available, it will offer to match against the different RDF classes found in the service. If I had made a file with both foaf:Person and foaf:Organization, for example, I could have chosen to reconcile only against foaf:Person for this project. Or I could have opted to “reconcile against no particular type” if I wanted to match against both (this is especially useful when a reconciliation service combines data from multiple sources which use different vocabularies to describe the same type of thing, e.g. foaf:Person and schema:Person). At this point one also chooses whether or not to automatically match when a high-confidence match exists. I experimented both ways and found that automatic matches required such a high degree of confidence that I felt I could trust them for this project.
It should be noted that the right-hand column with header “Also use relevant details from other columns” is not supported by the RDF Refine plugin and only works for other types of reconciliation services. My first version of the reconciliation service had included the organization code where a person worked in an attempt to improve matches, but without this working for RDF reconciliation, I was unable to add that level of confidence.
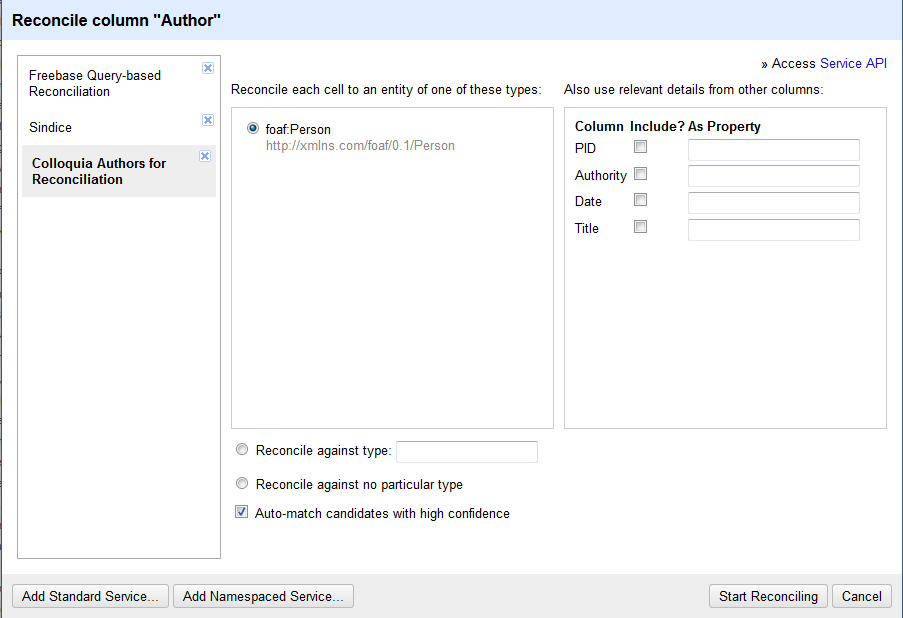
Figure 5. Select Class (or no particular type) against which to reconcile and whether to auto match (enlarge)
The following is an example of matches after I ran basic reconciliation. The green line at the top shows percentage of matches found. Each match immediately links the author’s name to their URI (in this case, their author page), see Figure 7. Clicking this link opened the author page as a pop-under within the service where I could confirm a match or evaluate several possible matches. If I wanted to see other possibilities for an automatic match or create a new topic, I could “choose a new match.”
In cases where the service did not find an automatic match, it lists several possible options with the match confidence, the closest form of the name, and the same link to the URI.
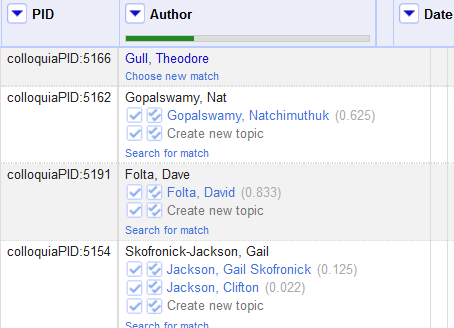
Figure 6. An example of initial match results
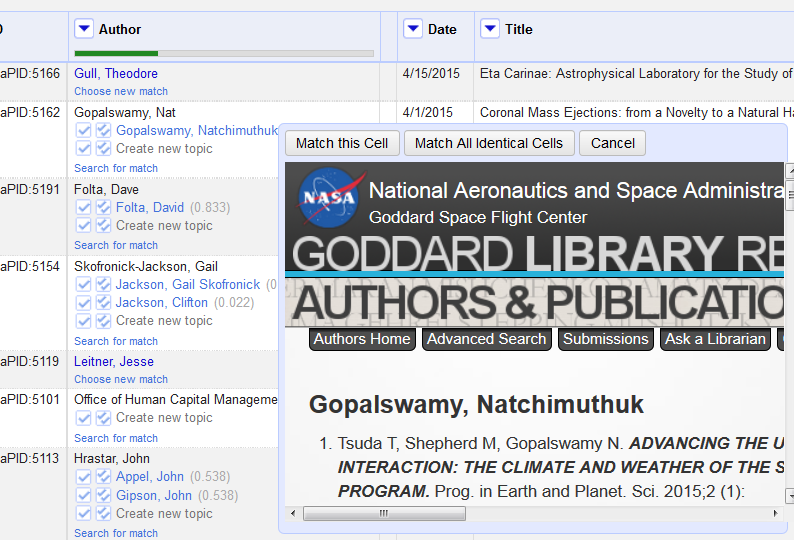
Figure 7. Clicking on an author link allows one to view the URI’s webpage and then opt whether to match this cell, all identical cells, or simply close the view (enlarge)
Initial reconciliation with auto-matching found 175 matches on the 710 names extracted from the collection. Because many authors were not caught by auto-match (see Figure 7 above for multiple authors who didn’t match as well as several for whom there were no matches), I performed individual review of the Author column. In most cases where a match existed, it was easy for me to confirm through personal experience with the author’s work or by seeing it was simply a different form of the name, e.g. Gail Skofronick-Jackson vs. Gail Skofronick Jackson. For around a dozen names, I had to open the author’s page and sometimes even perform brief local research on their publications. In total, I found another 110 matches for a total of 285 author matches. As for the rest, some authors had simply left Goddard, some had never published and were thus never in the Authors & Publications collection, some were mis-identified as affiliated with Goddard at all (the oldest metadata came from transcribed textual records which were occasionally too brief to ensure accuracy and I recognized certain errors from my institutional knowledge alone), and some were non-persons such as the “Office of Human Capital Management” visible in Figure 7.
Once the automatic and manual reconciliation was complete, I extracted the data from the names column into a new column. The reconciliation data is only available in OpenRefine as a part of the service and exporting the project into Excel or another other format would not include the data from the reconciliation process. First, I chose to “Edit Column” and “Add column based on this column…”
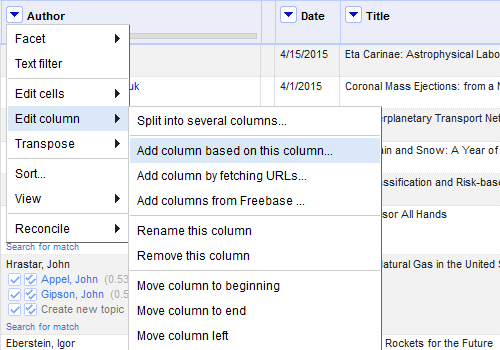
Figure 8. To extract data, start by adding a column based on the reconciled column
I then used the Google/General Refine Expression Language (GREL) expression
cell.recon.match.id
to select the URI/ID of the RDF subject to which the person was matched. The preview pane gives examples of what would be extracted for each row. I chose to leave the cell in the new column blank “on error” (if no reconciliation data existed).
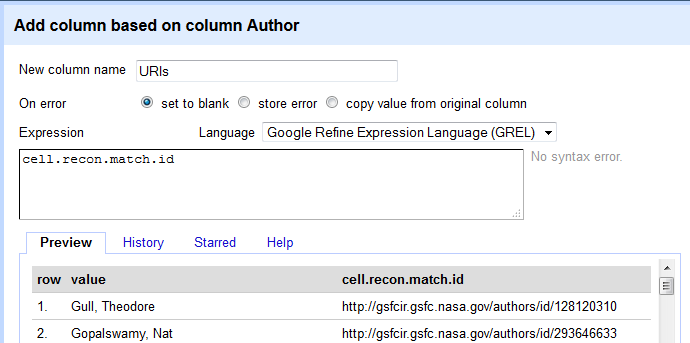
Figure 9. The object URI may be extracted with GREL expression cell.recon.match.id (enlarge)
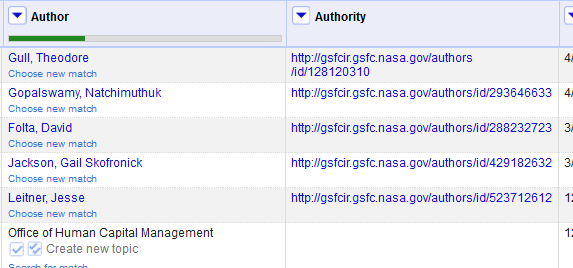
Figure 10. An example of extracted data (enlarge)
After extracting the data into a new column, I exported the project into Excel for simple manipulation and extraction. Since the authorPID (vs. author page URL) is necessary to create relationships in Fedora 3, I replaced the first part of the author URL with the prefix authorPID:. I then removed all columns but those containing colloquiaPID and authorPID and sorted the sheet based on values for authorPID so rows without a PID could be grouped and deleted. This file then became my master copy of the relationship data from which I would create update solutions for Fedora 3 and Fedora 4.
Phase 4. Updating Fedora 3 and 4
At this point in the process, I had a simple two-column sheet outlining relationships between colloquia objects and author objects. What remained was to transform these into a format which could be used to update Fedora. If a colloquia had multiple presenters who also had author objects, I would have to take that into account when performing updates. I also had to handle major structural differences between Fedora 3 and Fedora 4. The processes turned out to be significantly different, primarily due to Fedora 3’s requirements for updates.
Updating Fedora 3
Fedora 3 supports an XML language, Fedora Batch Modify,[12] which can be used to create or purge Fedora objects or to modify datastreams (XML files, images, PDFs, etc.) attached to a Fedora object. The difficulty? One must completely replace the datastream one is modifying. In this case, to add an author relationship to the RELS-EXT RDF/XML datastream for the colloquia object, one must recreate the entire datastream for that object.
At first, this challenge seemed insurmountable. Recreating the entire RELS-EXT added a degree of risk to the project that simply inserting an author relationship wouldn’t. But I decided to see just what recreating the information would entail. I began addressing the complication by asking three questions about the Colloquia collection’s RELS-EXT files:
- What is the same across all RELS-EXT files?
- What is different?
- What does the new information look like?
In the case of Colloquia files, the answers were:
- Same: Each has the relationship
- Different: Each colloquia is related to a particular subcollection using <rel:isMemberOf> <subcollection:N>. The subcollection indicates which division (Science, Engineering, etc.) sponsored the colloquia, therefore a colloquia may belong to multiple subcollections if it had multiple sponsors.
- New: Each colloquia being updated will have one or more relationships added to author records, the point of the project. To fit the Fedora 3 models currently in use for publications in Authors & Publications, this relationship will be defined as <rel:isPartOf> <authorPID:NNNNNNNNN>.
Based on this assessment, creating a replacement RELS-EXT would involve some standard relationships for every colloquia, the author reconciliation data, and the subcollection information for each colloquia that was being updated.
It was at this point that OpenRefine became very useful again. First, I queried Fedora’s Resource Index (again via RISearch) to extract subcollection data for all colloquia. I considered attempting only to extract data for the colloquia I was going to be updating, but soon realized that my process would allow me to easily sort out colloquia which did not need updating.
I combined the subcollection export with the author reconciliation data in the same sheet, ending with columns:
colloquiaPID subcollectionPID authorPID
and reordered based on the colloquiaPID column. The file included one line per relationship. A colloquia with one subcollection and three authors, for example, would have 4 separate lines. I imported this spreadsheet into OpenRefine where I began work on it. OpenRefine offers options for working on data on different lines that belongs to the same overall record. After import, an example colloquia looked like this:
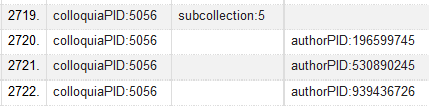
Figure 11. An example of colloquia information before blanking down
To have OpenRefine see all of these as one record, I had to remove the duplicate entries for the colloquiaPID. One does this by selecting the “blank down” option under “Edit cells” in the column’s drop-down menu. Functionally, Blank Down removes all duplicate data in the column that is both subsequent and adjacent. Imagined vertically, A A A will become A – – but A B A will remain the same. Blank Down works on any row, but for it to make OpenRefine view the objects as one record, the modified column must be the farthest left and it must be ordered so that all rows for a record are adjacent.
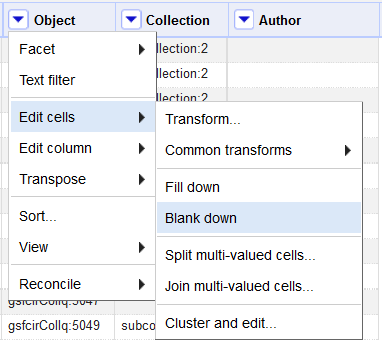
Figure 12. The Blank Down function
This is the result, once Blank Down is applied:

Figure 13. The same information, after OpenRefine’s Blank Down has been applied
Note the numbering change on the left-most column when compared to Figure 11 (OpenRefine’s row/record number). OpenRefine sees the group of rows as a single record and applies a single number. Now I could use OpenRefine’s functions for processing multi-valued cells. In this case, I need to join multi-valued cells. (See Figure 12 for where this can be found in the menu.) I selected a comma separator for the data which had previously been in separate cells. The operation applies to one column at a time, so for this project I needed to apply it to both subcollections and authors.
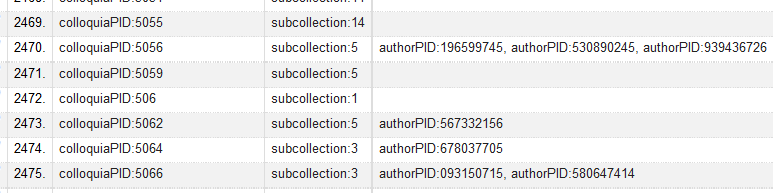
Figure 14. Results from joining multi-valued cells. (enlarge)
At this point in the process, the data consisted of a single row for each colloquia with its PID in the first column, the PIDs of all subcollections in the second column, and the authorPIDs of all speakers in the third column. The data was sufficient to recreate a RELS-EXT but now had to be transformed into Fedora Batch Modify statements. While I initially considered parsing it with Python or even XSLT, considering Phase 1 of the process reminded me that it could be done much faster with a simple regular expression find and replace.
First, I had to isolate the data that actually needed to be replaced. As mentioned earlier in this section, when extracting subcollection relationships, I had done a collection-wide extract. However, I would not need to update the thousands of records which would be unchanged. I exported the OpenRefine project as a tab-separated value (TSV) sheet, opened the sheet in Excel, and used row sorting to group rows which had nothing in the authorPID column. I then deleted rows without authorPIDs and resaved the project before opening it in Sublime Text 2 for actual manipulation.
In Sublime Text 2, I used a series of Regex searches and substitutions to search for a variety of possibilities, taking into account that each PID followed a known pattern and that a brief test indicated that there were no more than 3 subcollections and 4 authors for any one record. What follows is a sample line from the sheet, the regular expression used to match it, and the entire datastream as a replacement value for that line with backreferences to PIDS captured in the regular expression search.
colloquiaPID:4873 subcollection:3,subcollection:5 authorPID:837483920,authorPID:892493054,authorPID:294850493
(colloquiaPID:\d{1,4})\t(subcollection:\d{1,2}),(subcollection:\d{1,2})\t(authorPID:\d{9}),(authorPID:\d{9}),(authorPID:\d{9})
<fbm:modifyDatastream pid="\1" dsID="RELS-EXT" dsControlGroupType="X" dsLabel="colloquia_RELS-EXT_ds" logMessage="BatchModify - modifyDatastream">
<fbm:xmlData>
<rdf:RDF xmlns:rel="info:fedora/fedora-system:def/relations-external#" xmlns:fedora-model="info:fedora/fedora-system:def/model#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="\1">
<rel:isMemberOfCollection xmlns:rel="info:fedora/fedora-system:def/relations-external#" xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="info:fedora/collection:3"/>
<rel:isMemberOf xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="\2"/>
<rel:isMemberOf xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="\3"/>
<fedora-model:hasModel xmlns:fedora-model="info:fedora/fedora-system:def/model#" rdf:resource="info:fedora/cmodel:2"/>
<fedora-model:hasModel xmlns:fedora-model="info:fedora/fedora-system:def/model#" rdf:resource="info:fedora/cmodel:4"/>
<rel:isPartOf xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="\4"/>
<rel:isPartOf xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="\5"/>
<rel:isPartOf xmlns:rel="info:fedora/fedora-system:def/relations-external#" rdf:resource="\6"/>
</rdf:Description>
</rdf:RDF>
</fbm:xmlData>
</fbm:modifyDatastream>
This may sound time-consuming, but it was simply a matter of creating a regular expression search and a template for a single colloquia, subcollection, and author, and adding/removing possibilities. Once the template had been created, the find and replace process took no more than 5 minutes. To ensure none of the lines had been missed and the file created was properly valid, I added the header:
<?xml version="1.0" encoding="utf-8"?> <fbm:batchModify xmlns:fbm="http://www.fedora.info/definitions/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.fedora.info/definitions/ http://www.fedora.info/definitions/1/0/api/batchModify.xsd">
and closing
</fbm:batchModify>
tag and validated the XML file.
I then uploaded the modification file to one the of repository’s testing sites and used SPARQL and RISearch queries to see if calls for all items which considered themselves isPartOf authors whom I’d identified in the process would return colloquia as well as publications. The raw results were a complete success, so it was time to move on to experiments with Fedora 4.
Updating Fedora 4
After the challenge of updating Fedora 3, Fedora 4 turned out to be a much simpler situation. All RDF data in Fedora 4 is handled directly on the object rather than in an attached bitstream (Fedora 4’s term for what Fedora 3 called a “datastream”). These can be sent as a cURL PATCH call to the Fedora server, using SPARQL-Update to insert a single RDF relationship to the author’s object.
Not only did this negate the need to extract and group subcollection information with the author information, PATCH calls can be made over and over to the same object, so there was no need to group multiple colloquia speakers into a single PATCH. I started with a copy of the master file I’d created at the end of Phase 3 of the process, which I saved as a TSV sheet and opened in Sublime Text 2. I decided to use a similar regular expression method to create the PATCH statements. The following are sample data, query, replacement, and result.
Data:
colloquiaPID:1375 authorPID:160862354 colloquiaPID:4524 authorPID:160862325
Query:
colloquiaPID:(\d{1,4})\tauthorPID:(\d{9})
Replacement:
curl -X PATCH -H "Content-Type: application/sparql-update" -H "Cache-Control: no-cache" -d 'PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
DELETE { }
INSERT {
<> dc:creator <http://example.com:8080/fedora/rest/authors/\2>. }
WHERE { }' 'http://example.com:8080/fedora/rest/colloquia/\1'\n
Result:
curl -X PATCH -H "Content-Type: application/sparql-update" -H "Cache-Control: no-cache" -d 'PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
INSERT {
<> dc:creator <http://example.com:8080/fedora/rest/author/160862354>. }
WHERE { }' 'http://example.com:8080/fedora/rest/colloquia/1375'
curl -X PATCH -H "Content-Type: application/sparql-update" -H "Cache-Control: no-cache" -d 'PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
DELETE { }
INSERT {
<> dc:creator <http://example.com:8080/fedora/rest/author/160862325>. }
WHERE { }' 'http://example.com:8080/fedora/rest/colloquia/4524'
When saved as a cURL file and run from the command line, this immediately inserted the correct relationships into our Fedora 4 test instance (note, no passwords have been included in the PATCH statement, but if your Fedora 4 repository requires passwords for cURL calls, you would include them as well). Similar tests against the triplestore revealed that dc:creator searches would now retrieve colloquia URIs as well as publication URIs.
While this method seems simple, some idiosyncrasies recognized during the test process require a brief explanation of why it might require a few more steps to do to a live Fedora 4 repository. The testing version of the repository I updated uses PID prefixes and suffixes to create object UUIDs, splitting authorPID: 948347594 into /author/948347594/, etc., rather than using Fedora 4 default UUIDs, which are generated using a non-semantic Pairtree process[13]. However, because of some of the advantages of complex, Pairtree-based UUIDs and the need to create new objects in these collections, the final Fedora migration process used on the Goddard repository may abandon PIDs for Fedora 4-generated UUIDs.
In that case, a second step of reconciliation would need to be done before these cURL PATCHes could be generated. PIDs will migrate into Fedora 4 as triples using the predicate fedora3model:PID. As I envision it, one would use a triplestore to extract URIs with full UUIDs and PIDs for each set of PIDs. One could then store these in separate sheets in the same Excel workbook and use Excel’s MATCH and INDEX functions to recreate the pairings of colloquiaPID and authorPID in a third and fourth column of colloquiaUUID and authorUUID. A similar find/replace search based on matching and capturing each UUID would allow one to generate cURLs in the same fashion as above.
Alternatively, one might simply wait until the migration was complete and recreate the project from Phase 1 onward, using slightly different methods to extract data in Phase 2 since gSearch will be deprecated, so one is starting with the new UUIDs and not relying on PIDs. PIDs were used in this case because no permanent Fedora 4 version of this collection exists.
Comparing Methods for Updating Fedora 3 and Fedora 4
While this paper is meant to be a case study of the overall process of using one’s own data to create a reconciliation service and enhancing one’s own collections, the process of updating Fedora and the major differences between Fedora 3 and 4 prompted comparative reflection. When updating relationships between objects, Fedora 3’s methods are clearly more onerous and heighten the risk of data being lost through negligence or accident. If this project had also required updating the Author objects from Authors & Publications, it would have required extraction of every single relationship the repository records between two authors (hasCoAuthor) and every relationship an author has to their publications (hasPart). For prolific authors, this would have involved hundreds of relationships and while one could have followed similar methods as for subcollection, the risk of data loss would have caused greater anxiety.
In future, when working with any data that gets handled through RELS-EXT or could be handled as RDF in Fedora 4 (especially DublinCore), I would err on the side of waiting until the data was in Fedora 4 to perform the updates.
Conclusion
The process of reconciling and updating relationships between objects in a repository doesn’t end with performing the updates. While both the Fedora Batch Modify file and the cURL file stand ready to be deployed to the repository’s staging server, neither has been implemented at this point. The project was primarily an exploration of “could we do this?” and “how?” but more questions need to be answered before it can be deployed on the repository website.
First, how should the display be changed to reflect an author’s colloquia? While updating the colloquia module to include a link to the speakers author page instead of a textual search for their name would be simple, the question of the author page proved worthy of deeper consideration. As author pages currently only record publications, they may be regarded as incomplete curriculum vitae (incomplete because the repository’s mission statement does not include publications prior to or after their period of affiliation with Goddard). Should colloquia simply be intermixed with publications? Should they be two sections of the page or have tabs that allow users to switch between the two? These questions and more need to be asked before the relationships can be used and this part of the process will likely be folded into the overall redesign planned for the site’s migration to Fedora 4.
Second, what should be done about colloquia presenters who a) still work at Goddard and b) do not have author records? Is it inconsistent to only offer links to author pages if the speaker is also a published author? Or is it overkill to create author pages for those who don’t publish? Creating author records and pages for those who don’t publish requires us to reimagine “author” pages. It would also take significant time, at least in the beginning, to research the 400+ cases of a colloquia indicating a Goddard affiliation and whether or not that speaker was still at Goddard (if they have left, we cannot create a retrospective record as some of the data necessary to do so gets removed from our internal source) and then to create the record. But once it was done, the ongoing process would not be too time-consuming to maintain.
At this point, we’re faced with a lot of possibilities. This project and process will allow us to provide integrated access to resources in our repository. What remains is to decide how best to implement the other changes and to remain aware of possibilities for future enhancements.
Acknowledgements
This work was done under NASA/GSFC Contract NNG13AZ16C.
The author wishes to thank Christina Harlow, Kate Deibel, and Benjamin Armintor for resources or conversations which helped her solve several technical problems during the process.
About the Author
Ruth Kitchin Tillman worked as the Goddard Library’s Metadata Librarian through January of 2016. She starts in February 2016 as the Digital Collections Librarian for Notre Dame’s Hesburgh Libraries.
Endnotes
[1] The NASA Goddard Library Repository. http://gsfcir.gsfc.nasa.gov
[2] Fedora 3’s Resource Index Search (RISearch) allows access to the Resource Index which indexes relationships between Fedora objects using and basic metadata about the objects (DublinCore, Dates Created/Modified, etc.). This search merely exposes data from the index and cannot be used to perform updates to the objects or index. For further details, see: https://wiki.duraspace.org/display/FEDORA34/Resource+Index+Search
[3] Metadata Authority Description Schema. Used to encode authority records. The Goddard library uses a mildly adapted version which takes into account additional aspects of employment at Goddard. http://www.loc.gov/standards/mads/
[4] NISO Journal Authoring Tag Suite. http://dtd.nlm.nih.gov/publishing/
[6] The first of three useful tutorials explaining OpenRefine. https://www.youtube.com/watch?v=B70J_H_zAWM
[7] An RDF plugin for OpenRefine. http://refine.deri.ie/
[8] Friend of a Friend RDF vocabulary specification. http://www.foaf-project.org/
[9] This method of importing data into OpenRefine and extracting as an RDF skeleton may be used as an alternative, particularly to handle more detailed data or data that’s going to be used for more than a basic reconciliation: http://refine.deri.ie/rdfExport
[10] Sublime Text 2 supports use of regular expressions. http://www.sublimetext.com/2
[11] e.g. http://gsfcir.gsfc.nasa.gov/authors/id/857747614
[12] Documentation for the Fedora Batch Modify process in Fedora 3. https://wiki.duraspace.org/display/FEDORA34/Batch+Processing#BatchProcessing-BatchModify
[13] In a Pairtree filesystem, objects nest under hierarchical two-character directory names, e.g. http://fedorarepository:8080/fedora/rest/39/3b/b2/64/object-uuid. These directories are generally non-semantic. Unlike complex, proprietary structures intended to hide or obscure, the Pairtree hierarchy can easily be parsed by basic system tools, easily backed up, retrieved by any system which could parse the identifier, and migrated to or reindexed by any system which understands Pairtree. Pairtree isn’t the only such hierarchical structure, but it was the one chosen by Fedora’s developers.

Subscribe to comments: For this article | For all articles
Leave a Reply