by Marielle Veve
Introduction
As many libraries have previously done, in 2013 the University of North Florida (UNF) library contemplated harvesting the ETD metadata generated in their institutional repository, Digital Commons, to OCLC with the goal of avoiding duplication of cataloging efforts and improving efficiencies. When the library explored the literature, we discovered many semi-automated and some completely automated approaches. However, most of these approaches could not be implemented to the Digital Commons platform for various reasons. The completely automated approaches, such as the WorldCat Digital Collection Gateway did not seem to work properly with the Qualified Dublin Core (Qualified DC) metadata feeds that originated from IR software that use proprietary metadata, such as Digital Commons and DSpace[1] [2].
Many of the semi-automated approaches we considered were rejected because they relied completely on ProQuest Services to generate the initial ETD metadata. UNF, like some other libraries (McMillan, Halbert, & Stark, 2013), does not subscribe to Proquest for these services, as the practice of relying on ProQuest to generate initial ETD metadata has been scrutinized recently in favor of student choice and open access options (Clement, 2013). Other approaches relied on tools that would require a high level of programming expertise to be implemented (Park & Brenza, 2015), a background many catalogers do not have. Only one semi-automated approach was found that could be implemented in our institution’s case. This approach, developed by Sai Deng and Terry Reese (2009), is customized to address the specific needs of the DSpace IR, but could be extended and implemented to Digital Commons software if further customizations are performed. These customizations would address the differences that exist in software capabilities, schema used, and element display differences between DSpace and Digital Commons.
The DSpace workflow
Deng and Reese’s workflow starts with the generation of descriptive metadata within the DSpace IR software and exposes the result in Qualified DC schema using the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH); the resulting metadata is then harvested and transformed into MARC records with the assistance of an XSLT stylesheet (Extensible Stylesheet Language Transformations) and the MarcEdit OAI Harvester. After the transformation, the generated MARC records are imported into OCLC by cataloging staff. We have been successfully using this approach to harvest ETD metadata from our IR. The MarcEdit OAI Harvester tool has proved over time it can harvest metadata in any proprietary schema and from any IR software without any complications. Designed with the library community in mind, this tool is user-friendly and can be implemented by anyone with or without programming expertise; plus its customer service is excellent. Emails are answered within the same day by the tool’s creator or by other members in the discussion list. In addition, the tool has a huge community of followers and users who support its development in the long-term.
Even though Deng and Reese’s workflow can work smoothly with any IR that uses the DSpace software, some major customizations were necessary to address the issues that arise when a different IR software is used.
Obstacles to Digital Commons IR software implementation
In the case of UNF, we encountered the following obstacles when trying to implement Deng and Reese’s workflow with the Digital Commons software:
- The Qualified DC metadata exposed via OAI-PMH by DSpace is different from the Qualified DC metadata exposed by Digital Commons. This is because each institution makes their own internal decisions regarding which metadata elements to use in their IR metadata template and which ones to expose via OAI-PMH. In addition, DSpace and Digital Commons have different capabilities for displaying the metadata elements. For example, DSpace has the ability to display the ETD advisors’ names in inverse order (Deng, Matveyeva, & Wang, 2008) while Digital Commons cannot (Digital Commons representative, personal communication with author, October 13, 2015).
- The DSpace IR uses a different set of Qualified DC elements from the ones used by Digital Commons IR to map their ETD metadata to OAI-PMH. DSpace uses elements from the default Qualified DC in the DSpace metadata registry while Digital Commons uses the BePress Proprietary Schema for Qualified DC.
- The XSLT stylesheet used in the Deng and Reese case study uses elements from the DSpace proprietary schema and follows the older cataloging content rule standards, the Anglo-American Cataloging Rules, 2nd edition (AACR2). In order to be implemented to the Digital Commons software, this XSLT stylesheet would need to be adjusted to the BePress proprietary schema. We also needed to adjust it to reflect the current Resource Description & Access (RDA) content standards.
- Given that the initial metadata generated by DSpace will not be the same as the metadata generated by Digital Commons, we anticipated that an additional set of final edits would need to be performed on the MARC records.
Even with these major obstacles, Deng and Reese’s approach still presents a good set of practical tools and ideas that can be useful to the Digital Commons IR community if special customizations and adaptations are implemented to address these differences, such as the use of a customized ETD stylesheet and MarcEdit’s OAI Harvester.
For that reason we included these tools as part of the workflow presented below, but with additional customizations performed at each stage of the harvesting workflow to address these issues. The workflow is also updated to integrate the current description standards for ETDs mentioned in RDA.
Tailored approach for the Digital Commons platform: UNF Case study
We designed the following workflow to transform our IR ETD metadata into high quality, RDA-compliant MARC records that can be ingested by OCLC. The transformed records have authorized headings (LCNAF) for the ETD authors, college departments, and Library of Congress Subject Headings (LCSH). In addition, keywords supplied by the ETD authors are included. We have designed this workflow to work out-of-the-box with minimal edits [3] so that it can be used by other Digital Commons IR users who do not want to rely on ProQuest Services to produce the original ETD metadata nor have a strong background in programming. The workflow consists of seven main steps we implemented with the assistance of a customized Digital Commons crosswalk for ETD metadata (Appendix A).
Digital Commons Workflow Steps
Step 1. Created list of fields desired in final ETD record (a wishlist) — (Columns A & B)
The first step was to decide which descriptive metadata elements we wanted to display in our final MARC records. Examples of these fields are the authorized form of author, ETD title, degree acquired, college, and name of advisors. Appendix A, Column A provides a list of these fields with Column B displaying how they map to MARC fields.
Step 2. Customized Digital Commons ETD Submission Metadata Template — (Column C)
When looking at the original submission metadata template in Digital Commons, we noticed that some of the desired fields from the “wishlist” were already included there, while others were not. In order to include the additional desired fields that were not originally included, we created a new template and customized it to include as many of these desired fields as possible. Creating this new template helps ensure quality metadata from the beginning, a good practice that helps reduce editing efforts and avoid future problems.
Column C in Appendix A specifies the fields we added to the Digital Commons submission template—if not already there—while Column D illustrates how these fields should be mapped to the Qualified DC elements in BePress’s Proprietary Schema. Examples of the additional fields we added to the template are:
- birth date
- LCNAF authors’ names
- LCNAF corporate body
- advisors’ names in inverted order
- controlled subject terms
It is important to clarify at this point that most of these additional fields are only used to generate the final MARC records sent to OCLC. Fields such as ‘birth date’ are hidden from the public display in Digital Commons but still mapped to the appropriate OAI-PMH field. We added these fields to the ETD submission template and mapped them to the elements specified in Column D of Appendix A by sending a request to the institution’s designated Digital Commons’ service representative. Our new, customized Digital Commons template can be seen in Figure 1.
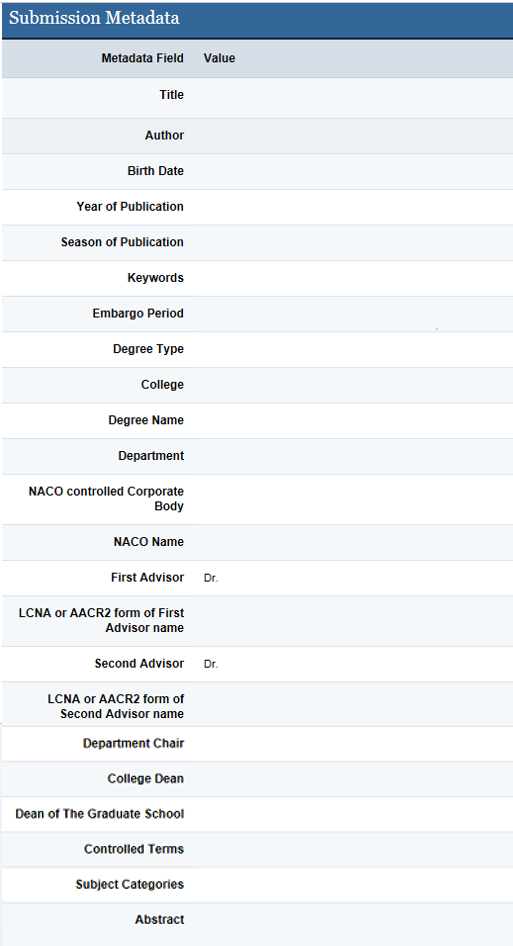 Figure 1. Customized Digital Commons ETD template
Figure 1. Customized Digital Commons ETD template
Step 3. Mapped fields in ETD Submission Template to OAI-PMH — (Columns C & D)
Digital Commons exposes its metadata via OAI-PMH in three schemas: “Simple-Dublin-Core (DC), Qualified-Dublin-Core (QDC), and oai_etdms” (BePress, 2015, p.2). From these three schemas, we selected Qualified DC as the preferred schema to harvest the ETD metadata for three main reasons. First, the metadata exposed in Qualified DC provides the broadest set of elements with the highest level of flexibility for mapping customized fields. Second, Qualified DC is one of the most commonly used XML schemas in IRs. According to Park and Tosaka (2010): “A trend of Qualified DC being used (40.6 percent) more often than Unqualified DC (25.4 percent) is noteworthy.” Third, the Qualified DC Proprietary schema used by Digital Commons integrates the additional ETD elements recommended by the Networked Digital Library of Theses and Dissertations (NDLTD) metadata standards (Robertson, 2011).
At this stage, We mapped the fields from the Digital Commons ETD template (column C) to the appropriate BePress Qualified DC elements in the BePress OAI feed, requested from:
http://digitalcommons.unf.edu/do/oai/?verb=ListRecords&metadataPrefix=qdc&set=publication:etd [4]
Appendix A presents our mapping of the elements in the Digital Commons template (column C) to their corresponding elements in the OAI feed (column D.) For any of the fields that do not match this exact pattern, we requested a mapping re-configuration from our Digital Commons consulting services representative. Some fields, like the MARC fields 336, 337, 338, and 540, are constant for each record. For these fields (noted in column C with the value “Will not be added at this point”), rather than mapping them in the OAI, we added them later using an XSLT stylesheet (Column E).
Step 4. Customized Institution’s ETD Stylesheet (XSLT) — (Column E)
The MarcEdit OAI Harvester tool provides a good set of generic XSLT templates that can be used and customized to meet particular institutional repository data transformation needs. We used the XSLT named “OAIDCtoMARCXML” included in the MarcEdit 6 package. The stylesheet was adapted to ETDs and customized to include the additional fields desired in the final MARC records and exclude the ones not wanted. Examples of changes and additions performed to this original XSLT and instructions on how to perform them are illustrated in Column E of Appendix A. A copy of this finalized customized XSLT stylesheet is available in Appendix B.
Step 5. Transformed Qualified DC into MARC metadata using an OAI Harvester & XSLT
We then use an OAI harvester tool to transform the Qualified DC metadata displayed in the OAI feed to MARC metadata with the assistance of the customized ETD XSLT stylesheet (Appendix B). An excellent open access OAI harvester is the MarcEdit OAI Harvester, which can crosswalk the files to marc records to be ingested by OCLC. We use this tool to formulate a feed request for ETD metadata in Qualified DC from our Digital Commons repository, using the customized XSLT stylesheet in Appendix B. An example of this request is presented in Figure 2. It is important to know that the “qdc” option used in this request example is not included in the default metadata drop-down menu in the MarcEdit OAI Harvester, however, typing “qdc” manually in the field will allow the harvester to complete the transformation. We selected the customized stylesheet in the crosswalk field and ran the crosswalk. This request will generate MARC records that look like Figure 3.
 Figure 2. Request for metadata using the MarcEdit OAI Harvester
Figure 2. Request for metadata using the MarcEdit OAI Harvester
 Figure 3. MARC record generated for ETDs
Figure 3. MARC record generated for ETDs
Step 6. Performed final edits using the Marc Editor Tool– (Column F)
Even though most of the metadata at this point has been customized with the assistance of the initial IR template and the XSLT stylesheet, there are still some final edits that need to be done. These edits are minor and can be performed in batch or by creating automated assigned tasks using MarcEdit’s MarcEditor. Column F in Appendix A contains a list of suggested final edits that can be performed. Examples include separating the different LCSH that display in one 650 field into separate individual 650 fields (Figure 4), fixing punctuation mistakes, substituting the word ‘YYYY’ in fields 502 and 008 for the actual year digits (Figure 5), and removing keywords that only serve a local purpose and will not make sense outside the IR context (Figure 6).
 Figure 4. Separating LCSH that display in one field into multiple 650 fields click to enlarge
Figure 4. Separating LCSH that display in one field into multiple 650 fields click to enlarge
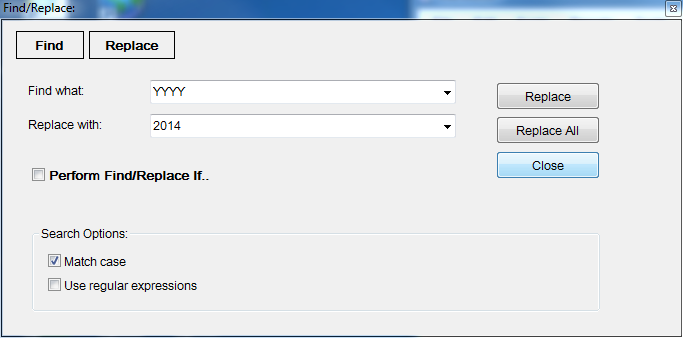 Figure 5. Substituting the word ‘YYYY’ in fields 502 and 008 for digits
Figure 5. Substituting the word ‘YYYY’ in fields 502 and 008 for digits
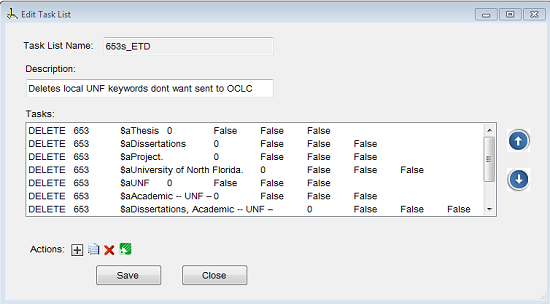 Figure 6. Automated Assigned task to remove locally purpose keywords
Figure 6. Automated Assigned task to remove locally purpose keywords
Step 7. Imported records to OCLC and perform final quality control — (Column G)
After final edits are performed with MarcEdit, we compile records back into MARC-8 and import to OCLC Connexion. Detailed instructions on importing and exporting records in batch to OCLC are located in OCLC’s documentation [5]. In OCLC, we perform a final quality control of records by validating them. Column G in Appendix A contains a list of suggested things to look for during quality control. Something that is of particular importance to check is that symbols in the abstract display well and that the abstract content was imported completely without errors. A common problem encountered with this particular XSLT (Appendix B) is that if the symbol “>” appears somewhere in the abstract, any data after the symbol will be dropped and will not be transferred to the new MARC record during the harvesting process. This is a side effect of the XML coding “remove-html” that is used in XSLT stylesheets to avoid transferring unnecessary HTML symbols to MARC records.
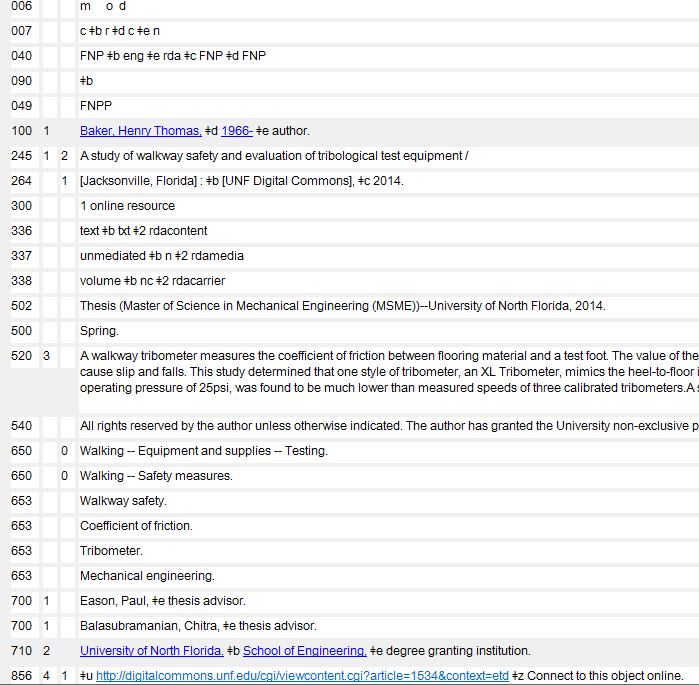 Figure 7 Final MARC record of ETD in OCLC
Figure 7 Final MARC record of ETD in OCLC
Advantages and disadvantages of this workflow: Future improvements
When implemented with Digital Commons repositories, the workflow presented in this paper will avoid duplication of efforts by generating high quality ETD metadata from the beginning and in just one place. The time that is saved can be better allocated to perform other important ETD tasks such as authority control for the ETD authors and the assignment of controlled subject headings (LCSH) in addition to the subject keywords provided by the ETD authors.
For those interested in implementing this workflow, the tools are free and no programming or major XSLT editing will be required, as most of the needed customizations have already been integrated. Another advantage of this workflow is that it has the ability to separate multiple LCSH that may appear in one 650 MARC field into individual separate 650 MARC fields as well as separating the authors’ keywords (653s) from the controlled headings (650s).
Lastly, by avoiding the use of ProQuest metadata services and the OCLC Digital Gateway, this workflow will enable other Digital Commons IR users to gain more control over the type and quality of ETD metadata produced for these important and unique materials. In addition to this, bypassing ProQuest will channel access to the full-text of ETDs into one place, the institutional repository, instead of having multiple access routes to full-text that may divert traffic from the IR.
On the other hand, this workflow presents two disadvantages. First, asking for authors’ birthdates in the ETD metadata template may raise privacy concerns among some scholars, even though the practice of asking for birthdates during the ETD submission process is not new to the profession and has been performed by libraries for a while. This privacy issue, can be addressed by either not requiring students to fill the birthdate field in the ETD template or by blocking this field from the public display in Digital Commons. Alternatively, using unique researcher identifiers such as the Open Researcher and Contributor ID (ORCID) to identify ETD authors has been suggested by some scholars. The ORCID registry assigns a unique alphanumeric code to authors instead of using birthdates or authorized forms of headings. Originally launched in October 2012, the registry offered a few mini-grants in 2013 for institutions that would be willing to implement and test the registry (TAMU Libraries, 2015). Texas A&M University Libraries and the University of Missouri were two of these grant awardees that pioneered the ORCID implementation into the ETD domain in 2014. Using ORCID identifiers for ETD authors, however, is a new concept that is still in its infancy and more research should be done to assess its applicability to bibliographic records in the MARC schema environment.
Another disadvantage of this workflow is that names of the ETD advisors have to be entered twice in the Digital Commons template. One form of the name is in direct order (FirstName LastName) while the other one is in the inverted form (LastName, FirstName). The reason for this duplication is that students enter their advisors’ names in direct order in the template while the inverted form is needed to generate the 700 fields for the MARC records. When Digital Commons was approached by this paper’s author to display the ETD advisors fields in the inverted order in the OAI, they said they were unable to do so. The only solution would be to add an additional field to the ETD template with the inverted form of the name [6]. An alternative solution to this problem is to include an XML coding in the stylesheet that can perform transformations for personal names, but doing so would be too complicated given all the possibilities a name can be displayed. Reese included an example of this complex XML coding in one of his XSLT stylesheets located at the Oregon State University IR [7]. Unfortunately, the coding for personal names used in this stylesheet cannot be used today without significant alteration, as it was created before the RDA days and still follows the former AACR2 rule conventions.
Conclusion
Finally the workflow presented in this paper, even though it is customized and tailored to address the particular needs of the Digital Commons IR software, can be extended to other IR software through further customization to address the differences in IR software capabilities and schemata used.
Notes
[1] S. Wynne, S. McIntyre, & M. Finn, discussion with author through metadatalibrarians mailing list, September 23, 2015.
[2] A. Harrell, W. Robertson, & M. Gibney, discussion at digitalcommons@google.groups, April 29, 2016.
[3] The only customization that will be required is changing the institution’s name and place in the stylesheet. (Fields 264, 502, 040, and 008 will be affected).
[4] To formulate this type of request, see BePress’s documentation for more details. “Digital Commons and OAI-PMH: Harvesting Repository Records.” Available at http://digitalcommons.bepress.com/reference/80
[5]“Cataloging: Export or Import Bibliographic Records” Available at https://www.oclc.org/content/dam/support/connexion/documentation/client/cataloging/exportimport/exportimportbib.pdf
[6] Digital Commons representative, email communication with author, October 13, 2015.
[7] “Oregon State University Electronic Theses DSpace (OAI-PMH) to MARC21XML Crosswalk” Available at https://ir.library.oregonstate.edu/xmlui/handle/1957/6300
References
BePress. (2015). BePress Proprietary Schema for Qualified Dublin Core. Retrieved from http://www.bepress.com/assets/xsd/oai_qualified_dc.xsd
BePress. (2015). Digital Commons and OAI-PMH: Harvesting repository records, 2-6. Retrieved from http://digitalcommons.bepress.com/reference/80
Clement, G. P. (2013). American ETD dissemination in the age of open access: ProQuest, NoQuest, or allowing student choice. College & Research Libraries News, 74, (11), 562-566. Retrieved from http://crln.acrl.org/content/74/11/562.short
Deng, S., Matveyeva, S. & Wang, T.M. (October 2008). Customized mapping and metadata transfer from DSpace/SOAR to OCLC and Voyager. Paper presented at the Ex-Libris Southcentral Users Group (ELSUG) Meeting, Wichita, KS. Retrieved from http://soar.wichita.edu/handle/10057/1573
Deng, S., & Reese, T. (2009). Customized mapping and metadata transfer from DSpace to OCLC to improve ETD workflow. New Library World, 110 (5/6), 255. doi: 10.1108/03074800910954271
DSpace. (2015). Default Dublin Core Metadata Registry (DC). Retrieved from https://wiki.duraspace.org/display/DSDOC4x/Metadata+and+Bitstream+Format+Registries
McMillan, G., Halbert, M. & Stark, S. (July 2013). Comprehensive study of National ETD practices. Paper presented at the annual meeting for the United States Electronic Thesis and Dissertation Association, Claremont, California. Retrieved from https://conferences.tdl.org/usetda/index.php/USETDA/USETDA2013/paper/view/666/318
OCLC Connexion Client Guides. (2014). Cataloging: Export or import bibliographic records. Retrieved from https://www.oclc.org/content/dam/support/connexion/documentation/client/cataloging/exportimport/exportimportbib.pdf
ORCID. (2015). Retrieved from https://orcid.org/about/what-is-orcid
Park, J.R., & Brenza, A. (2015). Evaluation of semi-automatic metadata generation tools: A survey of the current state of the art. Information Technology and Libraries, 34, (3), 24. doi: 10.6017/ital.v34i3.5889
Park, J.R. & Tosaka, T. (2010). Metadata creation practices in digital repositories and collections: Schemata, selection criteria, and interoperability. Information Technology and Libraries 29, (3), 108 and 114. doi: http://dx.doi.org/10.6017/ital.v29i3.3136
Reese, T. (2009). Automated metadata harvesting: Low-barrier MARC record generation from OAI-PMH repository stores using MarcEdit. Library Resources and Technical Services, 53, (2), 129. doi: http://dx.doi.org/10.5860/lrts.53n2.121
Robertson, W. C. (April 2011). Repository metadata: Challenges of interoperability. Paper presented at the ALCTS Institutional Repository Webinar Series. Retrieved from http://ir.uiowa.edu/lib_pubs/76/
TAMU Libraries. (May 2015). ORCID integration at Texas A & M. Retrieved from http://guides.library.tamu.edu/content.php?pid=553864&sid=4564757
About the Author
Marielle Veve has been Metadata Librarian at the University of North Florida since 2013. Previously she worked as Cataloger & Metadata Librarian at the University of Tennessee from 2006 to 2013 and Cataloger for Latin American materials at Tulane University from 2003 to 2006.
Appendix A
Digital Commons Crosswalk for ETD Metadata
| A | B | C | D | E | F | G |
| Description of desired fields for ETD “Wish list” |
MARC fields (follow RDA) |
Digital Commons submission template fields | Digital Commons OAI-PMH display (in BePress Proprietary Schema for Qualified DC) |
Customizations to XSLT (BePress’ schema + RDA) |
Final edits using MarcEdit | Quality Control in OCLC
|
| Author of ETD Authorized form |
100 | NACO Name & Birth Date (add in separate fields) |
<dc:creator> Map to the 2nd creator element |
100 will be mapped to dc:creator[2] and an additional constant will be added at the end of this field $e author. | If $q shows, remove comma before $q. If there is a title, such as Jr. or II, add $c in front | Press “F11” to link the 100 field to the LCNAF record |
| Title | 245 $a $b | Title | <dc:title> | |||
| Statement of Responsibility | 245 $c | *Will not be added at this point | *Will not show in OAI mapping | *Will not be added at this point | Can be added at this point using automated task 245$c | |
| Pub. place | 264 $a | *Will not be added at this point | *Will not show in OAI mapping | Will be added at this point. 264$a will be mapped to [Jacksonville, Florida]: | ||
| Publisher | 264 $b | *Will not be added at this point | *Will not show in OAI mapping | Will be added at this point. 264$b will be mapped to [UNF Digital Commons], | ||
| Pub. date | 264 $c | Year of publication (already there) |
<dc:date.created> | Instructions will be given to select last 4 digits (year) | ||
| Physical Description | 300/336/337/338 | *Will not be added at this point | *Will not show in OAI mapping | Will be added at this point using constants: 300$a 1 online resource 336$atext$btxt$2rdacontent 337$aunmediated$bn$2rdamedia 338$a volume $bnc$2rdacarrier |
||
| Degree | 502 | Degree Name | <dc:thesis.degree.name> | An additional constant will be added at the end of this field Thesis ( )–University of North Florida, YYYY. | Substitute the word ‘YYYY’ for actual digits. Will change field 502 and 008. | |
| Season pub (Spring, Summer or Fall) | 500 | Season of publication (needs to be added if not there) | <dc:date.issued> | |||
| Abstract | 520 | Abstract | <dc:description.abstract> | Check the content of ALL the abstract passed. For symbols and special characters not recognized by OCLC, change using a character from OCLC table. | ||
| Rights | 540 | *Will not be added at this point | *Will not show in OAI mapping | A constant field will be added at this point $a All rights…. And mapped to 540 | ||
| LCSH (controlled subjects) |
650 | Controlled terms (need to be added) | Will show in one element <dc:subject.lcsh> | Generate a separate 650 field for each LCSH. | ||
| Author provided subjects (uncontrolled) |
653 | Keywords | Will show in separate elements <dc:subject> | Remove local purpose keywords that you don’t wish transferred to final record | ||
| Thesis advisor(s) in inverted order | 700 | For each advisor: LCNAF or AACR2 form of (1st, 2nd, 3rd) advisor name (need to be added) |
<dc:contributor.advisor> | An additional constant will be added at the end of this field $e thesis advisor. | Yes. Check diacritics, if any, passed | |
| Univ & Dept. who granted degree | 710 $a $b | NACO controlled Corp Body (need to be added) |
<dc:thesis.degree.grantor> | An additional constant will be added at the end of this field $e degree granting institution. | Press “F11” to link the 710 field to the LCNAF | |
| URL | 856 | *Will not be added at this point | <dc:identifier> | An additional constant will be added at the end of this field $z Connect to this object online. | Verify url works. | |
| Fixed fields | LDR, 008,006,007,040 | *Will not be added at this point | *Will not show in OAI mapping | Will be added at this point using constants: 008 006 007 040$aFNP$beng$erda$cFNP |
Substitute the word ‘YYYY’ for actual digits. Will change field 502 and 008. |

Appendix B
Appendix B is available as an xslt stylesheet.

Subscribe to comments: For this article | For all articles
Leave a Reply