by Jason A. Clark and Scott W. H. Young
Introduction
Libraries and librarians exist in a space where vocabularies are structured and defined. Rubrics, like the Library of Congress Subject Headings or the Dewey Decimal Classification System, shape how we can talk about the people, places, and things in our libraries. Yet, meanings and definitions are in flux and there are times when the language of the Web moves faster than our classification systems. It was in this transitional space that our project began. At our library, we had conducted research on Semantic Web and structured data that focused on description and discovery of the things – the books, the digital images, the journals and articles – that make up the collections within our library, but we recognized a different opportunity. We asked, “What if we turned this practice of linked data into an application that helped in the discovery and description of the people in our library?” The “Linked People” project was our answer to this question [1]. At its core, the project is about remaking our people pages by connecting the local staff database to the Linked Open Data (LOD) cloud. With this proof-of-concept project, we were looking to find another use-case for a graph-inspired data model using web-ready open source tools. The project led to a new data model, a new user interface (UI), a network graph visualization, Search Engine Optimization (SEO) improvements for our people pages, and our people pages encoded as five-star Linked Open Data (LOD). In this article, we focus on the code to build this library knowledge graph as well as the linked data workflows and ontology expressions developed to support it. This work includes:
- Explaining how to encode and publish web-ready people profiles as RDFa HTML, JSON-LD, and RDF.
- Discussing leading schemas for person and identifier entities, such as Schema.org, FOAF, and eduPerson, and how to apply them.
- Detailing and sharing the ontology and data structures used for expressing relationships among people, their organizational roles, and research topics.
- Demonstrating how this structured data work impacts Search Engine Optimization (SEO) and discoverability for people profiles within commercial search engines.
- Visualizing research networks based on a graph data model.
We wanted to see what our library knowledge graph might look like and how it could generate new insights into how our people collaborate and how we present our skills and services to our users. We ended up learning even more about how data needs context and meaning and how people want to be understood and valued.
Literature Review
Our literature review is focused on several broad themes that we weaved together in developing this practical implementation. There really wasn’t a direct corollary article that encapsulated this idea of applying linked data to a library staff directory. More specifically, we focused on the linked open data landscape in libraries, research into the patterns of HTML5 and structured data markup, use cases and implementations of knowledge graph data models, and the development of metadata standards for describing people. Each of these components was essential in providing the frame for how we would link and construct our idiosyncratic library linked data application centered around library staff data.
Linked open data landscape in libraries
Libraries and cultural heritage institutions have been working with and around Linked Open Data (LOD) for a number of years. A distillation of that work is beyond our scope here, but two studies did help ground our understanding of the progress in our field. In their introductory study, Goddard and Byrne outline the benefits and obstacles to bringing library data into the linked open data field. They also put forward several ways for libraries to get involved in the practice of linked data and offering an encouraging call to experiment linking data in “small standalone collections” to develop “expertise and technologies within libraries” which we saw as a call to action (Goddard et al. 2010). Another primary resource to understand the LOD landscape is Smith-Yoshimura’s International Linked Data Survey for Implementers in 2014 and 2015 which includes a rich dataset featuring which institutions have implemented or are implementing linked data; what linked data sources institutions are consuming, and why; what institutions are publishing, and why; and finally, barriers and advice from the implementers (Smith-Yoshimura, 2016). There are efforts within libraries and cultural heritage institutions to connect linked data descriptions of people to their activity. VIVO is the project that immediately comes to mind and its original implementation was focused on mapping the networks and activities of life sciences researchers (Devare et al. 2007). In VIVO’s focus on people, their networks, and their activities, we took our inspiration for a library knowledge graph.
Patterns of HTML5 and structured data markup
When the HTML5 specification was introduced, new markup elements and attributes were included that opened up new possibilities for how we might make the web machine-readable. In his study and tutorial of these possibilities, Ronallo notes that “HTML5 includes a syntax called Microdata, that allows web publishers to layer richly structured metadata directly into their Web presentations.” (Ronallo 2012). RDFa and JSON-LD are two other syntax encodings that enable structured data in HTML pages. In their analysis of structured data in the Common Crawl dataset, Bizer et al. (2013) note that the growth of machine-readable descriptions of web content continues to grow. Additional efforts like the Web Data Commons provide a continually updated picture of the most recent usage and implementation of Microdata, JSON-LD, RDFa, and other Microformats. Each of these structured data formats enables incredible granularity of description when paired with a vocabulary like Schema.org and its full range of types that includes everything from CreativeWorks to Places to Organizations to Persons and their Actions. Google even has an “Introduction to Structured Data” that explains the hows and the whys of structured data noting that when “…information is highly structured and predictable, search engines can more easily organize and display it in creative ways.” Our interest in description of the entities on our staff pages and the benefits of marking up our people, their networks, and their activities for better searching experiences convinced us that structured data was necessary work.
Use cases and implementations of graph models
Graph visualization and its technique, application, and evaluation have been present in Library and Computer Science literature since at least the early 1990s, and in the last five years has especially risen in prominence with the availability of new technologies (Beck et al. 2016). The application of graph modeling is widespread, covering ground ranging from the humanities to social science to computer science. Notable examples are numerous. Linked Jazz, for instance, represents a high-water mark of humanities-based graph visualization (Pattuelli et al. 2013; Pattuelli et al. 2015). The relational data of social networks is a natural point of application for graph modeling, as Shulman et al. (2015) show in visualizing library Twitter networks. Anthropological pursuits have similarly intersected with graph visualization (Pasquaretta et al. 2014). Research communities and the connections between authors have also been studied and visualized through graph modeling (Nart et al. 2015), as has the World Wide Web itself (Meusel et al. 2014). Graph visualization is a powerful and flexible interdisciplinary tool for making visible the relationships among entities, especially when those entities are individual persons. For this reason, building a graph model was well suited for this project.
Metadata standards for describing people
Some of the earliest uses cases and vocabularies for the Semantic Web focused on people and their networks. In many teaching settings, the “Hello World” of an RDF XML expression is an encoding of people and their social networks. The Friend Of A Friend (FOAF) ontology was one of the first means by which person entities could be defined and people could describe their connections. Developers also realized it could be used to solve pressing problems like disambiguation of individuals and modelling organizational structures (Graves et al. 2007). Other person description schemas have been developed for implementation in software protocols like LDAP (Lightweight Directory Access Protocol). The eduPerson standard is one of these schemas designed to include widely-used person and organizational attributes in describing higher education. It provided us with another model for description of people and with required properties like eduPersonOrgDN (a distinguished, unique name representing the institution) reinforced our need to build organizational roles and descriptions into our application. While FOAF and eduPerson are useful in filling out models for descriptions of people and organizations, they tend to be more focused on internal or personal use of staff data. Schema.org, an initiative for creating and supporting a common set of schemas for structured data markup on web pages has a more external focus on discovery in commercial search engines. In tracing the history of Schema.org’s development, Guha et al. (2016) note that the “goal was to provide a single schema across a wide range of topics that included people, places, events, products, offers, and so on… The idea was to present webmasters with a single vocabulary.” Within this vocabulary, the Person type remains one of the most implemented (Guha et al. 2016). Given its popularity, simple key/value structure, and impact on findability, the Schema.org Person type became the keystone component in our library knowledge graph.
Building a Staff Directory Application with HTML5, RDFa, and Linked Data Practices
With our research complete and broad project goals defined around discovery in search engines, improving the browsing and searching of our staff data, publication of linked open data, and visualizing organizational and topic networks, we turned toward the work of building a new staff directory application.
A Linked Data Model
One of our first tasks was to construct a data model for the reworked application. The data existed in a relational database and we thought we could remodel those relationships using a new data model based on typical linked data structures that connect multiple entity topics through LOD vocabularies. This was a significant decision as it meant we would not be storing the data as a linked data triple store, but within a relational data model that would output linked open data. It allowed us to focus on how our existing technologies (SQL) could accommodate linked data practices. In thinking through the model, we needed a means to structure and encode a link from a library Person entity to a library Activity or Topic entity. This decision was largely driven by our goal of following a graph data model and the Resource Description Framework (RDF) triple pattern. An RDF triple is a means of describing a relationship of things as three constituent parts: the subject, predicate, and object. In our library case, we were looking to describe two primary triple patterns: how a person (subject) is related to (predicate) other colleagues (object) and how a person (subject) has (predicate) a certain topic of expertise (object).
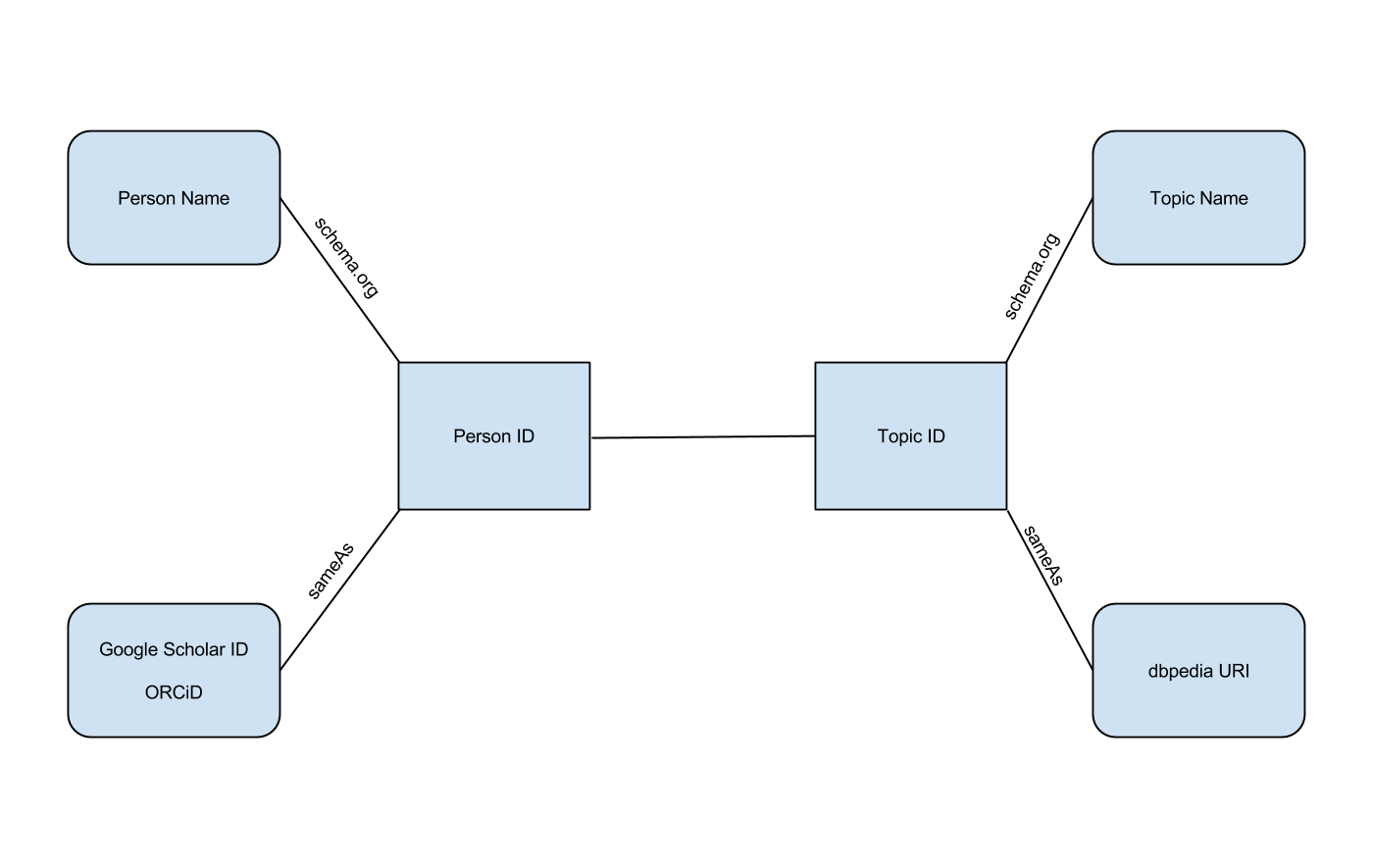
A draft of how this ontology would work is below (Figure 1). In this model, a library staff member is given a unique Person ID stored locally in our database. Each expertise topic is also given a unique Topic ID stored locally. Through RDFa markup, we can then articulate the relationship between Person ID and Topic ID. We provide context and meaning to each Person ID by connecting the ID to that person’s name via schema.org markup and a Google Scholar profile URL and an ORCiD URL using Schema.org’s “sameAs” property. Likewise with Topic IDs, we provide context and meaning by connecting the Topic ID to a name via schema.org and a DBpedia URL using Schema.org’s “sameAs” property. Through this process, each staff member is situated within a Linked Open Data graph that expresses identity and expertise.
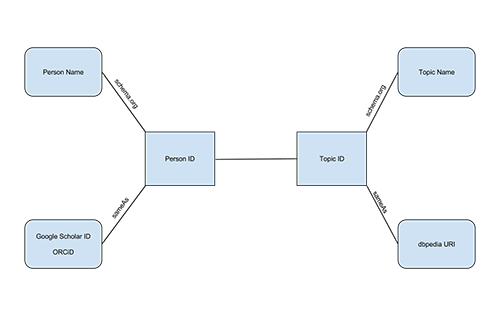
Figure 1. A visual representation of our ontology and where external vocabularies might appear (enlarge)
Structured Data Markup with HTML5 and RDFa
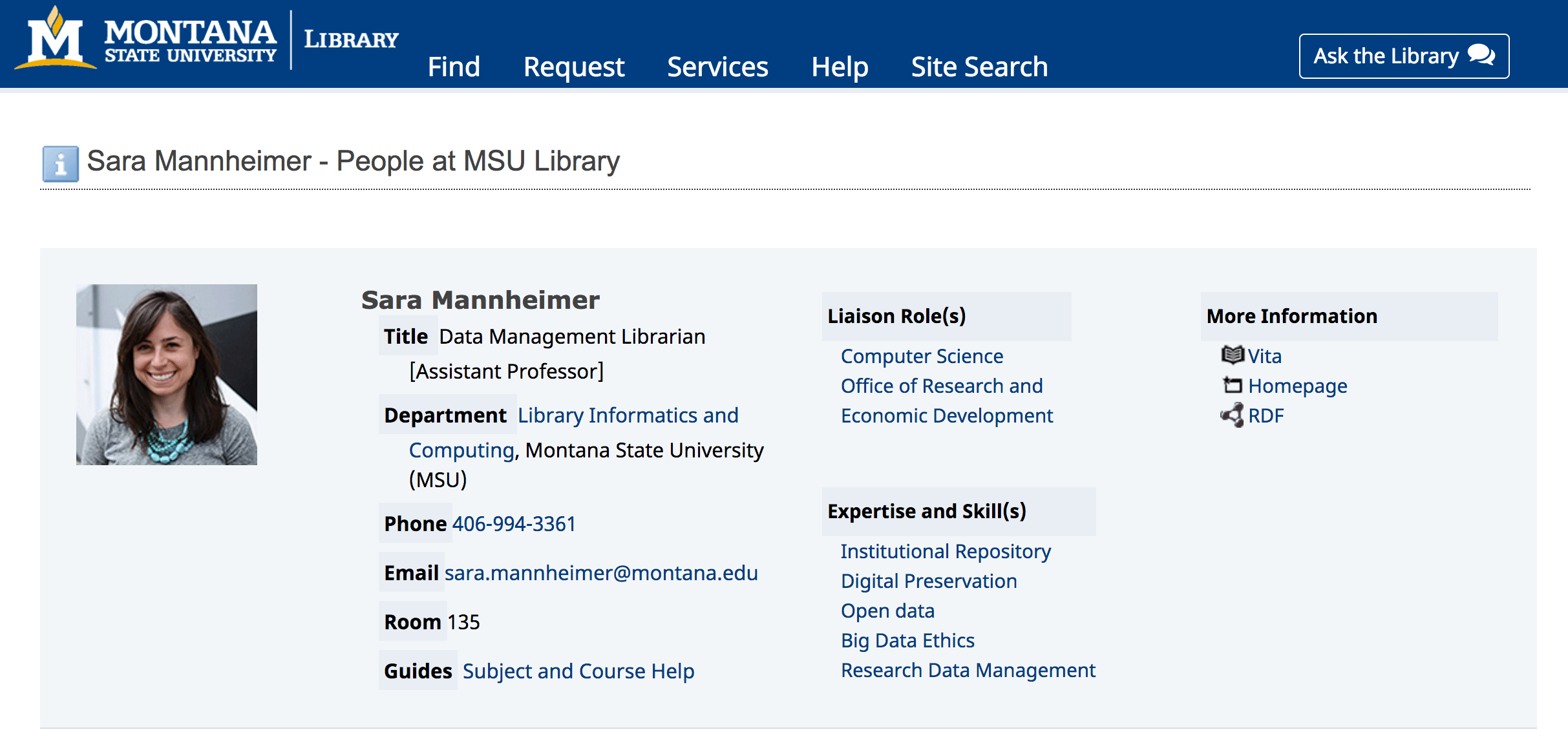
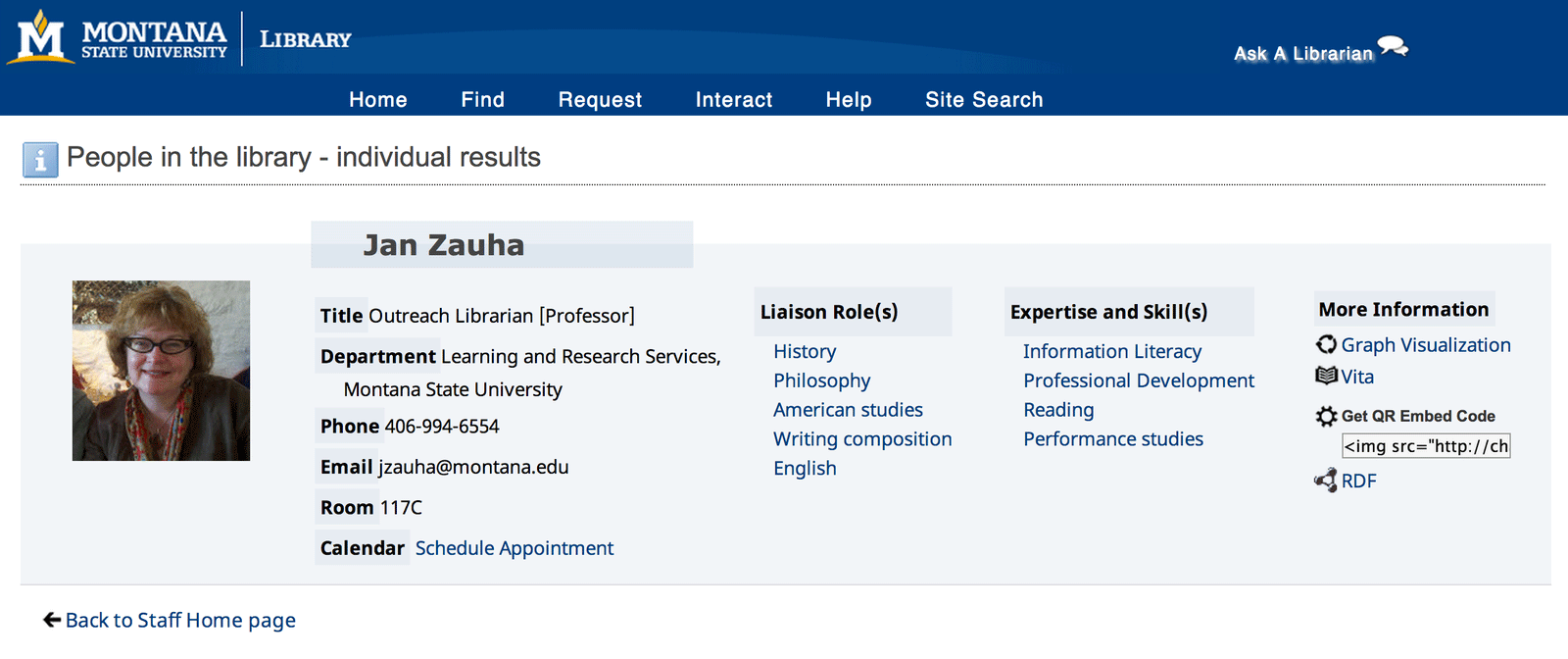
After the data model for staff profiles was finalized, we turned to markup that was “of the web”, namely semantic HTML and RDFa. We focused on the staff profile pages that would display the richest expression of staff data that would be accessible to machines (Figure 2).
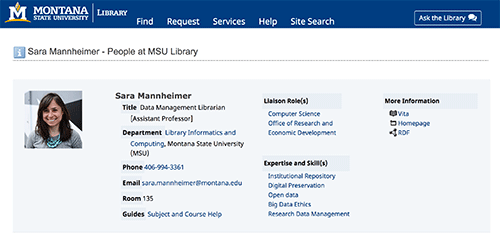
Figure 2. Web browser view of a staff profile page (enlarge)
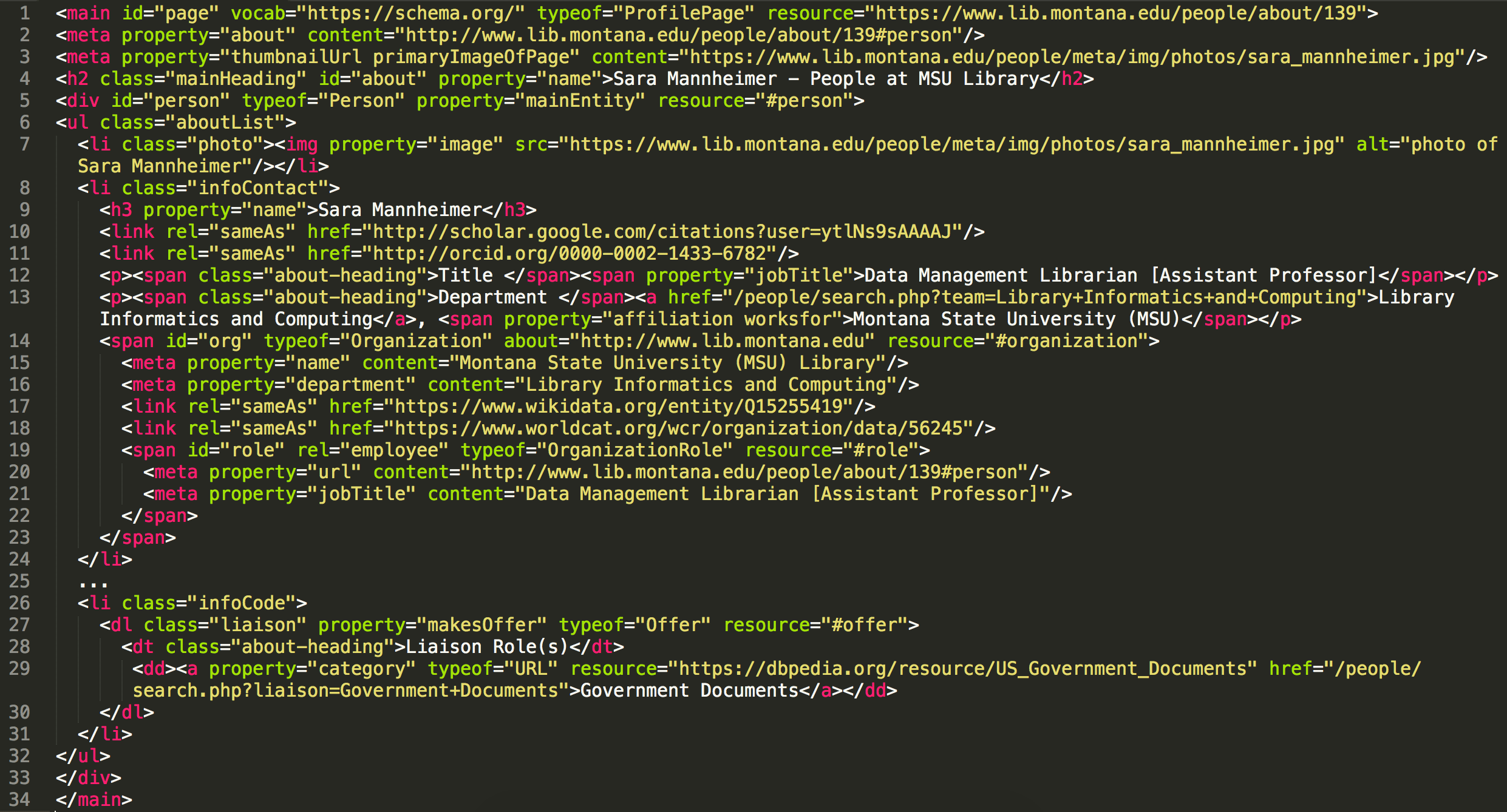
To the user, these pages perform as a typical web page allowing browsing and linking to related pages and people. But, in the HTML source, we encoded RDFa so that each staff profile is an expression of linked open data (Figure 3).
<main id="page" vocab="https://schema.org/" typeof="ProfilePage" resource="https://www.lib.montana.edu/people/about/139">
<meta property="about" content="http://www.lib.montana.edu/people/about/139#person"/>
<meta property="thumbnailUrl primaryImageOfPage" content="https://www.lib.montana.edu/people/meta/img/photos/sara_mannheimer.jpg"/>
<h2 class="mainHeading" property="name">Sara Mannheimer - People at MSU Library</h2>
<div id="person" typeof="Person" property="mainEntity" resource="#person">
<ul class="aboutList">
<li class="photo"><img property="image" src="https://www.lib.montana.edu/people/meta/img/photos/sara_mannheimer.jpg" alt="photo of Sara Mannheimer"/></li>
<li class="infoContact">
<h3 property="name">Sara Mannheimer</h3>
<link rel="sameAs" href="http://scholar.google.com/citations?user=ytlNs9sAAAAJ"/>
<link rel="sameAs" href="http://orcid.org/0000-0002-1433-6782"/>
<p><span class="about-heading">Title </span><span property="jobTitle">Data Management Librarian [Assistant Professor]</span></p>
<p><span class="about-heading">Department </span><a href="/people/search.php?team=Library+Informatics+and+Computing">Library Informatics and Computing</a>, <span property="affiliation worksfor">Montana State University (MSU)</span></p>
<span id="org" typeof="Organization" about="http://www.lib.montana.edu" resource="#organization">
<meta property="name" content="Montana State University (MSU) Library"/>
<meta property="department" content="Library Informatics and Computing"/>
<link rel="sameAs" href="https://www.wikidata.org/entity/Q15255419"/>
<link rel="sameAs" href="https://www.worldcat.org/wcr/organization/data/56245"/>
<span id="role" rel="employee" typeof="OrganizationRole" resource="#role">
<meta property="url" content="http://www.lib.montana.edu/people/about/139#person"/>
<meta property="jobTitle" content="Data Management Librarian [Assistant Professor]"/>
</span>
</span>
</li>
...
<li class="infoCode">
<dl class="liaison" property="makesOffer" typeof="Offer" resource="#offer">
<dt class="about-heading">Liaison Role(s)</dt>
<dd><a property="category" typeof="URL" resource="https://dbpedia.org/resource/US_Government_Documents" href="/people/search.php?liaison=Government+Documents">Government Documents</a></dd>
</dl>
</li>
</ul>
</div>
</main>
Figure 3. Machine-readable view of HTML RDFa for a staff profile (JSON-LD version also available for reference) (view as large image)
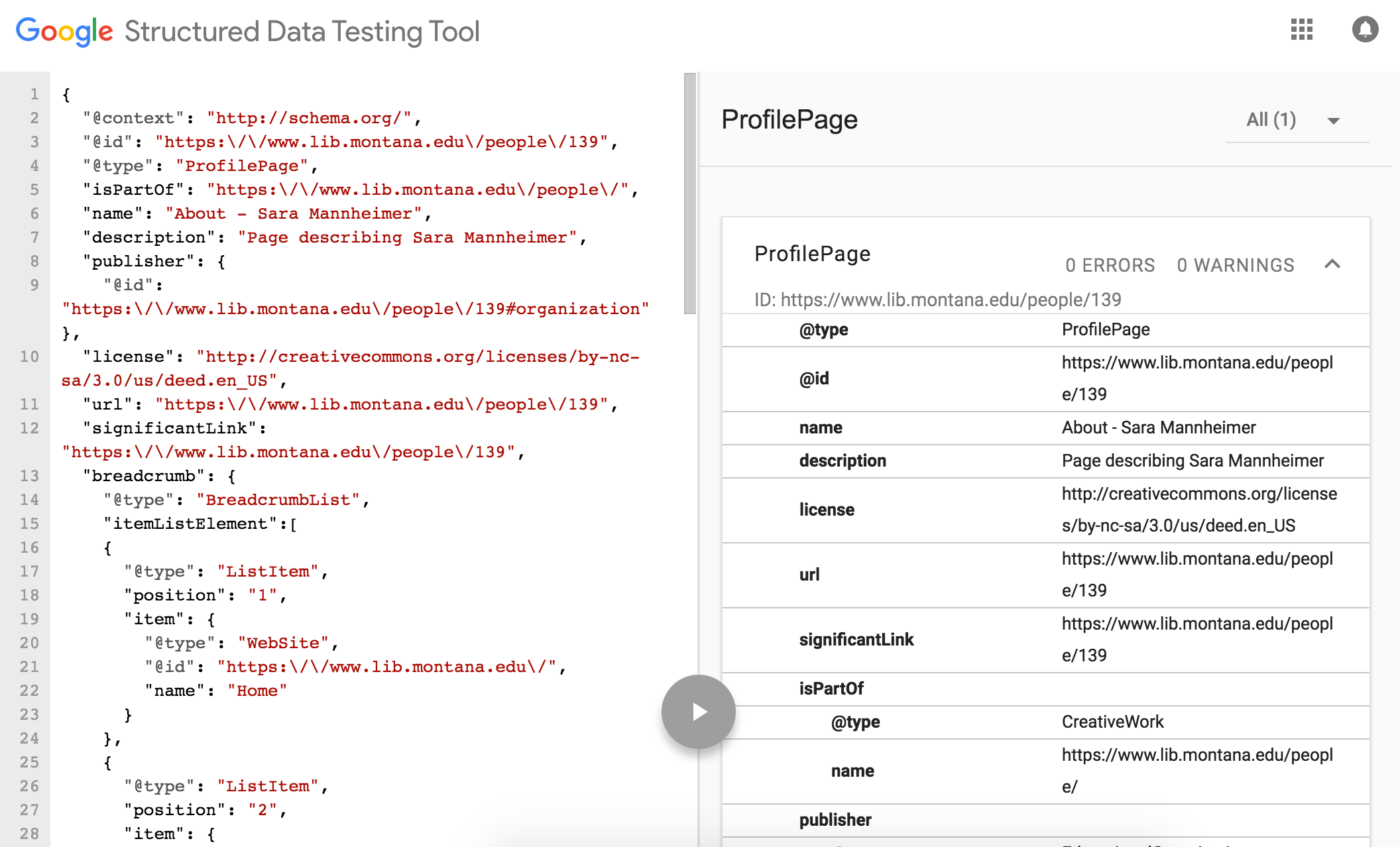
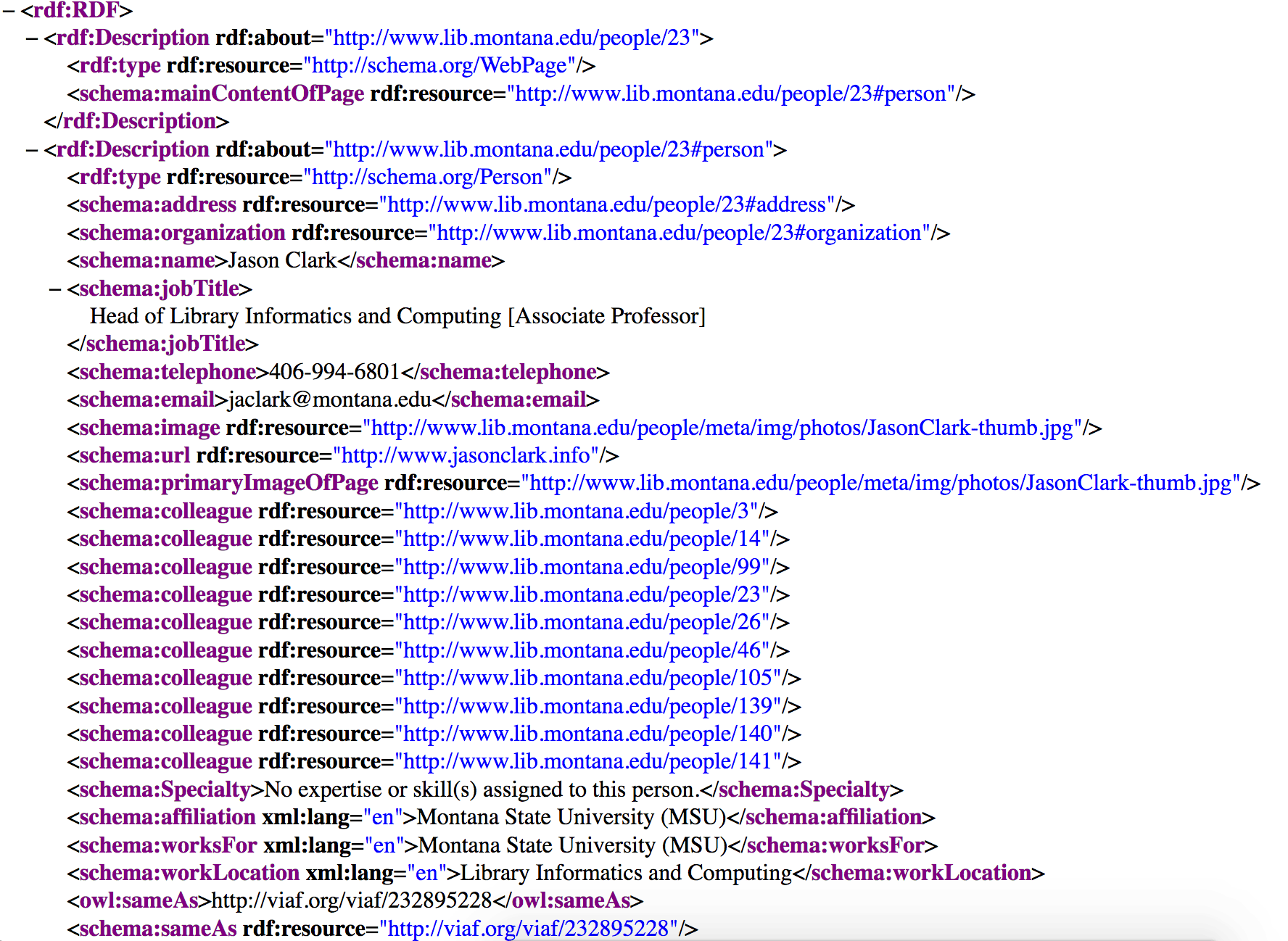
The data appears on the page and in the source via our database, but we tagged the data with rich structured data. A couple of highlights in the RDFa include: the definition of the page type as a ProfilePage, a disambiguation of the Person using a sameAs equivalency and the Orcid.org or VIAF identifier, addressable nodes for machines using a resource attribute and a URI #hash, and a mapping of liaison expertise using the “Offer” type. All of these encodings lead to a rich machine interpretation of the page where linked data entity expressions can be pulled and reused for linked data settings. And that might be the most compelling feature of this data model/encoding practice: the data exists in an agnostic format that can be transformed into alternative linked data expressions. For example, each staff profile page is also available as RDF/XML and JSON-LD. Below is the same profile page as JSON-LD interpreted by the Google Structured Data Testing Tool (Figure 4).
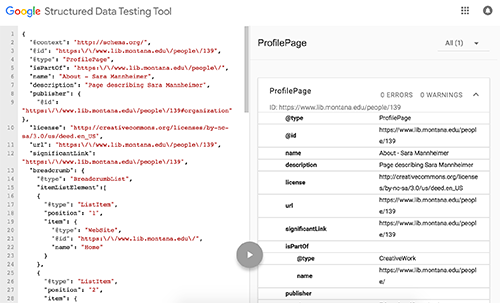
Figure 4. Structure data testing tool view of a staff profile page expressed as JSON-LD (enlarge)
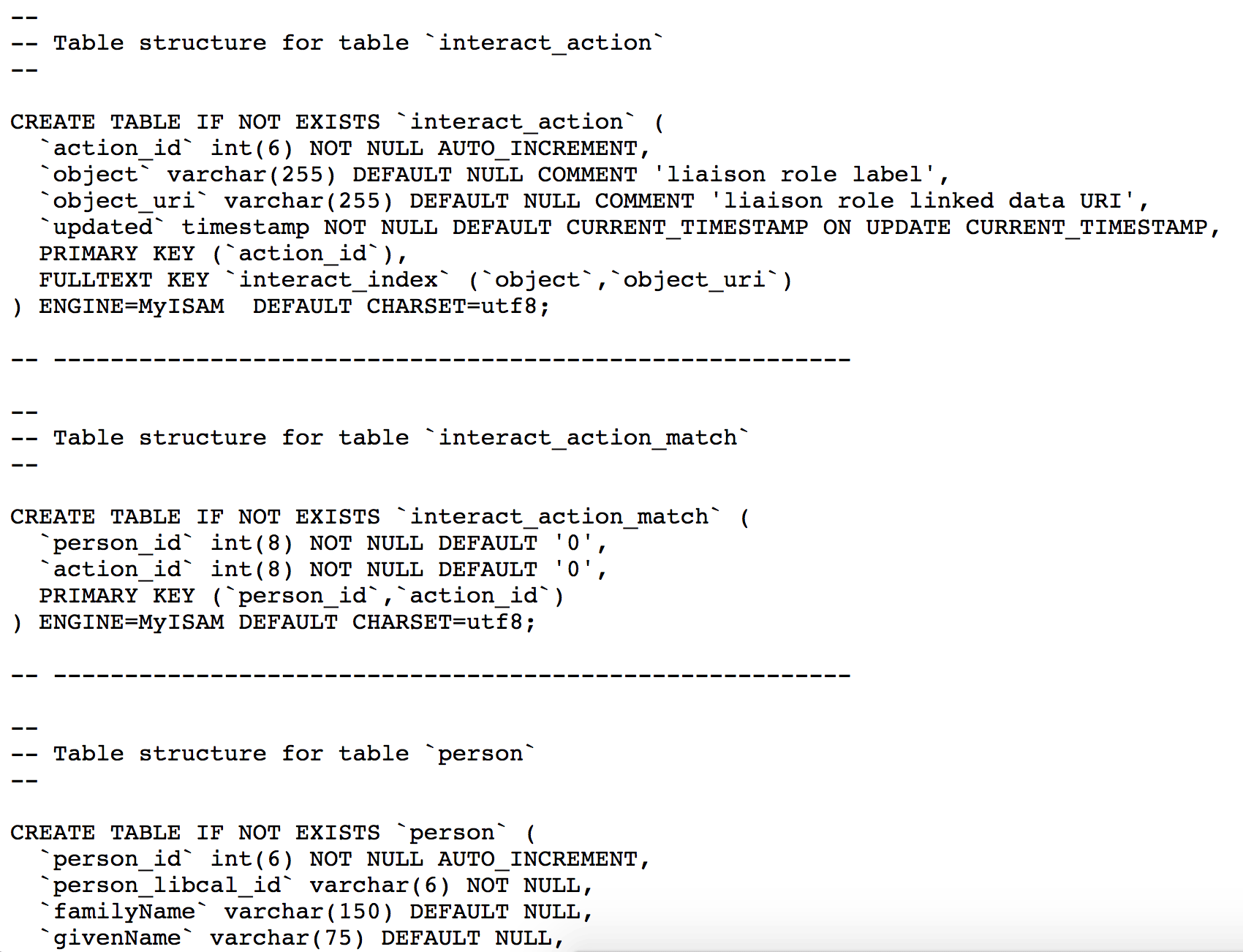
Again, we worked this graph model into a relational database setting with an emphasis on encoding the relationships that we saw as necessary to show our research networks and linked expertise topics. A snippet of the data model is available below (Figure 5).
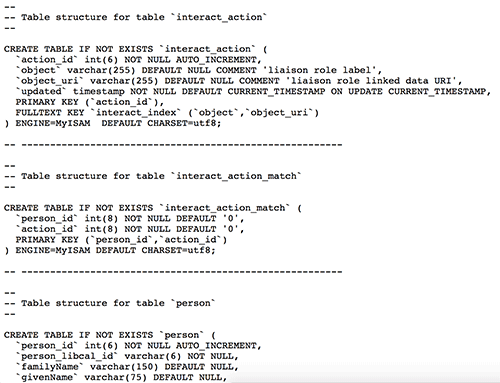
Figure 5. Snippet of Person entity connected to an Activity entity. The full data model is available in the corresponding linked-people GitHub repo (enlarge)
In the snippet, you can see the first few fields of the Person entity and its identifier (person_id), but the more interesting work here was finding a way to express the Action entity associated with the Person. The “interact_action” is borrowed from the Schema.org Action type and in this case the table stores the data and URIs to describe discipline and liaison relationships of our staff. You can also see how we created space for external vocabularies in the system using URIs in the “object_uri” field that are mapped to the equivalent resource URI in external LOD sources like DBpedia. We followed a similar pattern in a “create_action” table (not pictured here) to describe topical expertise relationships.
Impact
We expected to see certain results from our linked data work and this project produced impact in the following four aspects of our staff directory: web discoverability, user interface design and local search functionality, linked data implementation, and graph visualization.
Web Discoverability
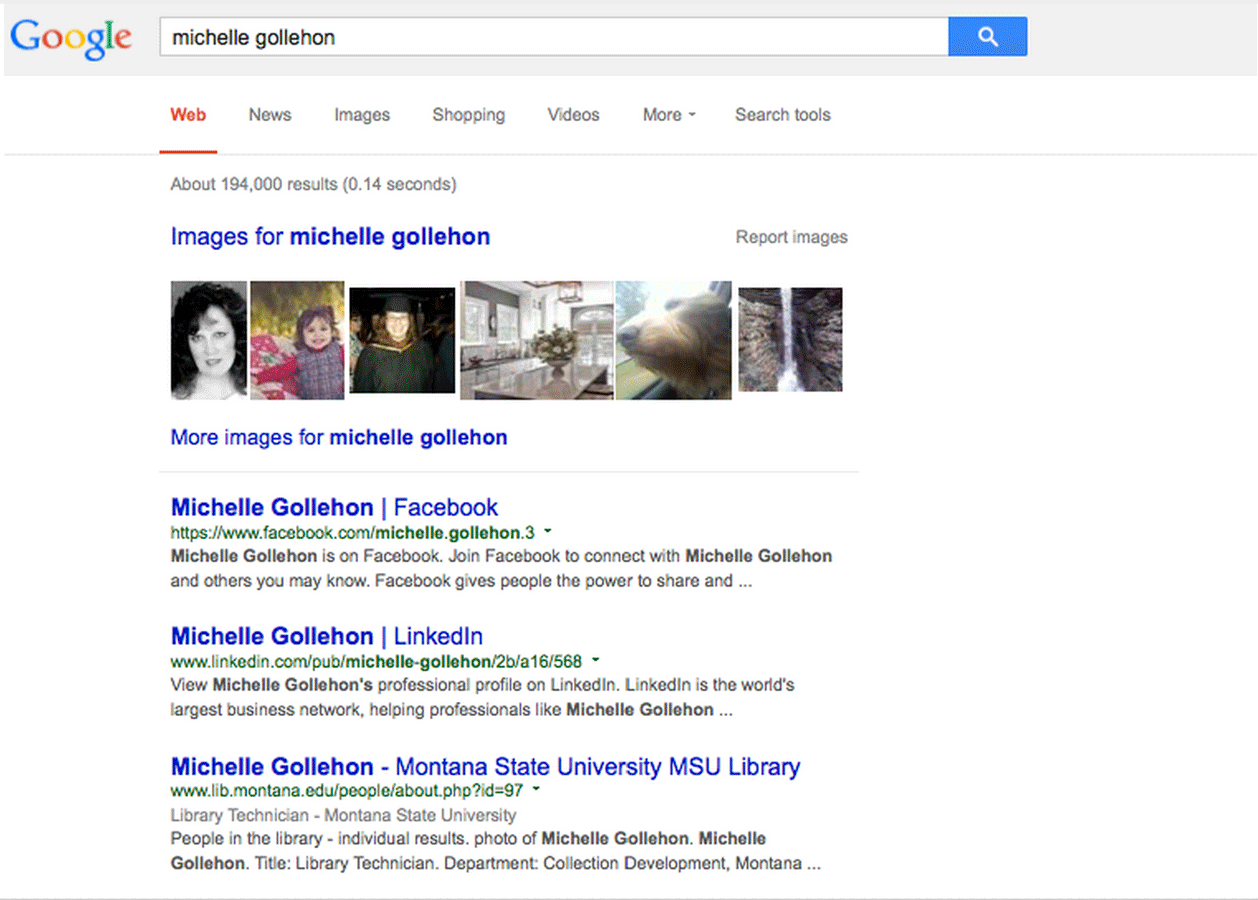
Structured data markup allows commercial search engines to parse and understand web content, and to deliver that web content accurately to users. By structuring our metadata with schema.org tags, our individual staff profile pages experienced a visible improvement in the search engine results page of today’s leading search engine, Google. We have included two examples below. In the first example, a search for our staff member Michelle Gollehon shows that her staff directory page appears in the third position, following a row of images and links to a Facebook page and a LinkedIn page (Figure 6). Following the implementation of structured data, a similar search places our staff directory page in the first position, followed by Facebook and LinkedIn (Figure 7).
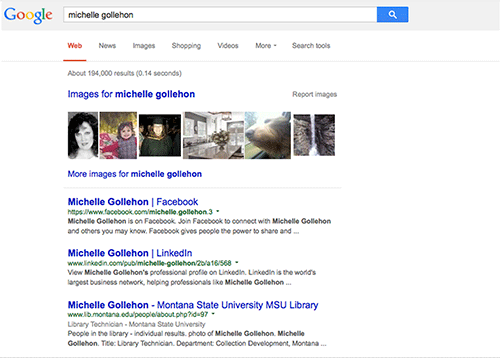
Figure 6. SEO before Linked People (enlarge)
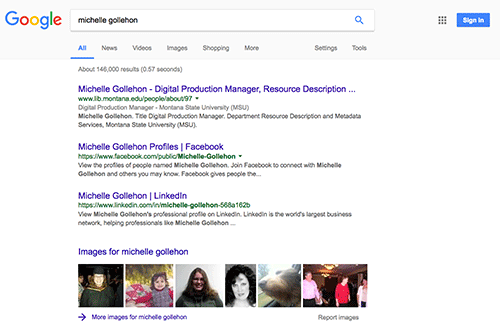
Figure 7. SEO after Linked People (enlarge)
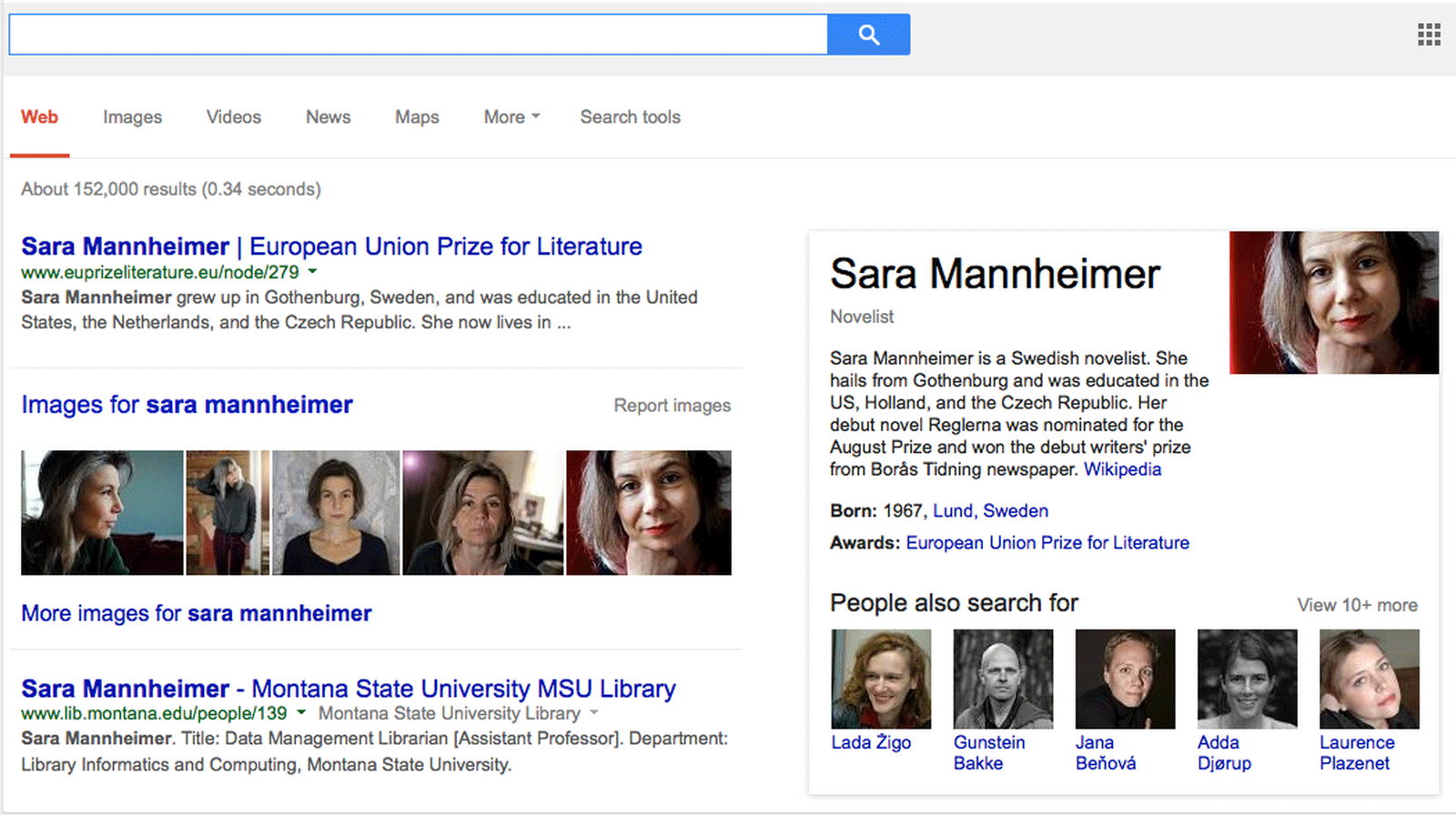
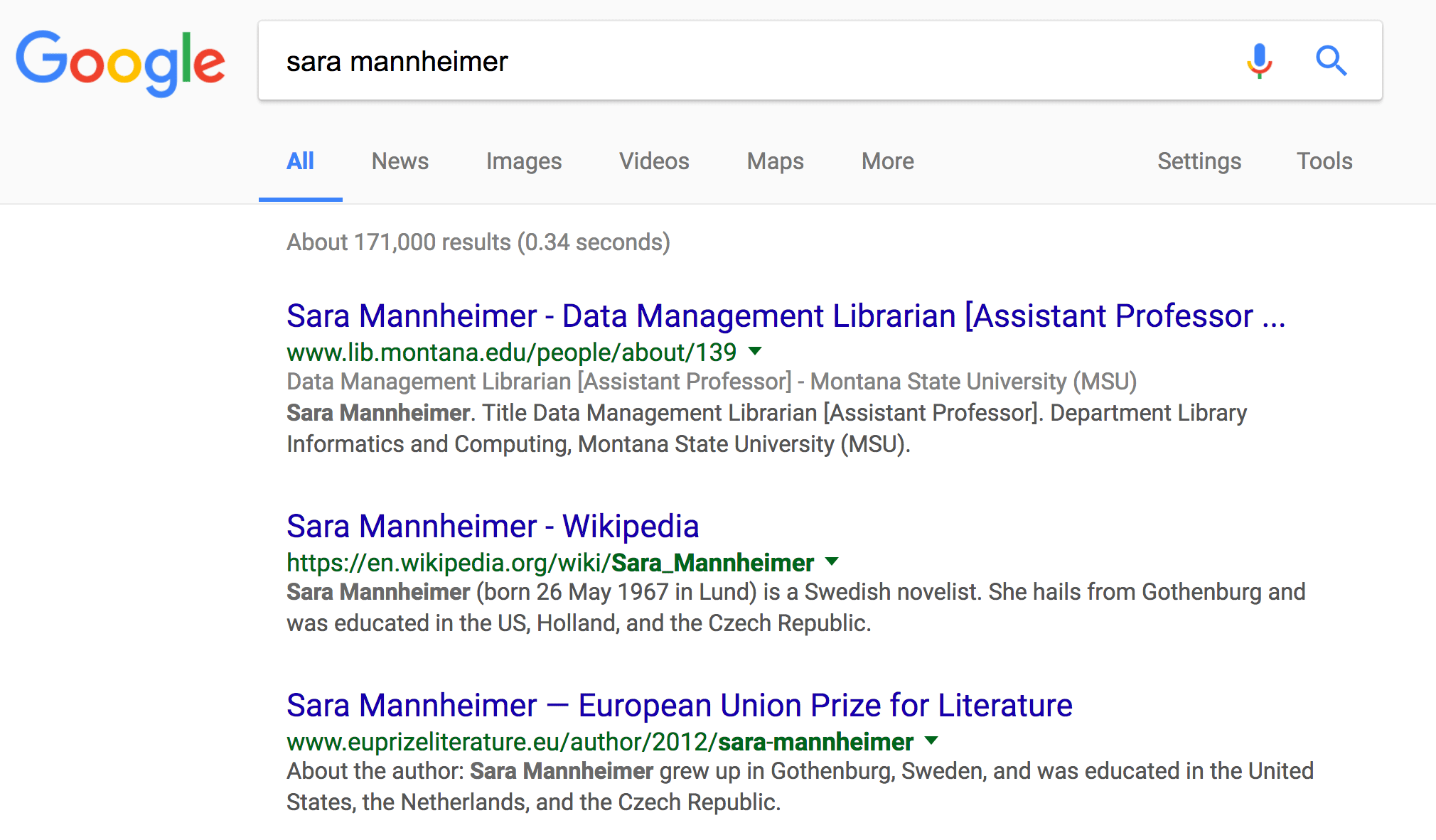
Likewise in our second example, a search for MSU Library faculty member Sara Mannheimer demonstrates a name ambiguity with Sara Mannheimer of Sweden, an award winning fiction writer (Figure 8). Sara Mannheimer of Sweden is a more prominent figure, so Google ranked the Swedish Sara Mannheimer ahead of the Montana Sara Mannheimer, even for searches originating from Montana. Following the implementation of structured data markup, the Google Search engine better understood Sara Mannheimer and her role as a faculty member at a Montana university, and consequently ranked our staff directory page higher than the Wikipedia page for Sara Mannheimer of Sweden (Figure 9). Our structured data also produced additional metadata about Sara’s role that now appears on Google search results pages, visible in grey text.
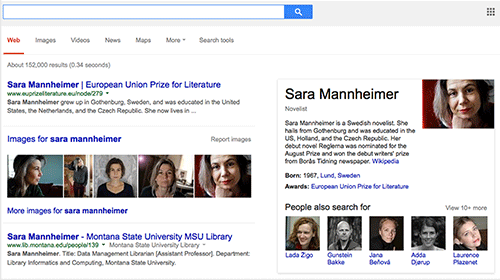
Figure 8. SEO before Linked People (enlarge)
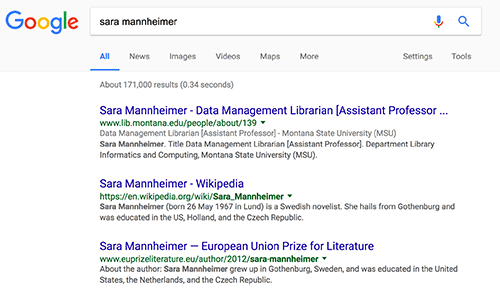
Figure 9. SEO after Linked People (enlarge)
Google Analytics reporting shows an increase in key metrics for our staff directory when comparing the Fall academic term of 2013 (August 26-December 13) with the Fall academic term of 2014 (August 25-December 12), representing pre and post periods for this project. Overall sessions increased by 280% (601 in Fall 2013 to 2,288 in Fall 2014) and overall visitors increased by 240% (530 to 1,801); inbound sessions from organic search increased by 436% (221 to 1,131), and inbound sessions specifically from Google Search increased by 441% (203 to 1,099). Google Analytics reporting from the Fall academic terms in 2015 (August 24-December 11) and 2016 (August 29-December 16) show that the gains in sessions, visitors, and search traffic have been sustained (see Table 1).
| Fall term 2013 | Fall term 2014 | Fall term 2015 | Fall term 2016 | |
| Sessions | 601 | 2,288 | 3,518 | 3,531 |
| Visitors | 530 | 1,801 | 3,178 | 3,146 |
| Sessions via Organic Search | 221 | 1,131 | 985 | 1,176 |
| Sessions via Google Search | 203 | 1,099 | 913 | 1,118 |
Table 1. Analytics Reporting for Montana State University Library Staff Directory, showing increased visits overall and increased visits from web search following the implementation of linked and structured data on Staff Directory web pages.
User Interface Design and Local Search Functionality
This project allowed us to link individual library staff with specific liaison and expertise areas. To provide end-user access to these connections, we developed a new user interface that now allows users to search and browse our staff directory via liaison area and expertise area. Our staff directory homepage previously lacked these points of discoverability (Figure 10), where now users are invited to “Browse by Liaison Area” and “Browse by Expertise Topic.” (Figure 11).
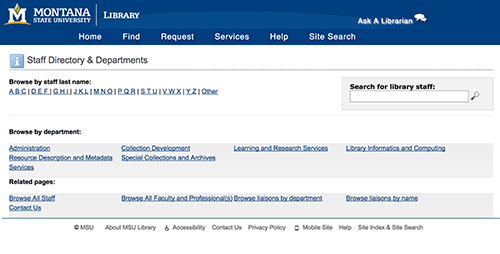
Figure 10. Staff Directory Homepage, before Linked People (enlarge)
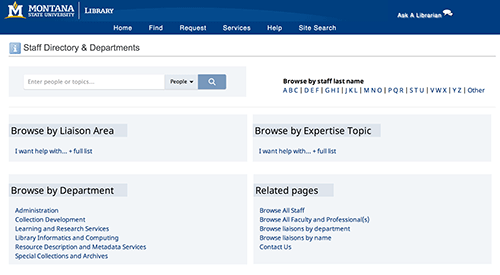
Figure 11. Staff Directory Homepage, after Linked People (enlarge)
Individual profile pages have also been enhanced to highlight the liaison and expertise areas of our staff (Figure 12; Figure 13). Our new staff directory pages allow users to find and contact staff members in ways that are relevant for their own work.
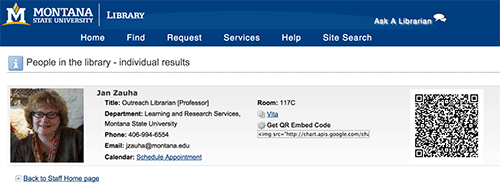
Figure 12. Profile Page before Linked People (enlarge)
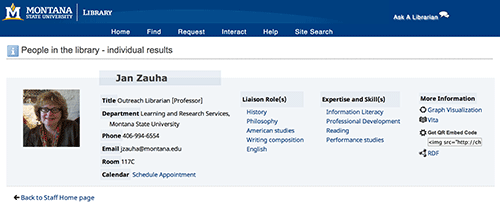
Figure 13. Profile Page after Linked People, showing connected Liaison Roles, Expertise, and RDF machine-readable link (enlarge)
Linked Open Data Implementation (Five-star LOD)
A primary goal of the project was the release of our staff data as five-star linked open data. This star rating is a formulation by Tim Berners-Lee from 2006 that outlines the steps to release open data. We had a goal of reaching the 3, 4, and 5 star ratings which state:
- 3 star – Make data available in a non-proprietary open format (e.g., CSV as well as of Excel).
- 4 star – Use URIs to denote things, so that people can point at your stuff.
- 5 star – Link your data to other data to provide context.
The various expressions – RDFa, JSON-LD, and RDF/XML – of our staff profile pages allowed us to achieve 5-star Linked Open Data.

Figure 14. RDF/XML of a staff profile page as an example of 5 star open data (enlarge)
When we generated and finalized our RDF/XML expression for each staff profile and linked to external URIs for context and description, our project became a linked open data resource at the 5 star level (Figure 14). And at this point, we are in a position to move beyond being a linked data publisher to a linked data user that can query and reuse the triples for further enhancements and analysis.
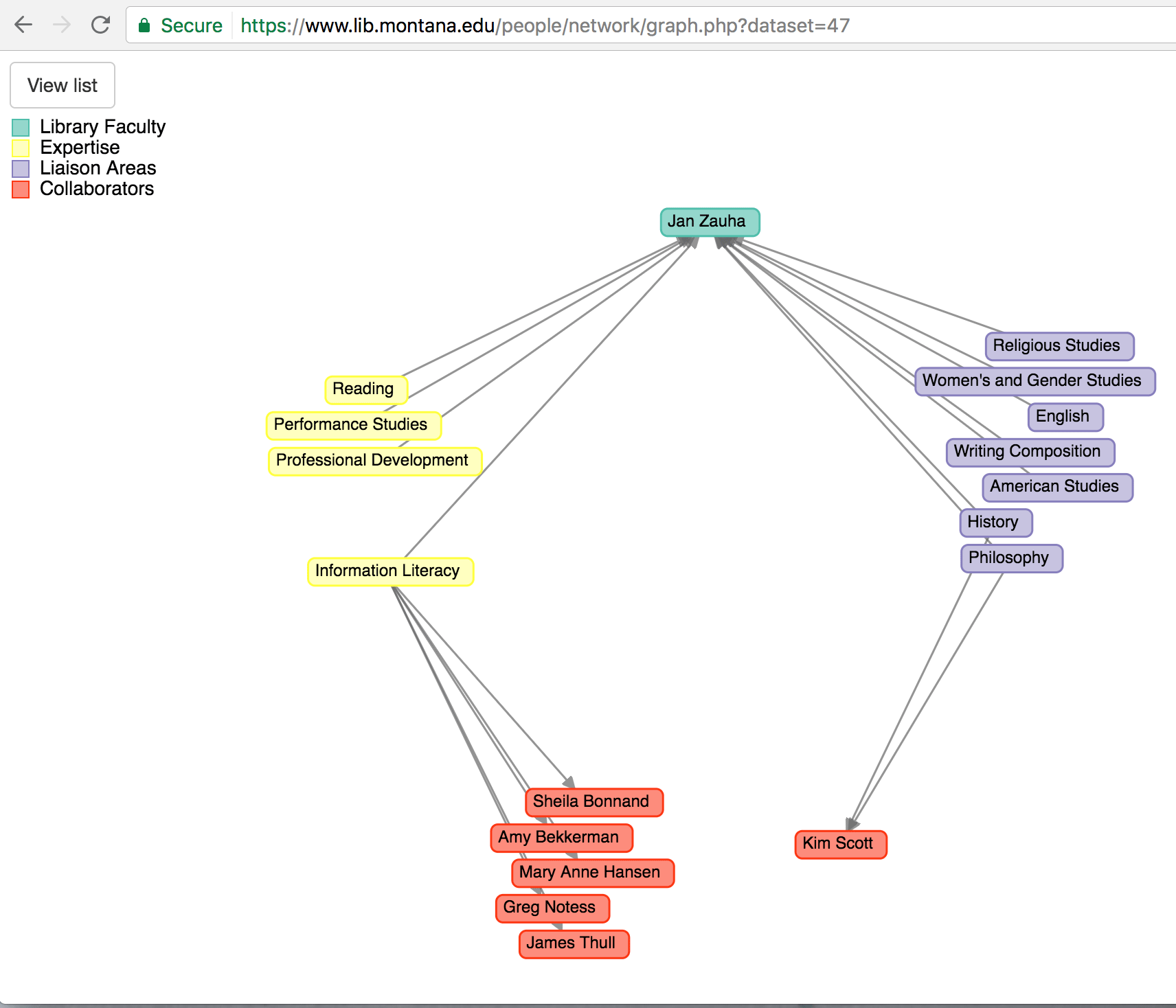
Graph Visualization
The fourth and final impact we saw from the project was around visualization. More specifically, we were able to produce a new method for visually browsing our staff members and their relationships. The d3.js library provides numerous options for visualizing a graph network, and we selected the “d3 process map”, a web app that integrated with our existing PHP scripting and uses a multi-field JSON object to generate data that also fit well into our RDF arrays. Using this d3 web app, we visualized the liaison and expertise areas for each of our faculty members (Figure 15). This graph allows us to illustrate relationships with faculty members who share liaison and expertise areas. [2] In our example in Figure 15, our faculty member Jan Zauha shares expertise in “Information Literacy” with five other librarians, and shared a liaison role with one other librarian.
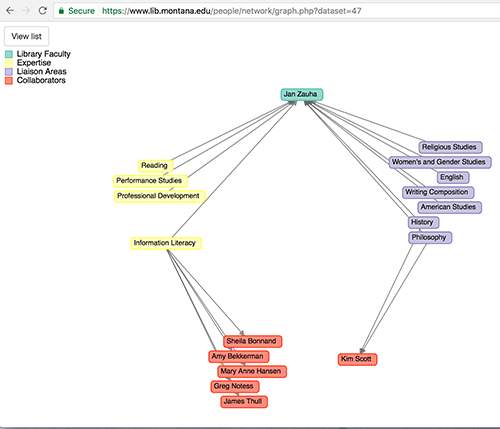
Figure 15. Graph Visualization for a faculty member at the MSU Library (enlarge)
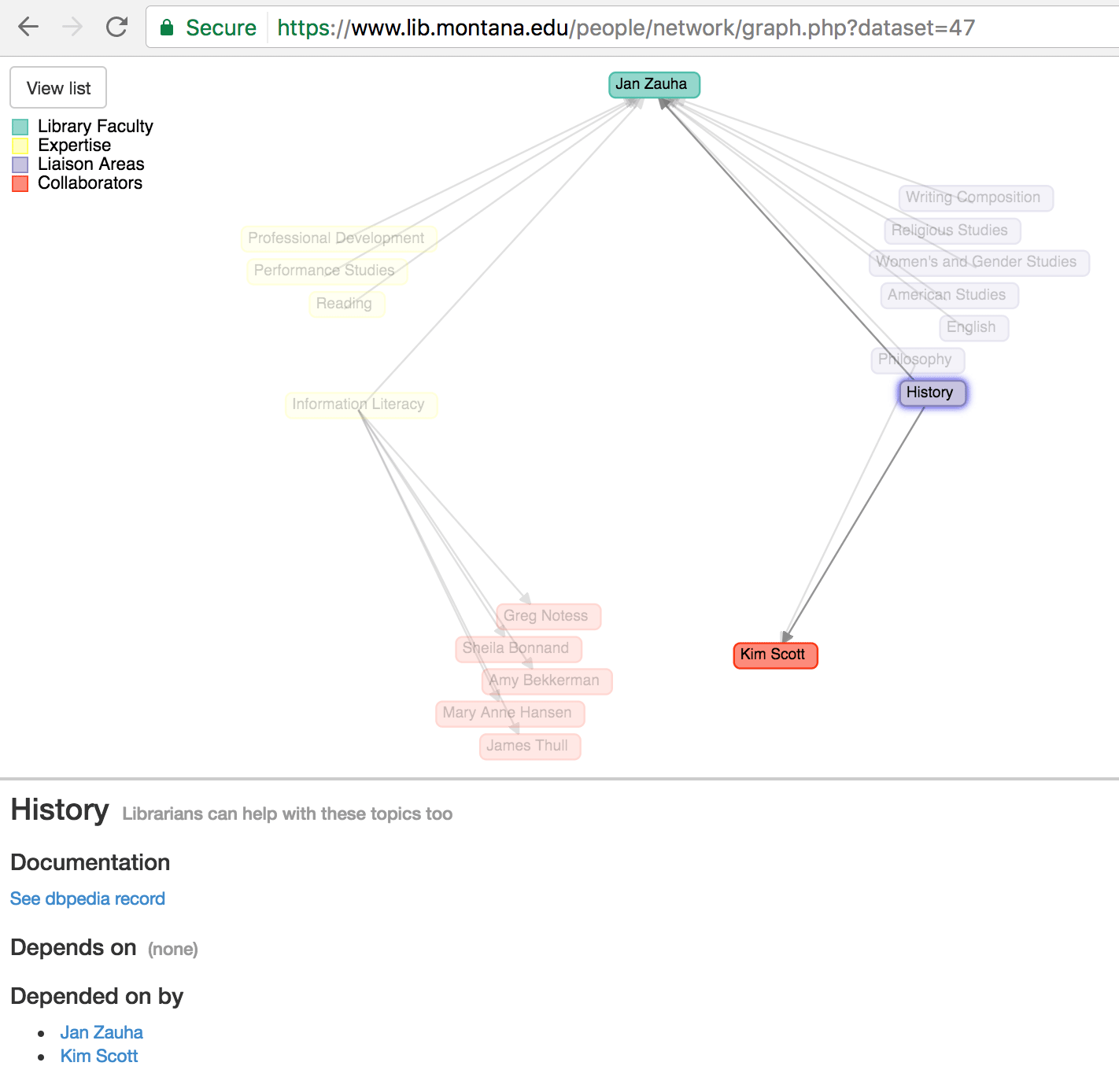
By clicking or tapping on a node, additional information connects users with the DBpedia record for a topic or the staff directory profile for a faculty member (Figure 16).
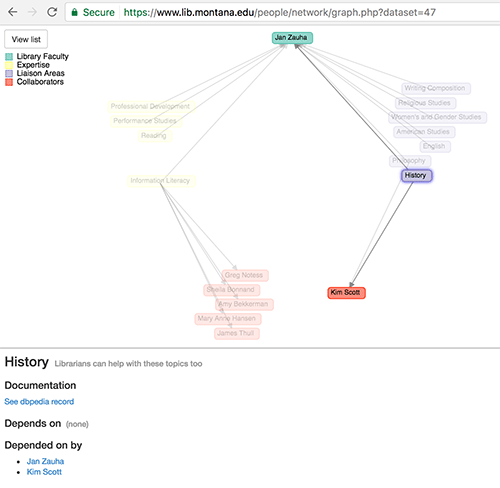
Figure 16. Graph Visualization for a faculty member at the MSU Library, showing node information (enlarge)
This graph visualization serves as an extension of our standard browse interface. Users can navigate through the network to discover new connections and relationships. Within the context of the project itself, the graph represents a working proof-of-concept for the application of linked data visualization for a library staff directory.
Conclusion and Lessons Learned
The work of this project was instructive and helped to build some new technical competencies for our library. In working through a linked data application and release into production, we became conversant in Semantic Web models and description practices, structured data markup, and network graph visualization. The smaller scope of a single dataset – our library people – gave us the chance to work in detail on a linked data model and build solutions towards specific goals.
Beyond these new skills, we recognized key lessons that any organization might see as takeaways from a similar project. First, think broadly about how these smaller projects can lead to future research. From this initial project, one of the writers was able to fashion a sabbatical project and a productive research thread. Second, there are advantages to building and prototyping in a simple format, like JSON-LD. Moving from the simple key/value format of JSON-LD into RDFa and RDF/XML is a much easier path because you can focus on sketching out the form of your expression without the complications of HTML nesting and or XML nodes. Third, don’t underestimate staff interest in describing themselves. A secondary goal of this project was to build interest and generate participation from our faculty and staff in owning their descriptions and definitions. In our initial proof-of-concept application, we worked from an abridged vocabulary based on our subject liaison topics and expertise. As the project evolved, we moved to a library-wide invitation where all interested parties could assign self-defined expertise topics to enrich the data model. The invitation was highly successful and left us wishing we had involved staff earlier in the process. Fourth, find standards that work with the grain of the Web. Our decision to use Schema.org was based on our interest in seeing libraries as publishers in the Web of Data, a recognition that machine-understanding of our data could lead to more relevance for library data and improved discoverability through search engines. Moreover, Schema.org’s backing by commercial search engines and wide implementation made for an easier learning curve due to ample documentation and examples. Even our choices to apply DBpedia, ORCiD, and VIAF were in recognition of the weight of the one of the most populated and popular LOD cloud data sources (DBpedia) and leading choices for researcher identification and disambiguation (ORCiD). And finally, we note that linked data practices and graph models can lead to better data models overall. The attention to detail needed to build and scope for disambiguation and connecting your data to external vocabularies enforces an intimacy with the data that isn’t always present in standard application development.
While Linked Open Data’s “killer app” may not yet have emerged, this project represents a contribution to the overall conversation around the practical application of Linked Data concepts and technologies. Most importantly with this project, we were able to realize a technical implementation of linked data that underscores what our library is about–the people who make the library happen–and conveys that “aboutness” to machines and humans.
Notes
[1] Code for the “Linked People” project is available under an open MIT license at https://github.com/msulibrary/linked-people
[2] Demo code for the visualization is available in our project GitHub repo at https://github.com/msulibrary/linked-people/tree/master/network
References
Allemang, Dean, and James A. Hendler. Semantic web for the working ontologist: effective modeling in RDFS and OWL. Waltham, MA: Morgan Kaufmann. 2011.
Beck, Fabian, Michael Burch, Stephan Diehl, and Daniel Weiskopf. “A taxonomy and survey of dynamic graph visualization.” In Computer Graphics Forum. 2016.
Bizer, Christian, Kai Eckert, Robert Meusel, Hannes Mühleisen, Michael Schuhmacher, and Johanna Völker. “Deployment of rdfa, microdata, and microformats on the web–a quantitative analysis.” In International Semantic Web Conference. Springer Berlin Heidelberg, 2013: pp. 17-32.
Devare, Medha, Jon Corson-Rikert, Brian Caruso, Brian Lowe, Kathy Chiang, and Janet McCue. “Connecting people, creating a virtual life sciences community.” D-Lib Magazine 13, no. 7/8 (2007). http://www.dlib.org/dlib/july07/devare/07devare.html
Graves, Mike, Adam Constabaris, and Dan Brickley. “Foaf: Connecting people on the semantic web.” Cataloging & classification quarterly 43, no. 3-4 (2007): pp. 191-202.
Goddard, Lisa, and Gillian Byrne. “The strongest link: Libraries and linked data.” D-Lib magazine 16, no. 11/12 (2010). http://www.dlib.org/dlib/november10/byrne/11byrne.html
Guha, Ramanathan V., Dan Brickley, and Steve Macbeth. “Schema. org: Evolution of structured data on the web.” Communications of the ACM 59, no. 2 (2016): pp. 44-51. http://queue.acm.org/detail.cfm?id=2857276
Meusel, Robert, Sebastiano Vigna, Oliver Lehmberg, and Christian Bizer. “Graph structure in the web—revisited: a trick of the heavy tail.” In Proceedings of the 23rd international conference on World Wide Web. ACM, 2014: pp. 427-432.
de Nart, Dario, Dante Degl’Innocenti, Marco Basaldella, Maristella Agosti, and Carlo Tasso. “A Content-Based Approach to Social Network Analysis: A Case Study on Research Communities.” In Italian Research Conference on Digital Libraries, pp. 142-154. Springer International Publishing, 2015.
Pasquaretta, Cristian, Marine Levé, Nicolas Claidiere, Erica Van de Waal, Andrew Whiten, Andrew JJ MacIntosh, Marie Pelé et al. “Social networks in primates: smart and tolerant species have more efficient networks.” Scientific reports 4 (2014).
Pattuelli, M. Cristina, Matt Miller, Leanora Lange, Sean Fitzell, and Carolyn Li-Madeo. “Crafting linked open data for cultural heritage: Mapping and curation tools for the linked jazz project.” Code4Lib Journal 21 (2013). http://journal.code4lib.org/articles/8670
Pattuelli, M. Cristina, Alexandra Provo, and Hilary Thorsen. “Ontology building for linked open data: a pragmatic perspective.” Journal of Library Metadata 15, no. 3-4 (2015): pp. 265-294.
Ronallo, Jason. “HTML5 Microdata and Schema. org.” Code4Lib Journal 16 (2012). http://journal.code4lib.org/articles/6400
Shulman, Jason, Jewelry Yep, and Daniel Tomé. “Leveraging the power of a Twitter network for library promotion.” The Journal of Academic Librarianship 41, no. 2 (2015): pp. 178-185.
Yoshimura, Karen Smith. “Analysis of International Linked Data Survey for Implementers.” D-Lib Magazine 22, no. 7 (2016). http://www.dlib.org/dlib/july16/smith-yoshimura/07smith-yoshimura.html
About the Authors
Jason A. Clark (jaclark@montana.edu) is an Associate Professor and Head of Library Informatics and Computing at Montana State University, specializing in web development, metadata and data modeling, web services and APIs, search engine optimization, and interface design. You can find him online at http://www.jasonclark.info and as @jaclark on Twitter.
Scott W. H. Young (swyoung@montana.edu) is an Assistant Professor and Digital Initiatives Librarian at Montana State University, specializing in user-centered design, web development, and community building with social media. Read more on his website, http://scottwhyoung.com.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply