by Kelly Thompson and Stacie Traill
Introduction
Over the past decade, vendor-packaged ebooks — once a small component of most academic library collections — have become staple resources. This transformation has come with substantial challenges for libraries in effective management of descriptive MARC metadata for ebooks. Challenges identified in the literature include quality control, completeness of coverage, scalability of workflows, and ongoing management. (Mugridge and Edmunds, 2012), (Traill, 2013). Solutions and workflows that address these problems are often both labor-intensive and specific to an individual library. Academic libraries ranging from small to very large have shared batch processing workflows for ebooks that vary widely, and largely focus on how to manage vendor-supplied MARC metadata. (Mugridge and Edmunds, 2009), (Martin and Mundle, 2010), (Wu and Mitchell, 2010), (Hodge, et al., 2013), (Sapon-White, 2014), (Chen, et al., 2016). Partial automation often plays a role in these workflows, especially for the tasks of record normalization, error checking, and access checking. (Lybarger, 2013), (Spurgin, 2014), (Fenichel, [accessed 2017]).
The recent emergence of library management systems (LMSs) that provide access to descriptive metadata for e-resources activated in system knowledge bases means that ebook management models are moving toward both greater efficiency and more complex implementation and maintenance choices. After many years of relying on vendor-supplied MARC records as the sole source of descriptive metadata for many ebook collections, the availability of other metadata supply streams is welcome. Records supplied directly by vendors have long been the most popular option for the provision of catalog and discovery access, often because such records offered the only feasible route for library discovery. The development of library services platforms, like Alma (Ex Libris) and WorldShare (OCLC), that integrate electronic resources management functions with traditional ILS functions means that multiple sources for e-resource metadata are now available to many libraries. But these choices come with serious implications for ebook management workflows: both the initial selection of a MARC record source and the ongoing management of ebook metadata streams present new challenges for many libraries. The integration of knowledge bases with linked MARC records into LMSs is intended to increase efficiency by eliminating the need to load (and periodically update or delete) MARC record batches for electronic resources. However, in practice, this integration means that libraries often have multiple options for procuring descriptive metadata for ebooks where previously there was only one choice. Depending on local standards and practices, metadata managers may need to evaluate multiple record sources for each new collection, because automatically-supplied records may not be the best choice for discovery and access. But there is a cost incurred if a library prioritizes using the best metadata, regardless of source: ongoing management for collections with non-LMS metadata sources must then be handled either manually or by processes outside the LMS. As ebook collections grow (and libraries’ staff shrink), management processes must also be scalable. Automated and data-driven processes for ebook management have always been desirable. In the current environment with its complex implementation choices and demanding maintenance workflows, automation is essential to make these choices and tasks manageable.
This paper will discuss the solutions to these problems currently in use at the University of Minnesota Libraries, where we rely on a combination of Python scripting and Alma’s batch import capabilities to manage MARC metadata for ebooks. We first present a use case in which Python scripts aid selection of the best metadata source among record providers offering a MARC record set for a given electronic collection. Sources evaluated include WorldShare Collection Manager (WCM), the Alma Community Zone (ACZ), and content providers that directly supply MARC records for their collections. Using “markers” or “flags” indicating record completeness, we are able to quickly determine aggregate quality of a record batch in order to make data-driven choices about the source of the metadata.
We also discuss Python scripts developed to assess record quality indicators once an automated workflow has been set up to import those records. Our case study involves both new records and record updates delivered from WCM via FTP and automatically imported into Alma. We will discuss how we programmatically evaluate record quality indicators and use them to split files into batches for either automated processing or human intervention. This process allows the majority of records to be loaded without any eyes-on work and produces manageable lists of problem records for manual investigation and remediation, allowing staff to spend targeted time on remediation activities with the highest impact on discovery and access.
Background
The implementation of Alma at the University of Minnesota Libraries (UMN) in late 2013 was followed less than a year later by OCLC’s shift to WorldShare Collection Manager for bulk record delivery as they began the phase-out of previous-generation record delivery services. Both of these systems are designed to provide discovery metadata for electronic resources activated in their respective knowledge bases: Alma does so by default for resources activated in its Community Zone, while WorldShare Collection Manager offers opt-in MARC record delivery of Worldcat bibliographic records linked to active knowledge base entries. By late 2014, it was clear to UMN staff that for at least some ebook collections, it would be necessary to choose a metadata source. What was not clear was how best to make those decisions.
The simplest solution for Alma libraries is to rely on the Alma Community Zone (ACZ) to handle both link resolution and discovery metadata whenever possible. However, as an early adopter of Alma, UMN chose not to take this approach, because the quality of ebook MARC records in the ACZ was generally very low in Alma’s early days. UMN had also been a heavy user of OCLC’s Worldcat Collection Sets to acquire ebook metadata, so when OCLC eliminated that service in favor of WorldShare Collection Manager (WCM), UMN implemented WCM MARC record delivery for ebook metadata previously sourced via Collection Sets. Of course, continuing to source MARC records directly from vendors is typically also an option (though in some cases vendors now work directly with OCLC to provide MARC records via WCM and do not provide records themselves).
With two or three possible record sources for each new ebook collection, we began routine manual evaluations (facilitated by MarcEdit) of MARC record files from each potential source before selecting one. Although this exercise was worthwhile, evaluations conducted via this method were time-consuming and necessarily incomplete, especially for large files containing thousands of records. Scripting offered a way to systematically and consistently evaluate every record in a file, and to generate rough quantitative measures that could be used for quick comparisons across files for the same collection from different sources.
Evaluating Record Completeness for Metadata Source Selection
Completeness is determined by evaluating files of MARC records from available sources (ACZ, WCM, vendor) with a Python script that checks for the presence or absence of several elements, and assigns weighted numeric values to each element. These values are added to arrive at a “total record score” for each record. The script is intended to be run as needed from the command line. It evaluates either every MARC binary file in the current working directory, or a single MARC binary file, based on console input.
Most elements were selected for automated evaluation based on UMN local guidelines for pre-import editing of MARC record files for ebooks (Traill, [updated 2017]). The guidelines were originally created following a project in which record sets from several ebook vendors were closely evaluated, and have been continuously updated. The UMN guidelines incorporate three major components: the results of the project described above, documented local discovery needs, and the Library of Congress’s Program for Cooperative Cataloging (PCC) provider-neutral guidelines (Program for Cooperative Cataloging, 2017). The script does not evaluate every element in UMN’s guidelines. Script-evaluated elements include most of those given in local guidelines that can affect end user discovery and/or identification of resources in UMN’s discovery layer, Primo.
Table 1. Completeness evaluation rubric
| Record Element | MARC field/position/subfield | How counted |
|---|---|---|
| ISBN | 020 | 1 point for each occurrence of field |
| Authors | 100, 110, 111 | 1 point for each occurrence of field(s) |
| Alternative Titles | 246 | 1 point for each occurrence of field |
| Edition | 250 | 1 point for each occurrence of field |
| Contributors | 700, 710, 711, 720 | 1 point for each occurrence of field(s) |
| Series | 440, 490, 800, 810, 830 | 1 point for each occurrence of field(s) |
| Table of Contents and Abstract | 505, 520 | 2 points if both fields exist; 1 point if either field exists |
| Date (MARC 008) | 008/7-10 | 1 point if valid coded date exists |
| Date (MARC 26X) | 260$c or 264$c | 1 point if 4-digit date exists; 1 point if matches 008 date. |
| LC/NLM Classification | 050, 060, 090 | 1 point if any field exists |
| Subject Headings: Library of Congress | 600, 610, 611, 630, 650, 651 second indicator 0 | 1 point for each field up to 10 total points |
| Subject Headings: MeSH | 600, 610, 611, 630, 650, 651 second indicator 2 | 1 point for each field up to 10 total points |
| Subject Headings: FAST | 600, 610, 611, 630, 650, 651 second indicator 7, $2 fast | 1 point for each field up to 10 total points |
| Subject Headings: Other | 600, 610, 611, 630, 650, 651, 653 if above criteria are not met | 1 point for each field up to 5 total points |
| Description | 008/23=o and 300$a “online resource” | 2 points if both elements exist; 1 point if either exists |
| Language of Resource | 008/35-37 | 1 point if likely language code exists |
| Country of Publication Code | 008/15-17 | 1 point if likely country code exists |
| Language of Cataloging | 040$b | 1 point if either no language is specified, or if English is specified |
| Descriptive cataloging standard | 040$e | 1 point if value is “rda” |
Element weighting is somewhat arbitrary. Records containing a large number authority-controlled subject strings (LCSH, MeSH, and FAST), contributors, and ISBNs receive high scores under this rubric, which we view as appropriate in light of the high impact these elements have on discoverability. Lower-weighted elements affect either retrieval in Alma or facets/filtering in our discovery layer, Primo, (e.g., 008 dates and language codes), or serve as general markers for record quality (e.g., the presence of “rda” in MARC 040 subfield e, and language of cataloging).
The code itself relies heavily on pymarc, “a python library for working with bibliographic data encoded in MARC21”, and regular expressions to parse and match values extracted from the MARC records (Summers, [updated 2017]). Once every record in a file has been evaluated and assigned a score, the script uses pandas, a Python data analysis library, to create a dataframe (a tabular data structure) and calculate the mean score and standard deviation for the file. The script outputs a CSV file for each MARC file processed (pandas … , [updated 2017]). The CSV is meant for human review, and includes mean, standard deviation, and the total score for each record, along with the score for each evaluated record element.
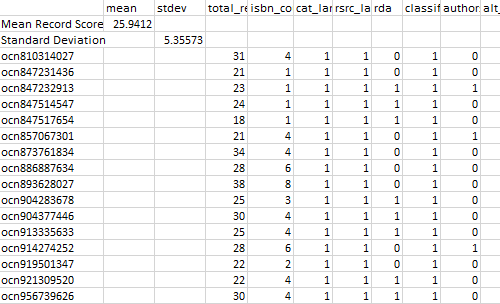
Figure 1. CSV output for a script-evaluated file
Completeness Evaluation Results for Selected Ebook Collections
UMN began using the completeness evaluation script in Spring 2017. Since then, we have used the script to select a record source for 11 newly-acquired collections. In most cases, three potential sources of MARC records were available. For two collections, only ACZ and WCM were options, while for two other collections, records were available only from either WCM or the content vendor. All of the MARC files from each source were evaluated with the completeness script.
Table 2. MARC record availability per collection/package
| Collection | Vendor | ACZ | WCM |
|---|---|---|---|
| A | Yes | Yes | Yes |
| B | Yes | Yes | Yes |
| C | Yes | Yes | Yes |
| D | Yes | Yes | Yes |
| E | Yes | Yes | Yes |
| F | No | Yes | Yes |
| G | Yes | Yes | Yes |
| H | Yes | Yes | Yes |
| I | No | Yes | Yes |
| J | Yes | No | Yes |
| K | Yes | No | Yes |
We have added additional features to the script to incorporate comparison of many collections across record sources. We use matplotlib, “a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments”, to read data from the pandas dataframes created in the analyses above and plot it in grouped bar charts (Matplotlib … , [updated 2017]). These visual representations of our data give us a snapshot view of record quality across sources and collections. The graphs presented here were inspired by forum responses on Stack Overflow and a blog post by Chris Albon. (How do I plot…, [updated 2012]), (Albon, 2016)
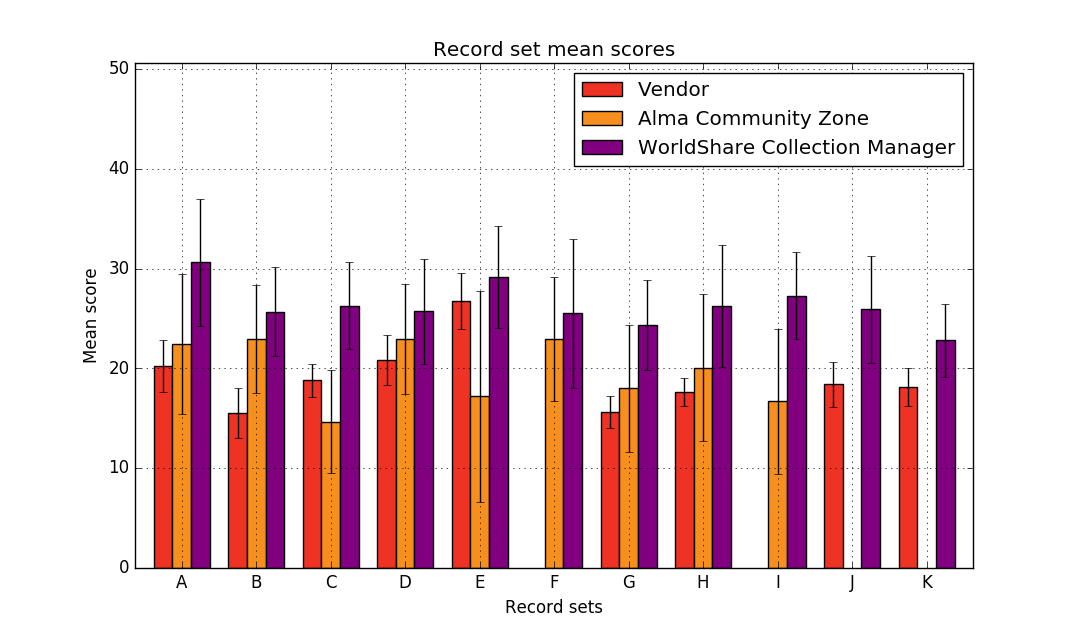
Figure 2. Mean record scores by collection
Figure 2 shows record mean scores (with error bars representing standard deviation) grouped by collection. This graph is useful in visually comparing record sets on the collection level, in order to select a record source for a particular collection.
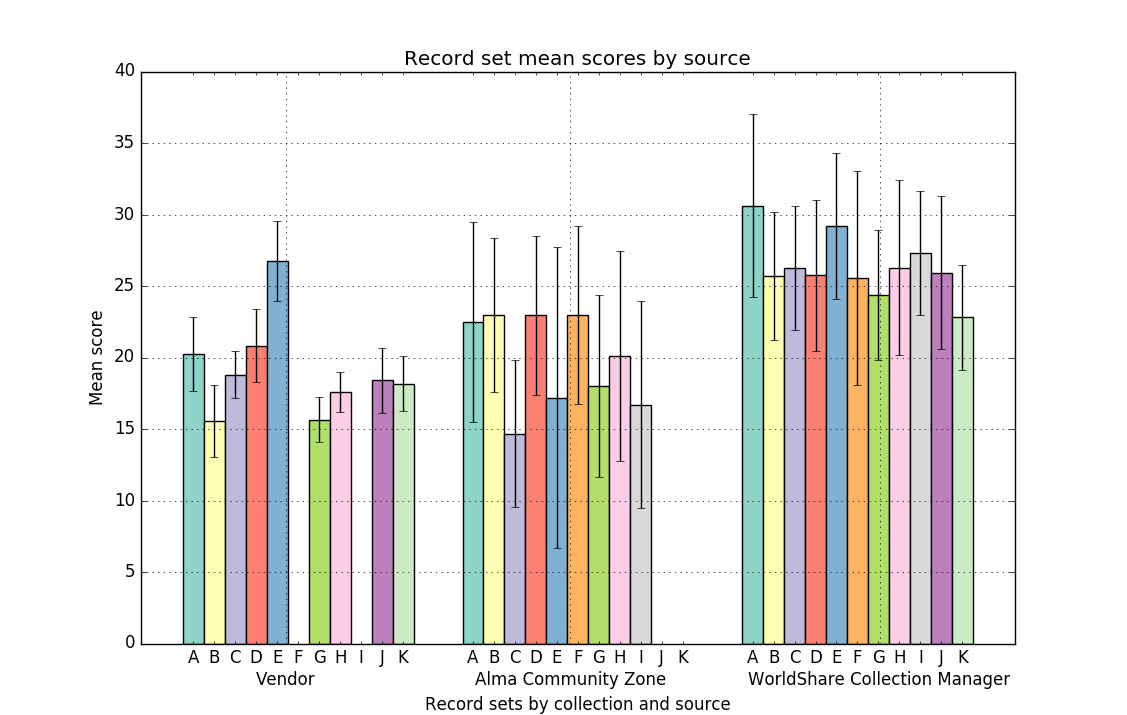
Figure 3. Mean record scores by source
Figure 3 shows record mean scores (with error bars representing standard deviation) grouped by record source. This graph is useful for visually comparing record sources on the record provider level. This helps us to get a sense of how our various record sources compare against each other holistically, beyond a single collection.
Table 3. Overall means of mean record scores by record set source
| All Vendor sets | All ACZ sets | All WCM sets | |
|---|---|---|---|
| Mean of all collections’ mean quality scores | 19.1 | 19.8 | 36.3 |
| Mean of all collections’ standard deviation among scores | 2.14 | 6.75 | 5.19 |
One insight is that it is important to consider not only the mean quality scores of a record set among different sources, but also the standard deviation within the sets. For example, the mean scores for vendor-provided record sets were comparable to that of Alma Community Zone records (an average of 19.1 points for vendor records and 19.8 points for ACZ records.) However, the standard deviation of the record scores in the Alma Community Zone sets was on average 6.75 points, compared to 2.14 for the vendor records. This data supports a gut assumption based on our previous hands-on examination of individual record sets that the quality of vendor supplied records tends to be more consistent within title sets than those from the Alma Community Zone (for example, vendor records tend to either all include an element or all lack an element, whereas records in the community zone could be quite different from each other). We surmise this is due to a variety of factors, most notably that vendors tend to use record creation methods that lead to very uniform records, whereas records in the ACZ are from a variety of sources. Some ACZ sources offer fairly rich descriptive metadata, while some records — mostly those generated automatically from knowledge base metadata — offer very minimal metadata.
These results clearly show why we have most often opted to use WCM as a metadata source when multiple sources are available. The WCM records sets consistently had high mean quality scores (here the average was nearly twice that of comparable sets from vendors or the ACZ, at 36.3 points compared to 19.1 and 19.3), and the standard deviation within the sets was comparable to that in the ACZ (5.19 and 6.75, respectively), indicating that the WCM set is not more variable due to a few high-scoring outlier records.
Using WCM with Alma in this way, however, means sacrificing some of the efficiency of Alma’s built-in e-resource management functions. This is a significant trade-off for the anecdotally positive, but as-yet-unquantified, improvements to user discovery we learn about via feedback from users and public services staff. But with some effort, we have been able to automate large parts of the WCM record management workflow, which means the reduction in efficiency (versus relying on automatic management via the ACZ) is much less than it would be otherwise. Although the initial implementation was challenging, WCM record delivery works well for the most part with Alma’s facilities for automating and scheduling MARC record import jobs. The next section of this paper will discuss how we use Python scripts for intermediate processing between WCM’s automated MARC file generation and Alma’s automated import jobs.
Record Quality Evaluation for WCM Delivered Records
Once we have selected WCM as a record source for a collection, we follow our procedures for activating the collection(s) in WCM and creating automatic import profiles in Alma to ingest these records. In WCM, settings are configured to automatically add and remove fields in the MARC records in order to follow local practices. For record updates, WCM enables the configuration of the record output to include a field stating the reason for the record update. This field is essential to our workflow for splitting updates files before upload, which we discuss further below. Daily, weekly, or monthly record delivery is scheduled on the collection level, and we schedule the automatic collection-level import profiles in Alma to run on a complementary schedule. While the process for importing and evaluating new record batches and updates are very similar, there are some key differences.
New Records
For new records, we configure the Alma import profile to pick up the record batches with file names containing “new” directly from the OCLC FTP server without any intervention on our part first. The rationale for this is that it is better to provide access as soon as possible and then clean up any issues that might impact optimal discovery when time permits.
Updates to Records and OCN merges
For updates to records (including changes to OCLC control numbers(OCNs) due to record merges), we use Python scripts to first pick up the files from the OCLC FTP server with file names containing “updates” or “merges”, assess and split out the files, and then only put files without serious issues back on an FTP server for the Alma import profile to pick up. A staff person regularly processes any records that could not be automatically imported. The rationale for this order of operations is because the record is an update, we assume we are already providing access to the resource with the record originally delivered, and that any updates are “bonus”. Because some of the updates have caused interruptions to service (multi-volume records with multiple URLs are not handled well by the WCM-to-Alma ecosystem, for example), in order to “first, do no harm”, we have decided to first process the records, even if that creates a small delay, and then import them into the system.
Evaluation and Output: What, Why, and How
The goal of the scripts detailed in the first part of this paper were to use markers within MARC record sets from different sources with the goal of selecting a record source based on aggregate collection quality. Once a record source has been selected, our focus gets a bit more granular, from the forest to the trees themselves. The scripts we run to evaluate records delivered from WCM aim to identify records that might cause problems we know to be common with this record source. The specific issues we look for vary between the new records and record updates, and we’ll discuss those in the next two sections. Like our record selection script, these scripts rely heavily on pymarc and pandas libraries, and script outputs are either CSV reports or MARC record files, as detailed below.
New Records
In evaluating new records, our primary goal is to identify records that may not match our record quality benchmarks. The three questions our scripts answer for each record are:
- Is the record truly for an electronic resource, or does the record describe a print resource?
- Is the record duplicated in the set or does it seem to indicate that it might be a record for a multi-volume set? (In either case someone would want to check to make sure the URLs are properly imported without overwriting themselves.)
- Is the language of cataloging for the record English?
The script also currently identifies records likely not cataloged in RDA as well as records without any kind of subject classification (call number or subject heading), but we are currently not doing any remediation on these records.
Because we have already selected the collection, we are not focused on overall record quality; we are mainly concerned with critical issues that have caused problems with discovery or access in the past at the new record import stage. As we mentioned above, these records should all have already been imported into Alma; these are post-ingest quality measures. Corrections or changes are typically made at the global knowledge base level (WorldCat and/or WCM), then imported into our local system (either waiting for the update to be delivered, or overlaying manually if the need is critical).
The script picks up the MARC record files containing the text “new” from the appropriate directory on the FTP server, and based on the three above categories, splits the files into three separate files of MARC records.
To gain insight into the selected record characteristics, the script uses pymarc functions to read a number of fields in the delivered MARC records that it then evaluates against a list of expected or acceptable values. For each characteristic, if the value found in the record matches the expected value we want, a value of 1 is assigned to the attribute. If it does not match the expected value, a value of 0 is assigned. The sum of all scores related to a specific characteristic is calculated. This pseudo-weighted score is compared to a benchmark value so the script can “decide” whether or not the issues with the record are critical enough to be put on a remediation list. Data is stored in a pandas dataframe and written to CSV as reports.
Table 4. Automated evaluation of WCM-delivered new records
| Record characteristic | Fields evaluated and scored (assign 1 if value meets expected, otherwise assign 0; sum scores) | Weighted score needed to trigger reporting for remediation |
|---|---|---|
| E-resource or print? | 006 positions 0, 6, 9 = mod
007 positions 0-1 = cr 008 position 23 = o 300 $a description includes “1 online resource” 337 $a = “computer” 338 $a = “online” |
<4/6 |
| Duplicate or multi-volume? | OCN matches another OCN in record batch
300 field contains “vol” or “v.” |
If repeats, indicate duplicate
If contains, indicate potential multi-volume |
| Language of cataloging | 040 $b = “eng” | =0/1 |
| RDA cataloging | 337 present ; 338 field present | =0/2 |
| Classification/Subjects | Call number (one or more of 050, 060, 070, or 090 present) ; subject headings (one or more of 600, 610, 611, 630, 650, 653 present) | =0/2 |
The output of this script is a list of records (OCLC numbers) in the batch sorted into CSV files based on what kind of human attention is needed. This script currently generates three files: a file of the actual values found in the records, a file that presents all scores and an overall sum score for each record (this file indicates which records are likely to be for print resources or have a language of cataloging that was not English), and a file indicating records that may be duplicates or multi-volume sets.
The script output is a report format instead of record files because the records should all have already been automatically loaded into Alma via FTP, and the records didn’t need to be sorted again. The reason for grouping the outputs in this way by these characteristics has to do with how the reports are then manually processed.
The reason that records flagged as possibly describing print resources or as having a non-English language of cataloging are grouped together in one output is that they would potentially be remediated by making a global edit to the WorldShare knowledge base. Within most WCM collections, libraries can assign a different OCLC control number (OCN) to represent a given resource in a collection. If the record provided does indeed describe a physical resource and there is a record in OCLC which describes the electronic version, we will update the WCM knowledge base with the proper OCN for that resource. For records cataloged in a language other than English, often the record simply does not have a $b in the 040 field, so we will update the master record in OCLC. If it was truly cataloged in a non-English language, and an English cataloging record exists, we will update the OCN in the WCM knowledge base as appropriate. If the impact on discovery seems critical, the record can be overlaid or imported from OCLC immediately; otherwise we just wait for delivery of the updated record. Neither of these errors is very common anymore, but when we first set up WCM, it was a more pervasive issue.
The potential duplicates and multi-volume sets are grouped together because these are issues that could potentially lead to problems with electronic inventory in Alma. Any manual remediation related to these records is done directly in Alma (for example, by updating URLs in Alma portfolios).
Updates for Existing Records
In evaluating updates delivered for records we have already loaded into Alma, our primary goal is to identify why a record update was sent so that we can merge the record into Alma appropriately. As mentioned above, WorldShare Collection Manager has a feature wherein you can export the “reason for update” data in your record output, making this otherwise impossible task feasible. Our record delivery is configured so that this information is placed in a 960 field, so the script evaluates the value of only that specific MARC field. The main types of reasons for updates to records that we see are:
- Changes to bibliographic records which are descriptive in nature, not related to an identifier or access URL change.
- OCN updates (This indicates the same record in OCLC has a new OCLC record number, or has been merged with another record. As of August 2017, these records are actually being delivered in their own files, which are distinguished with the text “merges” in the file name. We process these files with the same script; we just added regular expressions so the script will recognize these files as files to be evaluated along with the “updates” files. Also note that these OCN updates are different than changes to the WorldShare knowledge base which involve using a different record for the same resource. These changes are typically handled by WCM sending a delete file with the old record and then providing the new preferred record with the new record batch. We talk more about this in the “WCM Deletes Processing” section at the end of the paper.)
- Knowledge base URL changes
The script picks up the MARC record files containing the text “updates” and “merges” from the FTP server, and based on the three above categories, splits the files into three separate files of MARC records.
The first category, the descriptive changes category, is the easiest to deal with. Those records are considered “ready for FTP”, and are placed back on an FTP server for a scheduled Alma import profile to automatically retrieve and ingest. Currently these files are manually moved to the server because the scripts are run on a desktop computer and we had security concerns; however, when the scripts are running on our server, we will automate this step. If a library did not have access to a server, they could also manually upload these files for ingest into their LMS.
The second category of record changes, OCN updates, are also placed in the “ready for FTP” record file along with descriptive changes, but they are also duplicated in a second file so that a staff member can verify that the identifier change was successful. We have yet to find an error in this process, so we are considering eliminating this step; however, we are establishing an active OCLC synchronization process to keep our holdings up-to-date, so we try to practice the most effective “OCLC number hygiene” that we can while still automating as much maintenance as possible.
The third category, URL changes, is the most tedious to deal with and requires manual handling. Due to the way that Alma’s import profiles handle inventory updates, the current software only supports overwriting any portfolios (the inventory unit via which URLs are attached to bibliographic records in Alma) already existing on the record. Because the data from WCM do not indicate if the URL change is an update to a URL for the same resource, an addition of the next volume in a multi-volume set, or a false update (where the URL isn’t a new addition and hasn’t changed from a previous version, but is being sent labeled as a “KB URL Update”), we can’t sort the file any more granularly than “something with the URL(s) might be different”. Any remediation of these records is done manually, directly in Alma.
Multiple Delivery Frequencies, One Script
Because different collections change at different rates (for example, a perpetual access collection might hardly ever have new additions or significant changes, whereas a medical reference resource might change every day), WCM makes it possible to configure your record delivery at different intervals to suit these needs. We currently have various collections set on daily, weekly, and monthly record delivery frequencies. Each of these files is then output with a letter coded in the file name indicating if it is a daily, weekly, or monthly delivery. In order to process files on the most efficient basis, delivery frequencies are not handled separately. Two total scripts run as part of this process: a script for daily, weekly, and monthly “new” files; and a script for daily, weekly, and monthly OCN “merge” and “update” files. When we were developing this process, we used six separate scripts (one each daily, weekly, and monthly per file type), but have since streamlined this so the scripts just pick up records of any delivery frequency when they are run daily.
Alma ingest profiles for new records require a more specific schedule frequency (daily for daily record deliveries, weekly for collections with weekly delivery). We run the profiles for monthly deliveries weekly, to ensure that files do not sit unprocessed on the server for a month if the import profile misses it by a day. This specificity is mostly because Alma requires a separate import profile for each collection if the profile creates inventory, because the profile must be linked to a single electronic collection in which the inventory items (portfolios) are stored and maintained. For merges and updates, we have two import profiles, one to handle each type of file. These profiles make changes only to existing bibliographic records (matching on OCN) and never create or update inventory, so they do not need to link to any specific inventory collection. Separate import profiles for the “updates” and “merges” are needed only because each import profile recognizes actionable files by a regular expression for file name patterns.
Further Automation Opportunities
The scripts and processes described above have improved ebook metadata management at UMN by making it more consistent, data-driven, and efficient, while also improving metadata quality for discovery. However, we see potential for both the expansion of existing automation, and at least partially automating several other tasks we are currently managing manually.
Currently the Python scripts that process WCM update files run on a Windows 10 desktop computer. The scripts are scheduled to run on a daily basis using Task Scheduler, which comes pre-installed on Windows computers. This is a low-barrier-to-entry way to automate scripts for those who do not have access to their own server team.
However, now that we have refined our process, we are working with our systems administrators to get these scripts running directly on an SFTP server, for increased continuity and security. Server-side processing will also make it possible to automatically place processed update files on an SFTP server where Alma’s scheduled import profiles can pick them up.
WCM Delete Processing
Another future area of investigation is how to manage record delete files generated by WCM. While in many cases, delete records are legitimately for titles deleted from a collection, this is not always true: WCM also supplies a delete record when there is a switch in preferred record for a given resource. In these instances, WCM first sends a delete file for the existing record, and then sends a new or updates record for the new preferred record. While the gaps have grown smaller over time, in the past the lag between deletion and supply of a new record were too large, and caused interruptions in access that were noticeable to library users. Because we are reluctant to perform any maintenance activity that we believe has a high chance of interrupting user access, we currently handle deletes manually for those collections to which we have perpetual access rights. We do this by periodically performing a manual audit for a given collection on the records we have in Alma, the records available from WCM, and the list of titles to which the vendor says we should have access. This is an incredibly time consuming task, mainly because not every collection has a consistent identifier across MARC record data, vendor lists, and knowledge base KBART metadata. This inconsistent data makes automation a tremendous challenge, one that we are continuing to work on as services evolve.
Conclusion
We conclude this paper by stressing that as products under constant development and enhancement, both Alma and WCM see frequent changes to both the MARC records themselves and the ways those records are handled in their knowledge bases. All of the processes, analyses, and procedures described here are representative of this moment in time. We expect to continuously monitor available record sources and their characteristics, so that we may continue to adapt our workflows as the environment shifts. A good example of this is WCM’s recent (starting August 2017) addition of the “merges” file for OCN merges, as an alternative to including these records in the broader “updates” file. Because our script and import profile was already handing OCN changes in the “updates” files, we adapted our existing script to simply pick up these files as well. This was as simple as adding regular expressions for the “merges” file name patterns to the script. Before we started receiving these files, however, we had no idea what to expect or how this change would impact our previous workflow. These kinds of vendor-initiated changes are fairly common when dealing with electronic resource metadata provision, and we expect to keep encountering them.
Also worth noting is that the quality of discovery metadata for ebooks in the Alma CZ has demonstrably improved over time, and Ex Libris continues to work with both Alma customers and content providers to improve it further. The best eventual outcome for Alma libraries would be for metadata completeness and quality in ACZ records to match that available via WCM, making the processes described in this paper obsolete. That goal is unlikely to be reached anytime soon, but we will continue to work toward it.
Our goal in developing these scripts was to automate the processes for a) selecting ebook record providers and b) processing records for LMS ingest and identifying records that needed a human to look at them. We have established automated workflows for both of these processes, which account for national and local bibliographic standards and practices, informed by the quirks we have observed in the datasets over time. While these workflows have reduced the amount of hands-on analysis needed to provide adequate discovery for these resources on a day-to-day basis, we anticipate that future time- and expertise-intensive work will always be needed to update the processes when vended services or our local needs change.
References
Albon C. Group bar plot in MatPlotLib. [updated 2016 May 1]. Available from: https://chrisalbon.com/python/matplotlib_grouped_bar_plot.html
Chen M, Kim M, Montgomery D. 2016. Ebook record management at The University of Texas at Dallas. Technical Services Quarterly 33(3): 251-267. Available from: http://dx.doi.org/10.1080/07317131.2016.1169781
Fenichel, E. [accessed 2017 August 15]. Marc_BatchLoading_Checks (Github repository). Available from: https://github.com/EthanDF/Marc_BatchLoading_Checks
Hodge V, Manoff M, Watson, G. 2013. Providing access to E-Books and E-Book Collections: Struggles and Solutions. The Serials Librarian 64(1-4): 200-205. http://dx.doi.org/10.1080/0361526X.2013.760411
How do I plot just the positive error bar with pyplot.bar? [updated 2012 November 12]. StackOverflow post. Available from: https://stackoverflow.com/questions/13312820/how-do-i-plot-just-the-positive-error-bar-with-pyplot-bar
Lybarger K. 2013. Keeping up with ebooks: automated normalization and access checking with Normac. code4lib Journal 20. Available from: http://journal.code4lib.org/articles/8375
Martin KE, Mundle K. 2010. Cataloging e-books and vendor records: a case study at the University of Illinois at Chicago. Library Resources & Technical Services 54(4): 227–237. Availabe from: http://dx.doi.org/10.5860/lrts.54n4.227
Matplotlib: Python plotting [updated 2017 May 10]. Documentation webpage. Available from: https://matplotlib.org/
Mugridge, RL, Edmunds J. 2012. Batchloading MARC bibliographic records current practices and future challenges in large research libraries. Library Resources & Technical Services 56(3): 155–170. Available from: http://dx.doi.org/10.5860/lrts.56n3.155
Mugridge RL, Edmunds J. 2009. Using batchloading to improve access to electronic and microform collections. Library Resources & Technical Services 53(1): 53–61. Available from: http://dx.doi.org/10.5860/lrts.53n1.53
pandas: Python data analysis library [updated 2017 July]. Available from: http://pandas.pydata.org/index.html
Program for Cooperative Cataloging (PCC). 2017. Provider-neutral e-resource MARC record guide: P-N/RDA version. Available from: https://www.loc.gov/aba/pcc/scs/documents/PN-RDA-Combined.docx
Sapon-White R. 2014. E-Book cataloging workflows at Oregon State University. Library Resources & Technical Services 58(2): 127-136. Available from: http://dx.doi.org/10.5860/lrts.58n2.127
Spurgin KM. 2014. Getting what we paid for: a script to verify full access to e-resources. code4lib Journal 25. Available from: http://journal.code4lib.org/articles/9684
Summers E. [updated 2017 July 26]. Pymarc (Github repository). Available from: https://github.com/edsu/pymarc
Traill S. [updated 2017 May 25]. Editing and import guidelines for ebook record sets. Available from: https://z.umn.edu/ebookguidelines
Traill S. 2013. Quality issues in vendor-provided e-monograph records. Library Resources & Technical Services 57(4): 213-226. Available from: http://dx.doi.org/10.5860/lrts.57n4.213
Wu A, Mitchell AM. 2010. Mass management of e-book catalog records: approaches, challenges, and solutions. Library Resources & Technical Services 54(3): 164–174. Available from: http://dx.doi.org/10.5860/lrts.54n3.164
About the Authors
Kelly Thompson (kjthomps@umn.edu; http://orcid.org/0000-0002-3812-8910) and Stacie Traill (trail001@umn.edu; http://orcid.org/0000-0001-9945-2303) are Metadata Analysts at the University of Minnesota Libraries in Minneapolis.

Subscribe to comments: For this article | For all articles
Leave a Reply