by Mandy Neumann, Jan Steinberg, and Philipp Schaer
1. Introduction and Motivation
Building up new collections for digital libraries is an expensive and demanding task. Not only do digital content curators need to assess many different data sources intellectually but also need to invest a lot of time and effort to extract the available data sets. Usually this is done by coding custom data handlers or conversion scripts with languages like Perl or Python. While this might be a trivial task for programmers, librarians and content curators are most likely overwhelmed with such a task and its complexity and pitfalls.
One of the largest digital libraries that lead the way in digitizing this data extraction process is the dblp computer science bibliography [1], which built up their process chain to heavily rely on automatic metadata extraction from many different sources. Ley (2009) gave an excellent overview and insight into all the traps one might fall. Other examples are disciplinary open access repositories like the Social Science Open Access Repository (SSOAR) [2] that gather available full text items from different partner organizations like publishers, research institutes, and individuals. While some of these partners or content providers are technically and organizationally able to provide a clean set of parsable metadata, many do not have the necessary technical manpower to prepare these metadata sets. Ironically, many small and medium-size publishers do have a web page or an online catalogue. The same is true for many research institutes or funding agencies. Although managing and preparing high quality metadata is not their core business they are somehow able to present their content online in a rather structured form. This is an opportunity we would like to make use of and present a web scraping tool that does not demand that digital library curators program custom web scrapers from scratch but instead use a mighty, but still light-weight, toolkit that does not force them to learn to program.
Data curation is a typical task that is done by people with a library and information science background. These people are well-aware of markup languages like XML or HTML and maybe know a little about DOMs or processing XML-resources with XPath or XSLT. But to code a full-blown web scraper for various sites, they need the support of real programmers. To bypass this involvement of software developers and to empower librarians and documentalists, web scraping toolkits are an excellent way to gather content without diving deep into programming issues like development environments or dependency management. One of these toolkits is OXPath that is presented in the second section of this article.
At a first peek OXPath might look rather complicated, but keep in mind: The target audience for this tool is not full stack developers but librarians and documentalists. We have seen these people getting ready to scrape their first web resources after just a short tutorial and some demos. Even LIS students without any mentionable previous knowledge of web scraping and HTML/XML were able to write their first lines of OXPath after 2 hours. We think that their general knowledge of structure and presentation of library-related material helps them to get a handle on the task. From our understanding, this is a perfect foundation for OXPath as it is easy to install and allows users to dive into web scraping right away without learning how to install and maintain a development environment with dependencies, etc. Therefore we would like to introduce OXPath to a broader community and demonstrate the workflow to gather web data for digital libraries without being a programmer. On top of that we would like to present a syntax highlighting plugin for the popular text editor Atom we developed to further support OXPath users and to simplify the authoring process.
2. OXPath – A language for web scraping
In cases where a metadata provider cannot provide an API or similar tool, one will have to gather the data from their public website, as it is displayed to the human user. This could be done manually, which can be rather labour-intensive, or one would need to program a scraper specifically tailored to the target website that extracts the data for you.
For non-programmers, web data extraction tools provide an alternative to writing a complete web scraper from scratch. Most of them, such as FMiner [3], ParseHub [4] or import.io [5], are commercial with rather high costs or subscription fees. Another problem with those GUI-based tools is that often some advanced features are missing or that one is limited by the user interface that does not allow use of all the features of the underlying scraping software. We want to introduce the free and open-source tool OXPath [6] that allows the user to define the data to be extracted in a declarative way. The language of OXPath is based on the XML query language XPath 1.0 but extends XPath’s capabilities with some elements that allow the simulation of user interaction with a web page and the extraction of data in the course of these interactions. Those extensions are, for example, actions like clicking and form filling, a means for iteration to enable navigation through paginated content, and extraction markers. Also, in addition to XPath functions, OXPath introduces some additional useful functions to manipulate the data before it is extracted.
As an example, Listing 1 shows a simple OXPath wrapper for harvesting the result list of a request to Google Scholar. After entering the search string ’OXPath’ into the search field and pressing enter (line 2), it navigates the paginated result list by repeatedly clicking on the ’Next’ button (line 3) and extracts from each result the title and author information into title and authors attributes, respectively (lines 4–5). To extract the author information correctly, the substring-before function is used to catch only the text that occurs before a separator symbol.
doc("https://scholar.google.com/scholar?hl=en")
/descendant::field()[1]/{'OXPath'}/{pressenter /}
/(//a[contains(.,'Next')]/{click/})*
//div[@class='gs_r']:<paper>[.//h3:<title=string(.)>]
[? .//*[@class='gs_a']:<authors=substring-before(.,' - ')>
Listing 1. Sample OXPath wrapper for harvesting the result list of Google scholar after entering a search term
There are many possible usage scenarios for OXPath. For example, we used it for extending existing test collections in information retrieval with additional metadata (Schaer and Neumann 2017). In the field of digital libraries, OXPath can be used for harvesting bibliographic metadata from publishers’ websites, as presented by Michels et al. (2017) for dblp. Here, we want to guide you in more detail through the process of creating an OXPath wrapper for metadata harvesting, by taking one of our own use cases as an example.
3. Hands On and Walkthrough
Some publishers provide OAI-PMH endpoints or other APIs, but not all of them do, and in those cases in which an endpoint is available, sometimes not all data is provided there – but there may be more data that is displayed on the human-oriented interface, i.e. the web page of a journal.
Suppose you want to store metadata about a new working paper series in your digital library. The publisher has agreed to collaborate with you, but is not able to provide you their publications’ metadata neither via API nor a file dump or similar method. So you decide to write an OXPath wrapper to harvest it directly from the publisher’s website.
Before starting to write this OXPath wrapper, it’s worth taking a deeper look at the data. The attention should be on checking if the minimal set of metadata needed for the digital library is really available.
The next look should be at the source code of the website to get information about its structure. It’s a good sign if every metadata element in each dataset is formatted or marked in the same manner. Composed fields without a recognizable delimiter between the individual information can become quite complicated or even impossible to parse. To easily find the location of these fields in the code, most of the web browsers offer a possibility to jump to a clicked element’s source code location [7].
In the following part, the website of the Bonn International Center for Conversion (BICC) [8] serves as an example. Our goal is to get all working papers’ metadata including their Open Access full text links for importing them into our digital library.
First of all, an entry web page is needed on which all the relevant publications are listed. There’s a browsing category for ‘working papers’ that leads us to such a list (https://www.bicc.de/publications/by-category/all-issues/category/working-paper/).
With a text editor of our choice, we create a new text file called bicc_WP.oxp in which we can start to write our OXPath script.
We define our starting page:
doc("https://www.bicc.de/publications/by-category/all-issues/category/working-paper/")
In the source code of the website we identify the element that contains the list of the publications.
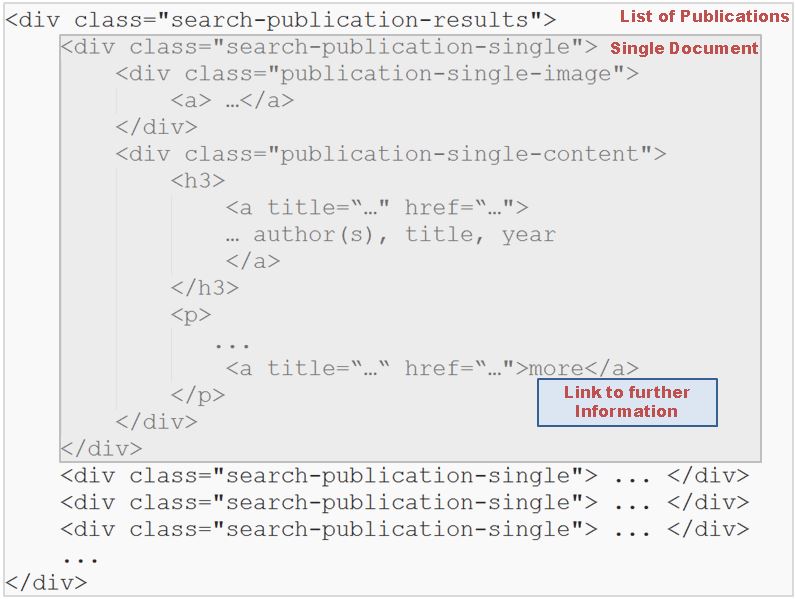
Figure 1. Source code excerpt of the website in question.
Now we tell OXPath that this is the place to start:
//div[@class="search-publication-results"]
In this div each document has its own container. In this case it’s another div. For each of these OXPath has to open an ‘item’ XML tag in our result document.
./div[@class="search-publication-single"]:<item>
For each of the items in the list, to get to the more detailed view of the corresponding metadata the ‘more’ button has to be clicked:
//p/a/{click/}
On this new page our analysis made evident that every metadata element we want to harvest is a child node of a div with the class name ‘tx-bicctools-pi3’. Therefore we select this node to be our starting point for the new page:
//div[@class="tx-bicctools-pi3"]
From there we collect the relevant data fields and output them into XML tags.
[? ./h1:<title=string(.)>] [? ./div[@class="publicationfield cover-field"]/img: <number=@title>] [? ./div[@class="publicationfield date_from"]: <date_from=string(.)>] [? ./div[@class="publicationfield abstract-field"]: <abstract=string(.)>] [? ./div[1]/ul/li/a: <url=@href>] [? ./div[1]/ul/li/a: <lang=string(.)>] [? ./div[2]/ul/li/a: <author=string(.)>] [? ./div[3]/ul/li/a:<topic=string(.)>] [? ./div[4]/ul/li/a:<geoContext=string(.)>]
When running the OXPath script now, the output looks a bit unclean. Many of the field contents are not yet in the form normally needed for a digital library import.
Here another advantage of OXPath comes into play. You can make use of all the standard XPath functions like normalize-space, substring-before, substring-after, replace and so on. In addition, there is some static information that is the same for every publication on the website. This information can be added in one go as well:
[? ./h1:<title=string(.)>]
[? ./h1:<publisher="bicc - Bonn International Center for Conversion">]
[? ./h1:<doctype="working paper">]
[? ./div[@class="publicationfield cover-field"]/img:
<number=substring-before(substring-after(@title, 'WP_'),'.jpg')>]
[? ./div[@class="publicationfield date_from"]:
<date_from=translate(normalize-space(substring-after(.,'Release date: ')),'-','/')>]
[? ./div[@class="publicationfield abstract-field"]:
<abstract=normalize-space(.)>]
[? ./div[1]/ul/li/a:
<url=concat('https://www.bicc.de/', @href)>]
[? ./div[1]/ul/li/a:
<lang=string(.)>]
[? ./div[2]/ul/li/a:
<author=string(replace(.,'PD Dr. |Prof. |Dr. ', ''))>]
[? ./div[3]/ul/li/a:<topic=string(.)>]
[? ./div[4]/ul/li/a:<geoContext=string(.)>]
After adding the static information and introducing the additional XPath functions in the expression, the resulting output is cleaner. The required content is present and fit for further processing.
Below is an excerpt of the final output:
<item>
<title>Local Security-Making in Kyrgyzstan and Tajikistan</title>
<publisher>bicc - Bonn International Center for Conversion</publisher>
<doctype>working paper</doctype>
<number>5_2016</number>
<date_from>2016/06</date_from>
<abstract>In cooperation with researchers in Tajikistan and Kyrgyzstan, BICC
(Bonn International Center for Conversion) is conducting a three-year research
project on everyday security practices in Central Asia ...</abstract>
<url>https://www.bicc.de/uploads/tx_bicctools/working_paper5-1_01.pdf</url>
<lang>English</lang>
<author>Marc von Boemcken</author>
<author>Dr. Conrad Schetter</author>
<author>Hafiz Boboyorov</author>
<author>Nina Bagdasarova</author>
<author>Joomart Sulaimanov</author>
<topic>Migration</topic>
<geoContext>Kyrgyzstan</geoContext>
<geoContext>Tajikistan</geoContext>
</item>
3.1 Some practical considerations
Although, as we hope to have shown, writing an OXPath expression is relatively straightforward after a little training, there are some things that have to be considered when you want to use them in production.
First of all, and this is true for web scraping in general, you have to be aware of the fact that the data you get might be messy. Metadata on web pages are meant to be displayed to a human user. For example, in the case of author names, the human readable form often differs from the format you would normally need to have in your digital library (e.g., Prof. Dr. John van Doe vs. Doe, John van). There may also be some metadata that is not displayed at all, e.g., unique identifiers for each dataset/publication, so you need a strategy for that. In our use case, the URL of the dataset can be used as a substitute. It’s not really handy, but unique and therefore a suitable working solution. Also, the volume/year and the issue of the present series cannot be reliably determined. In our example script, we try to extract these details from the filename of the front page images. For more reliable content, it is inevitable to get the information elsewhere.
Another point is that one should make sure that the website’s owner is well informed about the OXPath web scraping, either by a general allowance from them or a targeted agreement. Crawling web resources in general should respect some rules of politeness as web servers have both implicit and explicit policies regulating the rate at which a crawler like OXPath can visit them. An example might be to respect the robots.txt or to try to scrape during off-peak hours. Please be aware that these politeness policies must be respected as too many actions on a page in a short period of time can overload their servers and may cause your IP address to be blocked. It also will distort the web server statistics (hits and views of every single dataset). There are possibilities in OXPath to slow the script processing (e.g., the ‘click pause’ and the ‘wait’ command). This way we can trick web servers as they cannot distinguish between the web scraping process and a human web surfer anymore. Still it’s easier and advisable to just contact the web site operators.
OXPath trades speed for memory efficiency. Thus, an OXPath script in some cases may take hours to days to run because internally the whole web page is rendered and processed to allow a human-comparable extraction mechanism. On the other hand, OXPath maintains a rather small memory footprint compared to other tools made for extracting bulk data from web pages, as has been proven by Furche et al. (2013). In production use, one may try to distribute the whole scraping process on parallel threads but this is not a built-in feature.
Finally, one should be aware of the fact that websites are far more likely to change than API endpoints. It’s not only the data itself that may be changed or even deleted, but also the structure and design of the web page. Luckily enough, nowadays design and structure are, in general, neatly separated from each other. As OXPath addresses elements via their structural position (in the DOM tree) rather than by design features, it is, in general, immune to changes in the design of a page. Nevertheless, changes in the structure may also happen, which is why a given wrapper might have to be updated from time to time. In the future, we plan to provide users with tool support for scheduling and monitoring harvesting processes which also includes notification in case of such events.
In spite of its limitations, OXPath is a powerful and useful tool for harvesting semi-structured data from web resources. We think it is especially well suited for non-programming librarians with a general knowledge of XML technologies. In fact, all you need for a first start is the OXPath binaries, a Java runtime environment installed on your system and a plain text editor to write the expression. However, in our ongoing project we are working on providing more tool support around it. A first step in doing so was to implement a language package for the free and open-source text and source code editor Atom.
3.2 Syntax Coloring for OXPath
As stated before, an OXPath expression can be written using any text editor. Nowadays, a lot of text editors also include support for different formal languages (like programming or markup languages) by providing syntax highlighting for them. Syntax highlighting, or syntax coloring, does not have any function other than assisting the human reader and writer of source code. When different structural elements and keywords are visually discriminated by different colors it helps the reader with orientation in pre-written code. Also when writing code, highlighting helps spotting potential (lexical) errors – e.g., when a keyword is misspelled, it does not receive the keyword-specific coloring.
As syntax highlighting is especially helpful for newcomers to a language, we decided to implement a language package for the Atom editor to support and heighten the uptake of OXPath [9]. We chose Atom because it is a free, open-source editor available on the major operating systems with an active community of developers, maintainers and users behind it. Extensive information on how to add support for a new language in Atom, however, is unfortunately missing from the current version of the documentation [10]. A helpful resource is a blog post by Jérémy Heleine [11] that provides a complete walk-through for creating a simple syntax highlighting package and thus serves as a good starting point.
There are three important components of an Atom grammar. First, it specifies file extensions such that every time a file is saved with a specific extension, the corresponding language package is automatically activated. Second, it defines a set of rules in the form of regular expressions that match specific language constructs. Third, it maps the text matched by a rule to a CSS class – this information is used by Atom’s syntax themes to provide different coloring to elements of different classes [12]. For the file extensions, we defined .oxp and .oxt as those that will trigger the OXPath language package. Regarding the matching rules, we first checked the original grammar (which is written in JavaCC) to get an overview of the most important language constructs. Then we decided to create rules for the most important keywords – function names like contains or substring, the action keywords (like click or pressenter), XPath axes like preceding or ancestor, and, of course, the doc statement. Strings, delimited by single or double quotes, and numbers are also recognized. Finally, we decided that also the extraction markers, as an important component of any OXPath expression, should receive distinct highlighting. Figure 2 demonstrates the effect of the developed language package by contrasting the non-highlighted version of our sample OXPath expression, treated as plain text, with the highlighted version. Even with this rather short snippet it is apparent that the highlighted version is more readable as different structural elements are visually separated. With more elaborate expressions, we expect the effect to be even more pronounced. We thus hope that our language package for Atom will be of help for all users of OXPath, especially for newcomers getting started with the language.
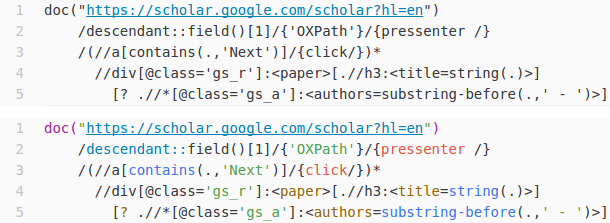
Figure 2. Demonstration of the effect of syntax coloring. Above: expression in plain text mode. Below: the same expression with associated OXPath grammar.
4. Conclusion
In this article, we have presented OXPath, a declarative expression language extending XPath for web scraper creation. OXPath is an easy-to-learn, light-weight, and all-in-one technology to gather metadata from web resources. We demonstrated with a real-world example from one of our own use cases how to use it for straightforward extraction of publication metadata from a small publisher’s website. We think that OXPath is a worthy alternative to other web scraping tools especially for librarians, not only because it is free and open source, but also because it provides full control of the extraction process. A basic knowledge of XML and its query language XPath is sufficient for getting started with the OXPath wrapper language – no further programming skills are required. It also requires no installation and only a simple working environment with Java and a command line. Although, as we’d like to point out, the integration in a Java development environment as a library is also possible for more advanced usage.
We think OXPath can be useful in many scenarios in the context of digital libraries. Although there are still relatively few tools to support the development process, we think that our contribution of a syntax coloring package for a popular text editor is an important step towards lowering the initial hurdle for newcomers to OXPath. There is still room for improvements, and any issues submitted through the Issue Tracker on GitHub [13] are highly appreciated. In the future, we want to work on further support for OXPath users which might include scheduling and monitoring harvesting processes and/or providing a visual tool for crafting OXPath expressions via the interaction with the target site.
Acknowledgements
This work was supported by Deutsche Forschungsgemeinschaft (DFG), grant no. SCHA 1961/1-2.
Appendix
The complete example from this article including a current version of OXPath and instructions on how to run it can be downloaded from:
https://github.com/neumannm/c4l-material
Currently only Ubuntu 64bit operating systems are supported, which will change in the future. You will have to have Java installed on that system to run OXPath.
OXPath is otherwise available for download at http://www.oxpath.org/download/. At the time of writing this article, the current version is 2.0 – a newer version with a slightly different and more advanced command-line interface is in development. Also, an exhaustive tutorial on OXPath will be published soon.
Notes
[1] http://dblp.uni-trier.de
[2] http://www.ssoar.info
[3] http://www.fminer.com
[4] https://www.parsehub.com
[5] https://www.import.io
[6] http://www.oxpath.org
[7] In Chrome: Right-click ? Inspect Element
Furthermore, there are extensions to some web browsers that allow to find specific elements via XPath or show the XPath to a given (clicked) location. See FirePath for Firefox or ChroPath for Chrome.
[8] https://www.bicc.de
[9] https://atom.io/packages/language-oxpath
[10] http://flight-manual.atom.io
[11] https://www.sitepoint.com/how-to-write-a-syntax-highlighting-package-for-atom
[12] Note that this fact gives us only indirect influence on the coloring of elements. It might still be the case that a syntax theme gives the same color to different CSS classes.
[13] https://github.com/neumannm/language-oxpath/issues
References
Furche T, Gottlob G, Grasso G, Schallhart C, Sellers A. 2013. Oxpath: A language for scalable data extraction, automation, and crawling on the deep web. The VLDB Journal 22:47–72. doi:10.1007/s00778-012-0286-6.
Michels C, Fayzrakhmanov, R.R., Ley, M., Sallinger E, Schenkel R. 2017. Oxpath-based data acquisition for dblp. In: JCDL ’17: Proceedings of the 17th ACM/IEEE-CS on Joint Conference on Digital Libraries; 2017 June 19-23; New York, NY, USA. ACM. p. 319-320. To appear.
Ley M. 2009. DBLP: Some Lessons Learned. Proceedings of the VLDB Endowment 2(2):1493–1500. doi:10.14778/1687553.1687577.
Schaer P, Neumann M. 2017. Enriching Existing Test Collections with OXPath. In: Jones GJ, Lawless S, Gonzalo J, Kelly L, Goeuriot L, Mandl T, Cappellato L, Ferro N, editors. Experimental IR Meets Multilinguality, Multimodality, and Interaction. Proceedings of the 8th International Conference of the CLEF Association, CLEF 2017; 2017 Sept 11-14; Dublin, Ireland. To appear.
About the Authors
Mandy Neumann is a research associate at the Institute of Information Science at TH Köln (University of Applied Sciences) in the Information Retrieval Research Group. She studied information processing and linguistics/phonetics at the University of Cologne where she received her Master’s degree in these subjects. mandy.neumann@th-koeln.de
Jan Steinberg is a research associate and software developer with the department Computational Social Science (CSS) at GESIS – Leibniz Institute for the Social Sciences. He graduated his studies in Information and Communication Sciences at TH Köln (University of Applied Sciences) with a Diplom and in Library and Information Sciences at Humboldt University of Berlin with a Master’s degree. He pursues special interests in information retrieval, open science, and natural language processing. jan.steinberg@gesis.org
Philipp Schaer is Professor for Information Retrieval at the Institute of Information Science, TH Köln (University of Applied Sciences) where he teaches courses on information retrieval, database systems, and search engine technology. He studied computer science with special interest in information retrieval and human factors in information systems and graduated at University of Koblenz-Landau where he received his degree as Diplom-Informatiker and later his doctorate in computer science. philipp.schaer@th-koeln.de, http://www.schaer.de

Subscribe to comments: For this article | For all articles
Leave a Reply