by Stacy Allison-Cassin‡, Dan Scott.‡
‡ Both authors contributed equally to this work.
Introduction
Creating and using linked open data (LOD) in library and GLAM (galleries, libraries, archives, museums) projects has historically been associated with a high level of institutional requirements. Erik et al (2015 [3]) asserted “the fact that LAM institutions are still having to select triplestores, SPARQL engines, indexing platforms, and other services means that there is still a relatively high bar for institutions to cross in taking up LD projects”. The requirement to select, host, and administer all of these systems establishes technical and resource barriers that can prevent organizations and individuals from participating in LOD entirely (Goddard and Byrne, 2010 [5]). Creating and publishing LOD has traditionally required technical skills to transform relational data, to support content-negotiation and alternate serializations, and to understand vocabularies and ontologies typically documented in RDFS or OWL.
Wikidata, launched in 2012 by the Wikimedia Foundation as the machine-readable store for all Wikimedia Foundation projects, is a freely available hosted platform that anyone–including libraries–can use to create, publish, and use LOD. Powered by Blazegraph, the platform offers a triplestore and high-availability SPARQL endpoint that (as of April 2018) has served roughly 3 million queries per day over the past year (Wikimedia Foundation, n.d. [11]); a full text search engine; and is administered by the Wikimedia Foundation. Its vocabulary is published and editable alongside other items in the platform using the same relatively user-friendly interfaces. In effect, Wikidata has responded to the barriers identified by Erik et al and Goddard and Byrne by providing a ready-made platform for any person or organization that wants to create, publish, and use LOD, including libraries. In their 2016 IFLA discussion paper, Bartholomei et al noted “[t]he potential of Wikidata to draw linked open data and linked open data authorities together across the world’s languages and many different ontologies and taxonomies has enormous potential to support researchers around the world.” [1]
The platform is increasingly important as a general LOD resource and as a “linking hub”, recognized in 2013 by Klein and Kyrios as they worked on integrating VIAF data into Wikipedia [7]. At the first Wikidata Conference, van Veen (2017 [10]) boldly suggested Wikidata could be both a linking hub and source of library authority data. As of February 2018, Wikidata now offers links to external data with more than 2,500 identifiers. An international, multilingual, community-based project, Wikidata is a practical choice for use by libraries, and requires all contributions to be licensed under the Creative Commons CC0 “No rights reserved” licence. This licence allows the contents (49 million items as of February 2018) to be used in any project without the cumbersome attribution requirements of other open data licenses, and ensures that every contribution to the repository broadens the range of freely available data.
Background
In 2015 Allison-Cassin began a LOD project focusing on the Mariposa Folk Festival. The project initially focused on creating a dataset of entities related to the Festival. Project plans included the enhancement of existing data through biographical snippets drawn from Wikipedia via DBPedia and links to bibliographic data stores such as the Virtual International Authority File (VIAF). Early findings of the project revealed there were few Wikipedia articles and little to no available data in standard LOD stores such as VIAF. This was especially the case for performers who were not white American males. As one moves into other categories or intersections of categories, for example Canadian women performers, the amount of data became drastically reduced. This echoes the findings of Pattuelli et al (2017), who reported a lack of linkable data for and about female jazz performers in contrast to the availability of data for male performers. The scarcity of linkable data is correlated to areas where structural inequalities in wider society exist.
Inspired by the effectiveness of focused edit-a-thon campaigns such as Art+Feminism to increase content in areas where representation is problematic, Allison-Cassin organized a year-long “Music in Canada @ 150” campaign to coincide with the 150th anniversary of the confederation of Canada to organize a group of music librarians across Canada to add content on Canadian music to Wikipedia and Wikidata. The Music in Canada @150 campaign did not specifically engage with First Nations, Métis and Inuit (FNMI) communities as the focus was on music librarians and cataloguers and their communities (i.e. music students and music faculty.) However, the organizers did try to encourage participants to focus on local collections and communities, with particular attention to those who might be considered underrepresented in dominant reference sources. The campaign also became a way to experiment with the creation of linked data and introduce Wikidata and structured data to an audience that was primarily made up of participants unfamiliar with LOD and metadata library practices.
Lowering barriers to LOD
Beyond relieving institutions of the need to maintain their own LOD infrastructure, Wikidata is designed to be usable by novices and support their growth as editors, community members, and contributors to the platform and LOD.
Ease of use with progressive capabilities
Compared to classic methods of generating LOD, such as hand-crafted RDF/XML or automated transformations of legacy relational data that require developer support, Wikidata’s editing interface (Figure 1) presents a comparatively simple key-value approach for creating and editing statements. Similar to the VitroLib LOD editor’s custom work forms (Khan et al, 2018[4]), it uses autocompletion to suggest matching items for the values of most statements. This approach makes it easier to create and edit LOD: contributors are not required to comprehend LOD principles before they can add a statement to an existing item, or before they can create a new item where one does not already exist. During the workshops, we demonstrated adding a statement such as participant for a given iteration of a music festival: the result would either be that the desired value to complete that statement already existed in Wikidata; or if the value did not exist and needed to be added, led naturally to an opportunity to show the creation of a new item from scratch. After creating an item with a label, and (optionally) a description and aliases, we showed that the new item had its own URI and was immediately ready to both fulfill the statement from the initial item and to be fleshed out with more structured data.
As editors gained experience, they were able to engage in more complex editing tasks such as entering multiple values for a single statement, adding qualifiers like start and end dates to statements, and adding references to provide verifiability for statements. From an editor’s perspective, they are merely qualifying their statement that a given person was part of a band with an additional assertion that the member’s start date was 2007. The corresponding LOD generated by these more advanced tasks is highly complex, requiring reification and a mix of namespaces, but none of this is evident to the editors, who are guided by the user interface in relatively user-friendly forms located within the same statement box.
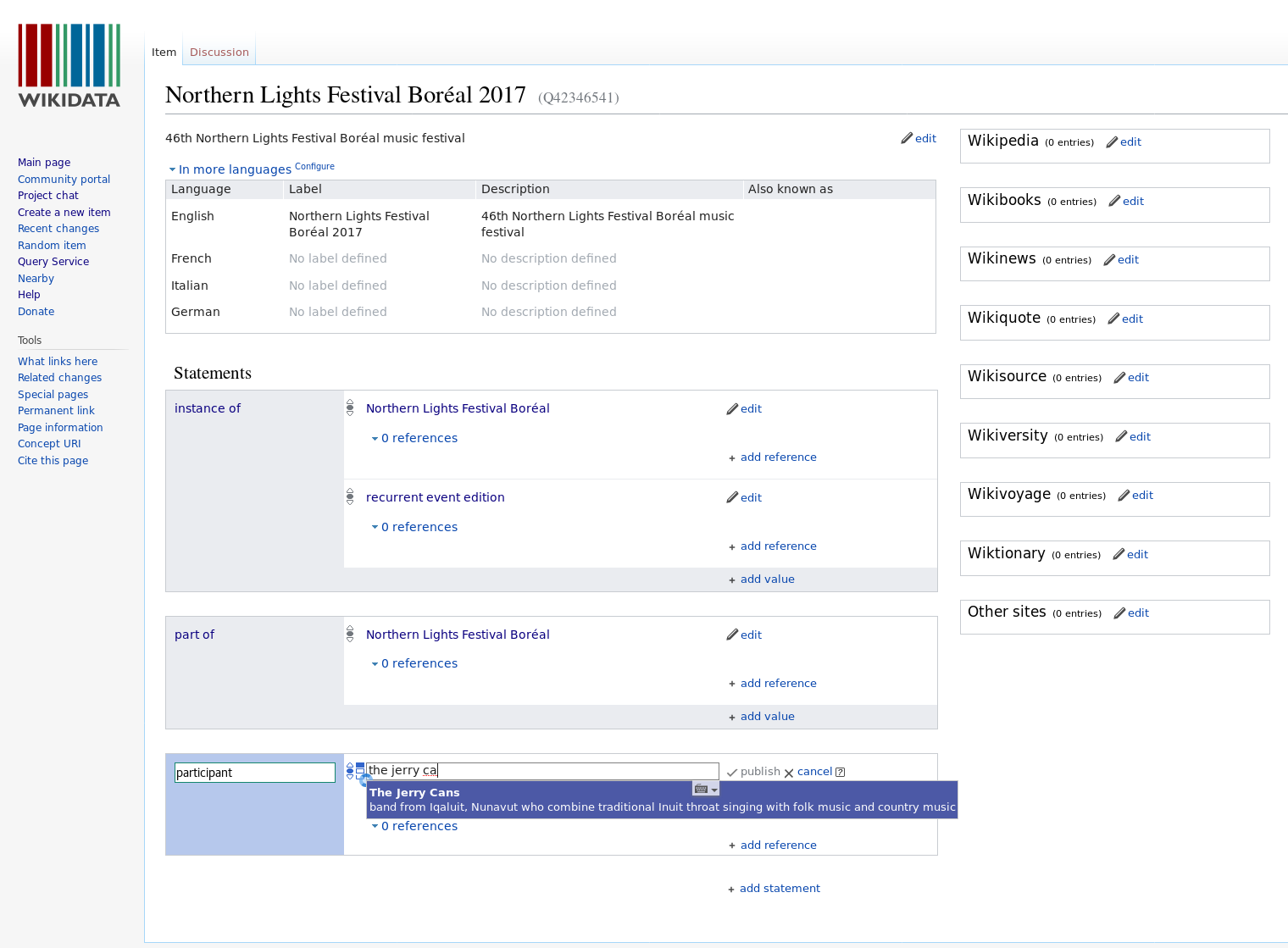
Wikidata also errs on the side of usability and progressive disclosure by allowing editors to create statements that initially violate property constraints, such as establishing inverse relationships between items or allowing only one item to use a unique value. When the editor reloads the page, Wikidata displays a warning next to the statement indicating that a violation may need to be resolved, with a link to the documentation describing the potential violation. In this way, the platform introduces the basic ontological principle that properties and classes can have additional requirements without frustrating new contributors at the point of data entry. As they gain experience with the platform, editors can generate lists of properties that violate constraints for a given project and address those violations by either manual or automated means: for example, missing inverse relationships could easily be added to target items.
Contextual vocabulary discovery
Many LOD vocabularies separate their development, documentation, and community discussion, an approach which makes it challenging for newcomers to find help in using or contributing to a given vocabulary. For example, all decisions about the RDA vocabulary are made by the RDA Steering Committee, while code is developed on Github, documentation is hosted at http://www.rdaregistry.info/, and usage is discussed primarily on an ALA mailing list. The Wikidata platform, in contrast, aims to be self-documenting: vocabulary classes and properties of items such as related Wikidata properties are all described as entries in the repository itself and displayed in a format readable and editable by humans (Figure 2). During the workshops, we used this visual evidence to highlight Wikidata’s knowledge organization system based on items that serve as classes, instances, and properties:
- class items organize Wikidata’s items hierarchically and can be distinguished by the presence of one or more
subclassof statement values as their primary property - instance items provide specific data about one individual item and can be distinguished by the presence of one or more
instance ofstatement values as their primary property - property items classify statements about items, including instances, classes, and properties, and can be distinguished by their identifier prefix of P instead of Q for class and instance items
Wikidata surfaces the evolution of its vocabulary in various ways, each of which invites editors to explore decisions that have been made, to learn a little more about the vocabulary, and to help organize Wikidata’s knowledge as well as contribute data. Every item displays a change log via a View History link. Similarly, a Discussion link puts the community’s ongoing decision-making processes for a given item in context and invites editors to join the conversation and contribute their perspectives. Editors comment based on their domain expertise, the project’s prior practice, and general ontology engineering principles. Property items include a special property property proposal discussion (P3254) that links to the original proposal and discussion for the creation of the property, thereby providing examples for editors that might want to propose a new property.
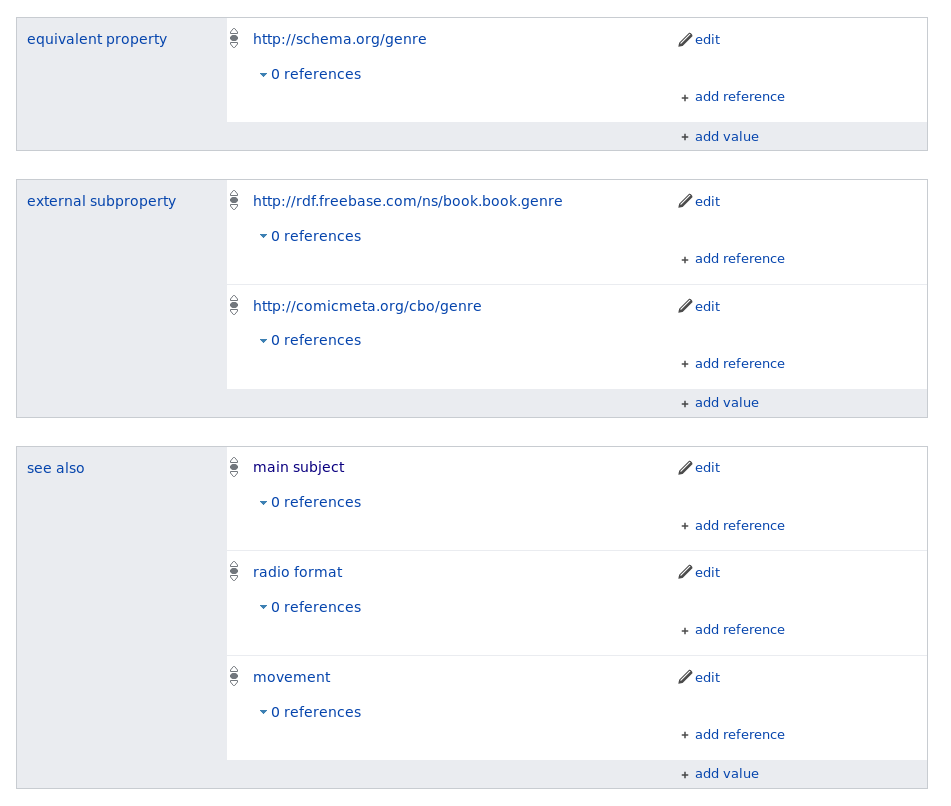
genre (P136) property
The same vocabulary data, which can include more abstract statements such as equivalent property (P1628) and external subproperty (P2236) for aligning the vocabulary with external vocabularies, is also available in machine-readable serializations such as JSON-LD, Turtle, and RDF/XML. The following example shows the subset of data that corresponds to the human-readable representation displayed in Figure 2:
$ curl -L -H "Accept: text/turtle" https://www.wikidata.org/entity/P136
@prefix wd: <http://www.wikidata.org/entity/> .
@prefix wdt: <http://www.wikidata.org/prop/direct/> .
wd:P136 a wikibase:Property ;
wdt:P1628 <http://schema.org/genre> ;
wdt:P1659 wd:P921,
wd:P415,
wd:P135 ;
wdt:P2875 wd:Q20990014 ;
wdt:P2236 <http://rdf.freebase.com/ns/book.book.genre>,
<http://comicmeta.org/cbo/genre> .
Similarly, the Wikidata platform surfaces domain and range constraints directly in vocabulary items as statements, shown in Figure 4.

genre (P136) property
Every item has a discussion page, which often includes autogenerated documentation providing useful links for displaying instances of a given class, showing class hierarchies, and listing reports of constraint violations. Discussion pages can also host conversations between users about topics and issues related to the item. For example, the discussion page for singer (Q177220) contains a topic from 2013 titled “Vocalists” in which Littledogboy asserts “Singer and vocalist are synonyms.” and Infovarius replies “Rapper is not singer but vocalist.” These exchanges provide insight into the Wikidata community’s evolving positions on items and their usage, as well as the challenges of working in an international, multilingual context.
Proposals for new properties follow an open community process, and the results of the proposals are archived; for example, you can search for all property proposals relating to music to see the history of their development and the outcomes. Any Wikidata editor can propose a new property, contribute their expertise to the discussions, suggest amendments or alternatives, and indicate their support or opposition to the proposal. If a consensus is reached, as in the case for sheet music (P3030) (which had been proposed as “musical score”), the new property may be created and used.
Just-in-time vocabulary evolution
Given the community-driven process of ontology development, alternative and potentially conflicting modes of representation can evolve over time. For example, the college library (Q1622062) and academic library (Q856234) types are currently both subclasses of the library (Q7075) type, but follow separate hierarchies:
- library
- research library
- academic library
- school library
- college library
A Wikidata editor trying to represent a library attached to an institution with the word “college” in its name must decide whether to classify it using the category most closely matching the institution’s name (college library), a category reflecting the academic and research orientation of the library (academic library), classify it as an instance of both academic library and college library, or engage with the community to resolve the issue for the entire platform by either merging college library with academic library or making college library a subclass of academic library.
Viewing the history of college library shows that in 2017 it changed multiple times between being a subclass of library, scientific library, school library, and academic library. While a Wikidata editor may feel empowered recognizing that they have the ability to directly improve the vocabulary, they may also be reluctant to attempt to resolve issues with an item that has a complex history. Many editors choose a prudent strategy of satisficing–choosing an existing option that is close enough to their intended meaning to convey the relationship to the data recipients–and trust in the broader community to resolve the potential issues in the future.
URIs and linking
While Wikidata’s lower barriers to accessing and editing existing LOD is helpful, libraries still need Uniform Resource Identifiers (URIs) to link their own collections and contributions of data. Unfortunately, URIs are still lacking for much of the long tail of topics, domains and areas of local interest that are central to the unique materials held by libraries and archives. Libraries can mint their own URIs, of course, but they may not have the resources to preserve the integrity of their namespaces over time, and those smaller namespaces may lack visibility. Creating an item in Wikidata immediately mints a URI with the pattern https://www.wikidata.org/entity/Q####, and offers the advantages of relatively higher visibility and stability. The Music in Canada @ 150 campaign organizers agreed that, while some of Wikidata’s music-related data (such as its almost 1,500 loosely organized music genres) might concern classically trained music cataloguers, it held great potential for addressing the social justice issues that had motivated Allison-Cassin to launch the campaign in the first place. As Scott wrote to the organizing committee on 2017-05-11:
The more minute details of, say, merging and creating music genres is definitely interesting and worthwhile, but when the entity for multi-Juno award-winners A Tribe Called Red doesn’t link to Ian “DJ NDN” Campeau or any of its other musicians because they don’t exist as entities in Wikidata, or reflect those awards, I want to tackle the more fundamental work of visibility first!
In preparation for the Music in Canada @ 150 campaign some initial analysis was conducted of coverage in Wikidata. Carolyn Doi conducted a survey of associate composers of the Canadian Music Centre (CMC) and with a sample of 3.85% of total entries in the CMC database only 40% had pages in Wikidata. Findings were similar with the Mariposa Folk Festival participants for 1961 to 1971. Of the 469 performers, only 33% had an item in Wikidata, and 49% in VIAF. Even more problematically, initial surveys of the Native Peoples Area, a section of the Festival which ran between 1972 and 1978, of 42 individual participants only 5 had a match on VIAF. These two examples reinforce the ways that many library catalogues and Wikipedia continue to reify dominant cultures and publication practices.
Using Wikidata to create structured data is a way local communities can have a global impact. The Canadian Music @150 Campaign was specifically focused on creating content about notable local musicians, composers and organizations that little visibility in libraries and online. The Juno Awards, “presented annually to Canadian musical artists and bands to acknowledge their artistic and technical achievements in all aspects of music” (“Juno Award”, n.d. [6]), represent a base level of Canadian culture for which information should be available in a global context. Many groups accordingly focused on filling in information about Juno Award winners to local bands and traditional musicians. The group at Memorial University in Newfoundland focused on creating Wikidata items and created 40 items, linking local musicians from Wikidata out to the LOD cloud. While these actions individually can seem small, they increased the amount of open data and helped create a community practice.
Since the campaign, Allison-Cassin has been working on Wikidata and content related to Indigenous communities in North America. In 2017, the Association of Research Libraries approved a project focused on social justice, linked data, Indigenous peoples and Wikimedia [9]. This project is specifically intended to engage with Indigenous communities in the creation of data. A Wikidata project was started by Allison-Cassin as a place to collect and discuss properties, data models and foster community. Allison-Cassin is also working with Indigenous community members, local GLAM institutions and Wikimedia Canada to start “Indigiwiki” to work on indigenize Wikimedia projects. The first meeting was held at the Toronto Reference Library in March, 2018.[13] These activities are intended to not just add to the availability of linkable data, but to actively engage communities in the description and content itself. This approach builds on the example of other projects actively engaged in decolonization of Wikimedia projects and the web, such as WhoseKnowledge? and Wikimedia Canada’s Aboriginal community outreach projects to give greater visibility to Indigenous peoples and culture.
Given its visibility as a central LOD platform, Wikidata’s URIs and data are being used in many projects, including the GLAM sector in projects such as SNAC, and in commercial efforts such as Songkick. Recognizing the increased visibility and likelihood of interlinking that results from uploading vocabularies to Wikidata, Europeana (2017 [2]) has called on the GLAM community to “Get [their] vocabularies in Wikidata.” This acknowledges the importance of local data about collections for enriching the network, as well as the current challenge of finding sources to which those collections can be connected. With Wikidata acting as a linking hub for locally held data, the “there’s nothing to link to” problem becomes much easier to address.
Wikidata as structured data community outreach
Wikidata is a good platform for helping librarians, library staff and community members to understand structured data, the impact of structured data on the web, and the Wikimedia Foundation’s rationale for starting the Wikidata project in 2012. The Music in Canada @ 150 Campaign included Wikipedia as well as Wikidata, and was concerned about surfacing content in both of Canada’s official languages (French and English). We highlighted the potential benefit of adding structured data to Wikidata specifically by showing the discrepancies between band member timelines that almost inevitably creep into the over 200 language variants of Wikipedia due to the complex timeline markup and the manual effort of synchronizing the markup across languages.
In Figure 5, a snapshot of English Wikipedia shows only 8 members as having participated in the Québec-based band Voivod, while in Figure 6 the French Wikipedia entry captured at the same time shows 10 members. If the corresponding Wikidata item listed the participants with qualifiers for start and end dates, aliases, and instrument played, then the timelines could instead be automatically generated for all Wikipedia instances, ensuring that a single edit to Wikidata would be reflected in all of the Wikipedia instances.
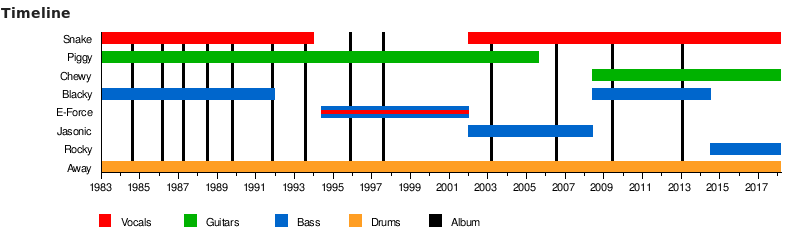
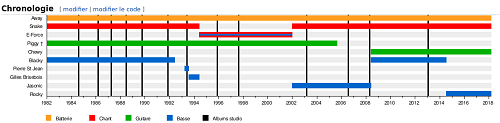
The Canadian music campaign reassured those who do not have a background in metadata that they can contribute structured data; specifically that subject specialists can make important contributions through their domain knowledge. Along with band member timelines, the workshop leaders showed how Wikipedia’s {{authority control}} macro (“Wikipedia:Authority control”, n.d. [12]) automatically displays selected external identifiers such as Library of Congress and Virtual International Authority File (VIAF) stated in the Wikidata item associated with a given Wikipedia article, and the more than 100 Wikipedia infoboxes that draw data partially or entirely from the article’s associated Wikidata item. The English Wikipedia article for the band Voivod had manually asserted in its infobox that the official website for the band was http://www.voivod.com/–which is just a page that loads http://www.voivod.net/ (the URI that had been stated in the Wikidata item) in an <iframe>–while the French Wikipedia article had asserted the website was http://www.www.voivod.net/ (which does not resolve). The infobox for the English article now uses the {{official URL}} macro, and the French article now uses the {{#invoke:Wikidata|frameFun|formatStatements|property=P856|}} macro, to instead pull the correct website from the band’s Wikidata item.
Participants only need a web browser and a basic guide, and through Wikidata they can begin creating LOD a statement at a time. Our workshops did not focus on publishing LOD, however: our materials for the workshops only mentioned LOD once. Instead, we showed how data stored in Wikidata could be integrated into library systems (per Seeing is believing: Wikidata in production library systems), encouraged participants to collaborate on editing tasks as a local example of how others can extend and improve their data, and provided guides with suggested instance of values and recommended properties for each of the data types we covered. LOD was therefore a secondary outcome of their contributions, not the primary goal for the participants–but we then briefly pulled back the covers to demonstrate how developers access the same data through APIs and SPARQL queries. In the SuperConference workshop, we prepared SPARQL queries that used Wikidata’s built-in map visualization to plot the Canadian libraries found in Wikidata, and recommended several items that were missing either coordinates or country: Canada statements that participants could edit so that they would immediately be added to the map. Wikidata’s SPARQL endpoint supports a number of useful visualizations to help build confidence in Wikidata specifically, and LOD in general, as a platform for library data, including maps for result sets that include coordinates, timelines for items with dates, galleries for items with images, and a variety of charts and graphs.
To help support the Music in Canada edit-a-thon, Scott created an introduction to Wikidata workshop that included a summary of the most relevant properties for describing musicians and music festivals (workshop notes) that he compiled by comparing and evaluating existing Wikidata items. While the discovery process can be enjoyable, it can also be frustrating, particularly if there is not a richly described existing template item that one can use as a model for creating new items. Recipients therefore appreciated the prescriptive guidance as a pragmatic way to speed up their productivity rather than getting mired in discovery. For a subsequent workshop, Scott created a more thorough guide for describing libraries and catalogues (excerpted in Figure 7).
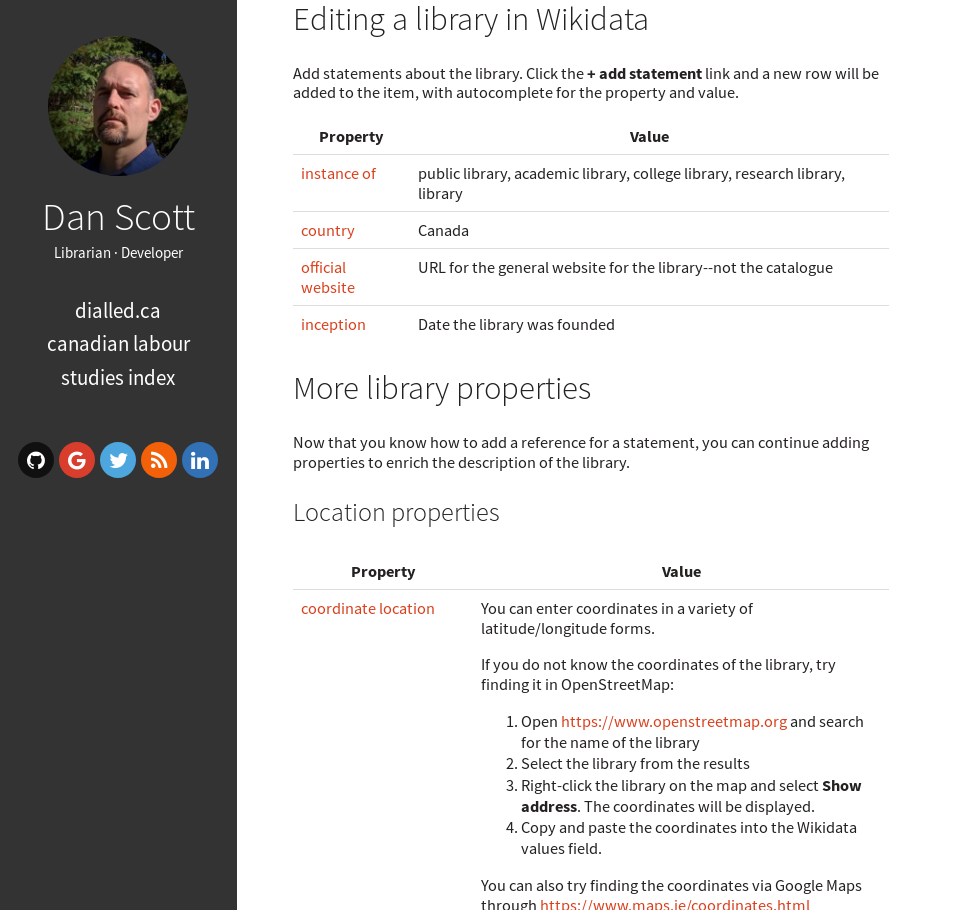
Music librarians and scholars participating in the project were creating or enhancing biographical articles in Wikipedia. We paired this with manual revision of the Wikidata items in focused areas and encouraged participants to add standard identifiers for sources such as VIAF, MusicBrainz, and SongKick. In the Canadian context, it was useful to demonstrate the way Wikidata can assist with bilingual work. It also facilitated more general conversations about openly available and licensed data, and how these approaches contrast to data in proprietary systems.
Seeing is believing: Wikidata in production library systems
Library workers sometimes understandably question the call to add enriched metadata–for example, relator codes or RDA elements to MARC21 records–if they do not immediately result in a change to the publicly visible display. Similarly, one of the challenges of embracing LOD is demonstrating why that effort improves the experience of library users. At the 2017 Evergreen International Conference, Scott witnessed a challenge to the efforts the open source library system developers had been putting into enhancing its support for LOD, so as he prepared his workshop materials for the Music in Canada edit-a-thon training session, he built a proof-of-concept extension to Evergreen (his library’s public catalogue) that would integrate musician and band data from Wikidata to create infocards in real-time within the detailed display of music records, as seen in Figure 7.
The code for the standalone proof-of-concept, written in vanilla JavaScript, is available at https://gitlab.com/denials/wikidata-music-infocard. The production code used in Laurentian University’s catalogue can be found in a feature branch of the Evergreen git repository.
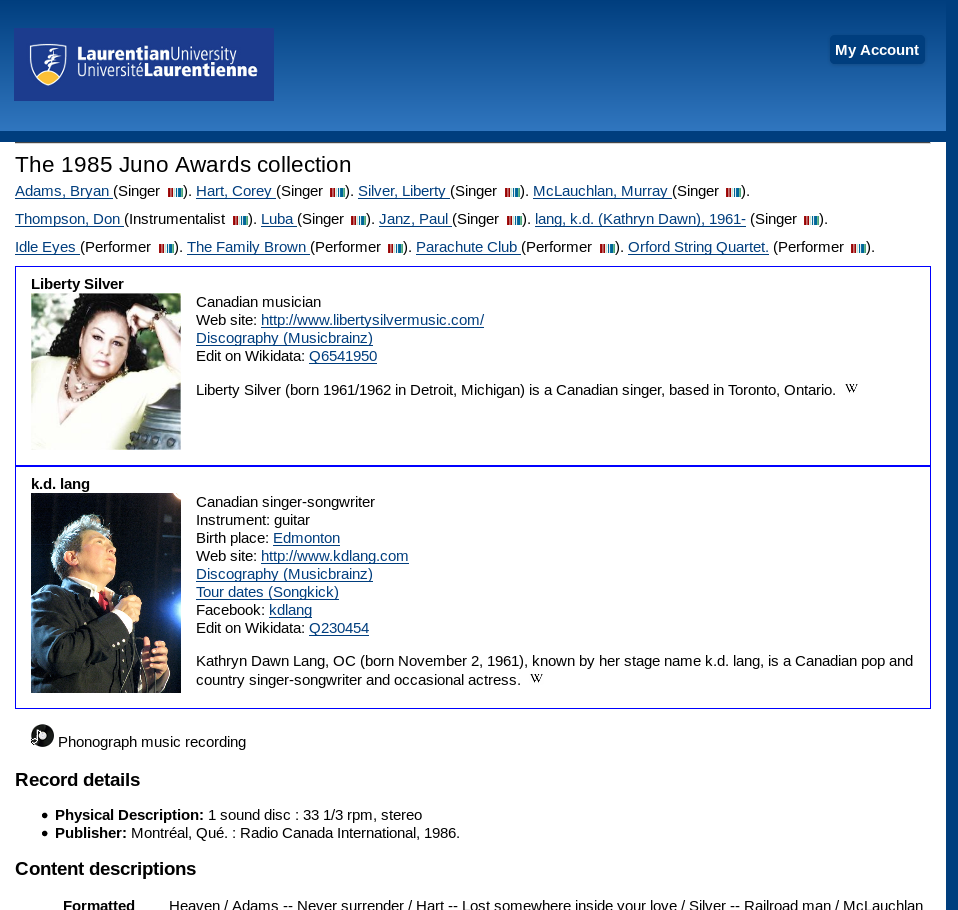
A single JavaScript file, added to the record display page, leverages the schema.org structured data that Evergreen already expresses in its HTML by determining if the page describes a schema.org MusicAlbum type. If so, it iterates through each of the contributors to the resource to add a Wikidata icon that, when clicked, checks Wikidata for a musician or band with a matching name and retrieves a subset of the possible information for display as an infocard. Figure 9 shows a simplified HTML example of the Evergreen page:
<body vocab="http://schema.org/" typeof="MusicAlbum">
<h1 property="name">The 1985 Juno Awards collection</h1>
<section id="contributors">
<h2>Contributors</h2>
<div typeof="Person" property="contributor" resource="#schemacontrib3">
<span property="name">Silver, Liberty</span>
(<span property="description">Singer</span>).</div>
<div typeof="Person" property="contributor" resource="#schemacontrib8">
<span property="name">lang, k.d. (Kathryn Dawn),</span>
<span property="birthDate">1961</span>-</span>
(<span property="description">Singer</span>).</div>
<div typeof="Organization" property="contributor"
resource="#schemacontrib10">
<span property="name">The Family Brown</span>
(<span property="description">Performer</span>).</div>
</section>
To encourage reuse and adoption, Scott wrote the JavaScript without using external libraries, and factored out the variable elements of the implementation into five CSS selector paths, per Figure 10:
/* Path for the schema.org type declaration */ var type_path = '[typeof~="MusicAlbum"]'; /* List of elements describing contributors */ var contributors_path = 'div[resource^="#schemacontrib"]'; /* Path to find the name within each contributor element */ var contributor_name = 'span[property="name"]'; /* Within each contributor element, where we can append a Wikidata clickable icon */ var name_path = 'span[property="description"]'; /* Path for appending the requested infocards */ var infocard_location = '#contributors';
Wikidata offers several different methods of accessing its data, but for this implementation Scott chose the SPARQL endpoint at https://query.wikidata.org/sparql, requesting the JSON-LD serialization for easy manipulation in JavaScript. The SPARQL query in Figure 11 is implemented as a UNION of three different subqueries, to find musicians, bands, or musical ensembles with names or aliases that match the requested contributor’s name, and to potentially return supplemental data to include in the infocard, along with a possible link to a corresponding Wikipedia entry (?wplink).
SELECT ?item ?itemLabel ?itemDescription ?image
(GROUP_CONCAT(DISTINCT ?instrumentLabel;separator="; ") AS ?instruments)
?birthPlace ?birthPlaceLabel ?website ?musicbrainz
?songKick ?twitter ?facebook ?wplink
WHERE {
?item rdfs:label|skos:altLabel|wdt:P1449 'A Tribe Called Red'@en .
# instance of = any subclass of band
{ ?item wdt:P31/wdt:P279* wd:Q215380 . }
UNION
# occupation = any subclass of musician
{ ?item wdt:P106/wdt:P279* wd:Q639669 . }
UNION
# instance of = any subclass of musical ensemble
{ ?item wdt:P31/wdt:P279* wd:Q2088357 . }
OPTIONAL { ?item wdt:P3478 ?songKick } .
OPTIONAL { ?item wdt:P19 ?birthPlace } .
OPTIONAL { ?item wdt:P1303 ?instrument } .
OPTIONAL { ?item wdt:P856 ?website } .
OPTIONAL { ?item wdt:P434 ?musicbrainz } .
OPTIONAL { ?item wdt:P2002 ?twitter } .
OPTIONAL { ?item wdt:P2013 ?facebook } .
OPTIONAL { ?item wdt:P18 ?image } .
OPTIONAL {
?wplink schema:about ?item .
?wplink schema:inLanguage "en" .
?wplink schema:isPartOf <https://en.wikipedia.org/> .
}
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en".
?instrument rdfs:label ?instrumentLabel.
?item rdfs:label ?itemLabel.
?item schema:description ?itemDescription.
?birthPlace rdfs:label ?birthPlaceLabel
}
}
GROUP BY ?item ?itemLabel ?itemDescription ?image ?birthPlace ?birthPlaceLabel
?website ?musicbrainz ?songKick ?twitter ?facebook ?wplink
LIMIT 10
Scott showed an initial prototype to the cataloguers at his library and had a positive reception, as it demonstrated the value of not only being able to combine freely licensed data with their library’s catalogue, but of contributing to that body of data rather than keeping it confined within their own library system. Later iterations received positive feedback at the Music in Canada @ 150 edit-a-thon training session and during a Wikidata breakout session at SWIB17. One of the suggestions was to incorporate a description from Wikipedia, if available, as Wikidata item descriptions are deliberately terse: they are intended only to disambiguate items that have identical labels, so many descriptions are as simple as “Canadian musician”. By comparison, Wikipedia provides richer descriptions that normally include a brief amount of biographical information. Having added the ?wplink attribute to the SPARQL query to retrieve a direct link to the associated English Wikipedia article, Scott used the MediaWiki API to extract the opening text for article and add that to the infocard with a link to the article, per Figure 12.
function addWikipedia(musician, r) {
var wpapi = 'https://en.wikipedia.org/w/api.php?origin=*' +
'&format=json&action=query&prop=extracts&explaintext=true&' +
'exintro=true&titles=';
var wplink = r.wplink.value;
// Strip the WP title from the link
wptitle = wplink.substring(wplink.lastIndexOf('/') + 1);
var req = new window.XMLHttpRequest();
req.open('GET', wpapi + wptitle);
req.onload = function (evt) {
var response = JSON.parse(req.response);
var key = Object.getOwnPropertyNames(response.query.pages)[0];
var description = response.query.pages[key].extract;
// Grab the first line of the article
// Link to article via Wikipedia icon
// Append to the infocard
}
req.send();
}
Results
Testing the widget with a sample of 100 records for music recordings held by Laurentian University, a collection heavily weighted towards classical and jazz, showed that 69.8% of contributor entries (1xx / 7xx fields) in the MARC records returned valid data from Wikidata (spreadsheet). Some of the reasons for failures to find a match in Wikidata included:
- Aliases missing from an existing Wikidata item. For example, in the record on which figure 5 was based, the SPARQL query searched for “k.d. (Kathryn Dawn) lang” when the label for Q230454 was “k. d. lang” and the only alias was “Kathryn Dawn Lang”; simply adding an alias to the Wikidata entry resolved the problem.
- Errors in the MARC record. In the same record, “Orford String Quartet” had been incorrectly transcribed as “Oxford String Quartet”; investigating the reason for the lack of a match resulted in a correction to the source MARC record.
- Failure of the code to correctly order names including more than one comma. For example, “Marriner, Neville, Sir” resulted in a search for “Marriner, Neville, Sir” instead of “Sir Neville Mariner”.
Resolving these failures suggests that the match success rate would have been close to 80% in this sample of records. While the name-based match algorithm can be improved, the best path forward would be to reconcile the records against Wikidata and add $1 subfields with the https://www.wikidata.org/entity/Q### real world object URI to each of the matching 1xx/7xx entries. This would provide the classic advantages of authority control, prevent users from requesting an infocard for an entry with no match, and enable libraries to identify entries that either need to be corrected or that need to be reflected in Wikidata.
The remaining 20% of the sample that is not easily matched in Wikidata represents much of the long tail of topics, domains and areas of local interest, such as French-Canadian composers, missing from the cultures that have dominated Wikidata and Wikipedia, and therefore would benefit most from having effort invested in ensuring they are represented in Wikidata as a first step towards global recognition of these locally notable contributors.
Future Goals
Scott’s library is currently adding Wikidata IDs to the authors and journals in the Canadian Labour Studies Index database, with the goal of contributing to the WikiCite project to build a bibliographic database in Wikidata. He also plans to use Wikidata as an LOD platform for a collection of grey literature about the environmental reclamation of mining sites that would benefit from linkage to concepts and authors not generally available in the broader scientific literature, as well as storing statements about specific mine sites which are currently identified only by rough coordinates. Longer term, Scott hopes to enhance his library system’s MARC records with Wikidata URIs in the $1 to identify real-world objects, following the recommendations of the PCC URI Task Group on URIs in MARC, surfacing those entries for which no match can be found as potentially valuable local information that his library will then prioritize for adding to Wikidata.
Allison-Cassin’s library is working on several initiatives related to Wikidata. York is collaborating with the Association of Research Libraries (ARL) on the previously discussed project focused on exploring Wikidata as a platform for social justice and LOD. This project is using a test case approach to model inclusive, community-led metadata in archives and special collections through the creation of a dataset of just over 200 Indigenous performers and assessing and expanding properties, qualifiers and other terminology. She is also exploring ways data and applications might be used by communities, students and scholars in a pedagogical environment.
Conclusion
Wikidata is one means by which libraries can surface the long tail of subject matter and address the systemic biases and exclusions often present in our systems of description and metadata and society at large. This works at several levels. It addresses the exclusion from participation in the creation of LOD, allows for larger community participation, encouraging the participation of people beyond those involved in metadata or systems work to get involved and understand the role of structured data and allows for the creation of rich data that is often excluded or unavailable in traditional bibliographic data, allowing for a multiplicity of viewpoints and modes of description.
This article described and reflected on some of the ways the authors have used Wikidata as a low-barrier method for creating and using LOD in libraries. The platform enables libraries and other GLAM organizations to easily publish LOD for collections and content. There are many pathways to get involved in the Wikidata community. Creating and editing Wikidata can begin with choosing a thematic area related to a collection of interest or group of scholars or individuals. By actively contributing data, creating applications participating in community initiatives and creating documentation libraries can help to improve the quality, impact and sustainability of the platform for libraries.
Tools and Resources
- News and overviews:
- Asof Bartov’s “A Gentle Introduction to Wikidata for Absolute Beginners [including non-techies!]”
- The Wikidata mailing list is a weekly newsletter detailing events, resources and new properties and developments.
- There is an active Facebook group and a Twitter community around the #wikidata hashtag
- Development:
- Module:Wikidata – English Wikipedia module for accessing data from the Wikidata item associated with a given article (or any article)
- Reconciling datasets with Wikidata via OpenRefine
- Wikidata SPARQL query help
- Wikidata is an instance of the Wikibase software, a specialization of MediaWiki, and supports the MediaWiki API with a module that adds Wikibase-specific “wb” actions: https://www.wikidata.org/w/api.php
- Articles & blog posts of interest:
- The Tom Longboat Awards as Wikidata by Mita Williams
- Research libraries and Wikimedia: A shared commitment to diversity, open knowledge, and community participation by Stacy Allison-Cassin
- Wikidata in Collections: Building a Universal Language for Connecting GLAM Catalogs by Alex Stinson
About the authors
Dan Scott (https://dscott.ca/#i) is an Associate Librarian and Chair of the department of Library and Archives at Laurentian University, where he is responsible for systems and scholarly communications. He is passionate about software freedom and open data, and is perhaps most notable for his contributions to the Evergreen library system and schema.org vocabulary. Dan is still pumped after organizing (with a great deal of assistance) his faculty association’s quite successful strike in the fall of 2017.
Stacy Allison-Cassin is an Associate Librarian and Digital Pedagogy Librarian at York University. Previously she was the W.P. Scott Chair in E-Librarianship and a Cataloguing Librarian for music materials and as co-founder of the scholarly communication initiative at York. Stacy is passionate about metadata, music and critical theory. As an active member of the Wikimedia community, Stacy writes and contributes to articles and content on First Nations, Métis and Inuit peoples and cultures as well as Canadian music.
References
1. Bartholmei, Stephan, Rachel Franks, James Heilman, Mylee Joseph, Vicki McDonald, Anna Raunik, Mia Ridge, and Mark Robertson. “Opportunities for Academic and Research Libraries and Wikipedia.” Columbus, Ohio, 2016. Available from: https://2016.ifla.org/wp-content/uploads/sites/2/2016/08/112-IFLAWikipediaAcademicandResearchLibrariesDiscussioDRAFT.pdf.
2. Europeana. “Get Your Vocabularies in Wikidata…” Europeana (blog), September 1, 2017. https://pro.europeana.eu/page/get-your-vocabularies-in-wikidata.
3. Erik T, Mitchell. “Chapter 4. The Evolving Direction of LD Research and Practice.” Library Technology Reports 52, no. 1 (December 17, 2015): 29–33.
4. Khan, H. J., Folsom, S., Snyder, T., Clark, R., Kelley, B. A., & Nichols, M. F. (2018). SHACL Semantics for Form Building. Presented at the U.S. Semantic Technologies Symposium 2018, Wright State University, Dayton, Ohio. Avaiable from: https://drive.google.com/file/d/1M_xhnG8qYL7M9akvIRSETfOgeSEfS9oh.
5. Goddard, Lisa, and Gillian Byrne. “Linked Data Tools: Semantic Web for the Masses.” First Monday 15, no. 11 (November 7, 2010). Available from: http://firstmonday.org/ojs/index.php/fm/article/view/3120.
6. Juno Award. (n.d.). In Wikipedia. Available from: https://en.wikipedia.org/w/index.php?title=Juno_Award&oldid=828286208.
7. Klein, Maximilian, and Alex Kyrios. “VIAFbot and the Integration of Library Data on Wikipedia.” The Code4Lib Journal, no. 22 (October 14, 2013). Available from: http://journal.code4lib.org/articles/8964.
8. Pattuelli, M. C., Hwang, K., & Miller, M. (2016). Accidental discovery, intentional inquiry: Leveraging linked data to uncover the women of jazz. Digital Scholarship in the Humanities, fqw047. Available from: https://doi.org/10.1093/llc/fqw047.
9. Surfacing Knowledge, Building Relationships: Indigenous Communities, ARL and Canadian Libraries. Availble from: https://scbrwiki.library.yorku.ca/.
10. van Veen, T. (2017, October). Wikidata as a universal (library) thesaurus. Presented at the Wikidata Conference. Available from: https://commons.wikimedia.org/wiki/File:Wikidata_as_universal_library_thesaurus_-_tvv.pdf.
11. Wikimedia Foundation. (n.d.). Wikidata Query Service (WDQS) endpoint usage. Available from: http://discovery.wmflabs.org/wdqs/#endpoint_usage.
12. Wikipedia:Authority control. (n.d.). In Wikipedia. Available from: https://en.wikipedia.org/w/index.php?title=Wikipedia:Authority_control&oldid=833261359
Notes
13. Collaborators include Trina Gover, Ryerson University and Melanie Ribeau, Toronto Public Library. Jamie Lee Morin, the Indigeneous Digital Collections Assistant came up with the term “Indigiwiki” for the group.

Subscribe to comments: For this article | For all articles
Leave a Reply