by Kelley McGrath and Lesley Lowery
Introduction
We’ve been hearing for years, even decades, that the MARC format is dying. Nevertheless, the MARC Advisory Group continues to meet twice a year and continues to approve new fields and subfields. In recent years, many new fields and subfields have been introduced into MARC 21 that could help users if the data they contain were exposed by library discovery interfaces. In this article, we will look at several of these, describing how we incorporated them into our consortial Primo discovery layer and discussing the challenges we encountered.
Primo Norm Rules
Primo is a patron-facing discovery interface for library resources created by Ex Libris that can ingest and combine data from multiple sources. Primo translates incoming data into standardized Primo Normalized XML (PNX) records. The PNX record is divided into sections, such as display, search, facets and links. Each section includes multiple fields, both out-of-the-box fields, such as “display:title,” and locally-customizable fields such as “display:lds12” [1]. Incoming data is transformed into the PNX format by Primo normalization rules (or norm rules), which are maintained in the web-based Primo Back Office [2]. Unlike traditional library catalogs, which generally only allow libraries to turn specific MARC fields and subfields on and off, and to have them displayed and indexed as-is, Primo norm rules enable significant customization of incoming data.
Each Primo norm rule consists of four main parts: source, conditions, transformations and action (figure 1). Source defines what the rule takes as input. This could be a MARC or Dublin Core field, a constant or another PNX field. A rule is only triggered if the input it is looking for exists in the source record. The second section contains conditions that have to be met before the rule will write anything to the PNX record. The third section contains transformations, or changes that are made to the source data before writing it to the PNX record. The options for conditions and transformations are hard-coded and must be selected from a dropdown list in the Primo Back Office. The final section is labeled action and specifies how the output of the rule relates to the output of the other rules for a given PNX field. The output may be added as a new instance of the current PNX field or appended to an instance containing data written by previous rules. The action section also determines whether there can be only a single value for the PNX field or if multiple instances of the field are allowed. We will now provide some examples of how we used the Primo norm rules to provide access to some MARC fields that are not commonly used in library discovery interfaces.
The fields and facets described in this article may all be seen in the sandbox interface at http://alliance-primo-sb.hosted.exlibrisgroup.com/primo_library/libweb/action/search.do?vid=UO_NRWG.
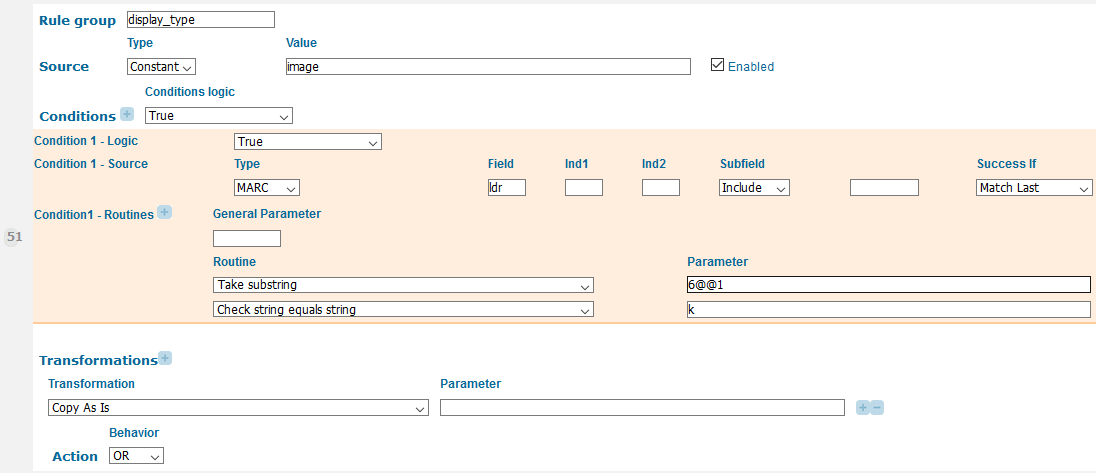
Figure 1. A Primo norm rule in the Primo Back Office interface showing the source, conditions, transformations and action.
Creator and Audience Demographics
Several new MARC fields were created as a consequence of the Library of Congress (LC) developing a new vocabulary for genre and form terms. Although Library of Congress Subject Headings (LCSH) were primarily designed to encompass topical subjects (what a resource is about), they have also traditionally been used to describe genre or form (what a resource is) in certain circumstances. In most cases, the same term is recorded in the same field (650: Subject Added Entry-Topical Term) for both topical use and genre/form use. For the end user, it is usually not possible to distinguish between these two functions when searching. Even when a different term is used (e.g., symphony for topic and symphonies for genre), the distinction is unlikely to be intuitive for a naïve user.
In 2007 the LC began a project to create a new separate vocabulary for genre and form with the intention of phasing out the recording of genre/form information in 650 (Subject Added Entry-Topical Term) and moving it to 655 (Index Term – Genre/Form), a field that is intended specifically for genre and form information.[3] In addition to enabling more precise searching, this change was meant to lead to data that is more suitable for use in faceted interfaces and for algorithmic processing. However, as the sample LCSH strings below show, the goal of implementing clean faceting faced a significant challenge. Although the underlined terms below could be incorporated into this new vocabulary, something had to be done with the related information that was also part of the existing Library of Congress subject headings, but is neither genre/form information nor topical information.
French poetry $y 20th century
English drama $x Women authors
Children’s films
American literature $z New York (State)
Songs (High voice) with piano
To account for this information, LC created some additional new vocabularies, including Library of Congress Demographic Group Terms (LCDGT) to describe characteristics of creators of and audiences for resources. In conjunction with the development of LCDGT, two new fields were added to MARC 21 to accommodate this information: 385 (Audience Characteristics) and 386 (Creator/Contributor Characteristics).
We implemented display, search and faceting of 386 (Creator/Contributor Characteristics). Figure 2 shows the display for a book of plays by English women that included an existing LCSH of “English drama–Women authors.”

Figure 2. The LCSH “English drama–Women authors” is split out to become genre/form
“Drama” + creator demographic group “Women; English; Britons” + original language “English” (the meaning of the term English in LCSH’s “English drama” is ambiguous; in this particular case it signifies both the original language of the dramas and the nationality of the playwrights. Note the variety of constructions found in LCSH for this type of information, such as Nigerian drama (English), English drama–Irish authors, American drama, and Hispanic American drama (Spanish), which makes it quite complex for the average person to search by characteristics of resource creators).
Figure 3 shows an example facet list from a search for “autobiographies.”
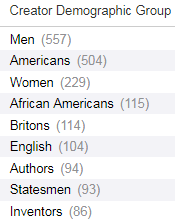
Figure 3. Creator Demographic Group (386) facets from a search for autobiographies.
386 (Creator/Contributor Characteristics) is straightforward to display and facet, but there are many questions about best practices for choosing what data to put in this field. It’s also likely that there is a better way to label this field for the public.
We also implemented display, search and faceting for 385 (Audience Characteristics), but this was more complex. Audience information appears in several places in MARC bibliographic records so we incorporated data from three different sources into a single Primo display field: the audience code in the 008 fixed field (008/22), the recently-created 385 field (Audience Characteristics) and the audience note field (521).
Display of 385 (Audience Characteristics) is straightforward and the rule follows the pattern used in Primo for displaying topical subject fields (figure 4).
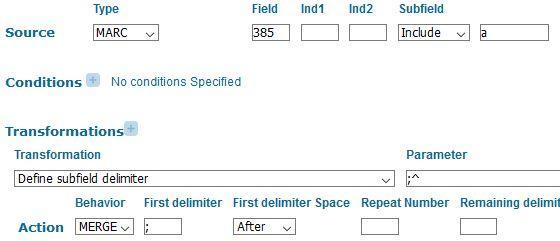
Figure 4. Primo norm rules that displays all the 385 (Audience Characteristics) subfield a’s (Audience term) separated by “semicolon space” punctuation. (Note that ^ signifies a space in Primo’s norm rule expressions.)

Figure 5. Audience facet results and display in Primo.
The 008 (fixed field data) is a little trickier. The meaning of bytes in 008 depends on a combination of position in the 008 and record type in the LDR. 008/22 is not used for target audience in all record formats. In the map format, this byte has a completely different meaning. If maps are not excluded from this Primo norm rule, suddenly all the quadrangle maps will appear to be intended for an audience of preschool children! We therefore add conditions to exclude the record formats (maps, serials and mixed materials) that do not include positions for audience in 008 (figure 6).

Figure 6. First part of 008/22 (Target audience) norm rule showing the condition that checks to make sure the LDR/06 (Type of record) format does not equal maps using Ex Libris’ internal abbreviations for record types where MP = LDR/06 (Type of Record) e or f.
We also added a condition to ignore the fixed field if the 385 field (Audience Characteristics) also exists. This is done to reduce redundancy in display and would be unnecessary if Primo de-duped PNX display fields as it does facets. We preferred 385 (Audience Characteristics) because it supports more granular information, as well as multiple values.
We then isolate the value of the audience fixed field, but, of course, we don’t want to display the raw value. The Primo Back Office provides the ability to create what it calls mapping tables that enable a list of values to be transformed into a second list of values. We send the audience fixed field code to one of these mapping tables to turn it into a human-friendly value for display (figure 7). We use a single mapping table for display, search and faceting. It is important to not only map the coded values from the fixed field to textual terms for display purposes, but also for inclusion in the search index so that users who see a term in a record can search for others like it. Because we also use the textual terms from the LCDGT vocabulary for faceting, we mapped the fixed field codes to that vocabulary to improve collocation. For example, the label for the value “c” in the MARC format is “pre-adolescent.” However, “preadolescents” is a cross-reference for “preteens” in LCDGT so we used “preteens” as our label.
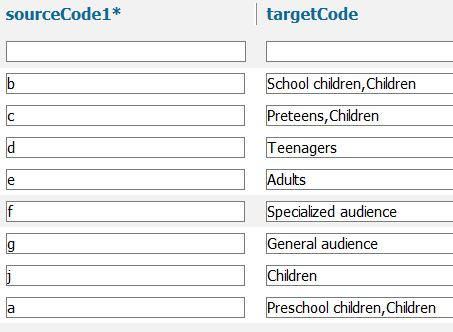
Figure 7. Mapping table that changes 008/22 (Target audience) fixed field values into human-readable strings. The sourceCode1 column contains the input and the targetCode column contains the output of the mapping table. Commas are used to separate multiple output values, which are later separated by the norm rule using the “split field” transformation.
Finally, we display the 521 field (Target Audience Note). This field includes indicator values that mark narrower meanings. We add prefixes to the note display based on these indicator values where applicable, as shown in figure 8 with 1st indicator 1 for interest age level.
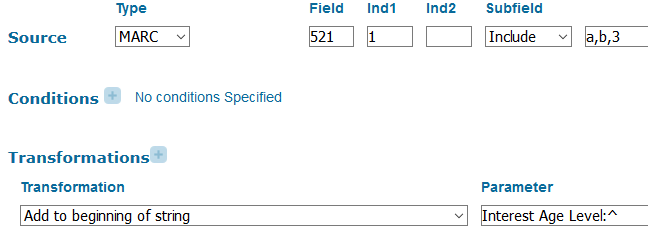
Figure 8. Primo norm rule that takes 521 (Target Audience Note) with 1st indicator 1 as its source and prefixes the content of the note with the associated more-specific label “Interest age level:”
We add both the terms from the 385 (Audience Characteristics) and the terms mapped from the audience fixed field to an audience facet. However, because of the way Primo weights facet values, the facet results are dominated by the fixed field terms, which far outnumber the uses of LCDGT, and it is hard to find examples with LCDGT. It’s also not clear how useful the “general,” “adult” and “specialized” audience fixed field values are as facets since they are much less consistently used than the ones for juvenile materials.
Medium of Performance
Medium of performance is another type of information that is commonly combined with genre in LCSH and now needs to be accommodated somewhere else. LC and the Music Library Association have developed a new vocabulary called Library of Congress Medium of Performance Thesaurus for Music or LCMPT and the 382 (Medium of Performance) field was added to MARC 21 as a place to record this information. 382 (Medium of Performance) is designed to support more complex details about medium of performance than LCSH and includes a large number of subfields. It was also intended to be useful in a faceted environment.
Looking at the raw 382 (Medium of Performance) field below, it is clear that some intervention is needed to make this new data usefully displayable and searchable in Primo.
382 01 $a viola $n 1 $p clarinet $n 1 $a piano $n 1 $s 2 $2 lcmpt
Although the Primo norm rules provide powerful tools for manipulating MARC data, there are some limitations on what is possible, especially for complex fields with many subfields. There are two approaches that can be used to deal with fields that include more than one type of subfield. The first approach is to process each type of subfield separately in its own rule and then combine the results. This allows you to treat specific subfields differently, but it doesn’t preserve the order of the subfields. That is, you could get all the subfield a’s followed by all the subfield n’s. The second approach is to process the different types of subfields with a single rule. In this case, you preserve the order of the data, but you can’t do something different to subfield a from what you’re doing to subfield n. We used a combination of both approaches to turn 382 (Medium of Performance) into something eye-readable. We will now walk through how we got from the raw MARC field shown above to the following human-readable display.
Duet: viola (1); piano (1) (alternate instrumentation: clarinet)
The first rule that applies takes subfield s (Total number of performers), a non-repeatable subfield, as input. Subfield s (Total number of performers) should contain a number representing the total number of performers. We use a mapping table to change numbers into words for display (figure 9). From our example field, the rule takes the input of 2 and maps it to the word Duet.

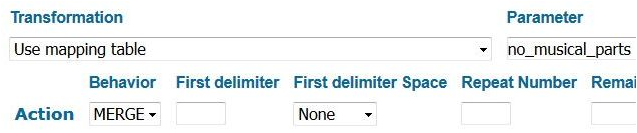
Figure 9. Primo norm rule that sends the contents of 382 subfield s (total number of performers) to the mapping table “no_musical_parts” and outputs the results of the mapping.
The second rule takes its input from multiple subfields: a (Medium of Performance), b (Soloist), e (Number of ensembles of the same type) and n (Number of performers of the same medium) (figure 10). The starting input for this rule in our example is the string “viola 1 1 piano 1”, which retains the order of the data, but does not identify the source subfield for any of the data.

Figure 10. First part of a rule that takes subfields a (Medium of Performance), b (Soloist), e (Number of ensembles of the same type) and n (Number of performers of the same medium) of a single instance of 382 (Medium of Performance) as input.
We then use a transformation to define a subfield delimiter (first line in figure 11). We use a semicolon and space (denoted by ^ in Primo expressions), which results in each subfield being separated by a semicolon and space. In our example, this gives us “viola; 1; 1; piano; 1”.
We then take advantage of the fact that we can identify numbers separately from instrument names to remove the semicolon preceding any number and instead put the number in parentheses. This is a situation that is crying out for a regular expression. There is a transformation in Primo’s documentation that looks like it would be helpful here, but unfortunately, that function is broken. So we explicitly wrote a replace transformation for the numbers 1-9 (figure 11). This will fail if there are ten or more performers coded as playing the same instrument, but that is an uncommon situation. This gives us “viola (1) (1); piano (1)”
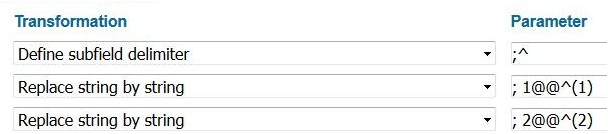
Figure 11. Transformations that separate each subfield with a semicolon followed by a space and then find semicolon, space, number and replace it with space (number). In Primo norm rule transformations, the string to find and the string to replace are separated by “@@” The “^” is used to represent a space in the replacement string.
There is another problem, though, which is that subfield n (Number of performers of the same medium) is used both for the number of performers in the main medium of performance statement and also after doubling and alternate instrumentation as shown in our example with the alternate clarinet part in subfield p (Alternative medium of performance).
382 01 $a viola $n 1 $p clarinet $n 1 $a piano $n 1 $s 2 $2 lcmpt
We don’t want to mix up the main medium of performance with the alternate or doubling instrumentation. For this rule, we only want the subfield n’s (Number of performers of the same medium) that correspond to the default instrumentation. However, we have no way to distinguish these different meanings of subfield n (Number of performers of the same medium), which is causing the multiple appearance of the number 1 after viola. We undertake another series of find and replace actions to remove extra numbers (figure 12). Because we cannot do this conditionally and each transformation only removes a single instance of an extra number, we tried to include enough transformations to account for the vast majority of situations. However, it is still possible to find medium of performance statements in our catalog with extra numbers if you know where to look.

Figure 12. Transformations that find ) space (number) and replace it with just ). This removes the extra numbers.
Finally, the merge action for this rule prepends a colon and space to the instrumentation if there is preceding text, such as the “Duet” written by the previous rule in our example (figure 13).

Figure 13. Data is merged onto an existing instance of a PNX field and is preceded by a colon delimiter, with a space after the delimiter.
The last thing to deal with in this example is the alternative instrumentation in subfield p (Alternative medium of performance). Given our choice between preserving the order of the data and thus associating clarinet with the instrument that it is an alternative for and being able to process the subfield separately, we have chosen the latter. This enables us to separately label the alternative instrumentation. In 2015 the Music OCLC Users Group (MOUG) commissioned a report that found that music librarians preferred a display that looks like
viola or clarinet (1); piano (1)
where subfield p (Alternative medium of performance) is preceded by the word “or” and directly follows the instrument for which it is an alternative [4]. Our display does not preserve the relationship between the viola and clarinet.
viola (1); piano (1) (alternate instrumentation: clarinet)
In order to preface the clarinet in subfield p (Alternative medium of performance) with some indication that it is an alternative, we have to process it in a separate rule (figure 14). We therefore lose the ability to retain the original subfield order.

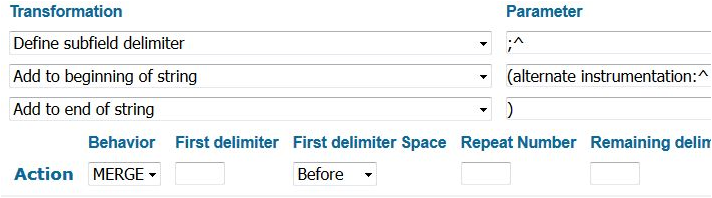
Figure 14. Rule adds “(alternate instrumentation: “ label to the beginning of 382 (Medium of Performance) subfield p (Alternative medium of performance) data, and closes the data with a “)”. Multiple instance of subfield p (Alternative medium of performance) are separated by a semicolon and space.
For the most part, we have just added the 382 (Medium of Performance) subfields to the general search index without any intervention. However, we have included rules to index the words, such as duet and alternate instrumentation, that we generated for display. It turns out that at least some users do want to search by words like “solo.”
Currently, we have implemented three facets based on medium of performance in the 382 field. The first one is a facet for instrument, voice or ensemble type. This includes everything from subfield a (Medium of Performance) and subfield b (Soloist). The terms from subfield b (Soloist) are double-posted with the qualifier solo to help users find pieces that have solo parts for their instruments (figure 15). This seems pretty straightforward, but there are a couple ways this facet behaves that are likely to clash with user expectations or preferences.
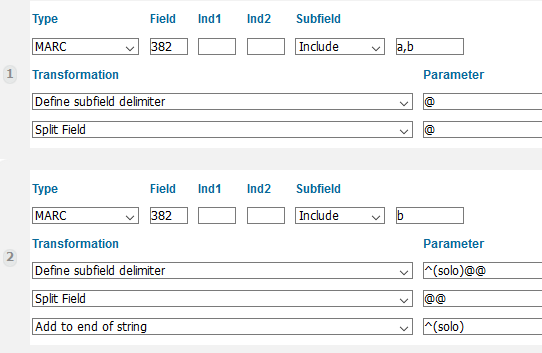
Figure 15. Rules that (1) add instrument/voice/ensemble type and (2) double-post soloist data with (solo) qualifier.
First of all, users probably want to find pieces that include all the instruments or voices that they select. That is, they want to do a Boolean AND search. If users select terms consecutively from the facet list in Primo, they will get an AND search. However, if they select multiple terms at once using Primo’s checkboxes and the “apply filter” button (figure 16), Primo will perform an OR search. This makes sense from the standpoint that for most long lists, an OR search would be preferred, and it’s desirable for all the facet lists to predictably exhibit the same behavior. But it probably isn’t what users want from this particular facet most of the time.
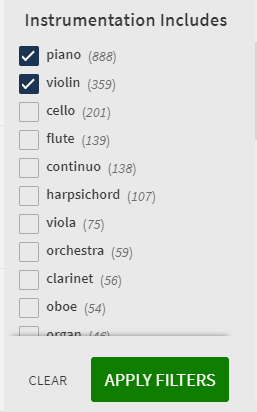
Figure 16. Primo check list of facet values.
Another important thing to notice is that the facets are working against bibliographic records for the whole resource being described so violin and piano just have to be somewhere in the record. The terms don’t have to be referring to the same piece as in the example in figure 17, which includes a piano concerto and a violin concerto.

Figure 17. Facet values are related to different pieces that are part of a compilation.
In addition to medium of performance, we also implemented a facet for total number of performers if that is given (figure 18). It doesn’t attempt to count ensembles, but just lists the presence of an ensemble. Some of the larger numbers of individual performers should possibly be double-posted under ensemble, but we’re not doing that right now. Again, the facets are working against the bibliographic record so if a user picks 1 performer and saxophone, there’s no guarantee that all the results will include a piece for solo sax. However, the results are not as misleading as they might be thanks to relevancy ranking and the fact that users can only ever see the top twenty values in a given facet.

Figure 18. Facet results for number of performers.
In order to compensate somewhat for that weakness, we have also created a medium of performance statement facet (figure 19), which allows users to specify exactly what combination of instruments or voices they are looking for.
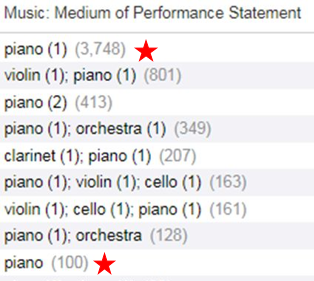
Figure 19. Medium of Performance Statement facet values.
There are a couple places where this facet doesn’t provide the collocation that users will expect. One is due to the fact that the MARC format allows you to omit the 1 for number of performers for any instrument or voice that has only a single performer. Since the facets are looking at literal text strings, they see piano and piano followed by 1 as two different things. (starred lines in figure 19) This is an old screenshot and we have since been able to resolve this issue by supplying a 1 following any medium of performance that doesn’t have a number of performers specified. This improves collocation in most cases, but does not account for situations where counting performers is not straightforward and conflates some cases where the number of performers is in fact unknown or unspecified. For instance, when a score includes multiple percussion instruments, in many cases, it is possible for a single performer to play more than one of the instruments [5].
A thornier issue is that the instruments or voices are not listed in a standard order, which again results in different strings that don’t collocate. The first and third lines in figure 20 both contain the same instrumentation, just in a different order. This is unlike LCSH headings for medium of performance, where there are rules for ordering the instruments so that correctly-constructed headings do collocate. As far as we can tell, reordering the instruments is beyond the capability of Primo’s data manipulation tools so the only solution would be to do some massaging of the data before sending it to Primo.

Figure 20. Lack of collocation for Medium of Performance Statement facet values.
Country of Production
One of the challenges of working with MARC data is dealing with inconsistencies. Definitions of fields, as well as practices and rules for entering data have changed over time. Incorrect information will exist in any large dataset, but lack of effective validation features in most software for editing MARC records leads to a higher error rate than would otherwise exist. The rules we wrote for dealing with the 257 field (Country of Producing Entity soon to be renamed Area of Producing Entity) [6] are a good example of compensating for this problem.
The 257 field was originally defined as Country of Producing Entity for Archival Films. It was designed to support the data element for Country of Production in Archival Moving Image Materials: A Cataloging Manual (AMIM) [7]. AMIM defines country of production as the country or countries where the headquarters of a film’s production company or companies are located, or the location of an individual producer if there is no production company. This was a purely descriptive element and contained values such as
257 $aU.S.
257 $aU.S. ; France ; West Germany.
257 $a[S.l.].
Prior to 2009, a controlled vocabulary was not used and the United States was commonly identified by the abbreviated form “U.S.”. Subfield a (Country of producing entity) was not repeatable and multiple countries were separated by the prescribed punctuation “space-semicolon-space.” The Latin abbreviation s.l. (sine loco) was used if the location of the producing entity was unknown.
In 2009, the field was renamed Country of Producing Entity and the limitations to archival cataloging and to moving images were both dropped, although the field has not seen much uptake outside of moving image cataloging. It was also revised to support controlled vocabulary. Both the field as a whole and subfield a (Country of producing entity) were made repeatable and subfield 2 (Source) was added as a place to record a code for the vocabulary from which the country name(s) were taken. Catalogers primarily use the LC Name Authority File (NAF) as a source for country names in 257 (Country of Producing entity) so the first two examples given above would appear as follows in current, non-archival cataloging.
257 $aUnited States$2naf
257 $aUnited States$aFrance$aGermany (West)$2naf
We are not aware of any method being used to record an unknown location with a controlled vocabulary. The MARC format still supports the older AMIM-style usage so our norm rules have to be prepared to deal with both forms of data. In addition, in the wild there exist examples that incorrectly mix both of these forms of recording data.
Using the punctuation from AMIM and the repeated subfield and source vocabulary in $2 from the controlled vocabulary method:
257 $aItaly ;$aFrance$2naf
Using an indication of controlled vocabulary in $2, but combining multiple locations in a single $a and separating them with punctuation:
257 $aItaly ; France$2naf
Identifying the variations that exist in any real dataset and figuring out how to deal with them is an iterative process. We eventually settled on the sequence of transformations shown in figure 21 to achieve a consistent display.

Figure 21. Transformations for 257 Country of Production.
Table 1 walks through the effects of the transformations on each of the variants described above. The fourth variant is omitted as its $a (Country of producing entity) differs from the first variant only because it ends in a period, which is removed in the sixth transformation. Yellow highlighting is used to show the effect of each transformation. In the table “_” indicates the addition of a space and “ ” indicates that a character was removed and replaced by nothing. In step 3, the transformation “replace spaces by string” is a necessary intermediate step because the general transformation “replace string by string” will not take a space as part of its input to find. Note that in Primo transformations “^” denotes a space and “@@” is used to separate the string to find and the string to replace it with.
Table 1. Transformation impact on source data variants
| Source = 257$a | $aFrance ; Italy. | $aFrance$aItaly | $aFrance ;$aItaly. | |
|---|---|---|---|---|
| 1 | $a ? “; “ | France ; Italy. | France;_Italy | France ;;_Italy. |
| 2 | “;;” ? “;” | France ; Italy. | France; Italy | France ; Italy. |
| 3 | “ “ ? “++” | France++;++Italy. | France;++Italy | France++;++Italy. |
| 4 | “++;” ? “;” | France;++Italy. | France;++Italy | France;++Italy. |
| 5 | “++” ? “ “ | France;_Italy. | France;_Italy | France;_Italy. |
| 6 | Remove “.” from end | France; Italy | France; Italy | France; Italy |
It is also necessary to think about consistency for facets. Because Primo only displays a limited number of values for dynamic facets (Primo facets where the range of possible values is not limited to a predetermined list), we wanted to minimize redundancy in the results. We therefore only draw the facet values from 257 (Country of Production) fields that include a subfield 2 (Source) with “naf” indicating that the country names are in the form used in the LC Name Authority File (figure 22). Primo provides transformations that allow us to split each subfield a into its own PNX facet field and to remove trailing semicolons and periods. Trailing characters in all but the final subfield have to be removed before using the “remove characters from the end” transformation as this transformation only acts on the final characters of the field as a whole. Although we could additionally split subfield a on internal semicolons, we have currently chosen not to do that. Instead we treat multiple places recorded in a single subfield a (Country of producing entity) as metadata errors to be cleaned up as they are identified.
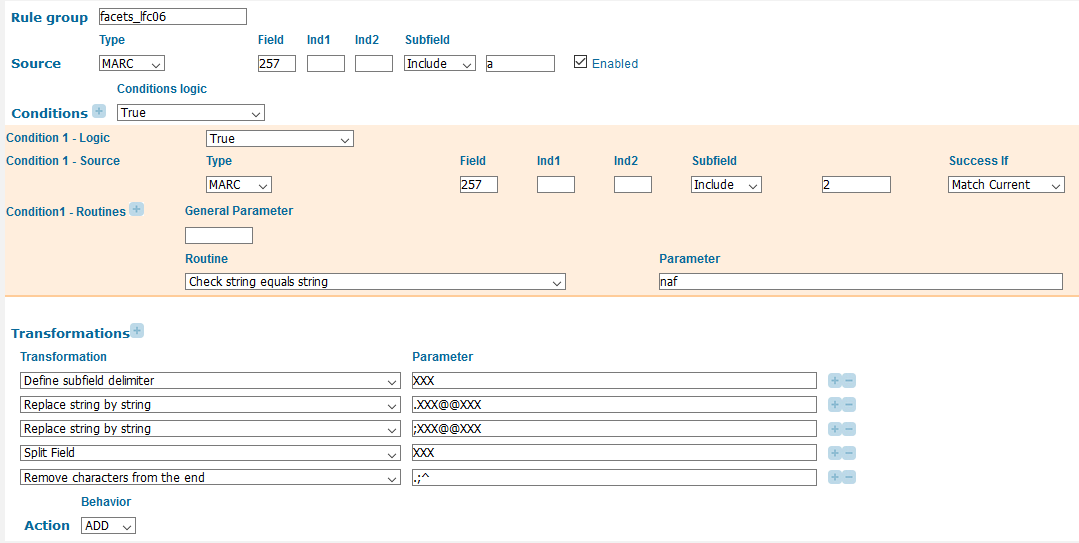
Figure 22. Primo norm rules for the 257 (Country of Producing Entity) facet. Note the condition that checks to make sure the 257 field currently being processed includes subfield 2 with a source code for the LC Name Authority File and the transformations to remove ending punctuation and separate each instance of the repeatable subfield a (Country of producing entity) into its own PNX facet field.
Composers, Directors and Performers
The MARC format has long had subfields that can be used to record the relationship between access points for names of agents and the resource being described. Roles such as editor and composer can be recorded either as relator terms (usually in subfield e) or as relator codes (in subfield 4). The emphasis on relationship designators in the new cataloging standard Resource Description and Access (RDA), which are recorded in subfield e as relator terms in MARC, has driven a resurgence of interest in these relationships.
The group that maintains the Primo norm rules for the Orbis Cascade Alliance has been mostly reactive, focusing on requests from member libraries. One of the requests we received was to make use of relationship designators, which indicate the relationship between a person or other agent and a resource, for search and faceting. Initially, it was not clear how we might effectively provide access to relationship designators via facets. It is possible to just add the relationship designators to the end of names in the creator and contributor facet. However, this has several significant drawbacks, as shown in the hypothetical example below.
Clint Eastwood, 1930- (116)
Clint Eastwood, 1930- actor (45)
Clint Eastwood, 1930- director (23)
Clint Eastwood, 1930- director, actor (26)
First of all, many names in our dataset are not associated with relationship designators. Many of the 116 unqualified instances of Clint Eastwood probably should be marked as actors or directors, leading to a lack of both precision and recall.
Secondly, some names are associated with multiple relationship designators. We do not think it is possible to separate these with Primo norm rules. In the example above, there are actually 71 results for Eastwood as actor, but they are split between the ones marked only as actor and those marked as both actor and director. In order to get all the resources for which Eastwood is an actor, a user would have to select both facets, which is not intuitive.
Finally, because Primo only displays a limited number of values for this facet, splitting names by role can lead to a significant reduction in the variety of names the user can pick from. This problem is exacerbated by the fact that records can potentially contain role information in varying degrees of specificity (actor vs. performer, director vs. film director), from multiple vocabularies (RDA’s “director” vs. AMIM’s “direction”) and either as terms or as codes ($e director vs. $4 drt). It is possible, but complex, to reduce some of this variation.
Instead of adding relationship designators to names in the creator and contributor facet, it is also possible to create separate facets for specific roles (see example at http://sinenomine.co.uk/curwen/?ix0=NAME&id0[]=119&roleback=&letter=s) [8]. This is the approach we took. It is not practical to make facets for all possible roles. The MARC Code List for Relators alone includes 268 valid terms [9]. Even if facets were made for all of those, usability would remain a big challenge and standards such as RDA in its instruction 18.15.1.3 (Recording Relationship Designator) allow the use of “another concise term” if none of the relationship designators in the RDA vocabulary is “appropriate or sufficiently specific.” [10]
We selected three roles for experimentation: composer, director and performer. We selected these for two reasons. First, we believe there are use cases where patrons would benefit from being able to search and browse for names in these categories separately. Secondly, role information is more likely to be present in records for music and moving images than in book records. Although $e (relator term) was commonly used to identify non-author roles, such as editor or translator, in older pre-AACR2 records, it was rarely used during the period when AACR2 was the predominant cataloging standard. Most libraries followed the Library of Congress Rule Interpretation that said not to record functions except for illustrators of children’s books. With the implementation of the RDA cataloging standard in 2013, the use of relationship information in name access points became far more widespread and consistent, but the legacy of decades of cost saving by not adding this information remains.
For composers and directors, we currently look only at personal names in 100 (Main Entry-Personal Name) and 700 (Added Entry – Personal Name). For performers, we look at both personal names and at corporate names in 110 (Main Entry – Corporate Name) and 710 (Added Entry – Corporate Name) to pick up performing groups. The rules take the name subfields that we will display in the facet as input. We then use a series of conditions about data in the same instance of the MARC field to flag the name if it is associated with the role that we’re looking for. For example, for the composer facet we look for the string “composer” in $e (relator term) or “cmp” in $4 (relator code) (figure 23).
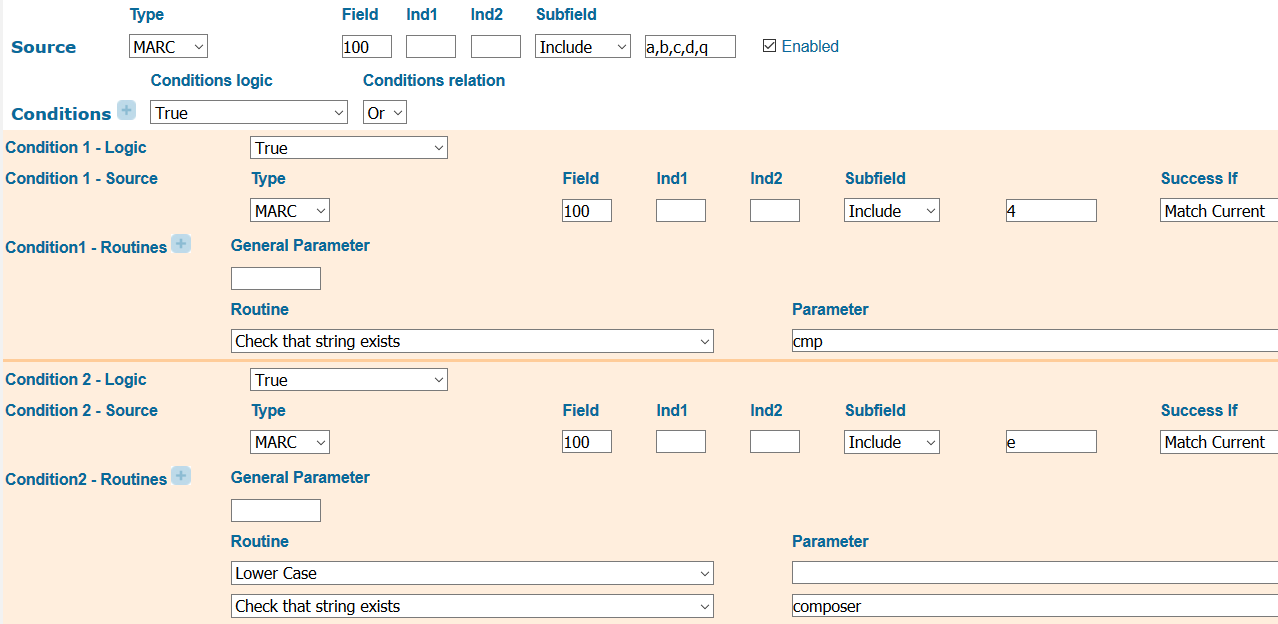
Figure 23. Primo norm rule for composer facet writes name from 100 field (Main Entry-Personal Name) if that 100 field includes a relevant relator code or term.
When working with MARC data, it is sometimes possible to compensate for missing data by making inferences from other data in the record. In the case of the “composer” relationship, we are able to increase recall in this way. For scores, we assume that all 100 fields (Main Entry-Personal Name) and names from analytic name-title access points in 700 (Added Entry – Personal Name) are composers. There are occasional older records for scores where the 100 field (Main Entry-Personal Name) contains an editor or compiler, but the increase in recall from assuming that 100 (Main Entry-Personal Name) contains a composer far outweighs the loss of accuracy. For musical sound recordings, we only inferred that the 100 (Main Entry-Personal Name) represents the composer if a uniform title was also present in 240 (figure 24). AACR2 cataloging permits performers or conductors to be recorded in 100 (Main Entry-Personal Name) for musical recordings in some cases. However, if 240 (Uniform Title) is present, it almost certainly means that the name in 100 (Main Entry-Personal Name) is the composer of that title. For recordings, we again included all the names from name-title entries in 700 (Added Entry – Personal Name) with 2nd indicator 2 (analytic added entries).
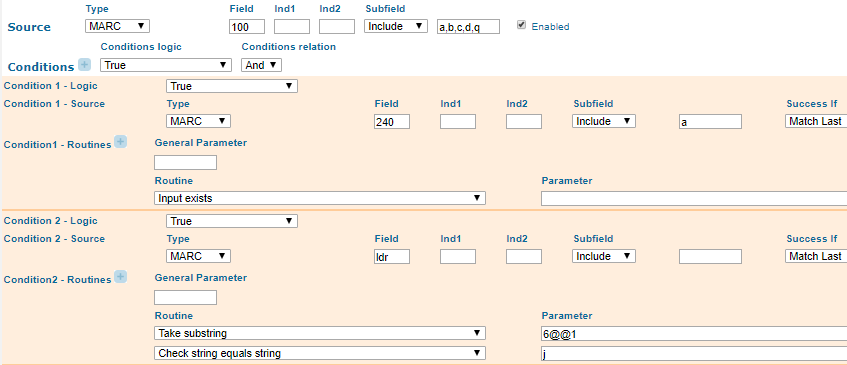
Figure 24. Primo norm rule that takes the subfields from 100 (Main Entry-Personal Name) that we intend to display in the composer facet. Features two conditions that must both be true: (1) 240 (Uniform Title) exists and (2) LDR/06 (Type of record) equals “j”(Musical sound recording).
Unlike composer, which can be accurately identified by the presence of the word composer in the relator term in subfield e, the “director” relationship presented a challenge due to the multiple contexts in which the word “director” appears. We both had to account for the various strings that identify directors (“director,” “direction,” “film director,”) and exclude strings that include the word director, but specify a different role (“director of photography,” “art director”). To identify potential strings for matching, we reviewed the MARC relator code list, the list of RDA relationship designators and the terms used in AMIM.
MARC relator codes are all three-letter strings and are recorded in subfield 4 (Relator code). There may be multiple instances of subfield 4 (Relator code) in a single 100 (Main Entry-Personal Name) or 700 (Added Entry – Personal Name) field as a person may have performed multiple functions. The Primo rule takes all the subfield 4’s (Relator code) in a single field as input as a single string with a space separating each subfield. So “$4drt$4pro$4act” is turned into “drt pro act” when subfield 4 (Relator code) is the source for a rule or condition. The MARC relator code strings are unique so it is sufficient to test for the presence of “drt” anywhere in the input from subfield 4 (Relator code) in order to decide to write the associated name in that field to the director facet. This may become more complicated in the future as the definition of subfield 4 (Relator code) has recently been expanded to allow the use of URIs [11]. This greatly expands the number of potential values for subfield 4 (Relator code), which means that a search for a MARC relator code such as “act” (actor) could pick up false drops where, for example, the string “act” is part of the domain name of a URI.
Relator terms are usually recorded in subfield e. 111 and 711 (conference names) are exceptions. Here relator terms are recorded in subfield j because a subfield for relator terms for conference names was only defined recently in response to RDA and subfield e was already in use. For the most part, our Primo norm rules for relator terms, like the rules for relator codes, merely check for the presence of a string, such as “television director.” Like subfield 4 (Relator code), subfield e (Relator terms) can be repeated. This creates a difficulty for identifying the plain string “director.” We want to pick up director when it is one of a number of relator terms as in “$edirector,$eproducer,$eactor,” but we don’t want to get “$edirector of photography.” To identify “director” when it is the only term in a specific subfield e, we have to isolate the strings in each individual subfield. To do this, after removing any periods or commas at the end of a subfield, we change the subfield delimiters to “+++” which gives “director+++producer+++actor”. We then add “+++” to the beginning and end of the whole string and look for “+++director+++” (figure 25).
If no matching terms or codes are present, we did not attempt to infer a directorial relationship.
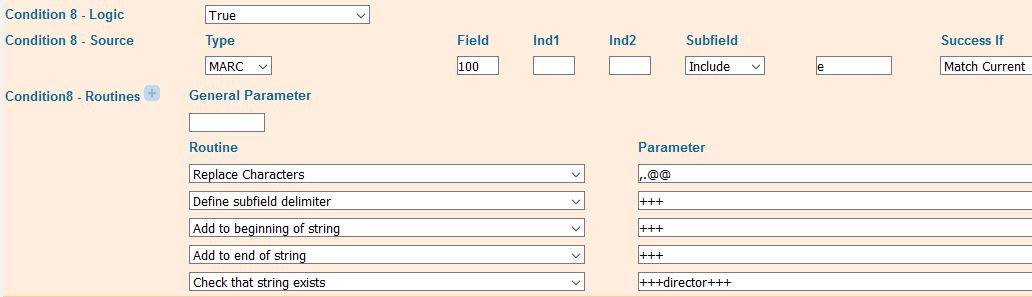
Figure 25. Condition that identifies plain string “director.”
We tried to include as many types of performers as possible in the “performer” facet. RDA helpfully subarranges many types of performers under the performer relationship designator. We browsed the list of MARC relator codes for equivalents to the RDA terms and anything else that implied performance. This results in a rule with a long list of “or” conditions that test for the presence of terms and codes for roles such as “performer”, “actor”, and “musician” (figure 26). If no matching terms or codes were present, we did not attempt to infer performer relationships.
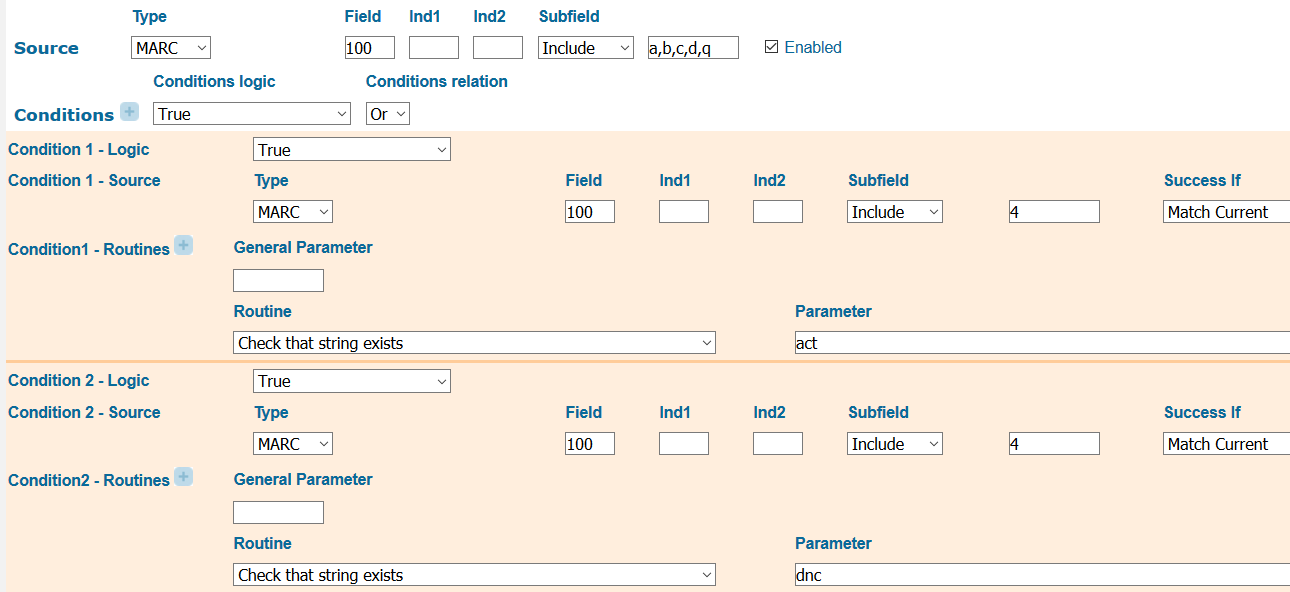
Figure 26. Norm rule for performer facet, showing conditions for “actor” and “dancer” relator codes.
Challenges
As with any innovation that attempts to capitalize on the granularity of MARC coding, bringing these new display fields and facets to our users via the discovery interface provided challenges large and small. Some of the problems we encountered are areas of concern in ANY discovery tool. Others were specific to our use of Ex Libris’s Primo discovery interface.
One general challenge is something we’ve dubbed the “chicken-or-egg” question. Although no large-scale dataset is likely to support perfect recall, new fields that aren’t widely used will suffer from significantly incomplete results when used as faceting values. This causes users to see them as inaccurate, and degrades trust in the facet’s accuracy, leading to disuse. This situation makes institutions hesitant to add facets or develop other functionality for new fields in their public search interfaces – which makes their cataloging shops hesitant to spend time encoding them. This results in the new fields not being widely used, and the cycle continues.
To address this problem, it’s possible to engage in retrospective conversion projects. The American Library Association’s Subject Access Committee is optimistic about the potential for “retrospective implementation of faceted vocabulary terms using algorithms developed, vetted, and tested by expert communities.” [12]. In fact, the Music Library Association has partnered with Gary Strawn to develop a tool that automatically adds MARC fields for non-topical facets, such as medium of performance, based on LCSH subject headings in individual bibliographic records for music in OCLC’s Connexion metadata editor. [13][14], (Files available at http://files.library.northwestern.edu/public/Music382/). The tool is currently intended to be paired with manual review by an informed user before updating the record. Caution should be exercised here, because such projects sometimes use incomplete or inaccurate algorithms to batch process records, which can result in badly-converted data. Retrospective conversion is limited to information that was previously recorded in an identifiable way and will also carry over inaccuracies from the existing data. Retrospectively-converted data will generally be less accurate, less complete and less granular than data added with human review. Our consortial catalog subscribes to updates to OCLC WorldCat master records so we hope that the combined effort of retrospective metadata enhancement and the wider community of catalogers will help us get beyond the “chicken-or-egg” dilemma.
Another problem in most discovery systems is search specificity in records for aggregates like music compilations on CD and literary anthologies. For instance, in the case of our “Medium of performance” facet, users limiting by multiple instruments will get results with those instruments present in the record – but that doesn’t mean the instruments all appear in the same piece. We’ve tried to improve this situation by providing the Medium of Performance Statement facet, which groups the instrumentation for each piece. However, if the user is looking for a specific medium of performance statement in a piece by a specific composer or in a specific key, they’re back to the aggregate problem (figure 27).
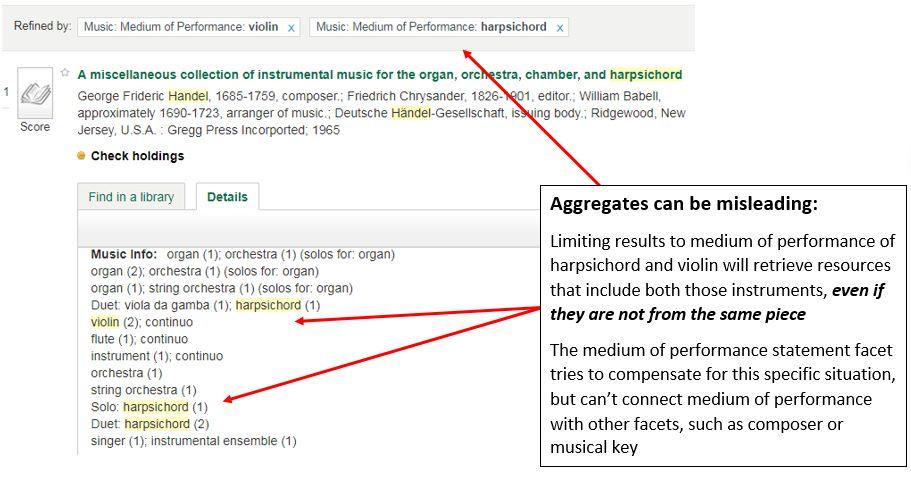
Figure 27. Aggregate records can defy user expectations when faceting.
Another challenge is the question of discovery “real estate”. One reason that many libraries in our consortium haven’t implemented new facets is that there are usability challenges with a long list of facets. Many of these fall “below the fold,” making them easy for users to miss. Amazon and other retails sites often compensate for this problem by showing a shorter list of facets that are contextually linked to the user’s search. One way to achieve this is to build a material-specific sub-interface in your library’s discovery interface. This raises its own crop of new challenges, however. How will you market the sub-interface to bring it to users’ attention? How easy is it to switch between the general search interface and the material-specific one? Will users get confused about which interface they’re using? [15]
Other challenges we came up against were specific to our discovery layer, Ex Libris’s Primo. In theory, facets could be used not only for narrowing searches, but also for open-ended browsing and exploring of a library’s collection [16]. However, Primo does not support true exploratory search [17] due to processing limitations. Users must enter a search term before they are shown any facets. Primo also limits the number of facet values that are displayed to the end user in most cases.
Primo supports two types of facets. Static facets are based on enumerated lists where all the possible values are determined in advance and have complete recall. In the case of static facets, the users are presented with all the values found in their complete result set and selecting a facet value will retrieve all the records in the database with that value. However, static facets are limited to relatively short lists of values. We use static facets for things like resource types and the MARC language codes. The MARC language code list contains around 500 values and it’s not clear how many more values could be supported by a static facet. Primo also supports dynamic facets, which use whatever terms occur in the data. In the out-of-the-box Primo configuration, dynamic facets select the top 20 terms that occur in that PNX facet field in the top 200 ranked records in the user’s result set and display only those twenty terms as options. Each facet value is qualified by the number of records that it will retrieve if selected. This total matches against only the first 50,000 records in the result set so it will be incomplete if the user has done a broad search. The number of terms shown and the number of records from which those terms are drawn can be adjusted, but there is a trade-off between improved recall and system performance. [18]
In Primo, customers can activate a database of article-level discovery data called the Primo Central Index (PCI). While access to this data greatly improves discovery for specific scholarly resources, the PCI metadata does not go through the same normalization process as the metadata in our local bibliographic database (Ex Libris’s Alma). The result is that the customized facets and display fields we’ve built for Primo cannot incorporate the data from the PCI. Only “out of the box” facets and fields can make use of the PCI metadata. We also have no control over the values that are written to the PCI PNX records. We would like to experiment with building material-specific sub-interfaces for music or videos, but we are unable to find a way to incorporate the PCI resources. In fact, we cannot even create an accurate resource type facet for online audio and online video because the PCI records contain a value of “media” for both audio and video. The two types of resources are identified separately for display so the necessary metadata seems to be there, but we are forced to create a single “eAudio & eVideo” resource type facet to align our local materials with the records coming from the PCI.
We’ve also been frustrated in our work by Primo’s interface for building customized fields and facets. As shown in this article, Primo uses normalization rules to translate MARC metadata into XML that can be used by the Primo front end. Like most SaaS application configurations, these rules are managed via a browser-based GUI with hard-coded elements. That gives us a fixed set of logical conditions and data transformations that we can use to find specific MARC data and turn it into user-friendly elements in Primo. Apart from this inflexibility, some specific interface problems we’ve encountered are broken transformations that require multi-step workarounds, long page load times, and limitations on copying single rules from one rule set to another.
One final problem of note in our specific case is that we would like to create MARC field-specific search and browse indexes for Primo. However, this is not currently supported. We can build “good enough” functionality in this regard by customizing “lateral linking” (hyperlinked) fields in Primo, but we very quickly come up against some limitations here as well. First, the limit in Primo is 9 locally-defined linking fields. Recent developments have seen an increase in the number of available “out of the box” linking fields, but not for locally-defined fields. Furthermore, these linking fields provide functionality that’s similar to faceting, but not equivalent. A user clicking on the linking field executes a new search rather than limiting their current search results. Whether this behavior is acceptable depends on local user expectations and the search context.
Conclusion and Looking Forward
We’ve been able to use many of the new fields and subfields introduced into MARC 21 to add user-friendly features to our consortium’s faceted discovery interface. While some of those developments were straightforward, others proved more challenging to achieve. Some of those challenges were due to the nuances of MARC and the inconsistencies of legacy data, while others were due to the nuances of our discovery tool (and of discovery systems in general). Despite these challenges, we feel strongly that our work has helped users across our consortium find the resources they need to advance their scholarly work.
As time goes on, and the use of fuller and more structured metadata increases, it is critical for libraries to explore new ways of making that metadata available for their users in human-readable displays and user-friendly elements like facets and search indexes. While these developments can present many challenges, we also feel confident that discovery tools will continue to evolve, making the process of customization easier and more sustainable as well.
References
[1] Ex Libris. 2018. The PNX Record. In: Ex Libris Knowledge Center. [Internet][Jerusalem]: Ex Libris; [cited 2018 June 5]. Available from: https://knowledge.exlibrisgroup.com/Primo/Product_Documentation/Technical_Guide/010The_PNX_Record
[2] Ex Libris. 2018. Working with Normalization Rules. In: Ex Libris Knowledge Center. [Internet][Jerusalem]: Ex Libris; [cited 2018 June 5]. Available from: https://knowledge.exlibrisgroup.com/Primo/Product_Documentation/Technical_Guide/020Working_with_Normalization_Rules
[3] Library of Congress, Policy and Standards Division. 2017. Introduction. In Library of Congress Genre/Form Terms for Library and Archival Materials (LCGFT) [Internet]. Washington, D.C.: The Library of Congress. p. 1-6. [cited 2018 June 5]. Available from: https://www.loc.gov/aba/publications/FreeLCGFT/2017%20LCGFT%20intro.pdf
[4] Belford R. 2015. WorldCat Discovery Display Preferences for Medium of Performance. Columbus, OH: Music OCLC Users Group. Available from: http://musicoclcusers.org/wp-content/uploads/WCD_Medium_Report_201504291.pdf
[5] Lee D. 2017. Numbers, instruments and hands: the impact of faceted analytical theory on classifying music ensembles. Knowledge Organization [Internet]. [cited 2018 June 5]; 44(6):405-415. Available from: http://openaccess.city.ac.uk/18645/
[6] Library of Congress Network Development and MARC Standards Office. 2017. MARC Proposal No. 2017-10, Rename and Broaden Definition of Field 257 in the MARC 21 Bibliographic Format. MARC 21 Proposals [Internet]. [cited 2018 June 5]. Available from http://www.loc.gov/marc/mac/2017/2017-10.html.
[7] Library of Congress. Archival Moving Image Materials: A Cataloging Manual (2nd Edition) [Internet]. Washington, D.C.: The Library of Congress; 2000 [cited 2018 June 7]. Available from: https://archive.org/details/AMIM2 or via Cataloger’s Desktop.
[8] Camden B. 2013. Relationship Designators and Facets: VCAT@Penn In: Program for Cooperative Cataloging Participants Meeting; 2013 June 27; Orlando. Available from: https://www.slideshare.net/BethCamden/relationship-designators-and-facets-vcatpenn
[9] Library of Congress Network Development and MARC Standards Office. 2018. Relator Code and Term List — Term Sequence: MARC 21 Source Codes. MARC 21 Proposals [Internet]. [cited 2018 June 5]. Available from http://www.loc.gov/marc/relators/relaterm.html.
[10] RDA Toolkit [Internet]. [updated 2017 April]. American Library Association, Canadian Federation of Library Associations, and CILIP: Chartered Institute of Library and Information Professionals; [cited 2018 June 7]. Available from: http://access.rdatoolkit.org/
[11] Library of Congress Network Development and MARC Standards Office. 2017. MARC Proposal No. 2017-010, Redefining Subfield $4 to Encompass URIs for Relationships in the MARC 21 Authority and Bibliographic Formats. MARC 21 Proposals [Internet]. [cited 2018 June 5]. Available from https://www.loc.gov/marc/mac/2017/2017-01.html.
[12] Working Group on Full Implementation of Library of Congress Faceted Vocabularies. 2017. A Brave New (Faceted) World: Towards Full Implementation of Library of Congress Faceted Vocabularies. Chicago (IL): American Library Association, Association for Library Collections and Technical Services, Cataloging and Metadata Management Section, Subject Analysis Committee, Subcommittee on Genre/Form Implementation. Available from: http://www.loc.gov/aba/pcc/documents/PoCo-2017/BraveNewFacetedWorld-170713.pdf
[13] Mullin C. 2018. Retrospective Implementation of Faceted Vocabularies for Music. Middleton (WI): Music Library Association, Vocabularies Subcommittee. Available from: http://works.bepress.com/casey-mullin/12/
[14] Mullin C, Strawn G. 2018. Deriving Faceted Terms from Library of Congress Subject Headings for Music: Challenges and Possibilities. In: Music Library Association Annual Meeting; 2018 Jan 31 – Feb 4; Portland, OR. Available from: https://hcommons.org/deposits/item/hc:19023/
[15] Music Library Association. Music Discovery Requirements [Internet]. Middleton (WI): Music Library Association; 2017 [cited 2018 June 5]. Available from: https://www.musiclibraryassoc.org/mpage/mdr_IVF
[16] McGrath K, Kules B, Fitzpatrick C. 2011. FRBR and facets provide flexible, work-centric access to items in library collections. Proceedings of the 11th annual international ACM/IEEE joint conference on Digital libraries, p.49-52. Available from: https://doi.org/10.1145/1998076.1998085
[17] Exploratory search. 2018. In Wikipedia. [Internet]: Wikimedia Foundation, Inc.; [cited 2018 June 5]. Available from: https://en.wikipedia.org/wiki/Exploratory_search
[18] Ex Libris. 2018. Facets. In: Ex Libris Knowledge Center. [Internet][Jerusalem]: Ex Libris; [cited 2018 June 5]. Available from: https://knowledge.exlibrisgroup.com/Primo/Product_Documentation/060Back_Office_Guide/100Facets
Suggested Reading
Library of Congress information page for LCDGT
http://www.loc.gov/aba/publications/FreeLCDGT/freelcdgt.html
McGrath, Kelley. Getting More out of MARC for Music and Movies with Primo: Strategies for Display, Search and Faceting (2017 OLAC Conference poster) http://pages.uoregon.edu/kelleym/publications/Primo&MARCforVideo&MusicPoster.pdf
McGrath, Kelley. Using MARC Facets for Music with Primo: Strategies and Challenges (ALA Midwinter 2018 presentation)
http://pages.uoregon.edu/kelleym/publications/McGrath_Using_MARC_Facets_for_Music_with_Primo.pptx
McGrath, Kelley and Lesley Lowery. Getting More out of MARC with Primo: Strategies for Display, Search and Faceting (2018 ELUNA presentation) http://pages.uoregon.edu/kelleym/publications/Getting_more_out_of_marc_with_primo-Eluna2018.pptx
Music Library Association Music Discovery Requirements (2017) http://www.musiclibraryassoc.org/mpage/mdr_IA
Music Library Association LCMPT Best Practices (Version 1.3, January 2018) https://c.ymcdn.com/sites/www.musiclibraryassoc.org/resource/resmgr/BCC_Resources/BPsForUsingLCMPT.pdf
Music Library Association LCGFT for Music Best Practices (Version 1.1, January 2018) https://c.ymcdn.com/sites/www.musiclibraryassoc.org/resource/resmgr/BCC_Resources/BPsForUsingLCGFT_Music.pdf
OCLC’s longitudinal statistics on field usage http://experimental.worldcat.org/marcusage/
The University of Oregon’s Primo sandbox for norm rules testing at http://alliance-primo-sb.hosted.exlibrisgroup.com/primo_library/libweb/action/search.do?vid=UO_NRWG
About the Authors
Kelley McGrath (kelleym@uoregon.edu) is Metadata Management Librarian at the University of Oregon Libraries. She is an experienced media cataloger and has been active in OLAC (Online Audiovisual Catalogers) for many years. She is a member of the Orbis Cascade Alliance Primo Norm Rules Working Group/Standing Group.
Lesley Lowery (llowery@orbiscascade.org) is the Network Zone Manager at the Orbis Cascade Alliance. Until this year she worked at Western Washington University, where she served as the Shared ILS Administrator and prior to that worked as a cataloger. She is a former member and chair of the Orbis Cascade Alliance Primo Norm Rules Working Group.

Subscribe to comments: For this article | For all articles
Leave a Reply