by Chris Diaz
Introduction
Static site generators build websites from plain-text files. Most are free to use and are available under an open source license [1]. They are often described in comparison to content management system (CMS) software, like WordPress or Drupal. CMS websites use database processes on a web server to dynamically create HTML on demand. Static site generators, however, perform all of the plain-text-to-HTML processing before the files are deployed online. This preprocessing workflow removes the need for high-touch system administration, database installations, server-side processing, and security patching, reducing the need for full-time developers and system administrators for digital publishing services. These advantages make static site hosting, maintenance, and preservation more affordable and sustainable for small teams.
Northwestern University Libraries began using static site generators for our digital publishing service in 2018. We initially licensed the Digital Commons platform from Bepress to support our open access publishing services, but the Elsevier acquisition made us question our reliance on proprietary software and motivated us to consider open source alternatives (Schonfeld 2018). At the same time, interest in open source software for library publishing was growing (Library Publishing Coalition 2018). This article reflects on our use of two open source static site generators for library publishing, including an overview and evaluation of the technologies while focusing on two popular use cases: scholarly publications and open educational resources.
Why build static sites?
Static sites are gaining popularity in the digital library and cultural heritage community [2]. The Getty Museum is currently developing Quire, a new monograph publishing tool that uses the Hugo static site generator (The J. Paul Getty Trust 2018). Newson’s excellent “Tools and Workflows for Collaborating on Static Website Projects” covers how static website generators work, the benefits they offer, and a case study for a digital collections project (Newson 2017). For digital publishing, the benefits of static sites include affordability, sustainability, and preservation.
Static sites are cheap to host and require very few computing resources. In addition to domain name services, dynamic sites require an operating system to manage the web server, the database, and all server-side scripting, often with significant software dependencies that require regular monitoring and maintenance. Modern web browsers are reducing the need for server-side processing for rendering dynamic web content. Static sites simply require storage and a content delivery network (CDN) from hosting providers. The requirements for specific operating systems, databases, software dependencies, or server-side scripting for are minimal or nonexistent for hosting static sites. In some cases, static sites can be hosted for free or very cheaply (e.g. $6.00 US – $30.00 US per year) by providers like GitHub Pages, Netlify, or Amazon Web Services (AWS).
Static sites are generally smaller than dynamic sites. For one of our conference publications with over 30 presentations, the entire working directory is 230 MB (includes the full Git version history, Markdown, configuration, and Sass files) and the output directory is 61 MB (which includes only the HTML/ CSS files and PDF full-text content). For comparison, some hosting providers suggest 1 GB of space needed to run one WordPress site, more than 10 times the needed disk space to host a static website (Jackson 2018).
Static websites are easy to maintain because they are composed of asset, HTML, CSS, and JavaScript files. Whereas dynamic websites are processed and built on-demand or cached on a server, static site generators process and build the site before the files are deployed online. The website doesn’t change until there’s a new deployment of the site. Websites powered by a CMS facilitate the exchange of information between the client and the server, such as user login credentials, which is stored in a web accessible database. Both the database and the CMS require system administrators to install and configure the software on the server, which require monitoring to ensure constant uptime, maintain software dependencies, handle regular security patches, and schedule server migrations. This is not the case for static sites.
Scholarly Publications with Jekyll
Jekyll [3] is an open source, command-line tool that transforms plain-text files into static sites. Jekyll is very popular among the open source community. It is often the tool of choice for blogs, project marketing websites, and technical documentation due to its integration with GitHub, which offers GitHub users free static site hosting with its GitHub Pages service [4]. GitLab [5] and Bitbucket [6] also provide free static site hosting.
Jekyll’s built-in toolset is well-suited to support scholarly publications, like journals and conference proceedings. Both sx archipelagos [7] and The Programming Historian [8] use Jekyll and GitHub Pages for hosting and publishing their peer-reviewed publications. We use Jekyll to build conference proceedings websites for content we’re storing in our institutional repository. The static site serves as an lightweight presentation layer for a collection we manage in our institutional repository. This provides us a low-cost, highly customizable, simple website for our institutional stakeholders (Diaz 2018).
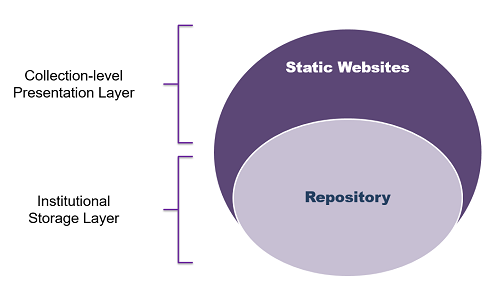
Figure 1: How static websites enhance institutional repository collections
Content
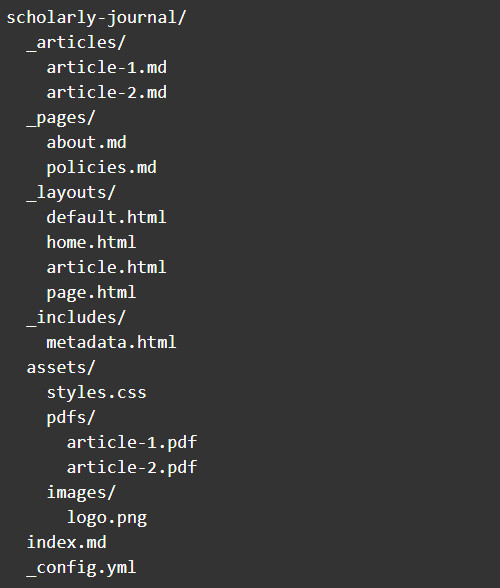
3The full-text and metadata are formatted as Markdown [9] and YAML [10] respectively. Both Markdown and YAML are stored in Markdown files (.md), which can be opened by any plain-text editor. Because static sites do not use content management systems, users interact with the plain-text files and folders directly. If you were to open a basic Jekyll project for a scholarly journal, for example, the folder and file structure might look something like this:
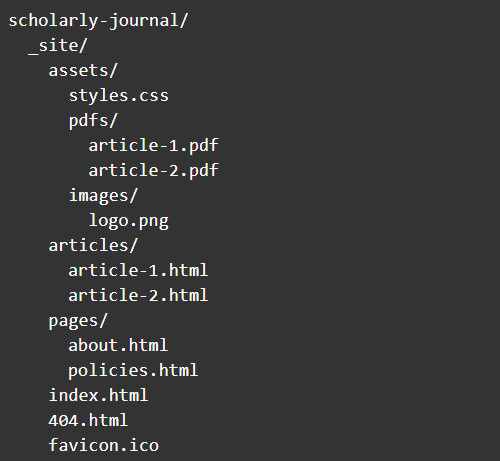
When you run the build command, the process takes all of the files in the scholarly journal file directory and outputs website files in subdirectory called _site. The _site directory contains everything you would need to deploy the site to the web.
Jekyll has built-in support for Collections, which enables you to define content types, such as pages, articles, and posters (Jekyll 2018). Each collection will likely have its own designated HTML layout and default metadata values. For a journal project, you could create a subdirectory called _articles and keep all of the journal articles as Markdown files.
The Markdown files include metadata and full-text content. The metadata appears at the top of the file as a key-value store represented as YAML, a field-driven markup language suitable for metadata. The full-text of the article is formatted as Markdown.

Both YAML and Markdown are human-readable, non-proprietary plain-text formats. From a preservation perspective, one could compress the Markdown files into a .zip file at the time of publication and store them in a preservation or repository system.
The _config.yml file contains all site-level configurations, such as the publication’s title, editor contact information, Google Analytics tracking code, and the website’s theme.
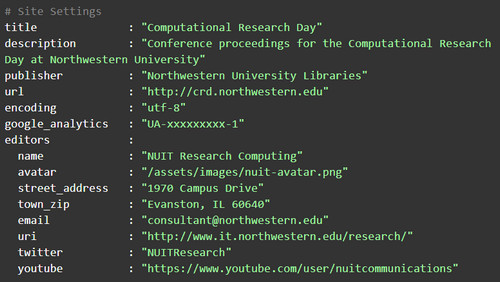
At Northwestern, we used Jekyll and our institutional repository to create a conference proceedings publication for Computational Research Day [11], an annual conference on data science and high-performance computing topics. We have made the source code [12] available for reference, however the style sheets are restricted to Northwestern University websites and are not openly-licensed.
Layout
Layouts for Jekyll websites are often set by a theme. There are hundreds of Jekyll themes available on GitHub [13] or RubyGems.org [14] for free. Themes allow users to ignore difficult design decisions requiring writing and editing HTML, CSS, and JavaScript. Most themes are designed for users to plug into their Jekyll projects without needing to edit any HTML, CSS, or JavaScript files, allowing content creators to focus on the full-text and metadata of their sites. However, because Jekyll was built with blogs in mind, there may be instances when library publishers would want to edit the layouts of their publications to enhance the display metadata and match the user expectations of scholarly audiences.
Jekyll Includes [15] is a method of modularizing HTML templates into component parts, sometimes referred to as partials, and can be useful additions to existing themes. These are small HTML files that are often limited to a specific HTML element in a page layout, like a search bar or navigation menu. These modules help keep the code better organized. For scholarly publications, Jekyll Includes are helpful when needing to call HTML elements on a conditional basis. For example, a scholarly publication might offer two or three Creative Commons license options for authors. With Jekyll Includes, you can create a template for displaying each of these licenses with their respective logo and govern their use with conditional logic based on the article’s YAML metadata.
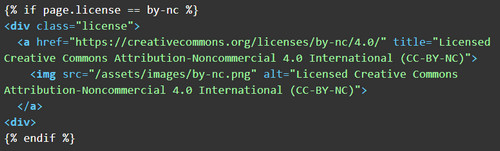
For scholarly publications specific to Northwestern University, we use the Sass [16] files and HTML pattern library created by the university’s marketing department to defer the layout and styling decisions. For non-Northwestern specific scholarly publications, we experiment with open source CSS frameworks or themes that contain responsive layout elements and usability features that are important to stakeholders.
Metadata
Jekyll’s use of the Liquid templating language makes reusing YAML data easy. Liquid is a system of tags, objects, and filters that Jekyll uses during the build process to load YAML and Markdown content into specified HTML elements (Shopify 2018). For articles, you can reuse the YAML front-matter for each journal article to create machine-readable metadata in the HTML header of each article’s web page to assist web search indexing and citation management systems. You could do this by creating an HTML file called metadata.html and assigning metadata values to designated HTML <meta> tags according to the scheme’s guidelines. Here is an example of a few lines from a metadata.html file following Google Scholar recommendations [17] that pulls from YAML front-matter for each journal article and places it into the <head> element of the rendered HTML:
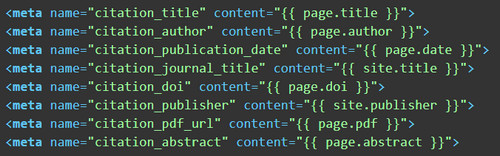
The metadata.html could include as many additional metadata schemas as you would like, including DublinCore and Open Graph. Each schema has its own <meta> tag attribute but uses the same YAML front-matter from the articles.
Publishing Workflow
We partnered with Northwestern Information Technology Research Computing department to publish the proceedings from Computational Research Day, a conference they organize. Research Computing announced a call for posters, presentations, and visualizations and marketed them to various departments on campus. The also managed the review and editorial timeline for the publication.
We used SmartSheets [18] to create a web form and serve as a submission management system for receiving documents, capturing submission metadata, assigning reviewers, and tracking the editorial timeline. The web form including an option for submitters to participate in the proceedings publishing; publication was not required.
To build out the website, I made HTML layouts based on Northwestern’s HTML pattern library and Sass files developed by the marketing department. I also set up a collection in our institutional repository to store the final versions of the poster and visualization submissions and mint DOIs. I used the metadata from the submission form to deposit the files into the repository and to manually create Markdown files for each submission. We reused the DOIs created by the repository for each submission to display on the website in order to facilitate.
To deploy the site, I used the s3_website gem [19] to deliver the static site files to a provisioned AWS using S3 bucket [20]. While the files are stored in S3, they are delivered using CloudFront [21]. I requested a Northwestern subdomain and launched the conference publication [11].
Figure 2: Screenshot of conference website, available at: http://crd.northwestern.edu/
We expect to maintain the website for the conference for up to three years after the conference has been discontinued. We chose to reuse the DOIs from the repository under the assumption that the active maintenance of the repository will outlast the availability of the static site.
Open Educational Resources
Bookdown
Bookdown [22] is an open source R [23] package that transforms plain-text into HTML, PDF, and EPUB. Bookdown works with text formatted with either Markdown or R Markdown [24], a version of Markdown that allows users to embed executable R code into Markdown files. Similar to Jekyll, Bookdown is a static site generator that renders content as online and downloadable e-books. It is popular within the R community of scholars and practitioners working in fields that use statistical computing.
We worked with a faculty member in the Statistics department to publish a set of modified teaching labs for an introductory statistics course that uses R. We chose Bookdown for this project because it was a specifically designed for the content he was creating and the computing environment he was introducing to his students.
Content
The book’s full-text content is stored in either Markdown or R Markdown files (.rmd). A Bookdown project contains a working directory of plain-text files that looks something like this:
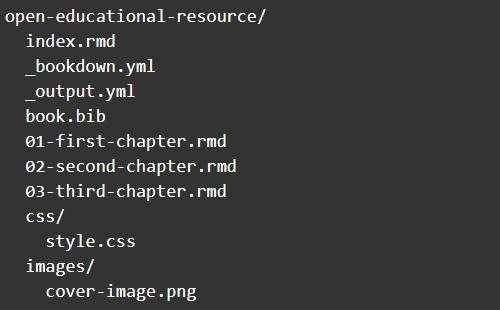
The index.rmd file is the homepage of the static site and title page for the book. This is where the book’s cover image, preface, biographical information about the author and contributors, rights, and licensing information can be found.
The chapters of the book are all R Markdown files in the root directory of the project. If they’re not using R code snippets, the chapter files can be standard Markdown. The Bookdown rendering process reads the chapter files using a specific file naming convention for setting them in order. The first chapter begins with a 01, the second chapter begins with a 02, and so on.
The R Markdown files use standard Markdown formatting with some syntax options that allows the files to reference data, execute R code, and highlight R syntax upon rendering HTML, EPUB, and PDF. Code snippets in the Bookdown package also includes support for Python, C++, Shell, SQL, and a few others [25]. Here’s an example of an R snippet in an R Markdown file:
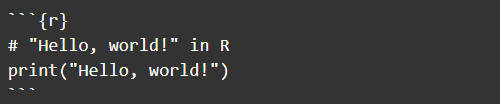
Layout
The layout for the book can be specified either in the YAML front-matter of the index.rmd file, or as a separate YAML file called _output.yml stored in the book project’s root directory. This is where users can specify the output directory, such as the folder name set to contain the rendered HTML files, options for the toolbar or navigation, colors, or typography settings.
Like Jekyll, there are options to take advantage of themes to handle the layout and styles of the rendered HTML. Bookdown has built-in support for three styles: GitBook, Bootstrap, and Tufte. Each of these styles have arguments to specify style options. Users can override these styles by replacing css: style.css with css: custom.css in the _output.yml file to reference the custom style sheet.

In addition to HTML, users can create settings for the EPUB and PDF outputs. These output files, like the site itself, are static files generated during the build process and will be downloadable by end-users through the user interface. The PDF generation is handled with LaTex commands using the Pandoc software [26] and the EPUB document is created by a CSS file.
Metadata
Bookdown has built-in support for Open Graph and Twitter Card metadata for social sharing optimization. Additionally, the front-matter in the index.rmd file contains some basic metadata, such as the book’s title, date, citation style, and basic description. It will also include several configuration options you can set with YAML front matter. Here is the YAML contained at the top of our index.rmd file for the statistics OER we are building:
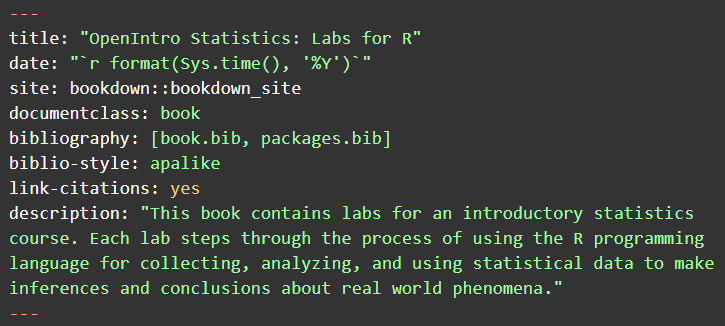
Like Jekyll, Bookdown has an includes method for adding HTML components to projects. This can be used add custom metadata to the HTML <head> element. Within the _output.yml file, you could add an instruction to include a metadata.html file.

The metadata.html file includes all of the <meta> tags and attributes according to the schema’s guidelines. You could use this same includes method to also add a Google Analytics script to monitor usage of the book by modifying the includes argument: in_header: [metadata.html, google_analytics.html]
Workflow
We used a Git-based workflow to collaboratively set up, edit, and publish the OER with GitHub. I set up a clean working directory with RStudio, installed the Bookdown package, which included all of the files needed to complete the plain-text processing, and initialized a new Git repository to track changes and commit history.
Although RStudio supports Git, we pushed commits to GitHub with GitHub Desktop. We were unable to figure out how to store SSH keys to circumvent the need for logging into to my GitHub account each time we needed to push a commit in RStudio, otherwise we would have used its built-in Git support.
The faculty member I worked with had familiarity with Markdown and R Markdown, so he emailed me all of the R Markdown files, which I then edited to fit Bookdown styles we set out to follow. This required some basic content organization, such as removing redundant YAML metadata and licensing information. I also provided some basic copy edits for the text.
Once I was able to render the book as HTML, I published the Git repository to Northwestern University Libraries’ organizational account on GitHub and added the faculty member as a contributor with write-access to the repository. We were both able to push commits from edits to the book and preview the book in HTML using the GitHub Pages hosting service.
In order to take advantage of GitHub Pages for hosting the book, this required some edits to the _bookdown.yml file. This file contains some basic settings, such as the ability to automatically label figures, tables, and chapter headings sequentially, and more importantly set the rendered book’s output directory.
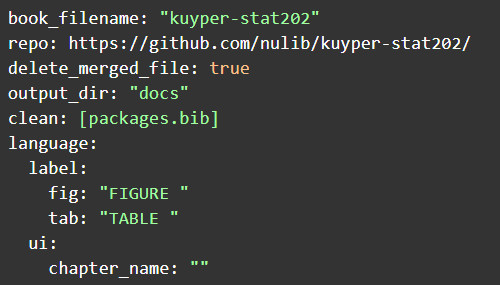
When you host your source code on GitHub, you have a few options to publish static sites. This is intended to provide provide developers a way to create a static sites for documentation or marketing of the open source package. Common methods for doing this includes pushing your static site contents (i.e. HTML and assets) to a GH-pages branch or a folder called docs. We chose to designate a docs folder in the _bookdown.yml file, instead of the default _book folder so that GitHub knows to create a website with those files. A final step to make this work was to add an empty file called .nojekyll to tell GitHub servers that the files are ready to be served without the need to run any Jekyll build processes.
Figure 3: Screenshot of published OER, available at: https://nulib.github.io/kuyper-stat202/
The book is currently a static site hosted by GitHub [27] and allows users to download the EPUB and PDF versions of the book. Future Bookdown projects will likely involve more customizations to the book’s style, better integrations with data repositories (i.e. storing datasets in our institutional repository and writing R scripts that interact with those data programmatically), and custom domains. We have also made the book’s source code [28] available.
Moving from a concept to a service
Our use of static site generators for digital publishing projects was a success, but scaling this concept into a service that supports distributed editorial teams would present a number of challenges whose solutions might be the topic of a future article. The websites we build serve primarily as public user interfaces for the content we publish; they are not all-in-one editorial and publishing systems.
The build processes involved in building the static websites can automate the conversion of Markdown to publishing output formats, such as HTML, PDF, and EPUB; however, static site generators do not support the initial document preparation, submission management, editorial workflows, or any other backend functionality available in other digital publishing systems. Those functions could be handled by Software-as-a-Service extensions or outside of the website infrastructure entirely.
In both Jekyll and Bookdown, the submission document needs to be converted to Markdown in order to be added to the site. This would require some human intervention to ensure that the conversion is successful, and likely the use of a computer program to convert from Microsoft Word[29] or Google Docs[30]. In the above case studies, the Markdown files for both projects were created by copying and pasting information from spreadsheets or supplied by the author.
The planning phase for a scalable workflow would involve decisions around which technologies and services will perform specific functions in the workflow, such as:
| Publishing Function | Description | Technologies and Services |
| Document preparation | Preparing MS Word or Google Doc submissions to Markdown, HTML, PDF, or JATS outputs; copyediting | – Pandoc [31]
– ConTexT [32] – Freelance copy editors or typesetters – Student workers |
| Submission Management | Accepting full-text and metadata submissions from authors and contributors | – SmartSheets [18]
– Scholastica [33] – Submittable [34] – Box.com [35] – DropBox [36] – Google Drive [37] |
| Analytics | Logging and analyzing page visits, user demographics, and downloads | – Google Analytics [38]
– Matomo [39] |
| Archiving | Depositing content for long-term storage and preservation | – Institutional Repository
– Digital Asset Management system – Local or cloud-based file storage system |
| Registration | Creating unique identifiers for published content (e.g. DOI, ISSN, ISBN) | – Cross Ref [40]
– DataCite [41] – Library of Congress [42] – Bowker [43] |
| Project Management | Tracking activities, task assignments, and timelines for the editorial team | – SmartSheets [18]
– Trello [44] – GitHub Project Boards [45] – Google Drive [46] – MS Excel [47] |
Examples of editorial and publishing functions needed in addition to static site generators
A selection of these editorial and publishing tasks would need to be stitched together with documentation and executed using a several pieces of software, some of which may be difficult for one or more persons to design and a rotating team of editors to manage. This is part of what makes all-in-one publishing systems attractive.
And then there’s the issue of deployment. Because static sites are generated before they are deployed, all of the content management of the site happens on local copies of the plain-text files on someone’s computer. If an editor needed to update a webpage or publish a new issue, they would either need to understand the static site generator workflow or coordinate with the publisher via email. It would be highly desirable in this case to install a headless CMS to push updates to the static site. There are numerous headless CMS options [48] that can be added to provide editors a friendly user interface for editing the site. The configuration would involve connecting the CMS to the static site’s GitHub repository and using a continuous integration and delivery service to auto-merge and deploy the updates. Otherwise, all of content editing and updating would be handled by the people who understand the workflow of the static site generator, have all of the necessary software available to them on their computers, and have the access rights to deploy the changes online.
At Northwestern, this problem has not yet been a deterrent for us to continue to use static site technologies because we have centralized digital publishing within a single position who is comfortable using git, static site generators, GitHub, and AWS resources.
Conclusion
Static site generators are great for creating simple, powerful, low-cost websites for scholarly or educational publications, but they cannot alone provide the all-in-one system functionality for scholarly publishing. Rather, these open source tools can used as components of the “open scholarly commons” as described in Lewis’s “The 2.5% Commitment,” which called on the colleges and universities to contribute to a shared infrastructure of open source technologies to facilitate scholarly communications (Lewis 2017). The Elsevier acquisition of Bepress exposed the extent to which the over-reliance on monolithic publishing and repository systems by library-based open access publishers is a problem. Using open source static site generators for digital publishing is one option for avoiding futute lock-in scenarios and supporting values of openness to research, education, and technology.
At Northwestern, using static site generators enabled us to provide nicer online publications to our stakeholders and support new use cases for library-based publishing than we were able to with the Bepress platform. For us, the downside of utilizing microservices for digital publishing is managing a complex set of technical components with varying levels of required skills and documentation within a single position; however, we believe that the upside is much greater. We can easily move away from Jekyll or Bookdown if we need to. This platform-agnostic approach allows us the flexibility to experiment with new publishing technologies and the ability to provide services that prioritize the needs of our stakeholders over the limitations of any particular platform. Static sites are a key component to this approach.
About the Author
Chris Diaz is the Digital Publishing Librarian at Northwestern University. He has held positions in academic libraries focusing on scholarly communication, collections management, and outreach since 2013. His previous publications include two edited volumes for the ALCTS Monographs series on college textbook affordability and library collections. He is currently focused on using open source technologies for web publishing and digital libraries. You can find him on Twitter @chrisdaaz or reach him by email at chris-diaz@northwestern.edu.
Notes
[1] https://www.staticgen.com/
[2] https://github.com/hardyoyo/awesome-static-digital-libraries
[5] https://about.gitlab.com/features/pages/
[6] https://confluence.atlassian.com/bitbucket/publishing-a-website-on-bitbucket-cloud-221449776.html
[7] http://smallaxe.net/sxarchipelagos/index.html
[8] https://programminghistorian.org/
[9] https://www.markdownguide.org/
[10] https://learnxinyminutes.com/docs/yaml/
[11] http://crd.northwestern.edu/
[12] https://github.com/nulib/computational-research-day
[13] https://github.com/search?q=jekyll+theme&type=Repositories
[14] https://rubygems.org/search?utf8=%E2%9C%93&query=jekyll-theme
[15] https://jekyllrb.com/docs/includes/
[17] https://scholar.google.com/intl/en/scholar/inclusion.html#indexing
[18] https://www.smartsheet.com/
[19] https://github.com/laurilehmijoki/s3_website
[20] https://aws.amazon.com/s3/
[21] https://aws.amazon.com/cloudfront/
[23] https://www.r-project.org/
[24] https://rmarkdown.rstudio.com/
[25] https://bookdown.org/yihui/rmarkdown/language-engines.html
[26] https://bookdown.org/yihui/bookdown/latexpdf.html
[27] https://nulib.github.io/kuyper-stat202/
[28] https://github.com/nulib/kuyper-stat202
[29] https://gist.github.com/vzvenyach/7278543
[30] https://word-to-markdown.herokuapp.com/
[31] https://pandoc.org/
[32] http://wiki.contextgarden.net/What_is_ConTeXt
[33] https://scholasticahq.com/
[34] https://www.submittable.com/
[35] http://box.com/
[37] https://www.google.com/drive/
[38] https://analytics.google.com/analytics/web/
[39] https://matomo.org/
[40] https://www.crossref.org/
[41] https://www.datacite.org/
[42] https://www.loc.gov/issn/
[44] https://trello.com/
[45] https://help.github.com/articles/about-project-boards/
[46] https://www.google.com/drive/
[47] https://products.office.com/excel
References
StaticGen: A list of static site generators for JAMstack sites. Available from: https://www.staticgen.com/
Shopify. (2018). Liquid basics. Available from: https://help.shopify.com/en/themes/liquid/basics
Diaz, C. 2018. Jekyll and institutional repositories. Open Repositories 2018. Available from: https://doi.org/10.21985/N28X22
Jackson, B. [updated 2018 August 16]. How much disk space does your hosting plan really need? [Internet] Kinsta.com. Available from: https://kinsta.com/blog/disk-space-wordpress-hosting/
Jekyll. 2018. Collections. JekyllRB.com [Internet]. Available from: https://jekyllrb.com/docs/collections/
Lewis, D. 2017. The 2.5% commitment [Internet]. Available from: http://doi.org/10.7912/C2JD29
Library Publishing Coalition. 2018. Owned by the academy: A preconference on open source publishing software [Internet]. Available from: https://librarypublishing.org/owned-by-the-academy-preconference/
Newson, K. 2017. Tools and workflows for Collaborating on static website projects. Code4Lib Journal [Internet]. [cited 2018 September 3]. Available from: https://journal.code4lib.org/articles/12779
Schonfeld, R.C. 2017. Elsevier acquires bepress. The Scholarly Kitchen [Internet]. [cited 2018 September 3]. Available from: https://scholarlykitchen.sspnet.org/2017/08/02/elsevier-acquires-bepress/
The J. Paul Getty Trust. 2018. Quire: A new publishing tool [Internet]. Available from: http://www.getty.edu/publications/digital/platforms-tools.html
Xie, Y. 2018. bookdown: Authoring books and technical Documents with R markdown [Internet]. CRC Press. [cited 2018 September 3]. Available from: https://bookdown.org/yihui/bookdown/

Subscribe to comments: For this article | For all articles
Leave a Reply