by Alicia Detelich
Introduction
In August 2017, representatives from across the Yale University Library (YUL) system began a year-long effort to implement the ArchivesSpace Public User Interface (PUI) as the primary search and discovery platform for special collections materials at YUL. The customized interface, dubbed Archives at Yale, launched in January 2019 replacing an access system that had been in use, mostly unchanged, for nearly a decade.[1]
The project team consisted of more than 35 YUL staff divided into six working groups, including the five-member Data Cleanup and Enhancements Workgroup. This workgroup was tasked with creating and updating metadata stored in ArchivesSpace to optimize search and display functionality in Archives at Yale.
During an initial planning meeting, the group identified and prioritized a number of data elements on which to focus cleanup and enhancement work. Several major differences between YUL’s legacy finding aid database and the PUI guided the group’s decision-making, including a feature of the PUI which enabled searching by date.[2]
Utilization of the PUI’s search-by-date feature requires that ISO 8601-compliant dates be present in the structured ‘begin’ and ‘end’ fields of ArchivesSpace date subrecords. The group was aware that much, if not most, of the date metadata in ArchivesSpace was represented only in the free-text ‘expression’ field, and that the majority of this data was not in ISO 8601 format. Numerous discussions about normalizing these date records had taken place since YUL migrated its data to ArchivesSpace in 2015, and the PUI implementation project presented a good opportunity to complete the task. [3]
The ArchivesSpace Data Model
The ArchivesSpace application is based on a data model comprised of numerous records, which are stored in a MySQL database, and which can also be created, updated, or deleted via a robust API. These records support an array of archival functions, including accessioning, description of analog and digital materials, authority control, and collection management.[4]
At a very basic level, records in ArchivesSpace can be divided into three categories: “top-level” records, subrecords, and enumerations. Top-level records are the primary record types in ArchivesSpace. They are assigned URIs, and their JSON representation can be accessed directly via the ArchivesSpace API.
Top-level records can be further divided into three types according to their function:
| Functions | Record types |
| Description | Resources, archival objects, accessions, classifications |
| Authority control | Agents, subjects |
| Collection management | Top containers, digital objects, locations, events, collection management, repositories |
The most commonly used top-level records are resources and archival objects, which correspond, respectively, to collection-level descriptive records and their hierarchical components. Archival objects must always be associated with a resource, and cannot be created independently. Most record types are linked to a particular repository, though agents, subjects, and locations are shared across all repositories.
Numerous subrecord types exist in the ArchivesSpace model. A few examples:
| Subrecord Type | Description |
| Dates | Dates associated with material creation, collection management events, etc. |
| Extents | Material type and/or quantity. 15 linear feet, 25 photographs |
| Notes | Free-text description fields. Scope and content, conditions governing access, etc. |
| Subcontainers | What’s inside a top container. Folder, item |
| Instances | Link between top containers and descriptive records |
Subrecords cannot exist on their own, but must be associated with a top-level record. As such, they do not have their own URIs, and can only be accessed via the API by retrieving the top-level record with which they are associated. Subrecords are repeatable, so their JSON representations are stored in lists within an associated top-level JSON record. The various subrecord types have their own database tables, are assigned primary keys, and contain foreign keys which link them to top-level records.
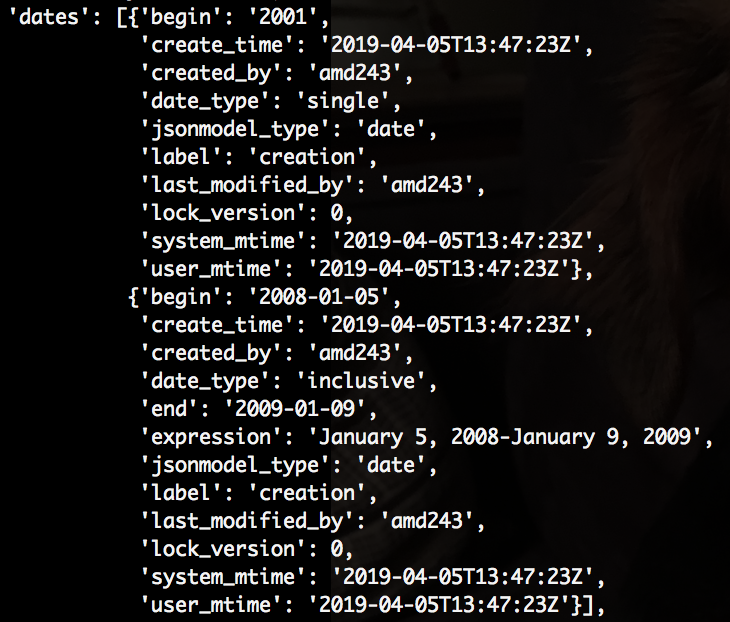 Figure 1. Date subrecords in a resource record JSON response
Figure 1. Date subrecords in a resource record JSON responseThe ArchivesSpace data model is also comprised of many types of controlled values, or enumerations. Enumeration values are assigned an identifier in the database, and this identifier is used as a foreign key in many top-level records and subrecords. The JSON response from the API represents enumerations as strings. A few controlled value types:
| Enumeration | Values |
| Extent type | Photographs, linear feet, videocassettes (vhs) |
| Name source | LCNAF, VIAF, SNAC |
| Archival record level | Collection, series, sub-series, file, item |
ArchivesSpace comes with a standard set of controlled values, but these can be modified by users.
Date Records in ArchivesSpace
Date subrecords in ArchivesSpace are comprised of several writeable fields. The ‘expression’ field can contain any free-text date formulation, and there is no constraint on adding non-date values to this field. The ‘begin’ and ‘end’ fields must contain ISO 8601-formatted date strings. Three types of controlled values – date type, date label, era, and calendar – are also included in the record. In the database, these fields contain foreign keys that link the date table to the enumeration_value table. In the JSON response from the API controlled values are represented as text.
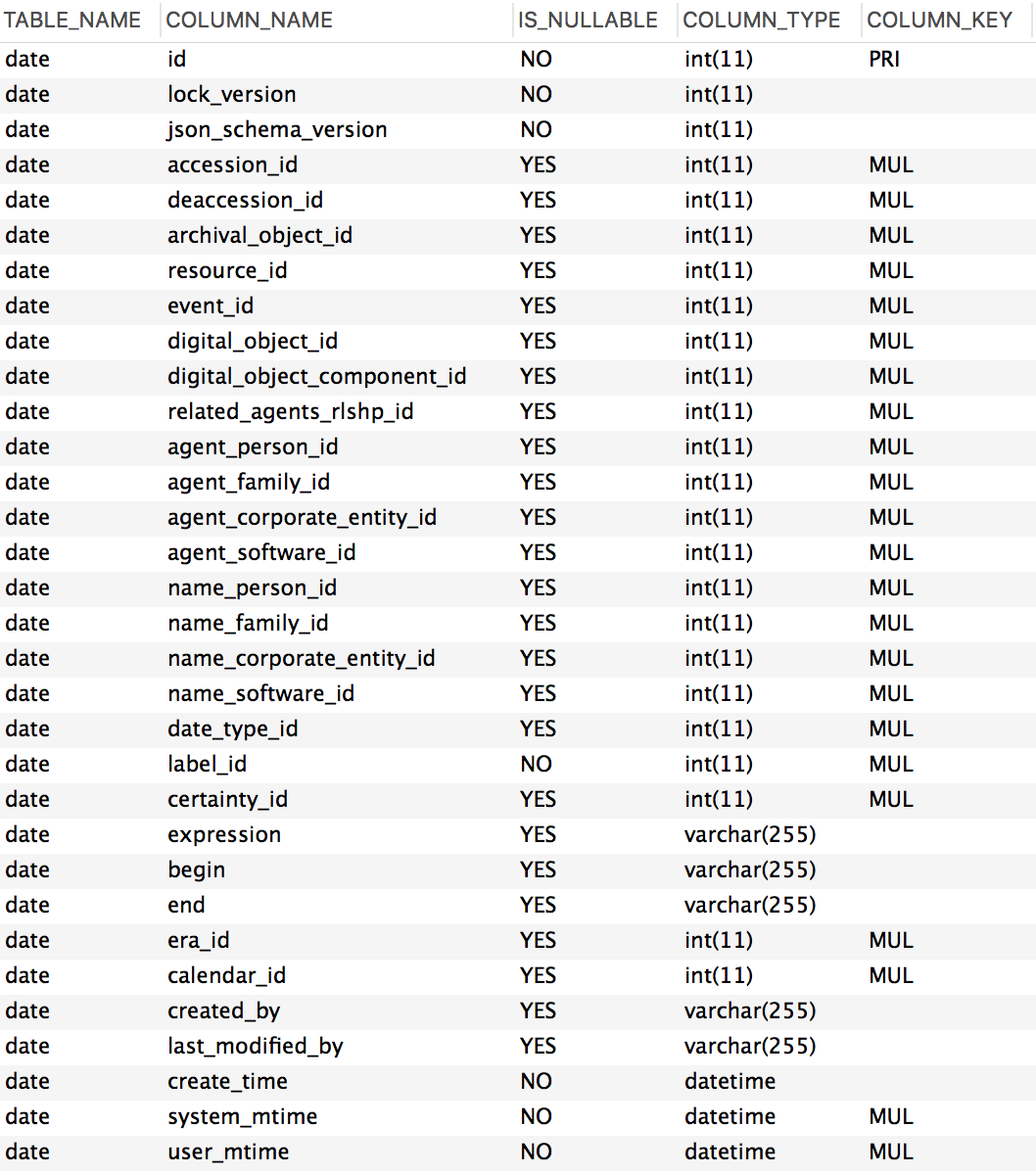 Figure 2. Date table structure
Figure 2. Date table structureIdentifying Unstructured Dates
YUL migrated its archival metadata into ArchivesSpace June 2015. A single production instance consists of 15 repositories representing 12 of Yale’s special collections repositories. Prior to 2015, a wide range of systems were used to manage archival metadata at Yale, including but not limited to three separate Archivist’s Toolkit databases. Practices for creating records within these systems varied widely across repositories and over time.
The resulting lack of conformity meant that most date metadata was migrated into the ‘expression’ field, and not the structured ‘begin’ and ‘end’ fields. Dates records created since 2015 more often, but not always, included structured dates.
To determine just how many of our date records were unstructured, we queried the ArchivesSpace database to identify all dates with a value in the ‘expression’ field but NULL values in both of the structured fields.[5] The resulting report contained three columns – the database identifier for the date subrecord, the URI for the top-level record to which it was linked, and the value of the ‘expression’ field.
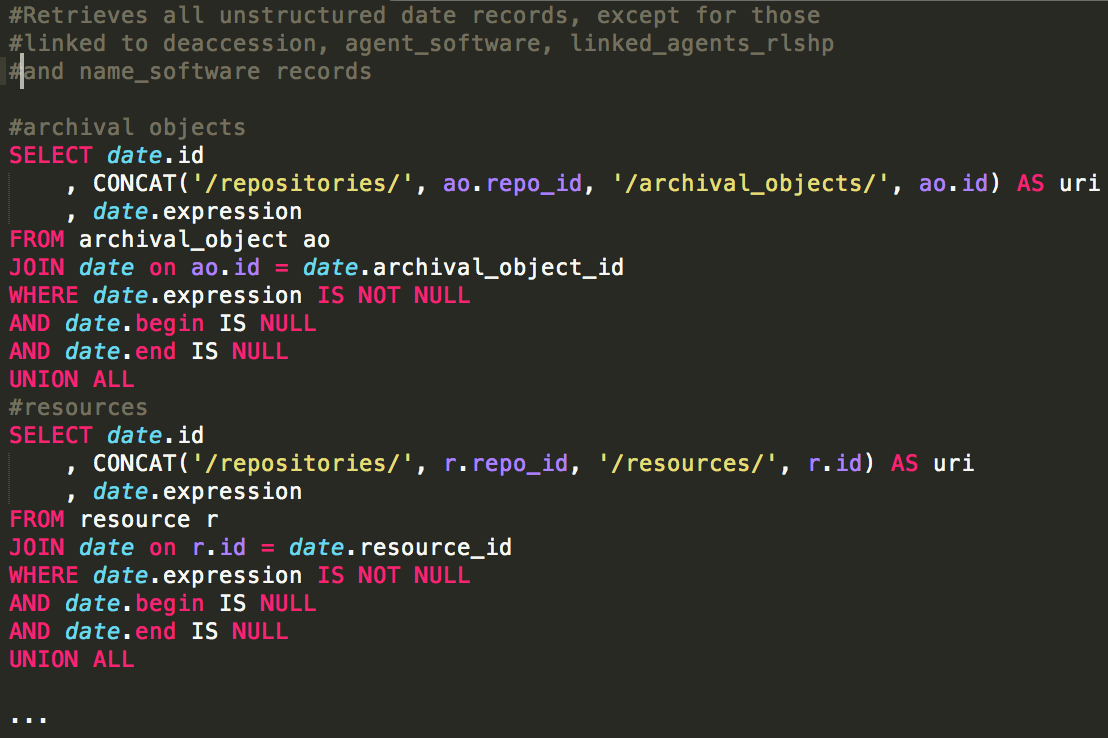 Figure 3. Snippet of get_unstructured_dates.sql
Figure 3. Snippet of get_unstructured_dates.sqlThe results of the query confirmed that the majority of our date records were unstructured – of the 1.65 million date records in the database in November 2017, 1.08 million, or about 66%, had a date value in the ‘expression’ field only.
Searching for a Scalable Solution
The large number of unstructured dates and the enormous variety in the content of the ‘expression’ field led us to experiment with a number of approaches before finding one that met all of our requirements. Our goal was to complete most or all of the work in-house, using our existing skill sets, in a relatively short period of time. We also wanted a mostly automated process which facilitated the re-use of data through various processing steps. And, of course, we needed a solution which could accurately convert a wide variety of dates to ISO 8601 format.
OpenRefine is a very useful tool that we all had experience using in the past, but it was not ideal for processing such a large dataset, even after allocating additional memory to the application. We also found writing a comprehensive number of GREL expressions from scratch to be very time consuming, and we preferred not to recreate something that might have already been done well by someone else.[6]
In addition to its dateutil module, Python has a number of third-party date parsing libraries, including dateparser and daterangeparser.[7] Python is capable of processing large amounts of data very quickly, but during testing we found the date parsing functions to be less comprehensive than other methods, and significant additional processing was often required to output accurate results. We were also reluctant to rely on a hodge-podge of third-party solutions, some of which did not appear to be widely used, as they presented issues for the future maintenance of any tool we created for this project.
We first heard of the Timewalk date parsing plugin for ArchivesSpace from discussions with fellow members of the user community, and we considered ways we could use the plugin to work with legacy data.[8] We knew that the parsing function was triggered upon saving a record in the ArchivesSpace staff interface, so we attempted, in a test instance, to GET/POST a number of records via the API without making any changes. The legacy dates we tested were parsed by the Timewalk, and though the results were generally accurate, we were left with a number of errors. We decided that we needed to parse the dates outside of the application and perform quality control on the results before pushing the changes to production.
Timetwister
The Timewalk plugin is based on Timetwister (itself based on Chronic), which was developed by Alex Duryee, Trevor Thornton, and others at the New York Public Library (NYPL). Timetwister is a Ruby gem with a command-line interface that provides powerful date parsing capabilities, including date ranges and multiple dates.[9][10]
While most members of the group – all technologically-oriented archivists – had a basic knowledge of Ruby and were comfortable working on the command line to accomplish routine tasks, we felt that writing a Ruby application or complex bash script that employed Timetwister would have been overly time-consuming considering our skill levels in these areas. Our established skill sets and workflows relied heavily on Python and SQL, and we wanted a solution which would allow us to use tools while also taking advantage of the powerful and accurate parsing capabilities of Timetwister.
Python + Timetwister = parse_dates.py
One of the most useful features of Python is its extensive standard library, which provides many advanced capabilities for working with data and operating systems. One of these, the subprocess module, enables users to run external commands from within a Python program, similar to how one would on the command line. [11] Having employed this module in other contexts, we knew that it we could use it to make repeated calls to the Timetwister command from within a Python for-loop.
With that in mind, we wrote a script, parse_dates.py, which performs the following sequence of actions:[12]
- Connect to the ArchivesSpace database using the pymysql and paramiko modules
- Execute the get_unstructured_dates.sql query and store the results in a list
- Iterate over the result list and call the Timetwister command with the subprocess module’s ‘Popen’ class, using each date expression as an argument
- Parse the ‘original_string’, ‘date_start’ and ‘date_end’ values from the resulting JSON response into a list. The ‘original_string’ field was retained to compare what was actually parsed with the original query data.
- Append the Timetwister data to the query output
- Write the output to either a single CSV or a series of CSV files based on type. If split into multiple CSVs, append the date type ID value to the output
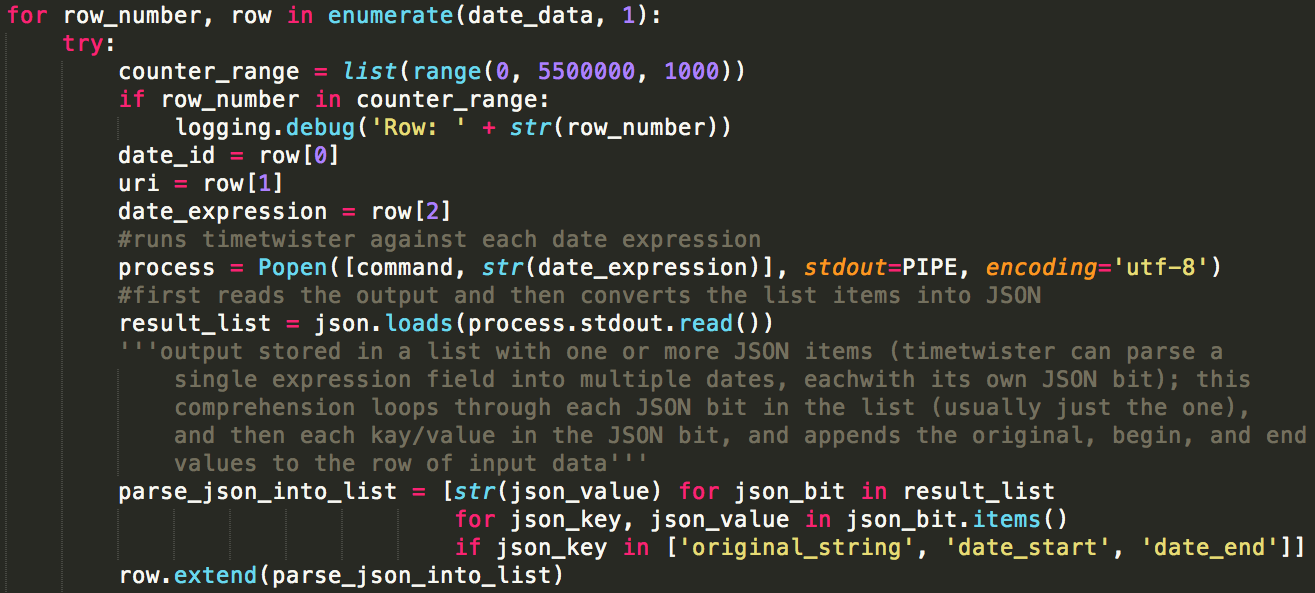 Figure 4. Snippet of parse_dates.py showing steps 3-5
Figure 4. Snippet of parse_dates.py showing steps 3-5The total runtime of the script was approximately 12 hours. We split the output into several CSVs in order to make it easier for the group members to review the output, and, as will be explained later, to perform the updates in chunks. The following table summarizes the results (with estimated counts):
| Date Type | Count | Percentage |
| single: value only in ‘date_start’ field | 330,000 | 30% |
| inclusive: : values in both the ‘date_start’ and ‘date_end’ fields | 490,000 | 45% |
| inclusive-begin: value like ‘2014-’ in the ‘date_start’ field | 125 | .01% |
| inclusive-end: value like ‘-2014’ in the ‘date_end’ field | 5 | .0005% |
| multiple: multiple date values in a single record, i.e. ‘October 2010, November 2016’ | 85,000 | 8% |
| unparsed: values could not be parsed by Timetwister, i.e. ‘undated’, ‘April 5’, ‘Tuesday’ | 175,000 | 16% |
| errors: any other errors | 250 (resolved by re-running parse_dates on subset of records) | .02% |
| TOTALS | ~1,080,280 | ~100% |
The group then manually reviewed the output. Because of the large quantity of dates, we used a sample size calculator to determine a reasonable number of records to review in order to be confident in the results – approximately 15,000 divided between five group members.[13] We excluded the unparsed, inclusive-end and inclusive-begin reports from the review. With the former, we wanted to return the results to the YUL repositories that created the records and ask them to consider supplying estimated dates. The latter two we also felt should not be updated until they were corrected to include a full date range.
We set aside the multiple date report, as well, since updating those would require correcting the expression field and creating a number of new date records, necessitating a different approach than the majority of the date records.
All of the date records we reviewed were accurately parsed. Our overall success rate was 75% – of the 1.08 million date records processed by Timetwister, over 820,000 were converted into ISO 8601 format. Another 8% could be updated with additional processing. The majority of the dates which Timetwister could not parse would not have been parseable by any tool.
Choosing an Update Method
The group considered both of our options for ingesting the output of the Timetwister script into ArchivesSpace: either via a database update or the API.
ArchivesSpace database access for YUL staff is read-only, so we first considered using the API to make the updates.[14] However, because subrecord IDs are not included in the JSON response from the API (except, for some reason, in digital object file version subrecords), and a single top-level record can have multiple associated dates, we weren’t sure how to precisely locate the dates we wanted to update.
We considered using the date expression string as a match point, which is probably sufficient in most cases, but also seemed less accurate than matching on the identifiers, as the original expressions could be changed in ArchivesSpace at any time prior to us running the update. The API can be rather slow, as well – we estimated that the update script would take between 3-7 days to run, during which time a host of connection issues and other errors could occur.
 Figure 5. Snippet of API update script
Figure 5. Snippet of API update scriptA database update seemed more logical, as it runs much faster, and the database identifiers could be used to ensure precision. However, while we were testing this option on a local copy of the database, we discovered an interesting property of ArchivesSpace subrecords – they are not persistent. When a top-level record is saved, all of its associated subrecords are deleted and recreated, and the “new” subrecords are assigned new database identifiers. This design choice was likely made to improve application performance, but it seemed odd, and required us to reconsider whether our proposed method was feasible.
After some discussion, we concluded that if we re-ran the parse_dates.py script relatively close to when we made the update to our production database, the number of changed date identifiers would be acceptably small.[15] The time savings and limited error potential of an SQL update as opposed to the API was a major factor in this decision.
We wrote two SQL scripts which created a temporary date table, imported the Timetwister output, and then updated the original date table with the values from the temporary table, without modifying any of the other fields in the table. We tested these scripts on the local database and were satisfied with the outcome. The scripts took just a few minutes to run and all records updated successfully.
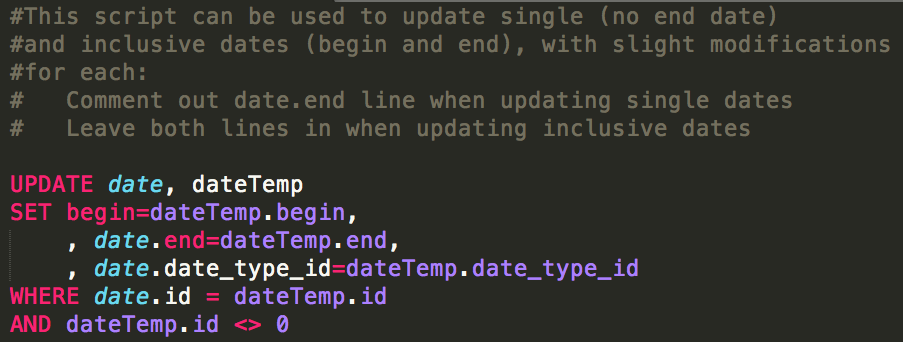 Figure 6. update_dates.sql
Figure 6. update_dates.sqlBecause we split the output into multiple CSVs by date type for quality control purposes, we decided that it would be easiest to create two temporary tables and run the update script in two chunks. This required us to slightly modify the update script depending on the date type, as single dates do not have an ‘end’ field. It is also possible to run the update using a single CSV and temporary table by adding a line which converts any blank fields in the CSV file to NULL values.
Because YUL’s ArchivesSpace database is read-only, once we finished testing locally we contacted our hosting provider, Lyrasis, to coordinate the production update. We provided them with our SQL scripts, which they modified and executed, first on our test instance of ArchivesSpace, and then, after we reviewed the output, in production.
We are confident in the accuracy of the parser, but since it was not feasible to manually review every record, we retained the original date expression value in addition to the newly-added ‘begin’ and ‘end’ values. This makes it possible for us to identify and correct any errors that may have occurred.
While we were concerned about changing date identifiers leading to failed updates, fewer than 1.5% – about 12,000 – of the database updates failed due to this issue, despite a (longer than planned) 3-week gap between data processing and update. Based on our previous experience, this failure rate is likely much lower than if we had performed the update via the API.
Analysis
The workgroup was very pleased with the results of this project. We increased the percentage of ISO 8601-compliant dates in YUL’s ArchivesSpace database from 33% to 83%, vastly improving the utility of the PUI’s search-by-date function, and thus the ability of our users to locate relevant archival and manuscript materials. Our work has also enabled YUL staff and other interested parties to perform more robust temporal analyses on our archival metadata.
By using an existing tool in a novel way, capitalizing on our skill sets, and creating an efficient data processing workflow, we were able to normalize a large quantity of date records with just 15-20 hours of staff time over two months. Additionally, we saved YUL thousands of dollars which had been budgeted for a vendor to do the normalization work.
We also worked to make our process reproducible by ourselves and others, and have continued to refine the scripts and our workflows. The parse_dates.py script can now be run interactively on the command line by users with relatively little technical experience, and we’ve made it easier to use the combined date output and perform just a single database update, among other improvements.
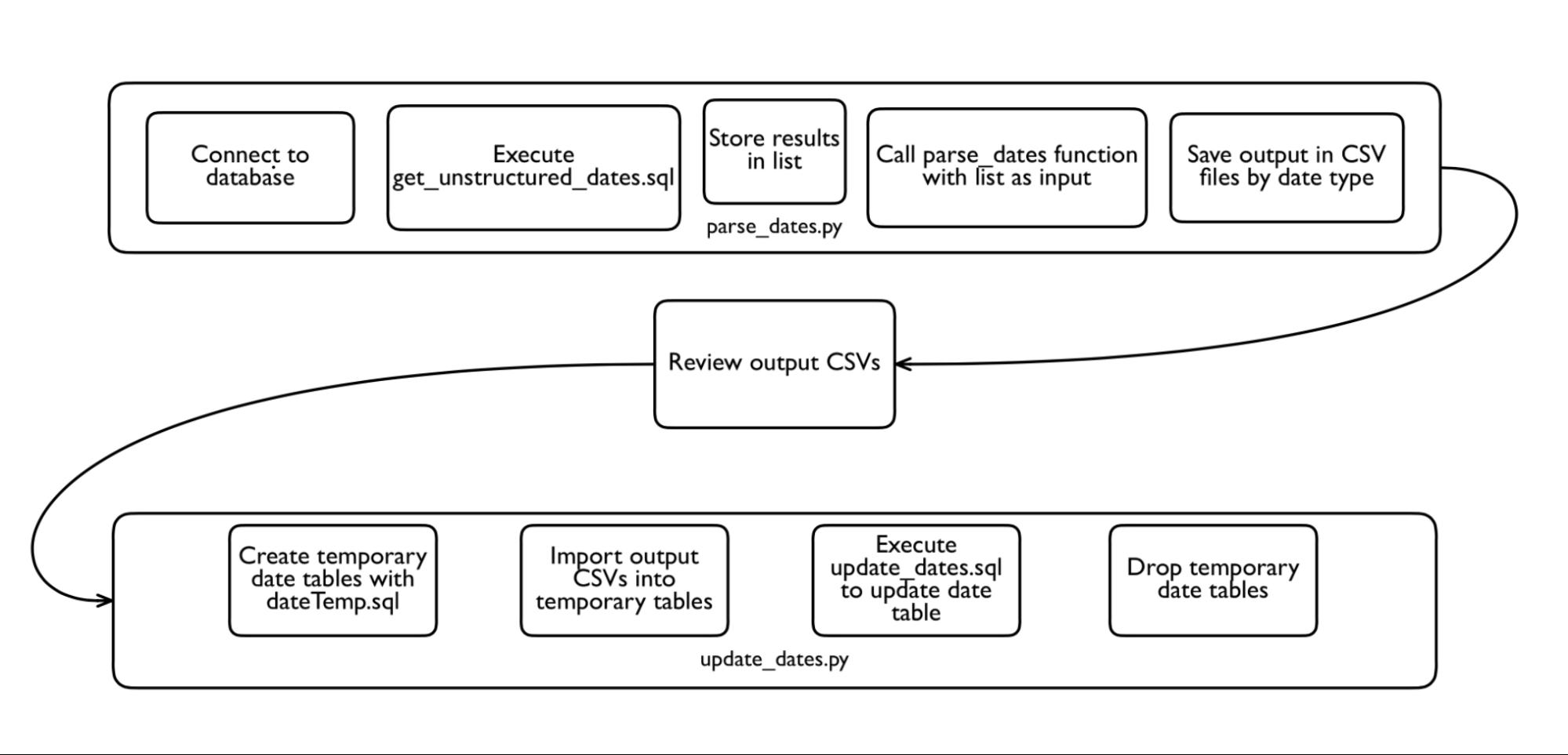 Figure 7. Project Workflow (revised)
Figure 7. Project Workflow (revised)The update was completed in February 2018, and to maintain the work we did during this project in 2019 and beyond, we began executing the normalization process, among other data auditing and cleanup tasks, on a quarterly basis. We continue to work through the dates which could not be parsed by Timetwister and those which require additional processing.
Our experiences on this project also led us to consider ways in which the ArchivesSpace application could be improved to better handle dates and other subrecords. While it would be ideal for subrecord identifiers to be persistent, this would likely require a level of development resources and community backing that is not currently available. Adding IDs to subrecord JSON responses would be a much easier task to accomplish, and could also be done via a simple plugin. Perhaps the best (realistic) option is a system-generated persistent identifier field, like those that already exist for note subrecords, which could be added to all other subrecords, as well. This could also be done with a local plugin, but would ideally be added to the core code, since it would improve the precision of subrecord updates made via the API for all users.
Source Code and Documentation
Ultimately, the point of this project was to provide a new path for researchers to discover special collections materials, and by this measure we feel that we were very successful. During the process we learned a great deal about creating efficient data processing workflows that rely on existing tools and skills to make the most of limited time and resources. We hope that others can make use of the tools we created as part of this work. All of the scripts and a tutorial are available on our Github page: https://github.com/YaleArchivesSpace/yams_data_auditing/tree/master/dates
About the Author
Alicia Detelich is a metadata archivist in the Manuscripts and Archives department at Yale University’s Sterling Memorial Library, and she was co-leader of the Data Cleanup and Enhancements Workgroup of YUL’s ArchivesSpace Public User Interface Implementation project. Her work is focused on developing computational tools and automating workflows for creating and enhancing archival description.
References
[1] Archives at Yale home page: https://archives.yale.edu/
[2] Yale University Library Public User Interface Project Data Cleanup Workgroup Blog Post: https://campuspress.yale.edu/yalearchivesspace/2017/11/29/cleaning-data-to-enhance-access-and-standardize-user-experience-part-i-planning-and-prioritization/
[3] ISO 8601 Wikipedia page: https://en.wikipedia.org/wiki/ISO_8601; ISO 8601 standard web page (full text behind paywall): https://www.iso.org/iso-8601-date-and-time-format.html; https://xkcd.com/1179/
[4] ArchivesSpace documentation: https://archivesspace.github.io/archivesspace/doc/
[5] get_unstructured_dates.sql: https://github.com/YaleArchivesSpace/yams_data_auditing/blob/master/dates/get_unstructured_dates.sql
[6] OpenRefine application documentation: http://openrefine.org/documentation.html
[7] dateutil library documentation: https://dateutil.readthedocs.io/en/stable/ dateparser library documentation: https://pypi.org/project/dateparser/; daterangeparser library documentation: https://pypi.org/project/DateRangeParser/
[8] Timewalk source code and documentation: https://github.com/alexduryee/timewalk
[9] Chronic source code and documentation: https://github.com/mojombo/chronic
[10] Timetwister source code and documentation: https://github.com/alexduryee/timetwister
[11] Subprocess library documentation, Python 3.7: https://docs.python.org/3/library/subprocess.html
[12] parse_dates.py: https://github.com/YaleArchivesSpace/yams_data_auditing/blob/master/dates/parse_dates.py
[13] SurveyMonkey Sample Size Calculator: https://www.surveymonkey.com/mp/sample-size-calculator/
[14] update_dates_by_expression.py: https://github.com/YaleArchivesSpace/yams_data_auditing/blob/master/dates/update_dates_by_expression.py
[15] create_datetemp_table.sql: https://github.com/YaleArchivesSpace/yams_data_auditing/blob/master/dates/create_datetemp_table.sql
update_dates.sql: https://github.com/YaleArchivesSpace/yams_data_auditing/blob/master/dates/update_dates.sql

Subscribe to comments: For this article | For all articles
Leave a Reply