By Chris Mayo, Adam Jazairi, Paige Walker, Luke Gaudreau
Introduction
In the summer of 2017, the Digital Repository Services department at Boston College Libraries initiated a project to replace our digital special collections repository platform. We first implemented DigiTool, an Ex Libris product, in 2003. While it served our needs for several years, the product eventually reached end of life, and Ex Libris discontinued active development. We had configured an interim discovery platform based on Blacklight in 2015, but this interface relied on the DigiTool backend and image viewer, and we knew all of these components would eventually need to be replaced.
One strength of DigiTool was its ability to interpret and render sophisticated METS structMaps. Our implementation made extensive use of the structMap data structure to order and show the relationship among multiple constituent files in a single digital object. Maintaining this functionality was a requirement; in order to mirror the reading room experience for archival materials, we have always matched our digitization workflows and the presentation of digitized materials to the levels of description and the physical arrangement of the materials. We used METS to represent order within items and files, and in some cases the differences between the physical and intellectual order of materials. We were committed to maintaining this robust level of structural description, but we also understood that this functionality was uncommon in repository software.
With our custom METS implementations in mind, we initiated an environmental scan to determine if there were any viable repository candidates that could fit our needs. After identifying our functional requirements, we set off on a six-month odyssey to research and test eight options in consultation with a diverse group of stakeholders from Archives, Systems, and Digital Scholarship. Although some of these candidates seemed promising at the outset, they each presented challenges. Some were new open-source solutions that did not yet include the functionality we required, while others were proprietary systems that lacked sufficient transparency and customizability. Others were more mature open-source solutions that raised concerns about long-term support. Our assessment process ultimately failed to identify a monolithic solution.
Conception
By this point, it had become clear to us that we needed to think creatively. In a final attempt to meet our needs with existing software, we sent an email to the Samvera community listserv, requesting responses from institutions using METS in a Samvera context. We received a reply from a developer who informed us that METS was part of his institution’s workflow, but that it was used primarily to generate IIIF manifests, and that these manifests, not the METS itself, were used to render structured digital objects.
Around this time, we received some alarming news from our university’s Information Technology Services department. They had been scanning local servers for Struts, a development framework with critical vulnerabilities that were exploited during the Equifax hack. As it happens, DigiTool was built with Struts, and because the application was end-of-life, it was using a particularly outdated version. Because DigiTool is closed-source software, we had little agency to address the root cause of this problem. Instead, we worked with ITS to isolate the server from our campus network to minimize the impact of any potential attacks, then rapidly accelerated our migration timeline.
We had previously reacted to the Samvera community response by surmising whether we could make do by spinning up an IIIF image server to host our digital collections. Now with the report from ITS, it started to seem like a more viable solution. We began discussing what services we would actually need to support search, display, and data backup and integrity in a more distributed ecosystem, and began seriously considering a solution based on the microservices architectural model, where multiple single-purpose systems are integrated to provide the functionality of a larger piece of multi-purpose software. In brainstorming the services provided by repository software that we’d need to replicate, we discovered that systems we already had in place could cover a surprising amount of ground.
Our archivists create and maintain canonical descriptive metadata for archival materials in a locally hosted instance of ArchivesSpace. We already had workflows in place for automatically generating description of Digital Archival Objects (DAOs) in batches, and for exporting MODS and METS to ingest into our repository systems along with digitized files.
In addition to our custom Blacklight discovery interface, we also harvested our digitized collections into Primo, our library discovery platform. While this allowed for serendipitous discovery alongside other library resources, it did not provide a facility for browsing collections. Conveniently, as we were researching solutions, Ex Libris announced a new Collection Discovery feature. With this feature, we could build collections in Alma and publish them to Primo alongside other records. Primo then presents these as browsable collection galleries. Alma also includes an OAI-PMH provider, which we could leverage to serve content to external entities like Digital Commonwealth.
From a digital preservation standpoint, DigiTool had conducted automated fixity checking of collections and stored the checksums in its database. However, we also stored a second set of our collections outside the DigiTool environment. These copies lived on an in-house preservation server, which was configured to run automated checksum audits using Audit Control Environment. Additionally, copies of these collections were transferred from this server to our LOCKSS-based distributed digital preservation solution, MetaArchive. Even if our new solution lacked preservation functionality, we could make up for that with already extant systems.
We also discovered, as anticipated, two major areas where we would lack coverage after moving out of a traditional repository system. The first was an image viewer. We saw the migration from DigiTool as an opportunity to adopt the International Image Interoperability Framework (IIIF), an exciting initiative that we were eager to apply to our own digital library work. While Alma offers partial IIIF support with its implementation of Universal Viewer, the Viewer Services module was not customizable enough for our needs. DigiTool had also provided access to technical metadata through digital entity files stored in a database. Although this option was clunky and often riddled with imperfections, it had fulfilled our need to search for and store PREMIS within our repository. We recognized that we would also need to devise a way to store technical metadata in an archival management system.
Feasibility
As we explored the feasibility of our proposed digital repository infrastructure, one of our most pressing concerns was how to render structural metadata effectively. We used osullivan, a Ruby implementation of the IIIF Presentation API, to write a Ruby gem that would convert our METS files into IIIF manifests. Fortunately, our Digital Scholarship group had already developed something similar for a separate IIIF project, which we used as a starting point. Because that code was written for a specific context, we had to refactor it significantly to make the gem compatible with all of our METS. This proved time-consuming but well worth the effort, as it provided the foundation for another gem, aspace-to-iiif, that generates a IIIF manifest from an ArchivesSpace digital object record.
Selecting the right image viewer also took some trial and error. We demoed a few IIIF viewers to our stakeholders, but the one that stood out was Mirador. Mirador had been on our radar as a potential viewer for Digital Scholarship projects, but we had not yet implemented it at Boston College. For this use case, it proved to be a perfect match. Our team appreciated the clean, modern interface, as well as the ability to display structural information in the side panel. For our IIIF image server, we wanted something that would be relatively easy to install and maintain. We decided on Loris, which was already in use for a different project at the libraries.
While we were pleased with the user experience presented in Primo, we found ourselves with several new challenges. First, we needed to devise a workflow for importing our DAO records into Alma. Since ArchivesSpace serves as our source of canonical metadata, we only needed the Alma records for arranging into collections and publishing to Primo. With some trial and error we were able to generate exports of object records in MARC format that captured critical descriptive metadata and distinguished the material from other Alma records. We worked to arrange the Alma records into collections by building sets of records matching by collection name.
We also needed to address the need for persistent links to DAO records in Primo. While Primo does include a permalink mechanism out of the box, it is not customizable and the links cannot be predictably controlled. We worked around this by creating a Primo customization that replaced the default permalink with a new one based on the legacy DigiTool PID and our internal handle server. We also added this PID as a searchable PNX field and added it to our existing Primo search middleware, primo-services. Our handle server was then configured to point to primo-services to perform a search for the given PID.
Finally, we needed to determine whether it was possible for us to generate and store technical metadata in ArchivesSpace for our files, to have this data available outside of our preservation environment. As we already had a process in place to automatically build Digital Archival Objects with bitstream-level data, this was primarily a question of finding an appropriate file characterization tool and mapping data to appropriate fields in the database. We began experimenting with EXIF, but eventually settled on FITS for its ability to characterize a wider range of filetypes. Some, but not all of the data we were interested in storing already has controlled fields in the ArchivesSpace data model, and so in many cases we have been forced to store data in labeled general notes fields. Managing these fields will be an ongoing challenge.
When we had outlined all of our needs and the ways we expected to fill them, we created the system model depicted in Figure 1.
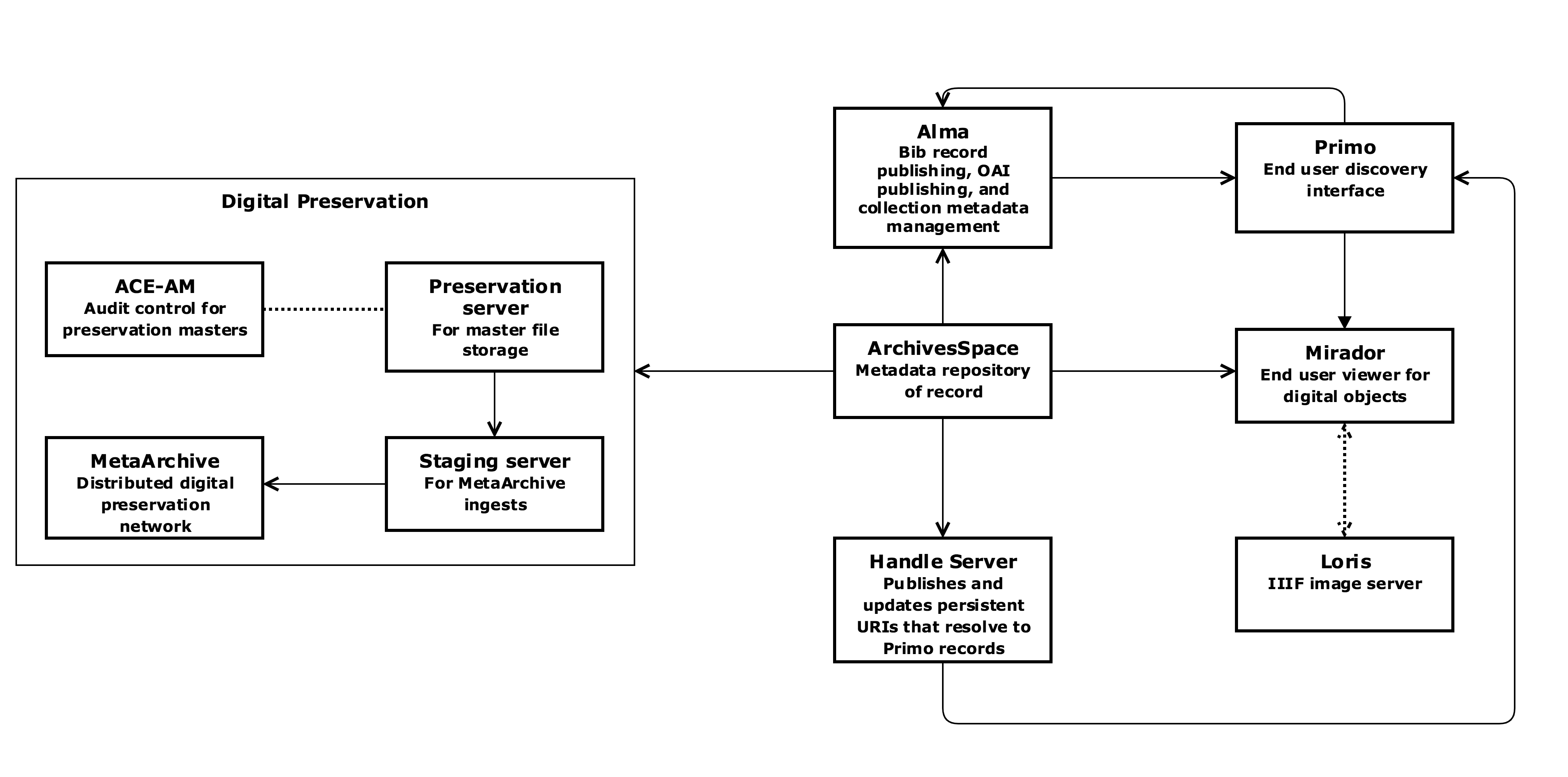
Figure 1. Diagram of system model.
Outcomes
As noted, the purpose of this article is to outline our experiences with implementation of a microservices-based repository solution. Given that any institution implementing a similar solution will ideally be selecting individual systems that best meet their own needs or are already implemented locally, we have chosen not to describe the technical specifics of our migration and integration workflows. We also omit our efforts to implement an Agile-style project management mode for the process of building and migrating to this system. We intend instead to present our outcomes as a series of challenges and positive outcomes, with an analysis of how each outcome relates to the microservices model: are there problems we could have avoided, or desired outcomes we would have lost, if we had not pursued a microservices-based solution?
One aspect of our new architecture that seemed beneficial at first was use of the description in ArchivesSpace as the canonical source of descriptive metadata. It had to be verified against our legacy data, and we would need to devise a way to publish it in Primo, but with the description already present in ArchivesSpace, no migration was required. However, this assumption was refuted by two of our major digitized collections. One, an archival photographic collection consisting of tens of thousands of images across hundreds of files, was not described in ArchivesSpace because we had not yet implemented an archival management system when digitization on this collection began over a decade ago. A similarly large collection of early New England financial and legal documents had not been described in ArchivesSpace because it is owned by our Law Library, not our Archives. In both cases, we used an export of legacy metadata to make these collections available in BC Digitized Collections. Still, they would require extensive backend work to be maintainable. In the six months since the system launched, we have partially imported the data for the photographic collection into ArchivesSpace, but much work remains to be done, and work on the legal documents collection is only just beginning. If we had been migrating to a new repository, we would have these collections under better intellectual control in the digital repository, but we would not have had the excuse we currently have to put the effort into migrating them into ArchivesSpace. The microservices model has unarguably given us more work, but it is work that needed to be done.
Using Alma and Primo to make our digitized collections discoverable presented its own challenges. Significant resources were dedicated to trial and error configuration of Primo normalization rules for display and search. In many cases the rules are duplicates of existing rules targeted specifically to Digital Archival Objects. The large number of rules and their reliance on precise combinations of metadata values has translated to significant maintenance costs.
We also learned that Primo Collection Discovery relies on additional API calls to build the browseable collection hierarchy. That dependency has proven to be problematic, with performance, caching, and security problems abounding. Over time many of these problems have been fixed, but in the meantime it has required a large number of manual workarounds, communication with public services staff, and persistent troubleshooting with Ex Libris.
Our integration of Alma in the BC Digitized Collections architecture is a weak point, particularly with regard to ArchivesSpace. We currently export ArchivesSpace digital object records as METS with embedded MODS, then transform them to MARC before ingesting to Alma. This workflow is effective, but it requires a fair amount of manual work that could be automated. We plan to explore the ArchivesSpace OAI provider as a potential solution, and have also discussed the possibility of writing a plugin to export digital objects as MARC. There is interest within ArchivesSpace community to pursue Alma integration (Kevin Clair at the University of Denver has already written a plugin to that effect), so this could be an opportunity to collaborate with other institutions that have similar needs.
Many of our preservation-related workflows remain manual rather than automated. After its initial ingest into ArchivesSpace, technical metadata is updated infrequently. Our fixity checking program, Audit Control Environment, does not integrate with ArchivesSpace, so related PREMIS events are not documented alongside other metadata. We also lack a solution for batch normalization of select file formats. To account for these needs, our team is investigating Archivematica as a potential addition to our suite of microservices.
In spite of these challenges, we’ve also experienced an equal or greater number of positive outcomes. Similarly to the challenges, many of these beneficial outcomes are related to the choice of a microservices model.
Of the eight potential repository solutions that we investigated before undertaking this project, five were open-source and three were vended solutions. We have the available technical resources that if we had chosen an open-source solution, we would have been hosting it locally, and our experiences with DigiTool had strongly predisposed us toward open-source software. Due to the proprietary formats used in the database, although we were able to get our data out of DigiTool, we did not reuse it extensively in the migration process other than as an audit checker. Some of the components of our solution are vended—Primo and Alma—and others are locally controlled and installed instances of open source projects—ArchivesSpace, Mirador, Loris, and Audit Control Environment. Critically for us, our canonical metadata lives in an open-source management system, which helps us feel more comfortable about our ability to migrate forward in the future.
Although there were additional considerations, one of the reasons an open-source repository was infeasible for us to implement was the amount of time our current staff of systems and support librarians had available. As noted, we already host several open-source systems locally, but we haven’t customized any of those systems to the extent that the available open-source repositories would have required. We felt that we couldn’t do justice to our needs without committing 1 FTE of developer time, which we simply didn’t have. Had we chosen a vended solution, upfront and ongoing monetary costs would have been significant. We were able to implement BC Digitized Collections without purchasing additional software or hiring new staff, clearly making it our most financially responsible choice. While we relied on dedicated project time from a systems librarian during the implementation and migration, ongoing maintenance and upgrades have been folded into existing Primo support mechanisms. We also gained a seat on our Library’s Primo Working Group, where we can advocate for our needs alongside issues from other stakeholders. It’s difficult to say whether we’d have been able to implement an existing repository solution, open-source or vended, in such a budget-neutral way.
However, this budget-neutrality was achieved partly through a combination of extant technical skills and our own interest and ability to gain new skills. In particular, our digital repository applications developer gained more expertise with the IIIF Presentation and Technical APIs in his support of Mirador and Loris and manifest generation. Our digital collections and preservation librarian explored and implemented FITS in her file characterization workflows to enable us to generate and store technical metadata. Our digital production librarian expanded their work with the ArchivesSpace API to support import and linking of new metadata fields, both technical and descriptive. The microservices model allowed us to select and implement services that matched with and enhanced our staff’s current technical capabilities, benefiting the project and the library.
We committed a significant amount of staff time to develop migration tooling for this project. Ordinarily, such scripts and transforms would hold little value once the migration ends, but we were thrilled to find the opposite with BC Digitized Collections. Some of these tools were brand new, such as our aspace-to-iiif gem. Others were heavily revised and refactored, such as the script that we use to batch generate digital objects. Regardless, many of them still find regular use in our daily workflows.
The microservices approach to our repository architecture has allowed us to develop greater flexibility and transparency in our workflows. Because these services are interoperable, we can apply them beyond our repository to improve our digital library program as a whole. For instance, we are now exploring integrations between ArchivesSpace, BitCurator, and Archivematica to create a more robust digital preservation campaign. Due to the open-source nature of many of these programs, we can also analyze their code to better understand their technical foundations. This allows us to assess how programs may impact the integrity of our collections and the privacy of our patrons. We believe that these flexible integrations will lead to fewer silos, more efficient workflows, and a stronger digital library overall.
Finally, one of our enduring goals as a department is to connect with and contribute to the larger community of practice. By taking an active role in multiple open-source communities, this project has positioned us to do that. Our interactions with the individuals and institutions involved in ArchivesSpace and IIIF have been deeply rewarding, and we look forward to working more with these communities.
Next Steps
As BC Digitized Collections was a significant departure from our previous repository platform, we were eager to see how our end users responded to it. We conducted usability testing in Fall 2018, which predictably revealed some design flaws. For example, we currently link to an external instance of the Mirador viewer from catalog records, which caused confusion for some test participants. We made this design choice because it was the fastest way to ship the product, but we would like to explore embedding Mirador in Primo to reduce friction. We plan to test this with the upcoming Mirador 3.
Similarly, we would like to expand our IIIF implementation, which at this point is fairly lightweight. We plan to add support for annotations, and are beginning to consider IIIF as a delivery mechanism for audiovisual content, as will be supported by version 3 of the Presentation API. We have also discussed extending our IIIF image server to other uses, such as a web app that allows staff to resize and crop images.
Usability testing also revealed biases in our design process that had gone unnoticed. A particularly salient example of this is the name ‘BC Digitized Collections’. As archivists and librarians, we took for granted that our users would be able to decipher this and understand what they would be able to find within the system. In fact, our test results suggested the opposite. A reevaluation of how we are naming and describing the system is forthcoming, with a greater sensitivity to our end users’ level of familiarity with library jargon and information architecture conventions.
We must also work to streamline how some of our systems are integrated. This includes development of additional ArchivesSpace export functionality, and perhaps use of the ArchivesSpace OAI provider to pipe records to Alma in a more automated manner. This is relatively low priority technical debt, but it is a notable downside of microservices: loose coupling can mean additional overhead to make cross-component workflows run efficiently. We are also investigating integration of Archivematica with ArchivesSpace, with the hope that technical metadata generated through Archivematica’s FITS may be ingested into ArchivesSpace and associated with the appropriate descriptive components. Although we are unsure of Archivematica’s capacity to accomplish this goal, we will continue to investigate integrations for our manual and siloed technical metadata workflows.
Conclusion
We decided to share our experiences with implementing a microservices-based solution because it’s an architectural approach that more libraries are becoming interested in exploring. Overall, our experiences have been highly positive: we gained significant technical expertise and broadened our horizons for giving back to the open-source community. At the same time, we implemented a new system that has garnered positive feedback from internal stakeholders in a largely budget-neutral fashion. On the other hand, this was possible because a large number of the services we intended to combine were already implemented in our library, and our staff had the interest, ability and bandwidth to take on new technical challenges. Any library considering implementing a microservices architecture should make sure to include stock-taking and feasibility steps in their project planning to minimize nasty surprises during the implementation phase.
Will we continue to use a microservices architecture for our digital repository in the future? We aren’t certain. Given that lack of maturity was a major roadblock in some of the repository solutions we considered, we may eventually find them maturing to suit our needs without requiring extensive local customization. When initially implementing BC Digitized Collections, we viewed it as a stopgap measure. We conceived of it to be as flexible and migration-friendly as possible, expecting to migrate one or more components forward eventually. It will be interesting to look back in five years and see whether we are still employing the same architecture, still using microservices with a different suite of interlinked services, or have migrated to a more monolithic repository system.
We hope that we have provided some idea of the benefits and tradeoffs inherent in this microservices-based model. We strongly believe that this approach can be beneficial to libraries that already implement a wide variety of systems, provided that they have the resources and technical skills to support tighter integration between those systems. We hope to see more mid-sized institutions like our own implementing similar solutions and contributing to the open-source ecosystem in the near future.
Resources and Github Repositories
Primo/Alma
Primo Services: an application for building persistent links to Primo records and searches
International Image Interoperability Framework (IIIF)
O’Sullivan, a Ruby API for working with IIIF Presentation Manifests
Burns Antiphoner, a Boston College Digital Scholarship project utilizing IIIF
Aspace-to-IIIF: a Boston College Ruby Gem converting ArchivesSpace Digital Objects to IIIF manifests
Mirador: a IIIF-based image viewing platform
Loris: a IIIF image server implementation
Other resources
About the Authors
Chris Mayo is the Digital Production Librarian at Boston College. They are a project manager, metadata wrangler, and general-purpose script writer and cat herder.
Adam Jazairi is the Digital Repository Applications Developer at Boston College. He manages BC’s digital library infrastructure.
Paige Walker is the Digital Collections & Preservation Librarian at Boston College. She works with the preservation, privacy, and security of the Libraries’ born-digital and digitized content.
Luke Gaudreau is the Discovery Systems Librarian at Boston College. He focuses on library discovery, user experience, project management, and design thinking.

Subscribe to comments: For this article | For all articles
Leave a Reply