by David Forero, Nick Peterson, Andrew Hamilton
Frequently academic departments want to know how many publications their faculty and researchers have published over a particular period of time. At the Oregon Health Science University (OHSU) these questions were traditionally handled by having a librarian manually search various publication databases. These searches were complicated, and the outputs of these searches were often cumbersome and unwieldy. This meant that the answers to questions were often limited by how much effort could be put forth by the librarian whom may spend many hours managing these searches and the resulting data.
The development of search strategies to capture accurate and relevant data brings with it many challenges. This is a problem of trying to generate an accurate and comprehensive list based on incomplete and sometimes inaccurate data (databases of publications) with almost always incomplete and contradicting information about authors (lists of university faculty or lack thereof). In this article, we will discuss the overall problem and what efforts we previously made to address it. Then we will discuss how we approached the problem differently. We developed an augmented search tool that lightens the load and normalizes the process on our campus. What’s more, the tool is open and could easily be customized for other institutions.
The Challenge
Here is a brief list of overarching problems when conducting a search of publications for an academic department:
- Who: What authors are considered part of the academic department.
- What: What source is being used to find all the publications.
- When: Which of the many dates associated with the publication is being searched.
The problem of “Who”
The most difficult challenge is figuring out which papers in indexes of publications should be counted. Many publications include the organizational affiliation of the authors, though, not all. Those that include the information tend to solicit the information from the paper’s authors and present the information as free-text. Additionally, authors can have multiple organizations to which they belong to and may list some or all of these affiliations. This is further confounded by temporality, as people often change organizations and there is rarely any kind of tracking of who was part of what organization when. Rather than looking at the problem top down and searching for organization data, one could do searches based on individual names instead. The typical problems with people with the same name crop up. If authors all used ORCID ids (https://orcid.org/), that could be a very effective strategy, though, our experience has been that too few authors utilize them to make this identifier useful. Also, getting definitive lists of people in the organization can be difficult. This fact might seem surprising but our experiences in higher education lead us to believe this is more often the case than not.
The problem of “What”
This issue is determining an authoritative source of what has been published. There is no one source to refer to for all publications for an institution. This is one of many compromises that must be made to approximate the full answer. For an institution like OHSU, Scopus and PubMed represent a fairly comprehensive publication source as both offer a wide selection of publications but neither encompass all possible publications formats; for example, smaller journals, thesis, technical reports and other publications which are not monitored by these two services. Also, there are the rare publications outside the main domains of faculty at our institution. For example, this article is extremely unlikely to turn up as a publication in either publication index and therefore won’t be counted in any tallies of OHSU publications.
The problem of “When”
As the previous point alludes, the exact definition of what counts as published might be hard to pin down. This may be a little in the weeds but it underscores the depth of problems facing a searcher. Also, the date it is published turns out to be often squishy. Publishers often “pre-publish” an article, and then later officially publish the article. What this means is the data in indexes like Scopus and PubMed are dynamic, in other words, the data can change and be updated and often have different object identifiers. So, a diligent person who monthly tallies the publications of a particular organization might count an article in two different months. Avoiding this requires tracking individual articles.
Our Previous Process
Prior to the development of our automated search tool, a list of OHSU authored publications was manually created by the OHSU Library by running a monthly update for OHSU affiliations in both PubMed and Scopus. The results of these updates were then imported into Refworks, and later EndNote, for processing which consisted of identifying and eliminating duplications between the two databases and moving newer versions of an article over to replace any existing versions in RefWorks. This monthly process was incredibly labor intensive and unsustainable for Library staff. It was decided that the monthly update strategy for OHSU affiliations within PubMed could serve as the foundation of the new tool.
As discussed, we had a very resource intensive process. Initially attempts to address this problem involved essentially building a local database of publications. This involved constantly resynchronizing the local list of publications with an index like Scopus and required a considerable amount of curation. In particular, the de-duplication and curation of members of organizational units was still considerable. Essentially this was a fancier version of the existing manual process.
Instead, the approach we took was to augment people’s searches to approximate some of the normalization done in the manual process. Part of this decision was based on the fact that, we knew we couldn’t get a set of perfect results and needed to focus on good enough. The new attempt would acknowledge the potential for incompleteness but instead focus on making the efforts less. Essentially, if we’re not going to get a perfect answer, can we put in less effort to get an equally complete answer.
For the “What” problem, the tool would leverage an existing publication index. We chose PubMed because though it was a smaller index, it does cover the main focus of our institution, and we could freely share the results without violating any contractual restrictions. We can easily capture the kinds of searches we were already doing.
For the “When” problem, we were essentially leaving that up the individual searcher. If the searcher cares deeply, they could track their list of publications. However, we were no longer going to try to deal with this problem at the institutional level.
The big problem was how to address the “Who” problem. Searching for specific people is fraught with difficulty as people change names and often have identical names with others. Our approach is only to search for people after we have a search limited by the scope by institution. Since OHSU does not have an identity management system, there are many collections of people in different departments for different purposes. We worked with the Registrars and Human Resources offices to get a list of people and their primary organizational unit within the institution. The idea was to essentially extract a list of most likely OHSU publications from PubMed and then try doing name matches with the lists from the Registrars and Human Resources. This isn’t a perfect solution, however; we have greatly reduced the likelihood of name collision by restricting the publication list to likely OHSU articles. Also, we have a problem with older articles, where it is more likely that an author is no longer associated with OHSU and therefore not in the “master” list provided by the Registrars and Human Resources. Fortunately, publication requests were most often for recent publications.
Automated Method
The service <http://library.ohsu.edu/oast/> we created uses a fairly standard LAMP (Linux, Apache, MySQL, PHP) stack. We will highlight two main high-level components of the search tool: PHP which is used to query the PubMed API for citation information and MySQL to query a local DB that is culled from our institution’s available Registrar and Human Resource data. In practice, any available web programming language will suffice, but we choose PHP since it is utilized heavily in-house. For the people data, we are still in the process of finding the most optimized way of matching Authors from PubMed queries but for now MySQL was chosen since we already had the data on-hand in this form. An important design choice here was to use fields that users already commonly use to search and mapping our fields directly to the fields used in PubMed.
The basic gist of the PHP form takes a series of user provided inputs, constructs and submits a PubMed query, compares those results with available people data and returns the final result set to the user as an ajax DataTable for viewing or export to common tabular data formats. User inputs on the form range from Journal Title [ta], Date Range of Publication [dp], Author Name [au], Grant Number [gr], etc.
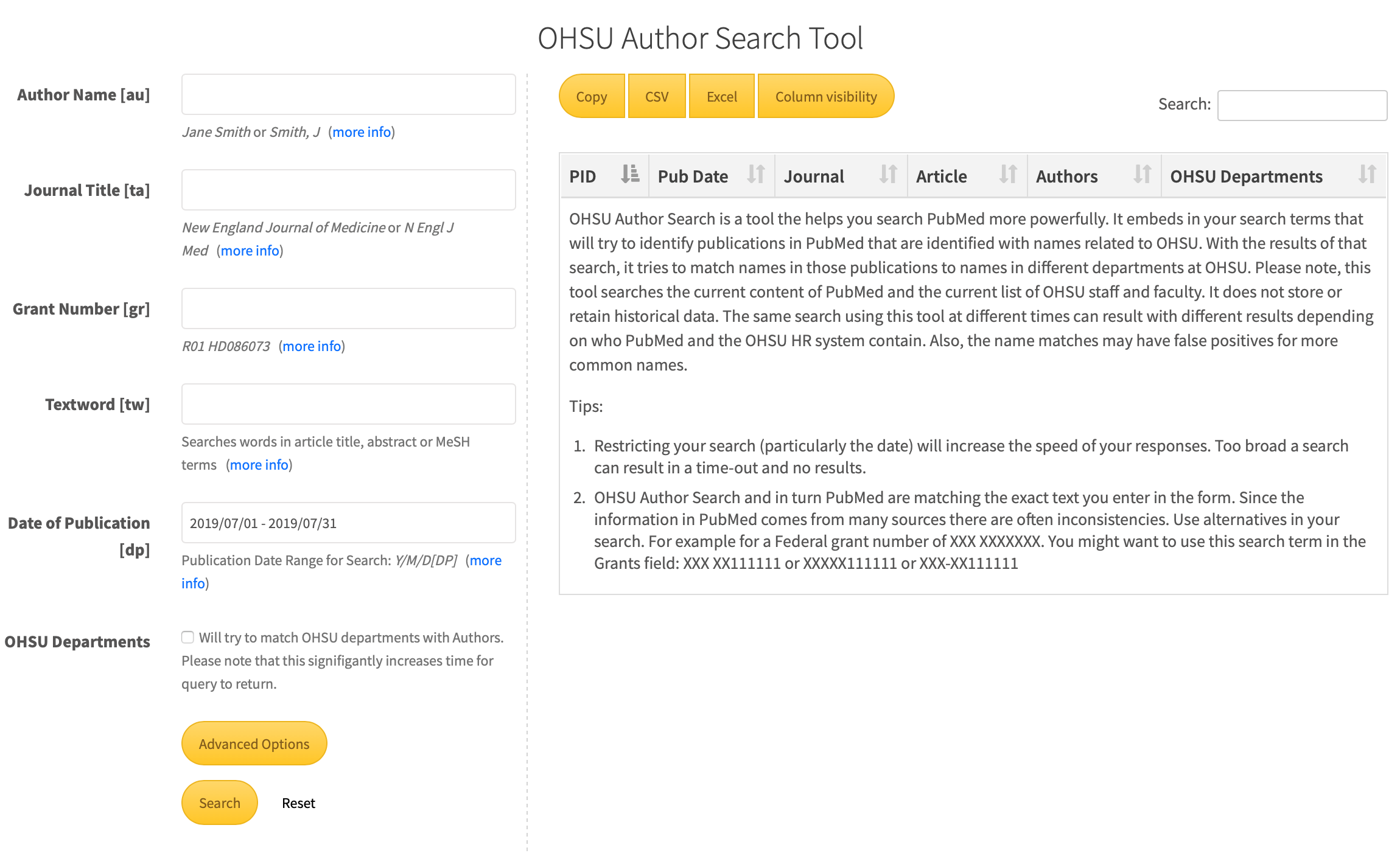
Fig. 1: OHSU Author Search Tool
Additional fields are available under the Advanced Options button for fine tuning the search. Under the Advanced Options is the original base query which is fully customizable by the end user. All user inputted fields are ANDed to this base query and submitted to the PubMed eSearch API when hitting ‘Search’ on the form.
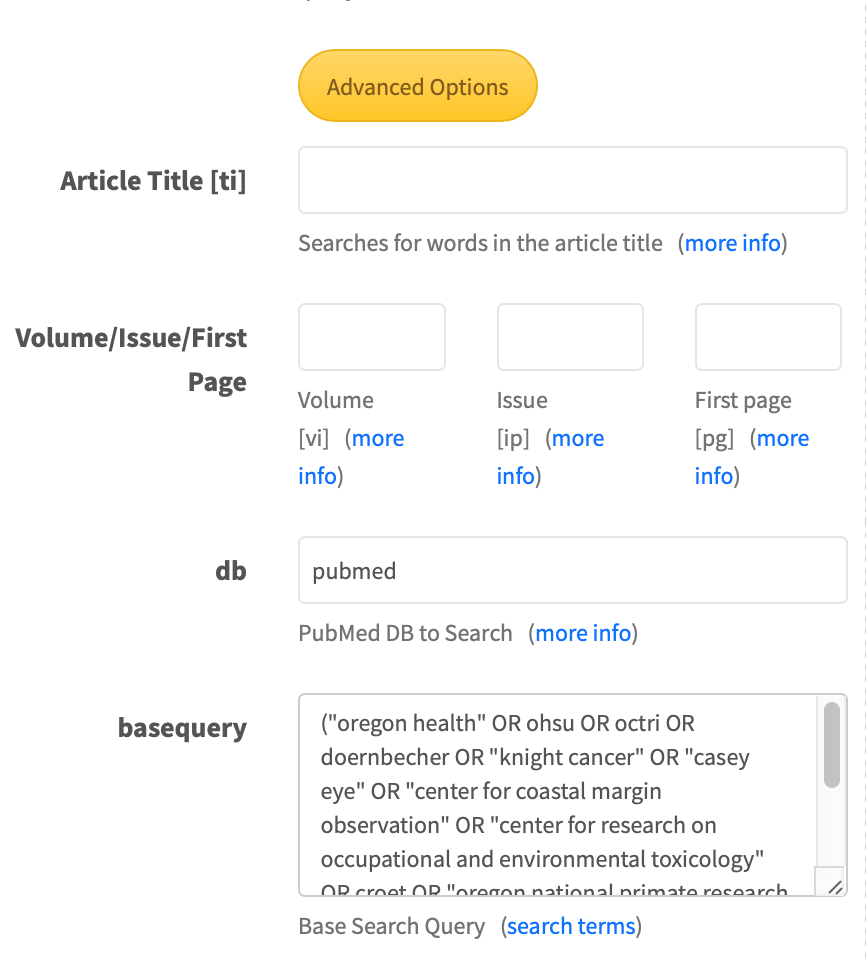
Fig 2: OHSU Search Tool advanced options
The API returns our result set and makes it viewable as a paginated table to the right of the search form using the ajax DataTables library. This allows for responsive sorting/filtering as well as exporting to common tabular data formats including CSV and Excel. If the user selects the ‘Match OHSU Departments’ checkbox then an attempt to match author names from the PubMed result set against our MySQL DB of OHSU people data is made and those names are bolded in the report and their associated campus departments are returned.
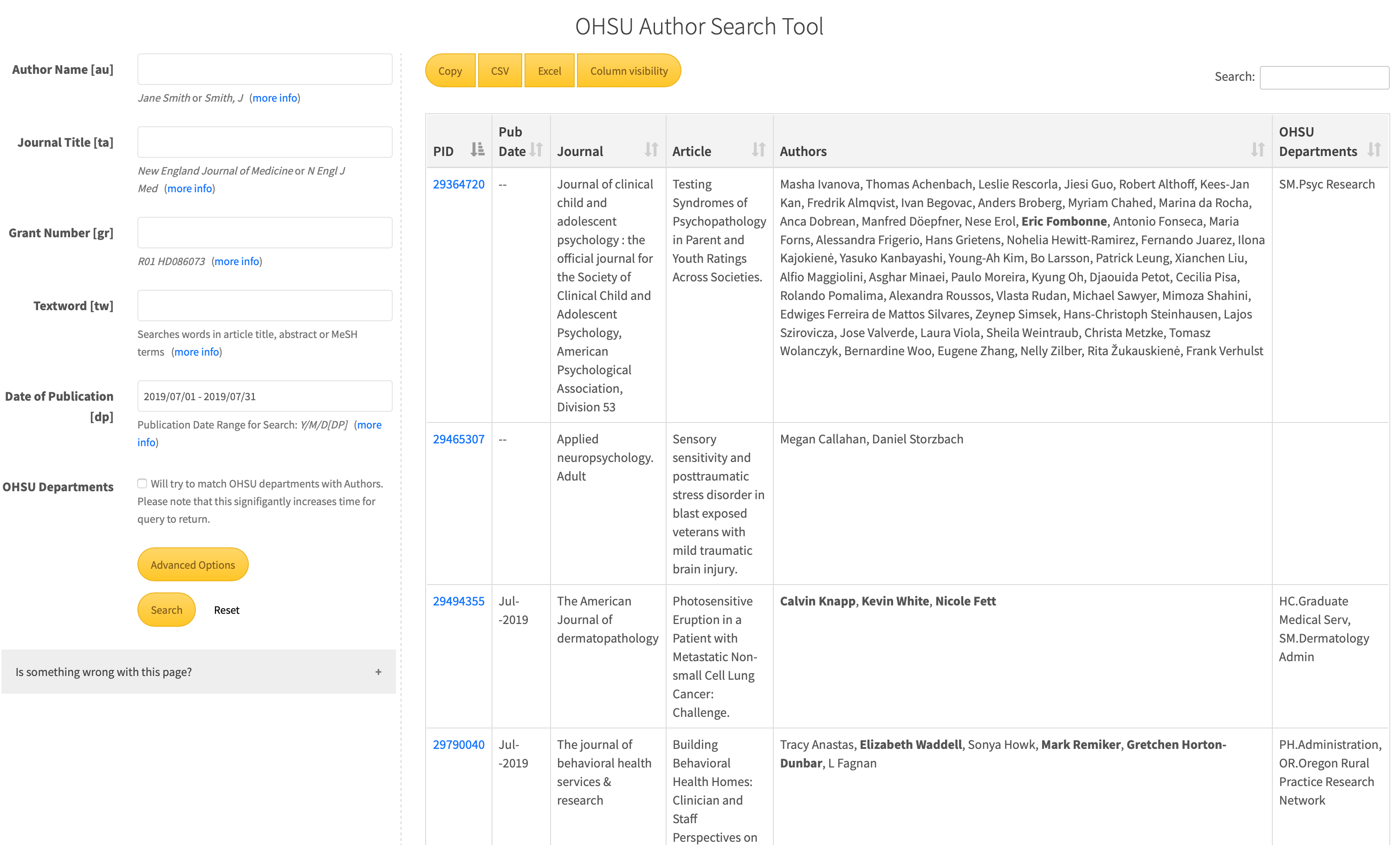
Fig. 3: OHSU Search Tool Results Set Example
The form is ‘self-POSTing’ in the sense that all modified search fields (including the base query) are constructed as a URI query string. This means that links to specific result sets are entirely portable or even entirely customizable outside of using the form itself for input. This makes canned result sets easy to construct against the tool. Our current plans are to expand this functionality to allow for proper API calls or direct CSV/Excel dumps for specific need cases.
Code is available on GitHub here: https://github.com/OHSU-Library/pubmed-query-util
Lessons learned
Our goal was to provide a service of equivalent quality with less resources dedicated to the effort. In this we were successful. As we did user testing, we learned more about what the users of this service needed. One particular lesson involved grant numbers. Essentially, OHSU staff used grant numbers to search for publications. Although most of the grants at OHSU are federal grant numbers which have a very specific format, we quickly discovered that these grant numbers are not consistently entered in different publications.
The biggest success in our minds is this tool augments the capabilities of people using it. Since everything in it is completely transparent. Users can bookmark the search and since the search query is embedded in the URL, it provides users with quick jumping off points from previous efforts. Also, since the tool provides an easy way to modify the core query for institution, individuals can tailor the query to accommodate their needs. For example, as other organizational units are formed, the user does not have to wait to request a change to the base search from the Library. Instead they can modify the search for themselves and that change is also embedded in the URL.
This tool enables individuals to start a search with a fairly intelligent starting place. These individuals can still get help from an experienced reference librarian but now they come to the conversation with a reasonable start and the librarian can augment and tweak the search. This is educational and empowering for the user and allows our librarians to focus efforts on more complicated requests.
As discussed, more consistent entry across all publications will make this process easier. Perhaps one day OHSU will have a central registry of authors’ ORCID IDs that is always up to date with Human Resource data and organizational affiliations while all publications have consistent ORCID ID usage and some kind of usage of controlled organizational identity. Until then, at OHSU we have found a way to empower our staff to make fairly quick power searches that provides solid results.
About the Authors
David is the technology director for the OHSU Library in Portland Oregon. He is active with the equity, inclusion, and diversity work both at OHSU and ACRL. He also co-manages the game lending collection at OHSU.
Andrew Hamilton, MS/MLS is an Assistant Professor employed as a Health Science Education & Research Librarian at the OHSU Library. Prior to joining OHSU, he worked for the NN/LM National Online Training Center from 1996-2002 where he travelled the United States teaching thousands of librarians how to search PubMed. Mr. Hamilton earned his Master of Library Science degree as part of a double Master’s degree for Drug Information Specialists (M.S.-Pharmaceutical Science/M.L.S.) from St. John’s University in 1993.
Nick is a Systems Analyst at the OHSU Library whose primary responsibilities include management, maintenance and support of the library’s servers, software, desktop computers, printers and AV equipment. His specialties include database development, systems integration and custom web development. Outside of work he is an avid photographer, filmmaker and budding woodworker.

Subscribe to comments: For this article | For all articles
Leave a Reply