By Michelle Suranofsky and Lisa McColl
Background
The Lehigh University Libraries and the Lehigh University Art Galleries (LUAG) enjoy a collaborative relationship. The two areas of the University continued this relationship in March of 2019 when the staff of the libraries agreed to catalog a collection of approximately 2,000 books owned and housed by LUAG. These books were being used internally for reference purposes by the staff of LUAG, and were being stored on shelves in a storage facility on campus. However, a newly remodeled space for a reference reading room in the main art gallery facility was being planned. The staff at LUAG wanted these books to be available to anyone in the campus community who wished to visit that space. They also wanted the books to be discoverable through the library’s online catalog.
While the library staff was eager to take on this project, we were also daunted by the task, knowing that the day to day demands of our job would continue without interruption. In consultation with the LUAG staff members we decided we could find a balance in getting the appropriate records into the catalog as quickly as possible, while keeping in mind that more granular details, if needed, could be applied to the records later. The opening for the new reading room was set for October 2019, and our goal became to have all of the books on the shelves, classified, and in the catalog in time for the opening reception.
Evaluating Solutions
As we began by considering where efficiencies in our typical cataloging workflow could be inserted for this project, automated OCLC record lookups came to mind. We estimated that most of the books in the collection were not too old to have ISBNs or LCCNs, so we thought that data would be a good entry point for automated searches. We wanted a tool that would select a single “best” OCLC record based on a cascading sequence of logic that mirrored as much as possible how we select a record manually. Ideally, it would choose the record that we would have chosen in an individual lookup. Although OCLC’s Connexion Client does have a batch lookup tool, we knew it could not be customized to the extent we needed to achieve the results we were looking for.
We began by looking at tools that utilized OCLC’s WorldCat Search API [1] for record selection. Two tools that were considered were Cornell University’s LS Tools [2] and Yale University’s backlog_lookup Open Refine project. [3] Our review showed both to have very rich feature sets. Looking at Yale’s backlog_lookup tool we got a sense of the large amount of logic and configurability built into it. With those rich features and configurability came a fairly steep learning curve that would have to be navigated in order to obtain the customizations we desired. Fortunately, while this review was taking place, the possibility of using a Google Sheets Add-on [4] for a technical solution opened up after hearing a podcast that focused in part on that feature. Steps in cataloging workflows often take place in spreadsheets so it seemed like a tool that existed within this environment would be a good fit. Further investigation revealed other attributes of Google Sheets Add-ons that met our needs:
- It has the ability to make calls to APIs
- It has the ability to parse and construct XML. This meant the add-on could seamlessly parse the MARC XML returned from the API calls – to inspect values and pull out values to write back to the spreadsheet.
- The code is written using plain Javascript and is fairly intuitive to work with.
- Google provides thorough documentation and coding examples for this platform
- The actual writing of the code can take place directly in a browser (using their ‘Script Editor’) so there is not much effort needed in setting up a development environment.
- This platform gives you the ability to easily share your projects. During the development process, the add-on could be shared in a similar way to sharing a Google Sheet or Google Document. This meant the code could be written, easily shared and tested providing an efficient feedback loop.
Iterations
Based on those positive attributes, we decided to move forward with creating a Google Sheets Add-on proof-of-concept. We were pleased with how quickly a rudimentary prototype came together. In the initial version, the record matching criteria was hard-coded. For our test case, we set the criteria to use the following sequence of logic for selection when given an ISBN or LCCN:
- Return records first that are held by Lehigh University (LYU)
- If no records are held by LYU, return if 040 contains DLC
- If no records are DLC, return if 042 contains pcc
- If no records are pcc, return the record that has the most holdings attached.
The add-on was able to call the OCLC WorldCat API using ISBNs and LCCNs that were entered into a Google Sheet and then insert the values from the MARC records contained in the API responses back into the Sheet.
During the next iteration of the project we added match criteria that would allow the user to retrieve records that represent a specific format. While the project for which this was being developed called for a return of records for print monographs, we began to think about future uses for this tool. We realized we would desire functionality from the add-on that would enable us to use it for a variety of formats. Therefore we decided if format selection could be entered by the user and not hard-coded the tool would be more extensible.
At first we considered using a form within the sidebar of the add-on to set the match criteria. Then, as we began to realize that additional match criteria could be desired, another option was put into place. The setting of the criteria, instead of squeezed into the sidebar, was placed onto a new tab in the spreadsheet itself. With this setup a large amount of real estate became available that would allow a user to input fairly complex matching rules, directly in the spreadsheet, with no knowledge of coding needed. This spreadsheet criteria tab also became a place for the user to specify the bibliographic data they wanted returned in their results.
Testing
With the selection logic and match criteria in place, it was time to test the add-on for accuracy. A good test subject came in the form of a donation of 83 math books that the library wanted to accession. Each book was searched for in OCLC’s Connexion Client, manually, and an OCLC number was decided upon and recorded. Then, in a Google Sheet, an ISBN or LCCN for each book was entered and the MatchMarc add-on was run. We compared the column of manually selected OCLC numbers with the column of machine selected OCLC numbers. There were only two discrepancies between the human chosen and machine chosen records, and they were both the result of human error: the add-on selected the best record each time.
Encouraged by these results we began using the add-on immediately to select records for LUAG’s collection of books. The process of copy cataloging was sped up considerably not only by this new lookup process, but also by the native spreadsheet format, out of which the following workflow developed:
After MatchMarc results populated the spreadsheet:
- The column of call numbers returned was used to create spine labels. While a Mail Merge feature is available in the G Suite, we decided to save the Google Sheet as a Microsoft Excel document and use MS Word’s Mail Merge feature to complete this task.
- The same Excel document used to create spine labels above was used to create brief MARC records using MarcEdit’s Delimited Text Translator function. Local information placed in the spreadsheet, like local notes, barcodes, and call numbers, became part of this brief MARC record.
- The brief MARC record file created above was merged with the MARC file from OCLC, using MarcEdit’s Merge Records function. The OCLC number was used in this process as the unique identifier on which to base the merge.
- As a final step before importing the MARC file into our ILS, a MARCEdit task removed unnecessary MARC fields and MARCEdit’s RDA Helper was applied. The records were then imported into our ILS.
- Finally, the Excel spreadsheet was used as a checklist to ensure barcodes and spine labels were placed on the correct books.
Using MatchMarc
MatchMarc is free and publicly available. It can be obtained by going to the “Add-ons > Get add-ons” menu in any Google Sheet. A search for MARC will show the add-on:

Figure 1. Screen-shot showing the icon for MatchMarc.
Once installed and launched, the user will see an “OCLC Lookup” sidebar.
The add-on sidebar gives a field for an OCLC API Key to be entered. If you need a key, click on “Request a Key” on the WorldCat Search API page.
The sidebar is also used to indicate which tab contains the ISBN and LCCN numbers and which tab contains the matching criteria. This allows the user to work in one spreadsheet using multiple tabs. Clicking the “Start Search” button initiates the search.
To help first-time users get started with the add-on the side bar provides a button labelled “Click to initialize sample tabs.” This will generate two tabs: one with a few test searches and a second tab with sample matching criteria. It is important that the match criteria tab is laid out in this format because it is coded to look in specific rows and columns.
A feature we added in the latest release of the add-on is the ability to have a MARCXML file emailed to you that will contain all of the records it considered a ‘match’. To receive the email, the user can enter an email address in field labeled “Create MARC record file and mail to” before clicking the “Start Search” button.
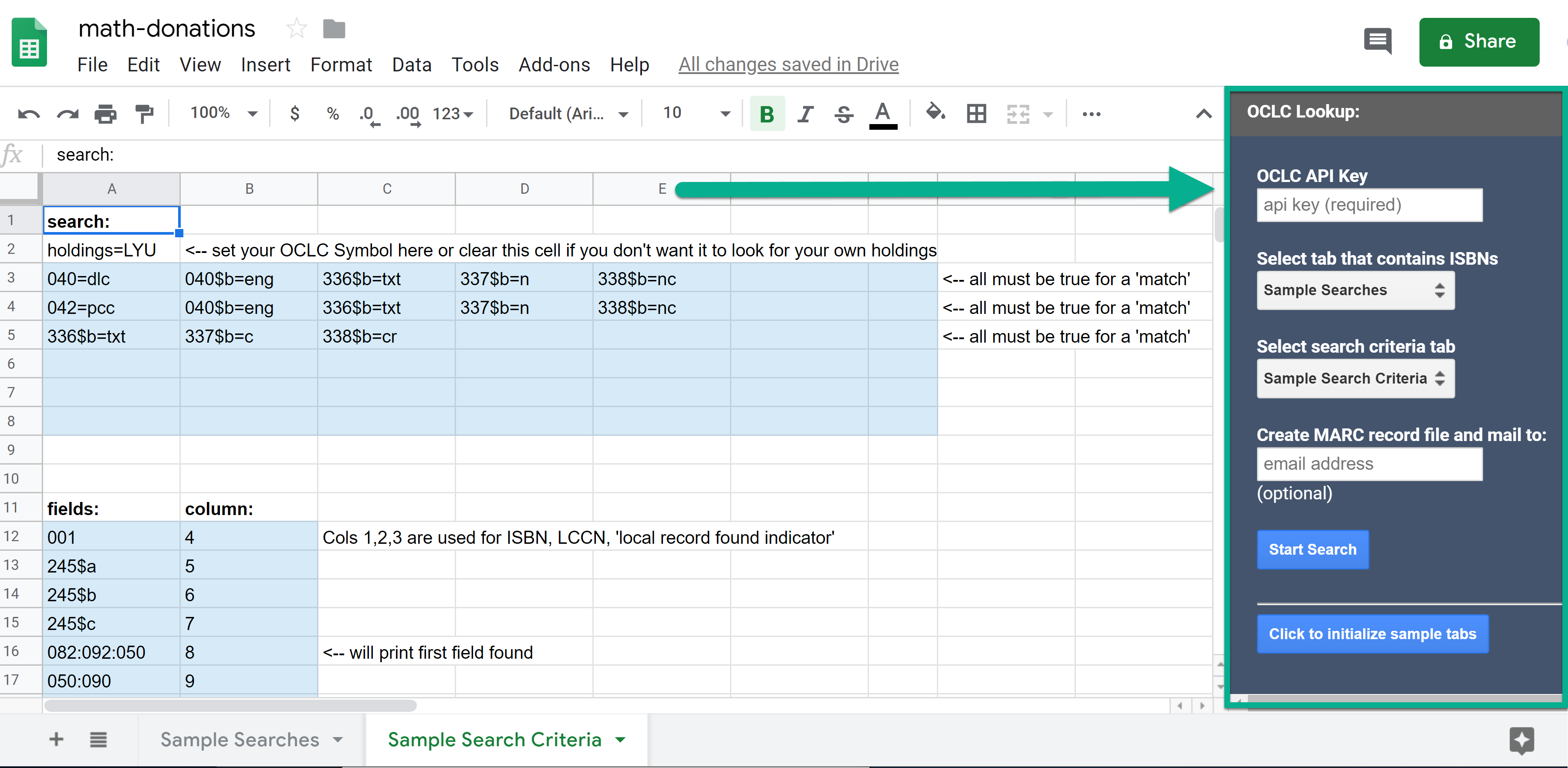
Figure 2. Screen-shot illustrating the Google Sheets add-on pointing out the sidebar where the API key is entered, tab selections made and email address entered.
MatchMarc operates using two tabs inside a Google Sheet.
The first tab is a place to input the information for the records that need to be searched. It expects Column 1 to contain an ISBN. If it doesn’t find anything in Column 1, it looks in Column 2 for an LCCN:

Figure 3. Screen-shot illustrating the search criteria (ISBN or LCCN) in the first two columns of the Google Sheet.
The second tab contains the matching criteria. On this tab the user can indicate whether or not a search for local holdings is needed. If configured this way, attempting to find local holdings will be the first API call it makes. If it finds a record, it writes the results to the spreadsheet. Otherwise, it makes a second API call instructing the API to return results sorted by the number of library holdings. When it gets those results it starts at the top of the match criteria (in the second tab) to try to detect the preferred record.

Figure 4. Screen-shot illustrating the Google Sheets tab that contains match criteria.
When the add-on finds a record where all of the match criteria in one row is found, it considers that record a match and writes the record details into the first tab.
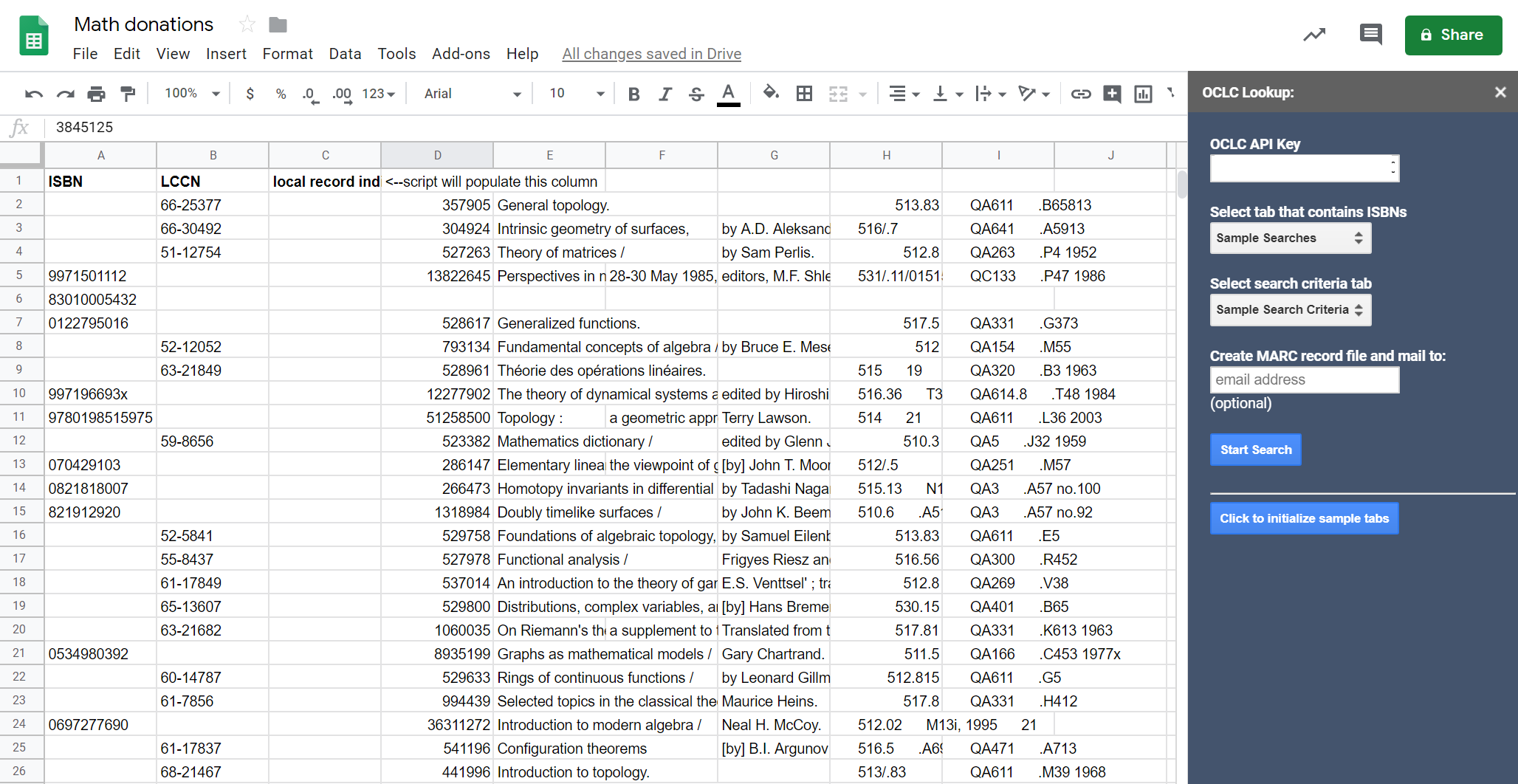
Figure 5. Screen-shot illustrating the record details added to the spreadsheet.
The desired bibliographic details from the MARC record that are written to the spreadsheet are also configurable in the lower part of the second tab.
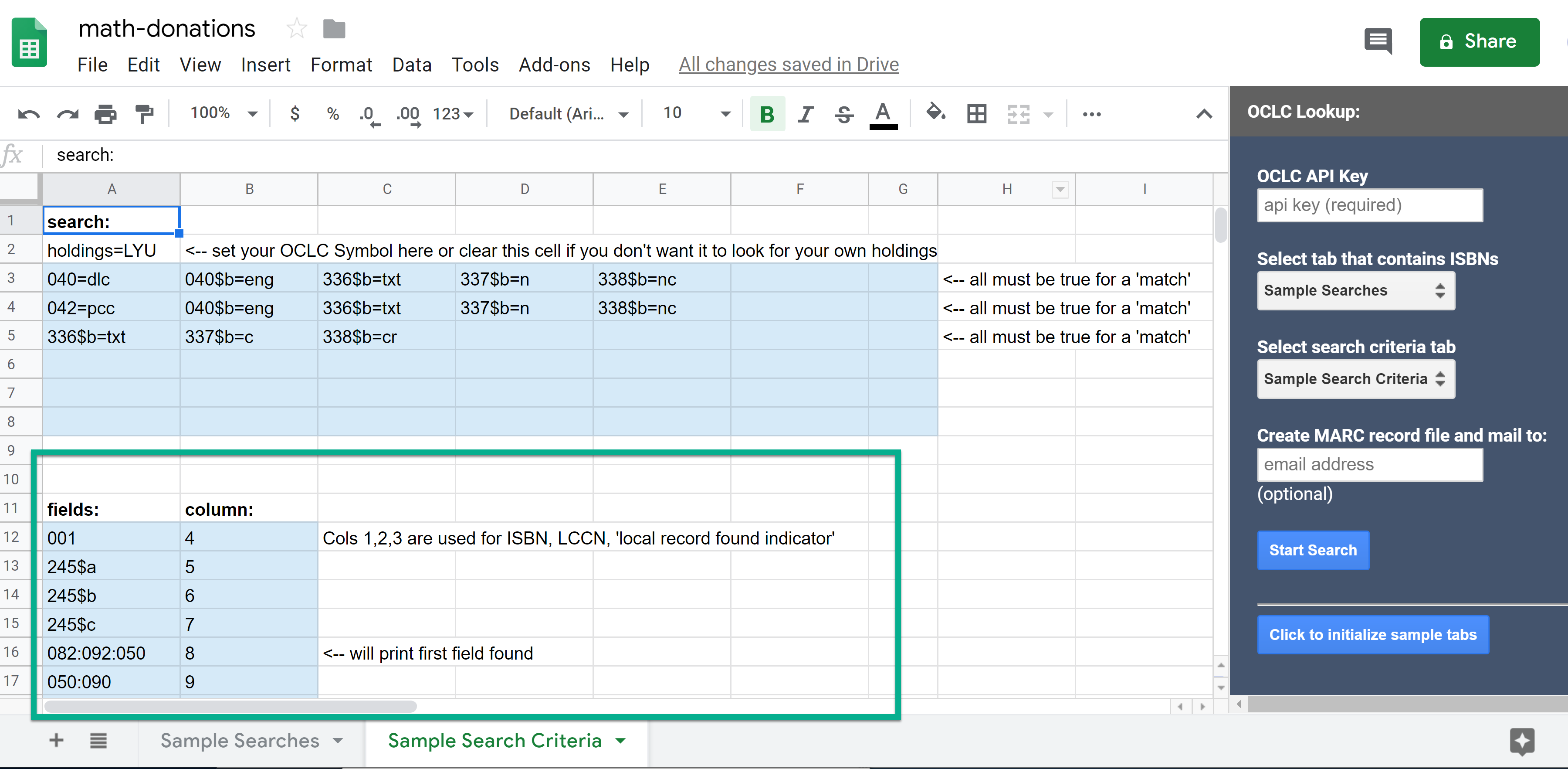
Figure 6. Screen-shot illustrating the Google Sheets tab that contains match criteria calling out the section of the tab where you configure the fields you want written to tab #1.
The add-on will compare the values in each row until it finds a match. If it does not find a match based on the set criteria it defaults to the record with the highest number of holdings.
Limitations
One limitation to using the Google Sheets Add-ons platform is the execution time limit of 10 minutes. This add-on was developed for a cataloging project that leant itself well to smaller batches of lookups. When we tried to apply the add-on to a large list of ebooks supplied by a vendor, we ran into the time limit problem.
Another limitation is its reliance on ISBNs or LCCNs. This is very effective if a list of these numbers is provided, or if the user has monographs with ISBNs that are embedded in scannable barcodes. When ISBNs are not located in a barcode that can be scanned, the user can enter the numbers manually. We have found that even this method is a time saver over a manual lookup. Many older monographs may not contain an ISBN or LCCN, thus making the add-on unusable in these situations. At times the ISBNs are incorrect, or duplicated. These cases, however, are relatively rare and can be detected with proper checks in place in the workflow.
Plans for Development
One exciting development that is planned for MatchMarc is that it will have the ability to take MARC fields and subfields and their values that a user adds to the results spreadsheet and apply them to the appropriate MARC record. When the MARC file is delivered by email, it will contain the full OCLC records with fields that were added to the Google Spreadsheet added to each MARC record. The field values can vary from record to record. This development arose from the fact that in our current workflow for the LUAG project, we add local information, like barcodes, call numbers, and local notes, directly on the spreadsheet. After receiving our emailed file of MARC records from OCLC, we use MarcEdit to turn the spreadsheet into a MARC file, then transfer that local information that was originally in the spreadsheet to the OCLC records, using MarcEdit’s merge function. Once all of the information is in a single MARC file, the file can be uploaded into our ILS, populating the holdings and item record with the appropriate information. This planned development will enable us to skip the steps of transforming the spreadsheet to MARC, then merging the files. We are hoping this will be useful for our daily acquisitions processes, since a “best” record could be found at the point of order by the add-on and the acquisitions data for that order could move from the spreadsheet to a delivered MARC file seamlessly.
Also planned is a new application that will use Google Sheets in the same way but will exist outside of the Google Add-ons platform. This will provide a way to work around the execution time limit while continuing to leverage the advantage of managing the match criteria and lookup values inside of a Google Sheet. We believe that expanding the functionality in this way will be useful for processing the large lists of ebooks we receive from vendors.
The complete source code for this project can be found here: https://github.com/suranofsky/tech-services-g-sheets-addon
About the Authors
Michelle Suranofsky (mis306@lehigh.edu) is a Senior Analyst on the Library Technology team for Lehigh University.
Lisa McColl (lim213@lehigh.edu) is a Cataloging/Metadata Librarian for Lehigh University.
References
[1] OCLC Developer Network [Internet]. Dublin (OH): OCLC Headquarters; [cited 2019 Sept 30]. Available from: https://www.oclc.org/developer/develop/web-services/worldcat-search-api.en.html
[2] Solla, Nancy [Internet]. [updated 2019 May 14]. Ithaca (NY): Cornell University Library Technical Services’s Batch Processing Unit; [cited 2019 Sept 4]. Available from: https://confluence.cornell.edu/display/tsawg/Library+Services+Tools
[3] Sugiyama, Yukari [Internet]. [updated 2019 Mar 29]. GitHub; [cited 2019 Sept 9]. Available from: https://github.com/ysugiyama3/backlog_lookup
[4] Extending Google Sheets with Add-ons [Internet]. G Suite Developer; [cited 2019 Sept 30]. Available from: https://developers.google.com/gsuite/add-ons/editors/sheets

Subscribe to comments: For this article | For all articles
Leave a Reply