by Erin Wolfe
Introduction
The Black Book Interactive Project (BBIP) is a grant-funded collaborative research project conducted by the History of Black Writing program (HBW) at the University of Kansas (KU) [1]. HBW has its origins in 1983 as an effort to compile a comprehensive bibliography of novels by African American authors, and it has continued to evolve into the present [2]. Since its inception, the main objective of HBW has been to increase the visibility and accessibility of these literary works for use in research, teaching, and other scholarly uses. BBIP’s focus is on computational access to works by “writers from underrepresented communities, most [of whom] are unknown and understudied” for use in digital humanities and digital scholarship projects [3].
In an attempt to increase the number of African American writings being studied and taught as part of the traditional African American canon [4], and specifically, the types of digital humanities research being done using these, HBW has been working since 2012 on developing a digital library of lesser known works by African American authors. The University of Chicago has been a primary partner in this, providing digitization services, OCR cleanup, and an interactive web interface using their existing Philologic software to provide access and cross-text searching capabilities [5]. This ongoing partnership has so far produced more than 1,500 digitized novels, with cleaned OCR for over 900 texts.
The primary goal of BBIP is to make these texts available for scholarly use, increasing their visibility by juxtaposing them against more well-known writings. However, more than simply providing access to the texts, BBIP wants to actively create avenues for discovery – “to engage in quantifiable analysis from a qualitative interdisciplinary perspective, identifying the specific properties of fictional data, authorship and epitextual elements that make the African American novel a distinctive cultural, linguistic and aesthetic practice.” [6] Through detailed data about content and context, BBIP hopes to bring forgotten and overlooked texts to light. By making this additional information available online, users will be able to use precise searching and filtering techniques, as well as some cursory data mining tools to uncover works relevant to their area of interest.
Metadata
Much of the information that BBIP aims to capture is not easily mapped to currently accepted metadata standards for bibliographic information and is generally outside of the purview of traditional cataloging. Some of these features are explicitly race-related, such as the ethnicity of the protagonist, or whether the text is set against socio-racial themes. Others are traditionally important in the study of African American literature, such as the setting of the novel, or primary themes in the text. Still other features serve as important historical context and avenues for further study, such as the literary predecessors and successors of the novel, or how the novel was received when it was published.
To this end, HBW received a grant from the National Endowment for the Humanities in 2014 to facilitate the development of a custom metadata schema that considers race as a central thematic characteristic and to complete a pilot project to create records for a sample of these novels. With the help of partners including consultants from the KU Libraries and KU’s Institute for Digital Research in the Humanities, and African American scholars from a variety of institutions, HBW developed a metadata template containing more than 50 elements that provides a means to capture these details in a systematic and structured way. HBW has since received additional grants to facilitate the creation of additional records and to fund scholars’ research using the materials [7].
The process of metadata generation is largely a manual one. BBIP staff members (primarily a mix of doctoral, graduate, and undergraduate students) might employ any of the following methods: skim reading or close reading sections of the text (e.g. to determine narrative voice and thematic elements), keyword searching (e.g. to identify specific subjects, locations, etc.), general web searches (e.g. to find biographical information about the author), targeted online research (e.g. to find published book reviews in contemporaneous newspapers), among others.
The thoroughness of this approach is the only realistic way to achieve the level of specificity desired by BBIP for this material. However, the manual nature does not lend itself well to scalability. First of all, the process is resource intensive (staff could spend as many as 4-6 hours on a single book). Furthermore, the application of the steps involved are not always applied in a systematic way, varying on factors such as inconsistencies in keyword search terms, online venues searched, or even the reviewer’s perception of the text [8].
Code/scripting
In an effort to see how computational tools might help BBIP staff with aspects of the metadata collection, members of the KU Libraries have developed several scripts, primarily using Python libraries, that can perform some targeted tasks, including natural language processing (NLP), text analysis, and harvesting open source data.
Extratextual information from Wikidata
To gather extratextual information about the author, we developed a script to query Wikidata for author entries and harvest relevant data points when possible. Wikidata serves as a structured linked open data source for the Wikimedia sites and is comprised of primary entries containing properties (represented by a ‘P’ number) and an associated value (represented by a URI based on either (a) a ‘Q’ number that identifies a Wikidata entry, or (b) a external linked data resource), returned as JSON from the API [9].
| Property | Value |
| P106 (occupation) | poet (https://www.wikidata.org/wiki/Q49757) |
| novelist (https://www.wikidata.org/wiki/Q6625963) | |
| civil rights activist (https://www.wikidata.org/wiki/Q1021386) | |
| P172 (ethnic group) | African Americans (https://www.wikidata.org/wiki/Property:P172) |
| P244 (Library of Congress authority ID) | https://id.loc.gov/authorities/n79076619 |
| P4823 (American National Biography ID) | https://doi.org/10.1093/anb/9780198606697.article.1600069 |
Table 1. Sample properties for author James Baldwin (Q273210)
Beginning with a list of author/title combinations, we query the Wikidata API for author name matches. To disambiguate the query results, we filter the returned values by checking the description property for keywords, such as “writer,” “novelist,” or “author.” From the filtered results, we use the pywikibot Python package [10] to parse the potentially complex JSON to look for property P214 (Virtual International Authority File (VIAF) ID). We then query the VIAF API and retrieve the associated list of works by that author and compare it against our initial entry. If the title of our initial inquiry is in the VIAF bibliography, then we can assume with a high degree of certainty that we have an accurate match and can then use pywikibot to harvest other relevant fields from the Wikidata entry (11 fields in all, including birth place, dates of birth and death, occupation, education, and more) and write them into the local metadata for that item.
Additionally, we can use the title list from VIAF to expand a bibliography of related works that may be used for further digitization possibilities, reference for researchers, or other future needs. The Wikidata process is imperfect, as it requires the author to have entries in Wikidata and VIAF that meet the criteria above; however, we have so far achieved about 47% total successful matches (32% successful for unique authors). Improved results could likely be achieved through further data cleanup or enhancement, such as adding birthdates from external sources or manual review to check for possible formatting differences. In addition, identifying gaps in Wikidata sources can provide an opportunity for BBIP to contribute missing information back to Wikidata as we discover it.
Identification of specific topics
One area targeted for textual analysis by BBIP is the identification of specific topics within a text. For example: Does violence play a role in the text? How is it depicted? To test with improving efficiency and scope of the manual review process, KU Libraries developed a script that evaluates the entirety of the text for the presence of a given topic and outputs a web page with relevant details for review.
This process utilizes NLTK’s WordNet corpus – a widely-used lexical database that semantically relates words based on their meaning, or “sense.” From an input word, WordNet returns one or more possible senses of that word, called synsets (Figure 1). WordNet consists of over 117,000 synsets that are enhanced with additional information, such as definitions, example usage, lemmas, part of speech, and more. These senses are interlinked through a number of conceptual relationships, such as synonymy or hyponymy (general-to-specific meanings), among others [11].

Figure 1. WordNet’s definitions of the term “music” (enlarge)
Beginning with a manually generated list of keywords related to a specific topic, we filter all of the WordNet-returned synset/definition pairs to ensure that only the senses that we want are included. Any senses that do not fit the desired topic are excluded, leaving only the synsets that match the topic for which we are evaluating. This review step is a manual process that only needs to be completed once but can be refined at any time. For example, see WordNet’s available senses for the term “music” (Figure 1): to exclude the definition “punishment for one’s actions” (e.g. “face the music”), the synset identifier “music.n.05” is simply excluded from the final list [12].
From this list of initial synsets, we use WordNet’s relationships to build an active thesaurus of related senses. This is primarily done via the hyponym function (i.e., recursively collecting increasingly specific terms, such as ‘animal’ -> ‘domestic_animal’ -> ‘dog’), as this provides more precise sense matches.
| Base term | Initial keyword list | WordNet hyponym synsets |
| Music | 46 | 1618 |
| Violence | 53 | 1879 |
| Religion | 58 | 1814 |
Table 2. Sample of expanded sense vocabulary using WordNet
With this expanded list of synsets as our base, we pass every word in the text through an algorithm in WordNet called lesk, which determines a likely meaning for the word given the context in which it appears [13]. WordNet returns the lesk-generated synset, which is checked against our list of topic synsets, with positive matches recorded for later review. Using this sense-based method, we can evaluate each individual word for meaning, rather than relying on keyword matches. At the end of the script, all positive matches are converted to an ordered html table, which can then be manually reviewed by BBIP staff to make a determination on what should be recorded in the metadata record.

Figure 2. Snippet of HTML output of sense matching, from Checkmate and Deathmate, by Martin Ashley (1973) (enlarge)
Additional functions
Identification of locations
African American scholars have long identified setting and location as important elements of African American literature, with deep potential for research and for understanding the cultural context of African American literature [14]. Named Entity Recognition (NER) is a common task in NLP which extracts specific names and concepts from the text – commonly persons, locations, organizations, etc. Using a combination of BookNLP (a pipeline of NLP tasks designed to work with long texts) [15] and LitBank (an annotated dataset and neural network model for tagging entities in literature) [16], we can extract location information in a few different ways to allow the researcher a focused lens through which to view these elements of the text. First, we can group the cities, states, countries, and other locations mentioned in the text.
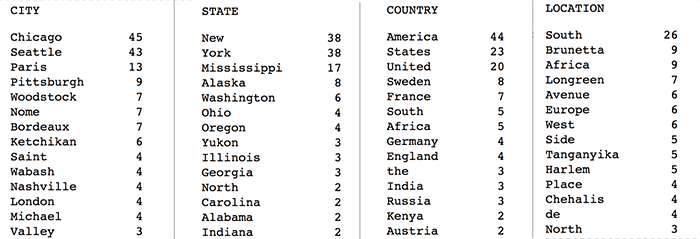
Figure 3. Sample of locations grouped by type, from Long Old Road, by Horace Cayton (1965) (enlarge)
Second, we can group locations according to the 2005 Automatic Content Extract (ACE) guidelines [17], which categorizes locations by conceptual type – specifically, (1) geo-political entity (a place with a population, physical or political boundaries, etc.), (2) location (a physical place without a political entity), and (3) facility (a man-made structure or place with a functional use). One of the features that makes LitBank an excellent tool for this type of material is that it is trained to recognize literary language and can capture not only short entities like “Egypt” and “the palace,” but also longer phrases like “the ancient cities of Egypt” and “the illustrious house of the Pharaohs.” As before, all of these grouping methods are output to an HTML file for review by BBIP staff or researchers.

Figure 4. Sample of locations grouped by ACE guidelines, from A Waif–A Prince; or, A Mother’s Triumph, by W.T. Andrews (1895) (enlarge)
Automated keyword extraction
There are a number of NLP methods to automatically extract keywords from a text, ranging in approach and effectiveness depending on the tool used and the type of text in question. When dealing with a novel, this process can become difficult. Keyword extraction in short texts, such as news articles or user reviews, is often reliant on specific word usage; however, in a novel, key themes often develop over the course of the work without ever being explicitly named. Some NLP tools give less common words a heavier weight in determining their importance, resulting in proper names dominating the results of early testing. Topic modeling can be a useful approach when working with groups of texts with distinctive topics referencing distinctive words. However, our experiences with topic modeling failed to produce any notably accurate or useful results. Again, this may be due to the lack of explicitly stated keywords.
Better results for our purposes were achieved using the RAKE (Rapid Automatic Keyword Extraction) libraries [18], which tends to capture potentially interesting textual aspects of the work without necessarily identifying thematic elements. For this project, these results are grouped and output to an html file for review. Further refinement could be done using a similar WordNet/lesk approach as described above, and then mapping identified synsets to a lexical type (or lexname).

Figure 5. Sample keyword extraction using RAKE, from Long Old Road, by Horace Cayton (1965) (enlarge)
Matching with HathiTrust holdings
Another prospect being explored by KU Libraries is the identification of titles in the BBIP digital collection that are also held by HathiTrust, a process which could allow researchers to make use of the HathiTrust Research Center’s computational analysis tools to examine BBIP texts [19]. This is done through matching on author/title combinations using the HathiTrust bibliographic metadata set and retrieving the HathiTrust identifier [20]. This process involves significant data cleanup (due to formatting variations between the sources) and then comparing results to find very close matches [21]. Since the HathiTrust data file is very large (nearly 17 million items), precise matching can be labor intensive and requires iterative adjustments to the input strings. Current mapping efforts are achieving about 50 percent success, and efforts to improve this are ongoing.
Conclusion
There have been a number of challenges using computational text analysis tools with the BBIP texts. This was not unexpected, as many accessible NLP tools are not currently well-designed for the specific types of information that BBIP is looking at. In addition, the BBIP novels themselves contain characteristics that are relatively unique, such as the inclusion of regional dialect in a long text format. Although vernacular has been a subject of some NLP exploration, particularly in modern day AAVE (African American Vernacular English) and social media usage, we have not yet been able to find a reliable method for handling dialect from an NLP perspective as applied to 19th and 20th century novels [22]. However, we have been successful in our primary goal, which is to provide methods to help BBIP staff or researchers extract specific types of information from a text, as well as harvesting open data from external sources, and to provide this data in an easy-to-access format. Neural networks and transformers are currently the state-of-the-art approach for many NLP applications, and we are testing a few different models (including word2vec, BERT, and XLNet) for existing and new tasks, including genre grouping, expanding the topic identification method, dialect identification, and others. The fields of natural language processing and machine learning applied to text are growing quickly, with new applications and methods being introduced at a rapid pace, and we plan for our approaches in computational analysis of these texts to keep evolving as well.
About the Author
Erin Wolfe (edw@ku.edu) is the Metadata Librarian at the University of Kansas Libraries. He is active with the Black Book Interactive Project and is interested in text mining, computational humanities, machine learning, and related areas.
References
[1] Black Book Interactive Project homepage: https://bbip.ku.edu/ ; History of Black Writing homepage https://hbw.ku.edu/
[2] For a full timeline of HBW, see https://hbw.ku.edu/timeline
[3] BBIP Statement of Humanities Significance: https://bbip.drupal.ku.edu/humanities-significance
[4] According to Dr. Maryemma Graham, head of the HBW, fewer than eight percent of known African American texts are included in the traditional canon of African American literature.
[5] History of Black Writing Novel Corpus at the University of Chicago, public/beta version: https://textual-optics-lab.uchicago.edu/black_writing_corpus
[6] BBIP Statement of Innovation: https://bbip.drupal.ku.edu/statement-innovation
[7] BBIP received the NEH grant in 2016. In 2018, BBIP applied for and received an additional grant from the American Council of Learned Societies (ACLS), which allowed for continued progress in refining the metadata schema, collecting data for additional works, and funding a program to allow a group of scholars to access and use these materials in their research. See https://bbip.ku.edu/project-updates
[8] Although outside the scope of this case study, it should also be noted that, since some of the metadata is collected manually from historical sources, the availability of this information relies on those sources themselves being findable and accessible. Several invaluable resources for finding contemporary book reviews or related information have been found, but the amount of resources that are not available electronically is unknown.
[9] Wikidata:Introduction: https://www.wikidata.org/wiki/Wikidata:Introduction . There are a number of online GUI tools to help identify which of the over 6,500 Wikidata properties might be relevant to a specific data set, such as Wikidata Propbrowse – https://tools.wmflabs.org/hay/propbrowse/
[10] Pywikibot usage with Wikidata: https://www.wikidata.org/wiki/Wikidata:Pywikibot_-_Python_3_Tutorial/Data_Harvest
[11] For more about WordNet, see https://wordnet.princeton.edu/. For usage of WordNet in NLTK, see https://www.nltk.org/_modules/nltk/corpus/reader/wordnet.html.
[12] This manual process is generally effective but not particularly flexible or efficient. Current tests are underway to examine the feasibility of improving this process using word2vec or neural networks. Several recent articles describe current efforts using neural networks that show promising developments in this area. C.f., Y. Levine, B. Yoav, et al. “SenseBERT: Driving Some Sense into BERT” (August 2019): https://arxiv.org/abs/1908.05646v1 ; C. Hadiwinoto, H. T. Ng, & W. C. Gan. “Improved Word Sense Disambiguation: Using Pre-Trained Contextualized Word Representations” (October 2019): https://arxiv.org/abs/1910.00194v1
[13] The lesk algorithm is useful but limited, relying on trained word order and co-occurrence and using the WordNet definitions to determine usage and meaning. In practice, this produces a number of false positive and false negative results, requiring human review to obtain fully trustworthy results. See previous note for future directions.
[14] C.f., Nunlye, V. L. “From the Harbor to Da Academic Hood: Hush Harbors and an African American Rhetorical Tradition” (2004) in Richardson, E.B. & Jackson, R.L. (Ed.) African American Rhetoric(s): Interdisciplinary Perspectives. Carbondale: Southern Illinois University Press.
[15] David Bamman, Ted Underwood and Noah Smith, “A Bayesian Mixed Effects Model of Literary Character,” ACL 2014.
[16] David Bamman, Sejal Popat and Sheng Shen, “An Annotated Dataset of Literary Entities,” NAACL 2019.
[17] C.f., Linguistic Data Consortium “ACE (Automatic Content Extraction) English Annotation Guidelines for Entities,” 2008. https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/english-entities-guidelines-v6.6.pdf
[18] C.f., RAKE (Rapid Automatic Keyword Extraction) library in Python: https://github.com/vgrabovets/multi_rake
[19] HathiTrust Research Center: https://analytics.hathitrust.org/
[20] Data files are updated regularly and can be downloaded from HT: https://www.hathitrust.org/hathifiles
[21] Currently, best results are achieved by measuring the Jaro-Winkler distance between strings using the Jellyfish library.
[22] C.f., A. Jørgensen, D. Hovy, & A. Søgaard. “Learning a POS tagger for AAVE-like language,” Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, p. 1115-1120. (2016) https://www.aclweb.org/anthology/N16-1130.pdf

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply