by Lukas Koster
Persistent identifiers: the basics
What is a persistent identifier?
There are a number of definitions of persistent identifiers available that differ in two ways: the nature of the objects to be identified, and the extent of persistence.
Here, a persistent identifier is understood as a “unique universal persistent identifier”. An “identifier” is a string used to refer to an object. “Unique” means that the identifier is only used for one object. “Universal” entails that the identifier is valid for the whole of the world or world wide web. “Persistent” means that the identifier remains available independently of individual institutions, systems or system implementations.
In actual practice a PID has two functions:
- Uniquely identifying an object
- Making available an object and/or information about that object on the web.
The process of generating PID’s is also known as “minting”.
Physical and digital objects?
Some definitions state that PID’s always refer to digital objects, such as the one in the Digital Preservation Handbook by the Digital Preservation Coalition: “A persistent identifier is a long-lasting reference to a digital resource.” [1] (also used by ORCID [2]) and the Dutch PIDwijzer (PID Guide) website: “A Persistent Identifier (PID) is a unique identification code attached to a digital object and registered at an agreed location.” [3].
However, a PID can also refer to physical objects and abstract concepts. English Wikipedia [4] (contrary to Dutch Wikipedia [5]) states: “A persistent identifier (PI or PID) is a long-lasting reference to a document, file, web page, or other object. The term “persistent identifier” is usually used in the context of digital objects that are accessible over the Internet”.
DOI’s (“Digital Object Identifier”), a well known and much used PID system, can be used for “any entity — physical, digital or abstract” [6]. A DOI is a “Digital Identifier of an Object”, not an “Identifier of a Digital Object” [7].
Example: a PID can be assigned to a physical museum object like a vase (a unique item). A digital representation of the object can also have a PID assigned, but that PID does not refer to the original physical object. The physical object’s PID does not identify it’s digital representation, although usually that representation will be shown when the physical object’s PID resolves to a web page describing the physical object, including, among others, location metadata.
Universality
A persistent identifier’s universality implies that the identifier is unique within the known universe, or the world. For practical reasons this means that the identifier is unique within a specific context. Because the uniqueness of identifiers without context cannot be guaranteed, PID’s are assigned within specific “web namespaces” administered by an institution, such as uva.nl, doi.org, handle.net. This is called the PID-URI. A single string can occur more than once, but only once within a reserved namespace, which makes that string unique. In case several institutions have the right to assign identifiers within a specific namespace, then these institutions are assigned a code of their own that is also part of the total identifier string. The actual single code is unique for the institutional code within the namespace. The institutional code is often called a “prefix”, the actual code a “suffix”. This approach makes it possible for existing identifiers, for instance internal system identifiers or other PID’s, to be used as suffix.
Persistence
“Persistent” as a rule is defined as “permanent”, “everlasting”, “eternal”. In reality this is not possible. A PID only continues to be unique and usable as long as somebody assures that to be the case. Usually it is an institution that administers identifiers and guarantees their uniqueness within a unique namespace on the web. For example: DOI 10.1109/CCGRID.2018.00098 is unique within the doi.org namespace, and the referenced object can be found via the PID-URI https://doi.org/10.1109/CCGRID.2018.00098. If the International DOI Foundation would cease to continue the doi.org domain name/namespace, the object in question could no longer be found via the identifier. The actual identifier string 10.1109/CCGRID.2018.00098 would by itself no longer be guaranteed to be unique on the web, although it could still be.
As mentioned before, English Wikipedia defines a PID as “a long-lasting reference to a document, file, web page, or other object”, where “long-lasting” is a relative concept. Other mentioned definitions have taken over the term “long-lasting”. Alternatively, instead of “persistent”, the term “persistable” is used in order to indicate that an effort is needed to keep identifiers unique and usable.
Resolution
Persistence not only refers to the continued existence of the identifier itself, but also to the continued findability and accessibility (usability) of the identified object on the web. A location independent PID on the web also performs the function of resolution, the translation to the actual location on the web, the Uniform Resource Locator (URL [8]), where the object in question is described and findable. The aforementioned DOI for instance refers to https://ieeexplore.ieee.org/document/8411085/. The technique of handling this resolution is called “redirection”. Whenever an object is described on a different web address (URL) than before, the PID-URI will have to redirect to the new location. This always requires administration activity.
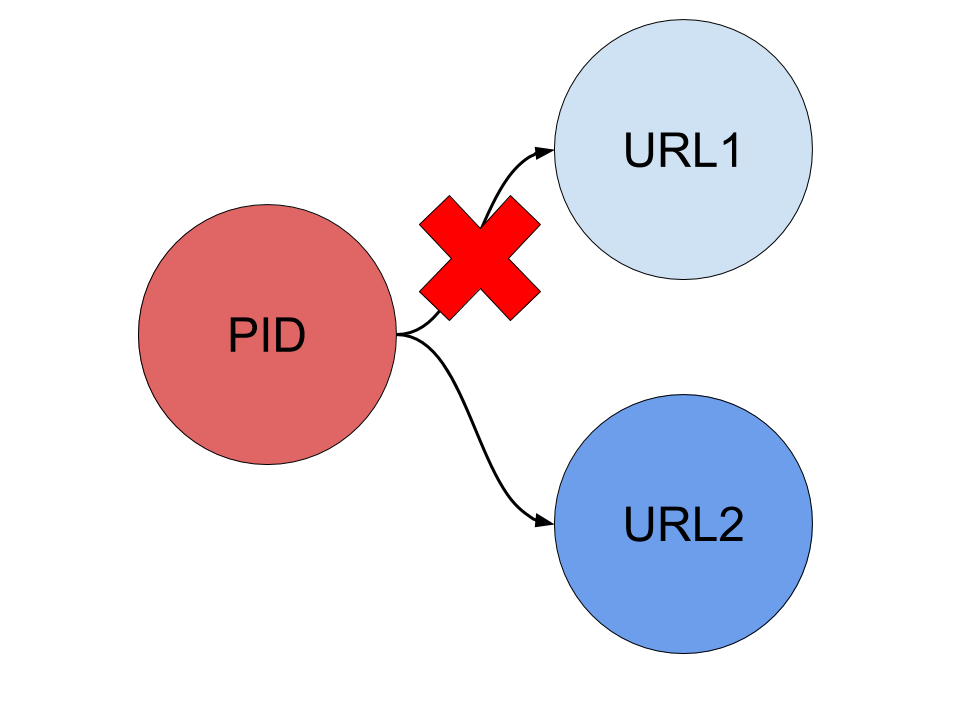
Figure 1. Redirection adjustment
The standard method of resolving PID’s is to employ a mapping table, in which for every PID-URI a target URL is recorded. Alternatively “rule based mapping” can be used, where base URL and the target URL’s syntax are dynamically generated by applying a template, pattern and/or a regular expression and adding the distinctive identifier. This is only possible if the old identifier is available in the new system or if a mapping table of old to new system identifiers is available, and if this identifier can be used in a query.
Administration
It should be clear that both persistence and resolution are only guaranteed by virtue of permanent administration. Somebody (usually an institution) has to guarantee the continued existence of the identifiers and the maintenance of up to date resolutions to the actual locations of the objects in question. Occasionally this can cause the implementation of major adjustments, for instance in the case of a system migration, where base URL and system identifiers of all records are changed.
Permalinks
“Permalinks” are often mistakenly regarded as persistent identifiers. Generally this term is used for the direct URL’s pointing to metadata records in a specific installation of a specific system. A permalink is always a full URL containing an internal system identifier generated by the system itself. The internal system identifier is only valid and unique within a specific system installation. After migration to a different system the old “permalink” will no longer work, unless redirection to the URL’s in the new system is possible. For this some mapping between old and new system identifiers is required.
Types of PID systems
An institution can choose to develop and administer its own PID system, or use a ready made, externally provided and administered system. The difference is that external PID systems are maintained and administered by a third party (usually for a fee), and that the third party guarantees the persistence and uniqueness of the identifiers. The correct redirection remains the responsibility of the institution itself, for instance in the case of system migration. Local administration will still be necessary.
PID systems have been around since the mid 1990’s. In everyday practice a limited number of external PID systems are used: NBN, Handle, DOI, ARK, PURL. See for instance Hilse and Kothe [2006].
The PID systems described below are characterized by type (PID/PID-URI/URL), responsibility for minting, assigning, resolving and server administration, and rule based mapping options. The level of responsibilities is indicated. “Local” means that the institutions are themselves fully responsible. “Central” indicates the dependency of a global entity. In some cases there is a certain distribution of responsibilities between “central” and “local”.
NBN
Type: PID
Syntax: urn:nbn:[country code]:[institutional code]-[pid-suffix]
Organisation registry: National (National Libraries)
Minting: Local
Assigning: Local
Persistence: National
Resolving: National: PID-URI = [national resolver URL]/[NBN]
Server admin: National
Rule based mapping: No
NBN’s (National Bibliographic Number) are administered by a number of national libraries [9], such as the German National Library, the Royal Library of Sweden and the Royal Library of The Netherlands. Resolving of NBN’s is handled on the national level. NBN makes use of the URN (Uniform Resource Name) mechanism [10]. An NBN consists of the protocol string “urn:nbn:” followed by an ISO two character country code, an institutional code prefix and an “assigned NBN string”, the actual identifier string or suffix. Existing identifiers can be used as assigned NBN strings.
Example: urn:nbn:nl:ui:29-8f66e0a8-b7c9-40a4-be28-54a7c01770, which identifies an article published in the repository of the University of Amsterdam. In this case the suffix 8f66e0a8-b7c9-40a4-be28-54a7c01770 is identical to an internal system identifier (UUID) of the repository system.
NBN policy differs per country. In The Netherlands affiliated institutions can assign NBN’s themselves if they comply with certain conditions referring to the repositories that digital objects are stored in [11]. The repository system for instance has to be a “Long Term Preservation Depot” approved by the Royal Library Registration Agency. This means that in The Netherlands NBN’s can only be assigned to digital objects.
Because a URN is not a URL, redirection of NBN’s has to go through a special resolving server. In The Netherlands this is taken care of by the DANS [12] administered server at http://persistent-identifier.nl/. The example: https://www.persistent-identifier.nl/urn:nbn:nl:ui:29-8f66e0a8-b7c9-40a4-be28-54a7c0177061.
For Germany and Switzerland that is https://nbn-resolving.org.
In The Netherlands NBN is a free service.
Handle System
Type: PID
Syntax: [naming authority code].[sublevel(s)]/[pid-suffix]
Organisation registry: Central (DONA)
Minting: Local
Assigning: Local
Persistence: Central
Resolving: Central/Local: PID-URI = https://hdl.handle.net/[handle]
Server admin: Local
Rule based mapping: Yes
Handles are internationally unique identifiers within the Handle System under responsibility of the DONA Foundation [13]. Handles can be assigned and administered decentrally by naming authorities. A handle consists of a prefix indicating the naming authority, and a “local name” or suffix, the unique identifier string within the context of the naming authority. This suffix can be an existing identifier. Handles can be administered by naming authorities in their own local handle servers for specific prefixes. The Global Handle Registry serves as an intermediate conduit for these local servers. Prefixes can have hierarchical levels for layered naming authorities, which are divided by a dot (“.”).
Handles are independent of the DNS architecture and URL syntax, but they can be resolved on the web via the Global Handle Resolver hdl.handle.net. Example: https://hdl.handle.net/11245.1/8f66e0a8-b7c9-40a4-be28-54a7c0177061, which refers to the same article as mentioned in the “NBN” paragraph before. Again, in this case the “local name” is identical to the internal UUID identifier of the repository system.
Handles can be assigned to any type of object. A single handle is a mapping between a handle identifier and the target URL of a specific object. In the case of a physical object that would be a “landing page”, containing at least a description of the object. Handle supports an elementary form of “multiple redirection”, which entails conditionally selecting a URL from a list, based on “id”, “country” and “weight” [14]. There are also “template handles”, for dynamically generating redirects based on regular expressions and patterns instead of one to one mappings for each handle.
Naming authorities are charged a one time and an annual fee per prefix. Currently this is $50 [15] for both.
DOI System
Type: PID
Syntax: 10.[registration agency code].[sublevel(s)]/[pid-suffix]
Organisation registry: Central (IDF), Nodes
Minting: Nodes: Registration Agencies
Assigning: Nodes
Persistence: Central
Resolving: Central: PID-URI = https://doi.org/[DOI]
Server admin: Nodes
Rule based mapping: No
DOI’s (Digital Object Identifier) [16] are based on the Handle System. The DOI System is administered by IDF (International DOI Foundation). DOI’s are assigned by decentralized DOI Registration Agencies (RA), like DataCite (mainly focused on research datasets) [17], Crossref (mainly focused on scholarly publications) [18] and Zenodo (focused on open science scholarly output) [19].
A DOI, like a handle, consists of a prefix for the “registrant” and a suffix as unique identifier within the prefix. And just like handles, prefixes can have a hierarchical subdivision. DOI’s always start with an extra prefix “10” for IDF as highest handle naming authority. Registrants are represented by the second prefix level, after the “10”, for instance Zenodo is 10.5281. Existing identifiers can be used as suffixes.
DOI’s are resolved through the global DOI server doi.org, for instance https://doi.org/10.14742/ajet.4926, which again refers to the above mentioned article, in this case as published in a specific journal. Because DOI’s are handles, they can also be resolved through hdl.handle.net: https://hdl.handle.net/10.14742/ajet.4926. And vice versa.
DOI’s can be assigned to any type of object: physical, digital, abstract.
DOI offers “multiple resolution” [20], making use of handle “multiple redirection”. The DOI Handbook explicitly states that this mechanism can be used for linked data content negotiation [21] (see below).
Institutions pay the Registration Agency in question a fee per registered DOI or per prefix, depending on the RA’s conditions. For instance DataCite DOI’s are created by DataCite members [22], such as figshare [23]. Institutions can become a DataCite Member or cooperate with an existing DataCite Member.
ARK
Type: PID
Syntax: ark:/[name assigning authority number]/[pid-suffix]
Organisation registry: Central (California Digital Library)
Minting: Local: Name Assigning Authorities (NAA)
Assigning: Local
Persistence: Local
Resolving: Local: PID-URI = [local resolver URL]/[ARK] / Central: https://n2t.net/[ARK]
Server admin: Local
Rule based mapping: Yes (via NOID for instance)
ARK (Archival Resource Key) [24] is a protocol for persistent identifiers including resolving for various types of “information objects”: digital, physical, abstract, people, institutions. ARK is developed and maintained by the California Digital Library. Currently a project is carried out to transfer administration to an international community [25].
A founding principle of the ARK is that persistence is purely a matter of service (Kunze and Rodgers, 2018). This leads to three requirements: an identifier gives access to
- “A promise of stewardship”
- A description of the identified object (metadata)
- The object itself, or a copy of it, if possible
In the ARK protocol an identifier is an association between a string of data and an object, so not just a string.
ARK’s are assigned by Name Assigning Authorities (NAA), that all have a Name Assigning Authority Number (NAAN). These NAA’s are maintained in a central registry [26].
An ARK consists at least of three mandatory parts: the string “ark:/”, the NAAN, and the “name” (the actual identifier or PID within the NAA context, the suffix). Again, existing identifiers can be used for the Name/suffix part. An example: ark:/12148/cb406766211. The “ark:/” part is necessary, because there is no global ARK resolver (similar to NBN’s “urn:nbn:”).
An implicit hierarchical subdivision can be applied, without using dots (“.”) as separators. This can be used to indicate for instance sub-naming authorities and specific repositories (Peyrard et al. 2014). In practice up to the first five characters of the actual identifier suffix (“name”) are used for this purpose. This “sub-namespace” part is also called a “shoulder” [27]. There is no fixed syntax rule for this option. In the example ARK given here, the “cb” part of the name/suffix indicates the shoulder.
A “Name Mapping Authority Hostport” including “http(s)://” can be added to make the ARK “actionable” (resolvable on the web), for example this catalogue record of the National Library of France (BnF): https://catalogue.bnf.fr/ark:/12148/cb406766211. The NMAH is not part of the ARK identifier. The NMAH is variable and can be changed. Several NMAH’s can be used for the same ARK, for instance to present an object in different systems, such as a catalogue or a repository. Example:
- https://catalogue.bnf.fr/ark:/12148/cb406766211 (in the BnF catalogue)
- https://data.bnf.fr/ark:/12148/cb406766211 (in the BnF linked data server)
Furthermore, a “qualifier” can be added following the “Name”. Qualifiers can indicate hierarchies by means of a slash (“/”) (for instance parts or pages), or variants by means of a dot (“.”) (for instance different formats, languages or versions). Qualifiers can in theory be used for linked data content negotiation, for instance by adding variants like “.rdf”, “.ttl”, etc. (Peyrard et al. 2014).
The NMAH should support the three basic ARK requirements using THUMP (“The HTTP URL Mapping Protocol”). In this protocol appending a question mark (“?”) to a URL means a request for the description (metadata) of the identified object, and appending two question marks (“??”) means a request for the “promise of stewardship”. Example:
Object: http://texashistory.unt.edu/ark:/67531/metapth346793/
Description: http://texashistory.unt.edu/ark:/67531/metapth346793/?
“Promise”: http://texashistory.unt.edu/ark:/67531/metapth346793/??
In practice this is not always possible, because a question mark is standard syntax for adding a query parameter to a URL, which may cause conflicts in the web server used. In any case, the ARK identifier has to resolve to at least the identified object. If there is no local ARK resolver available, there is always the global Name-to-Thing (N2T) resolver n2t.net, for instance http://n2t.net/ark:/12148/cb406766211.
There is a tool that can generate unique ARK strings (but also other identifiers like handles and DOI’s): NOID (Nice Opaque IDentifier) [28]. NOID can also be used as local resolver that can provide rule based mapping besides standard redirection [29].
It is also possible to manage and store ARK’s using the EZID service [30] provided by CDL. Depending on institution type an annual fee of $300 – $1500 is required.
A financial contribution is not required for acting as a Name Assigning Authority.
PURL
Type: PID-URI/URL
Syntax: [PURL resolver base URL]/[name]
Organisation registry: Central (Internet Archive)
Minting: Local
Assigning: Local
Persistence: Central
Resolving: Local/Central
Server admin: Local/Central
Rule based mapping: Partial URL
PURL (Persistent URL) is a resolution and redirection service for web resources. It was originally developed and administered by OCLC. In 2016 the maintenance was taken over by The Internet Archive [31]. PURL uses standard HTTP redirect services by means of standard HTTP status codes [32]. PURL’s are full URL’s, of which the base-url can be purl.org, purl.net, purl.info, purl.com. Institutions can create and administer their own PURL’s for their own domain.
The default and most used form of redirection is by means of the status code 302 (Simple redirection to a target URL). Example: http://purl.org/dc is redirected to https://www.dublincore.org/. Besides the HTTP status code there is also a “partial PURL” which will match the beginning of a URL and append the remainder to the end of the resolved URL, for instance http://purl.org/dc/elements/1.1/: http://purl.org/dc/elements/1.1/#terms-abstract, http://purl.org/dc/elements/1.1/#terms-title, etc.
PURL’s are not persistent identifiers by themselves, but they can be used as such. There is no rule based mapping other than the partial PURL option.
Private PID’s
Type: PID/PID-URI/URL
Organisation registry: Local
Minting: Local
Assigning: Local
Persistence: Local
Resolving: Local
Server admin: Local
Rule based mapping: Optional
Institutions also have the option of creating their own private PID’s. This implies that an institution has a tool at its disposal to generate unique identifiers within a specific namespace as well as a tool for resolving and redirecting these private PID’s by means of PID-URI’s to the actual URL’s of the identified objects. Most heritage and scholarly collaboration platforms only advocate the existing global PID systems Handle and DOI and don’t mention private PID systems. The Dutch PIDwijzer site even discourages the use of private solutions [33] because these would be less robust, reliable and durable and more costly and laborious than existing global PID systems, but that is debatable. Many heritage and educational institutions will very probably have a considerable future life before them, including their namespaces on the web. As far as costs and laboriousness are concerned, external PID systems also require a considerable maintenance effort, just like private systems.
An advantage of private PID systems is more flexibility in policies, applications and redirect options.
One option for generating private PID’s is using UUID’s as suffix. UUID (Universally Unique IDentifier) [34] is an identifier independent of a central authority. A UUID is a 128 bit number consisting of 32 hexadecimal digits in five groups separated by a hyphen. UUID’s are generated based on a specific algorithm. There are five versions, based on date/time/MAC-address, namespace/name or random. A UUID by itself is not a PID. There is no prefix/namespace context.
UUID’s are widely used, for instance in the PURE repository system mentioned in the examples before. The suffix 29-8f66e0a8-b7c9-40a4-be28-54a7c0177061 is a UUID. A UUID is not resolvable as such, it is only an identifier. UUID’s can be made resolvable by using a resolver and redirection mappings, like in handles, DOI’s, ARK’s or any other method, for instance the MuseumID PID system [35]. The MuseumID has two URN components based on UUID’s, the Museum Namespace (MNS) and the Museum Object Identfier (MOI).
| System | Type | Registry | Mint | Assign | Persistence | Resolve | Server admin | Rule based |
|---|---|---|---|---|---|---|---|---|
| NBN | PID (+ PID-URI) | National | Local | Local | National | National | National | No |
| Handle | PID (+ PID-URI) | Central | Local | Local | Central | Central/Local | Local | Yes |
| DOI | PID/PID-URI | Central/Nodes | Nodes | Nodes | Central | Central | Nodes | No |
| ARK | PID | Central | Local | Local | Local | Local | Local | Yes (NOID) |
| Purl | PID-URI/URL | Central | Local | Local | Central/Local | Central/Local | Central/Local | Partial url |
| Private | PID/PID-URI | Local | Local | Local | Local | Local | Local | Optional |
Typology of PID systems
Object types eligible for PID’s
Unique items, scholarly output
It is self-evident that institutions in principle only assign PID’s to objects they own or administer themselves. For these objects a distinction can be made between unique and non-unique items, and between institutional and external output. For all objects owned, administered and published elsewhere PID’s should be assigned by the appropriate institutions.
- Unique items
- Museum objects, manuscripts, research datasets etc.
- Copies of editions in itself not unique, but made unique by coloring, annotations etc.
- Non-unique items
- Objects published in large editions (books, articles, etc.)
- Institutional output
- Scholarly output by the institutional staff (books, dissertations, articles, chapters, datasets, presentations etc.). Because these objects are usually published in large quantities, they also count as “non-unique items”.
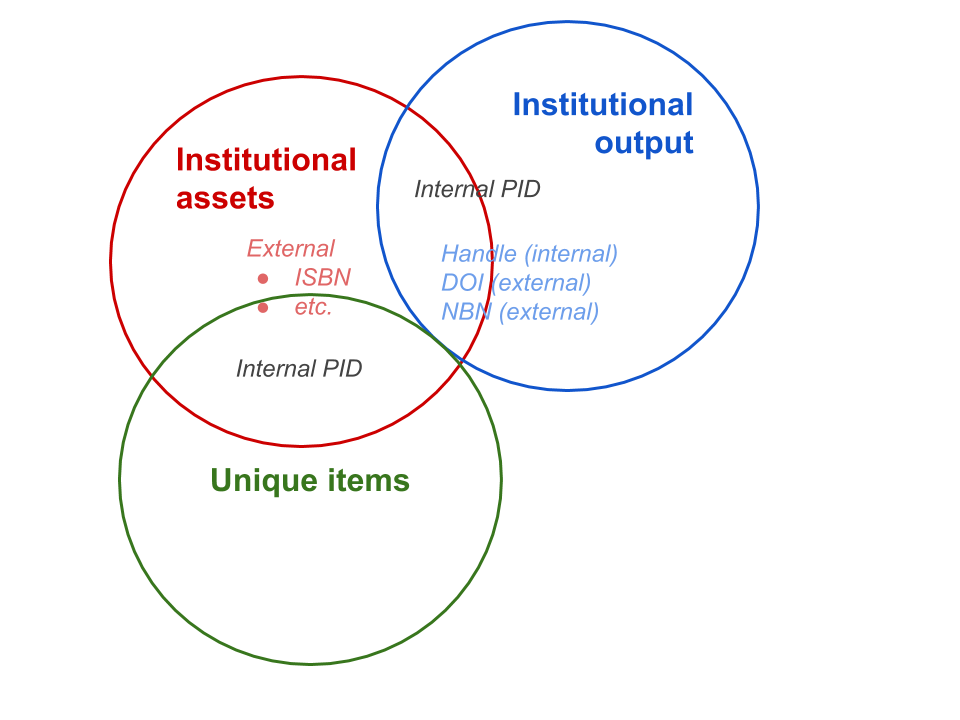
Figure 2. Overlap of item types
Institutions themselves are the appropriate authority for assigning PID’s to their own unique objects. It is standard practice that PID’s are assigned to scholarly output published in institutional repositories too, even if they also have an externally assigned PID, like a DOI for articles published in a journal. Non-unique objects owned or administered by the institution can be referenced by already available identifiers. Books for instance usually have an OCLC WorldCat number and/or ISBN on the FRBR Manifestation level.
Physical/digital
The basic rule is that a PID is assigned to the original object (“non-information resource” in linked data terms), either physical or digital.
One or more digital copies or versions of a physical object may be available. As a rule these digital versions are not assigned their own PID’s. There should however be some kind of relationship defined between the original object and its digital copies.
It is customary that a physical object’s PID resolves to a description of that object on the web (in linked data terms an “information resource”), including at least information regarding its current location and access options and optionally representations of the available digital versions. If possible also the web locations of these digital versions should be given (Van de Sompel et al. 2014).
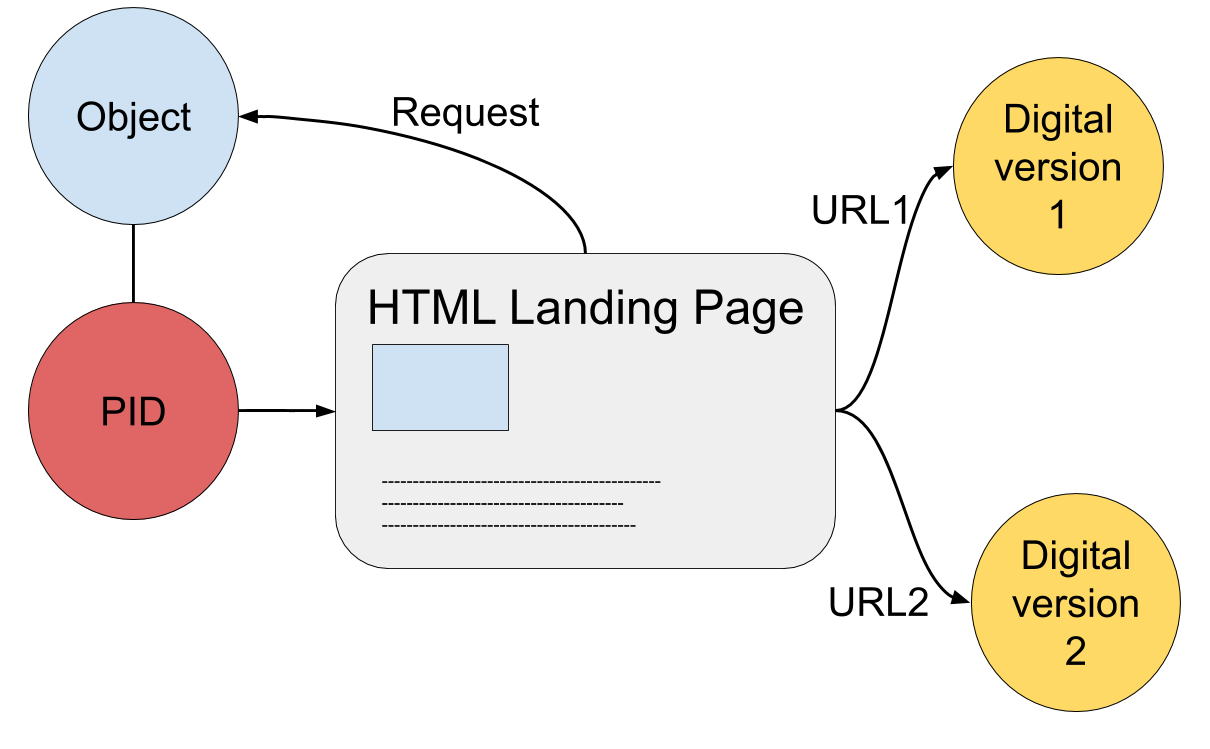
Figure 3. Source object and digital representations
The Europeana Data Model (EDM) provides for this basic situation [36]. An original object is described as a “ProvidedCHO”, where “CHO” stands for “Cultural Heritage Object”. Digital versions of it are “WebResources”. Both object types can have their own specific metadata and licenses. A ProvidedCHO and its WebResources are related by means of an “Aggregation” that can have its own metadata.
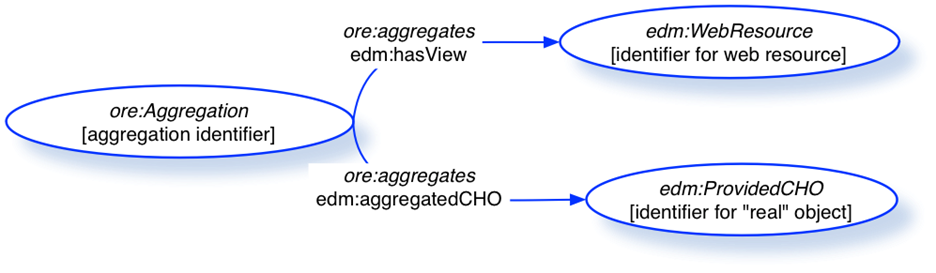
Figure 4. EDM Cultural Heritage Object model
In traditional MARC, still used in most library systems, this is a bit more problematic, because of the fixed flat record structure. One possibility is to use MARC 856 tags (“Electronic Location and Access”) with available indicators and subfields [37]. A disadvantage of this method is that it does not provide an opportunity for recording metadata (format, resolution, etc.) and license information for the digital versions. This problem can be countered by creating separate MARC records for digital versions. In this case these digital object records must be linked in some way to the original object record. The transition to BIBFRAME may solve this.
Special cases
Just a little bit unique
The above mentioned distinction between unique and non-unique objects is in reality not as rigid as it seems. In this case it concerns objects published in various volume sizes, with or without small differences, for example etchings, engravings, lithographs, old maps. With this type of objects multiple prints are made from one source (plate, stone etc.), of various quality caused for instance by tear and wear. Plates used for etchings and engravings can have multiple versions (“states”) with adjustments made on the original plates. This has happened a lot with old maps, which are in general copper engravings. The printed images were published and sold in various ways: separately, as part of a book or atlas, etc. The original prints are always in black and white, but individual copies were often hand colored. A single image can have many different copies.
A heritage institution may have multiple identical or varying copies of a printed object in its possession. The question is how to catalogue these different versions and if they all deserve their own PID. Are they to be regarded as unique works in their own right, or as different manifestations or even as multiple copies of one work or manifestation? The answer depends on the intended or actual usage of these objects. If the individual copies are treated as unique objects or individual works, then they deserve their own PID’s. How to resolve these PID’s is a different story. In any case there should be a web resource for the copy in question, for instance a descriptive page or a digital representation or similar.
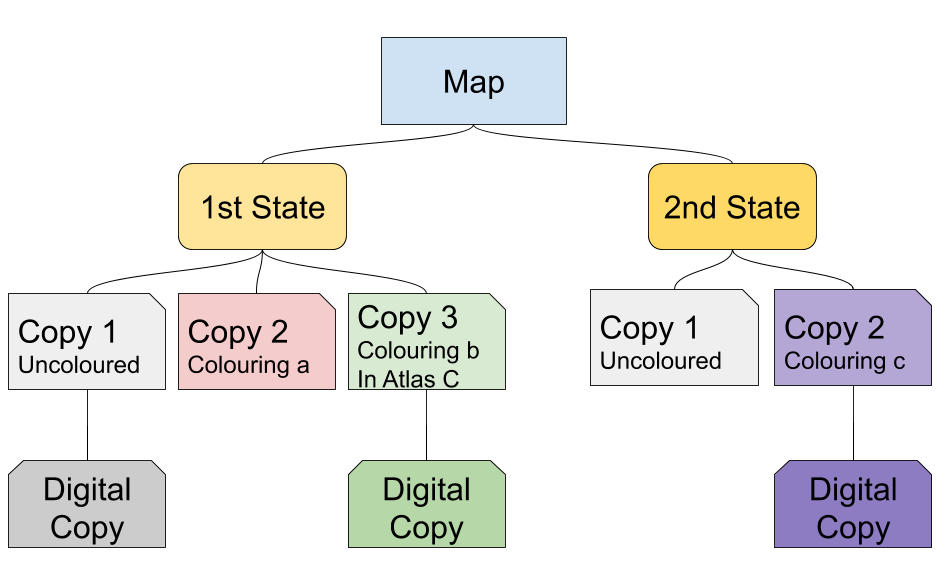
Figure 5. A map and its possible versions
The individual copies should be linked to each other in one way or another, as different versions of one source object. This can be achieved in a number of ways in catalogues and metadata.
Whole/part
Often objects are part of a bigger entity, or they can be divided into smaller parts themselves. Examples are:
- Archive – sections – objects
- Book – chapters
- Serial – volumes
- Wall map – separate sheets
Similarly the answer to the question on what levels PID’s are appropriate depends on the actual or intended usage.
Digital representations
In some cases it is necessary to use stable URL’s for digital representations of the original object, for instance in case explicit references are made to a specific digital representation with a specific resolution, if they are used in IIIF, or if the objects, or parts of them, are the subject of online annotation tools.
Versions of objects
In some PID systems it is not allowed to change the objects that are referenced. Usually this situation does not apply to physical objects, except possibly in the case of damage.
But for texts or datasets for instance this is a real possibility. Generally speaking every single version must be assigned a new PID. One option is to extend the original PID with a version numbering suffix. The original PID can refer to the most recent version. This would in fact mean that the PID does not refer to one and the same object in a persistent way.
Alternatively new PID’s can be assigned to every new version, so the original PID keeps pointing to the original object as it was at the time of assignment (Van de Sompel et al. 2013).
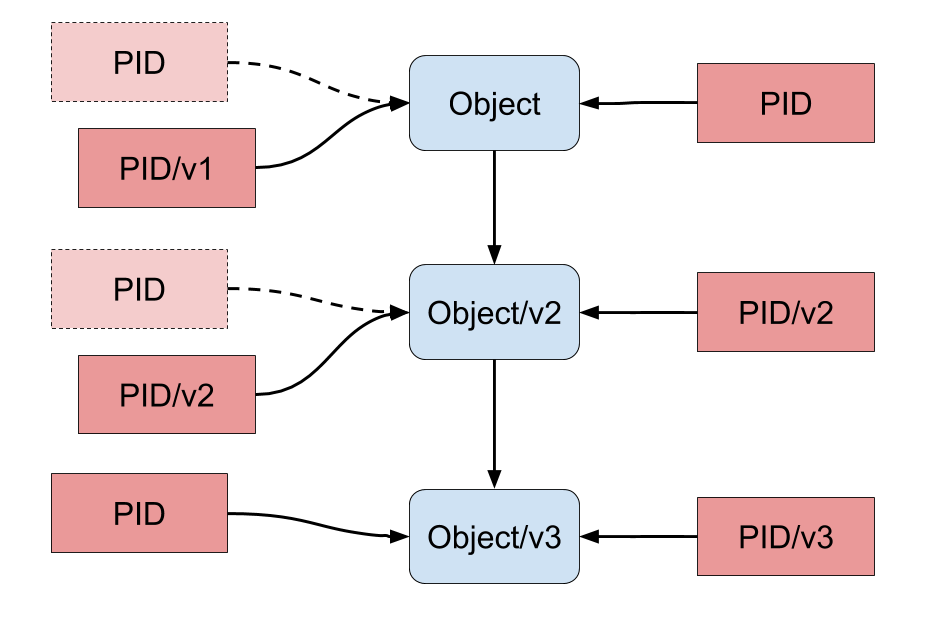
Figure 6. Object versions and the PID versioning methods (“v1” – “v3” = “version 1” – “version 3”). Timeline is from top to bottom. Left: PID refers to most recent object version, older versions get new PID’s. Right: PID refers to original object version, every new version gets new PID.
PID’s and Linked Data
Linked Data is a way of linking structured data in different datasets to each other by means of identifiers in order to present enriched information both for human use and for software processing (usually described as “machine readable”). The basic methodology consists of “triples”, where two things are related to each other, ideally presenting both things and the relationship as special PID-URI’s, HTTP URI’s [38]. Furthermore “content negotiation” is used to redirect these URI’s to either a human interface (like a web page) or a machine readable dataset in the RDF format, or to the object itself in the case of a digital object. Redirection of a URI/URL to a specific representation of the object is called “dereferencing”.
An example of such a triple:
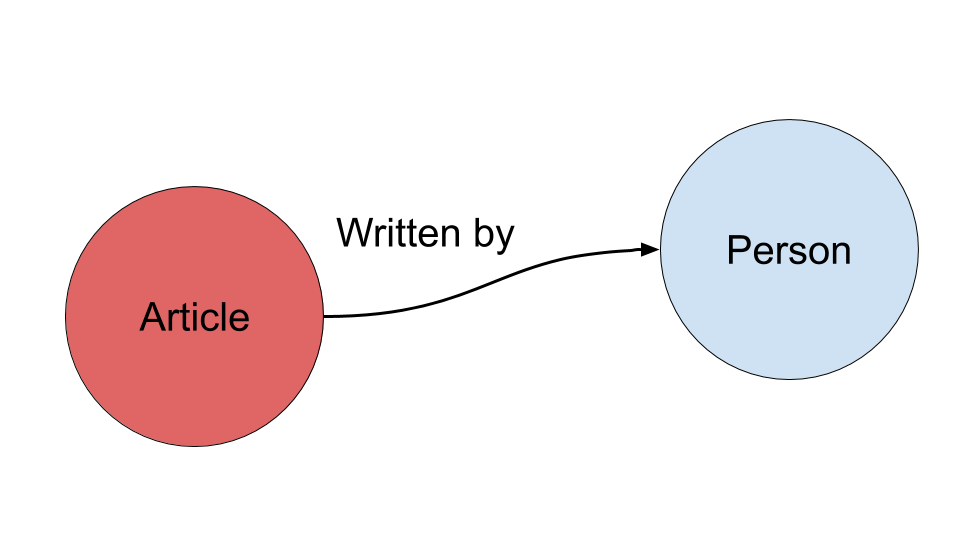
Figure 7. A triple
https://hdl.handle.net/11245.1/8f66e0a8-b7c9-40a4-be28-54a7c0177061 (an article)
http://purl.org/dc/elements/1.1/creator (written by)
https://orcid.org/0000-0001-8795-6838 (a person)
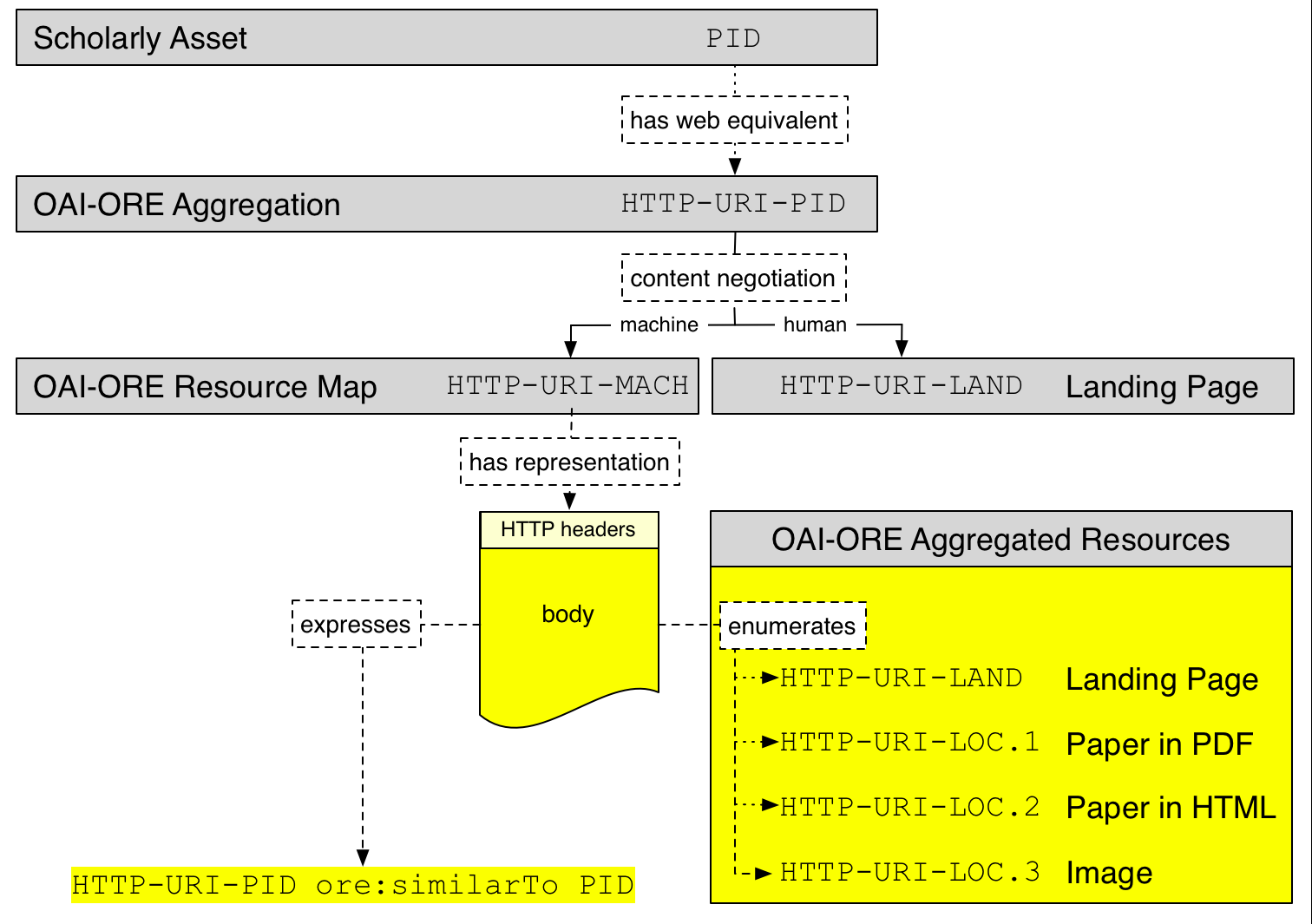
Figure 8. Content negotiation (Van de Sompel et al., 2014). HTTP-URI-PID = resolvable form of the PID; HTTP-URI-LAND = human readable web resource; HTTP-URI-MACH = machine actionable web resource; HTTP-URI-LOC = various end targets of the identified object
URI’s
A URI (Uniform Resource Identifier) is a unique identifier [39]. URI’s exist in two forms: URN (Uniform Resource Name) and URL (Uniform Resource Locator).
URN
A URN is a unique identifier in a specific namespace or URI scheme. URN’s do not have to comply to a specific protocol and do not have to be resolvable on the web. It is not a “locator”. URN’s can be monitored and guaranteed by central authorities, such as urn:issn and urn:isbn. Some PID’s are in the form of URN’s: urn:nbn. URN’s can be made resolvable by dedicated resolvers such as is the case with NBN.
URL
A URL is a unique identifier resolvable on the web and always leading to a web resource on a specific web server. URL’s use various protocols: http, ftp, mailto, etc. URL’s always contain a physical location on the web in the form of a hostname. HTTP URI’s are essential for Linked Data. The above mentioned PID systems that essentially don’t use the URL syntax (except PURL) can be expressed as URL’s by prefixing the PID’s with “http://” or “https://” and the hostname of the resolver. For instance https://hdl.handle.net/11245.1/8f66e0a8-b7c9-40a4-be28-54a7c0177061 for the handle 11245.1/8f66e0a8-b7c9-40a4-be28-54a7c0177061.
PID’s as Linked Data HTTP URI’s
In order to be used as a Linked Data identifier in RDF a URI has to comply with a second condition besides resolvability: content negotiation (so, selecting the representation to be delivered based on context). The described PID systems were not originally designed to do that. Handle, DOI and ARK have mechanisms that might be used for it, but these appear to be too basic to configure this in a satisfactory manner. DOI’s are not very suitable because the infrastructure is administered completely by an external party. In case the selected PID system cannot be used for content negotiation, additional functionality will have to be developed separately. With private PID systems content negotiation functionality can be part of the development.
Existing infrastructures and PID’s
Most heritage institutions will have at least one cataloguing system in which their collections’ items are described. These cataloguing systems either have an integrated or a separate end user interface used for presenting and making available the collection items on the web. Depending on the nature of the institution and its collections these systems can be focused on publications, physical artefacts or archived items, all with their own specific features. Many institutions have a combination of these collection types, possibly extended with repositories for digital objects. Research institutions will also have research information systems with integrated or separate repositories for scholarly output and research datasets. Many academic libraries will have all of these types of collections and systems to administer.
In many cases items are described in more than one institutional system, either by copying or by duplicate cataloguing. Metadata from many institutional systems are also harvested and published in all kinds of national and global aggregator portals. Scholarly output in the form of articles are also published and described in e-journals and e-journal aggregators.
Across this variety of digital heritage infrastructures many different PID policies can be found. PID’s may or may not be assigned to all objects or to only a subset. PID’s may be available for objects in specific systems only, but not in other systems the objects are described in. PID’s can be managed in a full mapping table or dynamically generated using rule based mapping. PID’s based on existing global systems can’t be used for publishing collections as linked data. Objects may have multiple PID’s (a local handle, a national NBN and a DOI). PID’s may be assigned to digital versions only instead of their original physical source objects.
An appropriate PID infrastructure
Based on the options of the described PID systems and the potential shortcomings of PID usage in existing infrastructures a list of requirements for PID systems can be drafted. The list can be used to formulate recommendations for specific activities regarding implementing PID’s.
Requirements for PID systems
- It must be possible to assign PID’s to objects of all kinds (physical, digital, abstract)
- Institutions must be able to generate and assign PID’s themselves
- based on existing internal system identifiers
- based on existing PID’s
- as new
- Automatic generation and assignment of PID’s for new objects must be possible
- Batch generation and assignment of PID’s for existing objects must be possible
- Resolving PID’s must be possible
- based on one to one mapping
- based on templates, patterns or rules
- It must be possible to adapt resolver mapping tables in batch
- PID’s must be usable as Linked Data URI’s by means of content negotiation
- It must be possible to store generated PID’s automatically in the object’s source system/database
- if possible as the default internal system identifier
- alongside the default internal system identifier
- It must be possible to copy PID’s from the source system/database to derivative systems/databases
- It must be possible to present PID’s in all relevant public end user interfaces
- It must be possible to publish PID’s in all machine readable interfaces
- It must be possible to retrieve objects and their metadata records by their PID’s in all public end user interfaces
- It must be possible to retrieve objects and their metadata records by their PID’s in all machine readable interfaces
Generating and assigning PID’s
Using more than one PID system does not have to be a problem. It just means more maintenance effort is required. Some PID systems are even administered externally, notably DOI’s for journal articles. If an institution already uses a specific PID system for a subset of its collections, it can extend the system to all of its objects, or decide to deploy a different system. In the later case the existing PID’s must still be maintained.
When implementing a new PID system it has to be decided what the basis of the new PID’s will be: new or existing identifiers. New identifiers can be generated based on UUID’s, the default numbering of the PID system itself, other PID systems already in use or a private algorithm. These identifiers can be incorporated as suffix in the PID system of choice.
As an example of using an existing PID system’s PID’s in another PID system: an institution could use an already used handle server to generate new handles, only to be used as suffixes in ARK. The original handles should of course not be published. In this case there is no need for implementing and administering an additional separate PID generator.
All information and cataloguing systems have unique internal system identifiers that can be used in PID’s. These internal system identifiers in a manner of speaking are promoted to PID suffix in the PID system in question and made universally unique. This is by far the easiest solution for implementing PIDs, because these PID’s do not have to be generated and stored separately in the metadata of the source system objects. This method only works if the PID’s can be generated dynamically on the fly using the internal system identifier as suffix by means of rules, patterns or templates. Of course in the case of a migration this method implies that existing internal system identifiers have to be stored as additional queryable identifiers in the new system.
If objects are available in more than one system/frontend, for instance the cataloguing system and a repository, and internal system identifiers are used as PID suffixes, then only one should be used for generating the PID. This is directly related to resolving PID’s (see below). It depends on the context of the institutional infrastructure which system will be leading.
Storing PID’s
In the case of using internal system identifiers PID’s do not have to be stored in an object’s metadata at all. But when creating PID’s using new external identifiers (UUID’s, existing PID’s, private algorithms), these PID’s do have to be stored separately. It depends on the cataloguing systems if and how this is possible. Library systems using MARC can use the MARC 024 tag (“Other Standard Identifier”) [40] to store identifiers. 024 subfield $2 (“Source of number or code”) can be used to record the type of identifier, for instance “doi” for DOI’s, “hdl” for handles. There is a list of standard identifiers [41] available, but systems not in the list can be used too. ARK could for instance be indicated by “$2ark”.
If objects are available in more than one system and internal system identifiers are used as PID suffixes, complete PID’s must be stored in all other systems as well.
Resolving PID’s
Most eligible PID systems have their own local and/or central resolver servers. In the case of a private PID system a resolver mechanism has to be implemented as well. The standard way of resolving PID’s is the use of a mapping table containing a target URL for every PID. This method is certainly usable for generating individual PID’s for new object registrations. The cataloguing workflow in this case should provide for automatic updating of the mapping table. Batch generation of new PID’s for all records of an existing system should be reasonably easy to implement too. But when migrating to a new system that will be a lot harder to achieve. All existing target URL’s in the mapping table will have to be replaced by URL’s pointing to records in the new system. Doing this in batch is only possible if a mapping list of all old system record identifiers and the new system record identifiers is available.
In this case (but also in the other cases) it is much easier to achieve this by one rule based mapping line. For this to be possible the PID’s must be stored and queryable in the new system. Something like:
[PID base-url]/prefix.suffix => [system base-url]?pid_field=[prefix/suffix].
If objects are available in more than one system, only one of these can be configured as target in the resolver. If internal system identifiers are used as PID suffixes, then obviously that system will be the target. In this case links between the objects in all systems have to be available.
ARK provides an alternative: the PID can be prefixed with multiple NMA’s (base-url’s), each requiring its own resolver of course.
PID’s and content negotiation
In order to be able to use PID’s as Linked Data HTTP URI’s the PID system has to support content negotiation. The base-url/hostname for PID’s used as Linked Data URI’s must be immutable (persistent) just as the PID’s themselves. On top of that the base-url server must host a PID resolver that also manages content negotiation. This base-url must not be one used for a specific system/frontend.
One strategy is to use a dedicated hostname for PID’s, like id.institution.org or similar. In this case there are two options. Under this dedicated PID hostname a server can be hosted that will perform full content negotiation including standard PID redirection to a human interface. Or one of the content negotiation options will be forwarding to an external PID system, such as Handle, to perform the actual PID resolution.
Alternatively the external PID system’s syntax, for instance Handle, will be used for everything. The PID resolver then redirects to the institutional content negotiation server, which handles also resolving of the PID to the human interface.
Of course it would be best if all external PID systems would offer content negotiation from the start.
Publishing PID’s
Presenting PID’s in various system end user interfaces should be relatively easy. PID-URI’s must be prominently presented as the proper way to refer to objects or records, instead of the URL shown in the browser bar, which usually shows the system URL with internal identifier.
If internal system identifiers are used as PID suffix, then all records in these systems will have a PID, if they comply to the PID criteria used or not. In this case mechanisms can be applied that the PID’s are only published for objects that deserve PID’s. An additional benefit is that PID’s already exist when these criteria are extended.
Publishing PID’s for machine readable interfaces should also not be a problem, for instance in API’s and as RDF subject URI’s. An alternative method would be to use HTTP headers in the frontends’ HTML pages, like it is done with the Signposting approach [42]. Here Typed Links with relation type “cite-as” are used, for example:
<link href=”https://hdl.handle.net/11245.1/8f66e0a8-b7c9-40a4-be28-54a7c0177061″ rel=”cite-as”>
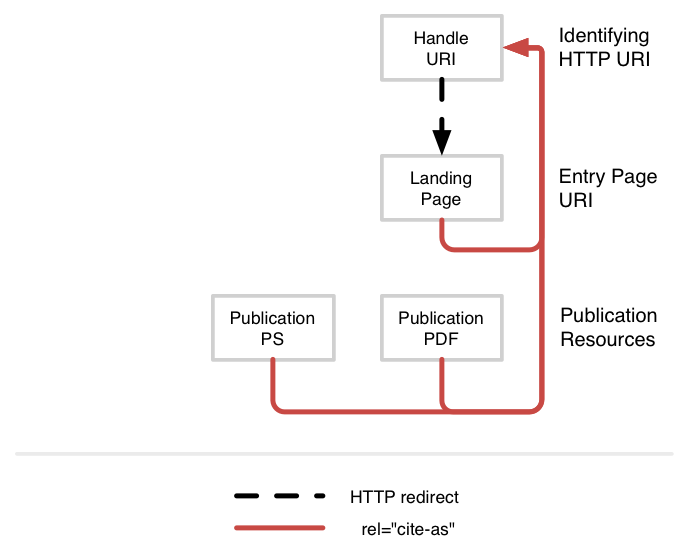
Figure 9. https://signposting.org/identifier/dspace/
Version and representation PID’s
It must be possible to show the relationships between the objects that have a PID assigned and their related versions and representations in the various frontends, using metadata and holdings data. It is important that these relationships are bidirectional, meaning that navigation is possible from object description to representations and vice versa.
Machine readable interfaces should also be able to capture these relationships. Signposting can be used for this too, by means of “collection” and “item” as well as “cite-as” relation types. The HTML page describing the object contains a relation type “item” link for each version representation. The representation HTML page then contains a relation type “collection” link. Additionally a “cite-as” link contains the PID-URI of the object itself.
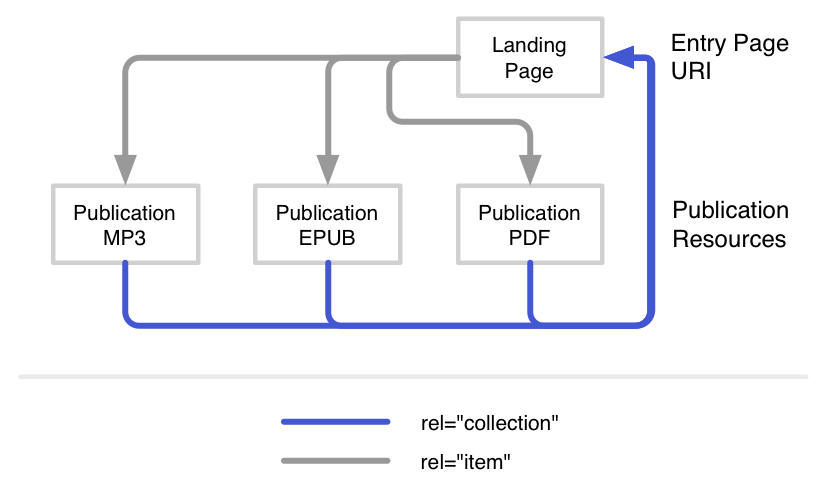
Figure 10. https://signposting.org/publication_boundary/irrodl/
Discussion
What should be done?
In order to improve internal and external interoperability, facilitate linked data and promote the reuse of digital collections, institutions must assign PID’s to all relevant objects. Institutions must define a central policy for using PID’s.
It is vital that already existing PID’s will keep working. Existing PID’s can be integrated in new PID systems.
PID’s must be available in all systems and interfaces (both for human end users and machine readable) used for describing the objects in question.
Institutions have to determine the default web representation of objects with PID’s. All other representations have to be findable from that default representation.
If institutions want to publish collection data as linked data, they should make sure that the PID’s can be used as linked data URI’s.
Options and issues
An easy way of implementing PID’s for all relevant physical and digital objects is to apply rule based mapping, generating PID-URI’s on the fly based on existing internal system identifiers. In practice this is possible with Handle, ARK or private PID’s. Of course the internal system identifiers will have to be migrated to any new system in order for the PID’s to continue to be valid and resolvable.
If there is any chance that existing internal system identifiers are subject to change, then this method is obviously not suitable. The alternative is that for every new record created for “PID worthy” objects in relevant systems an external PID is automatically generated, mapped and stored in the system. In this case rule based mapping can’t be applied. It depends on the system used if this is an option. Home grown and open source systems can and should be extended with the necessary functionality by the institution or the community. Commercial systems do not usually provide this functionality, but it should be or become standard practice.
Even if PID-URI’s are published prominently on web representation pages of objects, the browser address bars still present the actual target URL’s of the redirected PID-URI’s. Many people will store this URL instead of the preferred PID-URI either by actively copying the browser bar URL or by bookmarking a web page, thereby implicitly storing the URL. It seems impossible to eliminate this problem. An alternative solution for bookmarking tools could be that the Signposting “cite-as” relation type is used whenever available.
The institution has to decide on the criteria used for defining which object types PID’s are assigned to, while considering the special cases regarding the various physical and digital representations. Having said this, it would be very useful if institutions could implement existing standard profiles for dealing with PID’s for source objects (both physical and digital) and ways to identify the derived and related digital representations, as well as versions.
To facilitate linked data using assigned PID’s, content negotiation must be available in one form or another, preferably without having to use separate linked data URI’s besides PID-URI’s. In most cases a separate tool will have to be developed or implemented for this. This may involve the decision to use an institutional namespace instead of an existing PID system namespace.
This could be avoided if existing PID systems would support content negotiation as a built-in option. Looking at current developments it is incomprehensible that for instance Handle and DOI do not support full blown content negotiation.
Conclusion
A consistent policy for persistent identifiers for heritage objects is indispensable for institutions that want to streamline their internal digital infrastructure and publish their collections for reuse. The selected PID systems must support content negotiation in order to publish the collections as linked data.
There is not one PID solution that caters for all institutions. There are many dependencies involved: collection management/cataloguing systems, vendors, institutional IT expertise and staff, existing PID systems.
Many collection management systems, commercial and open source, do not provide integrated PID support (generating PID’s and resolvers). This is an issue that heritage institutions and their professional associations should ask vendors/developers to incorporate in their roadmaps.
Existing PID systems do not support content negotiation for linked data implementations. Heritage institutions and their professional associations should encourage PID system administrators to implement this.
Institutions with the appropriate technical ICT expertise, staff and funding can implement their own PID and content negotiation infrastructure, with or without commercial collection management systems.
Even then they have to decide on the best model or topology: which type of objects to assign PID’s to, how to implement the relationships between physical objects and digital representations, etc. Heritage institutions and their professional associations should investigate the possibilities of establishing some kind of shared open repository of standard profiles for implementing PID’s.
It is wise to test a number of different scenarios for various situations. You do not have to select one solution for all types of collections and systems. And it is not necessary to implement PID’s for all collections an systems at he same time. It is better to take small steps.
In any case, institutions must implement the solution that can be administered with the least effort, preferably with as much automation as possible, because only then persistence is feasible.
Acknowledgements
I am grateful to the following people for sharing valuable suggestions and feedback on earlier versions of this article.
- Herbert Van de Sompel (DANS, The Hague, The Netherlands)
- Jasper Bedaux (Library of the University of Amsterdam, The Netherlands)
- Remco van Veenendaal (National Archives, The Hague, The Netherlands)
- Tim Hasler (KOBV, Berlin, Germany)
About the author
Lukas Koster MSc (l.koster@uva.nl) is Digital Infrastructure Coordinator at the Library of the University of Amsterdam (UvA)/Amsterdam University of Applied Sciences (HvA).
Current projects: Digital Infrastructure Architecture Model, Implementing Object PID’s, Survey Digital Object Repositories, Object and Metadata Licensing, Resolvable Controlled Vocabularies. ORCID: 0000-0003-0214-4721.
Notes
[1] https://www.dpconline.org/handbook/technical-solutions-and-tools/persistent-identifiers
[2] https://support.orcid.org/hc/en-us/articles/360006971013-What-are-persistent-identifiers-PIDs-
[3] https://www.ncdd.nl/en/pid/
[4] https://en.wikipedia.org/wiki/Persistent_identifier (September 5, 2019)
[5] https://nl.wikipedia.org/wiki/Persistent_identifier (September 5, 2019)
[6] https://www.doi.org/faq.html (6. What can a DOI name be assigned to?)
[7] http://www.doi.org/factsheets/DOIKeyFacts.html
[8] https://nl.wikipedia.org/wiki/Uniform_Resource_Locator
[9] https://en.wikipedia.org/wiki/National_Bibliography_Number
[10] https://en.wikipedia.org/wiki/Uniform_Resource_Name
[11] https://www.kb.nl/organisatie/onderzoek-expertise/informatie-infrastructuur-diensten-voor-bibliotheken/registration-agency-nbn
[14] https://www.handle.net/overviews/handle_type_10320_loc.html
[15] https://www.handle.net/payment.html
[18] https://www.crossref.org/
[20] http://www.doi.org/doi_handbook/3_Resolution.html#3.3
[21] http://www.doi.org/doi_handbook/5_Applications.html#5.4
[22] https://datacite.org/members.html
[24] http://n2t.net/e/ark_ids.html
[25] https://wiki.duraspace.org/display/ARKs/ARKs+in+the+Open+Project
[26] https://n2t.net/e/pub/naan_registry.txt
[27] https://ezid.cdlib.org/learn/id_concepts
[28] http://n2t.net/e/noid.html
[29] https://metacpan.org/pod/distribution/Noid/noid#RULE-BASED-MAPPING
[31] https://archive.org/services/purl
[32] https://archive.org/services/purl/help
[33] https://www.pidwijzer.nl/en/faq
[34] https://en.wikipedia.org/wiki/Universally_unique_identifier
[36] https://pro.europeana.eu/resources/standardization-tools/edm-documentation
[37] http://www.loc.gov/marc/bibliographic/bd856.html
[38] https://www.w3.org/TR/ld-bp/#HTTP-URIS
[39] https://en.wikipedia.org/wiki/Uniform_Resource_Identifier
[40] http://www.loc.gov/marc/bibliographic/bd024.html
[41] http://www.loc.gov/standards/sourcelist/standard-identifier.html
References
ARK. [accessed 2019 Nov 21]. http://n2t.net/e/ark_ids.html.
ARK NAAN Registry. [accessed 2019 Nov 21]. https://n2t.net/e/pub/naan_registry.txt.
ARKs in the Open. [accessed 2019 Nov 21]. https://wiki.lyrasis.org/display/ARKs/ARKs+in+the+Open+Project.
Crossref. [accessed 2019 Nov 21]. https://www.crossref.org/.
DANS. [accessed 2019 Nov 19]. https://dans.knaw.nl/nl.
DataCite. [accessed 2019 Nov 21]. https://datacite.org/.
DataCite – Members. [accessed 2019 Nov 21]. https://datacite.org/members.html.
Digital Object Identifier System FAQs. [accessed 2019 Sep 17]. https://www.doi.org/faq.html.
DOI. [accessed 2019 Nov 19]. https://doi.org.
DOI – Linked Data. [accessed 2019 Nov 19]. http://www.doi.org/doi_handbook/5_Applications.html#5.4.
DOI – Multiple Resolution. [accessed 2019 Nov 19]. http://www.doi.org/doi_handbook/3_Resolution.html#3.3.
DOI Key Facts. [accessed 2019 Sep 17]. https://www.doi.org/factsheets/DOIKeyFacts.html.
Europeana Data Model. Europeana Pro. [accessed 2019 Nov 21]. https://pro.europeana.eu/resources/standardization-tools/edm-documentation.
EZID. EZID. [accessed 2020a Jan 30]. https://ezid.cdlib.org/.
EZID: Identifier Concepts and Practices at the California Digital Library. EZID. [accessed 2020b Jan 30]. https://ezid.cdlib.org/learn/id_concepts.
figshare. [accessed 2019 Nov 21]. https://figshare.com/.
Handle.Net Registry. [accessed 2019 Nov 19]. https://www.handle.net/.
Handle.Net Registry – 10320/loc Handle Type. [accessed 2019 Nov 19]. https://www.handle.net/overviews/handle_type_10320_loc.html.
Handle.Net Registry – Payment. [accessed 2019 Nov 19]. https://www.handle.net/payment.html.
Hilse H-W, Kothe J. 2006. Implementing Persistent Identifiers: Overview of concepts, guidelines and recommendations. London/Amsterdam: Consortium of European Libraries; European Commission on Preservation and Access. [accessed 2019 Sep 17]. http://xml.coverpages.org/ECPA-PersistentIdentifiers.pdf.
Klump J, Huber R. 2017. 20 Years of Persistent Identifiers – Which Systems are Here to Stay? Data Science Journal. 16(0):9. doi:10.5334/dsj-2017-009.
Kunze J, Rodgers R. 2008 May 22. The ARK Identifier Scheme. [accessed 2019 Aug 19]. https://n2t.net/ark:/13030/c7cv4br18.
Library of Congress: MARC 21 Format for Bibliographic Data: 024: Other Standard Identifier. [accessed 2019 Nov 21]. http://www.loc.gov/marc/bibliographic/bd024.html.
Library of Congress: MARC 21 Format for Bibliographic Data: 856: Electronic Location and Access. [accessed 2019 Nov 21]. http://www.loc.gov/marc/bibliographic/bd856.html.
Library of Congress: Standard Identifier Source Codes: Source Codes for Vocabularies, Rules, and Schemes. [accessed 2019 Nov 21]. http://www.loc.gov/standards/sourcelist/standard-identifier.html.
MuseumID. [accessed 2019 Nov 21]. http://museumid.net/.
National Bibliography Number. 2019a. In: Wikipedia. [accessed 2019 Sep 17]. https://en.wikipedia.org/w/index.php?title=National_Bibliography_Number.
NOID. [accessed 2019 Nov 21]. http://n2t.net/e/noid.html.
NOID – Rule Based Mapping. [accessed 2019 Nov 21]. https://metacpan.org/pod/distribution/Noid/noid#RULE-BASED-MAPPING.
Persistent identifier. 2016. In: Dutch Wikipedia. [accessed 2019 Sep 17]. https://nl.wikipedia.org/w/index.php?title=Persistent_identifier.
Persistent identifier. 2019b. In: English Wikipedia. [accessed 2019 Sep 17]. https://en.wikipedia.org/w/index.php?title=Persistent_identifier.
Persistent Identifier Wijzer – Frequently asked questions. [accessed 2019 Nov 21]. https://www.pidwijzer.nl/en/faq.
Persistent identifiers. 2015. In: Digital Preservation Handbook. 2nd ed. Digital Preservation Coalition. [accessed 2019 Sep 17]. https://www.dpconline.org/handbook/technical-solutions-and-tools/persistent-identifiers.
Persistent Identifiers. NCDD. [accessed 2019 Sep 17]. https://www.ncdd.nl/en/pid/.
Peyrard S, Tramoni J-P, Kunze J. 2014 Oct 1. The ARK Identifier Scheme: Lessons Learnt at the BnF and Questions Yet Unanswered. [accessed 2019 Aug 15]. https://escholarship.org/uc/item/58d52295.
PURL. [accessed 2019 Nov 21]. https://archive.org/services/purl/.
PURL help. [accessed 2019 Nov 21]. https://archive.org/services/purl/help.
Registration Agency NBN | Koninklijke Bibliotheek. [accessed 2019 Nov 19]. https://www.kb.nl/organisatie/onderzoek-expertise/informatie-infrastructuur-diensten-voor-bibliotheken/registration-agency-nbn.
Signposting. [accessed 2019 Nov 21]. https://signposting.org/.
Uniform Resource Identifier. 2019c. In: Wikipedia. [accessed 2019 Nov 21]. https://en.wikipedia.org/w/index.php?title=Uniform_Resource_Identifier&oldid=925198387.
Uniform Resource Locator. 2019d. In: Wikipedia. [accessed 2019 Nov 19]. https://nl.wikipedia.org/w/index.php?title=Uniform_Resource_Locator&oldid=54998398.
Uniform Resource Name. 2019e. In: Wikipedia. [accessed 2019 Sep 17]. https://en.wikipedia.org/w/index.php?title=Uniform_Resource_Name.
Universally unique identifier. 2019f. In: Wikipedia. [accessed 2019 Nov 21]. https://en.wikipedia.org/w/index.php?title=Universally_unique_identifier&oldid=927079784.
Van de Sompel H, Sanderson R, Shankar H, Klein M. 2014. Persistent Identifiers for Scholarly Assets and the Web: The Need for an Unambiguous Mapping. International Journal of Digital Curation. 9:331–342. doi:10.2218/ijdc.v9i1.320.
W3C Best Practices for Publishing Linked Data – HTTP URI’s. [accessed 2019 Nov 21]. https://www.w3.org/TR/ld-bp/#HTTP-URIS.
What are persistent identifiers (PIDs)? ORCID. [accessed 2019 Sep 17]. http://support.orcid.org/hc/en-us/articles/360006971013-What-are-persistent-identifiers-PIDs-.
Zenodo. [accessed 2019 Nov 21]. https://zenodo.org/.
Update
On May 13th 2020 following the author’s request we changed http://n2t.info to the canonical http://n2t.net in the URLs of three ARK links (the editor).

Subscribe to comments: For this article | For all articles
Leave a Reply