by Joshua D. Lynch, Jessica Gibson, and Myung-Ja Han
Background: Problems with Type Metadata and Existing Quality Controls
Introduction to the IDHH and Type Metadata
The Illinois Digital Heritage Hub (IDHH) gathers and enhances metadata from contributing institutions around Illinois and provides this metadata to the Digital Public Library of America (DPLA) for greater access. The IDHH helps contributors shape their metadata to the standards recommended and required by the DPLA. This paper describes the process for gathering and analyzing contributors’ Type metadata, problems seen in the analysis of the metadata, and ways that contributors, the IDHH, and the DPLA remediated problems found in the analysis.
The IDHH is the Illinois Service Hub [1] for the Digital Public Library of America (DPLA), and a collaboration among the Illinois State Library (ISL), the Consortium of Academic and Research Libraries in Illinois (CARLI), the Chicago Public Library (CPL), and the University of Illinois Urbana-Champaign (UIUC) Library. As of July 2019, the IDHH aggregated metadata from about 150 individual contributing institutions around the state. The metadata is harvested as Qualified Dublin Core (QDC)[2], also known as DCMI Metadata Terms (dcterms), and provided as QDC records to the DPLA.
As of July 2019, the IDHH harvested and exposed more than 310,000 records from 448 digital collections. Through metadata assessment [3], a best practices document [4], and training; the IDHH has made significant efforts so that contributors’ metadata conforms to the DPLA’s standards and recommendations which ultimately improve discoverability of the IDHH’s rich and unique digital resources.
As in any aggregated environment, some fields, including Type, have been difficult to standardize across the IDHH’s contributing institutions. The DPLA has robust quality controls for all its metadata and specific refinements for the Type field [5]. However, its ingestion systems require a quality baseline that was not present in the IDHH’s Type metadata. The IDHH Type metadata is very diverse and the DPLA requirements are strict; while all metadata from original records is retained and available in the DPLA’s API, only DCMI Type [6] values, such as ‘Image’, ‘Moving Image’, ‘Physical Object’, ‘Sound’, and ‘Text’ facetable in the DPLA’s API and catalog, as shown in Figure 1. Type is one of several data fields that the DPLA uses to create facets by which to narrow search results and to link from an individual record to a list of items of a given Type, as shown in Figure 2. The DPLA’s ingestion systems provide for mappings between a set list of non-conforming values and DCMI Types, but mappings and subsequent catalog features that rely on DCMI Type values seem to work best when valid DCMI Type values are present in an original record.
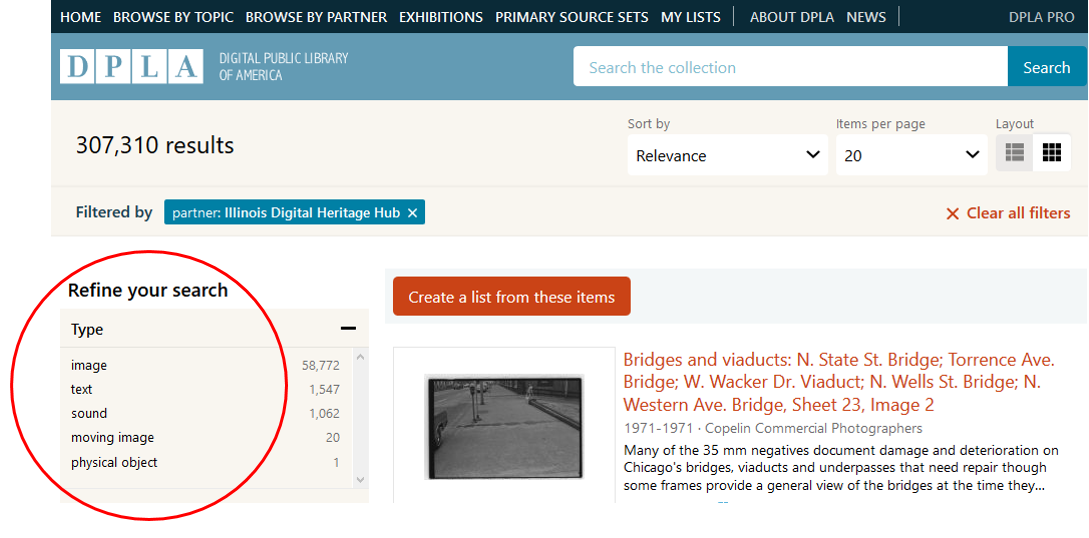
Figure 1. Type faceting options that appear with search results.

Figure 2. Type facet within a record. Clicking ‘image’ will link to other records in the DPLA with the same Type metadata.
Due to its importance for access, discovery, and interactivity, and the low rates of completion as seen in the DPLA’s search interface [7], it was determined that enhancement of the Type metadata contributed by IDHH institutions was necessary. Initial analysis revealed that there were 558 unique Type values in all IDHH records. After metadata analysis, a three-pronged approach to enhancing Type metadata was undertaken. Type metadata contributed by IDHH institutions could be improved by:
- institutions submitting better quality metadata,
- more robust XSL transformations of the aggregated metadata by the IDHH, and
- working with the DPLA in order to improve their quality controls on IDHH Type metadata, which may in turn lead to improved quality controls on Type and other fields for other hubs contributing metadata to the DPLA.
Overview of IDHH Type Metadata Problems
In-depth analysis discussed in detail below showed that, as of 2018-12-13, there were at least 558 unique Type metadata values among about 327,000 values total. Only about 176,000 of the 327,000 total values perfectly conformed to DCMI Type. Due to the large volume of unique values coming in and limitations in the DPLA’s Ingestion 1 [8] quality controls, only approximately 61,000 metadata values displayed and functioned as working facets in the DPLA’s search interfaces, as shown in Figure 3 below. This represented only one DCMI Type value for every five records that IDHH institutions had contributed to the DPLA.
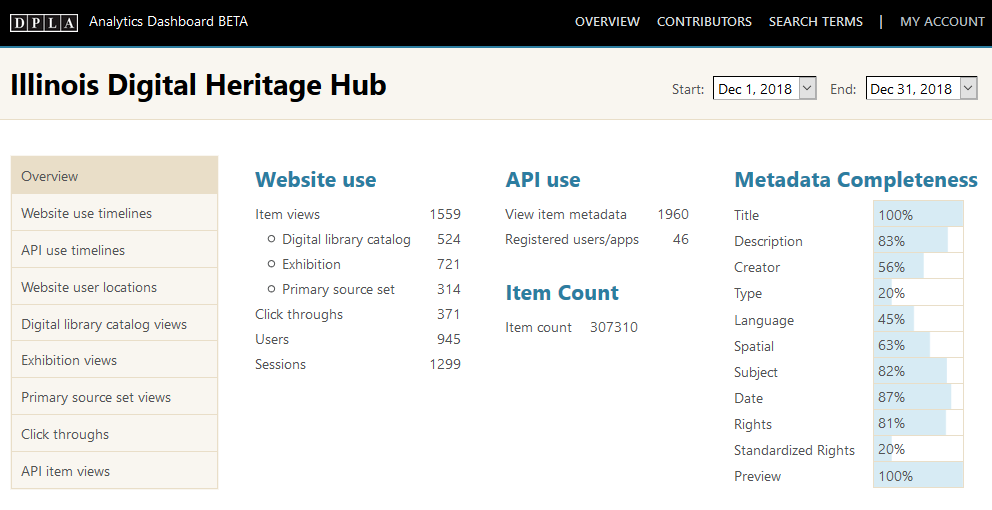
Figure 3. Low rates of Type completion in IDHH metadata indicated by DPLA Analytics Dashboard, 2018-12-14.
Some examples of problems in the Type metadata originally provided by contributors included:
- A wide variation of capitalizations (“Still Image” vs. “Still image” vs. “still image”)
- Highly granular values with slight variations of the same essential type or format (“Letter – carbon typescript”, “Letter – typescript”, “letter”, etc.)
- Large numbers of multiple delimited values in a field (e.g., “Text; Image”, “text; sound”, “Text; Still Image”)
- Superfluous delimiters appearing at the end of values or value sets (“Still Image;”, “Text; Image;”)
- A mix of semicolon- and comma-separated values
- Pluralization (Books vs. Book)
- Values that were otherwise misspelled or were better expressed in fields other than the Type field
Inspecting IDHH Type Metadata
Initial analysis using the DPLA Analytics Dashboard [9] and the DPLA OAI Aggregation Tools [10] originally developed by the North Carolina Digital Heritage Center and modified by the IDHH, only scratched the surface of what appeared to be widespread issues with IDHH-contributed Type metadata. While the Aggregation Tools would reveal Type metadata within a single collection, large-scale data analysis could not be easily accomplished with them due to their out-of-the-box design that evaluates one record set at a time.
IDHH and DPLA staff made several attempts from 2017 to 2018 to analyze the metadata of the entire IDHH record set with OpenRefine. Due to the size of the set and possibly insufficient available memory on the machines facilitating this effort, OpenRefine failed to parse the dataset after multiple attempts. Moreover, although OpenRefine supports gathering and analyzing XML through OAI-PMH queries, it was unknown to IDHH staff, even after extensive research, if and how OpenRefine can handle resumption tokens. Thus, the only method known to IDHH staff for dealing with huge OAI-PMH sets with OpenRefine is the tedious process of manually entering resumption tokens.
Alternative methods were investigated in order to gather and analyze all the IDHH Type metadata, including bulk download [11] of JSON-LD data created by the DPLA from the XML harvested from the IDHH and calling the DPLA’s API [12] for smaller samples of JSON-LD data. Ultimately, the latter option was selected primarily because data analysis tools like OpenRefine work better with JSON data than with XML and because gathering data via the API would provide the most up-to-date data available from the DPLA in a fairly small package. The download of a subset of metadata from all IDHH records, including only each record’s Type key-value pairs and four other fields discussed below was around 100MB, compared to the 1GB bulk download of all IDHH metadata.
A Python script [13] was created to generate DPLA API calls and to download all the JSON-LD data for each IDHH data provider, as read from a UTF-8 csv file. This script can run on Python 2.7 or higher and requires the installation of the Requests library [14], used for interacting with the DPLA API. It may seem more obvious to use the API to harvest all records that contain the name or ID of the hub in the provider metadata. The problem with this approach is that the API limits calls to 100 pages of 500 results each, or a maximum of 50,000 records. As only one of the IDHH’s providers currently contributes more than 50,000 records and its metadata already conforms well to DCMI Type, it was decided to gather collections by provider in order to work within the API’s limit. The following fields (see Table 1) were selected from each record in every IDHH-contributed collection, represented in the DPLA API as a JSON-LD object:
| Field Name | Description |
|---|---|
| dataProvider | Individual institution that provided record |
| sourceResource.collection.title | Title of collection of which a given record is a part |
| sourceResource.title | Title of the item an individual record describes |
| isShownAt | URL linking to the source instance of the record |
| originalRecord.type | Original Type value provided by IDHH |
| sourceResource.type | DCMI Type value created by the DPLA |
Table 1. JSON-LD fields selected with DPLA API.
The dataProvider and sourceResource.collection.title fields were selected in order to identify a given record’s contributing institution and collection. This allowed for faceting in OpenRefine by the institution that provided a record and by a record’s collection and thus, checking if problems with particular records represented widespread issues at the collection or institution level. Similarly, sourceResource.title was chosen to identify an individual record, and isShownAt was selected for easily linking to a record’s source instance. These fields allowed for greater refinement, especially in terms of faceting, grouping, and filtering the two Type metadata fields available in the JSON-LD sample: the originalRecord.type, or the value provided by the IDHH to the DPLA, and the sourceResource.type, the value created by the DPLA and available in its search interface if and when provider data has passed through the DPLA’s quality controls, discussed above. For reference, here is an example JSON-LD object from the data gathered:
"docs": [{
"sourceResource.title": "Lt. Col Rhodes",
"isShownAt": "http://www.idaillinois.org/cdm/ref/collection/parkridg001/id/668",
"sourceResource.collection.title": "Mel Tierney Post Servicemen File",
"dataProvider": "Park Ridge Public Library",
"originalRecord.type": "Text",
"sourceResource.type": "text"
}]
The script downloaded more than 900 JSON-LD data files containing the data from at least 94% of the IDHH’s more than 300,000 records. The remaining 6% comprised of records provided by the single institution, discussed above, whose records number greater than 50,000 and thus exceed the DPLA API’s call limits [15]. The JSON-LD files were then imported into OpenRefine 3.0 on the metadata specialist’s local machine and parsed in OpenRefine as JSON files, as shown in Figure 4.
Figure 4. JSON-LD data fields were uploaded to OpenRefine using the ‘Browse’ files feature.
The initial OpenRefine table revealed that many records had two instances of the sourceResource.type or originalRecord.type fields with corresponding values due to the presence of two elements in the XML records originally provided to the DPLA (see Figure 5).
Figure 5. Examples of two instances of Type metadata values.
Further refinement was required in order to prioritize action items from the overwhelming results. The originalRecord.type facets and corresponding counts were downloaded from the original OpenRefine set and were imported into another OpenRefine sheet. Facets were sorted alphabetically and case-sensitively. A blank down operation was performed to remove the duplicates that resulted from the two columns, multivalued cells were joined to get the total counts from the blank rows and the ones above them, and the multivalued cells were summed by creating a new column (see Figure 6) based on the following Google Refine Expression Language code:
forEach(value.split(','),v,v.toNumber()).sum()
Figure 6. OpenRefine’s “Join multi-valued cells” feature
The final product was a spreadsheet of 558 Type values and their respective counts from all IDHH collections.
The number of unique Type values revealed problems that could not be solved by the IDHH through XSL transformation alone. In addition to mass-normalization of common values by the IDHH, two other categories of issues were identified: those that would need to be redressed by the DPLA and those that would simply need to be tackled by individual contributors refining the metadata they provide.
Solutions for Data Clean Up
IDHH XSL Enhancements
Much of the work of enhancing Type metadata can be handled automatically through XSL stylesheet transformations applied in the IDHH REPOX aggregation server. An XSL template was developed [16] for matching on the dc:type element and performing operations on the text node, e.g., the Type metadata value the dc:type element contains.
Problems addressed with XSL
Many providers use commas or a combination of comma-separated values and, the more common delimiter, semicolons. Occasionally, commas and semicolons appear in the same field. In the XSL templates for transforming Type, a line of code utilizing the XPath replace() function converts commas to semicolons to normalize the delimiter.
<xsl:variable name="typeValue"
select="normalize-space(replace(., ',', ';'))"/>
The tokenize() XPath2 expression is used to split multiple values and then, each token is inspected separately using a for-each loop which calls up a template for matching a token to the correct DCMI Type.
Instead of relying on an exact match on a certain string value, the XSL transforms this lowercase string if it contains a certain keyword, using the XPath lower-case() and contains() functions.
<xsl:when test="contains(lower-case($rawType), 'physical') or
contains(lower-case($rawType), 'realia') or
contains(lower-case($rawType), 'object')">
<xsl:element name="dc:type">
<xsl:text>Physical Object</xsl:text>
</xsl:element>
</xsl:when>
When the lower-case version of a record’s dc:type value contains a keyword such as “still,” as in the half dozen or so common variations of “still image”, this text node is to be transformed into ‘Image’.
<xsl:when test="contains(lower-case($rawType), 'still')"> <xsl:element name="dc:type"> <xsl:text>Image</xsl:text> </xsl:element> </xsl:when>
XSLT Limitations
XSL works on individual nodes. Thus, if multiple dc:type elements are present, each will be passed through the normalization function. Some records will have Type values that will be transformed into the same value, for example:
<dc:type>Poster</dc:type> <dc:type>War Poster</dc:type>
Will be transformed into:
<dc:type>Image</dc:type> <dc:type>Image</dc:type>
Fortunately, the DPLA can de-duplicate specific fields and has been asked to do so for the IDHH’s Type metadata.
The keyword matches utilizing contains() described above will require continued careful attention to contributors’ Type metadata to insure that the values are transformed properly. Periodic tests, the latest of which at the writing of this paper was in 2019-05, show that the transformation has worked well for nearly half a year. However, there may eventually be newly-added Type values that contain a certain keyword which will be converted to incorrect Type values.
Clean up by Individual Institutions
Many problems boil down to unusual values appearing in the Type metadata field that cannot be handled by XSL transformations and must be remediated by contributors. Examples include phrases that appear to be more suited for an item description (dc:description) field or subject (dc:subject), URLs that seem to be duplicate record identifiers, rights metadata, and odd misspellings of common type values. It is simply not practical to transform these often-unique values that nonetheless pervade several collections and severely impact their Type metadata and discoverability. Moreover, working with institutions’ staff allows them to improve the metadata at the local level and the usability of their digital collection environments.
From the very first communications onward, the IDHH respectfully engaged contributors, providing encouragement and instruction on remediating Type and other metadata fields. This message included the purpose and significance of Type metadata in the DPLA, an overview of the DPLA’s selected controlled vocabulary, DCMI Type, as well as the steps the IDHH is taking to ease at least some of the burden on contributors in conforming to the standards of DCMI Type.
The IDHH took steps to help contributing institutions understand the issue and the best practices for Type metadata. An online Type Metadata Guide [17] for contributors was created and linked to on several other websites, including the IDHH LibGuide [18]. Regular office hours were held in order to offer the opportunity for contributors to discuss metadata remediation for Type or other fields.
Deploying XSLT and Type Metadata Guide
Testing and Deploying XSLT
The XSLT was developed in test-and-go fashion on small XML data sets in Oxygen Editor 18.0 [19]. On 2019-01-24, immediately prior to the first DPLA ingestion of 2019 for Illinois, XSLT was run for the first time on the IDHH REPOX 2.3.7 server. Key features of the transforms were tested by the harvest coordinator and metadata services specialist on several large datasets, including:
- The basic mapping from a provided metadata value to a DCMI type
- The transform’s effects on pluralized values, alternative spellings, white space, etc.
- The XSLT’s handling of delimited values on comma and semicolon delimiters
Tests also confirmed the duplication of values predicted in the development of the XSLT. However, no unexpected transformations occurred and the XSLT was deployed for transformations on all records provided to the DPLA on 2019-01-28.
Disseminating Type Metadata Guide
The Type Metadata Guide for contributing institutions was disseminated through the first half of 2019. The IDHH Metadata Best Practices were updated to include the guide and it has also been posted on the IDHH metadata working group website along with a list of values the IDHH transforms to DCMI Type. Institutions are encouraged to contact the metadata services specialist at the IDHH if they wish to recommend additions or other changes to the current mapping.
Measuring Impact of the Type Metadata Project
The IDHH Type metadata project returned impressive results. Before remediation efforts began, only 176,000 of 327,000 values (53.8%) conformed to DCMI Type and the field held 558 unique values. Of these values, only 20% of the IDHH’s more than 300,000 records were showing up with Type metadata in the DPLA catalog. Re-examinations of Type metadata on 2019-02-15 and on 2019-05-20 using the Python metadata downloader tool and OpenRefine showed remarkable improvements. The February check-up revealed that the number of unique metadata fields was reduced to 117. The number of DCMI conforming values as of 2019-02-15 was 300,985, whereas there were only 918 non-conforming values, meaning that 99.7% of IDHH Type metadata values conformed to DCMI, as shown in Figure 7.
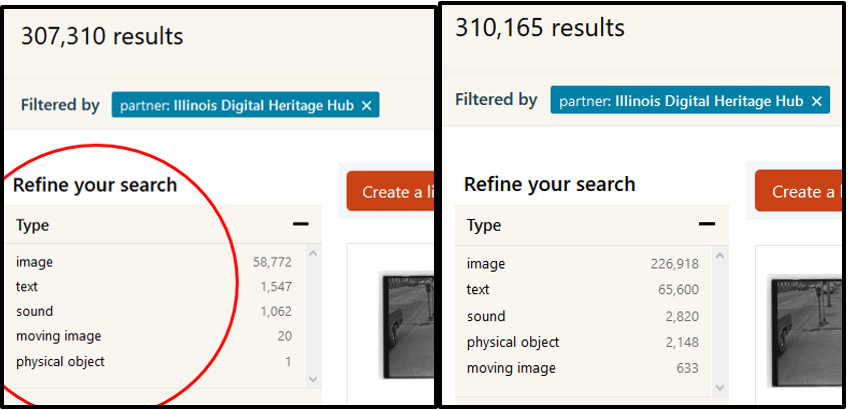
Figure 7. Screen captures of Type facets for all IDHH items in the DPLA, before (left) and after (right) the Type metadata project.
The February 2019 review also showed that there are still a few values that do not conform to DCMI Type left over from the original list developed in 2018-11. These were generally facets which number fewer than 10 values each and thus were not made a priority in the project. In addition, there were a few new values that must have slipped in due to changes provider institutions had made to their metadata since it was initially downloaded and checked in OpenRefine in 2018-11 and 2018-12 and which had not been accounted for by the XSL. Only two of these values had more than 100 instances.
The May 2019 check-up again revealed high percentages of conformity to DCMI Type. Of approximately 308,000 originally-provided Type metadata values, 307,000 conformed to DCMI Type, maintaining the 99.7% conformity to DCMI Type seen in the February review. There were 109 unique fields showing up in the analysis. There were only three non-conforming values with counts greater than 100 and the vast majority of these (over 86.5%) are being transformed by the DPLA’s ingestion system.
| Before project | February 2019 | May 2019 | |
|---|---|---|---|
| All Type values | = 327,000 | 301,903 | = 308,000 |
| Conforming values | = 176,000 | 300,985 | = 307,000 |
| % of Conforming values | = 53.8 | 99.7 | = 99.7 |
| Unique values | 558 | 117 | 109 |
| % of IDHH records with Type metadata in DPLA catalog | 20 | 93 | 92 |
Both reviews showed high percentages of completion of the dc:type metadata field and conformity to DCMI Type. This may be allowing the DPLA’s own quality control measures to do their best work. Most of the values not transformed by the IDHH’s XSL are transformed by the DPLA’s Ingestion system and, therefore, are no cause for concern. As of 2019-05-20, DPLA Analytics reports completion rates of the Type field at 92%, a far cry from the 20% rates seen in December 2018 (see Figure 8). This would likely be even higher if not for the fact that a number of contributors do not provide any Type metadata.
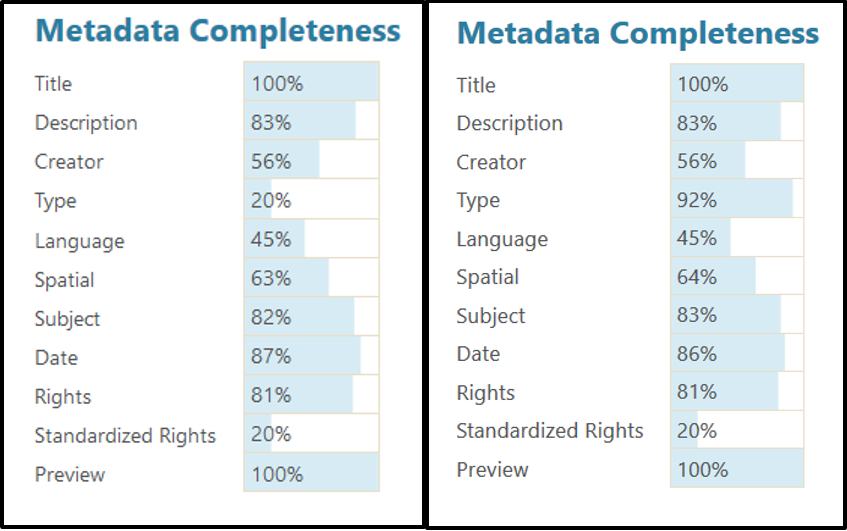
Figure 8. Type Metadata Completion Rates, December 2018 (left) and May 2019 (right). Note that Type now has the highest rate of completion of any non-required field.
It should also be noted that none of the problems foreseen by tokenizing multiple semicolon-separated Type values manifested in either the February or May check-up. The DPLA was able to de-duplicate Type values, thus making normalizing delimiters and tokenizing them worthwhile. Nevertheless, the IDHH will continue to review the Type metadata and transformations from time to time.
Next Steps: New Harvest and Analysis Systems and Continued Communication
The extensive XSL transformations now in place on the IDHH REPOX aggregation server make it impossible to analyze large samples of Type metadata originally provided by contributors using JSON-LD data from the DPLA API. Before the XSL was deployed, the DPLA received original values provided by IDHH contributors and therefore, these same values were accessible in the API and through bulk download in the originalRecord.Type field. After the XSL template for transforming Type metadata was deployed, original values provided by contributors are transformed by the IDHH before they are harvested by the DPLA and thus are not available through the DPLA API. Therefore, in addition to existing tools that allow for the analysis of small samples of contributors’ metadata, a mode of analyzing large and, if possible, the complete IDHH dataset of Type and other metadata values directly from contributors will need to be developed. Discussing new methods in depth is beyond the scope of this paper but may involve a change of harvesting platform from REPOX to one that provides more powerful data analysis, such as the Michigan Service Hub’s solution now widely adopted by other DPLA partners: Combine [20].
Type, like all metadata in a large-scale continuous aggregation, will be a moving target: current providers’ metadata may change and new collections with potentially new Type metadata values are being added regularly. New collections’ metadata will continue to be thoroughly assessed. Moreover, the IDHH will continue to communicate with providers planning to improve their Type metadata and other metadata fields.
Regular contact with the DPLA will be essential. In addition to the ongoing discussions on the DPLA’s role in normalizing provider data, it will be important to discuss any remaining or new issues involving the DPLA’s recently deployed new harvesting system, Ingestion 3 [21].
Conclusions: A Team Effort
The challenges of this project, particularly in gathering and analyzing the metadata, exposed some serious limitations in the IDHH’s infrastructure and provided impetus and inspiration for new procedures and platforms. It also revealed the many uses of the DPLA’s tools, especially its API and open APIs in general. Moreover, this project brought to light the growing importance of understanding multiple aspects of metadata work, including metadata harvest, analysis, and refinement, along with an ability to work with tools for each aspect. The project used several open source tools, including OpenRefine and the Atom editor for developing Python scripts. The Type metadata analysis and refinement project was a testament to the challenges and rewards of working with aggregated metadata and required the cooperation of all parties involved: providers, the hub, and the DPLA.
About the Authors
Joshua Lynch is a Metadata Specialist at the University of Illinois, Urbana-Champaign and the metadata manager and webmaster for the Illinois Digital Heritage Hub, a service hub of the Digital Public Library of America. Lynch’s professional experience and interests include metadata aggregation, curation, and remediation, web development, digital content creation, digital curation, and digital preservation.
Jessica Gibson is the Senior Application Support Coordinator at the Consortium of Academic and Research Libraries in Illinois (CARLI) and the harvesting coordinator for the Illinois Digital Heritage Hub. Gibson’s current work finds her managing and supporting large, library-related systems, but she will never forget her cataloging roots.
Myung-Ja K. Han is the Head of Acquisitions and Cataloging Services at the University of Illinois at Urbana-Champaign. Her research interests include metadata in digital library environment, metadata interoperability, and linked open data.
Notes
[1] For more information on Service Hubs and DPLA’s structure, see the DPLA’s documentation for prospective hubs: https://pro.dp.la/prospective-hubs
[2] Qualified Dublin Core (DCMI Terms) specifications page: http://www.dublincore.org/specifications/dublin-core/dcmi-terms/
[3] IDHH collection metadata assessment template: https://docs.google.com/document/d/1I46jjoehq5KI78VNWRBjR6a6DpLZIN_Xv7IaCD6lB3w
[4] IDHH Metadata Best Practices: https://docs.google.com/document/d/1q1AORHoa0ey0fUGOTYMHLvZNCm6Wq1Qe9DDvFZSRPT0
[5] For example, DPLA’s Ingestion 3 module for Type enrichment converts a growing list of currently 74 values to DCMI Type: https://github.com/dpla/ingestion3/blob/develop/src/main/resources/types/dpla-type-normalization.csv. Ingestion 3 performs similar operations on the language and format fields: https://github.com/dpla/ingestion3/tree/develop/src/main/resources.
[6] DCMI Type vocabulary specification: http://dublincore.org/documents/dcmi-type-vocabulary/
[7] DPLA’s catalog interface: https://dp.la/search?
[8] DPLA’s Ingestion 1 system: https://github.com/dpla/ingestion
[9] DPLA Analytics: https://analytics-dashboard.dp.la
[10] North Carolina Digital Heritage Center DPLA OAI Aggregation Tools: https://github.com/ncdhc/dpla-aggregation-tools
[11] DPLA Bulk Download: http://dpla-provider-export.s3.amazonaws.com/
[12] DPLA API documentation: https://pro.dp.la/developers/api-codex
[13] DPLA API JSON Downloader python script: https://github.com/jlynch2121/dpla-api-json-downloader
[14] Python Requests library website: https://2.python-requests.org/en/master/
[15] This was not deemed a serious issue as 75% of this provider’s records were gathered from the API. Analysis of the provider’s collections using the North Carolina Digital Heritage Center’s OAI Aggregation tools showed that they all conformed well to DCMI Type.
[16] XSLT for type metadata enhancement: https://github.com/jlynch2121/idhh-xsl
[17] Type Metadata Guide for IDHH contributors: https://ildplametadatawrkgrp.wordpress.com/documentation/type/
[18] IDHH Libguide originally created by Hannah Stitzlein, IDHH metadata manager and metadata services specialist at the University of Illinois, Urbana-Champaign from 2016-2018: http://guides.library.illinois.edu/idhh
[19] The cost of Oxygen may be prohibitive. The authors are also familiar with Atom, a versatile free and open source editor for almost any language, including XSL. An Atom plugin for transforming XML with XSL and testing transformations can be found at: https://atom.io/packages/atom-xsltransform.
[20] Combine documentation: https://combine.readthedocs.io/en/master/
[21] The Illinois Digital Heritage Hub metadata began to be harvested by Ingestion 3 in 2019-07. DPLA Ingestion 3: https://github.com/dpla/ingestion3

Subscribe to comments: For this article | For all articles
Leave a Reply