by Eric C. Weig
Small Virtual Machines
In my work at the University of Kentucky Libraries Special Collections Research Center, I rely more and more on low-cost, small virtual machines (VM) to manage small to medium sized digital libraries. [1] For example, I manage an oral history digital library that has 14,000 records, and another digital library of digitized photographs that has 110,000 records. In particular, the University of Kentucky Libraries use Reclaim Hosting as a vendor for many VMs. [2] I have found over the last five years that the small VM approach is a viable solution. However, one consideration with this approach is that these small VMs have limited storage space. For larger digital libraries, this makes them a good tool for managing a digital library’s front end search interface and index, but not as useful for storing lots of digital library objects such as images, audio, and video. This has made it necessary for us to explore alternate approaches to storing web addressable digital objects.
One avenue we have taken for the storage of both web deliverable and large archival reference copies of digital files, is our unlimited Google Drive for Education account. [3] Moving toward this as a solution has has offered both benefits and challenges.
Identified Benefits
Some instant benefits to utilizing Google Drive are unlimited storage space without an additional cost for our project. Google Drive is also very easy to use. Files can be pushed into Google Drive via command line scripting or through the use of an online GUI upload interface. In this way, files can even be dragged and dropped in. Setting file or folder permissions is also quite easy and offers a lot of flexibility as far as controlling access. [4]
Identified Challenges
An immediate local challenge with Google Drive became adjusting to an object vs. file based storage system. [5, 6] With past projects, file name references included within our metadata were used to build links to digitized files held in file based storage systems configured on web servers. Metadata for our digital projects includes references to related digitized files including images, video, audio, and PDF documents. Since Google Drive is an object based storage system, these file references were no longer sufficient to build URLs to access our digital objects.
Once our files were uploaded to Google Drive, the next task at hand was to find an efficient way of gathering a lot of Google Drive object identifiers. These were needed to build links to the new Google Drive objects. I knew that what we really needed was an automated way to produce a file manifest that would list file names and object identifiers for files within Google Drive. [7] The information from this file manifest would then need to be combined with existing metadata and loaded into our web publishing platform, Omeka.
- Sample Google Drive Object Identifier Based Link:
- https://drive.google.com/file/d/1MAEL63SUP6EyVgsXKIVxbrqkxCM1tWwE/view
- Sample Standard File System Based Link
- https://somedomain.org/files/series_one/240a.0001.jpg
Figure 1. Sample URLs for an image in Google Drive vs. an image in a file based storage system.
Lastly, I needed to learn how to utilize Google Drive objects within our web publishing platform’s public facing item view pages. This involved learning how Googlele Drive URLs worked, and producing custom code for our web publishing platform, Omeka, to allow for easy linking to Google Drive items and/or embedding them within HTML formatted item views. Object embedding, in particular, was a desirable goal.
Each of these challenges presented unanswered questions. In this way, the project was just like any other I had completed in the past. My approach has always been to simply dig in and figure my way through it one step at a time with hope that no insurmountable roadblocks would present themselves.
Google Drive API Scripting
Google Drive has a robust API that allows for JavaScript coding to interact with stored objects. [8] Searching through GitHub and the Google Drive API online manual, any number of examples for such scripts can be found. I was able to utilize a simple one, with minor modifications, in order to run a process on any given Google Drive directory in order to generate a file manifest holding metadata describing the files in a given directory. [9]
The Google Drive API offers a large number of descriptive data points which can be gathered. [10] For my purposes, since existing metadata sets included file names, in order to be able to map the Google Drive identifiers to their corresponding metadata records, I simply needed a manifest listing the file names and their corresponding Google Drive object identifiers. This was easily done using two established Google Drive data points. These specific data points are highlighted in the following code sample.
var file;
var filename;
var gdrivelink;
var row;
while(contents.hasNext()) {
file = contents.next();
name = file.getName();
link = file.getId();
sheet.appendRow( [name, link] );
}
Figure 2. Google Drive data points for gathering file names and Google Drive identifiers.
Setting up the script and running it were simple. [9] The resulting output of the script was a Google Sheet which held two columns. One column lists a file name and a second column lists the corresponding Google Drive identifier for the file.
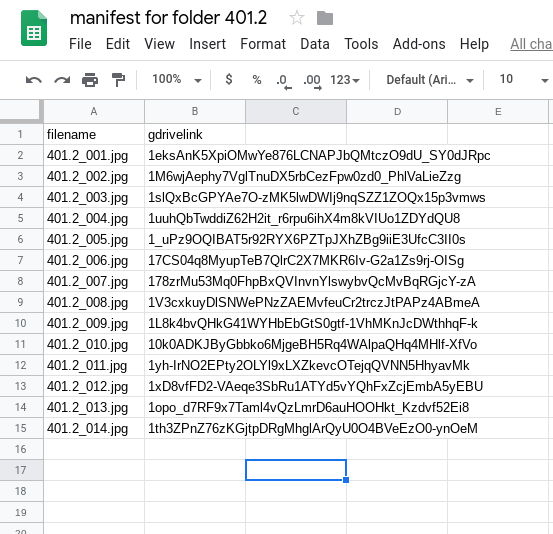
Figure 3. Example API generated manifest file.
The manifest, along with additional metadata describing the digital files, was then used to construct a single CSV file for batch loading the metadata into Omeka. During this part of the process, an important decision needed to be made. Google Drive offers a number of URL flavors for objects. Some of these specify how access to the object will work. For example, one flavor establishes a simple hyperlink to a Google Drive object. Another URL flavor can be used to embed a Google Drive object within an HTML page.
Sample Embed URL: https://drive.google.com/file/d/<objectid>/preview
Sample Link URL: https://drive.google.com/file/d/<objectid>/view
Figure 4. Example Google Drive URLs for both simple hyperlinks and object embedding.
Once I decided on whether or not to use hyperlinks or object embedding for our item view pages, I added the URL formatting into the manifest file and then merged that file into my CSV holding our existing metadata. In order to accomplish this merge, I keyed on file names matched between the manifest and CSV files. I was left with a single CSV file including the existing metadata and new Google Drive object URLs.
Luckily, there is an existing Omeka plugin for batch loading CSV formatted metadata. [11] So, once I had all the necessary metadata in a CSV file, including the Google Drive identifiers, importing into the Omeka database was easy.
A Simple Plugin for Omeka
Some bad news was that no Omeka plugin for utilizing Google Drive files existed. I needed to create one that would satisfy the following functional requirements:
- Parse the contents of an existing Omeka Item Type Metadata Field ‘URL’.
- If the field is not empty, determine whether or not the contents are in the form of a Google Drive URL.
- If a Google Drive URL is found, determine if the URL syntax is for a simple hyperlink or an embedded object.
- Based on information gathered in step 3, format the link to the Google Drive object accordingly.
- Allow site administrators to establish configuration settings for default hyperlink text, default linking behavior, and default iframe height and width.
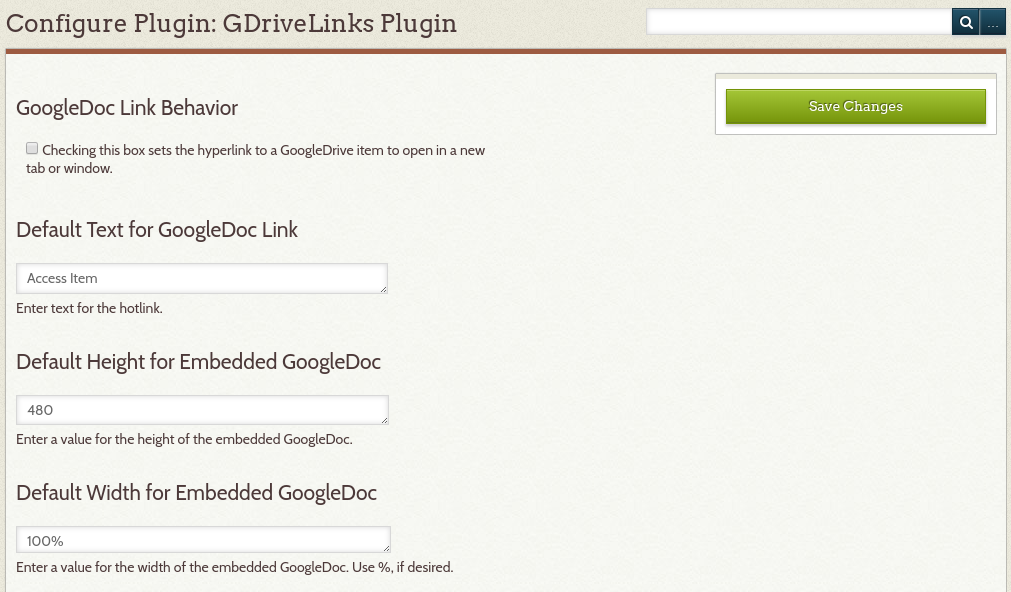
Figure 5. An image of the configuration page for the new GDriveLinks Omeka plugin.
In the sample plugin code below, the $text variable holds the value of the URL field. This field is intended to contain the Google Drive URL. Analyzing the URL syntax, the code parses the link and detects whether or not it is specifying a Google Drive simple hyperlink URL or a Google Drive embed URL. Based on the results of this analysis, the code then formats the link for the HTML page accordingly.
if (strpos($text, '/view') !== false) {
if (preg_replace('/[&lt;&gt;]/', '_', filter_var($text,
FILTER_VALIDATE_URL)) === $text) {
return "&lt;a href=\"" . $text . "\" target=\"" . $linktarget . "\"&gt;$linktext&lt;/a&gt;";
} else {
return $text;
}
} elseif (strpos($text, '/preview') !== false) {
if (preg_replace('/[&lt;&gt;]/', '_', filter_var($text,
FILTER_VALIDATE_URL)) === $text) {
return "&lt;iframe src=\"" . $text . "\" width=\"" . $embedwidth . "\" height=\"" . $embedheight . "\"&gt;&lt;/iframe&gt;";
} else {
return $text;
}
}
Figure 6. Sample PHP code from web publishing platform, Omeka. Controls public field display for Google Drive URLs.
Putting the Pieces Together
Once the new plugin was installed and configured and some of our metadata indexed, Google Drive objects began to appear within our item view pages. To promote the use of the plugin for others and help them visualize functionality, I created a demonstration site with some sample files. [12] Here are some user-facing screen shots of the plugin in action.
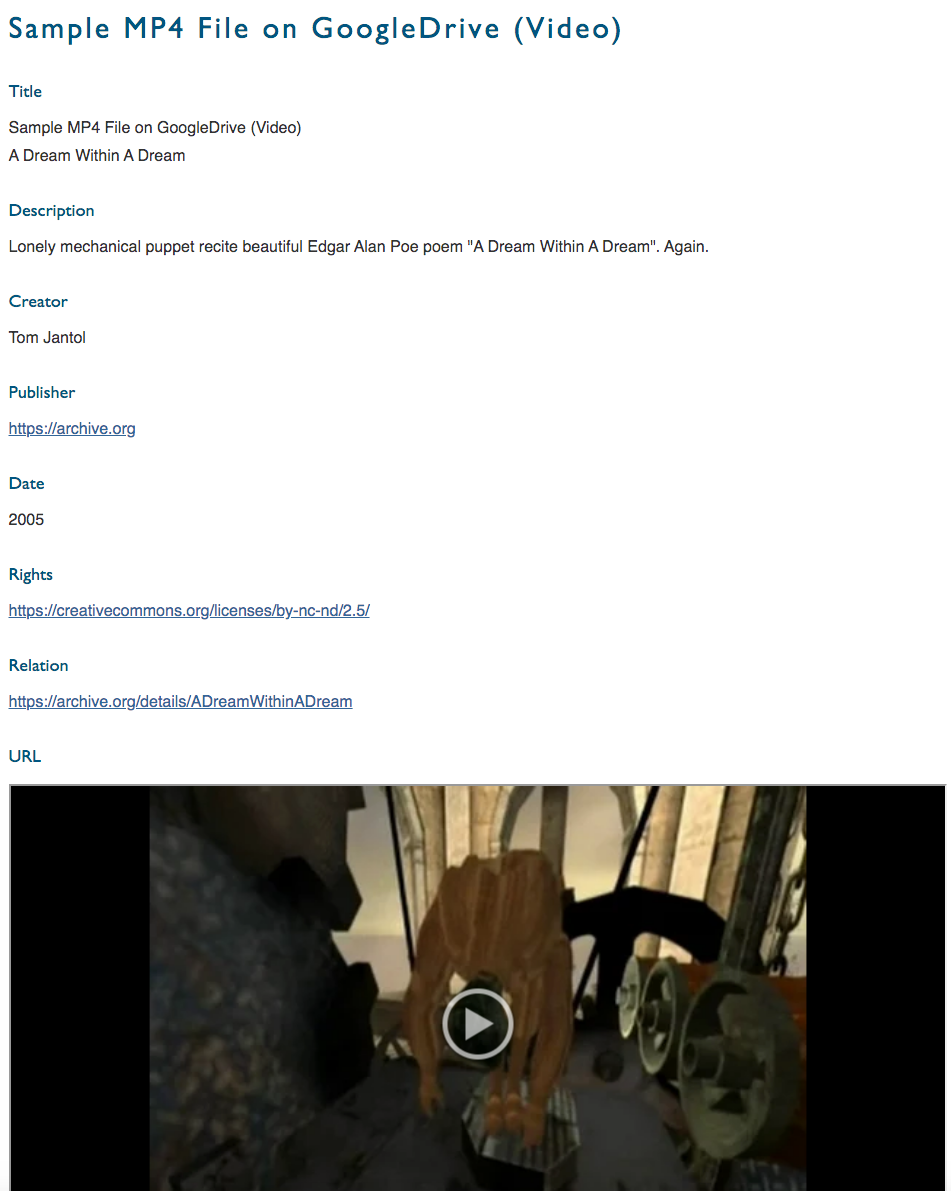
Figure 7. Example item view showing an embedded Google Drive video.

Figure 8. Example item view showing an embedded multipage Google Drive PDF.
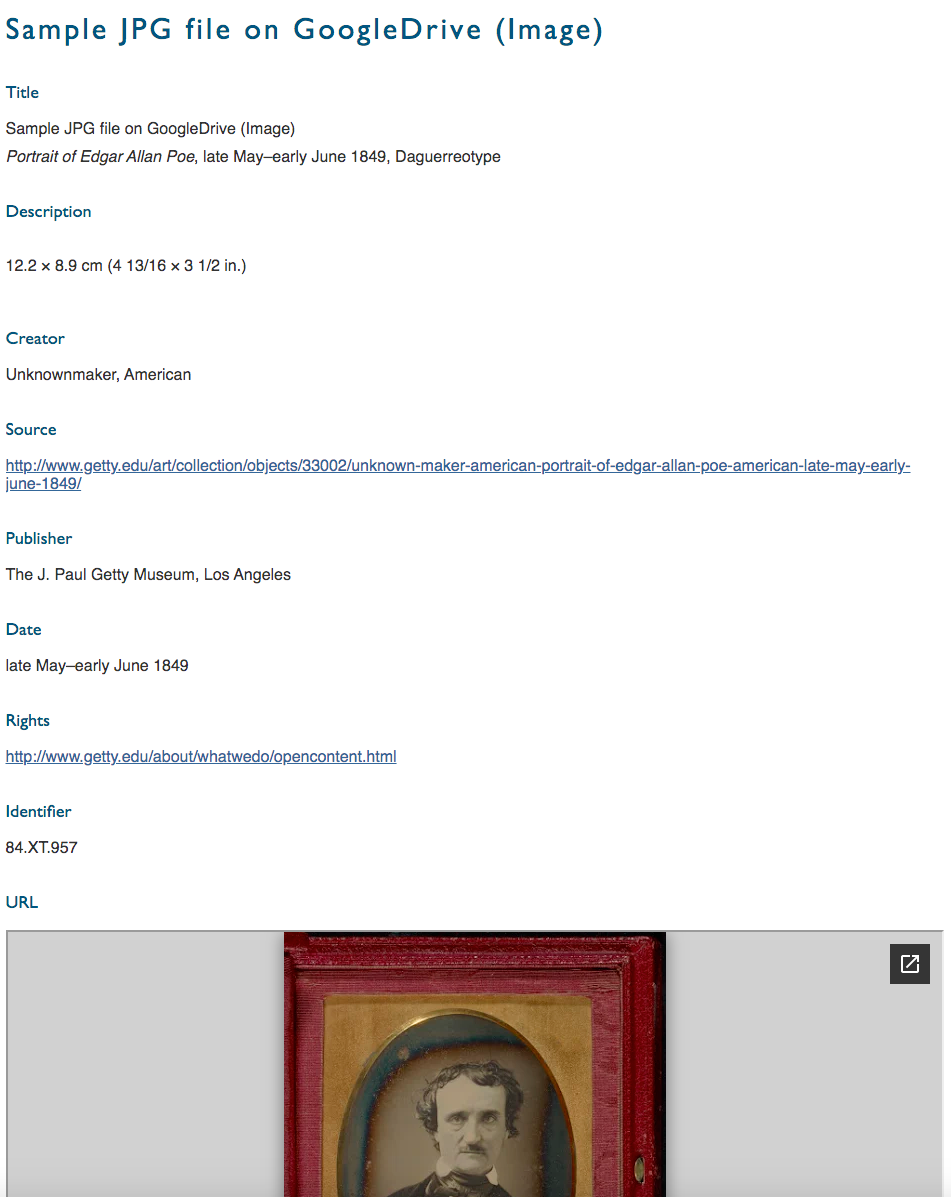
Figure 9. Example item view showing an embedded JPG image in Google Drive.
Outcomes
Now, identified challenges have been overcome and project goals achieved:
-
- to create an efficient method for generating Google Drive file manifests,
- to match files in Google Drive with their corresponding metadata in CSV format for loading into our web publishing platform,
- and to code and install a simple Omeka plugin for allowing linking/embedding with Google Drive URLs.
I now manage two large digital library projects utilizing Google Drive for digital library object storage. I have made both the Google Drive API code along with instructions for use, and the Omeka plugin available open source on GitHub. [9, 13] The plugin can also be found on the omeka.org plugins page. [14]
About the Author
Eric C. Weig has been an academic librarian at the University of Kentucky Libraries since 1998. His current title is Digital Library Architect. He designs, builds and manages digital libraries for the University of Kentucky Special Collections Research Center.
Notes
[1] https://en.wikipedia.org/wiki/Virtual_machine
[2] https://reclaimhosting.com/
[3] https://www.teachthought.com/current-events/google-drive-education-now-free-offers-unlimited-storage/
[4] https://www.guidingtech.com/google-drive-sharing-permissions-guide/
[5] https://en.wikipedia.org/wiki/Object_storage
[6] https://en.wikipedia.org/wiki/File_system
[7] https://en.wikipedia.org/wiki/Manifest_file
[8] https://en.wikipedia.org/wiki/Application_programming_interface
[9] https://github.com/libmanuk/GDriveManifest
[10] https://developers.google.com/apps-script
[11] https://omeka.org/classic/plugins/CsvImport/
[12] https://ukylib-exhibit-test.org/gdrive/
[13] https://github.com/libmanuk/GDriveLinks
[14] https://omeka.org/classic/plugins/GDriveLinks/

Subscribe to comments: For this article | For all articles
Leave a Reply