by Meredith L. Hale
Literature Review
Are bots effective?
Before launching into the process of making a Twitterbot, some evidence on their effectiveness in creating meaningful impressions on patrons is warranted. Existing literature indicates that bots, generally, are positively received and that they have had an impact specifically on library marketing and communication. In addition, bots are becoming more and more prevalent. As of 2017, it was estimated that 15% of Twitter’s users were bots rather than humans (Veale and Cook 2018).
A common initial reaction to proposing that library social media accounts consist of bot-created posts instead of solely human-created content is that automated content creation will not be as accepted or interesting for patrons. A study by Edwards et al. disproves this assumption; people typically interact with bots in the same way that they communicate with accounts run manually by humans (Edwards et al. 2014). Its results align with the Computers are Social Actors (CASA) paradigm. In their study, Edwards et al. had college students rate the credibility, interpersonal attraction, communication, and following likelihood of two Twitter feeds, one generated by a bot and another by a human. Participants were informed of the source of the feed upon viewing screenshots of each. Both feeds appeared to be generated by the Center for Disease Control (CDC) and shared content on STDs. The authors note that using the CDC as their test feed might have resulted in higher credibility scores than normal and indicate that future research should focus on more socially-focused agents more typical of Twitter. Because library accounts are often associated with established academic, community, or cultural heritage institutions, this attribution of credibility might also be given to library Twitterbots. Ultimately the study concluded that Twitterbots are viable substitutes for humans in transmitting credible information in a relatable way on social media.
In considering bots and how they are perceived by the Twittersphere, one also should recognize that human language itself is not always creative. Just like with tweets from bots, “natural” human products often rely on socially constructed clichés and catchphrases. Bots are made by humans and therefore project many human idiosyncrasies. Veale and Cook suggest that those skeptical of the creativity of Twitterbots compare the language they tweet to conversations at parties and country clubs. Formulaic tweets are also likened by the authors to the language used by children with chatterbox syndrome, which is characterized by the use of words that are not understood by their speaker for the sake of impressing others or socially passing (Veale and Cook 2018). Like with bots, these children repeat phrases they have heard from others or learned from media, but often the context in which the phrases are delivered is not quite appropriate. These children are considered smart and likeable, despite the lack of creativity and social awareness in the words they share. These examples show that comparing human and automated content may make individuals reevaluate what it means for something to be “creative.” In this way, bots can be used to spur critical conversations.
Ultimately, the goal of making a Twitterbot is not to see if it can pass as human, but to share content that can be trusted and spark ideas. As Veale and Cook state, “Twitterbots are not fake humans, nor are they designed to fool other humans” (Veale and Cook 2018). In fact, many established standards guiding how bots are named and used make no attempt to conceal their automated nature. Instead these characteristics are highlighted. For instance, it is typical protocol for a Twitterbot’s handle to include the word “bot” and for the description to indicate that tweets are automated rather than individually curated by hand. Identifying bots as bots actually makes users more comfortable about interacting with them (Veale and Cook 2018).
Twitter & Cultural Heritage Institutions
The examples given above provide evidence that Twitterbots can make meaningful impressions on patrons, but this research and assessment does not include examples directly relevant to cultural heritage institutions. There are many instances of library and museum Twitterbots that can be used to assess the effectiveness of this communication method and for inspiration in making your own. Included is a brief list of some favorite bots tied to cultural heritage materials along with the creator and numbers of followers associated with each. In creating this list, the method was to find any and all Twitterbots in existence that are associated with a Gallery, Library, Archive, or Museum (GLAM) that focus on sharing images from established collections on a regular basis. While sources like Veale and Cook’s bot index were consulted to find more instances of GLAM bots, ultimately the bots noted below came from my own efforts over the past year and a half to identify bots similar in function to @UTKDigCollBot. Other Twitterbot listings focus on bots that meet different goals than those typically desired by GLAMs.
This table shows that it is possible to reach hundreds, thousands, or even occasionally tens of thousands of people with a Twitterbot. At the very least, this means that having a Twitterbot raises the likelihood that the public will encounter content from your institution. Both @pomological, which shares images from the USDA Agricultural Library, and @boschbot, which shares tiny sections of paintings by Hieronymus Bosch, are noteworthy bots in terms of their total followers. Every bot listed creates posts that include an image and text, typically a title pulled from the metadata. Because the bots essentially tweet out existing data, they are characterized as “feed bots” (Veale and Cook 2018). These bots are passive in nature, in that they do not react to other users on Twitter. Outside of the cultural heritage realm, there are “watcher bots” that actively respond to the tweets of public Twitter users based on some criteria. For instance, @StealthMountain seeks out tweets with the phrase “sneak peak” and asks users if they’ve made a spelling mistake (e.g. “sneak peek”). In libraries and museums, it seems that this kind of interaction might be frowned upon as invasive as no instance of this type of bot in those environments exists. A 2012 study of academic library Twitter use broadly found that very few libraries use the social media platform for two-way conversation (Del Bosque et al. 2012). Beyond anecdotal evidence, there is no research showing why GLAMs have limited direct interaction with followers, but Twitter accounts managed by cultural heritage institutions routinely show the same distanced behavior.
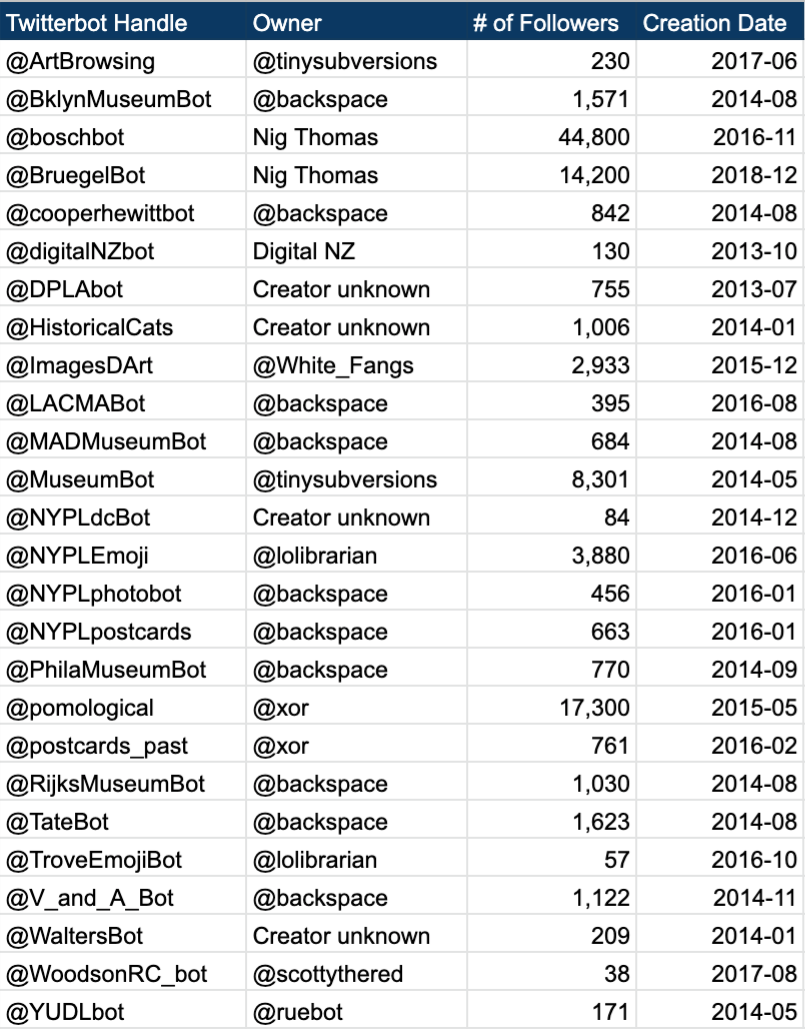
Table 1. Cultural heritage Twitterbots listed alphabetically (March 2020).
Of those listed, @NYPLEmoji is the only bot that breaks away from the “feed bot” characterization. When users tweet an emoji to @NYPLEmoji, the bot returns an image from the New York Public Library’s collections that relate to the emoji initially sent. For instance, if a user tweets a calendar emoji, a photograph or drawing in NYPL’s collections that depicts a calendar will be tweeted. While often simply a matter of visually matching, occasionally there’s less of a direct relationship between the visual content of the emoji and the resulting tweet. For example, in response to the “face with tears of joy” emoji, @NYPLEmoji sent a piece of sheet music titled “Tears of joy and sorrow” (Figure 1). As all of the emoji matches were hand coded, relationships like these are possible. A JSON file of emojis and their matching collection items can be found on Lauren Lampasone’s GitHub page for the bot [1].

Figure 1.Tweet from @NYPLEmoji posted on 01-08-2020
Although randomness is a key feature of many feed bots, posts by @NYPLEmoji are the result of a considerable amount of human control. Beyond having a curated list of emoji-image matches, the code also includes a few exclusions. In the NYPL-Emoji-Bot GitHub repository a file named “blacklist.json” shares five emojis that the bot will not post a reply to. The list includes the gun, knife, bomb, no one under eighteen, and poop emojis. As long as content can be programmatically identified, it is possible to exclude sensitive or undesired content from a Twitterbot.
One interesting feature of Twitterbots, supported by the table above, is that typically creators of Twitterbots have no direct affiliation with the institutions whose content they are promoting. In most instances, this information on the creator is given in the Twitterbot’s profile in order to be transparent. For instance, Darius Kazemi, perhaps better identified here as @tinysubversions, created two of the bots listed in Table 1. Ten of the bots were also created by John Emerson, whose handle is @backspace. Kazemi is a computer programmer and artist who previously organized the Bot Summit. Emerson is the founder of backspace, a design consultancy, and he identifies himself an “activist, graphic designer, writer, and programmer” [2]. Both individuals have strong interests in art and the public good and try to share the open access resources cultural heritage institutions make available. While individuals like these are disseminating images from major art museums, archives, and aggregators across the Twittersphere, smaller institutions are not as likely to be represented. Even when collections from an institution are represented in an aggregator bot, like @DPLAbot, this type of an account does not have the same focus as an institution-specific account. While Kazemi, Emerson, and others should be applauded for promoting (and having fun with) the digital content of GLAMs, I would urge cultural heritage institutions to actively share their own digital materials. This gives institutions more control over what materials are being shared and how, while also making it easier to attract users through an institution-specific account that has targeted content.
Copyright and Image Sharing
One of the major concerns most librarians have when dealing with digital collections is copyright. So, if you decide that you do want to invest the initial effort in creating a Twitterbot, you may likely ask if you need to consider any legal issues. First, before posting any digital items online, the institution should have ascertained whether or not it has the right to do so. Assuming this work has been done, creating a Twitterbot that further promotes these materials should cause no problems. Due to Open Graph tags [3], you can “share” an image on Twitter without actually uploading any content to the site. The link you include from your digital repository will allow a preview of the image to appear on Twitter. Therefore, if you have the right to share the image on your local repository, you have the right to create a Twitterbot that shares image previews through links. In a society focused more and more on “user-found” rather than “user-created” content (Carpenter 2013), Twitterbots are a legal source of information for users to both digest and retweet.
Method
To create UTK’s Digital Collections bot, I began by creating a new Twitter account and
activating developer access for it on the Twitter developer website [4]. Within Twitter apps, you
can retrieve all of the codes needed to interact with Twitter’s API (Consumer Key,
Consumer Secret, Access Token, and Access Token Secret). I used PyCharm as my
IDE for Python and Heroku for hosting. If you are interested in a less technical solution
for a Twitterbot at your institution, there are several options you can consider. Tracery [5] and Google sheets [6] are two options that have extensive documentation already present online. In terms of documentation, I personally benefited greatly from Jeanette Sewell’s presentation “The Wonderful World of Bots” given for an online Amigos Library Services conference [7] as well as Scott Carlson’s “You Should Make a Twitter Bot for Your G/L/A/M’s Digital Collection(s) [8].
In order for you to be successful in making a Twitterbot, it is critical that certain technologies have been implemented for your digital collections. First and foremost, Open Graph tags must be present in the metadata online for each record page in order for an image to appear when you tweet a link. To check and see if you have Open Graph tags, simply go to “View Page Source” or test a link to a digital object in Twitter’s card validator [9]. If you have Open Graph tags, you will see some of the following tags in your page source:,, etc. Twitter’s card validator is also very simple to use to check this. Simply insert a link to a digital object to preview what the tweet will look like. The validator also indicates how many metatags are present and reports if the Twitter card can be loaded successfully. When first beginning this project, Open Graph tags were not present in UTK’s Islandora records. Our Digital Initiatives department helped add these tags using Islandora’s Social Metatags module [10]. This addition was not only helpful to the Twitterbot, but enhanced the use of Digital Collections links across our social media outlets through the inclusion of more images.
Another technology that I relied heavily upon is the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH). In order to avoid having to manually add links and titles to a spreadsheet, you should find an automated way of generating this information. For institutions that contribute to the Digital Public Library of America (DPLA), the organization’s API [11] is a great alternative to OAI-PMH. Visit @dpl_eh (a Canadian Twitterbot) to see how this can be executed. Code is also present online in GitHub for this implementation [12].
Following the precedent set by many of the cultural heritage feed bots mentioned in the previous section, I decided to keep the output of the Twitterbot simple and focused on highlighting Digital Collections content. Each tweet included the title taken from the metadata followed by the “- Find it at:” with the link. Because Open Graph tags have been implemented, the image shows rather than the link text. Below is an example tweet that demonstrates the daily product the Twitterbot shares (Figure 2). The complete code for @UTKDigCollBot can be found on GitHub [13].
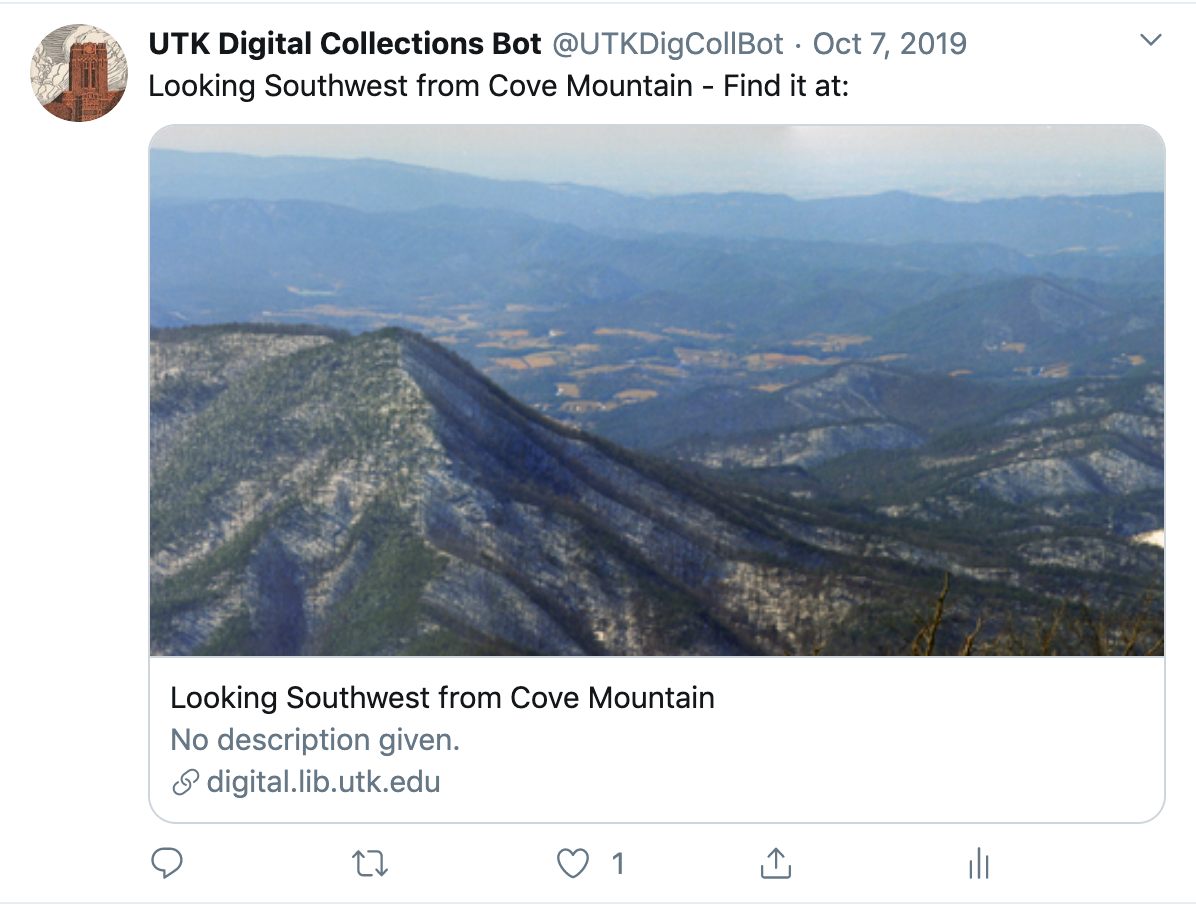
Figure 2. Example tweet from @UTKDigCollBot.
Challenges
While there is significant documentation in existence to help guide the creation of bots, several issues arose in my work that required novel solutions. In initially testing the bot, I found that some of the images I shared on Twitter were appearing grainy when posted. By going to the webpage and opening “View Page Source” to look at the files directly, I discovered that these images were thumbnails rather than full jpegs. Upon looking through the collections affected by this issue, I quickly discovered that this was due to the Islandora content model selected for each collection. Collections using Islandora’s compound or book models had thumbnails present in their Open Graph tags while collections using the large image content model supported high quality image sharing. To address this, I altered my program so that it only selected random images from particular collections by including only a portion of our OAI sets. As the Libraries continue to add collections, I also need to update the code to include this OAI set name so that this new content finds its way into the Twitter feed. Other Twitterbots seem to face similar image quality issues, but not all decide that displaying high quality images is important. The feed for @DPLAbot for instance, includes many grainy images (Figure 3), though this may be because the varied nature of its content from all DPLA institutions made it impossible to troubleshoot this problem effectively.

Figure 3. Fuzzy image from @DPLAbot reflecting the importance of considering image quality.
Being able to select particular collections to include in the Twitterbot also made it possible for me to avoid collections with known metadata issues and discover new issues. Throughout my time working at the University of Tennessee, I have worked to remediate metadata for all of our collections following migration to Islandora and a transition from following the Dublin Core schema to MODS. Through completing this project, I also became aware of new metadata issues that I needed to address in remediation. For instance, Figure 2 demonstrates that there are metadata records in our collections that have no abstract or description value. Because there is no value given in the MODS metadata, no description value can be included in the Open Graph tag. This results in the text below the image stating, “No description given.” While the visual content of the image may be able to overcome this lack of metadata and still gain the interest of the user, posting objects without descriptions likely does not promote engagement and may reflect badly on the institution creating the records. Since starting the Twitterbot, I have pointed to some of the empty descriptions highlighted through the Twitter posts as a way to advocate for spending more time to provide this information in metadata creation. Even a blanket description used for each and every item in a collection provides users with more context than “No description given.”
In addition, having the ability to select particular sets has also made it possible to exclude potentially sensitive or problematic content. Like many institutions, the University of Tennessee’s Digital Collections include racist content. For instance, within the university’s collection of sheet music, there are numerous illustrations of minstrelsy with degrading lyrics. Photographs of blackface are also present. While these digital objects are made publicly available in the Digital Collections interface for research purposes, I felt strongly that highlighting individual works of this type without context on Twitter would both portray the university in a negative light and not meet the expectations of bot followers. In the same way that @NYPLEmojiBot forbids image results from certain emojis, I decided to not include any sets that had content which might be offensive. While I believe that this type of material needs to be preserved and shared as part of the historic record, it seemed unproductive to share these images on Twitter without being able to provide additional information.
The most challenging aspect of this project was figuring out how to host the bot so that it was truly automated and did not require any intervention. A simple method is to run your program on a computer that is always on, although posts may be interrupted due to computer maintenance. Rather than relying on a spare computer or using library server space, I used Heroku, a free cloud application program, to run my Python program continuously. Running a program periodically can be achieved in Heroku by using either apscheduler or the Heroku scheduler add-on [14]. Heroku scheduler allows you to run jobs at pre-established intervals while apscheduler is more customized and allows you to specify any time or frequency for your job. While more complex than necessary for my needs, I am running UTK’s Digital Collections bot using apscheduler so that it is more flexible in the future. Another method for hosting you can explore is Amazon Web Services (AWS) Lambda [15].
Titles also posed an additional metadata-related obstacle to be overcome. Initially after completing the code and implementing the Twitterbot, there were times when no tweet would be posted for the day. Looking through error messages in the log on Heroku, it was determined that the code did not account for the possibility of multiple titles being returned. When additional handling was added to account for a list of titles being returned, as the metadata often contained both supplied and transcribed titles, the program successfully ran again. Figure 4 shares the code that handles these possibilities. In the “get_title” function, the first “if” statement accounts for the metadata that contains only one title. In this case, the function will retrieve a key-value pair following the dictionary data type. The second “if” statement is included to find instances in which multiple strings are associated with the title field in the form of a list. Only the first title in this list is retrieved, as is indicated by including an index of zero. Finally, an else statement is included to deal with the possibility of the title data not conforming to either a dictionary or a list format.
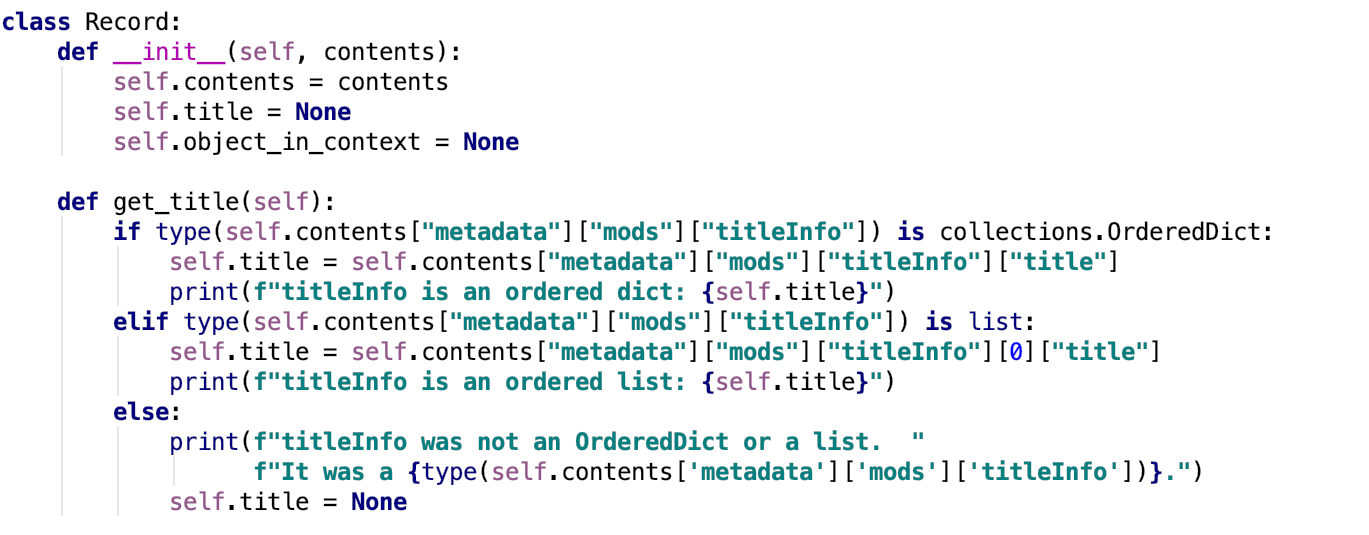
Figure 4.Handling multiple data types possible for title values.
Assessment
At the writing of this article, UTK’s Digital Collections bot had been regularly posting for nineteen months. In this time, the bot gathered a total 100 followers. Twitter analytics were used to gather more granular information about engagement with the Twitterbot [16]. A total of 46,197 impressions were collected, resulting in 838 engagements. An “impression” simply refers to the number of times users saw the tweet while an engagement records a more active interaction. On average, a single post resulted in 77 impressions and 1.5 engagements. The 838 engagements are composed of the following actions: 459 URL clicks, 246 likes, 62 expand details clicks, 51 user profile clicks, and 19 retweets. These numbers show that the Twitterbot brought 459 users to the Libraries Digital Collections website. Some of these users potentially were viewing the site for the first time. The most popular link was clicked a total of nine times and was associated with a sketch from the Anna Catherine Wiley sketches collection titled “Charcoal figure drawing of woman reclining” [17].
While the bot did gain interest from the Twittersphere, active engagement through comments were completely lacking. A few retweets elicited written responses from users, but no comments were made directly on @UTKDigCollBot. Given that the objective for this bot was to increase the visibility of the University of Tennessee’s Digital Collections without daily upkeep, not having to respond to comments can be seen as an asset. Still, for those that want to foster an active conversation through Twitter, a bot that simply posts materials may not meet your needs.
The metrics reported above did meet expectations, which, admittedly, were somewhat low as I was unsure what effect the bot might have given the paucity of information on the engagement library Twitterbots have produced at other institutions. Discussions have been had in the past on ways to more fully integrate the Twitterbot’s content with the Libraries’ official handle (@UTKLibraries), but the planning and curating of tweets for this main feed has proven to be a bit incongruent with the random tweets of @UTKDigCollBot. On occasion though, randomness and meaning have collided, which has made the tweets even more special. For instance, the Twitterbot tweeted an image from the Virginia P. Moore collection the same day a colleague was giving a presentation on it. When this happens, retweets and smiles follow.
Conclusion
This paper has demonstrated that creating a Twitterbot is an achievable goal for librarians. While they can be technical undertakings, there are also lower barrier solutions that can be implemented using Tracery or Google Sheets. Currently cultural heritage Twitterbots typically simply share content from cultural heritage institutions, but there are instances that demonstrate that GLAMs can create more dynamic and interactive feeds. @NYPLEmoji is an example of a cultural heritage bot that both matches visual content and elicits active posting from followers. Going forward, it would be helpful to better define what the engagement goals of Twitterbots should be for a particular institution to determine if these creations are meeting their purpose. The fact that many cultural heritage bot creators have no direct association with the institutions whose content is being tweeted suggests that GLAMs have yet to fully embrace this technology and that bots have potential to be a fruitful opportunity for outreach. It also indicates that for many the creation of a Twitterbot is a fun technical experiment more akin to art than a part of a formalized social media campaign. And, as Veale and Cook’s writings advocate, Twitterbots at their core will always have a bit of whimsy. Now that you can make a Twitterbot, it is important to seriously consider what it is you hope to achieve.
Acknowledgements
Considerable thanks are due to Mark Baggett, Department Head of Digital Initiatives at the University of Tennessee at Knoxville, for making @UTKDigCollBot a reality. His guidance in coming up with a solution for hosting as well as his development of the code were essential contributions to this project.
About the Author
Meredith L. Hale is the Metadata Librarian at the University of Tennessee, Knoxville. She is responsible for managing the creation and sharing of special collections metadata and contributing to the state’s DPLA service hub and the Digital Library of Tennessee (DLTN) Committee.
Notes
[1] https://github.com/lolibrarian/NYPL-Emoji-Bot
[2] https://backspace.com/is/in/the/house/address.html
[3] http://ogp.me/
[4] Set up developer access at https://developer.twitter.com/en/apps
[5] https://cheapbotsdonequick.com/
[6] http://www.zachwhalen.net/posts/how-to-make-a-twitter-bot-with-google-spreadsheets-version-04/
[7] https://www.amigos.org/node/4753
[8] http://www.scottcarlson.info/you-should-make-a-twitter-bot
[9] https://cards-dev.twitter.com/validator
[10] https://github.com/Islandora-Labs/islandora_social_metatags
[11] https://pro.dp.la/developers/api-basics/
[12] https://github.com/ruebot/dpleh
[13] https://github.com/mlhale7/UTKDigCollBot
[14] https://devcenter.heroku.com/articles/clock-processes-python
[15] https://aws.amazon.com/lambda/
[16] https://analytics.twitter.com/
[17] https://digital.lib.utk.edu/collections/islandora/object/acwiley%3A322
Bibliography
API basics [internet]. DPLA; [cited 2020 Feb 6]. Available from: https://pro.dp.la/developers/api-basics/
AWS Lambda [internet]. Seattle (WA): Amazon; [cited 2020 Feb 5]. Available from: https://aws.amazon.com/lambda/
Buckenham G. Cheap bots, done quick! [internet]. [cited 2020 Feb 4]. Available from: https://cheapbotsdonequick.com/
Carlson S. You should make a Twitter bot for your G/L/A/M’s digital collection(s) [internet]. [cited 2020 Feb 6]. Available from: http://www.scottcarlson.info/you-should-make-a-twitter-bot
Carpenter C. 2013. Copyright infringement and the second generation of social media: why Pinterest users should be protected from copyright infringement by the fair use defense. Internet Law 16.7:9-21.
Del Bosque D, Leif SA, Skarl S. 2012. Libraries atwitter: trends in academic library tweeting. Reference Services Review 49(1): 165-183.
Edwards C, Edwards A, Spence PR, Shelton AK. 2014. Is that a bot running the social media feed? Testing the differences in perceptions of communication quality for a human agent and a bot agent on Twitter. Computers in Human Behavior 33:372-376.
Emerson J. Backspace [internet]. New York (NY): Backspace; [cited 2020 Feb 1]. Available from: https://backspace.com/is/in/the/house/address.html
Hale M. UTKDigCollBot [internet]. San Francisco (CA): GitHub; [updated 2020 March 10; cited 2020 March 10]. Available from: https://github.com/mlhale7/UTKDigCollBot
Lampasone L. NYPL Emoji Bot [internet]. San Francisco (CA): GitHub; [updated 2018 July 24; cited 2020 March 12]. Available from: https://github.com/lolibrarian/NYPL-Emoji-Bot
The Open Graph protocol [internet]. [cited 2020 Feb 5]. Available from: http://ogp.me/
Sewell J. The wonderful world of bots: innovative ways to automate library marketing with metadata and Twitter. Paper presented at: Amigos Library Services, Innovating with Metadata 2017.
Ruest N. dpleh [internet]. San Francisco (CA): GitHub; [updated 2017 Jul 9; cited 2020 Feb 2]. Available from https://github.com/ruebot/dpleh
Scheduled jobs with custom clock processes in Python with APScheduler [internet]. San Francisco (CA): Heroku; [updated 2018 Aug 2; cited 2020 Feb 6]. Available from: https://devcenter.heroku.com/articles/clock-processes-python
Twitter card validator [internet]. San Francisco (CA): Twitter; [cited 2020 Feb 3]. Available from: https://cards-dev.twitter.com/validator
Twitter developer apps [internet]. San Francisco (CA): Twitter; [cited 2020 Mar 9]. Available from https://developer.twitter.com/en/apps
Veale T, Cooke M. 2018. Twitterbots: making machines that make meaning. Cambridge (MA): MIT Press. p. 19-29, 351-352.
Weigel B. Islandora social metatags [internet]. San Francisco (CA): GitHub; [updated 2019 Mar 28; cited 2020 Feb 4]. Available from: https://github.com/Islandora-Labs/islandora_social_metatags
Whalen Z. How to make a Twitter bot with Google spreadsheets (version 0.4) [internet]. Fredericksburg (VA): University of Mary Washington; [cited 2020 Feb 2]. Available from: http://www.zachwhalen.net/posts/how-to-make-a-twitter-bot-with-google-spreadsheets-version-04/
Wiley AC. Charcoal figure drawing of woman reclining [internet]. Knoxville (TN): University of Tennessee, Knoxville. Libraries; [cited 2020 Feb 2]. Available from: https://digital.lib.utk.edu/collections/islandora/object/acwiley%3A322

Subscribe to comments: For this article | For all articles
Leave a Reply