by Katharine Frazier
Introduction
The ability to quickly identify purchase options for in-demand books can help libraries better meet and anticipate their users’ needs. At the NC State University Libraries, the Collections & Research Strategy department conducts a monthly audit of items with multiple hold requests. We also keep track of items that are lost, missing, or have been checked out for more than one calendar year. These reports are created from a combination of our local holdings data and data from our print and ebook vendor GOBI (formerly Yankee Book Peddler): each item in the report is paired with purchase information, such as price and format. Collection managers use these reports to find instances where purchasing a new copy, whether electronic or print, can alleviate high demand and broaden access to our users.
While reports are an important part of making sure users can access the resources they need, compiling them is a manual, time-consuming task. This article discusses a new approach to creating reports through web scraping with Python, which expedites the collection of data from GOBI and greatly reduces the hands-on time required to create each report.
Background
Staff in Collections & Research Strategy are responsible for compiling two monthly reports known as the “Lost, Missing, Checked Out Report” and the “Multiple Holds Report.” These reports are created by downloading lists of lost, missing, checked out, and held items from our ILS, Sirsi. An average report contains up to several hundred items. To identify suitable print or ebook copies available to buy, each item is searched in GOBI. The final report includes holdings data (publication date, number of circulations, home location, etc.) for each item and, where available, purchase data (format, publication date, price). Whenever possible, this report includes purchase information for the newest available edition of an item: for example, if we have lost the 2014 edition of an item, the report will prefer data for a 2019 edition.
Unfortunately, GOBI does not offer an API to make searching an easy, automatic process. Despite expressing an interest in an API to our GOBI representatives, they have not shared any plans to develop one. Because of this, library staff have done all of this work by hand for years: searching, finding the best match, and manually inputting purchase data into a spreadsheet. This process often took anywhere from 10 to 15 hours a month per report. Most of this time was spent searching for items in GOBI, which can be a lengthy and imperfect process.
A laundry list of obstacles
GOBI has many qualities that make it a great resource for collection managers, but the search experience can sometimes be difficult. One significant cause of this is the default GOBI search bar, which appears at the top of each GOBI webpage. This bar only allows users to search by any one of the following: Keyword, Title, ISBN, Author/Editor, Subject, or Keyword and Table of Contents. For some items, searching by title or keyword is fine because the title is unique enough to retrieve only results for that particular item. For items with more general titles, this is a very inefficient way to search. Regardless of a title’s uniqueness, searching by title or keyword often returns an array of results that vary in relevancy. While GOBI allows users to sort (but not filter) these results by author name, this requires a user to spend time clicking through result pages until the desired author is found. To more quickly find accurate results, we set out to find a better way of searching.
Initial attempts to identify a better search experience in GOBI included using an item’s ISBN as a search term rather than title. While this did a better job of producing exact matches for a given item, we realized that GOBI does not provide links between different editions of items. Since we prefer the newest available edition for all items, searching by ISBN did not work.
We settled on a title and author search to access the most accurate results. To search by title and author, a user must navigate to the “Standard” GOBI search, which is located in the website’s search-related drop-down menu. While this produces higher-quality results, it causes unnecessary delays and frustration. When searching for hundreds of items, taking time to navigate to a separate search page can add up.
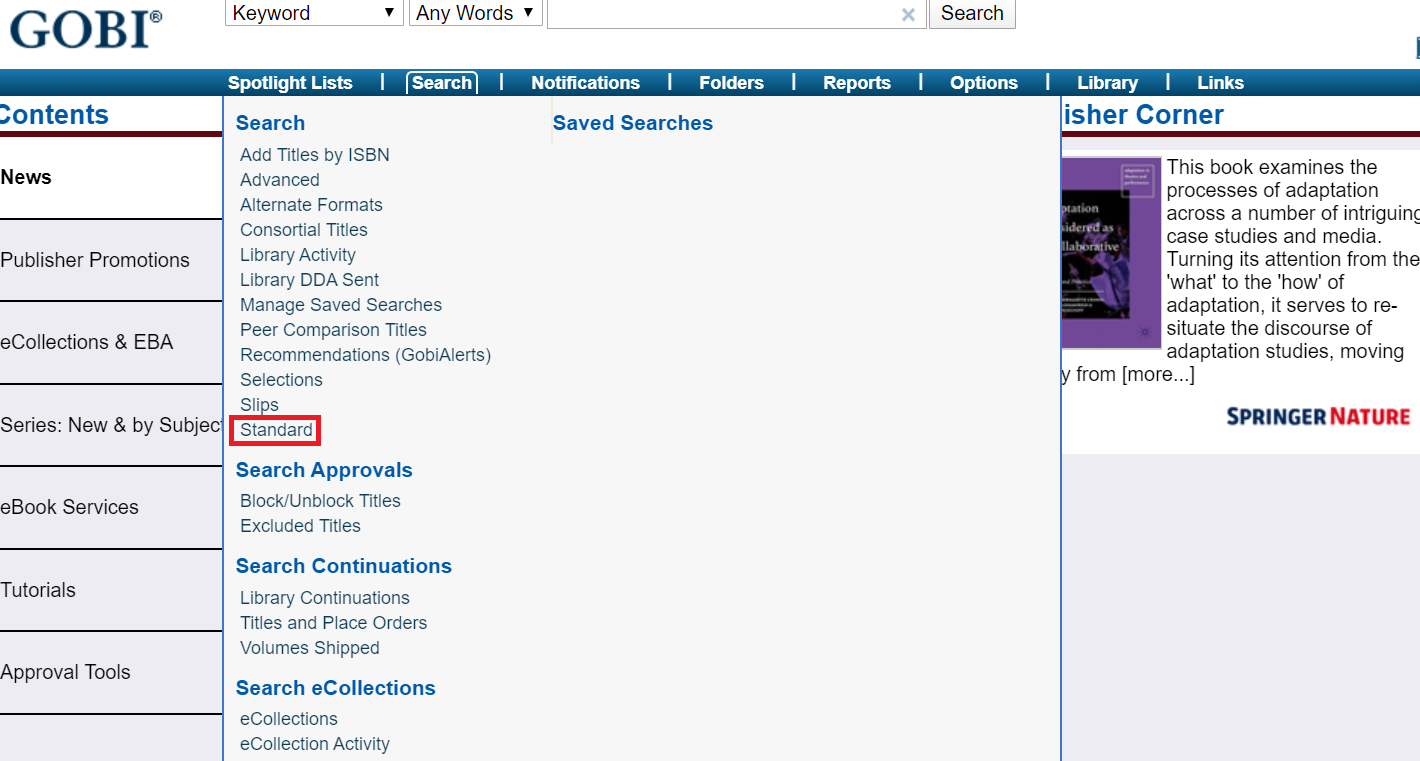
Figure 1. GOBI’s “Standard” search is only accessible through the Search dropdown menu.
Even though the standard search improved result quality, it did not remove all issues with the accuracy of results. GOBI orders results by “relevancy,” which means results are not sorted by date or edition number – the method that we would prefer to quickly gather information for our reports. A user must manually sort the results by publication date through another dropdown menu of options. Just like the separate “standard” search page, this process eats up valuable seconds and greatly increases the amount of time it takes to collect data for our reports.
With all of these issues creating delays in the search process, we decided to try a new approach. What if we didn’t have to do any of this searching by hand anymore – could this be automated?
Developing a Scraper
Before beginning to design our scraper, we conducted research to see if any other libraries had run into and solved a similar problem. However, we found no scripts or tools to fit our needs.
Because the NC State University Libraries is home to a community of Python users, we decided to explore Python as a potential avenue for automating these GOBI searches. Our process for developing the scraper consisted of identifying what the scraper would need to accomplish, bridging the gap between our ILS (SirsiDynix) and GOBI, and troubleshooting the scraper’s access to GOBI’s internal data.
An important note is that using web automation to scrape GOBI is not in violation of our agreement with EBSCO, GOBI’s parent company. Another consideration is that only existing GOBI customers will be able to use or adapt the following script. All information extracted from GOBI using our script is accessible only through logging in with an authenticated username and password.
Bridging the gap between ILS and GOBI
Before beginning to write our script, we determined that data from our reports of in-demand items would have to be cleaned before it could be searched in GOBI. Reports are drawn directly from our ILS, which outputs title information in a way not compatible with GOBI’s search functions.
Without cleaning, a title from one of our reports might read: Database systems : the complete book / Hector Garcia-Molina, Jeffrey D. Ullman, Jennifer Widom. Titles in Sirsi are paired with author(s), separated by a forward slash. When an unformatted title is passed into a GOBI search, GOBI will return either zero results or only results with the author’s name in the title, such as Studyguide for First Course in Database Systems by Ullman, Jeffrey D.
Fortunately, cleaning data from our ILS involved only a few steps. In Excel, we replaced occurrences of “/*” in the title column with a blank space. The wildcard removes all author information following the forward slash. Then, we used Excel’s in-built =TRIM(cell) formula to remove blank spaces in the title string. While this quick process is currently done by hand, it is a candidate for future automation.
Writing the script
The most important function our scraper needed to have was the ability to access and navigate web pages. We identified Selenium, a Python package that automates web actions, as the best module to use in developing our scraper thanks to its ease of use and robust documentation. Selenium was chosen over other modules for its focus on automation capabilities; other modules, like BeautifulSoup and Scrapy, are more focused on data extraction, and we needed to quickly log into, navigate, and engage with the GOBI website. Selenium, which interacts with web browsers like a human would, relies on webpages’ internal HTML structure (CSS, Xpath) to navigate pages and engage with interactive elements (links, search boxes, radio buttons).
We also installed ChromeDriver, a tool that allowed us to automate Chrome rather than Selenium’s default browser, Firefox. While this choice was made because we prefer to work with Google Chrome at NC State, the scraper would be equally operable in other browsers. The following code demonstrates how the script establishes a web browser window, navigates to GOBI’s homepage, and locates the input boxes to which it needs to send username and password information.
#establish webdriver (ex: ChromeDriver)
browser = webdriver.Chrome(r'PATH-TO-WEBDRIVER')
#tell browser to fetch website
browser.get('http://www.gobi3.com')
#find username field, send username
userElem = browser.find_element_by_id('guser')
userElem.send_keys('USERNAME')
#find password field, send password
passwordElem = browser.find_element_by_id('gpword')
passwordElem.send_keys(‘PASSWORD’)
passwordElem.submit()
After generating its own instance of a browser window, the scraper logs into GOBI and begins searching for paired titles and authors. This information is supplied from our monthly reports of in-demand items. To pair titles and authors, we drew title and author information from the report into two lists and created a dictionary from these lists.
#create lists for title, author, and year from original file titlelist = [] authorlist = [] datelist = [] #read in original file of report output wb = pd.read_excel(r'PATH-TO-REPORT.xlsx') #append column values from original file to lists titlelist = wb['title'].values authorlist = wb['author'].values datelist = wb['year'].values #create dictionary to match titles with authors zipObj = zip(titlelist, authorlist) titlesandauthors = dict(zipObj)
To find the most accurate results, our scraper searches via GOBI’s Standard search page. The script works by looping through the dictionary of paired titles and authors and completing the following actions for each item in the dictionary. A try and except clause is used to account for items that did not include author information in the original report.
#Begin iterating through dictionary of title/author in GOBI
for k, v in titlesandauthors.items():
#find search dropdown, click it
searchElem = browser.find_element_by_id('menu_li2')
searchElem.click()
#find "standard" option in search dropdown
standardElem = browser.find_element_by_xpath('/html[1]/body[1]/div[1]/div[2]/div[1]/div[12]
/a[1]')
standardElem.click()
#find title search bar on the standard search page: account for slow load time with wait
try:
titleElem = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="txttitle"]')))
except:
Continue
#send title from dictionary
titleElem.send_keys(k)
#find author search bar on the standard search page
authorElem = browser.find_element_by_xpath('//*[@id="author"]')
#send author from dictionary; account for error if no author present
try:
authorElem.send_keys(v)
except TypeError:
pass
We initially struggled with identifying the correct web element to use while scraping data from result pages. Each result in GOBI is housed in a separate HTML cell, making it difficult to scrape a page of results for all titles, all publication years, and all prices. After a few failed attempts to grab these individual data elements and merge them into a dictionary, we decided to instead scrape the entire page of results in one block. This action builds a web element containing a list of all results. The script then iterates through this list of items and turns each resulting web element into a text element.
#find all results on results page
itemElem = browser.find_elements_by_xpath('//div[@id="containeritems"]/div')
#begin iterating through the results, and transform each web element to text element
for item in itemElem:
individualitem = item.text
Next, the script extracts title, publication date, format (print/ebook), and price strings from each text element and determines the “best” fit out of all captured results. To do this, we created a series of regular expressions that search for patterns matching how GOBI formats each of these data points. Data extracted from these regular expressions are assigned the variables of “title,” “binding,” “date,” and “price.”
Once clean data points are extracted, we narrow the list of results to only those matching the original item from our report. Because our script has only gathered results with the correct author, we narrow by matching on title strings. For this, we decided to use a Python module named Fuzzywuzzy, which calculates the difference between two given strings with the Levenshtein Difference. Because of slight formatting differences between titles from our ILS and titles in GOBI, the threshold for a match was set at 70%. We found that stricter thresholds caused legitimate matches to be excluded. When the script finds a title match, the title and its accompanying data (binding, date, and price) are sent to lists. Lists are then combined into a dictionary called “choices.”
#apply fuzzy string matching to find accurate matches (not 100 to account for punctuation)
ratio = fuzz.partial_token_set_ratio(k,title)
#send matches to lists; match set at 70% for best results
if ratio > 70:
namelist.append(title)
bindinglist.append(binding)
yearlist.append(date)
pricelist.append(price)
#add lists to results dictionary
choices.update({'title':namelist})
choices.update({'binding':bindinglist})
choices.update({'date':yearlist})
choices.update({'price':pricelist})
After trying to proceed using this dictionary, we realized a need to have a more flexible format that would allow us to sort and split results. We identified Pandas, a package that creates dataframes (flexible sets of data presented in rows and columns) as the ideal tool to help us with our next steps. From the “choices” dictionary, we create a dataframe representing all of the GOBI results. Then, we split this into two sub-dataframes representing print-only and electronic-only titles.
#create initial dataframe gobidf = pd.DataFrame(choices) #create sub-dataframe for ebook results ebookoption = gobidf[gobidf['binding'] == 'Binding:eBook'] #create sub-dataframe for print results bestprint = gobidf[(gobidf['binding'] == 'Binding:Cloth') | (gobidf['binding'] == 'Binding:Paper')]
Because titles from GOBI are often formatted differently than titles from our ILS, the script runs another fuzzy string match to swap out the GOBI titles with the properly-formatted titles from our ILS. This process makes the eventual merging of the print and ebook dataframes with our original report easier by ensuring a merge on the title column will not result in mismatches.
#create list to contain confirmed correct print titles
correcttitles=[]
#compare each paper title to original title, keep only best match
for x in printtitles:
correct = process.extractOne(x,sirsititles)
correcttitles.append(correct[0])
#swap out list of print titles for list of confirmed correct print titles
bestprint['title'] = pd.Series(correcttitles)
In some cases, multiple matching results for an item are included in each dataframe. For any items with multiple results, we wanted to extract the “best fit” result. We defined “best fit” as the item with the most recent publication date. Using Pandas, this turned out to be a simple task. We applied a descending sort to the date column and removed all duplicate titles, leaving us with only the most recently published item. This step is repeated for both print and electronic dataframes.
#sort dataframe by date of publication, with newest of each title at top bestprint.sort_values(by=['title','Publication year in GOBI (Print)'], ascending=False, inplace=True) bestprint.drop_duplicates(subset='title', keep='first', inplace=True)
Finally, we merge our deduplicated dataframes with our report, which has been read into a dataframe named “original.” We use an outer sort, meaning that information from both dataframes will be present in the new, merged dataframe. By merging on title, we ensure that the information gathered in the two GOBI dataframes will align with the correct rows in our report dataframe. Once merging is complete, the dataframe is sent to Excel using Pandas’ to_excel function.
dfmerge = original.merge(bestprint,on='title',sort=False,left_index=False,right_index=True,copy=False, how= 'outer') #merge ebook dataframe with other merged dataframe (print & original combined) newmerge = dfmerge.merge(ebookoption, on='title', sort=False, left_index=False, right_index=True, copy=False, how='outer') #send to excel file newmerge.to_excel(r'PATH-TO-OUTPUT.xlsx')
This leaves us with a document that includes original holdings data from our ILS, paired with information about new copies in GOBI (price/publication date).

Figure 2. A sample of the script’s output displaying holdings information and purchase information. Not pictured are several columns to the right including total # of circulations, # of holds, home location, and current status for each item.
Troubleshooting
One significant issue we ran into while developing the script was the length of time certain searches in GOBI took to complete. Selenium is willing to wait for pages to load, but eventually it reaches a limit and times out, causing the script to return an error. To work around this, we included several time-out exceptions that, whenever a timeout exception occurs, override the exception and keep the script running.
except selenium.common.exceptions.TimeoutException:
pass
Including these exceptions allowed GOBI enough time to fully load its results pages. The timeout exceptions most often occurred while searching for items with generic titles, such as Microbiology or even Michelle Obama’s biography Becoming.
Another issue we experienced was Selenium working much more quickly than GOBI could load. Sometimes, GOBI would load a page (such as the Standard search page) but not display all page elements immediately. Selenium, thinking the page had loaded, searched for a given element and produced an error when it couldn’t find it. We solved this by using an explicit wait, which told Selenium to pause until an expected condition was met.
titleElem = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="txttitle"]')))
In this example, the expected condition is the title element’s XPath being present on the page. Once this element loads on the page, Selenium can continue. Until then, it is forced to wait.
Impact of the Script
Since developing this scraper, the time spent per month compiling reports has been drastically reduced. A task that used to take 10 to 15 hours a month now takes only 30 minutes of manual time. This manual time includes data cleaning and writing up an email summary of the reports, which is shared out to the Libraries’ Collections Interest Group (CIG).
When the reports were compiled manually, they would be sent out to the Libraries’ CIG mid-month. Now, the group receives access to them in the early days of the month. This gives collection managers more time each month to identify what needs to be purchased to fill user needs.
Because Selenium operates in its own browser window and can run silently in the background, the implementation of this script has also greatly increased the capacity of staff to spend time on other projects. It has even allowed for the inclusion of “creative time” to imagine new projects and applications for Python.
Conclusion
Since GOBI does not offer an API, we used Python’s powerful automation and data modules to design our own querying tool. While this scraping tool was created to address the unique needs of the NC State University Libraries, this tool could be adapted to other libraries’ specifications. The scraper currently searches for both print and electronic copies; depending on a library’s collection development plan, this could be reduced to just print or just electronic copies.
For libraries interested in providing maximum access to e-resources, the script’s method for choosing electronic copies could be altered. GOBI displays these options in alphabetical order of provider: for instance, EBSCO will always come before ProQuest. Within each provider, choices are arranged in ascending order by the access model: 1 user copies are displayed before 3-user and unlimited-user copies.

Figure 3. Example of electronic purchase options for an item in GOBI.
When considering electronic purchase options, our scraper defaults to the first choice available for each “best fit.” If a library was interested in only choosing unlimited user copies, one could refine the script to select those copies where available instead of the first option.
Areas for future exploration include automating the data cleaning process and adding a function to automatically select items and send them to a GOBI folder. This step would expedite the ordering process for libraries not wanting to make title-by-title purchase decisions. Our script produces a report that is still reviewed by a team of collection managers, but libraries with smaller collections departments or fewer staff could potentially skip this step.
A complete script for automating searches in GOBI and extracting purchase data can be found on the author’s GitHub page.
About the Author
Katharine Frazier is an incoming Library Fellow at the NC State University Libraries, where she has previously served as a University Library Technician in the Collections & Research Strategy department.

Subscribe to comments: For this article | For all articles
Leave a Reply