by Greg Sohanchyk and Dan Briem
Project Rationale
While drafting its latest three-year strategic plan, the library sought to gain a holistic understanding of its users. The library conducted a survey to give its users an opportunity to describe themselves, their needs, and their recommendations for the library’s future. Furthermore, as a complement to the survey, we wanted to perform an additional analysis using existing data to see what else we could learn about the library’s users.
We first discussed what we wanted to learn from this additional analysis and established the following objectives:
- Identify where in Harrison each building’s cardholders live.
- Identify where active cardholders live (i.e., those who have used their card recently).
- Identify where non-active cardholders and non-cardholders live.
- Identify if there exists a clear divide between where our West Harrison branch’s cardholders live and where cardholders of a third library in Harrison live.
- Examine relationships between socioeconomic metrics (e.g., income, age) and library card use.
We agreed that we wanted to present our findings in the form of an interactive data visualization, and given that many of our objectives concerned location, decided to build a geodemographic heatmap. Our first goal was to link the circulation data in our integrated library system, Evergreen, to geographic data and demographic data.
Initial Data Collection and Cleaning
Cardholder Data
Our integrated library system, Evergreen, provides data for all libraries in the Westchester Library System, of which the Harrison Public Library is a member. We pulled an ILS User report in Evergreen for the following metrics:
- Home Library: The library building with which cardholders have registered their library card.
- Harrison is rather spread out and is home to three library buildings. We pulled information about cardholders for all three buildings: Our main library building and its West Harrison branch, as well as the third building, the Purchase Free Library, which is located close to our West Harrison branch. We pulled this information in order to examine if there is any noticeable demarcation between where our West Harrison branch library’s cardholders reside and where the Purchase library’s cardholders reside. Note that Harrison residents are allowed to sign up for a library card with any of the three buildings.
- Max Checkout Date/Time: Date of most recent checkout. Evergreen appears to store this information for approximately six months for each cardholder. If a cardholder had a checkout date in the past six months, we considered the cardholder to be an active cardholder.
- For Mailing Address and Physical Address:
- Street (1): Residence number and street name.
- Street (2): Most commonly filled in for apartments (e.g., Apt 4A).
- City
- State
- Postal Code
- ID: We then assigned each cardholder in the report a unique integer ID.
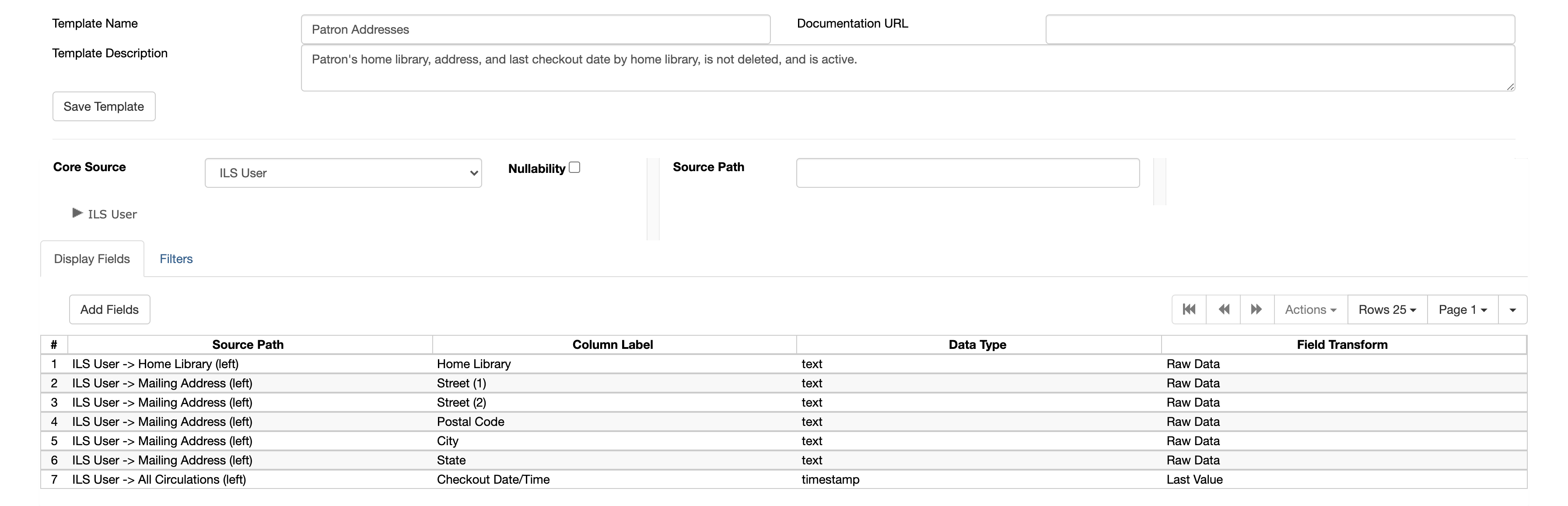
Figure 1. Screenshot of ILS user report we pulled. Physical address fields are out of frame, but were pulled in the same manner as mailing address fields.
Data Cleaning
Data cleaning consisted of cleaning typos and other issues found in each section of the addresses. It was essential to make sure the addresses were clean because we would need to get a coordinate set (latitude, longitude) for each address and had to have the addresses formatted in a specific manner (more on this in Geocoding). We cleaned data for each part of both mailing and physical addresses, and the majority of our data cleaning consisted of the following:
- Street (1)
- Made all text UPPER CASE.
- Made street names uniform. For example:
- Displayed variations of ‘street’ as ‘ST.’
- Displayed variations of ‘avenue’ as ‘AVE.’
- Displayed variations of ‘court’ as ‘CT.’
- Displayed variations of ‘road’ as ‘RD.’
- Deleted leading spaces.
- Moved P.O. Box and apartment data from ‘Street (1)’ to ‘Street (2).’
- Street (2)
- Moved city and state data to appropriate fields.
- City
- Corrected misspelled city names, with a focus on variations of “Harrison.”
- Moved state and zip code data to appropriate fields.
- State
- Changed state name written out in full and state abbreviation written with periods to two-letter abbreviation in ALL CAPS with no spaces (e.g., NY).
- Deleted leading spaces.
- Moved zip code data to the appropriate field.
- Postal Code
- Removed non-numeric characters.
- Fixed zip codes that were four or six digits long by using the rest of the address on file to determine which digit to add or delete (often the first or last digit).
- Moved city and state data to appropriate fields.
We then stored this data as a CSV formatted file.
American Community Survey (ACS) Data
The American Community Survey (ACS) is conducted every month by the United States Census Bureau. It is sent to a sample of about 3.5 million addresses in the fifty states, District of Columbia, and Puerto Rico. The ACS asks about topics not on the census, such as education, employment, internet access, and transportation [1].
In order to get separate data for as many areas of Harrison as possible, we chose to pull ACS data by census tract. Census tracts are geographic entities within counties (or the statistical equivalent of counties). There were 74,134 tracts defined for the 2010 census in the U.S. and its territories [2]. Per the United States Census Bureau [3]: “Census tract boundaries normally follow visible features, but may follow legal geography boundaries and other non-visible features in some instances. Census tracts ideally contain about 4,000 people and 1,600 housing units.” As we learned when building the map itself, Harrison is divided into seven census tracts.
The ACS offers data as 1-year estimates and 5-year estimates. 5-year estimates consist of sixty months of collected data (e.g., 2013-2017 ACS 5-year estimates are produced using data collected between January 1, 2013 and December 31, 2017), and can be used to examine census tracts and other smaller geographies because 1-year estimates are not available [4]. Because there was no option to download data for census tracts by town, we downloaded 2013-2017 ACS 5-year estimates data for every census tract in Westchester County for the following metrics using the now decommissioned American FactFinder tool on the United States Census Bureau’s website (ACS data can now be found at American Community Survey Data [5]) and stored the data as a CSV:
- Census Tract (Full): “Census Tract” + Number (e.g., Census Tract 84, Census Tract 84.02), County Name, State Name
- Total Population: Included in the ACS, produced by Population Estimates Program [6].
- Households; Estimate; Median income (dollars)
- Total; Estimate; Median age (years)
- Unemployment rate; Estimate; Population 16 years and over
- Percent; Estimate; Percent high school graduate or higher
- Percent; Estimate; Percent bachelor’s degree or higher
- Percent; Estimate; Population 25 years and over – Graduate or professional degree
Obtaining this data for each census tract in Harrison allowed us to use the heatmap to infer characteristics about our cardholders based on how they were distributed throughout the town’s census tracts. We pulled total population data by tract to estimate the percentage of residents in each tract that have library cards, and chose the other metrics to study the validity of our most common observations from working in the library each day. For example, a significant portion of library visitors appear to be senior citizens, and we wanted to study, for example, if there were relatively high concentrations of cardholders in parts of town with high median ages. We also wanted to study the overall relationship between age and library card use. Furthermore, we notice that many people use library computers to apply for jobs, so we wanted to include unemployment data. Finally, income and educational attainment are standard measures of wealth and social status, and we wanted to test hypotheses such as whether there is an inverse relationship between wealth and library card use (perhaps because those who are better off financially may feel they don’t need to use library resources).
Geocoding
Google Maps Geocoding API
To build a heatmap using Google Maps, we first had to create a project in the Google Cloud Platform Console, and add a Google Maps Geocoding API key [7] to the project. Note that Google will ask for billing information, and the Geocoding API uses a pay-as-you-go pricing model [8]. We set up a new account in such a way that there was a free credit promotion that we were able to complete the project without having to pay anything.
Note that Google has a set of stringent rules for its Geocoding API [9] and Google Maps [10]. We’ve linked to both pages, and encourage those interested in using these platforms to visit them to read the current policies. Notably, on its Geocoding API Policies page [11], Google states:
If you want to display Geocoding API results on a map, then these results must be displayed on a Google Map. It is prohibited to use Geocoding API data on a map that is not a Google map.
Getting a Coordinate Set for Each Address
Next, to plot each cardholder’s residence, we had to get a coordinate set for each address. We decided to geocode the physical addresses we pulled from Evergreen because they are the addresses displayed on cardholders’ IDs (e.g., driver’s license) at card signup. As mentioned in Initial Data Collection and Cleaning, it was essential to clean the addresses because we had to have them formatted in a specific manner in order to submit geocoding requests to Google Maps using the Geocoding API [12].
Geocoding API is accessed through an HTTP interface. Requests must be formatted in the same manner as the following [13]:
https://maps.googleapis.com/maps/api/geocode/json?address=1600+Amphitheatre+Parkway,+Mountain+View,+CA&key=YOUR_API_KEY
We used a PHP script on a locally running Windows/Apache/MySQL/PHP (WAMP) stack to make the Geocoding API requests. The same script parsed the JSON responses, linked the parsed responses with the unique cardholder IDs, and formatted them in two CSV files, which we combined manually. We had to make requests in batches so we wouldn’t exceed execution times or memory max on the local server. We set up the local WAMP server with a longer than default PHP process time, increased memory for requests, and set up an SSL certificate to make sure we were sending requests encrypted. We also cached the DNS request to the base URL so it didn’t need to do a lookup when we were sending data in the URLs. The requests were not asynchronous so the next request happened after the previous one was processed, and there was no need to delay timing on the requests to comply with Google’s terms of service.
Below is the script we used to submit geocoding requests and parse the JSON responses.
<?php
header('Content-Type: text/csv; charset=utf-8');
header('Content-Disposition: attachment; filename=result.csv');
$csv = '';
if ($handle = fopen('addresses.csv', 'r')) {
while($row = fgetcsv($handle, 9999, ',')) {
$id = $row[0];
$address = urlencode(implode(' ', array_splice($row, 1)));
$key = ''; // API key redacted
$url = "https://maps.googleapis.com/maps/api/geocode/json?address=$address&key=$key";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 2);
$json = json_decode(curl_exec($ch), true);
if ($json['status'] == 'OK') {
$add = $json['results'][0]['formatted_address'];
$place = $json['results'][0]['place_id'];
$lat = $json['results'][0]['geometry']['location']['lat'];
$lng = $json['results'][0]['geometry']['location']['lng'];
$csv .= "$id,$add,$place,$lat,$lng\n";
} else {
$csv .= "$id,,,,\n";
}
}
curl_close($ch);
}
fclose($handle);
echo $csv;
The information we pulled using the script are lines 4, 7, 8 and 22 in the following sample geocoding response, in JSON [14]:
{
"results" : [
{
"formatted_address" : "1600 Amphitheatre Pkwy, Mountain View, CA 94043, USA",
"geometry" : {
"location" : {
"lat" : 37.4267861,
"lng" : -122.0806032
},
"location_type" : "ROOFTOP",
"viewport" : {
"northeast" : {
"lat" : 37.4281350802915,
"lng" : -122.0792542197085
},
"southwest" : {
"lat" : 37.4254371197085,
"lng" : -122.0819521802915
}
}
},
"place_id" : "ChIJtYuu0V25j4ARwu5e4wwRYgE",
"plus_code" : {
"compound_code" : "CWC8+R3 Mountain View, California, United States",
"global_code" : "849VCWC8+R3"
},
"types" : [ "street_address" ]
}
],
"status" : "OK"
}
Getting Census Geographies for Each Address
The Census Bureau has a free geocoder that can provide locations’ census geographies (state, county, tract, and block). The geocoder is available as a web interface and as an API, and can handle up to 10,000 requests in batch mode [15]. After getting an API key, we once again used PHP on a locally running WAMP stack to make the geocoding API requests for the census geocoder, parsed the JSON responses, linked the parsed responses with the unique cardholder IDs, and formatted them in two CSV files, which we combined manually. We set up the local WAMP server with a longer than default PHP process time, increased memory for requests, and set up an SSL certificate to make sure we were sending requests encrypted. We also cached the DNS request to the base URL so it didn’t need to do a lookup when we were sending data in the URLs. We submitted census geocoding requests using the coordinates we got from Google when we geocoded cardholders’ physical addresses.
Below is a sample geocoding request using the coordinates of the New York Public Library’s main branch, where ‘x’ is longitude and ‘y’ is latitude:
https://geocoding.geo.census.gov/geocoder/geographies/coordinates?x=-73.9818&y=40.75225&benchmark=8&vintage=8&format=json
Note that when we performed the study, we had ‘benchmark’ and ‘vintage’ at their 2017 settings, to match the census tracts from which we pulled data using the 2013-2017 ACS 5-year estimates. Benchmark and vintage must be included to get census geographies [16].
Below is the script we used to submit geocoding requests and parse the JSON responses.
<?php
header('Content-Type: text/csv; charset=utf-8');
header('Content-Disposition: attachment; filename=result.csv');
$csv = '';
$base_url = 'https://geocoding.geo.census.gov/geocoder/geographies/coordinates';
$benchmark = '4'; // Integer – We have put ‘4’ for the most current setting as a
// placeholder (as 2017 settings are no longer available)
$vintage = '4'; // Integer – We have put ‘4’ for the most current setting (as
// 2017 settings are no longer available)
$key = ''; // API key redacted
// Send geocoding requests using coordinates
if ($handle = fopen('coordinates.csv', 'r')) {
while($row = fgetcsv($handle, 9999, ',')) {
$id = $row[0];
$x = $row[2];
$y = $row[1];
$tract = '';
$url = "$base_url?x=$x&y=$y&benchmark=$benchmark&vintage=$vintage&format=json&key=$key";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, true);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 2);
$json = json_decode(curl_exec($ch), true);
// PULL STATE, COUNTY, AND CENSUS TRACT INFORMATION FROM JSON
if ($json && array_key_exists('result', $json)) {
if (array_key_exists('geographies', $json['result'])) {
if (!empty($json['result']['geographies']['Census Tracts'])) {
if (array_key_exists('NAME',
$json['result']['geographies']['Census Tracts'][0])) {
$tract = $json['result']['geographies']['Census Tracts'][0]['NAME'];
}
if (!empty($json['result']['geographies']['Counties'])) {
if (array_key_exists('NAME',
$json['result']['geographies']['Counties'][0])) {
$tract .= ', ' .
$json['result']['geographies']['Counties'][0]['NAME'];
}
if (!empty($json['result']['geographies']['States'])) {
if (array_key_exists('NAME',
$json['result']['geographies']['States'][0])) {
$tract .= ', ' .
$json['result']['geographies']['States'][0]['NAME'];
}
}
}
}
}
}
if ($tract) {
$csv .= "$id,\"$tract\"\n";
} else {
$csv .= "$id,\n";
}
}
curl_close($ch);
}
fclose($handle);
echo $csv;
The census geographies we pulled using this script are lines 22, 36, 45, 56, 67, and 78 in the following excerpts from the JSON response for the New York Public Library request:
{
"result": {
"input": {
"benchmark": {
"id": "8",
"benchmarkName": "Public_AR_ACS2019",
"benchmarkDescription": "Public Address Ranges - ACS2019 Benchmark",
"isDefault": false
},
"vintage": {
"id": "8",
"vintageName": "Current_ACS2019",
"vintageDescription": "Current Vintage - ACS2019 Benchmark",
"isDefault": true
},
"location": {
"x": -73.9818,
"y": 40.75225
}
},
"geographies": {
"States": [
{
"STATENS": "01779796",
"GEOID": "36",
"CENTLAT": "+42.9198015",
"AREAWATER": 19244881040,
"STATE": "36",
"BASENAME": "New York",
"STUSAB": "NY",
"OID": 27490100833860,
"LSADC": "00",
"FUNCSTAT": "A",
"INTPTLAT": "+42.9133974",
"DIVISION": "2",
"NAME": "New York",
"REGION": "1",
"OBJECTID": 39,
"CENTLON": "-075.5942771",
"AREALAND": 122050448177,
"INTPTLON": "-075.5962723",
"MTFCC": "G4000"
}
],
"Counties": [
{
"GEOID": "36061",
"CENTLAT": "+40.7741301",
"AREAWATER": 28551431,
"STATE": "36",
"BASENAME": "New York",
"OID": 27590460844234,
"LSADC": "06",
"FUNCSTAT": "C",
"INTPTLAT": "+40.7766419",
"NAME": "New York County",
"OBJECTID": 2446,
"CENTLON": "-073.9698320",
"COUNTYCC": "H6",
"COUNTYNS": "00974129",
"AREALAND": 58680717,
"INTPTLON": "-073.9701871",
"MTFCC": "G4020",
"COUNTY": "061"
}
],
"Census Tracts": [
{
"GEOID": "36061008400",
"CENTLAT": "+40.7519695",
"AREAWATER": 0,
"STATE": "36",
"BASENAME": "84",
"OID": 20790460864064,
"LSADC": "CT",
"FUNCSTAT": "S",
"INTPTLAT": "+40.7519695",
"NAME": "Census Tract 84",
"OBJECTID": 43639,
"TRACT": "008400",
"CENTLON": "-073.9840942",
"AREALAND": 173067,
"INTPTLON": "-073.9840942",
"MTFCC": "G5020",
"COUNTY": "061"
}
]
}
}
}
Note that there is also an option to feed addresses through the census geocoder to get census geographies and coordinates. We tested this option, but we decided to use the coordinates we got using the Google Geocoding API over those of the census geocoder because we got more accurate results from Google. The census geocoder documentation mentions that it “takes the address and determines the approximate location offset from the street centerline” [15]. We checked some of the coordinates the census geocoder returned and indeed found that it generally returned coordinates for nearby cross streets rather than exact addresses, while Google generally returned coordinates for exact addresses.
After obtaining census geographies, we cleaned census tract information in the following manner to get Census Tract Code:
- We isolated the number from the census tract information pulled from the JSON (e.g., 84 from “Census Tract 84”).
- If the Census Tract Number was a whole number, we added two zeroes to the end of it (e.g., 84 -> 8400).
- If the Census Tract Number was a decimal, we removed the decimal (e.g., 84.02 -> 8402).
We were not affected by the fact that there are census tracts with the same number across multiple states since we decided to display on the map census tract boundaries for Harrison only.
Final Data Sets
After the initial data collection, cleaning, and geocoding were complete, we had the two principal data sets we needed to build the heatmap.
Principal Cardholder Data Set
Our final cardholder data set consisted of the following columns for each cardholder:
- ID: Unique integer identifier.
- Home Library: The library building with which cardholders have registered their library card. Recall that we pulled information for the three library buildings in Harrison: Our main library building and its West Harrison branch, as well as the Purchase Free Library, which is located close to our West Harrison branch. Harrison residents are allowed to sign up for a library card with any of the three buildings.
- Date of Most Recent Checkout: Within the past six months. If a cardholder had a checkout date in the past six months, we considered the cardholder to be an active cardholder.
- Latitude and Longitude: Coordinates of cardholder’s address (as separate columns).
- State Name: For state in which cardholder’s address is located.
- County Name: For county in which cardholder’s address is located.
- Census Tract Code: Census tract in which cardholder’s address is located. Note that this code will contain only numbers. This column was used to link the cardholder data to the ACS data.
Principal American Community Survey (ACS) Data Set
Our final ACS data set had the following information for all census tracts in Westchester County:
- Census Tract Code: Served as the ID for the ACS data, used to link the ACS data to the cardholder data.
- Total Population
- Households; Estimate; Median income (dollars)
- Total; Estimate; Median age (years)
- Unemployment rate; Estimate; Population 16 years and over
- Percent; Estimate; Percent high school graduate or higher
- Percent; Estimate; Percent bachelor’s degree or higher
- Percent; Estimate; Population 25 years and over – Graduate or professional degree
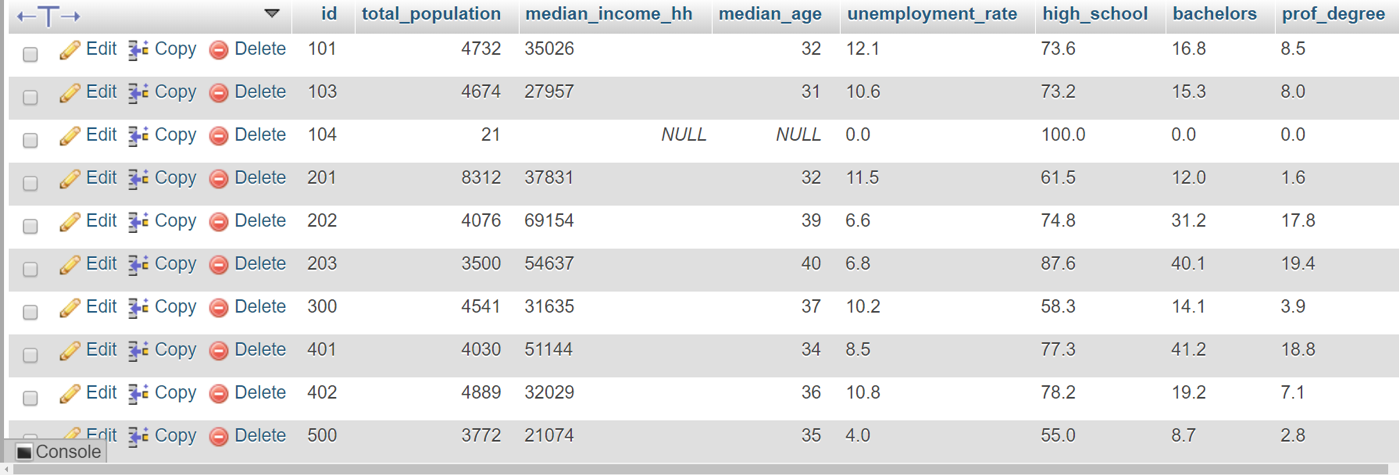
Figure 2. ACS data for census tracts in Westchester County stored in MySQL (partial).
We then stored both data sets as tables in a MySQL database.
Building the Map
To build the heatmap using Google, we had to add a Maps JavaScript API key [17] to our project in Google Cloud Platform Console. Next, we created a heatmap layer, queried the coordinates from the principal cardholder data set in MySQL, and plotted the coordinates of each cardholder’s physical address on to the map using the Maps JavaScript API [18].
Figure 3. An example of a heatmap as shown on Google’s Heatmaps documentation page [19].
Though we plotted all cardholders’ locations, we chose to display census tract boundaries (and ACS data) for only Harrison’s census tracts, as the overwhelming majority of cardholders live in Harrison (and you have to be a town resident to sign up for a library card with any of its three library buildings, anyway).
To display these boundaries, we downloaded TIGER/Line shapefiles for Harrison’s border and the boundaries of the census tracts within the town as KML layers from the census website [20] and used the Maps JavaScript API to add these boundaries to the map [21]. It helped us to have the KML files served with headers from an actual server instead of linked locally in directories when importing.
Below is the basic structure of what we did to create the map, load the KML layers, load the coordinates, and create the heat map layer. The code below assumes certain variables are populated, and we named the variables in a manner to make that clear.
// Initialize Google map
const map = new google.maps.Map(document.getElementById(elemId), {
zoom: 13,
minZoom: 12,
maxZoom: 15,
center: {lat: initLat, lng: initLng},
styles: mapStyles // Custom Google Map feature types, colors, etc.
});
// Render KML layers
const kmlLayers = data.censusTracts.map(tract =>
new google.maps.KmlLayer({
url: tract.url, // Header from a server
preserveViewport: true,
map: map
})
);
// Translate coordinates to Google Map coordinates
// We pulled this data from the principal cardholder data table in MySQL
const coordinates = data.coordinates.map(coordinateSet =>
new google.maps.LatLng(
parseFloat(coordinateSet['latitude']),
parseFloat(coordinateSet['longitude'])
)
);
// Render heatmap
const heatmap = new google.maps.visualization.HeatmapLayer({
data: coordinates,
map: map,
radius: 10,
opacity: 0.9,
dissipating: true,
maxIntensity: 10
});
Finally, we added tooltips that appear when users click on a census tract. We had to wire up interactivity to filter data based on the chosen tract and then format each tooltip, which displays cardholder summary statistics for each census tract in Harrison and ACS data for all residents in each tract. We also added interactivity to filter coordinates plotted based on cardholders’ home library. The data displayed on the map and the tooltips were all pulled from the cardholder and ACS data tables in our MySQL database.
Conclusions
The Map
In this section, we will discuss our conclusions from the final heatmap. As a guide, we have included the following image of the map without the coordinates plotted. Note how Harrison is divided into seven census tracts. The downtown library is located in the southeast corner of Harrison and is marked as HAR. The library’s West Harrison branch is located in northwestern Harrison and is marked as W. HAR. The Purchase Free Library is also located in northern Harrison and is marked as PUR. As previously mentioned, the Harrison Public Library operates the downtown library and the West Harrison branch, and these buildings’ abbreviations have been underlined.
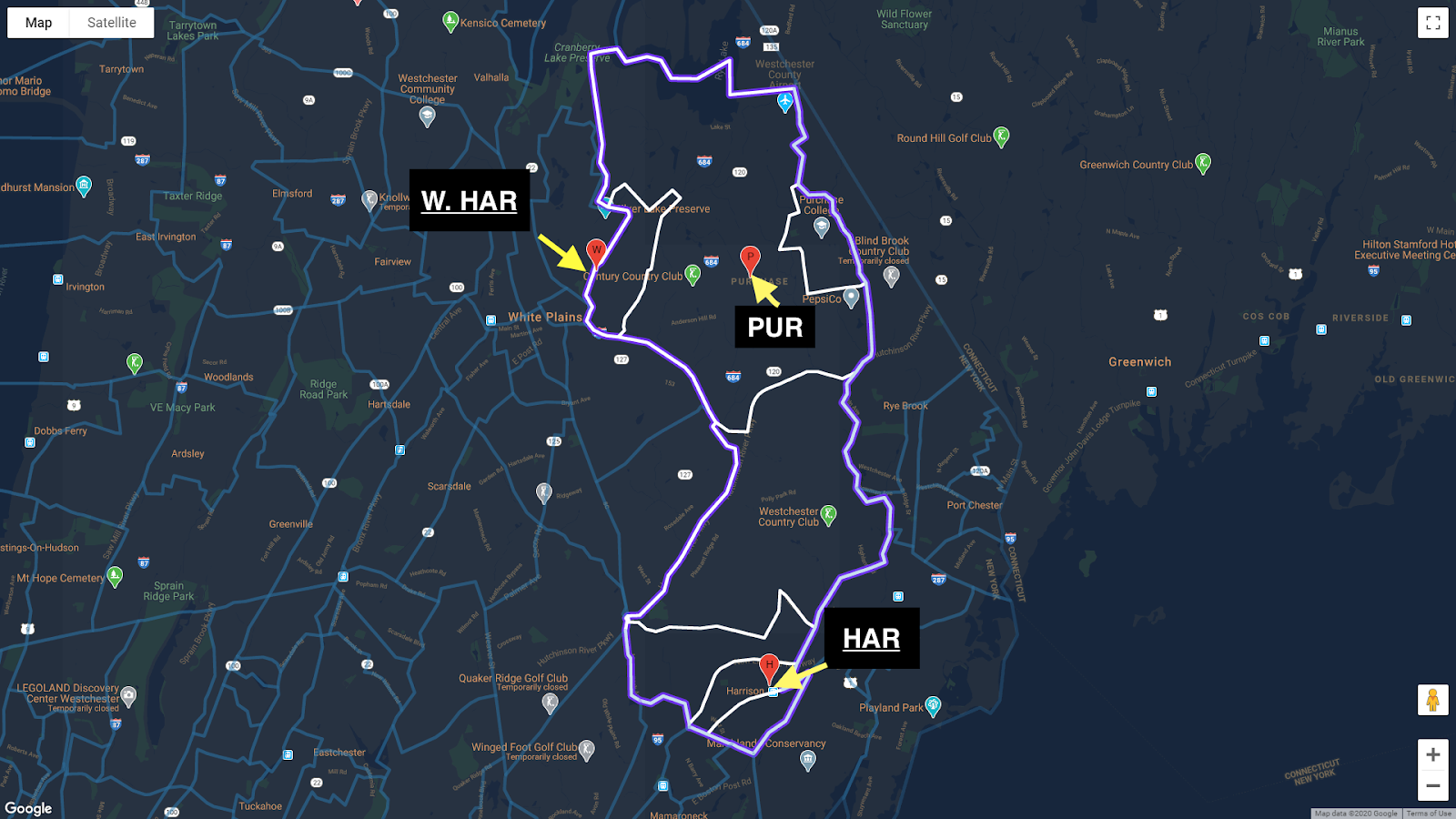
Figure 4. Harrison divided into its census tracts with its three libraries’ locations shown.
Home Library in Harrison
Our library’s cardholders – both for the downtown library and its West Harrison branch – overwhelmingly come from the census tracts closest to each library building. The downtown library is located almost exactly on the border between the two census tracts that comprise Harrison’s downtown district, and these two census tracts (which make up a densely populated downtown/residential area) contain the majority of the cardholders whose home library is our main library. There is, however, a cluster of main library cardholders across town in the West Harrison branch’s census tract, which could indicate either that West Harrison residents use the downtown building over their local branch, or simply that West Harrison residents stated that they wanted to register for a card at the “Harrison” library at signup and chose the main building by default. Similarly, an overwhelming majority of the cardholders whose home library is our West Harrison branch are located in the same census tract as our branch, and this tract encompasses a relatively small, but densely populated, residential area.
The Purchase Free Library is located at the center of Harrison’s wealthiest census tract, and its cardholders are scattered throughout this sparsely populated tract. To our surprise, relatively few of its cardholders live in the same tract as our West Harrison branch despite the close proximity of the two libraries. In fact, although they live in the same census tract as the Purchase library, there is a cluster of Purchase cardholders who live in the area outlined by the orange oval in the image below who actually live closer to our West Harrison branch than to the Purchase library. To the west, only a small wooded area separates their neighborhood and our branch library’s census tract, and to the east of this neighborhood – between the homes and the Purchase library – is a country club. This observation regarding home library demonstrates the perceived cultural differences between the residents in this part of town even though they live so close to each other.
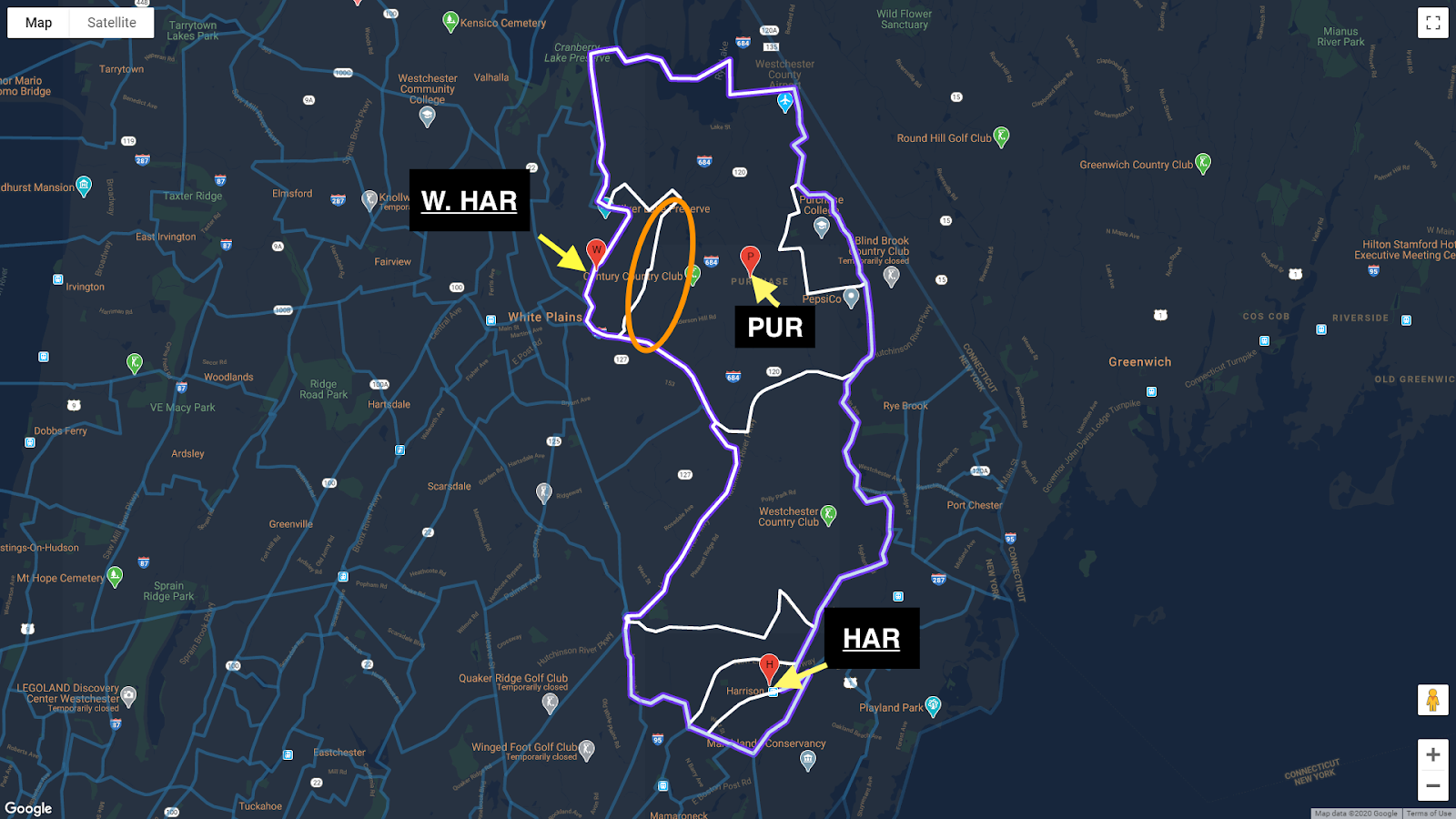
Figure 5. There is a cluster of Purchase cardholders who live in the area marked by the orange oval. These Purchase cardholders actually live closer to the West Harrison branch library than to the Purchase library.
Discoveries About Cardholders of the Two Harrison Public Library Buildings
Clicking on a census tract in the heatmap displays a tooltip that shows summary statistics for the tract detailing its demographics and the library card usage of its residents.

Figure 6. Metrics displayed for a selected downtown Harrison census tract.
We noticed that, at the extremes, there is an inverse relationship between median household income and the percentage of active cardholders (number of cardholders who checked out material in the past six months divided by the total number of cardholders) by census tract, which supports our hypothesis about the relationship between wealth and library card use. The Harrison census tract that is first in median household income has the lowest active cardholder percentage, while the tract that is second to last in median household income has the highest active cardholder percentage. We did not, however, observe any relationship between median household income and active cardholder percentage for the census tracts more towards the middle of Harrison’s household income range. It is worth noting, however, that despite their differences, all census tracts in Harrison have median household incomes above the national median household income, and examining this simple measure of central tendency by census tract does not capture the entirety of the town’s economic landscape.
We did not notice from this map a densely populated part of town with relatively few cardholders, which indicates that while the library should continue to focus on welcoming new cardholders, it should devote more resources towards reaching out to potentially lapsed cardholders and promoting our wide variety of services beyond our collection.
Regarding age, the understandings gained from the map mirrored other statistical insights (social media, surveys) and confirmed our intuition that older populations are more likely to use the library to check out materials. There was a direct relationship between median age, percentage of residents that have a library card, and the percentage of active cardholders by census tract. Accordingly, we are currently developing a formalized strategy focused on library services for Harrison’s over-50 population.
Limitations and Reflections
The heatmap’s primary limitation is that it includes data relating to only a subset of Harrison Public Library users: cardholders. Numerous groups make up our users, including cardholders, non-cardholders, library visitors, and those who use online resources such as our website. There is substantial overlap between these groups. For example, some library visitors attend movies, talks, and other programs (which they may have heard about on our website), and check out materials, while others visit only for the programs. Our integrated library system, Evergreen, provides us easy access to a cardholder database with information about where our cardholders reside, which we were able to use to build the heatmap. Though our cardholders make up a significant portion of our users, there are other users not captured by this analysis.
In addition, the data we used for the heatmap is imperfect. We have the date of a cardholder’s most recent checkout within the past six months, but we don’t know where the checkout occurred. It is possible that although the cardholder signed up for their card with the downtown library or West Harrison branch, they are now using a different library, as their card permits them to check out materials at any library in the county system. Finally, the census bureau notes that the “ACS, like any other sample survey, is subject to error” [22], and as mentioned in the Conclusions section, analyzing simple measures of central tendency provides only a cursory glance at a population.
Furthermore, using Google for this project provided an opportunity to reflect on protecting patron privacy. We restricted access to the tool to only a few authorized staff members, hosted our data in a locally managed MySQL database, set up an SSL certificate to make sure we were sending requests encrypted, and did not submit any additional contextual data when using Google’s Geocoding API. With these mitigations, we did not provide Google any information about these plots except that they are somehow all in a set. On reflection, however, this is a reminder that, as developers, we need to be mindful that we ultimately never know exactly how large companies might contextualize the data that they collect when we utilize their APIs.
If we were to do the project over, we would eliminate Google from the process. We would obtain coordinates using the census geocoder, accept the limited results, and use an open source platform, such as OpenLayers, to do the heatmap. In hindsight, perfect was the enemy of good, and we could have saved time, not had to enter any billing information (and risk being charged), and had the freedom to choose any platform we wanted to build the map since we would not have been bound to Google’s stipulation prohibiting using Geocoding API data on a map that is not a Google map.
Finally, readers may have noticed a metric called ‘Tapestry LifeMode’ in the tooltip displayed in the previous image. This was added by assigning an Esri Tapestry Segmentation [23] to each census tract in Harrison in an effort to give each neighborhood a general classification. This project was an initial experiment in learning more about library users in our continuous effort to improve service. We look forward to building on what we have done.
How Libraries Can Work with Open Data
Libraries have played a pivotal role in assisting with the 2020 census through promotional efforts, providing safe spaces to fill out the form, and numerous other initiatives. The conclusion of the 2020 census, however, doesn’t have to be the end of libraries’ involvement with open data. Libraries can use public data from the census, related census bureau surveys (e.g., American Community Survey, American Housing Survey (AHS), Current Population Survey (CPS)), and other open data sources to serve communities in a variety of ways.
As we’ve shown, libraries can use census bureau data to study the local population and strategize to meet its potential needs. Our use of the heatmap, for example, showed us the connection between proximity to a library building and library card signup rate, the inverse relationship between household income and library card use (for median household income extremes by census tract in our town), and the direct relationship between age and library card use. Our most notable development as a result of the heatmap project has been developing a formalized strategy focused on library services for Harrison’s over-50 population.
There are a number of organizations that support open data projects at libraries, such as Civic Switchboard, an Institute of Museum and Library Services supported effort that aims to “develop the capacity of academic and public libraries in civic data ecosystems” [24]. In 2019, Civic Switchboard awarded nine libraries with stipends ranging from $3,000 to $9,000 to work on open data projects with local governments and other organizations [25].
One recipient, the Robert L. Bogomolny Library at the University of Baltimore, used open data to complement and enhance the value of the existing collection. During a multi-week research project, students linked census data and other local open data to archival and special collections materials in an effort to contextualize materials and strengthen historical descriptions. For example, students took on projects such as linking employment data to historic photos of a job fair [26].
Libraries can also support local community initiatives by assisting with civic open data projects. Another Civic Switchboard stipend recipient, the Pioneer Library System in upstate New York’s Ontario County, collaborated with the Substance Abuse Prevention Coalition (SAPC) of Ontario County to map out the local substance abuse data ecosystem (i.e., who has the data, what types of data they have). The library system then shared the map with law enforcement, local government, and community members in order to encourage data sharing [27]. Relatedly, in 2015, under a Knight Foundation-funded initiative called “Open Data to Open Knowledge,” Boston partnered with its public library to catalog the city’s existing data into a user-friendly portal with the goal to make it clear that the data is public, with no restrictions to access [28].
Bibliography
[1] The Importance of the American Community Survey and the 2020 Census [Internet]. [updated 2020 Feb 27]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/programs-surveys/acs/about/acs-and-census.html
[2] More About Census Tracts – FCC Form 477 [Internet]. [updated 2015 Mar 26]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://transition.fcc.gov/form477/Geo/more_about_census_tracts.pdf
[3] Glossary [Internet]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/glossary/#term_Tract
[4] When to Use 1-year, 3-year, or 5-year Estimates [Internet]. [updated 2019 Sep 17]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/programs-surveys/acs/guidance/estimates.html
[5] American Community Survey Data [Internet]. [updated 2019 Sep 26]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/programs-surveys/acs/data.html
[6] American Community Survey Key Facts [Internet]. [updated 2010]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/content/dam/Census/programs-surveys/acs/news/10ACS_keyfacts.pdf
[7] Get an API Key [Internet]. [updated 2020 Apr 10]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/geocoding/get-api-key
[8] Geocoding API Usage and Billing [Internet]. [updated 2020 Apr 10]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/geocoding/usage-and-billing
[9][11] Geocoding API Policies [Internet]. [updated 2020 Apr 10]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/geocoding/policies
[10] Google Maps Platform Service Specific Terms [Internet]. [updated 2020 Mar 24]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://cloud.google.com/maps-platform/terms/maps-service-terms/
[12][13][14] Get Started [Internet]. [updated 2020 Apr 10]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/geocoding/start
[15] Census Geocoder Documentation [Internet]. [updated 2018 Nov 27]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/programs-surveys/geography/technical-documentation/complete-technical-documentation/census-geocoder.html
[16] Geocoding Services Web Application Programming Interface (API) [Internet]. [updated 2019 Dec]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://geocoding.geo.census.gov/geocoder/Geocoding_Services_API.pdf
[17] Get an API Key [Internet]. [updated 2020 Apr 21]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/javascript/get-api-key
[18][19] Heatmaps [Internet]. [updated 2020 Apr 16]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/javascript/examples/layer-heatmap
[20] Cartographic Boundary Files – KML [Internet]. [updated n.d.]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www.census.gov/geographies/mapping-files/time-series/geo/kml-cartographic-boundary-files.html
[21] Displaying KML [Internet]. [updated 2020 Apr 21]. Mountain View (CA): Google; [cited 2020 Apr 30]. Available from: https://developers.google.com/maps/documentation/javascript/kml
[22] American Community Survey Accuracy of the Data (2018) [Internet]. [updated n.d.]. Washington (DC): United States Census Bureau; [cited 2020 Apr 30]. Available from: https://www2.census.gov/programs-surveys/acs/tech_docs/accuracy/ACS_Accuracy_of_Data_2018.pdf
[23] Tapestry Segmentation [Internet]. [updated n.d.]. Redlands (CA): Esri; [cited 2020 Apr 30]. Available from: https://www.esri.com/en-us/arcgis/products/tapestry-segmentation/overview
[24] Civic Switchboard [Internet]. [updated n.d.]. Pittsburgh (PA): Civic Switchboard; [cited 2020 Apr 30]. Available from: https://civic-switchboard.github.io/
[25] Enis, M. 2020 Jan 15. Civic Data Partnerships. Library Journal [Internet]. [cited 2020 Apr 30]. Available from: https://www.libraryjournal.com/?detailStory=Civic-Data-Partnerships
[26] Udell E. 2020 Mar 2. After the Census. American Libraries [Internet]. [cited 2020 Apr 30]. Available from: https://americanlibrariesmagazine.org/2020/03/02/after-the-census/
[27] Pioneer Library System, Ontario County, NY [Internet]. [updated 2019 Dec]. Pittsburgh (PA): Civic Switchboard; [cited 2020 Apr 30]. Available from: https://civic-switchboard.gitbook.io/guide/case-studies/pioneer-library-system-ontario-county-ny
[28] Poon L. 2019 Feb 11. Should Libraries Be the Keepers of Their Cities’ Public Data?. City Lab [Internet]. [cited 2020 Apr 30]. Available from: https://www.citylab.com/life/2019/02/libraries-public-information-city-data-digital-archive/581905/
About the Authors
Greg Sohanchyk has worked at the Harrison Public Library in Harrison, New York in multiple capacities and is currently enrolled in the Master of Information program at Rutgers. He holds a B.A. in Statistics from Yale and is looking to work in the field of assessment and user experience librarianship.
Dan Briem is a library assistant at the Harrison Public Library. A self-taught programmer, he has led numerous technology initiatives at the library.

Becky Yoose, 2020-08-24
Hi all – While the practices in this article are not the most egregious examples I’ve encountered in terms of patron privacy risks and harms, the fact that this was published in a well-known and respected editor-reviewed journal concerns me for a number of reasons. I’ll do my best in conveying these reasons without breaking the comments form, so I’ll give the tl;dr versions of each reason below, and we can discuss individual reasons in depth in the resulting thread.
1. Lack of de-identification and data minimization – the patron dataset that was used in the project contains personally identifiable information (PII) that was not obfuscated or truncated. In addition, there’s no information about the methodology surrounding the pseudonymization of the patron data. In the transformed Principle Cardholder dataset, the latitude/longitude data field was kept even though the Census Tract Code field could have been used as a lower privacy risk proxy for the location. The inclusion of the unique identifier in the transformed dataset is also questionable, since the datasets being used do not necessitate a unique identifier to track individual behavior. Instead, this tying of data to unique individuals replicates what many Customer Relationship Management Systems (CRMSs) do in terms of market segmentation. Given the non-private nature of many CRMSs in their treatment of personal data, replicating a CRMS without addressing the privacy issues inherent in the system design also replicates the potential privacy harms (as well as systematic biases) that come with CRMSs.
2. Data needs and use – in the beginning of the article, the authors stated that the library sent out a survey to their patrons to gather demographic and library use information. Even though the data analysis was meant to complement the survey, the inclusion of socioeconomic data to study library card use calls the purpose of this analysis into question. Why was it necessary to know an individual patron’s income and education and how *exactly* will this knowledge supplement the survey? Was this use of patron data in the market segmentation project consented to by patrons, be it through notice through a privacy policy or through explicit consent? Again, what is being described in the article is a market segmentation project. Without explicit knowledge or consent from patrons about their use of data in such a project, we have some questions about a potential ethics breach from the practices in this article. [See also: the Civil Grand Jury report about Santa Cruz Public Library’s use of Gale’s Analytics on Demand for an example of when patrons find out about this type of use of their data.]
3. Data privacy and security – while the authors of the article rightly reflected on the privacy perils of using Google for the geolocation, the assumption that patron data in internal systems being inherently better in terms of privacy and security needs to be questioned. Internal systems are subject to the same risks of data and security breaches, leaks, and other forms of unauthorized access as external systems. These internal systems are also subject to law enforcement searches, as well as Freedom of Information (FOI) or public record disclosure requests. Granted, one can reconstruct this combination of patron data with external data sets with FOI requests; however, you still can mitigate privacy risks by not bringing different data sets containing PII together into one central location in the first place.
If certain actions were taken, such as the removal of unique identifiers and latitude/longitude from the Principle Cardholder set (aggregating the data), more rigorous data security and privacy practices around patron data use and storage, and an honest attempt into questioning the reasons for this specific approach “to gain a holistic understanding of its users”, then this case study could have been a fairly decent example of how to use Open Data to help with library operations. Sadly, what is left is an example of the use of patron data that puts patron privacy at risk and leaves the ethical questions about the practice of market segmentation using patron data unasked. Again, the fact that this was published in a well known and respected journal leaves me saddened that there was not more to address the privacy and ethical concerns brought up by this article.
Peter Murray, 2020-09-09
On behalf of the editorial committee…
We appreciate the time and thoughtfulness of your response.
Several members of the editorial board discussed this article in depth before publication. Reactions ranged from “nice code, and does in-house what vendors are doing” to “very concerning in terms of privacy and perhaps should not be published” to “please educate me what is wrong with this article”. The authors were asked to consider patron privacy issues and did rework their article to include what measures they had taken.
As we decide how to move forward, we have heard some calls for the removal of the article. Rather than do so, we feel that this should be an opportunity for further discussion and education. We believe the C4LJ should be a place where we learn from each other in the field, including from imperfect projects and the community responses they elicit.
One takeaway from this process has been a renewed recognition of the limitations of expertise on the editorial board in some areas, and the need to occasionally pull in outside experts to comment on articles.
We welcome more comments and feedback, and look forward to a productive discussion.
Becky Yoose, 2020-09-09
Thank you Peter and to the editorial team for your response. I appreciate that the editorial team took the time to discuss my concerns and have recognized the need to pull in external experts in the editor review process. I am still concerned about the lack of consideration for non-technical elements in the review process. On the technical level, yes, the code works, but code and tech in general can perpetuate practices/systems that harm others, even when that harm isn’t apparent to the creators.
There was a special issue that explored diversity and social issues in library technology some time ago, but it’s time to go beyond special issues. To acknowledge library technology’s role in creating and upholding systems of surveillance and oppression (among others), I ask the editorial committee to consider incorporating ethics and social responsibility (and etc.) in the regular review process.
Again, I appreciate the editorial committee’s time and care in discussing and replying, so I hope that we can continue this discussion.