by Nicole Wood and Scott Shumate
Background
Adding an OCLC institution symbol to a record in OCLC Connexion indicates that the item described in the record is owned by the corresponding library [1]. This is integral to the interlibrary loan process, in which these holdings are utilized to locate items for lending and borrowing. These holdings are added and deleted through OCLC as libraries acquire and weed materials. Some libraries may set holdings for their entire collection, while others may only set holdings for resources that they wish to circulate through interlibrary loan, excluding collections that are non-circulating like reference materials, or collections with copyright and delivery restrictions such as eBooks. If these holdings are not regularly reviewed, time, lack of training, and forgetfulness can culminate in a catalog that is no longer accurately depicted in OCLC.
OCLC offers two services to bring these holdings up to date: reclamation and data sync. During reclamation, library records are matched with the WorldCat equivalent and holdings are set and deleted accordingly. This provides a complete holdings overhaul and is most beneficial to libraries that “have not consistently maintained [holdings] and cannot easily isolate only the records that need to be updated” [2]. This is a fee-based service that may be cost-prohibitive to libraries with limited budgets. Data sync services for ongoing collection maintenance are included in OCLC cataloging subscriptions; however, this is only recommended for libraries that have maintained regular holdings updates [3].
At Austin Peay State University (APSU), holding updates are built into the workflow for acquiring and discarding materials. Holdings for e-resources are maintained through WorldShare Collection Manager, while print holdings are updated on a title-by-title basis as resources are added and removed from the collection. APSU’s last reclamation project was conducted in 2016. Over time, interlibrary loan and cataloging personnel began to notice rogue OCLC holdings that were not present in the APSU library catalog. The records covered a broad range of creation dates and bibliographic locations. It is likely that these incorrect holdings are the result of past weeding projects and the occasional instance of setting holdings for the wrong item during the initial cataloging process. Due to budget restrictions, a reclamation project was not possible. In order to perform the less cost-prohibitive data sync, the entire catalog needed to be reviewed to extract the limited number of records with incorrect holdings.
Because e-resource holdings are automatically updated through Worldshare Collection Manager, we only needed to update our holdings for print resources. The goal was to compare holdings in our ILS with our holdings in OCLC, extract non-duplicate entries, and either delete or add holdings accordingly.
OCLC Collection Manager
For this project, we wanted to correct OCLC holdings for the library’s print monographs. To initiate this process, we needed to get an overview of all of our current OCLC holdings for this collection. OCLC WorldShare Management Services users have access to a report of all titles held by their institution, but we do not subscribe to this service. WorldShare Collection Manager queries can provide the same information. Query collections deliver sets of MARC records from which the appropriate information can be extracted. Our query searched for all MARC records that have our OCLC symbol but do not have a material type of electronic. The steps for creating the query are:
- Create a new query collection in Collection Manager.
- Under ‘Worldcat Selection Criteria’ write the following string:
li:TPA NOT 14:TPA NOT x4:digital NOT mt: elc.
- ‘li’ is the index label for the holding library symbol. TPA is our OCLC symbol.
- ‘l4’ is the index label for local holdings records, which we only set for serials. By excluding local holdings records, we were able to exclude holdings for serials.
- ‘x4’ is the format/facet in worldcat.org. While we stated that we do not want a format of digital or a material type of electronic, this double clarification might be redundant.
- ‘mt’ is the index label for material type. While we used NOT mt: elc to create a query that did not include electronic resources, NOT mt: url could have also been used to create a query for records that do not have a URL present in the 856 field.
- Select one-time delivery to prevent ongoing delivery of this large file.
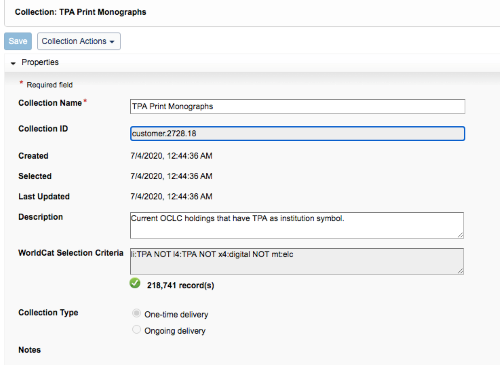
Figure 1. Screenshot of query collection in WCM - Scroll down and open the MARC Records accordion. Select ‘Deliver records for this collection in a separate file’ to ensure that these records aren’t merged with any other Collection Manager download files.
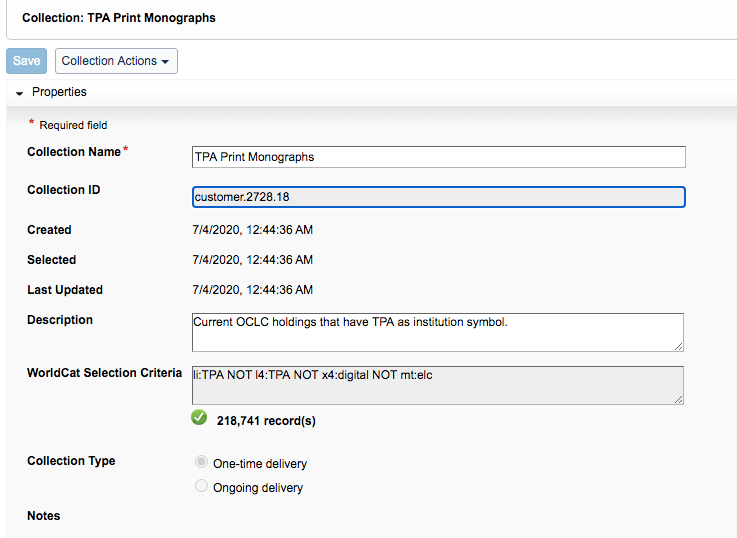
This query returned 218,741 records. According to our inventory records, we have 223,473 physical volumes in our collection that correspond to these search criteria. A portion of this discrepancy can be accounted for by factoring in the numbers for our uncataloged government documents and other non-circulating collections that do not have holdings set in OCLC.
MarcEdit
The Collection Manager query collection provided a download file with complete MARC records for each non-electronic resource that had our OCLC symbol attached to it. To compare these records with those in our ILS, it was necessary to discern a unique identifier, in this case the OCLC control number. The OCLC control number can be found in the 001 field of a MARC record, which corresponds with the bibliographic utility number in Sierra, our ILS. Depending on local cataloging practices, it may be helpful to consider the 019 (OCLC Control-Number Cross Reference), 035 field (System Control Number), or the 010 field (Library of Congress Control Number). These numbers can be isolated in MarcEdit using the find function or the tab delimited records function.
To use the find function:
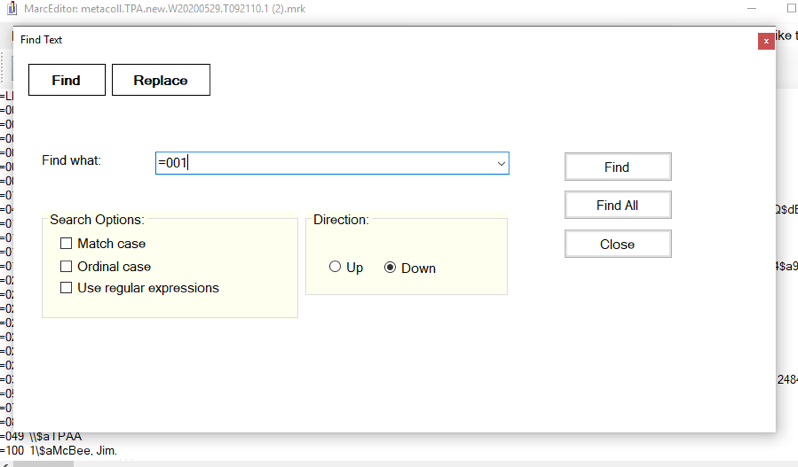
- Hold down ctrl + F or open the Find and Replace search box. Search for =001 and select ‘Find All.’
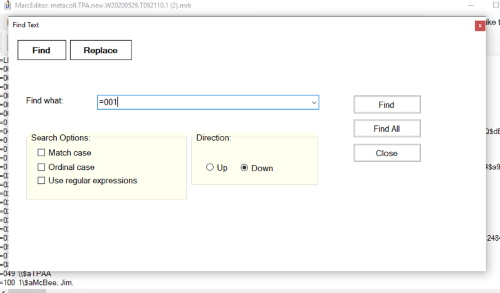
Figure 2. Screenshot of a Find and Replace search in MarcEdit. - When the search results load, click on the copy icon in the lower left-hand corner of the search results box to save the content to the computer’s clipboard (this looks like two pieces of paper stacked on top of one another).
- Open Excel and paste the control numbers. The pasted data will contain the found text (=001 [control number]) and the MarcEdit action (Jump to Record#:). Fortunately, the MarcEdit actions are in an isolated column and can easily be deleted.
- The found text and control numbers can be separated by using the ‘Text to Columns’ feature under the Data tab. The format for each cell is =001 [control number] (example: =001 49632629). Isolate the control number in a new column by using the space between =001 and the control number as a delimiter, and delete the column containing the =001 MARC field tags.
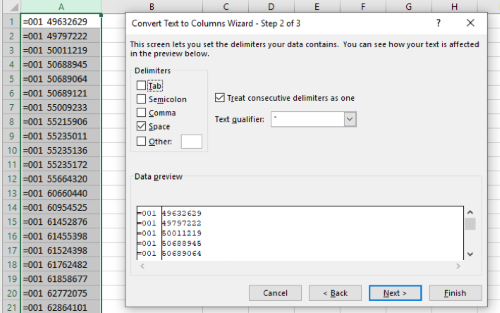
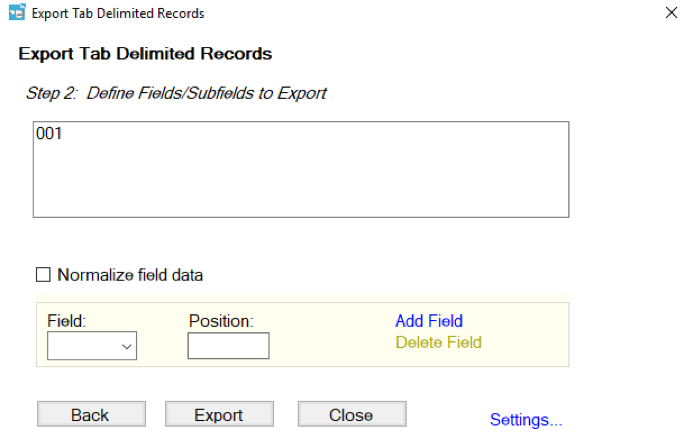
Figure 3. In ‘Text to Columns,’ use the space as a delimiter. - From the MarcEdit home screen, select ‘Export Tab Delimited Records’ under Tools.
- Set the file path from the Collection Manager download file to a new .txt file. Select tab as the field delimiter and a semicolon as the in-field delimiter.
- Add 001 as the field to export.
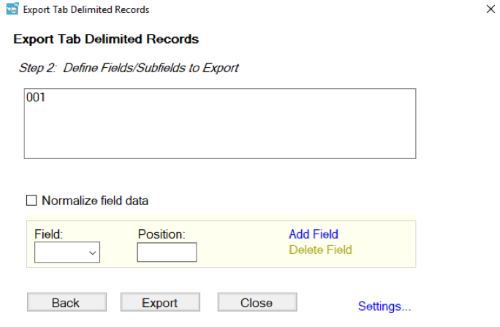
Figure 4. Add 001 as the field to export when using Export Tab Delimited Records. - Open Excel and import the external data from the new .txt file created by the MarcEdit export.
- If the data is imported in the format of [control number]\, copy and paste the following formula into an adjacent column to delete the last character (\) for each control number:
=LEFT(A1,LEN(A1)-1)
- Highlight all cells in the column of numbers without prepended zeros.
- Right click on the column and choose ‘Format Cells.’
- Choose ‘Custom’ for the category, and replace the word ‘General’ (under ‘Type’:) with the pattern 000000. This makes the minimum number of digits six and fills in the needed digits with prepended zeros.

To use the Export tab delimited records function:
Sierra ILS
Once the OCLC control numbers for non-electronic records with TPA as the OCLC symbol were identified, downloaded, and isolated, they could be compared to numbers in the 001 bibliographic utility number field in Sierra. If a record is in our collection and our holding symbol is attached to a record in Connexion, these numbers will match. If there is a number without a match, the holdings are incorrect – either because we own an item without the associated holdings or because holdings are set for an item we no longer have or for a record that has since been merged. Consider your library’s interlibrary loan circulation habits when creating a review file in the ILS. If you have non-circulating collections, such as reference or reserves, you will want to exclude these from the search.
The needed bibliographic utility numbers were identified by creating a query for non-electronic resources and exporting the 001 field for all records in the output review file. The query needed to create this review file will vary by ILS and by local cataloging practices. To pull the records for APSU, we ran a query for all bibliographic records that were in certain locations, such as main book collection, popular reading collection, and government documents. A similar search could have been performed for all records that did not have an 856 field. When satisfied with the contents of the review file, the bibliographic utility numbers were exported to a .txt file, and then imported the .txt file into Excel.
The creation of this query proved to be the most time-intensive step in this process, and the query was revised many times before the results were usable. After completing the steps below, if the file output is much smaller or larger than expected, spot check the records and adjust the search criteria accordingly.
Our final search criteria included:
ITEM RECORD = exists AND BIBLIOGRAPHIC LOCATION = general book collection OR juvenile book collection OR reference collection OR government publications OR video collection OR popular reading collection OR archives
Excel
Once lists of holdings from OCLC and the ILS have been acquired, Excel can be used to sort out entries that do not have a match. If a control number from OCLC does not have a counterpart in the ILS, it can be assumed that the record should no longer have holdings attached. Similarly, a control number that only exists in the ILS will need to have holdings set in OCLC. This does not take into account control numbers that might appear in the 010, 019, and 035 fields, but this limitation can be discussed with an OCLC cataloging specialist during the data sync process.
The imported data may have different formatting. Our ILS control numbers were exported as written, while OCLC assigned prepended zeros for all numbers with less than six characters. Excel will recognize 685 and 000685 as duplicate values, so there is no need to alter this formatting. If preferred, prepended zeros can be added to the ILS figures to make identical entries. To do so:
At this point, values with multiple entries could hypothetically be identified by using conditional formatting to highlight cells with duplicate values and then using sort and filter to remove any entries that are highlighted. However, these actions caused Excel to crash on several computers with varying levels of processing power.
CSV and Python
Scott Shumate converted the Excel data into two CSV files (one for ILS numbers and one for OCLC numbers) and wrote a Python script that compared both files and delivered values only found on one list to a separate output file. This code requires Python 3 and will need to be adjusted accordingly if using Python 2.
#!/usr/bin/env python3
# import library to let us read and write CSV files,
# and check operating system paths
import csv
import os.path
# Make an empty list/array called iii that will hold the
# iii values from our CSV
# then iterate through the csv and append each row
iii = []
with open('iii.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=",")
line_count = 0
for row in csv_reader:
iii.append(row)
line_count += 1
print("[III] Processed " + str(line_count) + " lines.")
# Make an empty list array called oclc that will hold
# the oclc values from our CSV,
# then iterate through the csv and append each row
oclc = []
with open('OCLC.csv') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=",")
line_count = 0
for row in csv_reader:
oclc.append(row)
line_count += 1
print("[OCLC] Processed " + str(line_count) + " lines.")
# Make an empty list for our output that will only contain
# our results
output = []
# Count variable is just for monitoring purposes.
# Look at each value in the iii list, then check to see
# if it is in the oclc list. If it is not,
# put that value into our output variable
# For monitoring purposes, this also checks our count and
# prints every 100 rows
count = 0
for i in iii:
if i not in oclc:
output.append(i)
count += 1
if count % 100 == 0:
print("[III] " + str(count))
# Count variable is just for monitoring purposes.
# Look at each value in the oclc list, then check to see
# if it is in the iii list. If it is not,
# put that value into our output variable
# For monitoring purposes, this also checks our count and
# prints every 100 rows
print("Done with III.")
count = 0
for o in oclc:
if o not in iii:
output.append(o)
count += 1
if count % 100 == 0:
print("[OCLC] " + str(count))
print("Done with OCLC.")
# Last but not least, output our "output" variable
# to an output csv file we can open in Excel
with open('output.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file, quoting=csv.QUOTE_NONNUMERIC, delimiter=',')
writer.writerows(output)
To get a list of records in OCLC but not our ILS, we ran the original script but deleted the following loop:
count = 0
for o in oclc:
if o not in iii:
output.append(o)
count += 1
if count % 100 == 0:
print("[OCLC] " + str(count))
print("Done with OCLC.")
Results
At this stage, it is important to spot check a few records in the output file to ensure that the queries and code behaved as expected. This process required many rounds of trial and error before a feasible solution was found. This is the approach that worked for us, but libraries with different OCLC subscriptions, ILSs, and cataloging practices will need to tweak things accordingly.
Our initial file output included 34,278 control numbers without matches. We conducted a quick review of 30 randomly selected records. Of these, 19 were present in both the catalog and OCLC holdings. Further investigation revealed that these erroneous outputs were the result of input data that needed to be cleaned up (e.g. a government document collection in which control numbers were assigned a prefix) or specific item record and bibliographic record locations that were not originally factored into the ILS query (e.g. books that were temporarily assigned to a display case or featured bookshelf).
Our final output file returned 9,676 records that did not have a match in the ILS and OCLC. We conducted another spot check of randomly selected records, this time looking at 50 records. None of the records had matches in our ILS and OCLC. Six of the 50 records had OCLC holdings but no equivalent in our ILS. The 44 remaining records did not match on the 001 field but had matches between the 001 field in our catalog record on the 019 field in OCLC.
If you are confident that your output file only contains control numbers for holdings that need to be added or deleted, this can be done quickly through a batch update in the OCLC Connexion Client. To do this, select ‘Batch Holdings by OCLC Number’ under the Batch tab, and copy and paste the relevant control numbers. This process can be used to update and delete holdings.
Because our 9,676 record output contained a mixture of holdings that needed to be deleted and records that needed to have control number updates, we processed these by creating a data sync collection in OCLC Collection Manager. Choosing to delete holdings through the Connexion Client places the responsibility on the cataloger to ensure that all of the data is accurate. When using a data sync collection to update records, an OCLC Database Specialist is assigned to the collection to review the submitted data and provide clarification on which type of data sync is required to achieve the requested modifications.
We will continue to add and delete holdings for our physical collection as items are acquired for or weeded from the collection, but this process provides the ability to spot check our collection as needed to account for the inevitable user error.
Additional resources:
To learn more about creating query collections, visit OCLC’s Collection-level settings in query collections guide [4]. To view a concise table of available indexes, visit OCLC’s Searching WorldCat indexes: Quick reference guide [5]. For a comprehensive description of all indexes, visit OCLC’s Indexes toolbox [6]. To learn more about creating data sync collection in Collection Manager, visit OCLC’s guide [7].
Bibliography
[1] OCLC. Cataloging: Take actions on bibliographic records. 2018. Available from: https://www.oclc.org/content/dam/support/connexion/documentation/client/cataloging/bibactions/bibactions.pdf
[2] OCLC. Create a Bibliographic Collection for a Reclamation. 2020, March 3. Available from: https://help.oclc.org/Metadata_Services/WorldShare_Collection_Manager/Choose_your_Collection_Manager_workflow/Data_sync_collections/Create_a_bibliographic_collection_for_a_reclamation
[3] OCLC. Available Data Sync Collections. 2019, May 7. Available from: https://help.oclc.org/Metadata_Services/WorldShare_Collection_Manager/Choose_your_Collection_Manager_workflow/Data_sync_collections/About_data_sync_collections_in_Collection_Manager/Available_data_sync_collections
[4] OCLC. Collection-level Settings in Query Collections. 2019, June 18. Available from: https://help.oclc.org/Metadata_Services/WorldShare_Collection_Manager/Choose_your_Collection_Manager_workflow/Query_collections/About_query_collections_in_Collection_Manager/Collection-level_settings_in_query_collections
[5] OCLC. Searching WorldCat Indexes: Quick Reference. 2020, February 25. Available from:
https://help.oclc.org/Metadata_Services/WorldShare_Record_Manager/Reference/Searching_WorldCat_indexes_Quick_reference
[6] OCLC. Indexes. 2017, October 12. Available from: https://help.oclc.org/Librarian_Toolbox/Searching_WorldCat_Indexes/Indexes
[7] OCLC. Data Sync Collections. 2020, May 19. Available from: https://help.oclc.org/Metadata_Services/WorldShare_Collection_Manager/Choose_your_Collection_Manager_workflow/Data_sync_collections
About the Authors
Nicole Wood (woodn@apsu.edu) is the Resource Management Librarian at Austin Peay State University in Clarksville, TN. She oversees the library’s monographs collection and maintains the library’s catalog.
Scott Shumate is the IT Analyst for Digital Services at Austin Peay State University. He works on digital initiatives and supports the use of technology in the library.

Tomasz, 2020-08-25
Thanks for sharing your experiences syncing your Worldcat holdings.
Just one quick suggestion. When comparing two large data sets as in your ILS and OCLC numbers csv files it’s much more convenient to use pandas Python package with all its magic. Finding duplicates, unique values, values present in one set but missing in the other, etc. is a breeze and can be reduced to a few lines of code. As your data sets get larger, advantages of pandas become more and more apparent.
Cheers!