by David B. Lowe, James Creel, Elizabeth German, Douglas Hahn, and Jeremy Huff
1) Introduction
A persistent challenge facing the digital library community is how to provide access to a large set of heterogeneous digital collections with disparate metadata. A widely adopted solution for searching these digital collections is Apache Solr. It is efficient and flexible open-source software with a broad user base in other industries. The Solr discovery Application Programming Interface (API) is a common solution in the library space with applications such as DSpace, Fedora, and Blacklight.
SAGE (Solr AGgregation Engine) is a new solution from Texas A&M University Libraries for aggregating Solr documents from across repositories. SAGE is an open-source application that provides two feature sets: 1) aggregation and 2) discovery views. SAGE combines any number of Solr indices (or “cores”), crosswalks the fields, and generates one (or more) aggregated index. The discovery view feature set can be utilized via the user interface (UI) or API and enables dynamic customization of search interfaces and search results for any given Solr core. SAGE source code and documentation can be found on GitHub.
Table 1. SAGE Links.
| Link Type | URL |
|---|---|
| Open Source Code | https://github.com/TAMULib/Sage |
| Collections in Production | |
| From Fedora | https://u.tamu.edu/berger-cloonan |
| https://u.tamu.edu/comrosters | |
| From DSpace | https://u.tamu.edu/cubamaps |
This article will provide an overview of the technical background of SAGE, suggest future development of SAGE, and discuss its current and future use within libraries.
2) Brief Historical Look at Library Search Tools
While Code4Lib Journal readers are undoubtedly familiar with the historical background of online searching in libraries, still there is a trend worth emphasizing that relates to the aggregational nature and function of SAGE. First, libraries can boast a strong heritage as early implementers of information and communications technology (ICT), with record #1 (The Rand McNally book of favorite pastimes) in the authoritative and collaborative OCLC bibliographic database denoted as entered in May of 1969. In the ensuing transition from card catalogs to Online Public Access Catalogs (OPACs), the library community embraced technologies such as Telnet, Gopher, and Wide Area Information Server (WAIS) to share the records of their holdings and make them searchable. While the card catalog had been an access system mostly limited to what books were on a given library’s shelves, forsaking it left some of the more nostalgic information seekers with nasty dispositions (see Baker 1994); in the end, the scale of library holdings and their growth rates were destined to overwhelm our analog systems. Harnessing the unstoppable force of the Web throughout the 1990s translated into momentum that could match that grand scale such that today, rare is the library that cannot be searched via browser online.
The succeeding generation of library catalogs, dubbed “discovery services,” sought to bring not just the physical book collections but also the library’s subscription content accessible online within typeable reach of a single search box. Like SAGE, discovery services feature a unified index of all the items they cover. They followed a foray into what were deemed “federated search” tools which covered essentially these same disparate resources, but the federated search tools attempted to access a heterogeneous array of indices in real time, so their comprehensive result sets were routinely thwarted by network traffic and other responsiveness factors. For both federated and discovery services, the technical innovation shared with SAGE is a heterogeneous index or set of indices from multiple sources that can be brought together into a single, searchable unit for the end-user.
In parallel with the rise of discovery tools, and in the wake of concurrent mass digitization efforts, ICT implementers in libraries began to devote increasing attention to making their freshly digitized collections available. Another development intertwined here from the early 2000s was the rush to build institutional repositories, primarily in support of Open Access (OA) efforts by providing a platform for hosting faculty, graduate, and (usually Honors-related) undergraduate student research. The lines between strictly defined institutional repositories (containing theses, dissertations, and OA journal articles) and venues for digital collections scoped more broadly (historical photographs, letters, maps, etc.) often became blurred.
Also in the 2000s, the information landscape witnessed two more important, related trends: mass book digitization and web search tool frameworks that made searching these new large text corpora possible in a timely manner. In order to index not just the metadata now, but also the bulky full text from within these millions of books required new tools, and the root driving force for searching that mixture of metadata and content has been Apache Lucene, first written by Doug Cutting and released in 1999 (Ingersoll 2007). Lucene still, as of July 2021, holds close to one third (31.66%) market share in the Enterprise Search category, according to Datanyze (Datanyze 2021). And it has fruitfully borne successful offspring. Hot on Lucene’s heels (currently at 31.46% market share) is Solr, based on the Lucene search library and created in 2004 by Yonik Seeley at CNET (Thuma 2018), who donated it to the Apache Software Foundation in 2006. Notably, HathiTrust, as the largest (currently over 17 million items) full-text book searching operation yet achieved by libraries, relies on Solr to power its searches. To close this thread, two other library-related, Lucene-based search tools worth noting include Elasticsearch (with 7.43% market share), first released by Shay Banon in 2010 (Banon 2010), and secondly XTF (eXtensible Text Framework), first released in 2005 (Haye 2005) by the California Digital Library (CDL) and used in some digital collections and archival finding aid applications in research libraries. It is Solr, though, that is most relevant to the topic of this paper.
To focus on digital library applications, it is fair to note that SAGE is not unique in the way it leverages these critical Solr resources. In fact, it owes much to the established Blacklight software efforts. Blacklight traces its origins to 2009 at the University of Virginia. In the Texas A&M University Libraries context, as we implemented Blacklight’s cousin Spotlight as our digital exhibits presentation tool, we also considered Blacklight, which is written in Ruby on Rails. Since our application development shop leans more toward Java, it was only natural that our developers sought to manipulate this critical piece of our architecture more nimbly and fluently.
3) Ecosystem Context
Concerning the people involved, the Digital Initiatives Unit at Texas A&M University Libraries includes an Applications Development team that produces custom software for the Libraries and contributes to open-source products that advance the Libraries’ mission. Past successes include a major role, in collaboration with the Texas Digital Library, in the development of Vireo (https://github.com/TexasDigitalLibrary/Vireo), a workflow tracking application for approving and depositing electronic theses and dissertations into institutional repositories. Vireo has been implemented widely among research universities thanks to its thoughtful design and ease of use. Among current projects, TAMU developers are heavily involved in the new open-source Integrated Library System known as FOLIO (for “the Future of Libraries is Open;” see: https://github.com/folio-org). A commitment to open-source is a part of the team ethos, and they pursue opportunities for collaborative development.
Concerning the technology involved, Solr provides an HTTP API to a backend implemented with the Apache Lucene search library. As we have seen, the Solr search platform is common in digital library applications such as catalogs, digital repositories, and other discovery tools. The Texas A&M University Libraries run a number of Solr-based applications, including instances of DSpace, Fedora, Spotlight, VuFind, and SAGE.
In a single-search-box world, our library patrons have come to expect the ability to search across various sources regardless of the application. However, providing such a search service presents technical challenges. The fact that all these applications employ Solr offers us a way forward.
The primary technical challenge in providing search across heterogeneous collections is the homogenization of their metadata. For the most part, a metadata schema’s implementation tends to be specific to an institution. Most library search applications allow for customization of the metadata schema and how documents appear in a search index. Efforts to standardize schemas across institutions can impose some order, but it seems unlikely to us that the worldwide library community will settle on one schema to rule them all. Some efforts that have had considerable success in specific contexts include MARC, Dublin Core, BIBFRAME, and schema.org. However, even broad multi-institution adoption of a schema standard (as has been the case with Dublin Core in DSpace) does not render metadata interoperable – local practices for what goes in a particular field will vary and local customizations to the schema are all but inevitable.
Furthermore, even within an institution with consistent practices, the metadata will vary across collections of different types of items. For example, photographs may not bear titles, but may require descriptive fields not applicable to print documents.
The requirements and restrictions of a Solr core afford SAGE a useful structural starting point. Solr cores consist of documents that themselves consist of keys and values in a flat structure. As adventitious and heterogeneous as a set of records may be, if it has been indexed into Solr, it must adhere to this structure. At the heart of SAGE is a mechanism for defining how a key in one Solr core could be mapped to a key in an aggregated index. Through this mechanism, a curator may choose how to reconcile and normalize the indices throughout the ecosystem. Furthermore, as we will see, a curator may choose different mappings for different ways of viewing the collections.
4) Aggregation
At the center of SAGE is aggregation, which may be considered analogous to an ETL (Extract, Transform, Load) process. Each aggregation process is referred to as a “job” and employs any number of each of these four elements:
- Internal Metadata: a user-defined set of metadata keys or labels
- Reader: gathers data from a source Solr core and employs a user-defined mapping from that source into SAGE’s Internal Metadata
- Operator: takes a value from a specified key from the source and performs pre-defined operations such as transformations (e.g., regex) or normalizations (e.g., date formatting)
- Writer: outputs the internal metadata, utilizing a user-defined mapping into an external Solr core
Through this process it is possible to normalize or modify the data using SAGE’s user-specified operators so that a uniform search experience can be provided to end-users even though the original Solr cores may be disparate and contain incomplete data. SAGE provides administrators with a simple interface to configure the aggregation process. In summary, the SAGE aggregation process, or job, reads a Solr core, performs any data manipulation through the operators, transforms data into a standard metadata schema, and writes the data into the SAGE Solr core.
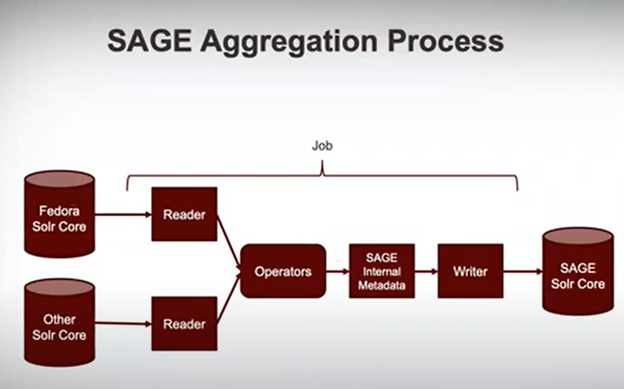
Figure 1. Aggregation: Overview.
Internal Metadata
The internal metadata schema is the local storage that SAGE uses to preserve the data elements that are read from various Solr cores. It can be created and modified at any time. There is no limit to the number of metadata elements that can be created, and the schema should contain all the elements that might be needed for aggregation. In defining the internal metadata schema for Texas A&M Universities Libraries we relied heavily on our Libraries’ metadata guidelines for our digital collections: https://hdl.handle.net/1969.1/175368.
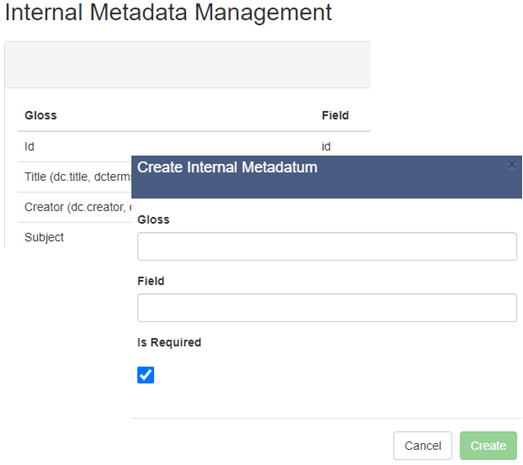
Figure 2: Aggregation: Internal Metadata.
Readers
Readers handle the process of running a query against a Solr core and of harvesting the data to be stored in the internal metadata. This process involves crosswalking the Solr core data definitions to the internal metadata schema. For Texas A&M Universities Libraries it is not uncommon for our digital collections to exist in DSpace and Fedora Solr cores. Below is an example of mapping the Solr fields from DSpace and Fedora into the internal metadata schema based on our metadata guidelines.
|
DSpace Solr core element |
Fedora Solr core element |
SAGE Internal metadata |
|
dc.title |
title |
Title |
|
dc.subject |
subject_ss |
Subject |
|
dc.creator |
creator_ss |
Creator |
Table 2: Aggregation: Possible metadata crosswalk mappings used by SAGE Readers
Operators
A powerful characteristic of SAGE is the operator feature. Operators are built in transformation functions that can be applied to the data as it flows through the aggregation process. These functions can be added to or expanded upon as needed. For example, one operator may perform data normalization so that all known variations on a given field could be standardized ensuring the results are consistent.
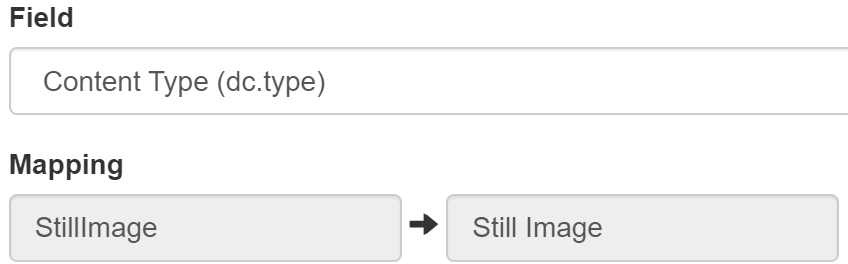
Figure 3. Aggregation: Operators.
Writers
Writers are similar in setup and use to the readers except they take the internal metadata and push it out to a Solr core which is used by Discovery. Moreover, multiple writers can push internal metadata with specific transformations to a single SAGE Solr core.
Figure 4. Aggregation: Writers.
Once the readers, operators, and writers are properly defined, it is possible to rapidly create multiple SAGE Solr cores that can be used by the Discovery view. Through this process the institution is able to easily highlight and promote disparate content and collections that normally may be buried deep in incompatible systems.
5) Discovery Views
Discovery View General Description
Aside from the creation of Solr cores from disparate sources, SAGE offers the Discovery View feature set. This suite of features focuses on exposing the aggregate cores through an attractive discovery interface. These interfaces can be created by administrative users and can be highly customized within the context of a management dashboard. Once created, they can be utilized by the end-users to conduct both keyword text and faceted searches of the aggregated data set.
Discovery Views for End-Users

Figure 5. Discovery View: Results Page.
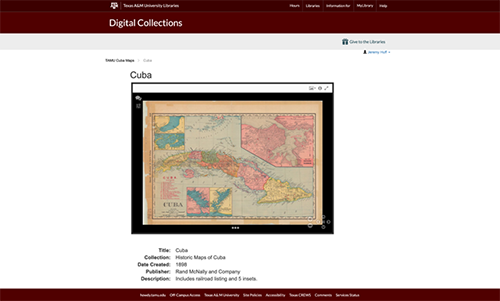
Figure 6. Discovery View: Single Item View.
SAGE’s Discovery View feature set is distributed between two modes of UI interaction: administrative and end-user. For the end-user, SAGE Discovery Views are landing pages featuring various form inputs which allow for several modes of search queries, and a results section that displays all records retrieved through the user’s query. After a search is executed, either through a keyword text query or a faceted search, the results are depicted in a list. Each result displays a predetermined subset of the record’s metadata and serves as linked navigation to a Single Item View. The Single Item View for any record displays a more complete depiction of the selected record’s public metadata as well as rendering the digital object via a viewer appropriate to its resource type.
Discovery Views for Administrators
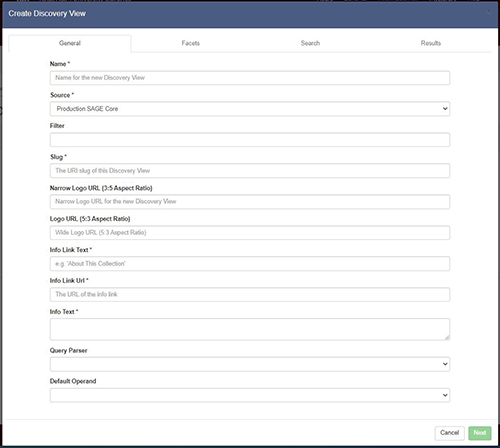
Figure 7. Discovery View: Single Item View.
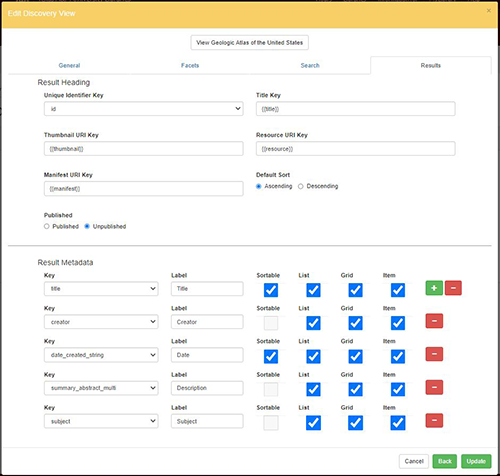
Figure 8. Discovery View Editing: Results Tab.
For the administrative user, SAGE Discovery Views offer a management dashboard that allows for the creation and customization of these Discovery Views. Each Discovery View can expose any Solr core known to the SAGE application. A Discovery View can be configured to pre-filter the records it exposes by providing a canned Solr filter query. This means that a discrete Discovery View does not necessarily need to expose the entirety of the Solr core upon which it is based. Given this, multiple Discovery Views might be created for different subsets of the same Solr core. For example, while there might be a single Fedora Solr core, there could be multiple Discovery Views based upon specific collections.
The fields and the widgets used to interact with these facets can be selected through the administrative interface, as well as the keys which are available for the text-based searches. Through this customization interface, the administrator can also select what metadata will be displayed within the result list as well as within the Single Item View. Additionally, various elements of the landing page can be customized, including a thematic image, associated links, and introductory text.
The Rationale Behind Discovery Views
A driving force behind the creation of SAGE Discovery Views was a desire to achieve two primary conveniences. The first of these is the ability to deploy and maintain a single instance of an application which allows for the creation and customization of multiple Search Engine Results Page (SERP), each with a unique configuration. If instead there is a one-to-one relationship between a SERP’s configuration and the application providing that view, the multiplication of SERPs would result in an increase in resource expenditure both in maintenance time and computing resources.
Secondly, it was desirable that the configuration of Discovery Views be exposed through a user interface and not require developer intervention to create or modify. This would empower non-developers to both expose and maintain the records they wished to make available through discovery.
Potential Future Development for Discovery Views
To date, SAGE is capable of rendering records with various viewers, including Mirador 2, the browser’s native PDF viewer, and a basic text renderer. These viewers are easily expanded upon, and this represents one area where SAGE can grow. Support for audio, video, map, and 3D object viewers are all plausible areas where SAGE is likely to see development.
Additionally, the facet widgets which SAGE exposes can be expanded. Currently, SAGE allows for link-list facet and free text facet (with type-ahead support) to be configured for each facet field. Additional facet widgets, such as range selection or geo-coordinate input, would greatly increase the value of SAGE discovery views.
6) Broader Implications
Implementing Disparate Data Source Types
Currently, SAGE has been developed to aggregate a single type of data source into a combined Solr core, and that source type is itself the Solr core. A possible future innovation in SAGE could be the addition of multiple source types. This would allow SAGE to create aggregate Solr cores not only from other Solr cores, but from disparate sources, such as: CSVs; TSVs; various APIs; or IIIF Collection Metadata. The potential source types that might be implemented are practically limitless. Fortunately, the groundwork for a feature of this nature was planned for in the earliest iterations of SAGE, reducing the development barrier for these disparate sources to be implemented.
General Library Discovery
The library discovery ecosystem comprises many systems and interfaces including legacy OPACs, e-journal search platforms, database directories, and local repositories. SAGE has the potential to move the library discovery space to an extensible search model where new targets are able to be developed and incorporated into the Libraries’ search strategy while maintaining a consistent search experience for users. The Discovery Views feature set enables non-developers to create and manage these experiences without the need to burden valuable developer time and resources. Future work can include additional value-added services such as recommendation, spell check, and other automated search assistance at a view-by-view level and additional views for any Solr-based system within the library’s discovery ecosystem and in the future, any source type.
Digital Humanities and Remixing
At the most basic level, the Discovery View capabilities unlock numerous potential applications for digital humanities (DH) and other text-focused research. Awareness of a digital object is an important first step in research, followed by the usual concerns while searching sets of things, such as precision and recall. The flexibility of Solr enables all of the above. Within a result set, researchers can turn to manipulating SAGE’s facets for counts to use in statistical inquiries relevant to sets of metadata and full text. As mentioned immediately above, the future direction of empowering the searcher to extend the greater index set would be another boon to DH in particular and text-based searching in general.
Bibliography
Always Already Computational – Collections as Data. “Collections as Data Facets.” Accessed January 8, 2021. https://collectionsasdata.github.io/facet1/.
Anant/Awesome-Solr. 2017. Anant Corporation, 2021. https://github.com/Anant/awesome-solr.
“Apache Solr.” Accessed January 8, 2021. https://lucene.apache.org/solr/.
Baker N. 1994 “DISCARDS.” The New Yorker, April 4, 1994. https://www.newyorker.com/magazine/1994/04/04/discards.
Banon, Shay. “You Know, for Search.” Elastic Blog, February 8, 2010. https://www.elastic.co/blog/you-know-for-search.
Becker D, Williamson E, and Wikle O. “CollectionBuilder-CONTENTdm: Developing a Static Web ‘Skin’ for CONTENTdm-Based Digital Collections.” The Code4Lib Journal, no. 49 (August 10, 2020). https://journal.code4lib.org/articles/15326.
Bolton, M, Creel J, Day K, Hahn D, Huff J, Laddusaw R, Savell J, and Welling W. “User-Configurable Discovery Across Collections,” May 22, 2019. https://tdl-ir.tdl.org/handle/2249.1/156404.
Cartolano RT. “History of Blacklight,” 2015. https://doi.org/10.7916/D8J38S9M.
Cole TW., and Shreeves SL. “Search and Discovery across Collections: The IMLS Digital Collections and Content Project.” Library Hi Tech 22, no. 3 (January 1, 2004): 307–22. https://doi.org/10.1108/07378830410560107.
Datanyze. “Apache Solr Market Share and Competitor Report | Compare to Apache Solr, Apache Lucene, Swiftype.” Datanyze. Accessed July 5, 2021. https://www.datanyze.com/market-share/enterprise-search–287/apache-solr-market-share.
———. “Enterprise Search Market Share Report | Competitor Analysis | Apache Lucene, Apache Solr, Swiftype.” Datanyze. Accessed July 5, 2021. https://www.datanyze.com/market-share/enterprise-search–287.
DB-Engines. “DB-Engines Ranking.” Accessed January 8, 2021. https://db-engines.com/en/ranking/search+engine.
Digital Library Services Task Force. “Final Report [of the] Digital Library Services Task Force 2.” University of California Libraries, 2011. https://libraries.universityofcalifornia.edu/groups/files/dlstf/docs/DLSTF2_FINAL_10May2011.pdf.
DuPlain R, Balser DS, and Radziwill NM. “Build Great Web Search Applications Quickly with Solr and Blacklight.” In Software and Cyberinfrastructure for Astronomy, 7740:774011. International Society for Optics and Photonics, 2010. https://doi.org/10.1117/12.857899.
European Commission. Joint Research Centre. Institute for Prospective Technological Studies. “Enterprise Search in the European Union: A Techno Economic Analysis.” LU: Publications Office, 2013. https://data.europa.eu/doi/10.2791/17809.
Gaona-García PA, Martin-Moncunill D, and Montenegro-Marin CE. “Trends and Challenges of Visual Search Interfaces in Digital Libraries and Repositories.” The Electronic Library 35, no. 1 (January 1, 2017): 69–98. https://doi.org/10.1108/EL-03-2015-0046.
Gilbert H, and Mobley T. “Breaking Up With CONTENTdm: Why and How One Institution Took the Leap to Open Source.” The Code4Lib Journal, no. 20 (April 17, 2013). https://journal.code4lib.org/articles/8327.
Goodmann E, Matienzo MA, VanCour S, and Vanden Dries W. “Building the National Radio Recordings Database: A Big Data Approach to Documenting Audio Heritage.” In 2019 IEEE International Conference on Big Data (Big Data), 3080–86. Los Angeles, CA, USA: IEEE, 2019. https://doi.org/10.1109/BigData47090.2019.9006520.
Haye, Martin. “Internationalizing XTF: Bringing Multilingual Features to the Extensible Text Framework,” May 2005. https://xtf.cdlib.org/wp-content/uploads/2010/08/Internationalizing_XTF_v2.pdf.
Ho J, and Stokes CK. “Metadata Guidelines for Digital Resources at Texas A&M University Libraries.” Working Paper, May 16, 2019. https://oaktrust.library.tamu.edu/handle/1969.1/175368.
Ingersoll, Grant. “Better Search with Apache Lucene and Solr.” 2007. https://web.archive.org/web/20120131154001/http://trijug.org/downloads/TriJug-11-07.pdf.
Kelbert P, Droege G, Barker K, Braak K, Cawsey EM, Coddington J, Robertson T, Whitacre J, and Güntsch A. “B-HIT – A Tool for Harvesting and Indexing Biodiversity Data.” PLoS ONE 10, no. 11 (November 6, 2015). https://doi.org/10.1371/journal.pone.0142240.
“Large-Scale Full-Text Indexing with Solr | Www.Hathitrust.Org | HathiTrust Digital Library.” Accessed July 5, 2021. https://www.hathitrust.org/blogs/large-scale-search/large-scale-full-text-indexing-solr.
Pham K, Reyes F, and Rynhart J. “Building a Library Search Infrastructure with Elasticsearch.” Code4Lib Journal, no. 48 (May 1, 2020). https://proxy.library.tamu.edu/login?url=https://search.ebscohost.com/login.aspx?direct=true&db=edsdoj&AN=edsdoj.594fb9ee35e64189900db986330db681&site=eds-live.
Pretoro ED, De Roock E, Fremout W, Buelinckx E, Buyle S, and Van der Stede V. “Optimizing Elasticsearch Search Experience Using a Thesaurus.” The Code4Lib Journal, no. 51 (June 14, 2021). https://journal.code4lib.org/articles/15749.
Seeley Y. “A History of Lucene and Solr.” Solr ’n Stuff (blog), June 16, 2014. https://yonik.com/lucene-solr-history/.
Thuma, John. “What Is Apache Solr.” Medium, August 9, 2018. https://johnthuma.medium.com/what-is-apache-solr-a18a60004e70.
Weig EC, and Slone M. “SPOKEdb: Open-Source Information Management System for Oral History.” Digital Library Perspectives 34, no. 2 (January 1, 2018): 101–16. https://doi.org/10.1108/DLP-03-2017-0012.
Williams S. “Better Search Through Query Expansion Using Controlled Vocabularies and Apache Solr.” The Code4Lib Journal, no. 20 (April 17, 2013). https://journal.code4lib.org/articles/7787.
Zhang H, Durbin M, Dunn J, Cowan W, and Wheeler B. “Faceted Search for Heterogeneous Digital Collections.” In Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries, 425–26. JCDL ’12. New York, NY, USA: Association for Computing Machinery, 2012. https://doi.org/10.1145/2232817.2232924.
Acknowledgements
The authors would like to acknowledge additional SAGE project developers Michael Bolton, Kevin Day, Ryan Laddusaw, Rincy Mathew, Jason Savell, and William Welling.
About the Authors
David B. Lowe (https://orcid.org/0000-0003-2856-8629 ) is an assistant professor and the Digital Collections Management Librarian at Texas A&M University Libraries, where he was recently selected as one of eight 2021 Texas A&M Institute of Data Science Career Initiation Fellows. His work responsibilities include policies and procedures for digital collections and the institutional repository in the Libraries. His research interests include applications of artificial intelligence and machine learning techniques to text mining in a scholarly communication and digital humanities context, with digital collections as data.
James Creel is a Software Applications Developer IV at Texas A&M University Libraries. James holds a Master of Science degree in Computer Science from Texas A&M and has 15 years of experience developing and managing digital library applications.
Elizabeth German is an associate professor and the Service Design Librarian at Texas A&M University Libraries where she focuses on bringing together user experience, project management, and accessibility in order to provide quality user experiences for researchers and learners. Her research interests include library search behavior, accessibility inclusion, and assessment.
Douglas Hahn is the Director of Library Applications and Integration at Texas A&M University Libraries with over 20 years’ experience in the computer information technology field. He received a Master of Science degree from University of North Texas. His current interests are in the evolution of the web, and technology’s impact on society.
Jeremy Huff is a Software Applications Developer III at Texas A&M University Libraries and has been involved in software development at the Libraries for the past 8 years. In addition to development on SAGE, he has represented the Libraries at Texas A&M on several other open-source projects, including both FOLIO and Vireo.

Subscribe to comments: For this article | For all articles
Leave a Reply