By Emmanuel Di Pretoro, Edwin De Roock, Wim Fremout, Erik Buelinckx, Stephanie Buyle, and Véronique Van der Stede
Introduction
With the HESCIDA project [1], KIK-IRPA [2] wishes to transform how users search across its collections. Now, the search platform, called BALaT [3], queries the API of the Collections Management System (CMS), namely Adlib Xplus [4]. A first step towards achieving a new system, called BALaT+, is to replace those API calls with another component, based on Elasticsearch [5], which is a search engine based on Lucene that is available via a REST API. Using Elasticsearch will allow more fine-tuning about the way data are indexed. The next step consists of integrating other datasets in BALaT+, such as the data produced from the scientific and technical research performed by KIK-IRPA researchers. BALaT+ must offer at least features on par with the current system but should eventually improve the overall search experience.
During the initial installation and configuration of Elasticsearch it became obvious that it was possible to exploit and profit from the work already done within the library and photo library part of the current system. The latter contains 98,037 entries, which can be terms coming from Dutch, English, or French. This thesaurus is used to describe the works of the library, and the resources of the photo library.
In this article, the exploratory work done to configure Elasticsearch and thus offer the expected functionalities for BALaT+ will be presented.
Overview of the method
The task at hand consists of generating configuration files for Elasticsearch based on a thesaurus available in a CMS. One solution would be to devise a specific algorithm to obtain that result, for instance by creating a data structure and querying it to obtain linguistic equivalences and narrower terms, an alternative would be to benefit from existing technologies to get to the results quicker and with less effort. To do so, a Resource Description Framework (RDF) graph [6] will be built by using a specialized vocabulary named Simple Knowledge Organization System (SKOS) [7], that help express basic structure and content of concept schemes such as thesauri [8]. In practical terms, the thesaurus will be converted in SKOS as an RDF/Turtle file to be later imported in an RDF graph, SPARQL [9] queries will then be used to get the needed information, and some basic processing will take place to format the results of queries as synonym files for Elasticsearch.
This solution is much more flexible than an ad hoc algorithm, as only the SPARQL queries will need to be updated if new situations need to be handled. And it is also a much stronger solution as proven technologies are used.
Collecting the thesaurus from Adlib Xplus
As mentioned, the CMS used by KIK-IRPA is Adlib Xplus from Axiell. To retrieve the thesaurus, the Adlib web API [10] was chosen as the easiest method. That API offers access to all the databases present in the CMS. To achieve this, a simple query to the search [11] command of the API is needed which looks like this query: http://adlib_server/wwwopac/wwwopac.ashx?database=thesau&search=all. The URL can be explained as follow:
- The Adlib Xplus installation part: http://adlib_server/wwwopac/wwwopac.ashx;
- The query part: the database parameter with the name of the database to query and the query parameter. A special keyword, all, is used to ask Adlib Xplus to return all records from the database.
It returns an XML file that looks like:
<adlibXML>
<recordList>
<record priref="2" created="2013-08-17T21:28:40" modification="2020-07-18T17:07:38" selected="False">
<broader_term>philosophie</broader_term>
<broader_term.lref>3</broader_term.lref>
<equivalent_term>metafysica</equivalent_term>
<equivalent_term.lref>1187</equivalent_term.lref>
<narrower_term>âme</narrower_term>
<narrower_term>beauté</narrower_term>
<narrower_term>cosmologie[f]</narrower_term>
<narrower_term>esthétique</narrower_term>
<narrower_term>mort</narrower_term>
<narrower_term>vie</narrower_term>
<narrower_term>vitalisme[f]</narrower_term>
<narrower_term.lref>39</narrower_term.lref>
<narrower_term.lref>65</narrower_term.lref>
<narrower_term.lref>121</narrower_term.lref>
<narrower_term.lref>63</narrower_term.lref>
<narrower_term.lref>83</narrower_term.lref>
<narrower_term.lref>84</narrower_term.lref>
<narrower_term.lref>35152</narrower_term.lref>
<priref>2</priref>
<term>
<value lang="">métaphysique</value>
</term>
<term.code>fr</term.code>
</record>
.
.
.
</recordList>
<diagnostic>
<hits>98037</hits>
<xmltype>Grouped</xmltype>
<first_item>1</first_item>
<search>All</search>
<sort/>
<limit>10</limit>
<hits_on_display>10</hits_on_display>
<response_time unit="mS" culture="nl-BE">2850,285</response_time>
<xml_creation_time unit="mS" culture="nl-BE">35,0035</xml_creation_time>
<link_resolve_time unit="mS" culture="nl-BE">25,0025</link_resolve_time>
<dbname>thesau</dbname>
<dsname/>
<cgistring>
<param name="database">thesau</param>
</cgistring>
</diagnostic>
</adlibXML>
The XML returned for the query consist in two parts. The first part is the recordList element that will be either empty or composed of one or multiple record elements, which are the data needed. The second part is the diagnostic element that contains various information related to the execution of the query on Adlib Xplus: the response time, the total number of results, the query, etc. The entire result of this query was stored in a file after processing it with the Python module xmltodict [12] and some basic modifications such as normalizing the keys of the returned dictionary, or the deletion of useless information. The JSON format was chosen because it is easier to work with and is the default format used by Catmandu [13], the tool chosen to transform our data into SKOS.
Data conversion
The JSON file containing the entire thesaurus needs to be transformed into SKOS so that it can be imported into an RDF graph and be queried easily with SPARQL. To do the conversion, Catmandu was used. It is a specialized tool aimed at facilitating access and conversions of data from different formats and origins.
Before diving into the technical stuff, here is a short explanation of the approach used:
- A SKOS representation of the data is required to be easily imported in an RDF graph; the specific serialization format is not relevant as the chosen tools are able to work as easily with RDF/XML, RDF/Turtle or any other RDF serialization format. RDF/Turtle was chosen because it is more compact and more human-readable;
- A template [14] will be applied to transform each record into an RDF/Turtle representation;
- The result of this processing will be saved into a file for later use.
So, consider the following data as input in JSON:
[
{
"priref": 1,
"term": "Astronomie",
"broader_term_lref": [
2
],
"narrower_term_lref": [
3
]
},
{
"priref": 2,
"term": "Sciences naturelles",
"narrower_term_lref": [
1
]
},
{
"priref": 3,
"term": "Astrolabe",
"broader_term_lref": [
1
]
}
]
the following result in RDF/Turtle is expected:
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix thesau: <http://hescida.kikirpa.be/thesau/skos/term#> .
thesau:1 a skos:Concept ;
skos:broader thesau:2 ;
skos:narrower thesau:3 ;
skos:prefLabel "Astronomie" .
thesau:2 a skos:Concept ;
skos:narrower thesau:1 ;
skos:prefLabel "Sciences naturelles" .
thesau:3 a skos:Concept ;
skos:broader thesau:1 ;
skos:prefLabel "Astrolabe" .
This was achieved by Catmandu using the following command:
catmandu convert JSON --file ../data/thesau.json to Template --template_before skos_turtle-before.tt --template skos_turtle.tt --file thesau_skos.ttl
And the explanation of this command:
-
- convert is the command provided by Catmandu that allow us to specify format to use via an architecture of importer and exporter plugins:
- JSON: the importer to use;
- –file ../data/thesau.json: a parameter to locate the JSON file to process; in our case, this is the export of the thesau database as mentioned previously;
- to: a part of the convert command letting us specify the name of the exporter to use;
- Template: the exporter to use; as the name suggest, text templates will be used to transform our data into another form; two templates will be used: one will be a preamble and will be called only once, and the other will be called for each record in the data;
- –template_before skos_turtle-before.tt to specify the template to apply before the beginning of the processing;
- –template skos_turtle.tt to specify the template file to apply to each record;
- –file thesau_skos.ttl to specify to the Template exporter where to store the result of the processing. In our case, a file named thesau_skos.ttl.
- JSON: the importer to use;
- convert is the command provided by Catmandu that allow us to specify format to use via an architecture of importer and exporter plugins:
Here is the content of the Template Toolkit [15] templates used.
Firstly, the skos_turtle-before.tt template used as a header for the result file, in which prefixes are defined that will be used later when creating SKOS concepts. These are respectively:
@prefix skos: <http://www.w3.org/2004/02/skos/core#> . @prefix thesau: <http://hescida.kikirpa.be/thesau/skos/term#> .
Secondly, the skos_turtle.tt template that was used to convert each JSON object into Turtle representation. Here is the content of the template:
[% IF priref.0 %]
thesau:[% priref.0 %] a skos:Concept ;
[%- FOREACH bterm IN broader_term_lref %]
skos:broader thesau:[% bterm %] ;
[%- END %]
[%- FOREACH nterm IN narrower_term_lref %]
skos:narrower thesau:[% nterm %] ;
[%- END %]
[%- FOREACH eterm IN equivalent_term_lref %]
skos:exactMatch thesau:[% eterm %] ;
[%- END %]
[%- FOREACH rterm IN related_term_lref %]
skos:relatedMatch thesau:[% rterm %] ;
[%- END %]
[%- IF term_code %]
skos:prefLabel "[% term.0.dquote %]"@[% term_code.0 %] .
[%- ELSE %]
skos:prefLabel "[% term.0.dquote %]" .
[%- END %]
[%- END %]
Elasticsearch configuration & the notion of Elasticsearch synonyms
Elasticsearch is positioned as a search engine accessible via a RESTful API. The index configuration allows for extremely detailed control to offer a rich and flexible search experience for users.
In this article, one of the configuration possibilities of Elasticsearch is of particular interest to us: the concept of synonyms [16]. This works as follows: when documents are submitted to Elasticsearch, the latter will apply several classic search engine treatments. One of these processes is tokenization: the production of strings (tokens) that will be integrated into the inverted index, the heart of any search engine. Synonyms are used as a token filter [17] and allow the interpolation of values. This is useful when variations of writing the same concept existed, for example: ipod, i-pod, i pod. In this situation, a list of correspondences is given that will match any of the entries in the list.
Elasticsearch allows us to structure the matching list in two ways. The first is to write the values on a line, separated by commas. This method, called synonym equivalences, means that all the values will be used in the index, and will thus allow finding results using any of the values. In this article, that solution is used for bilingual synonyms that will give us the multilanguage search feature. The second way to structure the list of synonyms is to use the syntax of explicit matchings. Here is an example of this syntax: sea cookie, sea biscuit => seabiscuit. This way, the values on the left side of the => are replaced by the values to the right of the symbol. This syntax is used for hierarchical synonyms that will give us the broaden search feature.
Generating bilingual synonyms
Once the concepts in the JSON file have been converted to the RDF/Turtle format, the necessary configuration for Elasticsearch can be generated.
First, the equivalences between languages are generated to provide the multilanguage search functionality. To achieve this, a graph was built with RDFLib [18], the Turtle data were imported, a SPARQL query was submitted and finally search results were processed to produce the file in the format required by Elasticsearch, namely “term1,term2”.
Here is the excerpt of the script that generates our list of bilingual synonyms:
def generate_bilingual(graph, output):
qres = graph.query("""
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX thesau: <http://hescida.kikirpa.be/thesau/skos/term#>
SELECT ?label ?equivalent WHERE {
?term skos:prefLabel ?label ;
skos:exactMatch ?concept .
?concept skos:prefLabel ?equivalent .
FILTER((LANG(?label) = "fr" && LANG(?equivalent) = "nl") || (LANG(?label) = "nl" && LANG(?equivalent) = "fr")) .
}
""")
seen = {}
with Path(output).open(mode="w") as outfile:
for row in qres:
term1 = synonym_cleaning(row[0])
term2 = synonym_cleaning(row[1])
if term1 != term2 and term1 not in seen and term2 not in seen:
outfile.write(f"{str(term1)},{str(term2)}\n")
seen.update({
term1: 1,
term2: 1
})
The complete script is available on the companion GitHub repository of this article [19].
Here are some explanations on the main aspects:
-
-
- The SPARQL query to obtain the list of linguistic equivalences is as follows:
PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX thesau: <http://hescida.kikirpa.be/thesau/skos/term#> SELECT ?label ?equivalent WHERE { ?term skos:prefLabel ?label ; skos:exactMatch ?concept . ?concept skos:prefLabel ?equivalent . FILTER( (LANG(?label) = "fr" && LANG(?equivalent) = "nl") || (LANG(?label) = "nl" && LANG(?equivalent) = "fr") ) . } - Currently, queries are explicitly limited to French and Dutch concepts with the filter part of the query;
- The synonym_cleaning() function is used to remove any syntax elements that are forbidden by Elasticsearch in a list of synonyms. The following cleaning operations are performed: lowercasing, deletion of commas, square brackets and slashes;
- The result of this processing is stored in a file for later use.
- The SPARQL query to obtain the list of linguistic equivalences is as follows:
-
Generating hierarchical synonyms
To produce hierarchical synonyms, the same approach as for bilingual synonyms is adopted. In fact, the script is almost identical, except for the data generation function, presented below:
def generate_hierarchical(graph, output):
h = dict()
qres = graph.query("""
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX thesau: <http://hescida.kikirpa.be/thesau/skos/term#>
SELECT ?term ?prefLab (count(?middle)-1 as ?distance) WHERE {
?category skos:prefLabel ?term ;
skos:narrower* ?middle .
?middle skos:narrower* ?concept .
?concept skos:prefLabel ?prefLab .
}
GROUP BY ?term ?prefLab
ORDER BY ?term ?prefLab
""")
print(f "We have {len(qres)} results when processing narrower terms.")
for row in qres:
if 0 < int(row[2]) < 4:
term1 = synonym_cleaning(row[0])
term2 = synonym_cleaning(row[1])
h.setdefault(term1, {"narrower": []})["narrower"].append(term2)
with Path(output).open(mode="w") as outfile:
for k in h:
terms = {
term: None for term in list([
*h[k].get('narrower', []),
k
])
}
if len(terms.keys()) > 1:
outfile.write(f"{k} => {', '.join(terms.keys())}")
Obviously, the SPARQL query is different since specific terms are needed, as well as an indication of the distance of the specific term from the concept being processed. This information is obtained by adding a temporary variable, ?middle, which is counted to get the distance between the concept (?term) and the specific term (?prefLab).
In the second part of the function the result is processed. Firstly, only specific terms with a distance lower than 4 are retained. And secondly the result is formatted as required for Elasticsearch’s synonyms syntax. This creates rows in the format “concept => specific term 1, specific term 2, concept”.
This is also available on the companion GitHub repository of this article [19].
Integrating the configurations into Elasticsearch
To integrate the synonyms in Elasticsearch, elasticsearch_dsl [20] is used as a high-level wrapper around Elasticsearch, which makes it possible to create simple python classes to execute queries against Elasticsearch. And in those classes, it is possible to integrate the bilingual and hierarchical synonyms as custom analyzers. In the context of Elasticsearch, an analyzer [21] is the set of rules to apply when a text is process during the indexing or searching phases. It is possible to configure how tokens are produced, normalized or filtered. In our cases, synonyms are applied as a token filter.
Here is an example:
from elasticsearch_dsl import (
analyzer, Date, Document, Keyword, normalizer, Text
)
class Example(Document):
title = Text(
analyzer=text_analysis,
fields={
"bsyn": Text(analyzer=bsynonym),
"hsyn": Text(analyzer=hsynonym),
"raw": Keyword()
}
)
class Index:
name = "example"
The Example class inherits from the Document class defined in elasticsearch_dsl. Within this class, an attribute title is defined that is configured as a text field whose analysis will be done with text_analysis. Three fields are defined:
-
-
- bsyn for bilingual synonyms, where a text field is defined the bsynonym analyzer;
- hsyn for hierarchical synonyms, where a text field is defined using the analyzer hsynonym;
- raw which is defined as a Keyword field, thus a direct copy of the data.
-
Next, text_analysis also needs to be defined:
text_analysis = analyzer(
"text_analysis",
tokenizer="lowercase"
)
A tokenizer is used to convert the tokens to lowercase. As a reminder, when processing synonyms, the terms were also transformed in the same way when generating Elasticsearch configurations.
Finally, the analyzers for the bilingual and hierarchical synonyms are defined. Both require a token filter that uses the list of synonyms (respectively bsynonym and hsynonym). The code for the filters and analyzers is shown below:
bsynonym_filter = token_filter(
"bsynonym_custom_filter",
type="synonym",
synonyms=bsynonyms
)
bsynonym = analyzer(
"bsynonym_custom",
tokenizer="letter",
filter=[
"lowercase",
bsynonym_filter
]
)
hsynonym_filter = token_filter(
"hsynonym_custom_filter",
type="synonym",
synonyms=hsynonyms
)
hsynonym = analyzer(
"hsynonym_custom",
tokenizer="standard",
filter=[
"lowercase",
hsynonym_filter
]
)
When the Elasticsearch index is created and configured, queries are submitted as follows:
example = Example()
results = example.search().query(
Q("simple_query_string", query="query string")
)
It is also possible to weight the fields and subfields:
example = Example()
results = example.search().query(
Q(
"simple_query_string",
query="query string",
fields=[
'title.bsyn^4',
'title.hsyn^2',
'title.raw^2'
]
)
)
where the ^ is the prefix to the ponderation to use for this specific field or subfield.
First results and conclusion
The whole process can be summarized by the following diagram:
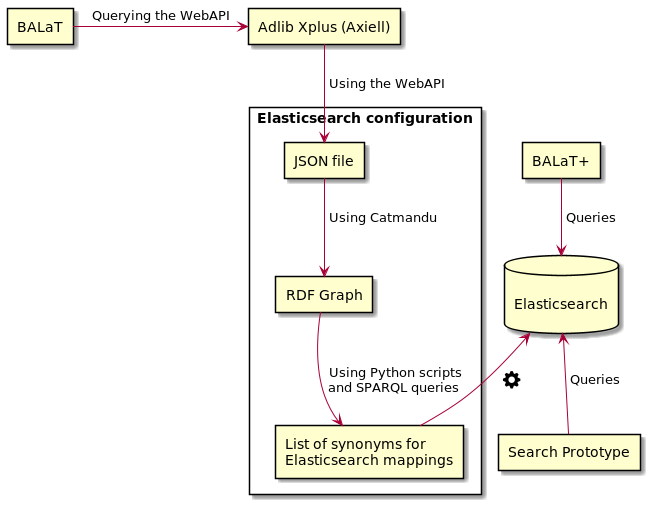
Figure 1. Summary of the workflow used to configure Elasticsearch based on our internal thesaurus.
Based on the 98,037 entries of the internal thesaurus, 12,312 bilingual synonyms and 9,132 hierarchical synonyms were produced to configure Elasticsearch. A prototype was developed to collect feedback from our internal users about the search experience. Here is a screenshot of that prototype:
Figure 2. Screenshot of the application developed to get feedback from our internal users.
That prototype is simply a web application querying the photo library indexed in Elasticsearch, which is configured with the generated list of synonyms. While this experiment is still in progress, some highlights can already be highlighted.
First, the multilanguage search functionality gives the expected results. If there are differences, those can be explained, among others, by the absence of the term in the thesaurus, and thus in the configuration of Elasticsearch. A possible solution would be to add these terms to the list and update the Elasticsearch configuration.
Second, the broaden search using the narrower terms as synonyms is powerful but needs some more configuration. For this exploratory work, the complete thesaurus was used, but a more precise approach needs to be set up to avoid terms with too many narrower terms. A solution would be to analyse queries submitted to BALaT, and build a list of terms that need to be expanded with narrower terms.
In conclusion, synonym generation for Elasticsearch configuration from an existing thesaurus does not result in a perfect configuration. These configurations must be adapted according to the collection to be indexed, but also according to the users’ feedback. Nevertheless, the use of the thesaurus makes it possible to exploit the work already done during the development of the thesaurus and thus to quickly have a first configuration specific to the collection to be processed.
Bibliography
[1] The Project. HESCIDA. [Internet] [accessed 25/4/2021]. Available from: http://hescida.kikirpa.be/
[2] KIK/IRPA. [Internet] [accessed 25/4/2021]. Available from: http://www.kikirpa.be/
[3] BALaT KIK-IRPA. [Internet] [accessed 25/4/2021]. Available from: http://balat.kikirpa.be
[4] Adlib. Axiell. [Internet] [accessed 25/4/2021]. Available from: https://www.axiell.com/solutions/product/adlib/
[5] Recherche open source : les créateurs d’Elasticsearch, de la Suite ELK et de Kibana | Elastic. [Internet] [accessed 25/4/2021]. Available from: https://www.elastic.co/fr/
[6] RDF 1.1 Concepts and Abstract Syntax. [Internet] [accessed 9/5/2021]. Available from: https://www.w3.org/TR/rdf11-concepts/
[7] SKOS Simple Knowledge Organization System Reference. [Internet] [accessed 9/5/2021]. Available from: https://www.w3.org/TR/skos-reference/
[8] SKOS Simple Knowledge Organization System Primer. [Internet] [accessed 6/5/2021]. Available from: https://www.w3.org/TR/skos-primer/
[9] SPARQL 1.1 Query Language. [Internet] [accessed 9/5/2021]. Available from: https://www.w3.org/TR/sparql11-query/
[10] Axiell WebAPI site – Welcome. [Internet] [accessed 25/4/2021]. Available from: https://api.adlibsoft.com/
[11] Axiell WebAPI site – search. [Internet] [accessed 25/4/2021]. Available from: https://api.adlibsoft.com/api/functions/search
[12] Blech M. 2021. martinblech/xmltodict. [Internet] [accessed 25/4/2021]. Available from: https://github.com/martinblech/xmltodict
[13] LibreCat/Catmandu data processing toolkit. [Internet] [accessed 25/4/2021]. Available from: https://librecat.org/
[14] Catmandu::Template – Catmandu modules for working with templates – metacpan.org. [Internet] [accessed 25/4/2021]. Available from: https://metacpan.org/pod/Catmandu::Template
[15] Template Toolkit Home Page. [Internet] [accessed 25/4/2021]. Available from: http://www.template-toolkit.org/index.html.
[16] Synonyms Guide | Elastic App Search Documentation [7.12] | Elastic. [Internet]. Available from: https://www.elastic.co/guide/en/app-search/current/synonyms-guide.html
[17] Token filter reference | Elasticsearch Guide [7.12] | Elastic. [Internet] [accessed 25/4/2021]. Available from: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html
[18] rdflib 5.0.0 — rdflib 5.0.0 documentation. [Internet]. Available from: https://rdflib.readthedocs.io/en/stable/
[19] KIKIRPA/thesaurus_elasticsearch_c4lj. 2021. Royal Institute for Cultural Heritage (KIK/IRPA). [Internet]. Available from: https://github.com/KIKIRPA/thesaurus_elasticsearch_c4lj
[20] Elasticsearch DSL — Elasticsearch DSL 7.2.0 documentation. [Internet] [accessed 25/4/2021]. Available from: https://elasticsearch-dsl.readthedocs.io/en/latest/
[21] analyzer | Elasticsearch Guide [7.12] | Elastic. [Internet] [accessed 25/4/2021]. Available from: https://www.elastic.co/guide/en/elasticsearch/reference/current/analyzer.html
About the Author
Emmanuel Di Pretoro holds bachelor’s degrees in library science and in computer science, as well as master’s degrees in Library and Information Science. He worked as a librarian and was involved in the training of future librarians where he taught various courses related to cataloguing, indexing, database modelling and on other subjects related to computer literacy and library science. He gained experience with web archiving when working on the Preserving Online Multiple Information: towards a Belgian strategy (PROMISE) project. Since 2020, he works as developer on the HESCIDA project.
Wim Fremout graduated as a MSc in Chemistry (Ghent University, 2002) and holds a PhD in Chemistry (Ghent University, 2014). Since 2003, he works as a conservation scientist in the Laboratories Department of the Royal Institute for Cultural Heritage (KIK-IPRA, Brussels, Belgium). He is specialised in the study and identification of pictorial layers and the characterisation of plastics and contemporary materials used in arts, applying a broad range of invasive and non-invasive techniques. In several international projects he is involved in research data management and digital access initiatives, and in the development of the DIGILAB platform in the European Research Infrastructure in Heritage Science (E-RIHS), which will provide access to digital resources in heritage science. Since 2019 he coordinates the HESCIDA project at KIK-IRPA that aims to create a data repository integrated in the institutional collection portal BALaT, which will become a local repository for DIGILAB.
Erik Buelinckx is scientific researcher at KIK-IRPA. He holds master’s degrees in information and Library Science, Documentation and Library Science and in Art History and Archaeology. He is responsible for documentary image databases and digitization projects in the Department of Documentation. He has experience in European projects (DCH-RP, Partage Plus, AthenaPlus, Preforma, Iperion, Fifties in Europe Kaleidoscope, Pagode – Europeana China) and is a member of DARIAH.BE, of the Europeana Members Council (2nd term), of the Time Machine consortium. He organises and participates in several interregional and international collaborations on multilingual thesauri in the field of CH. He is involved in the Belgian HESCIDA-project (HEritage SCIence Data Archive, 2019-2022) in the frame of E-RIHS.
Stephanie Buyle studied history at the University of Antwerp and Archival Science at the Free University of Brussels. Since 2016 she was appointed as scientific researcher at the Royal Institute for Cultural Heritage (KIK-IRPA). Her tasks mainly consisted of mapping data production and the problems associated with it. Since 2019, she works on the HESCIDA project as data manager. She is also involved within IPERION-CH and IPERION-HS projects (especially the topics related to research data management).
Véronique Van der Stede is an archaeologist (PhD in Art History and Archaeology, Université Libre de Bruxelles, 2003) and an assyriologist (Master degree in Assyriology, Université Libre de Bruxelles, 1996) whose research focuses on several aspects of the Mesopotamian civilization. She teaches Akkadian at the “Université Libre de Bruxelles”. Director of the ULB-team of the Euro-syrian Excavation of Tell Beydar (Syria), she took also part in archaeological missions in Thasos (Greece), Chagar Bazar (Syria) and Mleiha (UAE). Scientific researcher at the Art and History Museum (Brussels) between 2014 and 2019, she was involved in the coordination of the BarEO project (Brain-be, Belspo), an interdisciplinary research project aiming at ensuring the preservation of archaeological records produced during Belgian archaeological expeditions to the Near East and Iran. She is currently scientific researcher at KIK-IRPA in the frame of the HESCIDA-project (HEritage SCIence Data Archive, 2019-2022).

Subscribe to comments: For this article | For all articles
Leave a Reply