by Adrian Pohl
Background
The North Rhine-Westphalian Bibliography (NWBib) is a regional bibliography that records literature about the German state of North Rhine-Westphalia (NRW), its regions, places and people. As of now, NWBib comprises around 440,000 resources. NWBib collects monographs, articles, as well as other media like maps, DVDs, etc. The cataloging takes place in the North Rhine-Westphalian Library Service Centre (hbz) union catalog. The NWBib’s public interface for end users is the bibliography’s website at https://nwbib.de.
The hbz union catalogue contains more than 21 Million cooperatively maintained bibliographic titles including the German Union Catalogue of Serials (ZDB) [1] plus holding information from libraries in North Rhine-Westphalia and Rhineland-Palatinate. Aleph [2] is used as cataloging system, a migration to Alma [3] is underway. Cologne-based libraries and the Library Centre of Rhineland-Palatinate (LBZ) in cooperation with the hbz started an open data initiative in 2010 being the first to publish their catalog data under an open license. By now, the whole hbz union catalogue is published under CC0 Public Domain Dedication in different ways and formats: as Linked Open Usable Data (LOUD) via the user interface and API at https://lobid.org/resources and as full dumps both in Linked Open Data format and in MARC21/XML format with MAB2 [4] field numbering.
From the fall of 2017 to the beginning of 2020 we carried out a project to upgrade spatial subject indexing in NWBib from uncontrolled strings to controlled values from a spatial classification that is created from Wikidata [5]. This article gives an overview over what we have achieved and how.
NWBib as part of the hbz union catalogue
Before diving deeper into the actual project, a short explanation on how the technical and editorial work is divided between different people and institutions. NWBib editors are working at the University and State Libraries Düsseldorf and Münster while the whole underlying technical infrastructure (from cataloging to the web presence of NWBib) is managed by hbz which mostly means: the Open Infrastructure team. [6]
NWBib editors use the Aleph union catalog for cataloging, which means that NWBib records are also part of lobid-resources, a LOD-based web API for the union catalogue, at its core consisting of JSON-LD indexed in Elasticsearch [7]. Within lobid-resources, all NWBib titles – see for example https://lobid.org/resources/HT019035846.json – are marked like this:
{
"inCollection" : [ {
"id" : "http://lobid.org/resources/HT014176012#!",
"type" : [ "Collection" ],
"label" : "Nordrhein-Westfälische Bibliographie (NWBib)"
} ]
}
This information enables to easily query NWBib data via lobid-resources by attaching inCollection.id:"http://lobid.org/resources/HT014176012#!" to a lobid-resources query. This filter is utilized to offer the web interface for NWBib at https://nwbib.de which is, at its core, a web application built on the lobid-resources API.
Spatial subject indexing without controlled values
For years, subject indexing in NWBib has been done mainly by adding to a record the text strings of locations or regions a resource is about. It looked like this in the source data which is MARCXML with MAB2 field numbering (in a MARCXML representation, the information would be in field 084):
<datafield tag="700" ind1="n" ind2="1"> <subfield code="a">99</subfield> <subfield code="b">Duisburg</subfield> </datafield> <datafield tag="700" ind1="n" ind2="1"> <subfield code="a">99</subfield> <subfield code="b">Essen</subfield> </datafield>
The strings “Duisburg” and “Essen” refer to the cities in NRW with this name. Around three quarters of NWBib records (~300,000 records) contained one or more of these place name strings. In 2017, we had 8,800 distinct strings that denoted locations, mostly referring to administrative areas but also to monasteries, principalities, natural regions etc.
Enriching strings with geo coordinates
For years (2014-2019), we have been using Wikidata to enrich NWBib data with geo coordinates by matching those place strings to Wikidata items and pulling the geo coordinates from there. We had chosen a rather naive matching approach which resulted in poor or no matches for some resources. However, it was good enough to enable map-based filtering of results at nwbib.de.
Besides the sub-optimal matching there were other drawbacks with this approach. Of course the well-known problem occured which everybody encounters after some time when using strings instead of controlled values: You get lots of different strings for the same place because of different recording practices, omissions or typos. As said, in 2017 NWBib included around 8,800 distinct spatial strings which roughly referred to only 4,500 different places. Taking a look at a 2017 list containing all the distinct place name strings found in NWBib including an occurrence count, you find for example five strings referring to Wiesdorf, a part of Leverkusen:
– “Wiesdorf”
– “Wiesdorf <Niederrhein>”
– “Wiesdorf, Niederrhein”
– “Leverkusen-Wiesdorf”
– “Leverkusen- Wiesdorf (Niederrhein)”
Another drawback of the string-based approach was that we could not provide users with a hierarchical overview of all the places. To address these drawbacks, we started thinking about using controlled values from a spatial classification.
Doing it the right way using controlled values
You do not have to convince librarians that the best way to do spatial subject indexing is by using a classification rather than textual strings. Soon we all agreed to go this way, the main goals of the approach being:
- No multiple values referring to the same place
- A hierarchical view of all places by NRW’s administrative structure: government region, rural districts, urban and rural municipalities as well as city district.
Here is a mockup of the envisaged classification NWBib editors created in 2017:
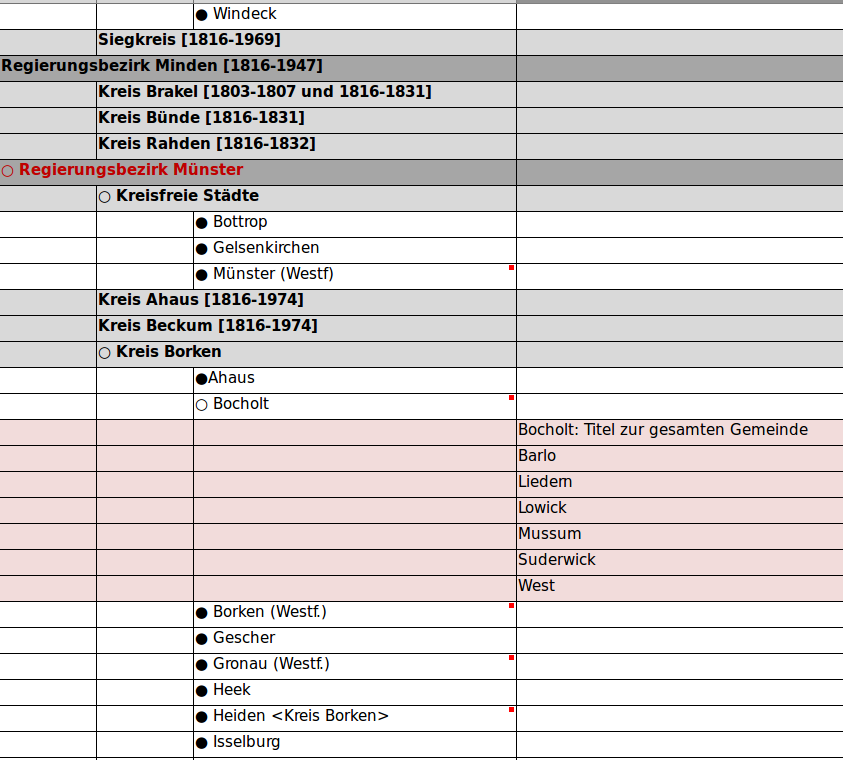
Figure 1. A mockup of a spatial classification created with a spreadsheet
Requirements for reuse of spatial authority data
Because of limited resources, NWBib editors would not be able to create a classification from scratch and maintain it all by themselves. Thus, we we were looking for existing authority data to be used for our purpose. We identified the following requirements towards the authority data to be reused for the spatial classification:
- Coverage: As many places as possible that were used in spatial tagging must be covered. This included some historical places.
- Hierarchy: Hierarchical relations between places must be included.
- Extensibility: NWBib editors must be able to add new places.
Furthermore, there should be one common entry for a place before and after incorporation into another geographic entity (e.g. parts of a town that had once been standalone administrative entities).
Why Wikidata rather than GND?
As the discussion happened in the German university library context, NWBib editors naturally tended to use the Integrated Authority File (GND) [8] which is the main authority file in German-speaking countries, being used and maintained by hundreds of institutions. As NWBib titles already had been indexed with GND subjects for some years (including spatial subjects), GND looked like the obvious candidate.
However, GND did not cover most of the requirements. Only few hierarchical relations then existed in the data, and with the changes during the move to Resource Description and Access (RDA) [9], more and more entries had been split into separate entries for an entity before and after its incorporation into a administrative superior entity, see e.g. these two GND entries for Wiesdorf: 4108828-1 (independent city between 1921 and 1930) & 4099576-8 (part of Leverkusen since 1930).
The next candidate we looked at was Wikidata as we had some experiences with it implementing the above mentioned geodata enrichment. Wikidata already had good coverage of place entries, geo coordinates and hierarchical information. As with the GND, Wikidata comes with a technical infrastructure for maintaining the authority data, the difference with Wikidata being that the editing community encompasses virtually anybody and not only catalogers. The implications are twofold:
- The bigger the community, the easier it is to keep the data up to date which means less work for NWBib editors.
- With anybody being able to edit the data, NWBib editors justifiably worried about unwanted changes and vandalism.
Furthermore, while the free infrastructure of Wikidata is great to start working on a project, it might lead to problems in the long run if you solely rely on Wikimedia to keep this infrastructure running. We guaranteed NWBib editors that we’d mitigate 2.) and would also mitigate the lack of control over the infrastructure by creating a solution that adds some kind of buffer between Wikidata and the NWBib classification so that we could identify and fix unwanted changes in Wikidata before deploying them in NWBib.
Implementation
As this project had to be carried out alongside other projects and in parallel to different maintenance duties by a team of three persons working part-time, the whole duration of the project covered more than two years. This fitted quite well with the constant need for review and feedback cycles which sometimes could take some time due to NWBib editors residing in two organizations different from the hbz.
Match strings
As said above, we already had been matching place strings with Wikidata items since 2014 in order to enrich NWBib data with geo coordinates. We had learned early on that using the Wikidata API is not sufficient for matching strings of places with Wikidata items. One reason being that different levels of administrative areas do have very similar names which led to systematic errors. So we created a custom Elasticsearch index from the query which was used in the matching process. As there was no single property for filtering all the places in North Rhine-Westphalia out of Wikidata and as we only wanted to get out those types of items we needed to match the strings with, we had to work with a SPARQL query that would be improved over several iterations, see the evolution of this SPARQL query in https://git.io/JOVS9 & https://git.io/JOVS7.
For an optimal matching result, we indexed the German name and alternative names (label, aliases) along with the geo coordinates (geo) for the enrichment. As place strings in NWBib data often contained the name of the superior administrative body for disambiguation, we also added this name to the index (locatedIn). Here is a full example of the information from Wikidata we loaded into Elasticsearch:
{
"spatial":{
"id":"http://www.wikidata.org/entity/Q897382",
"label":"Ehrenfeld",
"geo":{
"lat":50.9464,
"lon":6.91833
},
"type":[
"http://www.wikidata.org/entity/Q15632166"
]
},
"aliases":[
{
"language":"de",
"value":"Köln/Ehrenfeld"
},
{
"language":"de",
"value":"Köln-Ehrenfeld"
}
],
"locatedIn":{
"language":"de",
"value":"Köln-Ehrenfeld"
}
}
It then took quite some manual work in Wikidata (adding items and/or alternative names) as well as adjustment of field boosting in Elasticsearch (see https://git.io/J3LFi) to reach a successful matching for around 99% of all NWBib records, which covered approximately 92% of all place strings we had in the data. To get to a 100% coverage, NWBib editors adjusted catalog records and made more than 6000 manual edits to Wikidata adding aliases and type information or creating new entries.
Update NWBib data
Having reached the milestone of a 100% matching rate for all the place strings, we could move on to the next step: Updating NWBib data with information from Wikidata.
We did this by including the information in a spatial JSON object (the JSON key being mapped to the RDF property http://purl.org/dc/terms/spatial). To avoid being susceptible to vandalism or other unwanted Wikidata edits, we refrained from directly using Wikidata URIs. Instead, we minted custom URIs in the nwbib.de namespace and used the Simple Knowledge Organization System (SKOS) [10], a World Wide Web Consortium (W3C) recommendation for publishing classifications, thesauri or other controlled vocabularies as Linked Data using the Resource Description Framework (RDF) [11]. In a subsequent step, we’d create a SKOS classification from these SKOS concept URIs (see below). To link the SKOS concepts for those places to the corresponding Wikidata entities, the foaf:focus (http://xmlns.com/foaf/0.1/focus) property is used. [12] Besides the URI (id), the type information and geodata from Wikidata is also embedded in the focus object, see for example the spatial object from the record HT017710656:
{
"spatial":[
{
"focus":{
"id":"http://www.wikidata.org/entity/Q365",
"geo":{
"lat":50.942222222222,
"lon":6.9577777777778
},
"type":[
"http://www.wikidata.org/entity/Q22865",
"http://www.wikidata.org/entity/Q707813",
"http://www.wikidata.org/entity/Q200250",
"http://www.wikidata.org/entity/Q2202509",
"http://www.wikidata.org/entity/Q42744322",
"http://www.wikidata.org/entity/Q1549591"
]
},
"id":"https://nwbib.de/spatial#Q365",
"type":[
"Concept"
],
"label":"Köln",
"notation":"05315000",
"source":{
"id":"https://nwbib.de/spatial",
"label":"Raumsystematik der Nordrhein-Westfälischen Bibliographie"
}
}
]
}
With this setup, it becomes possible to query lobid for NWBib resources based on a place’s Q-identifier from Wikidata, for example:
spatial.focus.id:"http://www.wikidata.org/entity/Q365"
Having reached a state where controlled values for all the places are in NWBib/lobid data, we were still lacking a hierarchical overview of the places to be browsed by users. To enable this, we created a SKOS classification with broader/narrower relations.
Create & present SKOS classification
As NWBib editors did not want NWBib to directly rely on Wikidata’s infrastructure and data, we had early on decided to represent the classification in an intermediate SKOS file that we control. The NWBib web application would then rely on this file and not directly on Wikidata.
As an additional requirement, it became clear that we would not be able to maintain 100% of the classification in Wikidata for several reasons: Some parts of the classification were quite NWBib-specific and it wasn’t feasible to include them in Wikidata. Also, we could not claim authority over the preferred names used in Wikidata so that we had to think about a solution when a label in Wikidata would differ from the label we wanted to be used in NWBib. Here is the setup we came up with:
- A SKOS turtle file covering the core spatial NWBib classification with (currently around 40) concepts not covered in Wikidata or where we need to use another label than Wikidata: nwbib-spatial-conf.ttl
- The complete classification as a SKOS file created from 1.) and Wikidata: nwbib-spatial.ttl
The HTML classification that is rendered from the classisication SKOS file can be viewed and browsed at https://nwbib.de/spatial (where you can also download the SKOS version under https://nwbib.de/spatial.ttl). Here is a screenshot showing a part of the HTML classification:

Figure 2. A part of the NWBib spatial classification showing different hierarchical levels
You can directly link to each element in the HTML classification by using the concept’s hash URI which is based on its Wikidata ID – e.g. https://nwbib.de/spatial#Q365. Displayed in parenthesis behind each classification entry is the number of bibliographic resources in NWBib that refer to this place. This number is linked to a result view listing these resources.
Update Wikidata with links to NWBib
With the concept URIs resolving to their classification entry, the next step could be implemented: adding links from Wikidata to NWBib. Prerequisite is a Wikidata property that enables adding those links to Wikidata items. We proposed such a property in the beginning of June 2019, see https://www.wikidata.org/wiki/Wikidata:Property_proposal/NWBib_ID. After getting a few affirmative votes, the Wikidata property NWBib ID (P6814) was created quickly one or two days later. We then batch loaded the NWBib IDs with QuickStatements [13], see https://github.com/hbz/nwbib/issues/469 for details. After this step, we could get all relevant Wikidata entries by querying for all items that have a P6814 statement.
Until then, we were getting information about hierarchy (superordinate administrative entity) from P131 (located in the administrative territorial entity statements. As for some places multiple superordinate administrative entities were listed, we had problems to identify the one we would use for creating our classification’s hierarchy. That’s where the Wikidata property P4900 (broader concept) came into play. We used this property to batch load “broader” links to other Wikidata entries with a qualifier to the P6814 (NWBib ID) statements, see the corresponding issue for implementation details. The result, e.g. for Cologne (Q365), looks like this in Wikidata:
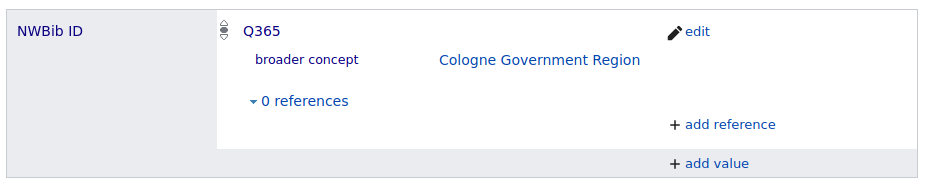
Figure 3. NWBib ID entry in Wikidata example with P4900 (broader concept) qualifier
The Wikidata entries which are used in NWBib can thus be identified by usage of the NWBib ID property P6814, e.g. by using this SPARQL query on the Wikidata query endpoint at https://query.wikidata.org:
# Get all places used in the NWBib spatial classification
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P6814 ?nwbibId.
SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
}
}
Support Aleph cataloging with concept URIs
By now, we had also replaced all spatial strings in the underlying Aleph system with SKOS concept URIs. To enable subsequent cataloging with those concept URIs, we somehow had to establish a process for cataloguers to easily add the controlled values into the bibliographic records. For this, we added a hidden copy button behind every classification entry to get the needed Aleph format with one click. One has to hover over the space behind a classification entry to make the button and an explaining tooltip visible, then click the button, select the correct field in Aleph and paste the entry there.
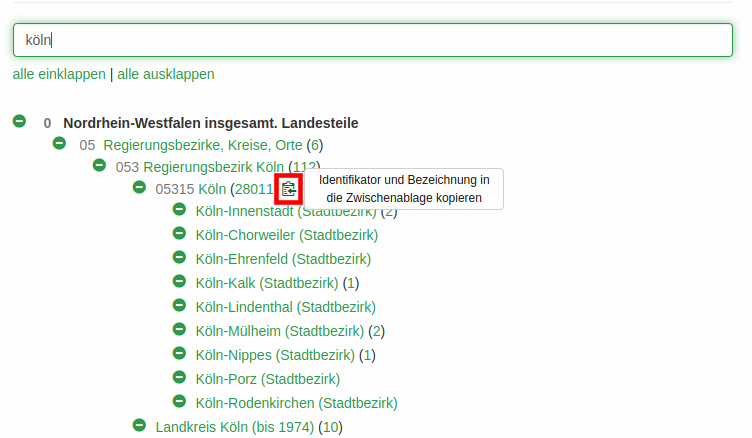
Figure 4. Hidden button with tooltip in the classification page for copying snippets into Aleph
For example, a click on the button as shown in the screenshot adds the following string to the clipboard which can directly be pasted into the right field in the Aleph cataloging client:
Köln$$0https://nwbib.de/spatial#Q365
The resulting catalog data looks like this (in the MARC21/XML export format that uses MAB2 field numbering):
<datafield tag="700" ind1="n" ind2="1"> <subfield code="a">Köln</subfield> <subfield code="0">https://nwbib.de/spatial#Q365</subfield> </datafield>
Monitoring and fixing synchronization issues
Setting up the new infrastructure for the spatial classification, we noticed two problems that might and did occur with regard to the synchronization between NWBib data and Wikidata:
- Spatial concepts used in NWBib and derived from Wikidata might not have a P6814 (NWBib ID) statement in Wikidata – either because they were newly added to NWBib or someone removed the statement from Wikidata.
- Wikidata entries with a P6814 (NWBib ID) statement miss an equivalent concept in NWBib.
To be notified about a potential asynchronicity, we set up a monitoring process that sends out an email whenever one of these cases occurs. Usually, a reported error can easily be resolved by adding/removing a P6814 (NWBib ID) from Wikidata.
Establish editorial process for maintaining the classification
Having set up this whole infrastructure we had to think about an editorial process for maintaining the classification. As noted, an up-to-date SKOS classification is created from:
- the manually maintained SKOS config file nwbib-spatial-conf.ttl which includes a) top-level concepts, b) hierarchical relationships that can’t be recorded in Wikidata with P4900 (broader concept) and c) concepts whose desired display label differs from the label in Wikidata,
- all Wikidata items with P6814 NWBib ID statements including – if existent – the qualifier P4900 (broader concept).
In general, statements from the config file (1.) overwrite those from Wikidata (2.). [14]
Having this technical update process in place, with a few iterations we established the following editorial process:
- NWBib editor decides to change an entry or to include a new place by adding an NWBib ID (P6814) statement.
- NWBib editor triggers a new build of the classification in the test system by clicking a button “Update from Wikidata” and checks whether the desired change is achieved.
- Editor can now already use the test classification for copying the entry into Aleph as described above.
- If everything is fine on test, editor notifies the lobid team via email and requests a rebuild of the classification in production.
- lobid team updates the classification in the production system and notifies editors about possible undesired changes coming in from Wikidata.
Assessment
Summarizing the result of the project, the NWBib’s spatial classification – which can be browsed at https://nwbib.de/spatial – is now comprising controlled entries for around 4,500 places or geographic areas. The underlying structured data is stored as an RDF/Turtle file using the Simple Knowledge Organization System (SKOS): https://nwbib.de/spatial.ttl. This SKOS file in turn is for the utmost part derived from Wikidata. An editorial process for updating the classification has been set up.
Both the NWBib editors who are responsible for cataloging and the development team are very pleased with the results of the project and the achieved possibilities of maintaining and using a larger spatial classification. Here are some of the benefits:
- Common sources of errors like typos or missing parentheses with qualifiers are now impossible.
- With regard to the cataloging workflow, we got the feedback that the new method of browsing and filtering the classification and clicking the hidden button to copy the field entry into Aleph would be much better and easier than the previous method of adding a textual stirng by hand. Especially, new staff or staff that is not so familiar with NWBib is very happy about the change.
- The previous process of deriving geo coordinates from Wikidata by matching strings resulted in some errors. Directly using Wikidata-derived controlled values for spatial indexing eliminates this source of error.
- The editorial process along with the monitoring tools results in a small and easily manageable maintenance burden for the team maintaining the technical infrastructure.
- NWBib users benefit from the hierarchical, browsable and clickable overview of the whole spatial classification.
- Finally, the connections to Wikidata enable us to utilize even more information from Wikidata in the future, e.g. by setting up a profile page for each place in the classification with a small description, a picture and the coat of arms.
Acknowledgements
Thanks to the NWBib editors Holger Flachmann, Stefanie von Gumpert-Hohmann, Elisabeth Lakomy, Irmgard Niemann, Ute Pflughaupt, Doris Ritter-Wiegand, and Cordula Tetzlaff for being open to this Wikidata-based approach and for the sincere, constructive and friendly communication which was crucial for the success of this project. Thanks to the Open Infrastructure team, especially Fabian Steeg and Pascal Christoph, for the good team work in general and especially in this project. Finally, thanks to Magnus Sälgö, Péter Király and Osma Suominen for showing their interest in the project during SWIB20 (see the Mattermost thread archived by me) which led me to document the project in this Code4Lib article.
Further resources
- Slides from WikidataCon 2019: https://slides.lobid.org/nwbib-wikidatacon/
- GitHub project Wiki (German): https://github.com/hbz/nwbib/wiki
- Project issues (mostly in German): https://github.com/hbz/nwbib/issues?q=is%3Aissue+project%3Ahbz%2F3
Notes
[1] For information on ZDB and how to query it, see Pohl, Adrian (2018): Accessing ZDB via lobid-resources. URL: https://web.archive.org/web/20210125181012/https://blog.lobid.org/2018/09/04/zdb.html
[2] https://librarytechnology.org/product/aleph/
[3] https://librarytechnology.org/product/alma
[4] “Maschinelles Austauschformat für Bibliotheken”, a data format similar to MARC21 used as exchange format in the German-speaking library world until 2013. See https://de.wikipedia.org/wiki/Maschinelles_Austauschformat_f%C3%BCr_Bibliotheken for more background.
[7] For details, see the blog posts about lobid-resources at https://blog.lobid.org/tags/lobid-resources
[9] http://www.rda-rsc.org/content/about-rda
[10] https://www.w3.org/2004/02/skos/
[12] For a detailled account on foaf:focus and related properties see Johnston, Pete (2011): Things & their conceptualisations: SKOS, foaf:focus & modelling choices. URL: https://efoundations.typepad.com/efoundations/2011/09/things-their-conceptualisations-skos-foaffocus-modelling-choices.html
[13] https://www.wikidata.org/wiki/Help:QuickStatements
[14] As a sidenote: In the beginning, we hoped to directly extract SKOS data from Wikidata using a SPARQL CONSTRUCT query. Unfortunately, Wikidata does not support CONSTRUCT queries for such a large amount of data, see the respective issue.
About the author
Adrian Pohl (pohl@hbz-nrw.de) has been working at the North Rhine-Westphalian Library Service Centre (hbz) in Cologne, Germany, since 2008. He is leading the Open Infrastructure team whose work focuses on open standards, tools and processes for the publication of structured data on the web.

Subscribe to comments: For this article | For all articles
Leave a Reply