by Shelly R. McDavid, Eric McDavid, and Neil E. Das
Introduction
In the past, renewal of journal and journal package subscriptions at Lovejoy Library at Southern Illinois University Edwardsville (SIUE) had been piecemeal, with each decision referencing metrics specific to that purchase alone in isolation from others. The two principal factors considered were percentage price increase over the previous year and cost per use. If the percentage price increase could be kept below roughly 4-5% and cost per use per journal article kept below the rate of ordering articles through delivery services such as ILLiad and Get It Now, then the journal or journal package was renewed. Regarding the process, the renewal price and statistical analysis were provided by the Electronic Resources Librarian to individual subject librarians who made the final decisions on renewals. In this system, cross-disciplinary analysis of journal subscriptions occurred only to ensure that a resource was not being paid for more than once. There was no more granular analysis, especially analysis based on the subject content of journals. Our project originated in the spring of 2019, with the goal of generating subject heading data for the journals we subscribed to at Lovejoy Library at SIUE. The desired outcome of the project was detailed analysis and education of library liaisons and campus faculty about the journal’s subscriptions in their disciplines, including usage data, cost per use, and potential alternate Open Educational Resources (OER) or Open Access (OA) resources or less costly comparable product replacements. Principal author Shelly McDavid had seen a similar model in action in her previous library and wanted to apply it to collection development and annual portfolio reviews of collections by LIS for campus disciplines at SIUE as well.
Background
At LIS at SIUE, we had not been in the practice of identifying subject headings of electronic resources to which we subscribed, nor did we perform any type of discipline specific journal usage analysis. These were the goals of this project, with an eye to such analysis serving as the basis of annual portfolio reviews to present to campus faculty and administrators. In fall 2020, the LIS Lovejoy Library Collections Analysis & Strategy Committee was formed to work toward these goals.
Subject Scraper Methodology
The principal problem addressed in this project was to collect specific metadata for a group of ISSN numbers in an efficient, systematic way across different library catalogs. The solution was to create a Python (v3.7.1) script which makes an HTTPS request to the catalog search engine for the ISSN number and parses the HTML search results to gather the relevant metadata for that ISSN. The script was designed to be used from the command prompt and allows for a single ISSN search or a batch search by passing in a CSV file. One of the required positional arguments is a catalog name: worldcat, carli_i-share, or mobius.
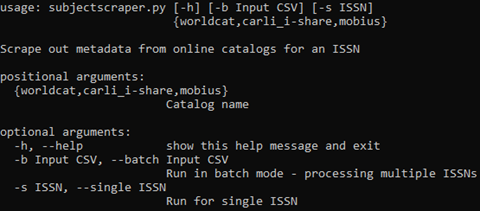
Figure 1. Output from running “python subjectscraper.py -h”.
Catalog Parameters
One feature of the script was to allow for flexibility in choosing the catalog for which the search is to be conducted, as only one catalog can be searched at a time. Since each library web catalog is formatted in different ways with different HTML structures and CSS styles, a Python dictionary data structure was created so the script could operate in a systematic way regardless which catalog was chosen. This dictionary was defined for each catalog and included the following parameters:
-
-
- base_url – The beginning part of the catalog search URL, starting from https:// and ending before the first / e.g., “https://www.worldcat.org”.
- search_url – This is the rest of the catalog search URL without the base_url, this is parameterized with a “{0}” for the ISSN to search for e.g., “/search?qt=worldcat_org_all&q={0}”.
- search_title – CSS selector for the parent HTML element that contains the ISSN title on the search results page.
- bib_record – CSS selector for the HTML element that contains the record metadata on the catalog item’s page.
- bib_title – CSS selector for parent HTML anchor element containing the item title on the catalog item’s page.
- bib_subjects – the HTML table element where the text begins with “Topics” or “Subject” in the catalog item’s page in context of bib_record.
-
The script as written supported WorldCat, MOBIUS Library Catalog, and CARLI’s VUFind Library Catalog, but more catalogs could also be searched by defining the above parameters for a specific library catalog. The parameters do require extensive knowledge of how HTML elements and CSS styles work and function.
Process
Regardless of whether the script is running in single or batch mode, the process of searching for an ISSN is the same and involves two URL requests for a single ISSN:
- Search the catalog for the ISSN and get the URL for the catalog item.
- If the catalog item URL is valid, search the catalog item’s page for relevant metadata.
- Output or write to disk the metadata and search criteria.
The script does not work for every ISSN and will give informative errors for any failure involved in the above steps.
One complication when sending URL requests to web servers is that there must be a time delay between requests, otherwise the server will assume that it is being spammed and deny the request. So, every URL request is preceded by a time delay of half a second.
Output
If the script is running in single ISSN mode, the output is sent to the screen. This output includes the ISSN that was searched for, the catalog item URL, the item title, and the list of subjects that are in the record for the item.

Figure 2. Output from running subjectscraper in single mode.
In batch ISSN mode, a CSV output file is created in the current working directory with the chosen catalog name appended to the file name i.e., “batch_output_worldcat.csv”. This output file will contain the same output from above but for all ISSNs listed in the input file. Some ISSNs will produce errors when searching, and for those the URL, title, or subjects may be blank. The script will also show a progress bar when in batch mode to inform the user about the approximate time to completion.
External Libraries
The script uses the following external Python libraries:
-
-
- urllib.request.urlopen – this is how the URL request is made.
- bs4.BeautifulSoup – this is an HTML parser that operates on the results from the URL request.
- tqdm.tqdm – this is the progress bar when running in batch mode.
-
Source Code – subjectscraper.py
from urllib.request import urlopen
from bs4 import BeautifulSoup
from tqdm import tqdm
import re, argparse, sys, csv, time
catalogs = {
#'catalog name' : {
# 'base_url' : beginning part of URL from 'http://' to before first '/',
# 'search_url' : URL for online catalog search without base URL including '/';
# make sure that '{0}' is in the proper place for the query of ISSN,
# 'search_title' : CSS selector for parent element of anchor
# containing the journal title on search results in HTML,
# 'bib_record' : CSS selector for record metadata on catalog item's HTML page,
# 'bib_title' : CSS selector for parent element of anchor containing the journal title,
# 'bib_subjects' : HTML selector for specific table element where text begins with
# "Topics", "Subject" in catalog item's HTML page in context of bib_record
'worldcat' : {
'base_url' : "https://www.worldcat.org",
'search_url' : "/search?qt=worldcat_org_all&q={0}",
'search_title' : ".result.details .name",
'bib_record' : "div#bibdata",
'bib_title' : "div#bibdata h1.title",
'bib_subjects' : "th"
},
'carli_i-share' : {
'base_url' : "https://vufind.carli.illinois.edu",
'search_url' : "/all/vf-sie/Search/Home?lookfor={0}&type=isn&start_over=0&submit=Find&search=new",
'search_title' : ".result .resultitem",
'bib_record' : ".record table.citation",
'bib_title' : ".record h1",
'bib_subjects' : "th"
},
'mobius' : {
'base_url' : 'https://searchmobius.org',
'search_url' : "/iii/encore/search/C__S{0}%20__Orightresult__U?lang=eng&suite=cobalt",
'search_title' : ".dpBibTitle .title",
'bib_record' : "table#bibInfoDetails",
'bib_title' : "div#bibTitle",
'bib_subjects' : "td"
}
}
# Obtain the right parameters for specific catalog systems
# Input: catalog name: 'worldcat', 'carli i-share', 'mobius'
# Output: dictionary of catalog parameters
def get_catalog_params(catalog_key):
try:
return catalogs[catalog_key]
except:
print('Error - unknown catalog %s' % catalog_key)
# Search catalog for item by ISSN
# Input: ISSN, catalog parameters
# Output: full URL for catalog item
def search_catalog (issn, p = catalogs['carli_i-share']):
title_url = None
# catalog url for searching by issn
url = p['base_url'] + p['search_url'].format(issn)
u = urlopen (url)
try:
html = u.read().decode('utf-8')
finally:
u.close()
try:
soup = BeautifulSoup (html, features="html.parser")
title = soup.select(p['search_title'])[0]
title_url = title.find("a")['href']
except:
print('Error - unable to search catalog by ISSN')
return title_url
return p['base_url'] + title_url
# Scrape catalog item URL for metadata
# Input: full URL, catalog parameters
# Output: dictionary of catalog item metadata,
# including title and subjects
def scrape_catalog_item(url, p = catalogs['carli_i-share']):
result = {'title':None, 'subjects':None}
u = urlopen (url)
try:
html = u.read().decode('utf-8')
finally:
u.close()
try:
soup = BeautifulSoup (html, features="html.parser")
# title
try:
title = soup.select_one(p['bib_title']).contents[0].strip()
# save title to result dictionary
result["title"] = title
except:
print('Error - unable to scrape title from url')
# subjects
try:
record = soup.select_one(p['bib_record'])
subject = record.find_all(p['bib_subjects'], string=re.compile("(Subjects*|Topics*)"))[0]
subject_header_row = subject.parent
subject_anchors = subject_header_row.find_all("a")
subjects = []
for anchor in subject_anchors:
subjects.append(anchor.string.strip())
# save subjects to result dictionary
result["subjects"] = subjects
except:
print('Error - unable to scrape subjects from url')
except:
print('Error - unable to scrape url')
return result
# Search for catalog item and process metadata from item's HTML page
# Input: ISSN, catalog paramters
# Output: dictionary of values: issn, catalog url, title, subjects
def get_issn_data(issn, p = catalogs['carli_i-share']):
results = {'issn':issn, 'url':None, 'title':None, 'subjects':None}
time.sleep(time_delay)
url = search_catalog(issn, params)
results['url'] = url
if url: # only parse metadata for valid URL
time.sleep(time_delay)
item_data = scrape_catalog_item(url, params)
results['title'] = item_data['title']
if item_data['subjects'] is not None:
results['subjects'] = ','.join(item_data['subjects']).replace(', -', ' - ')
return results
# main loop to parse all journals
time_delay = 0.5 # time delay in seconds to prevent Denial of Service (DoS)
try:
# setup arguments for command line
args = sys.argv[1:]
parser = argparse.ArgumentParser(description='Scrape out metadata from online catalogs for an ISSN')
parser.add_argument('catalog', type=str, choices=('worldcat', 'carli_i-share', 'mobius'), help='Catalog name')
parser.add_argument('-b', '--batch', nargs=1, metavar=('Input CSV'), help='Run in batch mode - processing multiple ISSNs')
parser.add_argument('-s', '--single', nargs=1, metavar=('ISSN'), help='Run for single ISSN')
args = parser.parse_args()
params = get_catalog_params(args.catalog) # catalog parameters
# single ISSN
if args.single is not None:
issn = args.single[0]
r = get_issn_data(issn, params)
print('ISSN: {0}\r\nURL: {1}\r\nTitle: {2}\r\nSubjects: {3}'.format(r['issn'], r['url'], r['title'], r['subjects']))
# multiple ISSNs
elif args.batch is not None:
input_filename = args.batch[0]
output_filename = 'batch_output_{0}.csv'.format(args.catalog) # put name of catalog at end of output file
with open(input_filename, mode='r') as csv_input, open(output_filename, mode='w', newline='', encoding='utf-8') as csv_output:
read_in = csv.reader(csv_input, delimiter=',')
write_out = csv.writer(csv_output, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
write_out.writerow(['ISSN', 'URL', 'Title', 'Subjects']) # write out headers to output file
total_rows = sum(1 for row in read_in) # read all rows to get total
csv_input.seek(0) # move back to beginning of file
read_in = csv.reader(csv_input, delimiter=',') # reload csv reader object
for row in tqdm(read_in, total=total_rows): # tqdm is progress bar
# each row is an ISSN
issn = row[0]
r = get_issn_data(issn, params)
write_out.writerow([r['issn'], r['url'], r['title'], r['subjects']])
except Exception as e:
print(e)
Limitations
While there are many limitations to this project, one glaring limitation is that typically subject headings are generated and assigned by a human, and this equates to the possibility of human error. We were hopeful to norm our subject heading data by generating and comparing data from three sources. However, the VuFind Catalog has been retired requiring us to update the subject scraper script for the new CARLI I-Share Catalog, something we have not done at this time.
Another factor impacting the task of scraping subject headings from library catalogs is that many servers, like the one for OCLC’s Worldcat, can only be pinged 999 times in a 24-hour period from the same IP address. This is a common practice for servers. Therefore, when needing to scrape over a few thousand subject headings this work must be parsed out over a series of days.
Future Work
At the time we completed this project, LIS at SIUE did not have the structure in place to apply the goals of this project into real world action. However, in the summer of 2020, a new dean took over leadership at LIS and established the Collection Analysis and Strategy Committee that fall. A stated yearly goal of this committee is to create “a data driven approach to collection development with analysis of annual usage data, cost per use data, and, when applicable, journal impact factor data.” And additionally, “the library presents its objective view of potential cuts and engages the academic department faculty in a conversation about departmental needs, related to curriculum and research agendas.”[1]
However, our future work of analyzing subject headings in journal collections will not rely on the custom developed Python Web Scraper code that we describe in this article. OCLC has since developed an experimental API (Application Programming Interface) called FAST API. “FAST is an acronym for Faceted Application of Subject Terminologies for subject headings data” (Fast API [updated 2021]).[2] Now we will leverage this API to generate subject headings to aid in our electronic journal usage analysis by subject for collection development and to create annual portfolio reviews for campus departments.
One specific area of possible future work is the analysis of our large journal packages from major publishers. This aspirational goal is inspired by the ideas of Nabe and Fowler in “Leaving the ‘Big Deal’… Five Years Later” (Nabe and Fowler 2015).[3] Understanding the subject compositions of these massive databases would be a key tool in assessing whether we might replace these costly subscriptions with more targeted options. This would certainly aid in achieving the goals of maximizing ROI on journal expenditures and creating departmental portfolio reviews
Conclusions
This project was valuable in two major ways, both of which set the stage for the processes that will allow LIS at SIUE to get the most out of our journal and database subscriptions going forward. First, the idea to analyze journal collections by subject headings in addition to cost per use, itself, anticipated the work that has been taken up by the Collection Analysis and Strategy Committee. This will allow for far more granular analysis of our renewals and is a foundational concept in the creation of discipline-based portfolio reviews for university departments. Second, examining the architecture of the three library catalogs, writing the Python script, and testing and correcting errors provided an understanding of the quality and extent of the subject heading metadata of academic journals. This knowledge will be invaluable as we now employ and assess the usefulness of the API from OCLC in accomplishing the same tasks as our Python script. However, we are hopeful that the script and processes described in this article may provide a low-cost pathway for others to analyze their own journal collections, if only as an experiment or as a first step in the journey toward more robust journal usage and subject analysis.
Code Availability – GitHub https://github.com/smcdavi/subjectscraper.py/blob/master/subjectscraper.py
References
[1] McDavid, S. [2020]. Library and Information Services Collection Committee Proposal. Edwardsville (IL): Southern Illinois University Edwardsville; [Cited 2021 July 31].
[2] Fast API [Internet]. [Updated 2021]. Dublin (OH): OCLC. [cited 2021 Jul 15]. Available from https://platform.worldcat.org/api-explorer/apis/fastapi
[3] Nabe J, Fowler, D. [2015]. Leaving the “Big Deal” … Five Years Later. The Serials Librarian [Internet]. [cited 2021 Jul 15];69(1): 20-28. Available from https://www.tandfonline.com/doi/full/10.1080/0361526X.2015.1048037
About the Authors
Shelly R. McDavid has been STEM Librarian (since February 2019) and Area Coordinator for Access & Library Spaces (since January 2021) at Southern Illinois University Edwardsville in Edwardsville, Illinois. Her research interests include evidence-based and data-driven decision making for assessment of library collections, data, instruction, operations, resource sharing, services, and spaces in libraries, institutional repositories, scholarly communications, and open educational resources.
Author email: smcdavi@siue.edu
Eric McDavid is a Programmer/Analyst who works with the Center for Health Policy at the University of Missouri.
Author email: mcdavide@missouri.edu
Neil E. Das has been Electronic Resources Librarian at Southern Illinois University Edwardsville in Edwardsville, Illinois since January 2019. His research interests include student and faculty research behavior in the use of library discovery layers, library provided databases, and Google Scholar.
Author email: nedas@siue.edu

Subscribe to comments: For this article | For all articles
Leave a Reply