By Leanne Olson and Veronica Berry
Introduction
This paper grew out of a need we experienced at the University of Western Ontario. When we began digitizing material from our special collections and archives, we found that there were several popular software options for performing optical character recognition (OCR) recommended by our colleagues, but evaluation of their effectiveness for historical documents was anecdotal. We wanted to make an informed choice and understand which program would best fit our needs.
We started with a search for evaluations of OCR software. Information about OCR in the literature tended towards quick blog posts (e.g. Gringel 2020; Han 2019) or in-depth articles designed for digital scholarship projects, often with a heavy dose of computer science (e.g. Springmann et al. 2016; Clausner et al. 2020). We realized that relying on the results from previously published evaluations wouldn’t be helpful, as software continues to evolve: a study from five years ago may no longer be applicable. Could we recreate a test used elsewhere? Many of the evaluative tests of OCR processes for digital humanities projects are time-consuming (for example, creating a ground truth document) and require significant expertise.
We wanted to develop a reasonably simple method to evaluate software in a way that made sense for our digitization projects. We wanted to be able to reproduce this method when we had a new type of material to digitize, and to re-run the test a few years in the future to determine if the “best” software had changed.
We considered our digitization project needs. Our Archives and Special Collections Team is interested in creating searchable PDFs from scanned, typed documents such as journals, newspapers, and books. These PDFs are accessed by our users through our digital repositories such as Omeka, Open Journal Systems, and our institutional repository that runs on Digital Commons. Some of our items are scanned in-house, and some scanning is outsourced. We are also currently scanning handwritten material, but that is outside the scope of this paper — our archivists are piloting a user transcription project for handwritten documents such as diaries. For this project, we are not looking at the METS/ALTO XML standards for digitization projects, though we are hoping to explore this in the future.
For this study, we determined that we wanted to know how OCR programs facilitate searching and accessibility of documents in a repository or database, replicating how our users would interact with the documents online. We examined how well these programs recognize individual words and how well they handle page segmentation.
We tested three (and a half) popular OCR programs: ABBYY Finereader (and its Hot Folders option), Adobe Acrobat Pro, and Tesseract. We also looked briefly at two options from Google.
We chose documents from recent digitization projects in our archives and special collections, each with different potential problems that could affect the accuracy of the OCR. We tested each program on the same section of each of three documents.
Background
Optical Character Recognition and Historical Documents
Optical Character Recognition software is not perfect, particularly when dealing with historical text (Carrasco 2014). Problems with OCR in widely-used academic resources are well documented. For example, Thompson’s study found OCR errors rates of up to 30% in digitized historical issues of the British Medical Journal (Thompson, 2016, 1). Kichuk (2015) describes problems with poor OCR in major e-book providers such as Project Gutenberg, the Internet Archive, and HathiTrust. Carracso (2014) provides a variety of reasons for why OCR of historical documents is more difficult: the quality of the original document might be poor, with stains or smudging, older fonts may be less easily recognized by software, the documents may have complex layouts, and older vocabulary may be spelled differently and less easily recognized. Han (2019) states that “in most cases if you need a complete, accurate transcription you’ll have to do additional review and correction.”
Low quality OCR can hurt the effectiveness of searching over documents. If words are misrecognized or not recognized at all, a keyword search in a database or repository will not return the document, leaving out relevant material for researchers (Thompson 2015). From the library or archive’s perspective, if the documents aren’t findable, the work, time, and money we’ve put into digitizing them is wasted.
Pletschacher argues that knowing the accuracy of OCR helps us “manage researcher expectations and understand what we as a library are offering” (2015, 39). For example, Thompson notes that “More sophisticated search methods, e.g., those based on text mining…techniques, can be even more adversely affected” (Thompson 2015, 1). If we know the approximate accuracy of the OCR on a digitization project, we can advise a researcher whether the resource is searchable, whether it’s accurate enough for text mining, and whether additional cleanup work will be needed. Evaluating the accuracy of OCR for a project in advance also helps to estimate the time needed to correct errors after OCR (Clausner 2020).
Understanding the accuracy of the content we’re providing means that we as librarians and archivists can decide whether the OCR output from software is good enough for a specific project, or whether we’ll need to set aside staff time after running OCR to continue cleanup. For example, at the University of Western Ontario, most of our projects only require searchability, but on one project we are partnering with our Department of Philosophy to perform accurate cleanup of individual characters in the journal Locke Studies to prepare it for a text analysis project.
Methods for testing OCR accuracy
As part of planning this project, we looked at the literature for methods used to test OCR. We discuss how we adapted these methods below in our “Testing method” section.
To evaluate OCR software, we have access to “[t]wo sources of information: the output of the OCR engine, and the ground truth content of the image” (Carrasco, 2014, 182). The output of the OCR engine refers to the accuracy of the individual characters: how well the OCR software recognizes each character. The ground truth content refers to where the characters are located on the page.
When testing with characters, Alkhateeb (2017) recommends looking at “The number of inserted, deleted, replaced (substituted) symbols in the recognized text” (769). In the literature, there are a variety of similar formulas used for testing the error rate of individual words.

where WER is the word error rate, iw is the number of words inserted, sw the number of words substituted, dw the number of words deleted, and nw the total number of words in the document. Essentially, each of these authors is recommending a similar method for calculating character/word accuracy. Generally, when testing OCR software for specific projects, testing characters is more onerous and less useful (Pletschacher, 2015) than testing words, and “word error rates are usually higher than character error rates” (Carrasco 2014, 180).
Testing the layout of the document
While OCR software might excel at recognizing individual characters, for some projects this is not enough. Pletschacher explains that “[i]n addition to textual results, page reading systems are also expected to recognise layout and structure of a scanned document page. This comprises segmentation (location and shape of distinct regions on the page), classification (type of the regions defined by the segmentation; e.g. text, table, image, etc.), and reading order (sequence/grouping of text regions in which they are intended to be read)” (Pletschacher, 2015, 39).
With a simple text document this is straightforward. However, OCR software can have trouble recognizing different document layouts, such as newspaper columns, headlines, photo captions, and tables. Sentences and paragraphs can blend together, with the software reading across the entire page from left to right without recognizing breaks between columns, articles, or tables. Page contents can be scrambled, with sentences running together, paragraphs in the wrong order, or tables reduced to gibberish.
A thorough way to test page layout recognition is to manually create a ground truth. This is a transcription of the original document, replicating the exact location of each character (Pletschacher, 2015; Carrasco 2014). Carrasco (2014) developed a tool to compare a ground truth transcription to an OCR output, Pletschacher (2015) developed ground truths for a project analyzing historical newspapers, and Springmann (2016) looked at automatic ways to compare OCR accuracy using ground truth documents.
Creating the ground truth is a very time-consuming, detailed process, and the literature also includes a few cautions about understanding what information it provides. Clausner notes that “if the reading order is wrong the character accuracy measure can be very low, even if the actual recognition of each individual character is perfect”, and that sometimes, reading order does not even matter – in a newspaper, “there is no prescribed order in which to read the different articles on a newspaper page” (Clausner, 2020, 391).
When we designed our study, we thought about what made sense to us for testing: was it important to look at the accuracy of individual characters, or full words? Did the exact placement of a character on a page in a transcription matter to us, or would our users primarily interact with scanned documents by searching them? Is it feasible to take the time to create a ground truth document each time we want to test the accuracy of software for a new project? We get into our own decisions below.
Our Study
Resources selected for testing
We began planning our study by thinking of typical text digitization projects seen in academic library archives and special collections: digitization of historical newspapers, older reports published by the university, journal backfiles for open access projects, and special collections books.
We looked only at printed English text in the Latin alphabet, excluding handwriting, music notation, other languages, and other alphabets, all of which require more sophisticated OCR work. For now, we’re interested in beginner-level projects.
We selected three digitized resources to test with different OCR software: the 1928-29 Annual Report of the President from the University of Western Ontario, the January 16, 1975 issue of Western News from the University of Western Ontario, and the first issue from 1865 of the Voice of the Bondsman newspaper from Stratford, Ontario.
We selected these resources for several reasons:
- They were from a variety of different time periods (1856, 1929, and 1975)
- They were typical of the textual material our Archives and Special Collections team digitizes
- They had different formats and some of the common issues affecting OCR quality, such as columns, tables, varying font types and sizes, noise and smudging on the original paper, images and captions, older or unusual spelling, and skewing
- The scans were high quality, and the items were scanned at 300 dpi or above
- The items had already been digitized, since we did not have regular access to our scanning equipment during the Covid-19 pandemic
The chart below (Figure 1: Digitized resources tested in this study) summarizes the resources we tested. The University of Western Ontario provides open access to each of these resources, and they can be viewed at the links below the chart.
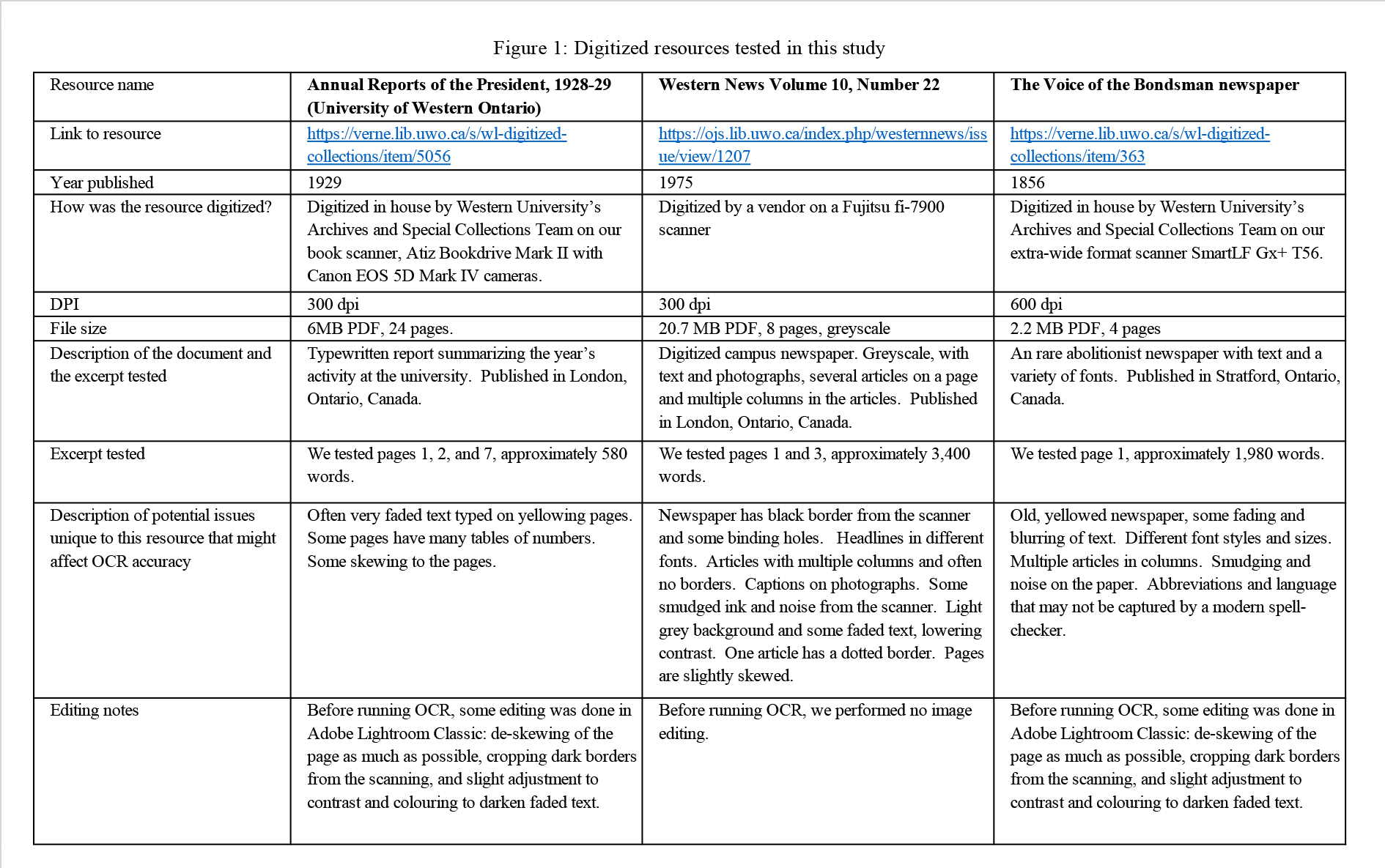
Figure 1. Digitized Resources Tested in This Study – Annual Reports of the President, Western News, Voice of the Bondsman
Software selected for testing
We intentionally chose software that is commonly used, that is affordable (under $300/year for an individual license) and that has a modest learning curve. On our Archives and Special Collections Team, we don’t have regular staff involved in text-based digitization (we do have an Archives Assistant who specializes in photographs, but she does not have extra time in her schedule for other digitization projects). We have one librarian who manages our in-house digitization (one of the authors, Leanne Olson), who often needs to find help from part time students or staff from other departments who have extra time to spare while working on a service desk. The lack of consistency in staffing means we are not looking for software that takes a long time to set up or is difficult to use.
At Western, staff are currently using ABBYY Finereader and Adobe Acrobat Pro DC for different projects. We were also curious about trying an open source software program to compare its effectiveness for our purposes, and had heard Tesseract recommended by colleagues at other institutions.
The chart below (Figure 2: Software Tested in This Study) provides a glimpse at the software we selected for this study:

Figure 2. Software Tested in This Study – ABBYY FineReader, Adobe Acrobat Pro, Tesseract
ABBYY FineReader PDF allows users to edit PDFs, and it has features that allow the user to “draw” columns and other text breaks onto the digital document to allow for more precise OCR. We tested the standard desktop version, as well as ABBYY’s Hot Folder feature. This allows administrators to “[s]et up a watched folder on a local or network drive, FTP server, or mailbox, and any files placed in it will be converted automatically with the predefined settings, immediately or according to a schedule.” (https://pdf.abbyy.com/how-to/) We were curious to see if this process worked as well as running OCR in the individual desktop program. The desktop version we tested was an individual ABBYY FineReader PDF license that one of the authors purchased for a $260 CAD yearly fee. The Hot Folders feature was provided by our library’s IT services for all staff to use.
Adobe calls Adobe Acrobat Pro “the complete PDF solution” (https://acrobat.adobe.com/ca/en/acrobat.html), and it allows users to create, edit, convert, share, and sign PDFs. We tested Acrobat Pro as part of an individual Adobe Creative Cloud license that had already been provided by our library’s IT services to one of the authors. To purchase Adobe Acrobat Pro individually, the cost is $270 CAD per year.
Tesseract is an open source OCR engine. Users can interact with Tesseract directly from the command line (which is what we did for our testing), by using an API, or by using third-party add-on graphic user interfaces (https://tesseract-ocr.github.io/tessdoc/). Similar to ABBYY FineReader, Tesseract allows for more refined document definition, though different options on the command line.
We tested all software on Windows 10 Enterprise version 2004 with the exception of Adobe Acrobat Pro, which we tested on MacOS Mojave version 10.14.6. We installed the standard version of each program, without custom modifications.
We looked into two other options from Google, but did not test them fully as a part of this study. Google Drive has an OCR function as part of its cloud storage service, and allows users to freely convert image files and PDFs to text in a Google Document. (https://support.google.com/drive/answer/176692). Google also offers the Google Cloud Vision API which is a paid product with an OCR function (https://cloud.google.com/vision/docs/ocr). Vision API focuses on images stored in the Google Cloud, using machine learning to understand and classify images, build metadata, detect objects and faces in the images, read handwriting, and extract text from images. (https://cloud.google.com/vision)
Method
When developing our testing method, we thought about the purpose of performing optical character recognition on these digitized documents. What would our users care about, and what are their needs? Generally, we’re interested in making sure the document is searchable and findable in databases or repositories. We’re also interested in ensuring the document is accessible to users with visual or other disabilities.
Occasionally, we might have users interested in extracting transcriptions from the documents or running digital humanities projects – however, from what we’ve learned in our literature review, we knew that at Western we didn’t have the staff time available to handle post-OCR corrections to the point where the text is perfect or close enough to perfect for these boutique projects. Therefore we are primarily interested in searchability and accessibility.
Preparing the documents
We started with the documents in PDF form, since our goal is to create searchable PDFs. The Voice of the Bondsman newspaper and President’s Reports bound volumes were originally scanned as TIFFs (with the archival TIFFs retained for digital preservation purposes), edited as needed, and then converted to PDFs for access. The Western News digitization project was outsourced, and we only had access to the PDFs (the vendor did not provide image files). Beginning with the PDFs for each project allowed us to test the scans using the same process.
In the case of Tesseract, we did need to convert the PDFs to image files to run the software. We did this using an open source program ImageMagick (https://imagemagick.org/) that can be called from the command line in the same way Tesseract is. In some cases, the documents had already been edited as part of our post-digitization process (outlined above in Figure 1).
We ran the OCR software on each document. On our first pass, we did not give the software any instruction on what to do with columns, tables, or other document formatting. We were curious to see how the software would handle these issues out of the box.
Determining OCR accuracy
In deciding how to evaluate the OCR quality for each program, we focused on two things: how well the document could be searched in a database or repository (word accuracy using counting and percentages of correct words) and how well the document could be accessed by someone visually impaired (page segment accuracy using a screen reader). We will call these two tests “Word accuracy test” and “Screen reader test.”
Word accuracy test
We chose to test the accuracy of words to determine how well the documents could be searched in an online database. We eliminated the approach of counting characters based on Pletschacher’s suggestion that “due to the nature of the algorithm, calculating the character accuracy is too resource intensive for long texts (such as found on newspaper pages). Moreover, character accuracy is typically only interesting to developers of OCR systems and not normally used to assess the suitability of recognized documents for specific use scenarios” (2015, 41). In our case, we are looking at a specific use scenario: searching the document.
We worked one page at a time. To determine the error rate for individual words, we manually counted the number of words on the page in the original PDF, and recorded this. Then, we selected all text in the OCRed page and pasted it as unformatted text into a text editor (Microsoft Word). This was our text document to compare to the original PDF.
We compared the text document to the original PDF file by manually counting the correct words and the errors. At this stage, we focused on accuracy of the individual words: we did not worry about the order of paragraphs and articles, or about sentences that ran together from the OCR engine misreading columns.
Before counting errors, we took a quick look at the resulting text to see what types of errors had been introduced, in order to make consistent decisions on how to treat them.
We counted a word as incorrect if it had any of the following problems:
- A missing character
- An extra character (including a space breaking up a word)
- An incorrect character (where a character is replaced by an incorrect on)
- Swapped characters (where all the characters are present, but in the wrong order)
- An entire word missing
Each of these errors breaks the word and keeps it from being found in a full text search.
We compared our initial decisions to equations offered in the literature and found they corresponded well with equations already developed. This is what we used:
![]()
In this case, “∑ Total words” refers to the total of all words on the page in the original document; we counted these by hand. “∑ Incorrect words” is the sum of all words with one of the problems listed above (1-5).
We chose not to count differences in formatting such as italics, underlining, font face, font size, or punctuation that did not break the word (for example, if a comma was inserted in the middle of the word, it would affect searching, but if a semicolon after a word was replaced by a comma, it would not). We might have different considerations if we were digitizing material for digital humanities projects, which often involve writing algorithms to recognize patterns in a large corpus of text. Errors in punctuation, case, font size, font face, underlines, italics, etc. become more important with this type of project.
Screen reader test
To determine the effectiveness of the OCR engine at preserving segments in the case of documents with columns, tables, or articles, we first thought about creating a ground truth as in several of the papers we read (e.g. Carrasco 2014, Clausner 2020). We realized that this didn’t make sense for our study: we didn’t have the time or staff resources to create the ground truth documents, and we were also asking a different question than those researchers. We were interested in how the quality of the OCR would affect users of the PDF interacting with it in an online database.
We had recent experience learning about how our users interact with PDFs from digitization projects. In the fall of 2020, the University of Western Ontario ran an accessibility study of our digitized collections site in Omeka. We watched users interact with the site and saw visually impaired students using screen readers to listen to PDFs read out loud. We realized that was what we cared about in our digitization projects: would any problems with OCR that affected columns, articles, and tables, actually inhibit the ability of users to interact with our documents
We briefly tested copying text from each PDF and pasting it into a text editor (Notepad). We found that the text created by each OCR program had errors in ordering columns, articles, and tables. We thought of counting the number of segments (e.g., a newspaper article, a column of text or numbers) that were out of order in the resulting text document. However, this still doesn’t replicate the user experience we’re interested in, since our users would not be interacting with plain text versions of the documents. We wanted to test the OCRed text using the PDF itself.
We thought back to our accessibility testing and used the free screen reader NVDA version 2020.4 (https://www.nvaccess.org) to test whether the document’s OCR could be read correctly by a screen reader. For this test, we went back to the original OCRed PDFs. The NVDA screen reader, once installed and open on the user’s computer, reads the text out loud as the user hovers over different sections of the document. We opened a PDF and hovered over the text to see how well it was read, making notes on the effectiveness of the screen reading for each of the documents. We focused on two aspects of use:
- Whether the text was recognized well enough to be understandable by ear, even if some words were slightly garbled
- Whether the screen reader could read columns, tables, and articles correctly, or whether it blended sentences together between page sections, making it incomprehensible to the user.
By nature this test was qualitative: the screen reader gave us a good sense of how well the OCR had worked, without forcing us to spend time creating a ground truth to get specific percentages of correct and incorrect text positions.We developed these basic rankings for the screen reader test:
| Excellent | There are few to zero errors in the text and no errors in the page segmentation, so the document is read smoothly |
| Good | Words are understandable even with errors in the text; there are few or small errors in the page segmentation, such as in headings or captions |
| Fair | The words are difficult to understand, and some words may be skipped, but sentences are generally in order and a user can listen to the text, even if the experience is frustrating |
| Unusable | Either the text recognition or the page segmentation is poor enough that a user cannot understand the document by listening to it |
Figure 3. Screen Reader Evaluation Categories
Findings
Below, we share our findings for each of the programs on each of the documents. Figures 4 and 5 summarize our recorded word error percentages and our notes and rankings from the screen reader experiment. Then, we discuss our general notes about each program.
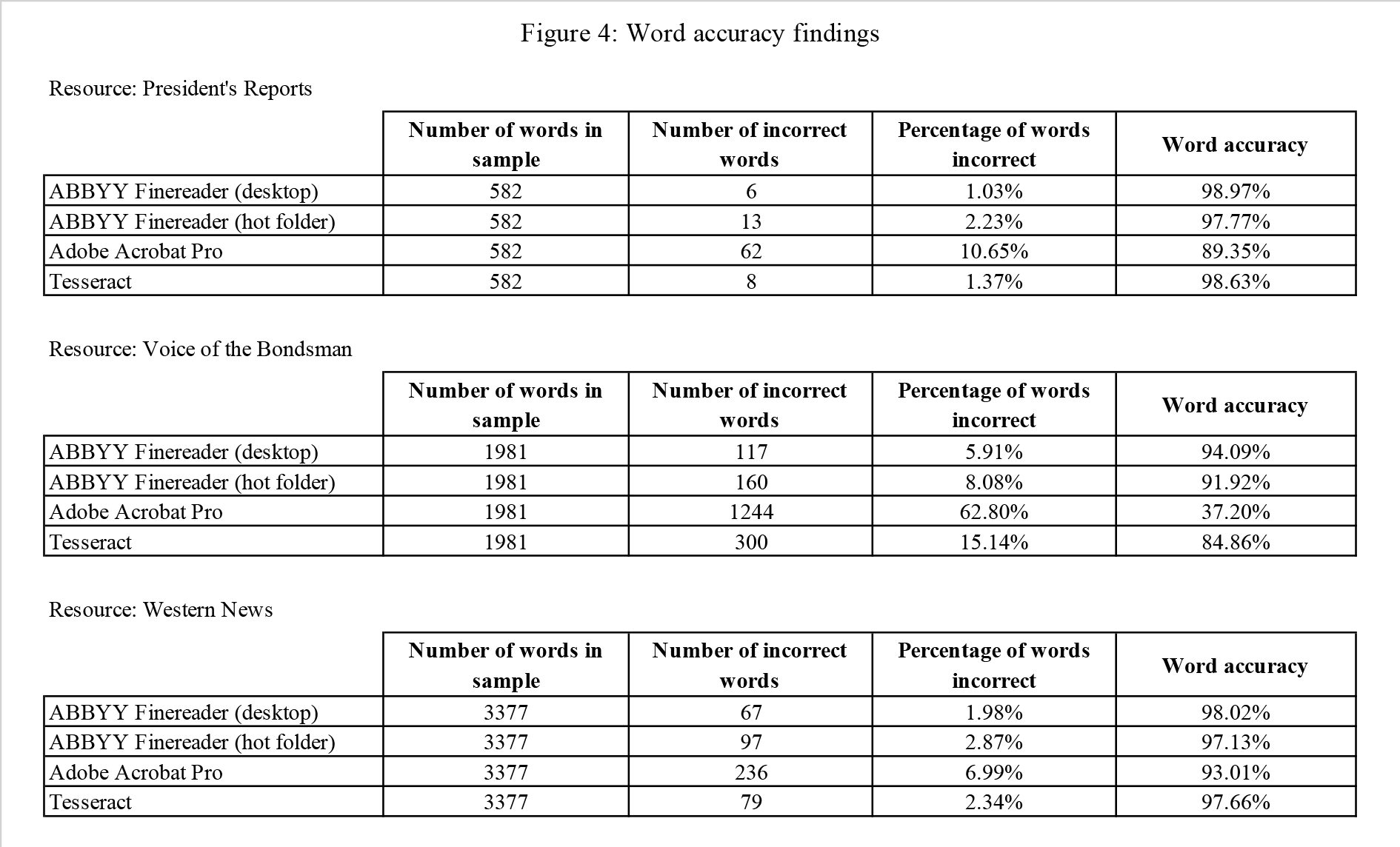
Figure 4. Word Accuracy Findings.
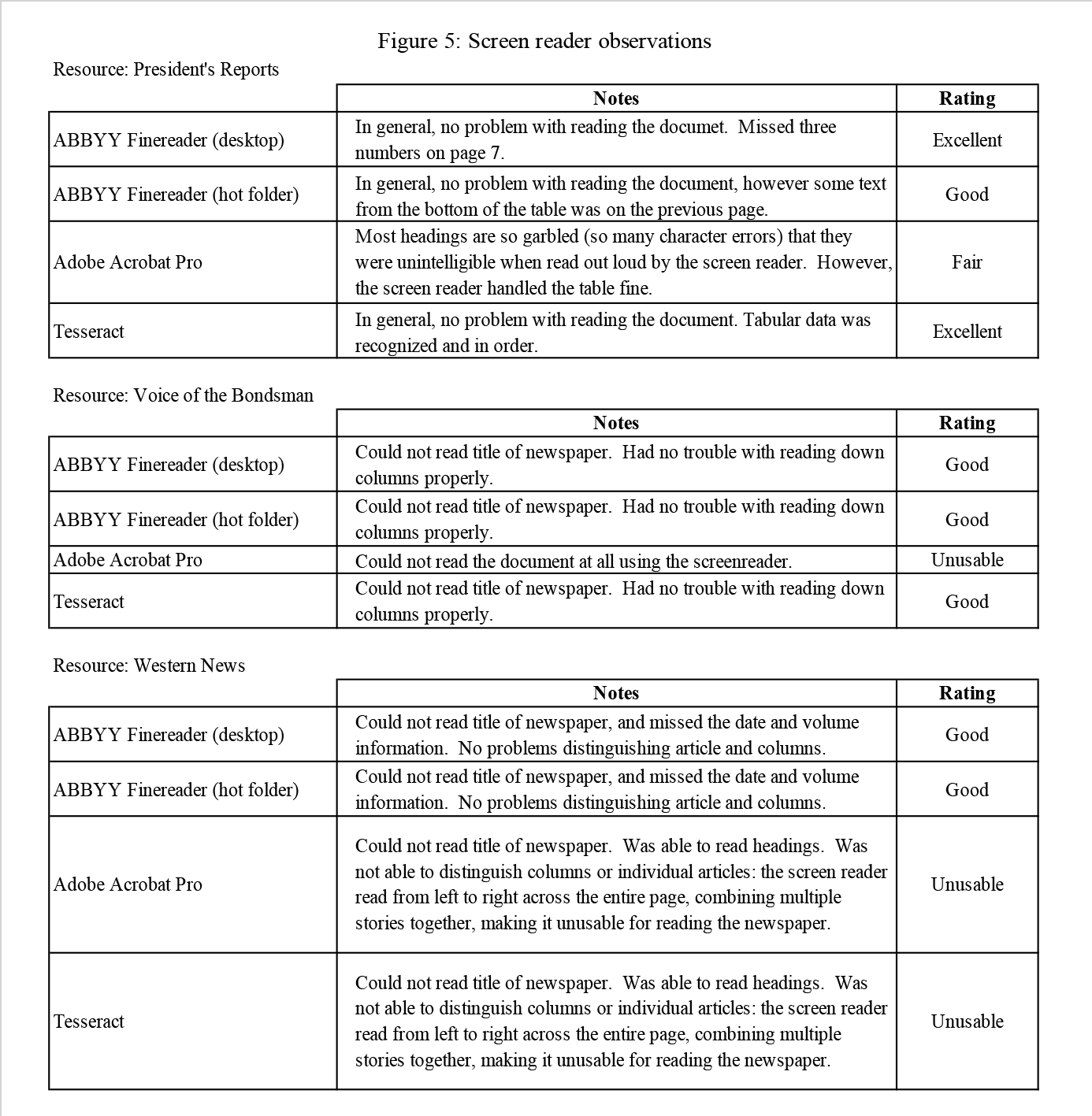
Figure 5. Screen Reader Observations.
General observations on software performance
The word accuracy test showed us that in general, the two versions of ABBYY and Tesseract were all fairly similar when it came to recognizing text. Both handled the article and table content well in Western News and the President’s Report, and struggled with larger or different fonts used in headers, article titles, and photo captions.
Tesseract was weaker on Voice of the Bondsman: it had more difficulty filtering out noise and smudges on the newspaper and occasionally inserted symbols (representing the noise) that broke individual words. Tesseract also inserted extra “words” with Western News when it interpreted dotted borders between articles as characters. Tesseract handled the screen reader test well with Voice of the Bondsman and the President’s Reports, but failed at understanding column breaks in Western News.
ABBYY Finereader was the strongest at recognizing breaks between articles and tables. We also found the accuracy of both versions of ABBYY (desktop and Hot Folders) to be similar.
On all three resources, Adobe Acrobat Pro performed worse than the other programs, and with the oldest text, Voice of the Bondsman, the OCR quality was not acceptable. Adobe in particular had difficulty with word accuracy: although the individual characters were often correct, many of the errors were extra spaces in the middle of words, no spaces between the words, or punctuation inserted in the middle of words – all of these issues render the words unfindable in a search.
We were asked by the Code4Lib editors to investigate two Google products as well. The first was Google’s Cloud Vision API.
The best way to understand how the Cloud Vision API works is to drop an image in their “Try the API” function: https://cloud.google.com/vision. We tested this and it was able to quickly determine whether there was a person or animal in the photo, recognize the emotion on a person’s face, recognize objects, extract text from book titles in the photo, and assign metadata labels (keywords) based on what the photo contained. The Vision API seems most useful to create metadata and identify objects and text in large collections of digitized photos, which is how the New York Times has used the product (https://cloud.google.com/blog/products/ai-machine-learning/how-the-new-york-times-is-using-google-cloud-to-find-untold-stories-in-millions-of-archived-photos).
The API does include a Document Text Detection feature that is potentially applicable to text digitization projects. We found the setup process to be quite involved and that it wouldn’t work for our purposes: our study’s purpose was to find software that is easy to set up and can be used by librarians or archivists new to digitization and OCR work. The Cloud Vision API is intended for users significantly more advanced than we were, and its primary purpose is not creating searchable PDFs or screen readable PDFs, but extracting text from images. This is a fascinating and useful tool, but not one that made sense to use for our text digitization projects.
Google Drive has an OCR function as part of its cloud storage service, and allows users to freely convert image files and PDFs to text in a Google Doc. (https://support.google.com/drive/answer/176692). We found that Google Drive worked fairly well at recognizing text in the President’s Reports, but was unable to recognize any text in Western News and was not able to open Voice of the Bondsman. Google Drive is likely not useful for archival and special collections materials, but may work as a no-cost solution for very clear, modern texts.
Recommendations and Conclusion
Pre-OCR workflow
Before running optical character recognition on scanned documents, we recommend putting thought into the scanning and image editing process. We generally try to choose the cleanest copies we can find, scan documents with at least 300dpi, and perform batch image editing after scanning and before converting the images into PDFs. We recommend using an image editor such as Adobe Lightroom or GIMP to batch deskew and rotate your images, adjust contrast, darken or lighten text if needed, crop out black borders from scanning, or fix any other obvious problems with the scans that make it more difficult to read the text. We used this study to refine our workflow. Our process now is to scan items as high-resolution TIFFs, batch edit the images in Adobe Lightroom, export them as TIFFs or JPGs (depending on the quality we need), then import them into Adobe Acrobat Pro and combine them into a PDF. We then switch to ABBYY Finereader for running OCR.
Selecting software
These recommendations are based on our testing and the type of digitization projects undertaken by staff in library archives or special collections. In your own library or archive, it’s worth doing some quick tests to determine which software works best for our project. The accuracy counts we’ve recorded in our test are a snapshot in time: the software will likely continue to improve in the future. Also, the more time you are willing to spend with the software up front (learning settings in Tesseract or ABBYY FineReader, in particular), the more you can improve the accuracy of your OCR results.
We found ABBYY FineReader to be the most useful when the goal is to OCR a document that will be uploaded into a repository or database, where you want the text searchable and a high accuracy for the OCRed words. We recommend the “hot folders” feature if you have multiple people needing to run OCR on many documents. It allows users with little knowledge of OCR or digitization to drop documents into a folder on a network drive and have the OCR run automatically, producing high accuracy for documents with basic page layouts (for example, a book or a journal article). It will also provide high word accuracy for more complex layouts, and ensure these documents are searchable.
For a small and complex project, we suggest trying the desktop version of ABBYY Finereader to individually OCR scans with difficult page segmentation content such as columns, tables, or newspaper articles: the digitizer can spend extra time up front to “draw” the page segments, ensuring that ABBYY will OCR the document correctly. For more basic page layouts, this isn’t necessary.
We recommend using Tesseract when you want to extract text and get it into a text file for a digital humanities project, or to add a transcription or full text metadata into a repository. With Tesseract, we used the standard text output to do our testing (saving the step of copying and pasting text from the PDF so we could count errors). We used pdf in the output format to output a searchable PDF, which is what we want for our experiment with the screen reader. Tesseract handled the tables extremely well compared to the other programs — everything was in order. We would recommend Tesseract for if you want to extract text from a PDF and maintain tabular order. Tesseract is also an excellent free, open source alternative to ABBYY and fairly easy to learn if a staff member is comfortable with the command line interface.
Both the ABBYY Findreader desktop version and Tesseract include additional tools and settings for recognizing columns and tables. With ABBYY, the user can “draw” and select columns before running OCR, to show the software where to segment it. Tesseract has different settings that can be called when running commands on multiple pages. For a small project similar to Voice of the Bondsman, where the newspaper is older and deals with a lot of noise, it may be worth testing out ABBYY’s manual column selecting. For larger projects such as Western News, this isn’t feasible from a workload perspective. ABBYY handled the columns fairly well with standard settings; if using Tesseract we would recommend doing some experimentations with the different commands first. We started with the manual and examples on the Tesseract GitHub site: https://tesseract-ocr.github.io/tessdoc/Command-Line-Usage.html
Google Drive works as a free tool if you need to OCR a very simple document, such as a report that’s been scanned. We don’t recommend it for archival material.
Adobe Acrobat is very useful for editing PDFs, organizing pages, rotating pages, etc., but based on our tests in this study, we now know Adobe Acrobat is less useful for OCR of digitization projects common to archives and special collections, as we found the accuracy to be quite low with the historical documents tested.
Further investigations:
At Western, we plan to continue testing our chosen software (ABBYY Finereader and Tesseract) following the method in this study, as we embark on new digitization projects. As we get a sense of which software works best for different types of projects, and how much post-OCR correction is needed, we’re developing internal best practices documents that can apply to general classes of projects: for example, large-scale newspaper digitization, or small scale rare book digitization. We’re also working on manual post-OCR correction for a Digital Humanities project that requires perfect or near-perfect OCR at an accuracy the software can’t reach on its own, and we plan to continue fine-tuning our methodology.
References
Alkhateeb F, Abu Doush I, Albsoul A. 2017. Arabic optical character recognition software: A review. Pattern Recognition and Image Analytics [Internet]. [cited 2020 May 21];27(4):763–776. Available from: https://link.springer.com/article/10.1134/S105466181704006X
Carrasco RC. 2014. An open-source OCR evaluation tool. In: Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage; 2014; Madrid: ACM Press. p. 179–184 [Internet]. [cited 2020 May 26]. Available from: http://dl.acm.org/citation.cfm?doid=2595188.2595221.
Clausner C, Hayes J, Antonacopoulos A, Pletschacher S. 2017. Creating a complete workflow for digitising historical census documents: considerations and evaluation. In: Proceedings of the 4th International Workshop on Historical Document Imaging and Processing; 2017; Kyoto: ACM Press. p. 83–88 [Internet]. [cited 2020 Jun 16]. Available from: http://dl.acm.org/citation.cfm?doid=3151509.3151525.
Clausner C, Pletschacher S, Antonacopoulos A. 2020. Flexible character accuracy measure for reading-order-independent evaluation. Pattern Recognition Letters [Internet]. [Cited 2020 May 20];131:390–397. Available from: https://www.sciencedirect.com/science/article/pii/S0167865520300416?via%3Dihub
Gringel F. (2020). Comparison of OCR tools: how to choose the best tool for your project. Medium [Internet]. [updated 2020 Jan 19]. [cited 2020 Jun 15]. Available from: https://medium.com/dida-machine-learning/comparison-of-ocr-tools-how-to-choose-the-best-tool-for-your-project-bd21fb9dce6b.
Kichuk D. 2015. Loose, falling characters and sentences: the persistence of the OCR problem in digital repository e-books. portal: Libraries and the Academy [Internet]. [cited 2020 May 18];15(1):59–91. Available from: https://muse.jhu.edu/article/566423
Han T, Hickman A. 2019. Our search for the best OCR tool, and what we found. Source [Internet]. [updated 2019 Feb 19]. [accessed 2020 Jun 16]. Available from: https://source.opennews.org/articles/so-many-ocr-options/.
Pletschacher S, Clausner C, Antonacopoulos A. 2015. Europeana newspapers OCR workflow evaluation. In: Proceedings of the 3rd international workshop on historical document imaging and processing; 2015; Gammarth, Tunisia: ACM Press. p. 39–46 [Internet]. [cited 2020 May 22]. Available from: http://dl.acm.org/citation.cfm?doid=2809544.2809554.
Springmann U, Fink F, Schulz KU. 2016. Automatic quality evaluation and (semi-) automatic improvement of OCR models for historical printings. ArXiv [Internet]. [cited 2020 May 21]. Available from: http://arxiv.org/abs/1606.05157.
Thompson P, McNaught J, Ananiadou S. 2015. Customised OCR correction for historical medical text. In: 2015 Digital Heritage. Vol. 1. p. 35–42. Available from: https://ieeexplore.ieee.org/document/7413829
About the Authors
Leanne Olson is the Digitization and Digital Preservation Librarian in Archives and Special Collections at Western University in London, Ontario, Canada. Previously, Leanne worked as a Metadata Management Librarian, also at Western.
lolson3@uwo.ca
https://works.bepress.com/leanne-olson/
Veronica Berry is the Records Management & Document Control Specialist at HTS Engineering. During her MLIS at Western University she participated in an eight-month co-op at Western Libraries where she worked on projects relating to digital preservation and digital collections.

Subscribe to comments: For this article | For all articles
Leave a Reply