by Jenn Randles & Andrew Bullen
Introduction
The Tennessee State Library and Archives and the Illinois State Library identified a need to add citation information to individual image records in OCLC’s CONTENTdm (https://www.oclc.org/en/contentdm.html). Experience with digital archives at both institutions showed that citation information was one of the most requested features. Unfortunately, CONTENTdm does not natively display citation information about image records; to add this functionality, custom JavaScript had to be written that would interact with the underlying React environment and parse out or retrieve the appropriate metadata to dynamically build record citations.
Jenn Randles, then Digital Materials Librarian at the Tennessee State Library & Archives, and Andrew Bullen, Information Technology Coordinator for the Illinois State Library, both expressed a willingness to work on this problem via the CONTENTdm User Community Forum site. Shane Huddleston, Senior Developer at CONTENTdm, volunteered to assist Randles and Bullen. This article delves into each approach, demonstrates the code of each solution, and displays the end results.
The Problem
Both institutions’ statewide repositories for digital collections contain a large number of digital objects from a wide variety of contributors. The Tennessee Virtual Archive [TeVA] (https://teva.contentdm.oclc.org/) comprises 67 collections. The Illinois Digital Archives [IDA] (https://www.idaillinois.org/) consists of more than 200 collections.
Metadata in TeVA is uniform across the varied collections since metadata is submitted by one organization. IDA collections, however, have widely varied metadata schemas since they are contributed by many institutions. Using the IIIF API works well when metadata fields are consistent across collections but isn’t applicable otherwise. Therefore, the contributors had to develop their own approaches. Despite working on two solutions, Randles and Bullen worked together to develop JavaScript code that would work for each environment. They consulted as needed with Shane Huddleston for expert guidance on programming JavaScript in CONTENTdm’s React environment.
Since there had to be two approaches to the same problem, Randles and Bullen have each written and documented their separate, successful code solutions.
Solution 1. Jenn Randles, Tennessee Virtual Archive.
tl;dr. Because TeVA’s metadata is uniform, Jenn parsed the IIIF JSON manifest for the record to dynamically build the citation.
Link to script: https://teva.contentdm.oclc.org/customizations/global/pages/js/tsla-cite-global.js
For TeVA, the most pressing reason to provide citations alongside a digital collection item is simple: users asked for it. Over the five years I held this position, one of the most requested features was citation on each item. To start my work, I reviewed other institutions to see how they accomplished this task. Other organizations added citations manually, but with over 30,000 records already in the system, we did not have the staff to undertake such a project.
We do have the AddThis Widget (https://www.addthis.com/) on every item page on TeVA, but it only includes one citation manager: CiteThis. Since many of our users among the general public do not use that service or any citation manager at all, I wanted to go with another option. My end goal was not to provide academic-style citations but give users like bloggers and genealogists a quick way to record sources without having to make many decisions.
I made the decision to use CONTENTdm’s International Image Interoperability Framework (IIIF) API to dynamically build record citations. CONTENTdm enabled the IIIF API (https://help.oclc.org/Metadata_Services/CONTENTdm/Advanced_website_customization/API_Reference/IIIF_API_reference) on all hosted sites several years ago. The IIIF framework provides a way to access digital assets and their metadata from a variety of platforms like Mirador and Leaflet. Knowing that the metadata I needed existed in the IIIF item manifest that was already a part of CONTENTdm, this seemed like the perfect opportunity to try it out.
Since all TeVA’s metadata is in fields with the same labels across collections, I knew I could use the API to return the same data from each item and print it to the screen in a specific order.
Data Needed
First, I determined what data I needed from the API:
- CONTENTdm collection alias
- CONTENTdm item ID
- Title
- Creator
- Date of item
- Collection Name
- Storage location (box and folder in the collection)
- Digital Object ID (essential for locating digital surrogates)
- Owning institution (we house both Tennessee State Library and Archives and Tennessee Historical Society collections)
- Repository (TeVA)
Getting Collection alias and item ID
The first step is to find two variables: the CONTENTdm collection alias and item ID. Both can be grabbed from the URL of the item’s page. The format of URLs in CONTENTdm is https://teva.contentdm.oclc.org/digital/collection/[collection alias]/id/[ID], such as https://teva.contentdm.oclc.org/digital/collection/highlander/id/1032.
The CONTENTdm item ID is different than our Digital Object ID. We need both, since the itemID is part of the IIIF manifest URL. To get these I split the window pathname, called those parts by index number, and assigned them to variables. I had to include the global var at the front, since an upgrade to the backend broke my previous code. I need to declare this at the beginning; otherwise, it throws an error and no citation shows on the page.
var global = global || window;
pathArray = window.location.pathname.split("/");
collAlias = pathArray[3];
itemID = pathArray[5];
Mapping Manifest Fields
I now have the necessary information to build a manifest link. I can map CONTENTdm fields based on API labels in the manifest, such as in https://teva.contentdm.oclc.org/iiif/2/highlander:1032/manifest.json.
An IIIF JSON manifest is an array of key-value pairs that can appear in a different order based on what metadata exists in the record. Simply calling these by index will not work due to this variable order; however, since our labels are consistent across collections, I can use them instead. The script calls data by label later on, but first I will put these fields in order of the final citation, so they show up in the order I want.
const mappings = {
Title: "itemTitle",
order: 0,
Creator: "itemCreator",
order: 1,
Date: "itemDate",
order: 2,
"Collection Name": "itemCollection",
order: 3,
"Storage Location": "itemStorage",
order: 4,
"ID#": "itemID",
order: 5,
"Owning Institution": "itemOwning",
order: 6,
Repository: "itemRepository",
order: 7,
};
Check For Parent Record ID
I now need to check and see if the script was not returning manifests due to items being part of a compound object. Compound objects are multi-page items stored in a hierarchy on CONTENTdm. In TeVA, we always have citation fields on the item level, but often not on the page level. Additionally, each page of an item and the main item-level record itself have different CONTENTdm IDs. We need to check whether a record has a parent and return that parent record information to locate the manifest. Otherwise, the script will not return anything since it cannot find the manifest.
I got this code from Shane Huddleston at OCLC- thanks!
function getParent(item, collection) {
return (
fetch(
`/digital/bl/dmwebservices/index.php?q=GetParent/${collection}/${item}/json`
)
.then((response) => response.json())
// make GetParent API call and return as JSON
.then((json) => {
let parent = false;
// parse JSON for 'parent' value; -1 indicates parent ID is the same as item ID
if (json.parent === -1) {
parent = item;
} else {
parent = json.parent;
}
return parent;
})
.then((parent) => {
// once parent is known, check if IIIF Pres manifest exists
return fetch(`/iiif/info/${collection}/${parent}/manifest.json`)
.then((response) => {
if (response.status != 200) {
console.log("No IIIF manifest exists for this record.");
parent = false;
// if no manifest exists, return is 'false' so that IIIF button is not inserted
return parent;
} else {
// check if manifest is for single-item PDF
return fetch(
`/digital/api/collections/${collection}/items/${parent}/false`
)
.then((response) => response.json())
.then((json) => {
if (json.filename.split(".").pop() === "pdf") {
// if item format is pdf return is false so that IIIF button is not inserted
console.log("pdf?", json.filename.split(".").pop());
parent = false;
return parent;
} else {
return parent;
}
})
.catch((error) =>
console.log("Item API request failed.", error)
);
}
})
.catch((error) => {
console.log("Manifest request failed.", error);
parent = false;
return parent;
});
})
.catch(function (error) {
console.log("GetParent request failed.", error);
parent = false;
return parent;
})
);
}
API Call, Assigning Data Via Labels
The next step is an API call, pointing to the manifest using collAlias and itemID, then mapping label/value pairs to the variables in the const mappings.
async function buildMetadataObject(collAlias, itemID) {
let response = await fetch(
"https://teva.contentdm.oclc.org/iiif/info/" +
global.collAlias +
"/" +
global.itemID +
"/manifest.json"
);
let data = await response.json();
return data.metadata.reduce(
(acc, { label, value }) => ({ ...acc, [mappings[label]]: value }),
{}
);
}
Creating the Citation
The final section takes the pieces specified and puts them in order using the following steps:
- Grab today’s date for date accessed.
- Create reference URL from collAlias and itemID.
- Add itemTitle to blacklist because we need to add quotes to it in the builder.
- Reduce to ignore undefined values, since not every field has data in it. It was printing “undefined” before this addition.
- Create const itemCite using mappings order and join those. I decided to go with a local citation format so we don’t need to update often and it won’t clutter the page. The format works for the public who just needs something quick and not a specific format. This gets us a citation that works for many users, without much upkeep on our side or accounting for multiple formats.
- Add link to our citation info that has a guide to citations for digitized archival materials, then put the entire thing in a div at the end of the metadata section after a line. I grabbed this location idea from my co-author Andrew Bullen- thanks!
function insertCitation(data) {
var tTitle = data.itemTitle;
var url =
"https://teva.contentdm.oclc.org/digital/collection/" +
global.collAlias +
"/id/" +
global.itemID;
var dateToday = new Date().toISOString().slice(0, 10);
const fieldBlackList = ["itemTitle"];
const itemCite = `<hr /><strong>Citation:</strong> \n "${
data.itemTitle
}," ${Object.values(mappings)
.reduce((acc, cur) => {
if (fieldBlackList.includes(cur)) return acc;
const value = data[cur];
return value ? [...acc, value] : acc;
}, [])
.join(
", "
)}, ${url}, accessed ${dateToday}. <br>Note: This citation is auto-generated and may be incomplete. Check your preferred style guide or the <a href="https://teva.contentdm.oclc.org/customizations/global/pages/about.html">About TeVA page</a> for more information.`;
const citationContainer = document.createElement("div");
citationContainer.id = "citation";
citationContainer.innerHTML = itemCite;
if (tTitle) {
document
.querySelector(".ItemView-itemViewContainer")
.appendChild(citationContainer);
}
}
Printing to Page
This section prints the citation after the page loads or on the page update.
(async () => {
document.addEventListener("cdm-item-page:ready", async function (e) {
const citationData = await buildMetadataObject();
insertCitation(citationData);
});
document.addEventListener("cdm-item-page:update", async function (e) {
document.getElementById("citation").remove();
const citationData = await buildMetadataObject();
insertCitation(citationData);
});
})();
Link to the whole script: https://teva.contentdm.oclc.org/customizations/global/pages/js/tsla-cite-global.js
The End Result
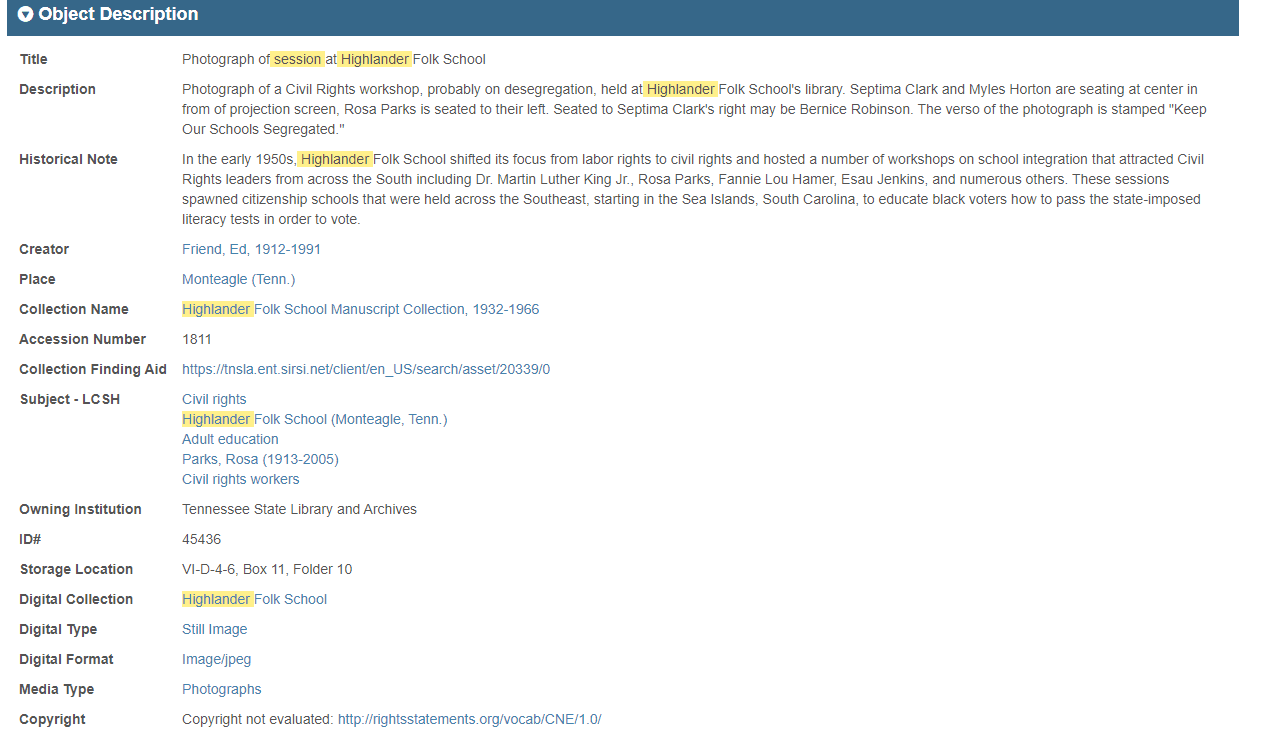
Figure 1. Metadata from a TeVA collection item. IIIF JSON manifest for this item: https://teva.contentdm.oclc.org/iiif/2/highlander:1032/manifest.json

Figure 2. Dynamically-created citation for the item in Fig. 1
Solution 1: Conclusion
If I were to expand this, I would work on a multi-format citation generator so users could choose what they needed. I would still display the local citation on the page but would have other options available with a few clicks.
Solution 2. Andrew Bullen, Illinois Digital Archives
tl;dr. Because IDA’s metadata varies widely across the collections, Andrew created a Collection of Collections that contains a field listing the collection’s field names. He then used CONTENTdm’s APIs to retrieve the data from the record itself, which could then be used to assemble the proper record citation.
Link to the whole script: https://www.idaillinois.org/customizations/global/js/citation.js
A Collection of Collections
We have found a useful addition to our CONTENTdm instance is a management collection, which contains administrative information about the other collections. Our so-called collection of collections can be viewed at https://www.idaillinois.org/digital/collection/p16614coll32/search/. Among the information contained about each collection is the Creator of the collection, which contains the agency and its URL of the contributor; controlNumber, which is useful in connecting the agency and collection to an agency administration system; and, since we have a number of local history collections, city and county, which will someday be used to map the collections and geolocate them.
We added a field, citationField, that contains the field names of the elements that make up image citations in most formats. We chose what we determined were the most popular: MLA (version 8), Chicago/Turabian, APA (version 6), and IEEE. The seven field names are held in a string separated by the pipe symbol (|).
Field Names and Nicknames in CONTENTdm
Since our contributing institutions contribute and create their own metadata records, we cannot count on uniform field names or even the existence of all of the fields that make up a citation. A problem that we encountered from the first was that CONTENTdm stores fields using a nickname, which can vary from collection to collection even if the label used is the same. For instance, one institution might have a field of Creator, with a nickname of creato, and another might have the same field name stored as creator.
I created a simple PHP program to display the field names and their nicknames of a given collection. It is invoked from a shell prompt as php findCitation.php <CONTENTdm collection alias>.
<?php
$alias = $argv[1];
$fieldData = file_get_contents("https://server16614.contentdm.oclc.org/dmwebservices/index.php?q=dmGetCollectionFieldInfo/$alias/xml");
// Of course, change the line above to the URL for your server instance…
$fieldData = simplexml_load_string($fieldData);
foreach ($fieldData->xpath('//field') as $record) {
$resultA[] = array(
'nick' => (string) $record->nick,
'name' => (string) $record->name
);
}
$resultACount = count($resultA) - 1;
for ($iA=0;$iA<=$resultACount;$iA++) {
$nick = $resultA[$iA]["nick"];
$name = $resultA[$iA]["name"];
echo "$name: $nick\n";
}
?>
In order for our method to work, we need to assemble author, title, date, type, collection name, institution name, and description from each collection. For many collections, we can assemble reasonable surrogates; for some, fields are not available and so are simply marked as “n.a.” or “n.d.”.
The information is then added to the citationField field in the record, as the nicknamed aliases for Creator | Title | Original Date | Type | Collection Name | Publisher | Description.
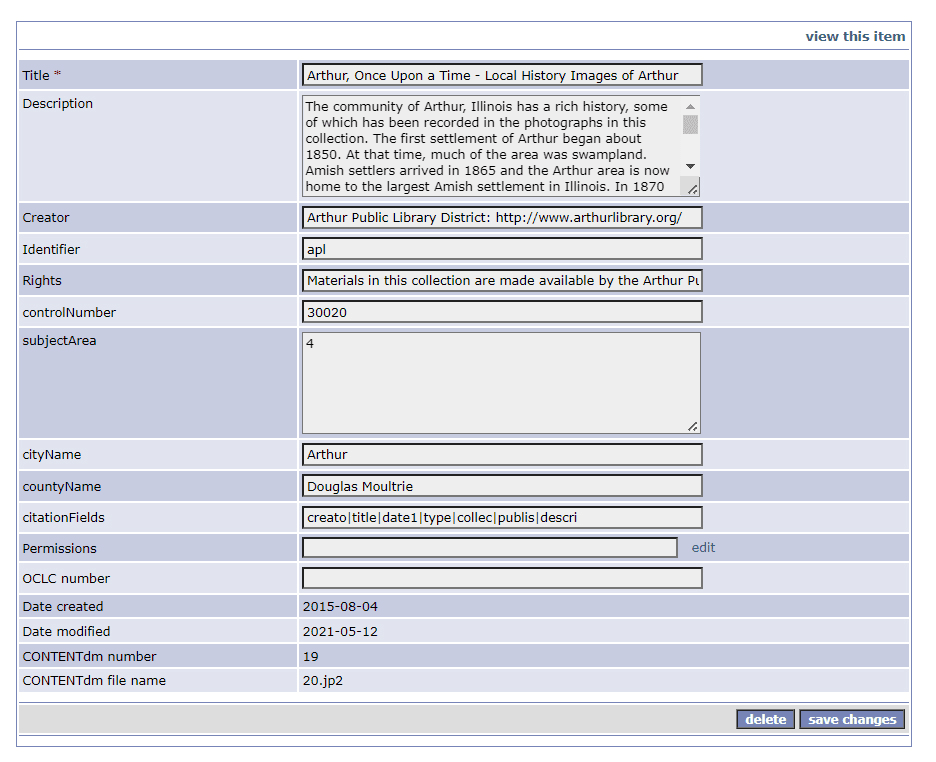
Figure 3. Screen shot of a collection of collections record
CONTENTdm’s APIs and the JavaScript Program
Two listeners initiate the program. They check, respectively, for a brand new page and for a next or a previous page change.
document.addEventListener('cdm-item-page:ready', async function (e) {
executeScript(e.detail.collectionId,e.detail.itemId);
});
document.addEventListener('cdm-item-page:update', async function (e) {
document.getElementById('citation').remove();
executeScript(e.detail.collectionId,e.detail.itemId);
});
executeScript begins the program action itself. We need to access the information contained in our collection of collections in two steps. In the first step, we need to find out what the seven-element citationField value is as well as retrieve the alias of the collection.
function executeScript(collectionName,recordNumber) {
var cdmStr = "/digital/bl/dmwebservices/index.php?q=dmQuery/p16614coll32/identi^" + collectionName + "^all^and/citati!identi/citati/1/1/0/0/0/0/json";
const request = new XMLHttpRequest();
request.open('GET', cdmStr);
request.responseType = 'json';
request.send();
request.onload = function() {
var obj = request.response;
generateDiv(obj, recordNumber);
}
}
executeScript takes two values, the CONTENTdm alias of the collection and the record number of the current record. It then makes an API call, dmQuery (https://help.oclc.org/Metadata_Services/CONTENTdm/Advanced_website_customization/API_Reference/CONTENTdm_API/CONTENTdm_Server_API_Functions_-_dmwebservices), querying the collection of collections (p16614coll32) to return the seven-element citation string and the collection alias. It then calls the next function, generateDiv, to actually build the citation entries.
generateDiv is called with two values, the JSON results of the first dmQuery API call and the record number of the current record. It then takes the citation field and splits it into its elemental parts. The resulting variables contain the nicknames of the relevant fields in the main record.
var apiRecord = obj['records'];
var citation = apiRecord[0]['citati'];
var collectionID = apiRecord[0]['identi'];
if (citation) {
var recordData = citation.split("|");
var creatorLabel = recordData[0];
var titleLabel = recordData[1];
var dateLabel = recordData[2];
var typeLabel = recordData[3];
var collectionLabel = recordData[4];
var institutionLabel = recordData[5];
var descriptionLabel = recordData[6];
generateDiv assembles a new CONTENTdm API call, dmGetItemInfo, to access the data of the record in question.
var mainRecordStr = "/digital/bl/dmwebservices/index.php?q=dmGetItemInfo/" + collectionID + "/" + recordNumber + "/json";
It creates a container, a <div>, so that the newly assembled citation data has a home:
const citationContainer = document.createElement('div');
citationContainer.id = 'citation';
…and actually makes the async query, resulting in a JSON record being returned:
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
var myObj = JSON.parse(this.responseText);
Since we know the nicknames for the fields in question, we can now load variables with proper values:
var author = myObj[creatorLabel];
if (author.length === undefined) {
author = "n.a.";
}
var title = myObj[titleLabel];
var dateOriginal = myObj[dateLabel];
if (dateOriginal.length === undefined) {
dateOriginal = "n.d.";
}
var type = myObj[typeLabel];
if (type.length === undefined) {
type = "n.a.";
}
var collectionName = myObj[collectionLabel];
var institution = myObj[institutionLabel];
var description = myObj[descriptionLabel];
We will need to know what day today is, as well as what the address of the record is:
var dateToday = new Date().toISOString().slice(0, 10); var url = "http://www.idaillinois.org/digital/collection/" + collectionID + "/id/" + recordNumber;
And we can then assemble the four citation formats (MLA, Chicago, APA, and IEEE):
var MLA = "<hr />\n<h3 style=\"color:#aa0000;\">Cite this image:</h3>\n<p><strong>MLA (v.8)</strong>: " + author + ". \"" + title + ".\" " + institution + ": " + collectionName + " (Illinois Digital Archives)," + dateOriginal + ", " + url + ". " + dateToday + ".</p>";
MLA = MLA + "<p><strong>Chicago/Turabian</strong>: " + author + ", <em>" + title + "</em>, " + collectionName + " (Illinois Digital Archives), " + dateToday + ", " + url + ".</p>";
MLA = MLA + "<p><strong>APA (v.6)</strong>: " + author + ". (" + dateOriginal + "). " + title + " [" + description + "]. Retrieved " + dateToday + ", from " + url + "</p>";
MLA = MLA + "<p><strong>IEEE</strong>: [X] " + author + ", \"" + title + "\", " + institution + ": " + collectionName + " (Illinois Digital Archives)," + dateOriginal + ". [Online]. Available: " + url + ". [Accessed: " + dateToday + "].</p>";
citationContainer.innerHTML = MLA;
document.querySelector('.ItemView-itemViewContainer').appendChild(citationContainer);
Incidentally, it took some detective work on my part to find the different regions that make up a CONTENTdm item record in order to place the citation <div>. I did a view source on an item record and found a likely CSS file (https://www.idaillinois.org/digital/f45fcea/app.css). I then experimented with the line
document.querySelector('.ItemView-itemViewContainer').appendChild(citationContainer);
to find the proper region of the record for my citation <div>, using likely candidates until I hit upon the proper container.
Link to the whole script: https://www.idaillinois.org/customizations/global/js/citation.js
The End Result

Figure 4. End result of item metadata and citations below
Loading Custom JavaScript Programming Into CONTENTdm
Because CONTENTdm is now based on the React JS library and environment, a second program is needed to properly load custom JavaScript programs. Shane Huddleston has provided a loader script, loader-1.1.js (https://cdmdemo.contentdm.oclc.org/digital/custom/recipedownloads) that will check the ready state of the page being loaded and then execute the listed JS programs. Here is an example of his loader program, which loads an IIIF metadata viewer and then a citation generator:
loader.js
'use strict';
// helper function to load js file and insert into DOM
// @param {string} src link to a js file
// @returns Promise
function loadScript(src) {
return new Promise(function(resolve, reject) {
const script = document.createElement('script');
/* script.crossOrigin = 'anonymous'; */
script.src = src;
script.onload = resolve;
script.onerror = reject;
document.head.appendChild(script);
});
}
// helper function to assemble full URL of each JS file
function filePath(file) {
return fileDirectory + file;
}
// path corresponding to directory where JS scripts are uploaded
const fileDirectory = '/customizations/global/js/';
// array containing file names of each JS file
const scriptFilesToLoad = [
'field-insert-iiif.js',
'citationGenerator.js'
];
(function() {
const allScripts = scriptFilesToLoad.map(filePath);
allScripts.forEach(loadScript);
document.addEventListener('cdm-custom-page:ready', function(e) {
if (e.detail.filename === 'field-insert-iiif') {
loadScript('/customizations/global/js/field-insert-iiif.js');
}
else if (e.detail.filename === 'citation') {
loadScript('/customizations/global/js/citationGenerator.js');
}
});
})();
Loading Your Programs into CONTENTdm
In your server administration, go to COLLECTIONS->WEBSITE->(login)->CUSTOM->CUSTOM SCRIPTS. Browse to the location of your new JS programs on your local computer.
Upload the citation.js program.
Press the SAVE button, and then the PUBLISH button.
The very last program to load is the loader.js program. SAVE it, PUBLISH it, and it should work. Please note that the programs must be loaded, saved, and published in this order.
Conclusion
Fortunately, we both were able to leverage different aspects of CONTENTdm’s system to provide an effective way to generate citations on the fly for digital collections content. If your collections have the needed citation information in the same fields across collections, the first approach using the IIIF manifest may be best for you. If it varies, try the second approach, and see what works for you. We encourage other institutions using CONTENTdm to try our solutions or develop their own and share it with the wider CONTENTdm user community. We hope that our solutions may lead to a citation recipe in the CONTENTdm cookbook or ideally, even a new feature in a future release.
About the Authors
Jenn Randles (jenn.randles@tn.gov) is Enterprise Data Librarian at the State of Tennessee Center for Enterprise Data and Analytics, formerly Digital Materials Librarian at the Tennessee State Library & Archives. Jenn enjoys user experience design, building and maintaining digital collections and data catalogs, and finds satisfaction in making systems accessible for users at any level of tech knowledge.
Andrew Bullen (abullen@ilsos.gov) is the Information Technology Coordinator for the Illinois State Library. He works with the preservation and presentation of born-digital state documents, digitized cultural resources, and other digital humanities opportunities. He also works with optical musical recognition and crafting narratives from digital artifacts.

Subscribe to comments: For this article | For all articles
Leave a Reply