by Ross Spencer
Introduction
A file format identification report is a specific type of dataset produced by format identification tools such as DROID[1], Siegfried [2], or FIDO[3].
Each of the tools, DROID, Siegfried, and FIDO are cross-platform (Windows, Linux, MacOS) utilities designed to scan individual files or collections of files. The output of this “scan” is called an identification result – a small chunk of metadata that describes a file or set of files in more detail.
A single identification result might include the following:
- Absolute path to the file on the local filesystem.
- Filename.
- Filesize.
- Checksum (e.g. MD5, SHA256, or SHA512).
- Date last modified.
- PRONOM[4] unique file format identifier (PUID).
- File format name.
- File format version.
- MIMEType.
A collection of file format identification results will usually output this information in a two-dimensional (table) format, with each row describing a different file. Optionally, directory entries will also be described [5].
In aggregate, a file format identification report is an important artefact in the process of understanding and preserving a set of digital objects.
This paper will describe the importance of this information and the ways it can be leveraged and used as inputs to other stages of the digital transfer process.
Droid, Siegfried, and FIDO
There are three primary format identification tools used in the digital preservation community across our respective GLAM (Galleries, Libraries, Archives, Museums) sectors[6]. These tools share a single property that distinguishes them from other utilities available to users, for example, the “file” command in Linux, FreeBSD, or Unix environments [7]. Each of these tools attempts to resolve file format identification down to a single PUID from the PRONOM file format registry [8].
PUID (PRONOM Unique Identifier)
PUIDs are “minted” by the developers of PRONOM. They are identifiers for file formats and tend to have granularity down to version of the format [9].
PUIDs were first designed to be URIs in their own right in the INFO namespace[10]. In practice, the INFO namespace was not widely adopted and in 2010 it was recommended that adopters of the namespace migrate to HTTP links following the publication of recommendations around HTTP URIs that supported identification (the INFO part) and resolution (the association of links with human or machine readable data)[11].
PUIDs in practice do resolve as HTTP URIs with a human readable and machine readable description available to the caller. E.g. human readable (xhtml) and (xml), respectively, below[12]:
- https://www.nationalarchives.gov.uk/PRONOM/fmt/1
- https://www.nationalarchives.gov.uk/PRONOM/fmt/1.xml
A PUID is part of a pairing between itself and a file format signature – a series of bytes written in PRONOM regular expression format that identify specific versions of a file format.
The purpose of a PUID therefore is to pair data on a caller’s hard drive, namely a users’ files and file formats, with the PRONOM registry – thus creating an unambiguous identification.
Jackson (2010) describes their hope for a linking model for file format registries[13]:
“My current thinking on the data model is that the format registry design should only be concerned with minting identifiers for formats, and collecting the minimal representation information required to support this. I think that if we can get this right, then we can use those identifiers to describe the other entities, like software tools and digital object characteristics, but without forcing them all into the same system.”
A linking model like this starts to look like a graph. The PUID is the first node on that graph. With it in place, and returned by the aforementioned tools, it is possible to create connections between our collections and the technical metadata required to maintain them [14].
DROID
DROID[15][16] was the first tool that was developed that utilizes the PRONOM file format registry. It was created in partnership with The National Archives, UK (TNA) by Tessella Scientific Software Solutions[17]. Recent adaptations have been developed in-house by TNA and with support around the identification engine (Byteseek) from Matthew Palmer[18].
DROID’s support by a non-ministerial government department, and its widespread use across the UK government for the transfer of digital records means that it comes with a strong reputation for the job that it does. It is written in Java and works cross-platform, on Windows, Linux, and MacOS.
DROID is capable of scanning the contents of aggregate file formats [19]. Its primary output is a comma-separated-values (CSV) table describing files and folders row by row.
DROID describes the structure of files and directories using ID and PARENT_ID. An ID that is of type Folder and has no children, can be reliably identified as an empty folder in the DROID CSV. DROID also has a field that describes empty directories as “empty”.
The fields used in the DROID output are as follows:
| ID
PARENT_ID URI FILE_PATH NAME METHOD |
STATUS
SIZE TYPE EXT LAST_MODIFIED EXTENSION_MISMATCH |
HASH
FORMAT_COUNT PUID MIME_TYPE FORMAT_NAME FORMAT_VERSION |
FIDO
FIDO[20] was created in 2010 by Adam Fraquhar of the British Library. FIDO was developed in Python. Where PRONOM specifies its own regular expression language for describing file-format signatures, FIDO converts PRONOM file format signatures into Python regular expression syntax and uses a standard regular expression matching engine to perform the same function as DROID. Theoretically, as there is greater standardization in regular expressions used by Python, there is a greater opportunity for others to write file format signatures for PRONOM.
Providing a host system has a Python interpreter, FIDO is cross-platform just like DROID. FIDO is capable of scanning (recursing) into aggregate file types just like DROID. FIDO is focused on identifying the file format of files.
If a set of nested directories existed that are all empty, e.g.
$ tree empty_folder_one/ empty_folder_one/ ----> empty_folder_two --------> empty_folder_three 2 directories, 0 files
FIDO would output no identification row for this set of folders. As such it is not possible to reliably determine whether a collection contains empty directories[21].
FIDO outputs a CSV file without a header, however, its fields are as follows:
| STATUS
TIME PUID |
FORMAT_NAME
SIGNATURE_NAME FILE_SIZE |
FILE_NAME
MIMETYPE MATCH_TYPE |
The FIDO documentation describes them using the following syntax:
| “OK,%(info.time)s,%(info.puid)s,%(info.formatname)s,%(info.signaturename)s,%(info.filesize)s,\”%(info.filename)s\”,\”%(info.mimetype)s\”,\”%(info.matchtype)s\”\n” |
Siegfried
Siegfried[22] is developed and maintained by Richard Lehane and was first announced in 2014.
Siegfried has been written in Golang. This provides different benefits to Java and Python, but it still provides all important cross-platform compatibility. Siegfried is compiled and released for Windows, Linux, and MacOS.
Siegfried offers alternative identification options including Freedesktop’s MIME-Info, the Library of Congress FDD (File Format Definitions), and Wikidata. Siegfried also implements a PRONOM identifier using file format signatures from the registry but using a different pattern matching algorithm to DROID or PRONOM to return its results based on those definitions.
Siegfried’s primary output is YAML[23], a plain-text structured key-value serialisation language.
Siegfried’s output is structured into a header which describes how Siegfried was configured to run, e.g. it will describe Siegfried’s version, and the version of the PRONOM signature file used.
Following the header, Siegfried outputs blocks of identification results. Siegfried’s identification fields are as follows[24]:
| filename filesize modified errors |
md5 match: ns match: id match: format |
match: version match: mime match: basis match: warning |
Including the header section, the result for a single digital object might look as follows:
---
siegfried : 1.9.2
scandate : 1970-01-01T00:01:00
signature : default.sig
created : 1970-01-01T00:00:02+00:00
identifiers :
- name : 'pronom'
details : 'DROID_SignatureFile_V100.xml;
container-signature-20211216.xml'
---
filename : 'filename.htm'
filesize : 42
modified : 1970-01-01T00:00:00Z
errors :
md5 : efe3693aa7019eb73969a0418e380e04
matches :
- ns : 'pronom'
id : 'fmt/471'
format : 'Hypertext Markup Language'
version : '5'
mime : 'text/html'
basis : 'extension match htm; byte match at 0, 15 (signature 1/2)'
warning :
Siegfried also outputs its own version of a CSV file, as well as a CSV file conforming to DROID’s specification. Like FIDO, Siegfried only outputs rows for files that it discovers, and so it is not possible to reliably determine empty folders using this report.
DROID, Siegfried, or FIDO
For the purposes of the remainder of this overview, the focus will be on DROID and Siegfried.
While each of the tools discussed have their merits in terms of performance, how they can be implemented, and their ease of use in different contexts, both DROID and Siegfried have support for different hashing (checksum) algorithms.
A checksum is unique to a file whereas a filename is not. We will go on to describe where each of the checksum, filepath, and filename are used in different, flexible ways in support of leveraging these reports for different needs and so having access to a file hash is one of the single most important aspects of a file format identification report if we are going to extract as much potential out of them as possible.
Fractal in their details
Once a collection has been scanned, then it is possible to drill down into the details of the reports generated, including the implications of those details which will help with understanding content, and work that may need to be planned in future to better look after the materials transferred, donated, or received.
Format identification
Format identification is perhaps the first detail that should be focused on. Format identification tells us the file format that a record is encoded in. For example, this paper may be encoded in HTML (Hypertext Markup Language) or PDF (Portable Document Format) at some point. If there was a dataset associated with this paper it might be encoded in a tabular format such as CSV (Comma Separated Values), or JSON (JavaScript Object Notation).
Format identification is perhaps the first most important part of the conversation around maintenance of digital objects. As described, the PUID is the first node in the graph of dependencies that build a picture of an operating environment where digital records were first created, e.g.
| format ‘a’ ? was created on software‘b’ ? was developed for operating system ‘c’ |
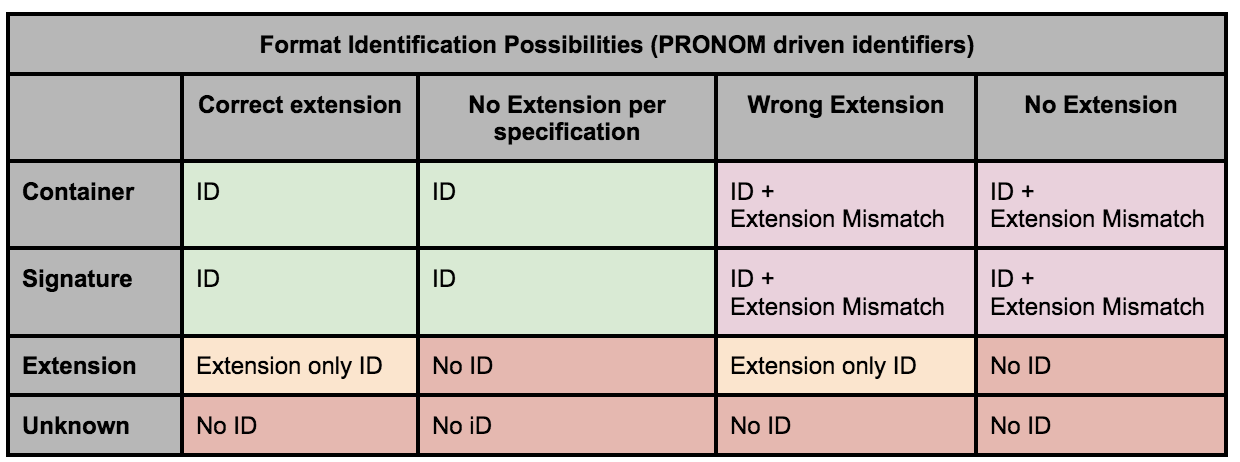
Strength of identification
The file format identification report will contain indicators of the strength of a file format identification.
A container identification will normally indicate that the base format of a file format is ZIP, or OLE2[25]. These are both “container” objects whose contents determine a sub-type of file format, e.g. Microsoft Word 97 utilises OLE2 to create its DOC file format; and Microsoft Word 2010 utilises ZIP to create its DOCX file format.
A signature based identification is more simple and uses identifying byte-sequences within a file’s binary stream, to determine what file format it might be.
Container and Signature based identification may be considered the most accurate form of identification using the tools discussed in this paper.
Extension based identification merely maps a file format extension, e.g. ‘.docx’, ‘.doc’, ‘.csv’, to a list of “known” extensions and their file format name, and no content analysis is completed, meaning that the file may not be what it purports to be. An “extension mismatch” will be returned when a Signature or Container identification is returned but the mapped extension is considered to be incorrect.
Beyond that, formats may also remain “unidentified” which raises the potential of other work to be completed to look after a digital object.
Format identification combinations can be summarized as follows:
Unidentified file formats as an indicator of further work
Unidentified files are an important detail in a format identification report when it comes to determining the work that needs to be done to stabilize a collection.
Unidentified files represent an unknown that in time needs to be corrected. Various different pathways may exist:
- Understanding an exception flow for information into a digital repository, i.e. anticipating that something like Rosetta’s Technical Workbench[26] will raise an exception for unknown objects unless already anticipated.
- Manually identifying the format of the unknown objects, e.g. through forensic analysis, or the use of other tooling, e.g. EXIFTool, Linux File Command, etc.
- Preparing a file format signature submission to the PRONOM development team along with a collection of samples of the file format, either from your collection, or from elsewhere, e.g. UK Web Archive[27].
Identified file formats as an indicator of unwanted files
Format identification when compared with an acceptable file formats policy may determine that there is work required to “weed” or destroy files in a given collection. This might result in two reports – a list of file paths of objects to be maintained and a list of those that should be removed. The latter being documented and agreed with the agency or donor, implicitly through legislation or more explicitly recorded.
Identified file formats as an indicator of the complexity of a collection
Identified files are an important detail in a format identification report when it comes to understanding the complexity of a collection and the work required to maintain it. Each different file format becomes an aspect of the collection that will be monitored over time. Preservation plans and policies might already indicate file formats that are associated with certain risks around sustainability[28]. Aligning the results of the identification report with those policies helps us to identify gaps, and new formats that come under our custodianship from this point on.
File and directory names
Depending on the source of the identification report, only a small section of a filesystem’s structure is described. Take for example, the following two excerpts taken from an Archives New Zealand Series[29]:
One record might arrive with the following file path output in a format identification report:
| /Speeches/Culture and Heritage/speech notes for Launch of Nga Iwi O Aotearoa-Book.doc |
From this detail we can derive:
- The record is part of the ‘Speeches’ structure in the minister’s folder structure.
- It is connected to ‘Culture and Heritage’.
- The document is presumably:
- Speech notes.
- Related to the launch of the Nga Iwi O Aotearoa (Maori peoples of New Zealand) book.
- It was likely typed in Microsoft Word (.doc) format.
| /Speeches/Conservation/NZCPS notes for iwi hui Kaikoura.doc |
From the second structure we can derive:
- The record is also part of the Minister’s speeches.
- However, it is connected to ‘Conservation’.
- From the title of the document it may be:
- About NZCPS (New Zealand Coastal Policy Statement).
- And to be presented at a Maori Iwi (tribe/s) Hui (meeting).
- In Kaikoura, on the east coast of New Zealand’s South Island.
- It was likely typed in Microsoft Word (.doc) format.
This information can form part of the archival record with Culture and Heritage, and Conservation forming sub-series. The filename becomes the title in the archival record.
If we wanted, however, we can begin to draw potential lines of connection in the archival description between other access points and authority records, such as Kaikoura the place, and more general classifications of Maori record and collections related to Maori people: with more granular description possible, once the content is described more thoroughly, such as specific Iwi, geographical regions, and so forth.
Other lines of investigation around full file-path information may be possible, for example, natural language processing for classification of the different parts of the structure. This can potentially pick up people, places, and other different topics or facets.
Encoding
File paths and filenames encapsulate different encoding issues. Paraphrasing the archivist summaries of demystify[30]:
Paths may cause issues across different systems and applications. These could be filenames that include UTF-8 characters such as macrons and other diacritics, or incidences of filenames with multiple space characters following one after the other.
Filenames may have explicit recommendations against using them, e.g. reserved names described by Microsoft[31].
The early detection of this information can be achieved in many different ways but using the format identification report as a pivotal part of other digital transfer activities is one approach.
With improving capabilities for handling Unicode in modern programming languages, and the long, and long-overdue process of moving away from ASCII (American Standard Code for Information Interchange), quality control and assessment of the accurate transfer of file paths from one encoding or language into other systems of record, be those digital preservation, or archival description, or some other host platform, should merely be a formality. That being said, the deliberate act of looking after this information[32] ensures we do not lose data.
The purposeful management of “problematic” file names such as those described as reserved by Microsoft, can only further increase our ability to maintain our digital record.
Empty directories
Empty directories can show up in a format identification report. Directories that contain only other directories and no files can show up also.
Empty directories may be an indication of a file not transferring correctly or not being picked up correctly before being transferred. One might cross-check the format identification report with any other manifest sent with a collection of items.
Empty directories are difficult to record but they also have informational value as described in the file path examples above. They are part of the original order of a transfer and so a deliberate decision must be made about how to maintain that information – and/or how to document their removal from a transfer, as part of an appraisal process, or another process somewhere down the line.
Specifications such as Bagit[33] or OFCL[34] (Oxford Commons File Layout) do not have an easy task looking after empty directories and suggest workarounds. Standards such as METS provide ways of documenting folder structures that can accommodate empty directories.
File Sizes
File size in format identification reports help us to determine the volume of digital storage required. They help us to predict and request more storage resources. We may record the aggregate value as part of the accession record, and in archival description as we record the size and scope of a collection.
File-sizes that are too large may be indicative of files that need more analysis and attention. For example, as one becomes more familiar with what to expect from different file-types, take a Word Document, if its size starts to creep into the tens of megabytes or more, then it might warrant review for embedded content and complexity. File-sizes that are too small may be indicative of a need for further work as well; an MP3 (MPEG-2 Audio Layer III) or FLAC (Free Lossless Audio Codec) file that is only bytes or kilobytes in size may not have any significant intellectual payload and could be reappraised. Files, in general, that are too small[35] may benefit from further forensic investigation to determine if they have been transferred correctly or incorrectly selected for transfer.
Zero-byte files
Zero-byte files are a specific example of where file sizes are important to recognize and understand up-front. It is also a concrete value that can be easily detected versus the fuzzier concept of a file being “too large’ or “too small”.
Zero-byte objects may have sensible naming conventions and sensible file-format extensions but have zero-payload. They would render blank in a hexadecimal (hex) editor if they were to be opened for forensic analysis.
Zero-byte files, perhaps more so than empty directories, may be indicative of something that may have gone wrong in a file transfer. It is something to ask of the agency or donor, or of any additional manifests sent with the digital objects.
Documenting these may be challenging, and if they are to be “preserved” it is important to make sure receiving systems, e.g. your digital preservation platform, understand how to look after them and do not remove them from a transfer. Ultimately, it may simply be a further discussion with the agency or donor about their selection for transfer and may eventually be removed from the collection.
Having this information in the format identification report may help the agency or donor in the appraisal process. It helps us as long-term custodians as we process these collections.
Date last modified
Date last modified is a date that can be accessed consistently across the widest range of file systems[36]. For archival purposes the earliest date and latest date in a digital collection may accurately map to the beginning and end range of a sub-series description. From a debugging perspective the date last modified of different files should be monitored as the first indicator of a problem during transfer, appraisal, or analysis – homogenized (all dates are the same), or dates that are too recent compared to the others in the transfer may point to unintended changes to data, and some of those changes might have been made before fixity was truly in place for a transfer. It may also mean there is a problem somewhere in the digital transfer workflow where we attempt to preserve this information across different filesystem boundaries.
Checksum analysis
While creating checksums cause a loss of performance when identifying digital collections, because of the need to read an entire file from disk, with respect to this paper, a checksum is one of the most powerful features of the format identification report.
DROID and Siegfried share ‘md5’, ‘sha1’, ‘sha256’ as checksum options, and Siegfried also offers ‘sha512’, and ‘crc’ (cyclic redundancy check). It will largely depend on institutional policy which one is adopted. When we look to match objects against “known” checksums as is discussed later on, it may be important to match the algorithm used by the source registry of those checksums.
A checksum, as we know, describes the fixity of a digital document. They describe the uniqueness of the content of a digital record as it was at a given point in time. If a checksum for a digital object changes then it is indicative of something changing in the file, either by design or through corruption.
A checksum is a digital fingerprint for a file. In combination with a file path, we can identify a file uniquely in a collection of digital objects. We can use both as a fingerprint that enables us to describe the digital object in front of us. At the most fundamental level: {<checksum> + <file path>} allows us to unambiguously attach the rest of the information in a format identification report with that row of data. The combination enables the following:
| {<checksum> + <file path>} | Format Identification | Additional descriptive information about the digital record, e.g. archival description; additional technical metadata. |
| FIle size | ||
| Date last modified |
Duplicate detection
The importance of distinguishing checksum + file path is that a collection may contain duplicates of other files. They may sit at different paths in the collection structure, but they are byte-for-byte duplicates.
Having the checksum in a report allows us to identify the byte-for-byte duplicates[37]. Having the file path allows us to understand the context. Once the purpose of a duplicate can be ascertained they are likely to be important enough to maintain, e.g. given enough context we might find enough information to distinguish different purposes for something. In the fictional example below, we can see a speech may have been recycled and used at a museum event in December 2021, and reused at a Library Opening January 2022[38]:
| /Speeches/Culture and Heritage/museum_speech_dec_21.txt |
| /Speeches/Culture and Heritage/library_opening_speech_jan_22.txt |
Maintaining duplicates may be an expensive undertaking and if context cannot be properly established, or we find the context largely identical, or duplicates are numerous enough, then there are disposal activities we can perform around this.
Connecting collections
Perhaps one of the most exciting prospects using checksums is to identify provenance across collections. I discuss in a previous paper the ways in which checksums might be used to identify links across series in archival collections[39]. Taking one example, checksum duplicates received from two different agencies may tell us something about how both agencies were in communication with one another and then the presence of a document in two different contexts may illuminate more about that interaction.
System files
Operating systems and different applications software are distributed with default files that are helpful to the user, or support the software itself. These files are best characterised as system files. The number of examples of “system files” is extensive. The true-type font “Arial” that is distributed with Microsoft Windows could be classified as one, Windows’ default wallpapers or executables (MS Paint, Minesweeper, and so forth). Likewise, distributions of Linux or MacOS will have common files and applications. Common to specific versions of these “off-the-shelf” products, these files with few exceptions will share the same checksum with each other, and so, CMD.exe on my copy of Windows 95 is going to have the same checksum as on your copy of Windows 95. When I download DROID 6.5 from The National Archives, UK, it will also share the same checksum as your copy of DROID 6.5, and so will all of DROID’s supporting files.
These files do not usually need to be maintained with a collection as they do not represent an intellectual output of the creator. If we can identify these files they can be weeded, or recommended for destruction, ideally during appraisal, but potentially at any time during the transfer lifecycle.
Registries for the checksums of these commonly distributed system files exist. A checksum in a file format identification report can be looked up against those registries and can help with further decision making around appraisal and disposal. Later we will look at Steffen Fritz’s tool “filedriller” which recognizes this within the digital heritage context and attempts to help with just this.
Zero-byte-ness
A final, but curious property of checksums, that may be of interest to some, is that a checksum can also identify whether a file is zero-bytes. Another way of identifying zero-byte files, albeit one that is less practical than looking at the size if it is available, is by looking for a zero-byte checksum in a report. The checksum will always be consistent with the algorithm. A mapping of some zero-byte checksums is shown below:
| sha256 e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 sha1 da39a3ee5e6b4b0d3255bfef95601890afd80709 md5 d41d8cd98f00b204e9800998ecf8427e |
Distance scanned in file
A small but important part of identification is its accuracy. Identification is largely dependent on how much information needs to be scanned to return an identification result.
A feature that exists in both DROID and Siegfried is a limit on how many bytes are scanned when running identification. DROID introduces this feature to users “out of the box” and limits scanning to 65535 bytes. Users who want to make sure a file is scanned in its entirety need to set this value to -1. Siegfried works the other way around and scans the entirety of a file out of the box and asks the user to configure a maximum number of bytes if it is desired.
When a max scan value is set, there is always a possibility that a file will not be correctly identified. In reality, it is likely to be partially identified using indicators of another format.
An example might be the PRONOM record for PDF/A-1a[40] which describes a signature as:
| Identifies the byte sequence which equals – xmlns:pdfaid=”http://www.aiim.org/pdfa/ns/id/ which is the PDF/A identification namespace within the PDF/A meta-data, followed by 1 and A, which are the two mandatory elements and values for PDFA/1a. See ISO 19005-1:2005 and Technical Corrigendum 1 for further information. |
The sequence is “variable” according to PRONOM which means that it can be found anywhere in a file. If that offset is over 65535 bytes it can be missed using default DROID configuration. A more-likely result if this variable sequence is missed is a more standard PDF identification which may or may not be enough information for some users.
Introduced into Siegfried was the return of information about how many bytes have been scanned when generating an identification result.
This information can be used to configure a maximum byte scan value by finding an average for all the identification results in your collection. This could potentially be used to calibrate variable signatures in PRONOM in the future as well.
If a balance of speed and accuracy is important, then these settings are worth looking into in more detail.
Codifying the details
Acknowledging the summary of details described so far, it becomes important to extract information from a file format identification report in a fast, consistent, and repeatable way. A collection can then be evaluated and reevaluated throughout appraisal and further processing activities using the same format identification report or updated copies based on the same collection of objects.
A spreadsheet can only do so much, and it is difficult to repeat large numbers of queries and ensure those queries are always correct. It is also difficult to do without a consistent mental model of the information that you are looking at. For example, how you anticipate teasing apart information on identification accuracy, e.g. by container or signature, or both, or including extension-only identification as well.
One approach this author has investigated is to convert the spreadsheet into a standardised database and then run sets of queries against that database.
The database conversion component is called sqlitefid[41]. Sqlitefid will convert DROID and Siegfried reports into a consistent database schema that can then be queried.
The database schema looks as follows:
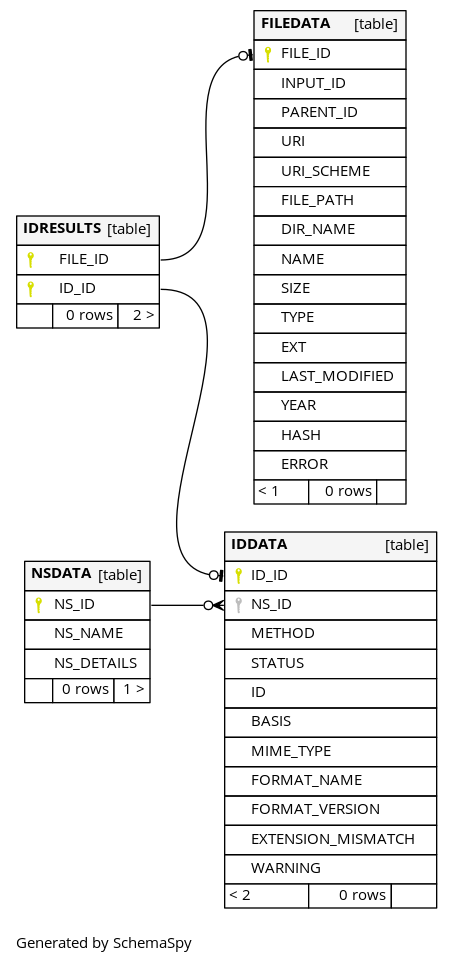
Figure 1. Fields and tables created by Sqlitefid.
The abstraction described in this schema is already used to normalise DROID and Siegfried reports and can also be used for FIDO or any others outputting similar information.
The tool demystify[42] uses sqlitefid and was first written in early 2014 and attempts to find a consistent set of queries to ask the database it creates. A summary of these queries is documented below.
| count all files in the database count all identification results for all identifiers as one count all rows in the id data table count of all extension mismatches count of extensions for all signature and container identified files in the database count of files from the database identified using signature or container methods for a given namespace count of files from the database with multiple identifications for a given namespace id count of files with multiple identifications count of non-pronom signature or container identification results count the number of container files in the database count the number of distinct files in the database count the number of files in container objects, e.g. zip count the number of namespaces used by an identification report count the number of unique directories in the database count the number of unique identifications count the number of zero-byte files in the database count of pronom signature or container identification results create a frequency list of unique errors output by the identification tool create a frequency listing of all ‘last-modified’ years in the database create a frequency listing of duplicate files in the database create a frequency listing of file format extensions in the database identify gaps across all namespaces used in an identification run list extensions of container objects in the database list the paths of the zero-byte files in the database select all ‘folder’ file paths from the filedata table select all filenames from the filedata table select all identification results across the database and order by namespace select all namespace data select all non-folder file paths from the filedata table select all unique file format extensions in the database select distinct file names from the database select file and id metadata from the database for a set of files in a given list of format ids select file paths and file names from the database for a set of files with extensions in a given list select file paths and names from the database for file names in a given list select file paths and names from the database for folder names in a given list select file paths from the database where the name is in a given list select files from the database that have extension mismatches select files identified using signatures or containers using PRONOM select information about all mimetypes recorded in the database where a mimetype is listed select information about all signature or container identified files in the database select information about files identified by extension only select information about namespace and identification based on the given identification method select metadata about all results ordered by namespace select metadata about identifications for a given identification method select metadata about objects with a byte match identification select paths from the database for files with a given checksum select the checksum type used by the database select the format identification tool used sum the total bytes used by all files in the database |
The SQL for these queries can be found in this Gist: https://perma.cc/N4PT-CKNG[43].
Brunnhilde[44] will be discussed as a stand-out example of the approach of using a database as an interface below. Brunhilde was created by Tessa Walsh in 2016 and uses an in-memory sqlite database to function as an intermediary between a Siegfried format identification report and additional reporting on top of that[45].
An API for querying format identification reports
It is this author’s contention that a more traditional API driven approach may be feasible, and an improvement over the existing implementation in sqlitefid. An API approach would enable a format identification report to be queried using http queries and would offer users and developers more granularity with how they access results and piece them together to generate some of the outputs that will be discussed in more detail below.
Outputs become inputs
With the potential of our format identification report becoming clearer, we can explore how the report is used, or can be used as an input to different tools.
Accession Inventory / Manifest
With a checksum and file path, the format identification report can first function as a reliable inventory. A bureaucratic piece of information that describes what was received, and formatted correctly, and what was transferred into digital storage.
At Archives New Zealand, DROID was previously converted from CSV to their Archival Description System’s “Archway” input format[46]. The mapping required adding series and repository information to the data already contained in the report. File paths were split into sub-series, and file names formatted to record titles. The checksum in the report became a way of tying the digital record to this report and was important for aligning the Archway import sheet with the input required for the Rosetta Digital Preservation System[47].
At the end of a transfer process the report could then be formatted again in such a way to be returned to the transferring agency or donor to confirm what was received, transferred into preservation storage, and create a complete record of the digital transfer.
droid-convert
Where the “archwayimportgenerator” was specific to Archive New Zealand’s archival description system at the time, droid-convert is a more recent tool developed by The National Archives UK that might provide a useful reference to readers. The approach is similar and takes a DROID report and transforms it into a format for transfer into TNA’s digital preservation system[48].
Appraisal
The format identification report supports appraisal and re-appraisal. As previously discussed, the data in the report provides a snapshot of how a transfer needs to be stewarded and a collection maintained.
Demystify
As discussed, demystify was first created in 2014 and takes the information in a format identification report and queries it systematically to provide comprehensive consistent reporting from the data. It endeavours to provide a static analysis of a collection. Demystify outputs a HTML human readable summary of all of the information it can gather. Demystify can be run on different versions of a collection’s format identification report as preparation work on the collection progresses.
Demystify was first inspired by c3po[49] (Clever, Crafty Content Profiling of Objects). c3po it was decided could not easily be run in restricted government compute environments and so similar capability was translated to Python standard library components in demystify wherever possible.
Demystify can help users filter collections into two different parts [50], quickly summarised as “files that we do not need to investigate further”, and “files that might need additional effort to transfer safely or remove from the collection”, namely “heroes” and “rogues”. The feature was created by this author and Andrea K. Byrne, and uses an allowlist and denylist feature to help archivists flag different issues they would like to investigate further in an isolated part of the file structure.
Brunnhilde
Brunnhilde is distributed with Bitcurator[51] and was created by Tessa Walsh. Brunnhilde is best described by the creator, as follows [52]:
“Brunnhilde was written to supplement existing file format identification and characterization tools, with a focus on producing human-readable high-level reports for digital archives and digital preservation practitioners.”
Brunnhilde provides collection level statistics, as well as augmenting this with file level information about whether viruses can be detected using ClamAV[53], or personally identifying information using Bulk Extractor[54].
Freud
Freud is another analysis tool[55]. Developed by Paul Young at The National Archives, UK in 2018 it takes a DROID report as an input and returns information about:
- Unidentified Formats.
- Extension only identification.
- Multiple IDs.
- Extension Mismatches.
- Compressed archival container formats.
- Duplicate files.
- Zero byte files.
- Formats not on an allow list.
Filedriller
Filedriller[56] uses the checksum output of Siegfried to compare file hashes associated with files to those in the National Software Reference Library (NSRL) database[57]. The NSRL is one example of the aforementioned databases to capture information about commonly found files in different computing environments. Fonts, or wallpapers, for example, distributed with Windows are recreated many times across all of the numerous deployments of Windows systems. These files all share the same checksum and so if they are identified in a collection it is highly likely they are not considered important in the transfer. With this information identified, a curator or archivist can begin to make this decision. Filedriller can help with appraisal and removal of unnecessary information from our collections.
Rosetta ingest sheet
A “Rosetta ingest sheet” is a very specific example that was primarily used in Archives New Zealand, but the codebase has been used by a few other institutions running Rosetta as well including the J. Paul Getty Trust in California and The Centre for Jewish History in New York.
Rosetta provides CSV as one mechanism for the ingestion of large numbers of digital objects. With the format identification report, an artefact that existed at the beginning of a transfer from a government agency to re-appraisal, and ingestion, it could be transformed into a CSV that matched the specification expected by Rosetta. Paths needed to be modified to match those of a zip-based structure, and information would be optionally augmented with information provided by the archival description system. Data was tied together with checksums and combined with a zipped directory of all the digital objects in a transfer provided Rosetta with everything needed to store everything securely in preservation storage [58].
Depending on the requirements of other digital preservation systems, this approach could be adapted to those as well. The key is treating this information we have at our fingertips as the fulcrum of that workflow.
Simulating a collection
The current generation digital preservation tooling might not always work out of the box. As developers we have to find different ways of debugging systems and workflows. One limitation to this is that the final line of debugging, accessing original files, is not always possible.
One approach this author has adopted in the past is when failing to get access to original digital objects, asking for a DROID or Siegfried report from the collection. A report might provide enough information to tease out some potential issues with a digital transfer.
As the report has file-paths including file names and file sizes, it is possible to programmatically recreate a directory structure including mock files and mock data matching the size of the original collections. This data can then be wrapped in such a way as to mimic a transfer to help us understand if there is anything inherent in this detail that might be causing a problem somewhere. Sometimes it has been feasible to create skeleton file format samples mimicking specific file-formats[59]. Mimicking collections more closely using forensically detailed techniques such as this can help to generate more debugging information (potentially more realistic debugging) as these mock collections move through a transfer workflow.
It may not always be possible to identify a problem this way but it has been useful for providing a means for more realistic bulk testing of systems, and to remove lines of investigation from a debugging analysis in the past.
Conclusion
The file format identification report can be described as a primitive of the digital transfer process. A single format identification on its own might seem too atomic and have limited reuse value, but reports collecting this information in aggregate can make them a pivotal asset in the digital transfer process.
As an abstraction of a filesystem and a digital collection, perhaps one of the most interesting aspects of the format identification report is that it provides a static view of what can be a lot of data, and what can be used in many different contexts. A file format report can be used to understand a digital collection even before an archive or library has access to those digital objects. They provide a picture of a world that can be used to analyze, debug, and maintain. It can be output once and revisited multiple times saving processing time and resources along the way.
A fascinating tease for the future of these reports from the maintainers of DROID might be to include “format type/classification” in the output one day[60]. One’s imagination starts to work overtime with the thoughts of the ways this information can be presented in a static analysis to provide different perspectives of a digital transfer and to understand its potential descriptive uses as well as understanding the habits and practices of a donor or agency.
The format identification report is a dataset and treated as such we find that it is fractal and illuminative in its detail. While this paper covers a lot of potential uses, it is hoped that it has not uncovered all the potential uses. And it is hoped the reader will be inspired to provide examples to counter international biases in some of the tooling discussed here, and complete any gaps that are undoubtedly found herein.
References
Acrobat PDF/A – Portable Document Format 1a. (2022, February 11). PRONOM. Retrieved March 7, 2022, from https://web.archive.org/web/20220307081426/https://www.nationalarchives.gov.uk/PRONOM/fmt/95
Aggregate >> Quality and Functionality Factors . (2022, 1 28). Sustainability of Digital Formats: Planning for Library of Congress Collections. Retrieved March 6, 2022, from https://www.loc.gov/preservation/digital/formats/content/aggregate_quality.shtml
archives-new-zealand/archives-nz-rosetta-csv-ingest. (2014, August 13). GitHub. Retrieved March 13, 2022, from https://github.com/archives-new-zealand/archives-nz-rosetta-csv-ingest
archives-new-zealand/archwayimportgenerator: Code to create an Archway Import Sheet from DROID CSV + external CSV. (2017, May 31). GitHub. Retrieved March 7, 2022, from https://github.com/archives-new-zealand/archwayimportgenerator
Brown, A. (2006, July 27). The PRONOM PUID Scheme: A scheme of persistent unique identifiers for representation information. Retrieved March 6, 2022, from
https://perma.cc/AXW5-8R6S
Brunnhilde. (2022, February 4). COPTR. Retrieved March 13, 2022, from https://coptr.digipres.org/index.php?title=Brunnhilde&oldid=5570
bulk-extractor. (2021, November 15). Kali Linux. Retrieved March 13, 2022, from https://www.kali.org/tools/bulk-extractor/
ClamAV About. (2022, March 13). ClamAVNet. Retrieved March 13, 2022, from https://www.clamav.net/about
Clipsham, D. (2021, December 1). DROID to additionally provide info on format type/classification? GitHub. Retrieved March 7, 2022, from https://github.com/digital-preservation/droid/issues/663
Comparison of file systems. (2022, January 31). Wikipedia.org. Retrieved March 7, 2022, from https://en.wikipedia.org/w/index.php?title=Comparison_of_file_systems&oldid=1069049316
Demystify, tool for static analysis of format identification reports. (2013, December 10). GitHub. Retrieved March 7, 2022, from https://github.com/exponential-decay/demystify
digital-preservation/droid: DROID (Digital Record and Object Identification). (2012, April 25). GitHub. Retrieved March 6, 2022, from https://github.com/digital-preservation/droid
DROID (Digital Record Object Identification). (2021, August 17). COPTR. Retrieved March 6, 2022, from https://coptr.digipres.org/index.php?title=DROID_(Digital_Record_Object_Identification)&oldid=5245
DROID: file format identification tool. (2022, March 8). The National Archives. Retrieved March 8, 2022, from https://www.nationalarchives.gov.uk/information-management/manage-information/preserving-digital-records/droid/
ExLibris. (2018, August 14). Technical Analyst Workbench. Exl-Edu. Retrieved March 13, 2022, from http://exl-edu.com/12_Rosetta/Rosetta%20Essentials/SIP%20Processing/TA%20Workbench/story_html5.html
exponential-decay/moonshine: Given four bytes, download a random file from web archives implementing the UKWA Shine interface. (2018, March 14). GitHub. Retrieved March 7, 2022, from https://github.com/exponential-decay/moonshine
exponential-decay/rosetta-csv-ingest: Generate a Rosetta CSV ingest
sheet with just a DROID export CSV. (2017, May 10). GitHub. Retrieved March 7, 2022, from https://github.com/exponential-decay/rosetta-csv-ingest
exponential-decay/sqlitefid: Normalize file format identification results (DROID, Siegfried) into a single SQLite DB. (2017, May 26). GitHub. Retrieved March 7, 2022, from https://github.com/exponential-decay/sqlitefid
Farquhar, A. (2010, October 13). openpreserve/fido: Format Identification for Digital Objects (FIDO) is a Python command-line tool to identify the file formats of digital objects. It is designed for simple integration into automated work-flows. GitHub. Retrieved March 6, 2022, from https://github.com/openpreserve/fido
FIDO (Format Identification for Digital Objects). (2021, April 22). COPTR. Retrieved March 6, 2022, from https://coptr.digipres.org/index.php?title=FIDO_(Format_Identification_for_Digital_Objects)&oldid=4293
File (command). (2021, October 11). Wikipedia.org. Retrieved March 6, 2022, from https://en.wikipedia.org/w/index.php?title=File_(command)&oldid=1049303302
File Format Identification. (2021, April 20). COPTR. Retrieved March 6, 2022, from https://coptr.digipres.org/index.php?title=File_Format_Identification&oldid=3863
File format registry: new version released by the UK National Archives. (2005, November 18). Cambridge Network. Retrieved March 6, 2022, from https://perma.cc/LGF4-7H4Y
Formats, Evaluation Factors, and Relationships. (2017, March 2). Library of Congress. Retrieved March 7, 2022, from https://www.loc.gov/preservation/digital/formats/intro/format_eval_rel.shtml#factors
Fritz, S. (2020, November 25). steffenfritz/filedriller – filedriller. Codeberg. Retrieved March 7, 2022, from https://codeberg.org/steffenfritz/filedriller
Implementation Notes. (2022, February 3). Oxford Common File Layout. Retrieved March 7, 2022, from https://ocfl.io/0.1/implementation-notes/#empty-directories
Jackson, A. (2010, December 8). Breaking Down The Format Registry. Open Preservation Foundation Blogs. Retrieved March 6, 2022, from https://perma.cc/87S5-A77K
McGath, G. (2013, January 15). The Format Registry Problem. The Code4Lib Journal, (19). https://journal.code4lib.org/articles/8029
Microsoft Compound File – Just Solve the File Format Problem. (2021, September 8). Just Solve the File Format Problem. Retrieved March 7, 2022, from https://web.archive.org/web/20210119190525/https://www.nationalarchives.gov.uk/PRONOM/fmt/754
Murphy, N. (2022, February 16). A Beginner’s Guide to Brunnhilde: Reasons for Using the Brunnhilde Software. Digital Preservation Coalition. Retrieved March 7, 2022, from https://www.dpconline.org/blog/blog-niamh-murphy-brunnhilde-reasons
Naming Files, Paths, and Namespaces – Win32 apps. (2021, January 4). Microsoft Docs. Retrieved March 7, 2022, from https://docs.microsoft.com/en-us/windows/win32/fileio/naming-a-file?redirectedfrom=MSDN
The National Archives, UK. (2018, January 19). digital-preservation/droid-convert. GitHub. Retrieved March 7,
2022, from https://github.com/digital-preservation/droid-convert
National Software Reference Library (NSRL). (2016, April 19). NIST. Retrieved March 7, 2022, from https://www.nist.gov/itl/ssd/software-quality-group/national-software-reference-library-nsrl
OCLC. (2010, May 22). Notice to freeze “info” URI scheme. “info” URI Registry (Frozen). Retrieved March 6, 2022, from https://perma.cc/6EVN-6BC6
Palmer, M. (2010, December 8). nishihatapalmer/byteseek: A Java library for byte pattern matching and
searching. GitHub. Retrieved March 6, 2022, from https://github.com/nishihatapalmer/byteseek
Petrov, P. (2011, May 4). peshkira/c3po: Clever, Crafty Content Profiling of Objects. GitHub. Retrieved March 7, 2022, from https://github.com/peshkira/c3po
Political Papers – Speeches and press releases. (2002-2008). Archives New Zealand. Retrieved March 7, 2022, from https://collections.archives.govt.nz/web/arena/search#/item/aims-archive/22090/political-papers—speeches-and-press-releases
PRONOM changes and DROID signature file release notes. (2022, February 22). The National Archives. Retrieved March 6, 2022, from https://web.archive.org/web/20220306185322/https://www.nationalarchives.gov.uk/aboutapps/pronom/release-notes.xml
PUID for encrypted PDF’s . (2016, November 22). Google Groups. Retrieved March 6, 2022, from
https://web.archive.org/web/20220306190252/https://groups.google.com/g/droid-list/c/OgeJX6oEaAc/m/E01waCKSAwAJ
RFC 8493 – The BagIt File Packaging Format (V1.0) . (2018, October). IETF Tools. Retrieved March 7, 2022, from
https://datatracker.ietf.org/doc/html/rfc8493
richardlehane/siegfried: signature-based file format identification. (2014, February 28). GitHub. Retrieved March 7, 2022, from https://github.com/richardlehane/siegfried
Siegfried. (2021, April 21). COPTR. Retrieved March 6, 2022, from https://coptr.digipres.org/index.php?title=Siegfried&oldid=4106
Spencer, R. (2013, June 14). Generation of a Skeleton Corpus of Digital Objects for the Validation and Evaluation of Format Identification Tools and Signatures. International Journal of Digital Curation, 8(1). https://doi.org/10.2218/ijdc.v8i1.249
Spencer, R. (2015, August 25). Hero or Villain? A Tool to Create a Digital Preservation Rogues Gallery. Open Preservation Foundation Blog. Retrieved March 7, 2022, from https://openpreservation.org/blogs/hero-or-villain-a-tool-to-create-a-digital-preservation-rogues-gallery
Spencer, R. (2017). Binary trees? Automatically identifying the links between born-digital records. Archives and Manuscripts, 45(2), 77-99. 10.1080/01576895.2017.1330158
Spencer, R., Thornton, K., Lehane, R., & Cochrane, E. (2021, October16). Wikidata: A Magic Portal for Siegfried and Roy. iPRES Proceedings 2021. https://osf.io/t8qab/
Walsh, T. (2016, January 9). tw4l/brunnhilde: Siegfried-based characterization tool for directories
and disk images. GitHub. Retrieved March 7, 2022, from https://github.com/tw4l/brunnhilde
Walsh, T. (2022, March 8). Brunnhilde Overview. bitarchivist.net. Retrieved March 8, 2022, from https://www.bitarchivist.net/projects/brunnhilde/
YAML Ain’t Markup Language (YAML™) version 1.2. (2021, October 1). The Official YAML Specification. Retrieved March 7, 2022, from https://yaml.org/spec/1.2.2/
Young, P. (2018, February 15). digital-preservation/freud. GitHub. Retrieved March 7, 2022, from https://github.com/digital-preservation/freud
Footnotes
[1] (DROID on the COPTR Registry, 2021)
[2] (Siegfried on the COPTR Registry, 2021)
[3] (FIDO on the COPTR Registry, 2021)
[4] Introduction to file format registries and describes the importance of PRONOM: (McGath, 2013)
[5] as-is the case with DROID and will be discussed throughout this paper.
[6] A more complete collection of format identification tools is listed on the COPTR registry: (File Format Identification Tools on the COPTR Registry, 2021)
[7] File is just one example outside of the GLAM community.. File uses similar techniques to the others we will describe, and has been around since the 70s through different implementations. File attempts to resolve a file format identification to a descriptive string, so a web-page might be identified by file as: `index.html: HTML document, UTF-8 Unicode text, with very long lines`, rather than, say, fmt/471 (HTML 5.0) in the PRONOM registry. (File (Command) Described on Wikipedia, 2021)
[8] Other tools popular in the GLAM sector, such as JHOVE can assert something about a format’s identification and return a PUID. A key differentiation for the purpose of this paper is the identification coverage with those drawing directly from the PRONOM registry able to identify in upwards of a thousand different formats. PRONOM v102 has over 1600 file formats at time of writing: (PRONOM Release Notes, 2022)
[9] An example of a format description at the feature level: (Microsoft Word Document (Password Protected) 97-2003, 2015) and related thread on the droid-list discussing the use of PRONOM for further “characterisation” like identification: (PUID for Encrypted PDFs Discussion on Google Groups, 2016)
[10] (Brown, 2006)
[11] (OCLC, 2010)
[12] PRONOM has multiple namespaces. For the purpose of this paper, the file format namespace is fmt and x-fmt and the distinction between the two is largely historical. x-fmt records are no longer created, only updated or deprecated, and fmt records are created for new formats.
[13] (Jackson, 2010)
[14] Beyond the scope of this paper, other registries may yet complement PRONOM and enable resolution of a file format identification to a single web-resource that can unambiguously identify a file format. See (Spencer et al., 2021)
[15] (DROID: File Format Identification Tool, 2022)
[16] (Digital-Preservation/droid: DROID (Digital Record and Object
Identification), 2012)
[17] (File Format Registry: New Version Released by the UK National Archives, 2005)
[18] (Palmer, 2010)
[19] (Definition of an Aggregate Format Type From the Library of Congress, 2022)
[20] (Farquhar, 2010)
[21] From both a forensic, and an archival perspective, this asks us to think carefully about how we describe the original order of a collection, which may negate, for a few, some of the positives described around file format identification reports later on in this paper.
[22] (Richardlehane/siegfried: Signature-Based File Format Identification, 2014)
[23] (YAML Ain’t Markup Language (YAML™) Version 1.2, 2021)
[24] “match” is used for convenience where “matches” describes a collection (nested sequence) of format identification results in Siegfried with a relationship of one collection to many potential IDs.
[25] (OLE2 Described on the Just Solve It File Formats Wiki, 2021)
[26] The Rosetta Technical Analyst Workbench is part of the Rosetta Digital Preservation System from ExLibris. Files that demonstrate issues, such as being unidentified, are captured in the workbench for further analysis. Files can be treated in the workbench, or moved into long-term preservation storage. If the problems are understood, exceptions can be created before a digital transfer is made so that known problems with treatments already in progress can be ignored. Publicly available documentation on the technical analyst workbench feature is minimal but it can be observed in various tutorials and videos (ExLibris, 2018)
[27] Moonshine is an example of a utility that can download objects from the UK web archive based on matching four byte sequences using a sparsely documented part of the UK Web Archive’s API: (Exponential Decay/moonshine: Given Four Bytes, Download a Random File From Web Archives Implementing the UKWA Shine Interface, 2018)
[28] See (Library of Congress’ Factors to Consider When Evaluating a Digital Format, 2017)
[29] (Political Papers – Speeches and Press Releases, 2002-2008)
[30] (Demystify, Tool for Static Analysis of Format Identification Reports, 2013)
[31] (Microsoft File Naming Guide, 2021)
[32] For example, proper quoting, and escaping of file path strings in software and scripts that interact with this data.
[33] (RFC 8493 – The BagIt File Packaging Format (V1.0), 2018)
[34] (Description of Empty Directory Handling in the OCFL Specification, 2022)
[35] Bytes in size (less than one kilobyte) may be a good rule of thumb.
[36] (Metadata Features of Different File Systems, 2022)
[37] The DROID user interface for example takes on the form of a table that allows for sorting on different columns. If the checksum column is sorted (labelled ‘Hash’) duplicates will line up underneath each other in alphanumeric order.
[38] It also tells us something about this individual’s habits.
[39] (Spencer, 2017, 77-99)
[40] (PDF/A-1a on PRONOM, 2022)
[41] (Exponential-Decay/sqlitefid: Normalize File Format Identification Results (DROID, Siegfried) Into a Single SQLite DB, 2017)
[42] (Demystify, Tool for Static Analysis of Format Identification Reports, 2013)
[43] The queries are generated from sample data.
[44] (Walsh, 2016)
[45] (Murphy, 2022)
[46] (Archives-New-Zealand/archwayimportgenerator: Code to Create an Archway Import Sheet From DROID CSV + External CSV, 2017)
[47] (Archives-New-Zealand/archives-nz-rosetta-csv-ingest, 2014)
[48] (The National Archives, UK, 2018)
[49] (Petrov, 2011)
[50] (Spencer, 2015)
[51] (Brunnhilde on the COPTR Registry, 2022)
[52] (Walsh, 2022)
[53] (ClamAV About, 2022)
[54] (Bulk-Extractor, 2021)
[55] (Young, 2018)
[56] (Fritz, 2020)
[57] (Information About the NSRL Reference Library, 2016)
[58] (Exponential-Decay/rosetta-Csv-Ingest: Generate a Rosetta CSV Ingest Sheet With Just a DROID Export CSV., 2017)
[59] (Spencer, 2013) provides a description of how to generate mock files simulating many different file formats.
[60] (Clipsham, 2021)
About the Author
Ross Spencer (ORCID: 0000-0002-5144-9794) is a digital preservation specialist for the international games and book publisher, Ravensburger AG in Germany. Ross has been part of the digital preservation community for over a decade and has formerly been a digital preservation analyst and programmer in the teams at The National Archives UK, Archives New Zealand, and Artefactual Systems Inc.
Acknowledgements
This author would like to acknowledge Jan Hutar and Andrea K. Byrne for their friendship, debate, and their persistence and contribution to some of the tools in this paper. To Talei and Anna and the team at Archives New Zealand for refining many of the concepts in demystify. To Joshua Ng for the push to refactor (and name!) demystify and for providing me with the inspiration to talk about it in a modern light. And to Richard Lehane for his patience with the bug reports and the opportunity to work alongside him on Siegfried over these years. Finally, to Sara Amato for their feedback editing this piece for Code4Lib. Thank you all!

Subscribe to comments: For this article | For all articles
Leave a Reply