by Kirsta Stapelfeldt, Sukhvir Khera, Natkeeran Ledchumykanthan, Lara Gomez, Erin Liu, and Sonia Dhaliwal
Introduction
The Digital Scholarship Unit (DSU) at the University of Toronto Scarborough Library provides UTSC-specific support for digital scholarship in the areas of data, the digital humanities, digital collections, digital preservation, and scholarly communications. Frequently, the DSU partners with Faculty and researchers for the creation of public digital scholarship and humanities projects (here referred to as DS projects). The DSU is not unique in recognizing the substantial barriers to the preservation of digital scholarship projects over time, and the ways in which orphaning DS projects is at odds with the library’s overall commitment to preservation and dissemination of the scholarly record (Ridley et al., 2015). Several articles have identified the ways that institutional funding (insufficient to the costs of maintaining DS projects over time) and research funding models (limited in time, and focused on immediate outputs) inhibit adequate maintenance and long-term access to projects (Barats et al., 2020; Drucker, 2021; Edmond and Morselli, 2020; Smithies et al., 2019). Funding agencies may require a research data management plan, but many dimensions of DS work can be lost if these plans do not consider sustainability in the context of the modern web, and the multiple details that must be considered in application development to sustain the project or make it accessible long-term (Smithies et al., 2019). DS projects often focus on access and engagement (often via interactive web application features), and are hosted and developed using personal accounts on third-party services that are easily abandoned. Rationale for why sustainability is overlooked in DS is manifold and well described: beyond the endemic issue of resourcing, there are challenges with resourcing DS teams with the technical skills required within the confines of a given project (Narlock et al., 2021), as well as with the different perspectives of researchers in the humanities/interpretive social sciences and software developers (Barats et al., 2020; Edmond and Morselli, 2020; Poole et al., 2020; Smithies et al., 2019). Broad solutions to these problems have been proposed, including collaborative partnerships between librarians and researchers (King, 2018; Miller, 2017) and advocating for policy framework changes to enable sustaining digital initiatives (Ridley et al., 2015).
On a more technical level, there are various approaches to preserving the legacy of DS projects. Freezing a project is one way to maintain the closest original user experience, however, the drawbacks of this are threefold; lack of maintenance and security, incompatibility over time, and external dependencies (Bingert and Buddenbohm, 2016; Oltmanns et al., 2019). The solution that the DSU is interested in exploring is the use of web archiving and accession of the resulting project files into the institutional digital collections.
Institutional Context
The University of Toronto Scarborough Library is one of the University of Toronto Libraries, and benefits from services managed and resourced for the entirety of the system of 40+ libraries. These resources include an institutional subscription to Archive-It, the Internet Archive’s service, for “collecting and accessing cultural heritage on the web.” In December 2020, the DSU drafted a proposal to gain special access to the University’s Archive-It subscription to experiment with the archiving of select digital scholarship projects. The DSU worked on this project in partnership with emerging and new professionals in library and computer science to provide meaningful learning experiences as well as opportunities to collaborate in interdisciplinary research teams. Once approved, the DSU began piloting the Archive-It service as well as supplementary tools for crawling/recording, playback, and description of web archives for digital scholarship projects.
Technical characteristics of Digital Scholarship Projects
In the DSU’s experience, the context in which web-based DS projects emerge results in a tendency toward certain technical characteristics. DS web applications are typically not developed by a full web development team in permanent roles, but rather with a high level of turnover in project staff. Moreover, the iterative nature of the work usually leads to a lack of clear specifications at the onset of development while the limited time and resources in these projects usually leaves little time for code refactoring. Large portions of a project may be maintained by post-docs or other temporary research staff that leave and take project knowledge with them, making it challenging to work with the specific technologies they leave behind. Web-based DS projects often focus on user interactivity and engagement (usually JavaScript powered), and often use third-party services to achieve mapping/geospatial visualizations and streaming videos, which poses particular challenges for recording and replay. Annotation is another common characteristic in DS projects, with scholars providing additional information to digital collection images, which are sometimes served via an external image server, and in our case, utilizing zoomable images powered by OpenSeadragon (Barnes et al., 2017). Web archiving (referring here to single-time crawls of at-risk DS projects) is a broad and diverse field of policy and praxis that the DSU seeks to apply to this set of challenges in the areas of crawling, replay, indexing and description for web archives.
When a website is ‘crawled’ the target is usually a WARC (Web ARChive) file, which is a format supporting the concatenation of the data that comprises a website into a single file, and is an established international standard. Recently, the draft WACZ (Web Archived Collection Zipped) format specification offers additional tools to extend the richness and functions of web-archives and other configurations of web-based recorded data. There are other formats for web archiving, but the DSU work has focused on WARC as the established international standard. The specific technologies utilized for the creation of these files can be limited in the content and interactivity they can capture. For example, unindexed or so-called “deep” content is not easily captured (Sharma and Sharma, 2018), and neither is content that relies on user interactivity (via things like mouse clicks) to expose (Brunelle et al., 2016). Robots.txt and other technologies declare the preferences of site builders for crawling, indexing, and the timing of requests. In combination with the structures of a site, this can affect the ability to crawl effectively (Archive-It Team [updated 2021]). Content with HTML that references external services or that requires external API calls will continue to rely on the existence of these services. This can make it difficult to verify the existence of all the files required to manage successful replay of a website. In replay, if these services change so that the HTML no longer can call the service, this element of the web application will no longer be available in the replayed WARC. Players also require that specific technologies remain available in the browser, if an object is to be ‘played’ back in a browser. The recent end of life for the Adobe Flash player, for example, and the slow removal of flash support from browser technology has provided new challenges for replaying content on the web that utilized this technology. In short, it can be difficult to determine what has actually been ‘preserved’ and what remains reliant on external services that may disappear in future, and what has been captured may not remain playable in the long term if browser support for the crawled files disappears. These factors combine to reflect the “archivability” of the site, which Stanford Libraries defines as “the ease with which the content, structure, functionality, and front-end presentation(s) of a website can be preserved and later re-presented, using contemporary web archiving tools” (Archivability, n.d.). Finally, there are metadata challenges for the resulting web archives. While most crawlers generate substantive automatic technical and administrative metadata, descriptive metadata must be produced by a human being with sufficient context of the original project to allow for the discovery and citation of the archive. The lack of consistent application and development of descriptive metadata standards is well recognized in the web archiving community (Dooley and Bowers, 2018) and there have been attempts to address this via standards development (Dooley and Bowers, 2018).
Crawling and Recording Digital Scholarship Projects
The International Internet Preservation Consortium provides an entrance into the numerous tools used for acquisition (crawling/recording) of websites. A separate initiative (Data Together) maintains a substantial list of Web Archiving software that compares major features, although this appears to have been last updated in 2018. In the early attempts to archive DS projects, the DSU utilized Conifer and Webrecorder Desktop (which also has a browser extension), and Archiveweb.page, in addition to the technologies provided by Archive-It: Heritrix, Umbra, and Brozzler. An overview and comparison of the major characteristics is provided in Table 1.
Table 1. Table of tested Crawling Technologies.
| Crawling Technology | Notes |
| Conifer | Online service based on Webrecorder, relies on a user manually playing all interactions for recording. |
| Webrecorder Desktop | Relies on a user manually playing all interactions, which reveals content to the crawler for capture. |
| Archiveweb.page | The ArchiveWeb.page chrome extension is part of the Webrecorder project, which develops multiple open-source tools for web recording and replay. |
| Archive-It’s “Standard” (Heritrix and Umbra) | Archive-It’s standard crawling technology is a combination of Heritrix (used for 20 years for web archiving), extended by Umbra, a technology that allows for dynamically rendered sites (increasingly the internet standard) to be viewed and crawled by Heritrix. |
| Archive-It’s Brozzler crawler | Archive-It’s most modern crawling technology, Brozzler does not follow hyperlinks, but rather records interactions between a browser and website and allows for the download of things like linked video content, zooming images and game elements of a website. |
Overall, Archive-It’s crawlers provided more automated in-depth crawls (in which more web pages were captured with less work required from an end user) than Conifer, Webrecorder Desktop, and ArchiveWeb.page, and Archive-it has a substantial user community and tools for quality assurance. However, all of the non Archive-It tools were useful in generating complete web archiving files. ArchiveWeb.page was the most successful (more successful than Archive-it technologies) in capturing and storing embedded media, resulting in a truer site archive.
Replaying Digital Scholarship Projects
The DSU has also explored replaying web archives for DS projects. The Archive-It service’s Wayback machine is provided by default with an Archive-It service subscription, and plays back WARC files that are produced through the service or that are uploaded into the system. However, the addition of code for the Wayback player can occasionally block the functionality of a page on replay. To circumvent this, a user can place an ID flag to load the archive without the additional Wayback code. To supplement access to web archives provided by the Archive-It subscription, the DSU also seeks to keep recorded files in the local digital collections and make them available as part of the digital collections (an earlier version of Islandora software supported storage of WARCs via the Web Archive Solution Pack, but had no native playback functionality). To support replay in our new system (also based on Islandora) we are targeting an integration with the Webrecorder project, which provides several open source tools and packages for recording and replay, including the ReplayWeb.page viewer, a serverless (client-side) web archive replay tool viewer supporting additional formats beyond WARCs. When looking for existing integration projects with Drupal, Lara Gomez found an example of viewer integration in Archipelago’s “Strawberry field” modules. Archipelago, developed under the auspices of non-profit service provider “Metro” is also an open-source digital asset management project that, like Islandora, uses the content management system Drupal. Based on the work in Archipelago, Lara was able to create a Drupal module providing this integration more generally for Drupal users.
The resulting ReplayWeb.page player module provides a field formatter that can take a Drupal media field storing a compliant file format (i.e WACZ, WARC) and play it using ReplayWeb.page within the Drupal/Islandora site (see Figure 1 for how this looks in an interface and Figure 2 for an edit page that shows the options available for site editors). ReplayWeb.page relies on a service worker, and requires an SSL (https) certificate to work. The main advantage of the ReplayWeb.page is that it does not require a server side application such as Webrecorder pywb to replay the web archive.
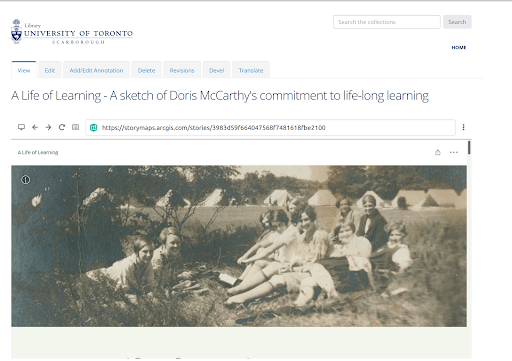
Figure 1. Storymap WACZ file replay in Dupal/Islandora integrated with ReplayWeb.page.
WACZ files can be created from WARC files using py-wacz. Further, ArchiveWeb.page supports the downloading of archives it creates as WACZ. In the DSU’s experience, the WACZ file format provides a much faster replay experience. For example, a 100 MB WARC file can take 2 – 3 minutes to load, while the same size WACZ file takes only a few seconds to begin to play. The WACZ format allows web archive collections to be loaded incrementally as the user replays in the browser, substantially improving the experience for end users.
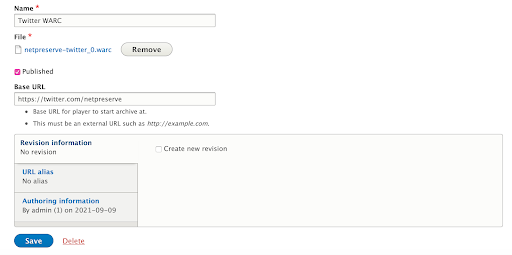
Figure 2. End users can specify which URL in the web capture should be loaded by default in the viewer based on an uploaded file (Here, netpreserve-twitter_0.warc).
Metadata and Discovery
The DSU provides access to its completed captures immediately through Archive-It’s public portal. Collection-specific portals provide a way of pointing users to a specific set of web archives that have been grouped together through Archive-It’s partner interface (see Figure 3). The Wayback machine’s calendar-based interface supports multiple crawls of a single domain, with long-term continuous web preservation in mind.
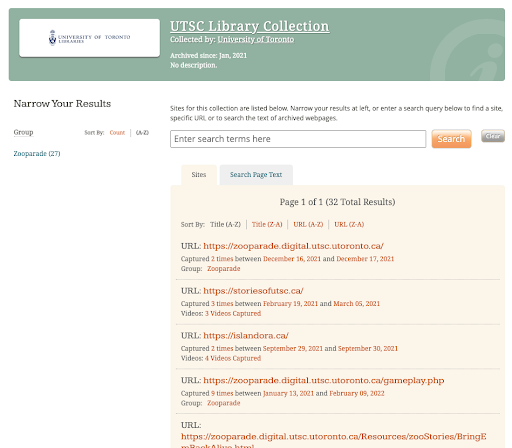
Figure 3. Captured WARC files accessible through the Archive-It public portal.
Metadata can be added at the “seed” level and can be bulk uploaded. Metadata fields are based on Dublin Core, with the ability to add custom metadata fields (see Figure 4). Files can also be downloaded from Archive-It for offsite storage or, in the case of the DSU, supplementary preservation workflows and alternative display and discovery. The DSU has been exploring downloading these files and loading them into test digital collections. The DSU uses standard and extended metadata profiles based on MODS version 3.4 in compliance with the DLF/Aquifer Implementation Guidelines for Shareable MODS Records. By downloading and accessioning the WARCs into our local system, DSU staff take advantage of the familiar collections management approaches, metadata and discovery, with which other collections are authored and maintained, with advantages such as extended metadata support and customizable themes.
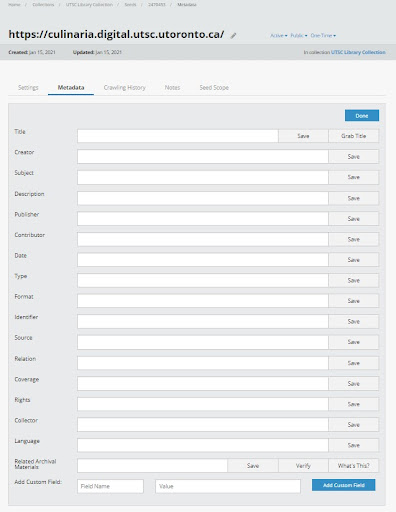
Figure 4. Archive-It’s partner interface. Users can add metadata to captured sites.
Sukhvir Khera provided a mapping for both our local metadata profile and Archive-It’s metadata profile to the “Descriptive Metadata for Web Archiving” recommendations developed by the OCLC Research Library Partnership’s Web Archiving Metadata Working Group (WAM). The goal would be to cover the recommendations in both systems, with the ability to add additional information and link resources in our local collections, preserving digital projects developed in collaboration with UTSC students and Faculty. In Islandora 7.x, stored WARCs could be fully indexed using the Web Archive Solution Pack, which provides Solr 4+ integration, and this could be a useful approach for providing better content indexing for these file types in our local digital collections.
Digital Scholarship Project Preservation: Use Cases
The following section outlines specific cases of DS projects and the extent to which playable WARCs could be generated, based on the specific technical characteristics of the application and the applied toolset.
Preserving Gaming Functionality
A virtual version of the Marlin Perkins board game was developed in 2014-2015 by students in the DSU as an entryway into a digitized collection of Zoo ephemera preserved at the library. The (largely JavaScript) application provided dynamic, user-driven gameplay. The browser-based game also contained Flash content. During gameplay, end users would interact in order to produce 25 static HTML web pages. This type of web application, presenting mixed content requiring human interaction is a recognized challenge for web archiving (Lohndorf [updated 2022]; Frequently asked questions, n.d.; Archivability, n.d.).
Crawlers compared for the capture of the “Zoo Parade” game were Conifer, Webrecorder Desktop, and Archive-It’s Brozzler crawler. Conifer was unable to capture the flash elements of the gameplay page, and captured only the preliminary static HTML pages (see Figure 5). In comparison, the capture made with Webrecorder Desktop captured a screenshot of the gameplay page, as well as the preliminary HTML pages. Archive-It’s Brozzler crawler, using the ‘ignore robots.txt’ rule and seeds for all 25 HTML pages produced a reasonable facsimile of the original game (see Figure 5 and 6).
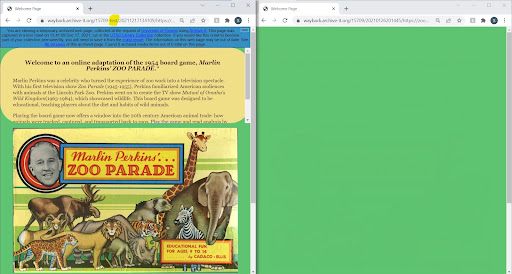
Figure 5. Comparison of captures: Brozzler (left) and Conifer (right).
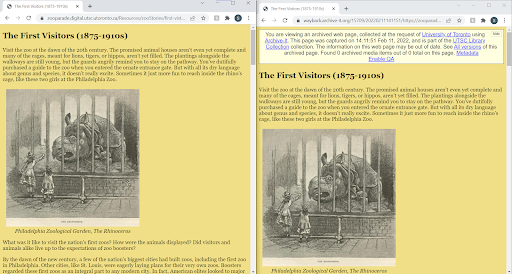
Figure 6. Comparison of live web page (left) and Brozzler capture (right).
End users are not able to play the game through the capture, but they are able to view the static (HTML) resources to get an understanding of gameplay and can still play the game on the live site.
Preserving Web Mapping Projects
The Mapping “Scarborough Chinatown” project mapped popular 20th century malls as a way for users to browse images of historical Scarborough restaurants and supplementary research materials. The project used Drupal’s Leaflet plugin. Mapping software like Leaflet and ArcGIS contain large amounts of custom JavaScript, making it difficult not only to capture maps with various crawling technology, but also to replay in Wayback (Rollason-Cass [updated 2021]; Using The Wayback Machine [updated 2021]).
Conifer, Standard (Heritrix and Umbra) and Brozzler were compared for the capture and Wayback replay of the Leaflet map. All these crawling technologies had difficulty capturing the content inside the pop-up bubbles in the embedded map, requiring moderate modifications to the page so that URLs could be more easily captured. Archive-It’s “Standard” crawlers captured some static elements of the site consisting of text files and a few image files, while Brozzler captured the page more comprehensively, including JavaScript files. By using Developer Tools to review captures in Wayback, Sukhvir determined that while Archive-It’s crawlers were able to capture different elements of the site they were unable to capture and replay the interactive Leaflet map (see Figure 7).

Figure 7. Thumbnail image captured by Archive-It’s “Standard” crawler.
In contrast, Conifer was successful in capturing many elements that make up the Leaflet map (see Figure 8).
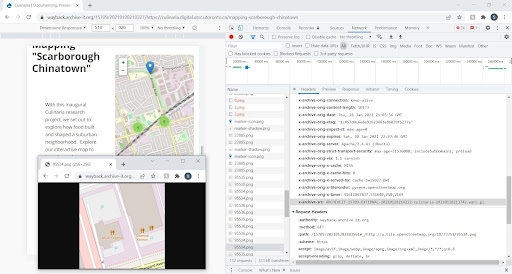
Figure 8. Leaflet map captured by Conifer and uploaded to Archive-It for playback in Wayback.
Although it is difficult to measure how complete the Conifer capture of the Leaflet map is, Sukhvir was able to determine that many of its elements (i.e. small images that make up the ‘internal zoom on click’ functionality of the map, icon markers, symbols and thumbnail images) were captured. It can be difficult to determine what file(s) are powering replay in Archive-It, which uses an index called the Wayback CDX/CI to provide the best matched capture of a given URL and timestamp across multiple WARCs. When a Conifer crawl was uploaded into Archive-It, it was indexed and a more complete capture was playable via the Archive-It web interface (see Figure 9).
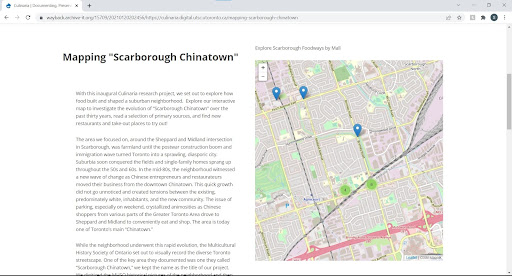
Figure 9. Wayback replay of the interactive Leaflet map.
Preserving Externally Hosted Media
An Esri Storymap was created in 2021 about artist Doris McCarthy (1910-2010) and embedded into the web-based repository containing her digitized papers and artwork. In addition to challenges with the underlying map (as discussed above), the Storymap also used embedded images drawn directly from the underlying repository (Islandora) as well as embedded content from a third-party video streaming service (in this case, Vimeo). There were also a number of structural issues in the Storymap that could have resulted in infinite crawls of non-relevant content (crawler traps), and time-limits and redirects in the site architecture that complicated crawling. Archive-It’s Standard (Heretrix) crawler, their Brozzler crawler, and ArchiveWeb.page were all tested for capturing the site. To assess the completeness of the crawl, the individual captures were compared in the Wayback player and the ReplayWeb.page player.
In the Wayback player, wayback URL flags (see Figure 10) revealed that the video was not captured by Archive-it.
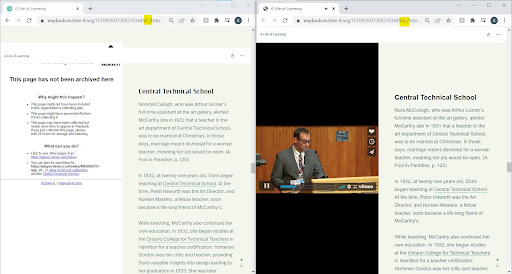
Figure 10. Comparison of video replay in Wayback: Identity flag (left) and Iframe flag (right).
The lack of archived video content in the capture was further verified by the crawl’s “file type report,” a native tool in Archive-It provided to assess the completeness of crawls (Figure 11).
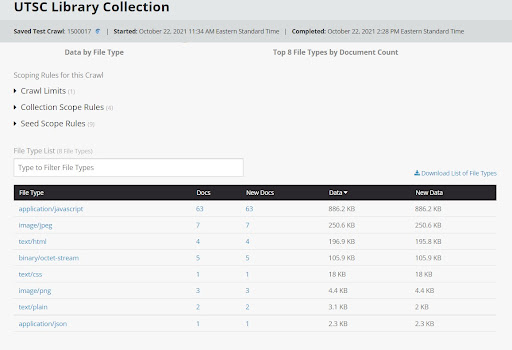
Figure 11. Storymap crawl’s file type report included no media.
The file type report provides a breakdown listing all of the content (documents or URLs) captured by file types, which can be reviewed in-depth by clicking on each hyper-linked file type (see Figure 12).
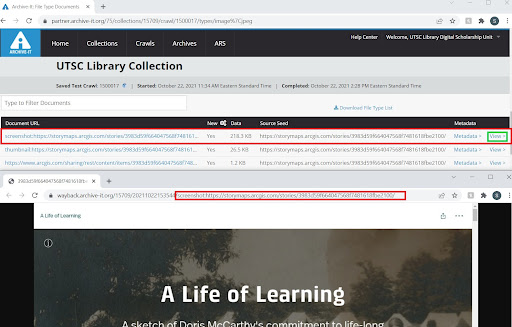
Figure 12. Storymap crawl’s file type report allows each image file to be viewed individually.
There are no video file types listed in the report, confirming that the Vimeo Video has not been captured as part of the recording, and so, if the file is removed from Vimeo, the content will be lost. This was also obvious when the WARC file from Archive-It was loaded into the ReplayWeb.page viewer.
The ArchiveWeb.page crawl was assessed in the ReplayWeb.page viewer using Firefox’s web developer tools. The Network tab of Developer Tools in most modern browsers will reveal the sources of image and video files on the web page (see Figure 13).
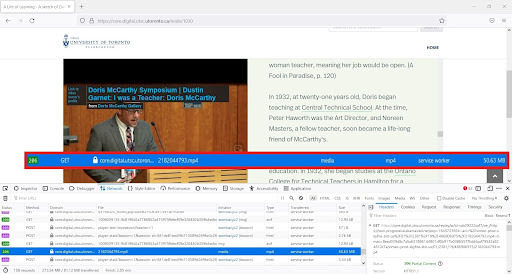
Figure 13. Developer tools: Network tab review of Wayback replay of the Storymap crawl.
Using this tool for Firefox, it is possible to see that the mp4 file hosted on Vimeo was captured in the ArchiveWeb.page recording, making this a much stronger capture that does not rely on the continued hosting of the file by Vimeo. The resulting file played well in the Drupal integration with ReplayWeb.page (see Figure 14).
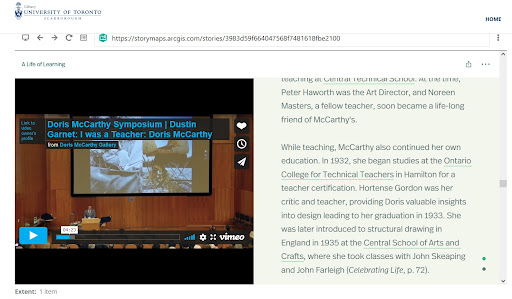
Figure 14. Storymap WACZ file includes embedded Vimeo video, playable in Firefox browser.
Therefore, while Brozzler’s capture was an improvement over Archive-It’s Standard crawler, the most complete archive was achieved by ArchiveWeb.page. One remaining limitation is that the embedded Vimeo video is only playable in the Firefox browser, which permits a broader range of MIME types than Chrome and Safari at the time of writing.
A note on Quality Assurance when crawling dynamic JavaScript content
The challenges of preserving JavaScript have been recognized for the past decade (Brunelle et al., 2016; Leetaru, 2017; Boss and Broussard, 2017; Using the Wayback Machine [updated 2021]; Lohndorf [updated 2022]). Wayback replay software adds another layer of complexity to this challenge as it provides playback of captures that interact with the live web, providing the sense that material has been archived when it is still reliant on live web resources. By relying on Wayback, it can be difficult for a user to decipher what content has been captured, how complete the capture is, and what embedded media files might be loading from the live web (see Figure 15).

Figure 15. Storymap dynamic image playback comparisons: Identity flag (left) and Iframe flag (right). Both show an image that has been loaded from the open web. This same image fails to load in ReplayWeb.page.
Archive-It’s crawl reports are a more reliable source to review captures for their completeness. Particularly, the “File Type” reports and Developer Tools have been key to verifying what content has been captured. For example, to determine whether dynamic images with internal zoom on click functionality were captured for the Storymap crawl, a review of the file type report revealed that only the smaller images were captured. Webrecorder’s ReplayWeb.page replay technology has been useful for reviewing quality assurance as well. When downloading WARC files for testing in the ReplayWeb.page player, the difference between captured data and data that rely on the open web becomes more obvious (see Figure 16).

Figure 16. Storymap dynamic image playback in ReplayWeb.page: successfully playing data that has been captured (text file on the right) and failing to load an image from the open web (image file on the left).
Preserving Images served via an Image Server
The Harlot’s Progress in Context (HPIC) was created in 2015 to support student-assignments about the work of William Hogarth (1697-1764). Images were displayed in the Open Seadragon viewer for Islandora, using the Islandora Web Annotations Solution Pack (Barnes et al., 2017). The zooming functionality of the OpenSeadragon viewer and the JavaScript-powered pop-up annotations were both captured and playable using Archive-It’s Standard (Heritrix) crawler (see Figures 17 and 18 for depictions of the captured, annotated images).
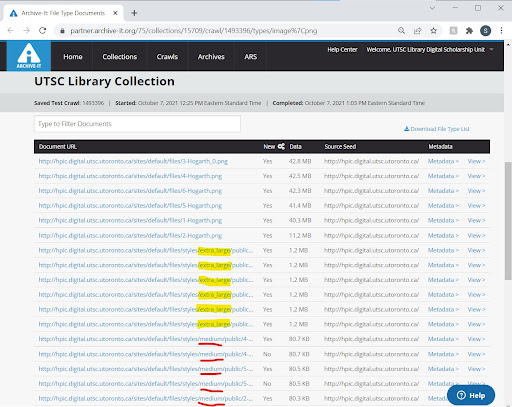
Figure 17. HPIC crawl’s file types report shows that images at multiple sizes have been captured (Extra-large images captured are highlighted in yellow. Medium-sized images captured are underlined in red.)
Archive-It’s Standard (Heritrix) crawler alone captured this site in a one-time test crawl. The successful capture and replay of this crawl reflect a high level of archivability in this site, making this design one that should be replicated in future projects. In the case of the HPIC project, the images (both extra-large and medium sized versions), and annotations were all captured with relative ease (see Figure 17). Furthermore, presenting the annotations as static text in the page, as well as through on-click pop-ups, they were more easily captured for replay (see Figure 18). In addition, the type of zooming functionality provided by Open Seadragon (click-to-enlarge), facilitated the capture of the larger version of images by directing the Heritrix crawler to these specific images through the provision of standard links in HTML format (Guidelines for preservable websites, n.d.).
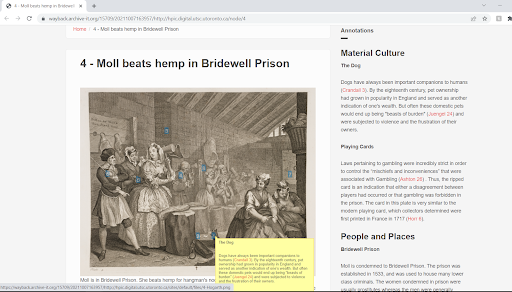
Figure 18. Annotated image beside text panel of annotations playable in Wayback.
Conclusions and Future Directions
Archive-It provides a comprehensive suite for the capture and replay of webpages, including DS projects. The system is designed for Archivists to capture repeating crawls as web pages change, rather than single crawls for capture of an at-risk DS project, and so one-time crawls may represent something of an ‘off-brand’ use of the service. Crawls taken through Archive-It can also be downloaded for use in local digital collection systems. External recorders such as Conifer, Webrecorder, and ArchiveWeb.page also perform well, and have been successful at mitigating gaps in Archive-It’s crawling capabilities (particularly ArchiveWeb.page, which exceeded the performance of all other crawlers when capturing externally hosted media).
Despite the occasionally daunting complexity of web archiving, existing technologies do facilitate recording and preserving elements of DS projects in risk of being lost to technological obsolescence. However, the pilot revealed ongoing challenges with the long-term preservation of embedded and dynamic content that remain unresolved at time of writing. Despite ongoing challenges, the DSU concludes that preserving a playable WARC provides benefits over maintaining a full application stack with better durability.
We also concluded that archiving DS projects is potentially very resource intensive. Producing a capture requires manual playing of site functionality and checking for quality, and while richer descriptive metadata is always preferred, its production takes time and attention. As with all digital objects, WARCs and WACZ will also require ongoing maintenance to ensure preservation and access. The comparative costs in time and accessibility for WARCs vis a vis other digital objects for the DSU remains to be seen.
This web crawling pilot has inspired the DSU to consider archivability earlier in DS projects, following a trend identifiable in literature about web archiving (Leetaru, 2017; Brunelle et al., 2016; Archivability, n.d.; Creating preservable websites, n.d.). In future, the DSU will explore how archivability intersects with compliance to the Web Content Accessibility Guidelines (WCAG) and responsive web development (for low bandwidth and mobile first populations) in service of universal design.
Bibliography
Archivability [Internet]. n.d. San Francisco (CA): Stanford Libraries; [cited 2022 Feb 17]. Available from: https://library.stanford.edu/projects/web-archiving/archivability
Archive-It Team. [updated 2021 Sep 8]. A new wayback: Improving web archive replay [Internet]. San Francisco (CA): Archive-It Blog. [cited 2022 Feb 23]. Available from: https://archive-it.org/blog/post/archive-it-wayback-release/
Archive-It Team. [updated 2022 Feb 17]. Archive-It system status [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/360019259671-Archive-It-System-Status
Barats C, Shafer V, Fickers A. 2020. Fading away … the challenge of sustainability in digital studies. Digital Humanities Quarterly [Internet]. [cited 2022 Feb 23]; 14(3):1-17. Available from: http://www.digitalhumanities.org/dhq/vol/14/3/000484/000484.html
Barnes ME, Ledchumykanthan N, Pham K, Stapelfeldt K. 2017. Annotation-based enrichment of Digital Objects using open-source frameworks. Code4Lib Journal [Internet]. [cited 2022 Mar 4]; (37). Available from: https://journal.code4lib.org/articles/12582
Bingert S, Buddenbohm S. 2016. Research data centre services for complex software environments in the humanities. Information Services & Use [Internet]. [cited 2022 Feb 23]; 36(3-4):189-202. Proceedings of the 20th International Conference on Electronic Publishing Positioning and Power in Academic Publishing: Players, Agents and Agendas; 2016 Jun 7-9; Göttingen. Available from: https://doi.org/10.3233/ISU-160817
Blumenthal K-R. [updated 2020]. Archive-It 7.0 release notes [Internet]. San Francisco (CA): Archive-It Help Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/360039653811-Archive-It-7-0-Release-Notes#Wayback
Blumenthal K-R. [updated 2021 May]. Archive-It APIs and integrations [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/360001231286-Archive-It-APIs-and-integrations
Blumenthal K-R. [updated 2022 Jan]. Quality assurance overview [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/208333833-Quality-Assurance-Overview
Boss K, Broussard M. 2017. Challenges of archiving and preserving born-digital news applications. IFLA Journal [Internet]. [cited 2022 Feb 23]; 43(2):150-157. Available from: https://doi.org/10.1177/0340035216686355
Brunelle JF, Kelly M, Weigle MC, Nelson ML. 2016. The impact of JavaScript on archivability. International Journal on Digital Libraries [Internet]. [cited 2022 Feb 23]; 17:95-117. Available from: https://doi.org/10.1007/s00799-015-0140-8
Cobourn AB. 2017. Case Study: Washington and Lee’s first year using Archive-It. Journal of Western Archives [Internet]. [cited 2022 Feb 23]; 8(2):1-13. Available from: https://doi.org/10.26077/f2bf-4185
Creating preservable websites [Internet]. n.d. Washington (DC): Library of Congress. [cited 2022 Feb 17]. Available from: https://www.loc.gov/programs/web-archiving/for-site-owners/creating-preservable-websites/
Data together research: Web archiving [Internet]. [updated 2018 Sep 17]. Data Together; [cited 2022 Feb 23]. Available from: https://github.com/datatogether/research
Dooley J, Bowers K. Descriptive metadata for web archiving [Internet]. Dublin (OH): OCLC Research; 2018 [cited 2022 Feb 23]. Available from: https://www.oclc.org/research/publications/2018/oclcresearch-descriptive-metadata.html
Drucker J. 2021. Sustainability and complexity: Knowledge and authority in the digital humanities. Digital Scholarship in the Humanities [Internet]. [cited 2022 Feb 23]; 36(Supplement_2):ii86-ii94. Available from: https://academic.oup.com/dsh/article/36/Supplement_2/ii86/6205948?login=true
Edmond J, Morselli F. 2020. Sustainability of digital humanities projects as a publication and documentation challenge. Journal of Documentation [Internet]. [cited 2022 Feb 23]; 76(5):1019-1031. Available from: https://doi.org/10.1108/JD-12-2019-0232
Frequently asked Questions [Internet]. n.d. San Francisco (CA): Stanford Libraries; [cited 2022 Feb 17]. Available from: https://library.stanford.edu/projects/web-archiving/frequently-asked-questions
Guidelines for preservable websites [Internet]. n.d. New York (NY): Columbia University Libraries; [cited 2022 Feb 17]. Available from: https://library.columbia.edu/collections/web-archives/guidelines.html
King M. 2018. Digital scholarship librarian: what skills and competences are needed to be a collaborative librarian. International Information & Library Review [Internet]. [cited 2022 Feb 23]; 50(1):40-46. Available from https://doi.org/10.1080/10572317.2017.1422898
Leetaru K. 2017. Are web archives failing the modern web: Video, social Media, dynamic pages and the mobile web [Internet]. New York (NY): Forbes Magazine; [cited 2022 Feb 22]. Available from https://www.forbes.com/sites/kalevleetaru/2017/02/24/are-web-archives-failing-the-modern-web-video-social-media-dynamic-pages-and-the-mobile-web/?sh=3b2d652b45b1
Lewis V, Spiro L, Wang X, Cawthorne JE. Building expertise to support digital scholarship: A global perspective [Internet]. Washington (DC): Council on Library and Information Resources; 2015 [cited 2022 Feb 23]. Available from: https://www.clir.org/pubs/reports/pub168/
Lohndorf J. [updated 2021]. Archive-It crawling technology [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/115001081186-Archive-It-Crawling-Technology
Lohndorf J. [updated 2022 Feb 17]. Known web archiving challenges [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/209637043-Known-Web-Archiving-Challenges
Maemura E. 2018. What’s cached is prologue: Reviewing recent web archives research towards supporting scholarly use. In: Freund L., editors. Proceedings of the Association for Information Science and Technology. Hoboken (NJ): Wiley. p. 327-336. Available from: https://doi.org/10.1002/pra2.2018.14505501036
Miller A. 2017. A case study in institutional repository content curation: A collaborative partner approach to preserving and sustaining digital scholarship. Digital Library Perspectives [Internet]. [cited 2022 Feb 23]; 33(1): 63-76. Available from https://doi.org/10.1108/DLP-07-2016-0026
Narlock M, Johnson D, Vecchio J. 2021. Digital preservation services at digital scholarship centers. Journal of Academic Librarianship [Internet]. [cited 2022 Feb 23]; 47(3):102334. Available from https://doi.org/10.1016/j.acalib.2021.102334
Oltmanns E, Hasler T, Peters-Kottig W, Kuper H-G. 2019. Different preservation levels: the case of scholarly digital editions. Data Science Journal [Internet]. [cited 2022 Feb 23]; 18(1):51. Available from http://doi.org/10.5334/dsj-2019-051
Poole AH, Garwood DA. 2020. Digging into data management in public?funded, international research in digital humanities. Journal of the Association for Information Science and Technology [Internet]. [cited 2022 Feb 23]; 71(1):84-97. Available from: https://doi.org/10.1002/asi.24213
Ridley M, Appavoo C, Pagotto S. 2015. Seeing the forest and the trees: the integrated digital scholarship ecosystem (IDSE) project of the Canadian Research Knowledge Network (CRKN). Proceedings of the ACRL 2015 Conference; 2015 Mar 25-28; Portland: American Library Association. p. 676-682. Available from: https://www.ala.org/acrl/sites/ala.org.acrl/files/content/conferences/confsandpreconfs/2015/Ridley_Appavoo_Pagotto.pdf
Rollason-Cass S. [updated 2021]. Archiving ArcGIS [Internet]. San Francisco (CA): Archive-It Support Center; [cited 2022 Feb 23]. Available from: https://support.archive-it.org/hc/en-us/articles/360051604431-Archiving-ArcGIS
Sharma DK, Sharma AK. 2018. Deep web information retrieval process: A technical survey. In: The Dark Web: Breakthroughs in Research and Practice [Internet]. [cited 2022 Feb 23]. Available from: https://doi-org.myaccess.library.utoronto.ca/10.4018/978-1-5225-3163-0
Smithies J, Westling C, Sichani A-M, Mellen P, Ciula A. 2019. Managing 100 digital humanities projects: Digital scholarship and archiving in King’s Digital Lab. Digital Humanities Quarterly [Internet]. [cited 2022 Feb 23]; 13(1):1-16. Available from: http://www.digitalhumanities.org/dhq/vol/13/1/000411/000411.html
Usability & Web Accessibility [Internet]. n.d. New Haven (CT): Yale University; [cited 2022 Mar 3]. Available from: https://usability.yale.edu/web-accessibility/articles/images
Using The Wayback Machine [Internet]. [updated 2021]. San Francisco (CA): Internet Archive; [cited 2022 Feb 23]. Available from: https://help.archive.org/hc/en-us/articles/360004651732-Using-The-Wayback-Machine
About the Authors
Kirsta Stapelfeldt is a librarian and the Head of the Digital Scholarship Unit at the University of Toronto Scarborough Library.
Sukhvir Khera is an Emerging Professional in Digital Scholarship in the Digital Scholarship Unit at the University of Toronto Scarborough Library.
Natkeeran Ledchumykanthan is an Application Programmer of the Digital Scholarship Unit at the University of Toronto Scarborough Library.
Lara Gomez is a current computer science student at the University of Toronto Scarborough in the Software Engineering stream, and has completed two terms with the Library as an Emerging Professional in Application Development.
Erin Liu is an Assistant Archivist at the University of Arts London Archives and Special Collections Centre. She was an Emerging Professional in Digital Scholarship at the University of Toronto Scarborough Library Digital Scholarship Unit between 2020 and 2021.
Sonia Dhaliwal is the Data & Digital Collections Librarian in the Digital Scholarship Unit at the University of Toronto Scarborough Library.

Subscribe to comments: For this article | For all articles
Leave a Reply