By Arun F. Adrakatti and K.R. Mulla
Introduction
E-lecturing has become increasingly popular over the past decade. There is an exponential increase in the amount of lecture video data being posted on the internet. Many universities and research institutions are recording their lectures and publishing them online for students to access independently of time and location. In addition, there are numerous Massive Open Online Courses (MOOCs) that are popular across the globe for their ability to provide online lectures in a wide variety of fields. The availability of online courses and ease of access has made them a popular learning tool. Lecture videos and MOOCs are hosted on cloud platforms to make them available to registered users. Most of these resources are for the benefit of the public. The majority of lecture videos are available on popular video-sharing platforms such as YouTube, Vimeo, and Dailymotion. Due to a shortage of storage servers and internet bandwidth, academic and research institutions are having difficulty maintaining video repositories.
There are a great number of lecture videos uploaded to online platforms that are annotated only with a few keywords, which results in the search engine returning incomplete results. There are only a limited number of keywords available to access lectures and the search can be conducted primarily using their occurrences or tags. Videos are retrieved solely based on their metadata, such as their title, author information, and annotations, or by user navigation from generic to specific topics. Users can fetch the materials only based on limited options. Irrelevant and random annotations, navigation, and manual annotations made without considering the video contents are the major stumbling blocks to retrieving lecture videos.
Existing approaches and proposed models
The fast development of video data has made efficient video indexing and retrieval technologies one of the most essential concerns in multimedia management.[1]
Bolettieri et al. (2007) proposed a system based on MILOS, a general-purpose Multimedia Content Management System that was developed to aid in the design and implementation of digital library applications.[2] The goal is to show how digital information, such as video documents or PowerPoint presentations, may be reused by utilizing existing technologies for automatic metadata extraction, including OCR, speech recognition, cut detection, and MPEG-7 visual Video Retrieval (CBVR).
Yang et al. (2011) provided a method for automated lecture video indexing based on video OCR technology, built a new video segmenter for automated slide video structure analysis and implemented a new algorithm for slide structure analysis and extraction based on the geometrical information of identified text lines.[3]
An approach for automated video indexing and video search in huge lecture video archives has been developed.[4] By using video Optical Character Recognition (OCR) technology on key-frames and Automatic Speech Recognition (ASR) on lecture audio files, automatic video segmentation and key-frame identification can provide a visual guideline for video content navigation and textual metadata. For keyword extraction, both video- and segment-level keywords are recovered for content-based video browsing and search using OCR and ASR transcripts as well as identified slide text.
The authors developed and proposed text to speech extraction from videos and text extracted from OCR from the slide used while delivering the lecture videos. Most of these proposed ideas and developed concepts are in commercial platforms which the academic and research institutions are not in a position to be able to afford.
Motivation for the Project
In the Indian scenario, the vast majority of lecture video repositories and MOOCs are hosted on the YouTube platform and the web links are embedded in content management systems (CMS) and e-learning applications. Typically, these applications only search for metadata and human annotations associated with specific videos. Some applications lack search engines, and the SWAYAM (Study Webs of Active-Learning for Young Aspiring Minds) platform is the best example of this. The user needs to browse the videos according to the subject on this platform. A commercial video lecture application focuses only on recording and organizing video lectures based on their subject and topics. The retrieval of videos from repositories is the least concern and applications neglect user concerns. The users do not find the desired information on the lecture video repositories and invest lots of time in browsing and listening to the videos to gain information.
The popular open source institutional repositories systems are limited to maintaining only document and image files. The retrieval is restricted to metadata and human annotations. These limitations and restrictions led to the design and development of the Educational Lecture Archive with more focus on the retrieval of the videos based on the content from these videos.
Development of Content-Based Video Retrieval System
The capture of e-lecturing has become more popular and the amount of lecture video data on the web is growing rapidly. Universities and research institutions are recording their lectures and publishing them online for students to access independent of time and location. On the other side, users find it difficult to search for the desired information from these video repositories. To overcome this issue, the application is designed and developed to organize the education lecture videos through the practical approach of searching videos based on the entire speech contained in the video. The application is named CBMIR (Content-Based Multimedia Information Retrieval).
The scope of CBMIR covers only educational lecture video repositories maintained and hosted by universities, R&D, and nonprofit organizations of India and is limited to speech extraction and automatic text indexing of lecture videos available in the English language.
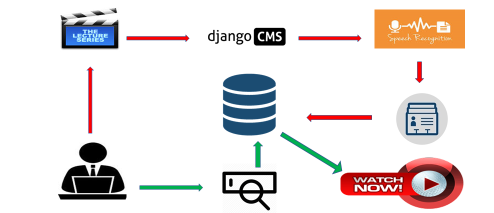
Figure 1. Overview of the CBMIR application.
Technical Requirement
- Linux based OS – Ubuntu
- Django – Content Management System: Python-based web framework.
- Python – Programming language
- Anaconda – Python distribution
- Whoosh Library: Whoosh is a fast, full text, Python search engine library.
The CBMIR application has three major modules: the administrator, information processing & retrieval, and user platform. Figure 2 shows a detailed workflow process for an administrator uploading video into repositories to a user retrieving the desired videos from repositories.
Flow Chart
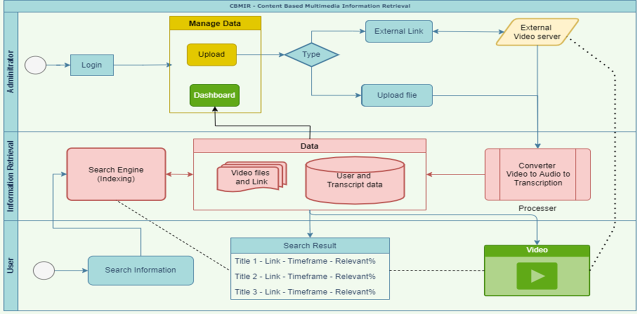
Figure 2. Flow Chart of the Content-Based Multimedia Information Retrieval.
Modules of CBMIR Applications
Administrator Module
The Administrator module allows the admin to upload the external video using hosted weblinks, and to upload the video file from a personal device or external storage device. Figure 3 shows the dashboard of the Administrator module. The authorized admin will have access to the application to manage and upload the data. The admin can view / edit / delete the videos uploaded using the option to manage the content library. The admin can add a new user and assign a limited admin role to distribute the workload of uploading the content in cases when they are creating large educational repositories. The admin was given the privilege to add / edit / delete the text of transcript uploaded into the database.

Figure 3. Dashboard of Administrator Module.
Information Retrieval Processing Module
The following are the step-by-step processes for the information processing and storage of videos with the CBMIR application. Figure 4 shows the status bar of the work process after uploading the external video link into the CBMIR application.
- Uploading videos
- Download the video from external source: video will be downloaded to the application server from an external server or from the device using YouTube API to access the YouTube data and Google API for accessing the YouTube data for login credentials.
- Download the videos from the device: Video uploaded from personal devices or external storage devices using Python library.
- Video to audio: Video file will be converted to audio using the FFmpeg Python library
- Audio to text: Audio file will be converted to a text file with speech recognition using Pocket-Spinx Python library with an acoustic model
- Text segmentation: Whole text will be broken into multiple segments based on the timings.
- Automatic indexing and searching: The text file will be auto-indexed using the Whoosh Library
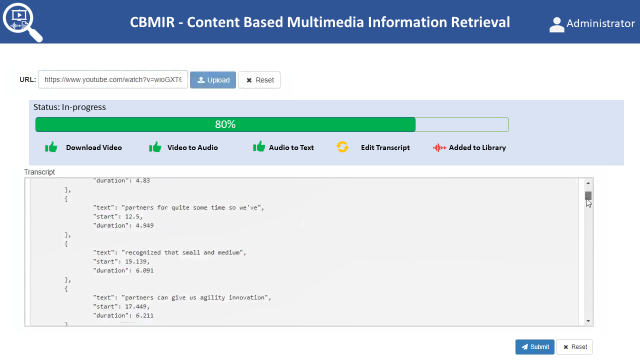
Figure 4. The status bar of processing of information and storage.
User Module
The user module acts as a search engine, where the page contains a search box. It shows a dashboard below the search box that displays the total number of videos and subject, or topic-wise, collections. The user is allowed to search desired information using keyword terms. Search results are displayed based on the word occurrence. The Whoosh Library converts all audio files into a text file, auto indexes these files, and makes a fast searchable format. The keyword term will be searched in the database and a list of videos will be displayed. The video starts playing on a single click on a specific video.
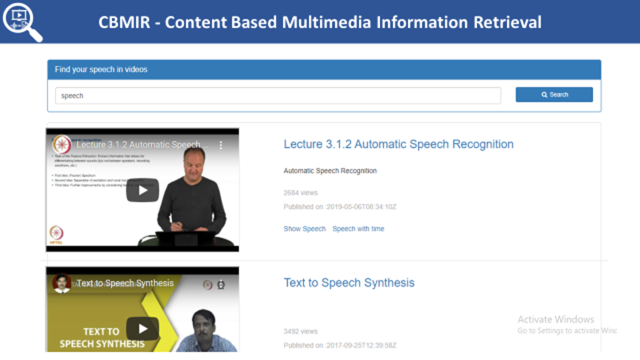
Figure 5. Display of search result of the Keyword Speech.
The whole text will be broken into multiple segments based on the speech timing and auto indexed into the database. With the advantage of segmentation, the video will start playing on the specific keyword or phrase searched by the user.
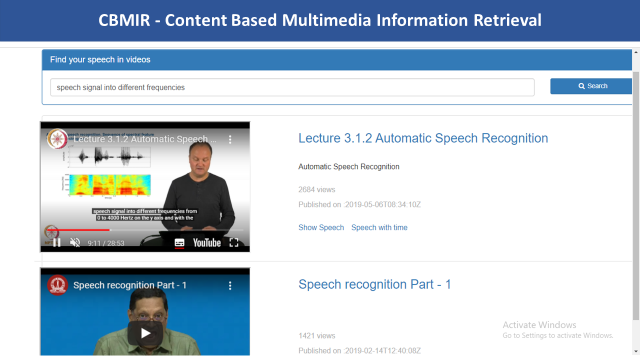
Figure 6. Display of search results based on the time segmentation.
Unique features of applications:
- Open source application: The CBMIR application is designed and developed based on the open source web application and databases. The source code of the application will be shared on a popular source code distribution platform for further development from the community.
- Fast and full-text search engine: Searching through a full-text database or text document is referred to as a full-text search. A search engine is embedded within CBMIR that analyses all the words contained within a document and compares them to the search criteria specified by the user during the search process. Searching a huge converted text file using a full-text search ensures fast retrieval of results for large numbers of documents. The search engine provides efficient search results that are accurate and precise in all fields.
- Domain based lecture video repository: The CBMIR application allows subject-based lecture video archiving for academic institutions. This repository provides consolidated subject-specific lectures and helps users to spend less time searching on popular video sharing platforms for lectures.
- No video advertisements on the application: The video on the CBMIR application will not play advertisements. Popular video sharing platforms typically include advertisements at the beginning and middle of their videos.
- Lightweight, less storage space, and unlimited video upload: The CBMIR application is very lightweight and it can extract speech, convert it into audio, and save text files stored into databases; usually it requires less storage space. There is no limitation in uploading video into the application.
- Text Segmentation for retrieval of video content: The application divides converted text from audio into sets of words along with video timestamp. The video is played from the specific timestamp depending on the user desired search term.
Conclusion:
Due to Covid-19, E-lecturing became a part of the academic community for all levels of education. Academic institutions are finding it difficult to archive lecture video on internal servers and hosting on popular video sharing platforms for future use. Users find it difficult to search the desired video information from the larger video repositories. The search function is restricted only to metadata, human annotation, and tags of a particular video. To overcome this problem, the CBMIR application has been developed using open source technology to build educational videos repositories based on the relevant subject, focusing on fast and full-text search of the video content.
The current CMBIR application is limited to converting the speech to text in the English language only. The further development of the application includes converting speech to text for Indian regional languages, translating converted transcripts into Indian regional languages, including voice search options, text extraction using OCR technology, finding objects from the videos, creating a dashboard on the user module, etc. The source code of the CBMIR application is being submitted to the authors’ university in order to fulfill requirements for a degree and will be distributed on GitHub under a Creative Commons CC BY-NC License after completion of the degree.
Reference
[1] Saoudi, E. M., & Jai-Andaloussi, S. (2021). A distributed Content-Based Video Retrieval system for large datasets. Journal of Big Data, 8(1). https://doi.org/10.1186/s40537-021-00479-x
[2] Bolettieri, P., Falchi, F., Gennaro, C., & Rabitti, F. (2007). Automatic metadata extraction and indexing for reusing e-learning multimedia objects. Proceedings of the ACM International Multimedia Conference and Exhibition. https://doi.org/10.1145/1290067.1290072
[3] Yang, H., Siebert, M., Lühne, P., Sack, H., & Meinel, C. (2011). Lecture video indexing and analysis using video OCR technology. Proceedings – 7th International Conference on Signal Image Technology and Internet-Based Systems, SITIS 2011. https://doi.org/10.1109/SITIS.2011.20
[4] Yang, H., & Meinel, C. (2014). Content based lecture video retrieval using speech and video text information. IEEE Transactions on Learning Technologies, 7(2). https://doi.org/10.1109/TLT.2014.2307305
About the Authors
Arun F. Adrakatti (arun@iiserbpr.ac.in) is Assistant Librarian at the Indian Institute of Science Education Research (IISER) in Berhampur, Odisha, India.
K.R. Mulla (krmulla@vtu.ac.in) is a Librarian at Visvesvaraya Technological University in Belagavi,
Karnataka, India.

Subscribe to comments: For this article | For all articles
Leave a Reply