By Dan Lou
The Issue of Record Discrepancies
At a certain point our acquisition librarian noticed there were large discrepancies between the records from vendors (Axis360 and OverDrive) and those in our Sierra system. The vendors usually send us regular record updates, but unfortunately overtime, it still became a challenge to keep the information perfectly synchronized.
In order to resolve these discrepancies more efficiently and quickly, I was asked to compose a Python script to compare record details and identify the exact records we needed to modify in our catalog.
Comparing Records with ISBN
As the first step I tried to identify the discrepancies in records by comparing ISBN numbers.
I chose Python pandas (pandas 2018[1]) as the data analysis tool for this task. Pandas is an open source Python package that is widely used for data science and machine learning tasks. Pandas is built on top of another Python package named Numpy that provides support for multi-dimensional arrays, and it works very well with other Python packages like Matplotlib that is widely used for data visualization. Pandas makes it simple to do many of the time consuming, repetitive tasks associated with working with data, including but not limited to loading and converting data, data scrubbing, data normalization, data fill, data merges and split, data visualization, data inspection etc.
You can install pandas and all the relevant packages on your local machine but a better option is to start your coding with Google Colab(Google 2019[2]). Google Colab is a cloud-based Python Jupyter notebook service and it provides a free tier. By default, pandas and matplotlib are already pre-installed in Google Colab. To enable pandas in a Jupyter notebook in Google Colab, we simply import the package and give it an short alias:
import pandas as pd
We exported the relevant MARC records from Sierra to a comma-separated values (CSV) file, and loaded it into the Jupyter notebook as a Pandas Dataframe object. For example, this is how we read a CSV file of the Axis360 audiobook records exported from Sierra:
sierra_axis_audio = pd.read_csv( "/content/drive/My Drive/Library/axis_overdrive/sierra_axis360_audio.csv")
This file typically contains columns like title, author and ISBN entries. A record sometimes can contain more than two ISBN numbers, and those are stored in the “Unnamed” columns towards the end for now:
sierra_axis_audio.columns
Index(['TITLE', 'AUTHOR', 'ISBN1', 'ISBN2', 'Unnamed: 4', 'Unnamed: 5',
'Unnamed: 6'],
dtype='object')
We also needed to further clean up all the ISBN numbers in order to compare them with those from the vendor. A typical MARC 020 field can contain many subfields besides the subfield a for the ISBN number. In our exported file, the ISBN field usually contains more information than we needed for the comparison. For example, “9780804148757 (electronic audio bk.)“, “9780062460110 : $62.99” etc.
I composed a Python function to extract the isolated ISBN number from each of the columns after the “AUTHOR” column, and compile all the ISBN numbers into a new DataFrame object. One Sierra record can contain multiple ISBN numbers. In this way, I was able to generate a complete list of all ISBN numbers from the MARC records exported from Sierra:
def extract_isbns(df):
isbns = pd.DataFrame()
result = pd.DataFrame()
for i in range(2,len(df.columns)-1):
new_isbns = df.iloc[:,i].astype(str)
new_isbns = new_isbns.str.split(' ', 1).str[0].str.strip()
isbns = pd.concat([isbns, new_isbns])
isbns = isbns.reset_index()
isbns = isbns[isbns[0]!='nan']
return isbns
In comparison the vendor’s CSV file is simple and straightforward. It contains only one ISBN field with the clean ISBN number. It also has some other fields like title, author, publication date, data added, format, total quantity and total checkouts. All that is left to do is to import these as a Pandas Dataframe object.
Next I composed a Python function to compare the ISBN numbers in the cleaned up data from both sources. I created a new column, “Exist,” in both Python Dataframe objects. If an ISBN number from a vendor record exists in a Sierra record, the “Exist” column on the Sierra record has a value of “1”; if not, the value is “0”. The opposite is also true. If an ISBN from the Sierra record matches that of a vendor record, the “Exist” column on the vendor record will have a value of “1” set; if not, the value is “0”. The function also returns two additional Dataframe objects that contain the discrepant records only.
def find_mismatch(vendor_df, sierra_df, sierra_isbns_df):
vendor_df["Exist"] = vendor_df["ISBN"].astype(str).isin(sierra_isbns_df[0])
not_in_sierra = vendor_df[vendor_df["Exist"]==False | vendor_df["Exist"].isna() | vendor_df["Exist"].empty]
sierra_isbns_df["Exist"] = sierra_isbns_df[0].astype(str).isin(vendor_df["ISBN"].astype(str))
exists = sierra_isbns_df[sierra_isbns_df['Exist']==1].drop_duplicates("index")
not_exists = sierra_isbns_df[sierra_isbns_df['Exist']==0].drop_duplicates("index")
not_exists = not_exists[~not_exists["index"].isin(exists['index'])]
isbns = pd.concat([exists, not_exists])
sierra_df = pd.merge(sierra_df, isbns, how="left", left_index=True, right_on="index")
not_in_vendor = sierra_df[sierra_df["Exist"]==False | sierra_df["Exist"].isna() | sierra_df["Exist"].empty]
return vendor_df, sierra_df, not_in_vendor, not_in_sierra
After running this script against our records, I did some data analysis to see how many conflicting records were resolved after comparing ISBN numbers. I generated the list of all MARC records that need to be added to the ILS and another list of records that need to be removed. As shown in the following chart, we were able to identify that the majority of our Axis360 records were well positioned, but on the OverDrive side, about a third of the records are problematic. In total, we still have over 4,600 records in Sierra that are troublesome.
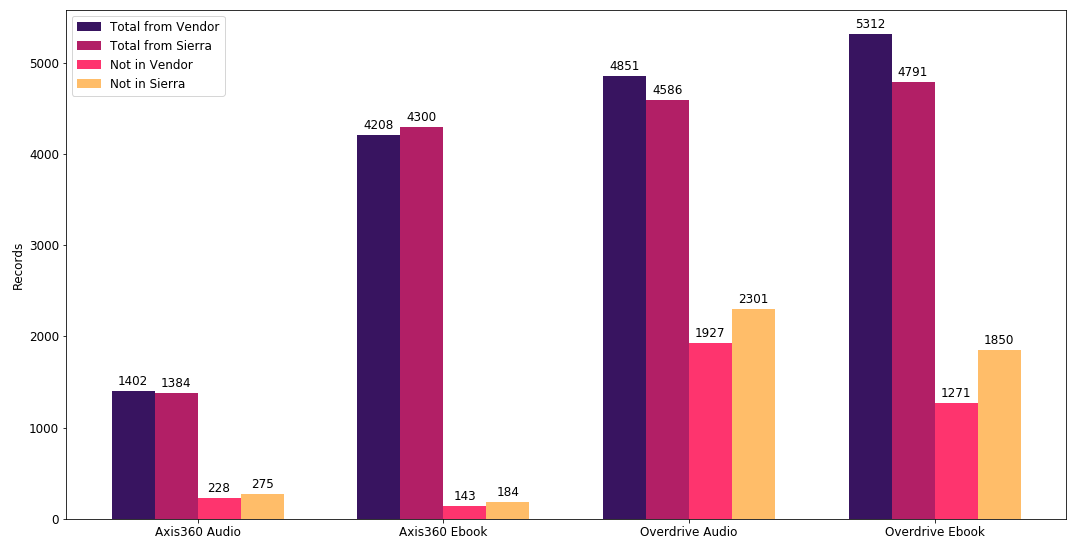
Figure I. Vendor vs. Sierra: Total Mismatches by ISBN
Comparing Records with Title and Author fields
To further scale down the issue, I moved on to align the remaining mismatched records by comparing the similarity of the author and title fields. A list of mismatched records is one of the outputs from the previous step after aligning the ISBN numbers.
First, we needed to clean up and extract the title and author field. I made a function to concatenate the title and author fields for each record from both sources. The following function transforms all text to lower cases, removes extra punctuation, extracts the relevant information, and concatenates the data to create a new column, “TitleAuthor,” for all the records:
def extract_title_author(vendor_df, sierra_df, vendor_title_field, vendor_author_field, sierra_title_field = "TITLE", sierra_author_field ="AUTHOR"):
vendor_df['TitleAuthor'] = vendor_df[vendor_title_field].astype(str).str.lower().apply(remove_punctuations).astype(str) + ' ' + vendor_df[vendor_author_field].astype(str).str.lower().apply(remove_punctuations).astype(str)
sierra_df['TitleAuthor'] = sierra_df[sierra_title_field].str.lower().str.extract("([^[]*\w*)").astype(str).apply(remove_punctuations).astype(str) + ' ' + sierra_df[sierra_author_field].str.lower().astype(str).apply(remove_punctuations).astype(str).str.extract("([ a-z]*)").astype(str)
Then I used the Python module difflib to compare the similarity of the “TitleAuthor” columns from both sources. The difflib module provides classes and functions for comparing data differences. Here is the function to compare and get the similarity level from two sources:
from difflib import SequenceMatcher
def get_close_matches_indexes(word, possibilities, n=3, cutoff=0.6):
if not n > 0:
raise ValueError("n must be > 0: %r" % (n,))
if not 0.0 <= cutoff <= 1.0:
raise ValueError("cutoff must be in [0.0, 1.0]: %r" % (cutoff,))
result = []
s = SequenceMatcher()
s.set_seq2(word)
for idx, x in enumerate(possibilities):
s.set_seq1(x)
if s.real_quick_ratio() >= cutoff and \
s.quick_ratio() >= cutoff and \
s.ratio() >= cutoff:
result.append((s.ratio(), idx))
After comparing the similarity of the title and author fields, I was able to generate new spreadsheet files for all of the mismatched records. Each row in the spreadsheet contains a Sierra record together with the most similar record from the vendor side using title and author. All rows are sorted by similarity level (on a scale of 0 to 1). Similarity level 0 means the two records in the row are very different; 1 means they are highly identical.
Again, I made some charts to see how much it would help to scale down the issue further.

Figure II. Similarity of Title and Author for Mismatched Axis 360 Audio Records
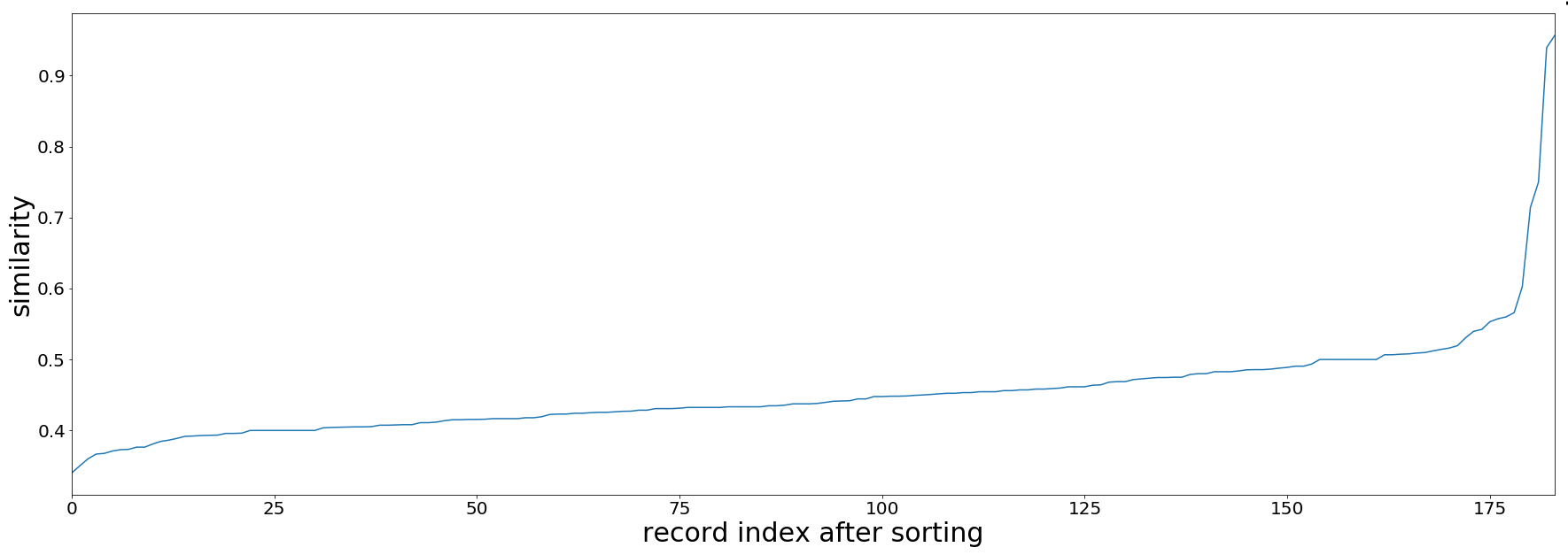
Figure III. Similarity of Title and Author for Mismatched Axis 360 Ebook Records
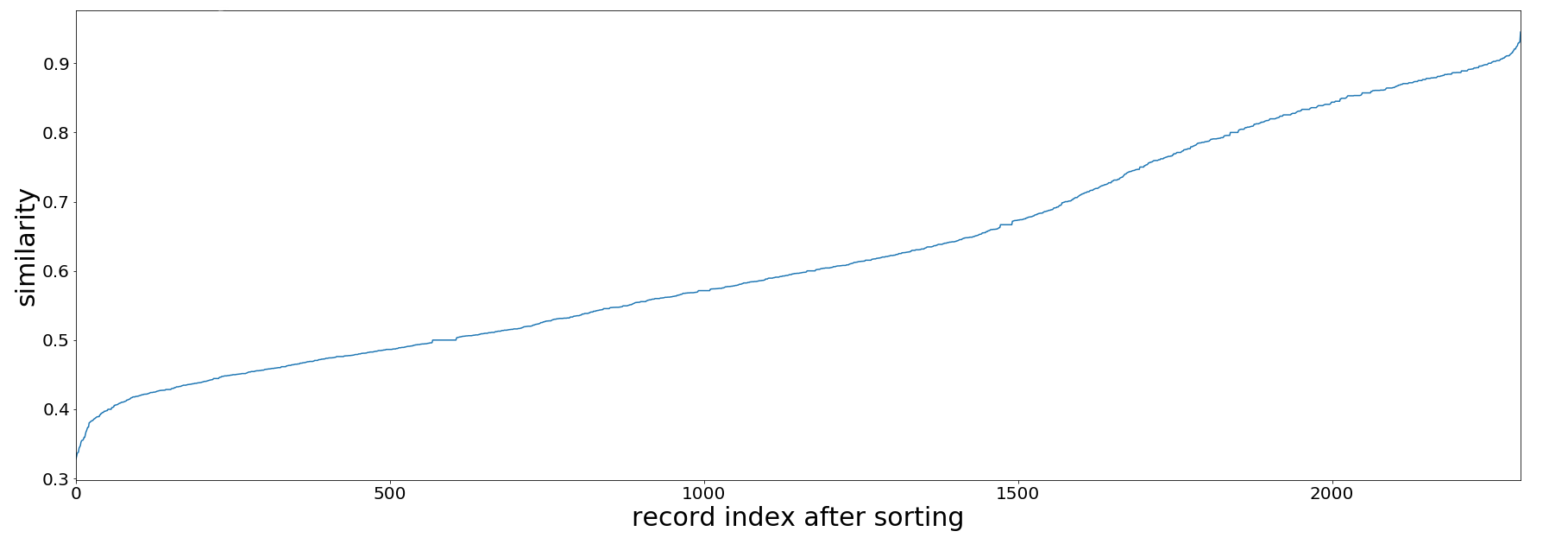
Figure IV. Similarity of Title and Author for Mismatched Overdrive Audio Records
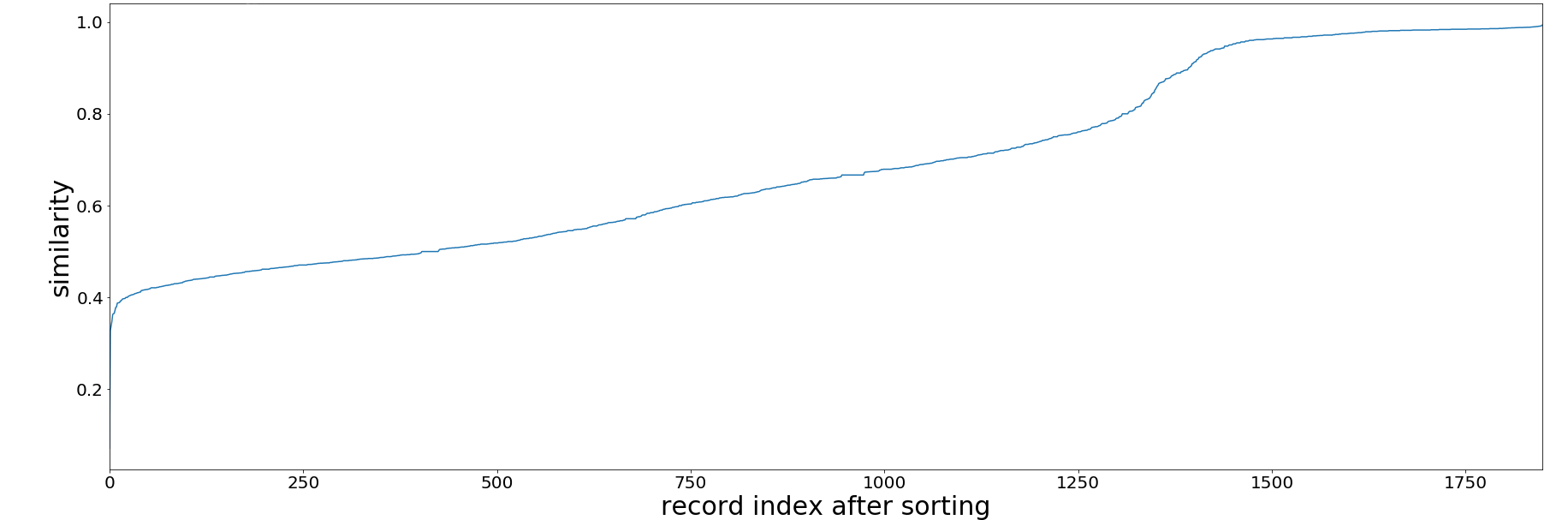
Figure V. Similarity of Title and Author for Mismatched Overdrive EbookRecords
As shown in the charts, if we take a similarity level of 0.7 as a benchmark, roughly two-thirds of the mismatched records required more cataloging effort. With the Python scripts we successfully narrowed down a problem of 30,843 records to that of 3,394 within a few days. Only the 3,394 records require further examination by our cataloger. This reduced the cataloging effort eventually needed to fix record discrepancies.
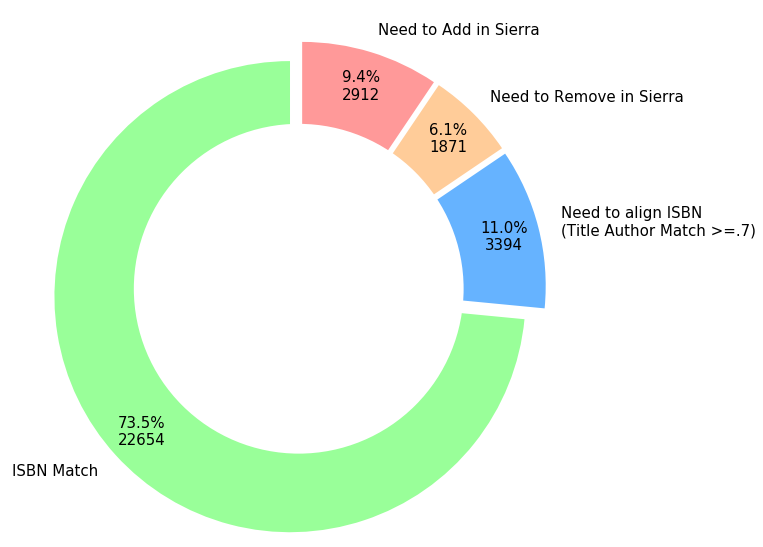
Figure VI. Comparing 30,843 Records from Sierra and Vendors (Overdrive and Axis360)
Conclusion
It has become an increasing challenge to keep the MARC records of online resources up to date between the library’s ILS and the vendors’ provided records due to the frequent changes taking place. The solution described in this article is a good remedy to identify and fix record discrepancies accumulated over time. I highly recommend libraries adopt this method and make it a routine task to prevent the issue having a snowball effect.
It is better if we can insert in the vendor provided MARC records a customized field to identify the valid date range. Then we can develop a script to automatically renew or modify the records that are close to or past the due date by retrieving them from the ILS system via record exporting or via API. Many vendors tend to not generate a 404 error page when a library loses access to an online resource like an eBook, so the script will need to be developed to be versatile enough to detect those links that stop working properly.
On the other hand, a huge change has been taking place in recent years as the record system of online resources slowly eases out of the library’s ILS. For example, library online service provider BiblioCommons has implemented BiblioCloudRecords which allows libraries to add certain online resources records via API to the library’s catalog website without needing to add the MARC records to the ILS. While this improves the resource access for library customers, it means patron data and usage statistics have inevitably shifted from libraries to the vendors. Online resources have had a stronger presence in the library’s collection since the pandemic and will become more and more influential in the foreseeable future. It is a good question to ask now how libraries could better position ourselves in this new online resources landscape.
References
[1] Pandas. 2018. Python Data Analysis Library — pandas: Python Data Analysis Library. Pydataorg. https://pandas.pydata.org/.
[2] Google Colaboratory. 2019. Googlecom. https://colab.research.google.com/
About the Author
Dan Lou is a senior librarian at Palo Alto City Library, where she works on web content management and develops pioneering projects on robotics, coding, AR and distributed web. Her particular interests include Python, machine learning and data analytics. Previously, she worked as a technical project manager at Wolfram Alpha, a knowledge base queried by Apple Siri and Amazon Alexa. Before that, she was a systems librarian at Innovative Interfaces.
Author email: loudan980@gmail.com

Subscribe to comments: For this article | For all articles
Leave a Reply