by Mitchell Scott
Introduction
It is becoming increasingly common for academic libraries to seek out partnerships with campus bookstores [1]. Academic Libraries are interested in working with the bookstore to receive the title level data that the bookstore collects on what books are being required for an upcoming semester. Libraries are seeking these partnerships to leverage the use of their collections, specifically their already licensed unlimited access eBooks, and their ability to purchase unlimited access eBooks, to offer as no-cost alternatives to students. Offering library supplied no-cost eBook alternatives to students allows the library to play a role in affordability initiatives and potentially create the no-cost conditions that have been shown with OER (Open Educational Resources) use to increase student success metrics [2]. While some libraries find receptive bookstore partners [3], others do not, and those develop alternate processes to get at the title level data on what books are being required for an upcoming semester [4, 5, 6]. No matter how libraries get their hands on this data, once acquired, they have developed various methods to pursue the daunting task of matching ISBNs or title level data on what is required to ISBNs or title level data on what is already licensed, owned, or can be purchased as unlimited access eBooks [7, 8, 9, 10].
Ideally, this process could be automated and the hundreds, and potentially thousands, of bookstore ISBNs could be batch searched against the hundreds of thousands, potentially millions, of eBook ISBNs that make up the library’s eBook holdings. However, it is not that simple. For one, the ISBNs represented on the campus bookstore list vary with some book records having only a print ISBN, some having only eBook ISBNs, and some having both a print and eBook ISBN.

Figure 1. Examples of a bookstore supplied spreadsheet with one ISBN per book.

Figure 2. Examples of a bookstore supplied spreadsheet with multiple ISBNs per book.
Another aspect that complicates this process is which ISBN is represented in the bookstore list and whether the one selected by the bookstore will correspond to any ISBNs indexed in the library’s eBook collection, the Library Management System (LMS), or Library Discovery. Unique ISBNs are granted based on varying formats and editions. This means certain books can have unique ISBNs for paperback and hardback versions [11]. eBook ISBNs are also granted by format type and exist for standard eBook versions, EPUB versions, and PDF versions [12]. Unique ISBNs could also be a part of a record for revised editions of the same book. With varying ISBNs represented in the bookstore data the library could be attempting to match a print ISBN to an eBook ISBN (not going to happen) or match a different eBook format to the library held eBook format (might happen).

Figure 3. Example of eBook MARC record and the multiple ISBNs contained within it.
Another complication to batch searching by ISBN is that libraries are dependent on whether their LMS has the functionality that allows for the batch searching of ISBNs and if they are one of the libraries that does have an LMS that allows for ISBN batch searching, how well it searches indexed ISBNs. From 2015-2017, I was a librarian at an institution that used Ex Libris Alma, when Alma was relatively new, and Alma had an Analytics component that allowed for the batch input of hundreds, to potentially thousands, of items and searched against Alma data made available within its Analytics component [13]. Although possible, I never used Alma Analytics for ISBN searching and wonder about the ability and accuracy of the system to do this level of searching and matching. It is my understanding that, in most cases, Library Management Systems commonly index one ISBN per book, which is usually the primary or preferred ISBN for a particular title. This means that not every ISBN granted to an eBook is searchable, and a bookstore eBook ISBN might not be found in LMS or Discovery searches [14,15,16]. If print ISBNs are searched, then they commonly will not result in identifying its eBook alternative within a LMS as these systems do not commonly cross search in that way. Within the library literature, only one article references a process that potentially does batch searching with ISBNs and that is at the University of Minnesota, where they have worked on similar processes since 2015. Eighmy-Brown notes that data management staff “match the libraries electronic resource titles and ISBNs with those in the bookstore“ [3].
I have been working with campus bookstores on this process since 2018 and unfortunately, have never been a user of a LMS that allows for any level of batch searching. After having the experience of manually searching bookstore ISBNs and titles in a Library Discovery platform to identify assigned materials that have available library eBooks, I was interested in automating the process. Having some Python programming experience, I turned to Python and discovered the pymarc library [17], which was built to work with MARC records, and developed a script and process that takes the ISBNs present in a bookstore list, and matches them against existing library eBook holdings. As a result of this matching, I can then take the ISBNs that did not match to determine what could be purchased as an unlimited access eBook. This script and process works in accurately identifying matches in this content because the script iterates over all the eBook MARC records that I input into it, indexes every ISBN that is present in an eBook’s MARC record (all print, eBook, and format or version ISBNs), and then matches the bookstore ISBNs, whether print or eBook, to the ISBNs from the eBook MARC records.
The process
This process starts with identifying and harvesting the eBook MARC records that are to be a part of the match process. Since we only use unlimited access eBooks for this initiative, I only include unlimited access licensed eBook collections and individual purchases, when optional. The outlier here is EBSCO eBooks, which does not allow for the separation of unlimited access eBooks from other more limiting user models at the MARC level–I still include these but check these matches manually to determine the user model of the eBook. I use the OCLC Worldshare Collection Manager [18] to harvest the MARC records for the eBook collections and titles that I want to include.
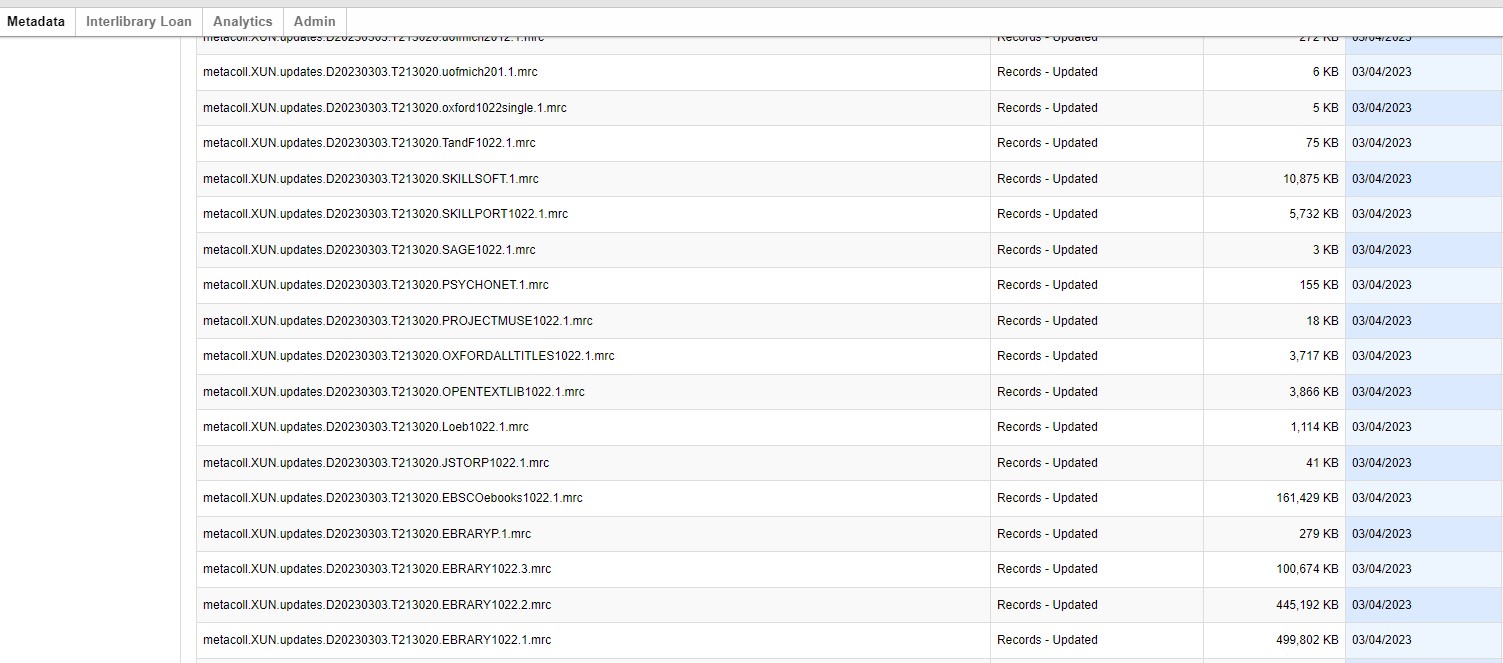
Figure 4. Downloading files from the OCLC Collection Manager.
At St. Norbert College, where I worked previously, the OCLC Worldshare Management System (WMS) was our LMS and the Collection Manager was a required component for e-resource activation, linking, and discovery. Despite being on a different LMS at Indiana University Southeast, I still use the OCLC Collection Manager for this process. This is due to complications for extracting institution specific eBook MARC records from the shared Indiana University LMS (largely limited users with these admin privileges and the large amount of e-resource MARC content loaded) and because of my familiarity with the Worldshare Collection Manager. Once I have all the MARC records harvested that I want to include in this process, I run the first Python script that kicks off the matching work [19].

Figure 5. Folder with MARC files and Python scripts that pull data from these MARC files.
The first script to run iterates over all the eBook MARC records that I have compiled. There are several libraries that I import to use alongside Python’s basic library for this process.
from pymarc import MARCReader import glob import re from collections import defaultdict import pickle
This script uses the glob library [20] to iterate over one file type (.mrc) and progress over all MARC files until all the MARC files have been opened and processed. With the pymarc library and its MARCReader function, the script iterates over every MARC record within these files and extracts specific data to build a dictionary for later recall.
This dictionary is built using the collections library [21] and is compiled with ISBNs, from the 020 MARC field and 020 MARC subfields a and z, as the dictionary key.
def main():
ebook_dict = {} ###main e-book dictionary that maps vendor, title, and access URL to e-book isbn
def ebook_get_isbns():
for file in glob.glob('*.mrc'): # glob alows you to open all file types in a folder. Will process all .mrc files
try:
print('Getting ISBN list...')
with open(file, 'rb') as marc:
reader = MARCReader(marc)
for r in reader:
for field in r.get_fields('020'):
for subfield in field.get_subfields('a', 'z'):
re_sub_isbn = re.search(r'/((978[\--- ])?[0-9][0-9\--- ]{10}[\---][0-9xX])|((978)?[0-9]{9}[0-9Xx])', str(subfield)) # regex to trim ISBNs
This step extracts all ISBNs contained within the eBook MARC record. I use regular expressions in Python [22] to trim the ISBNs before adding them to the dictionary as the key.
The dictionary values, also extracted from the MARC, are then attached to the ISBN keys. These values are the title of the book (245 and 245 MARC subfield a) and the URL of the eBook (856 MARC field).
for field in r.get_fields('245'): # gets eBook title from MARC
ebook_dict[final_sub_isbns].append(field.value())
if field is None:
for subfield in field.get_subfields('a'): # gets title in 245 a
if subfield is None:
pass
else:
re_title = re.search(r'^(.+?)\/', subfield) # regex for title
title = title.strip('/')
title = title.strip()
ebook_dict[final_sub_isbns].append(title)
for field in r.get_fields('856'): # regex for eBook URL
url = field.value()
re_url = re.search(r'http(.+?)$', url)
if re_url is None:
pass
else:
url = re_url.group(0)
ebook_dict[final_sub_isbns].append(url)
One outlier to this is the vendor’s name value that I create from the MARC file name (I use a file naming convention that is the VENDOR_DATE OF EXTRACT_NUMBER OF FILE (if multiple MARC files exist).
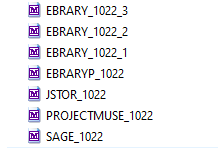
Figure 6. File naming convention for extracting vendor name for dictionary.
For this value, I use regular expressions to match to the vendor’s name that prepends the file and use it as a dictionary value.
else:
final_sub_isbns = re_sub_isbn.group(0)
vendor_name = re.match(r'^(.+?)_', file) # regex to get the vendor from the file name
vendor_key = vendor_name.group(1)
ebook_dict.setdefault(final_sub_isbns, []) #sets the ISBN as the dictionary key
ebook_dict[final_sub_isbns].append(vendor_key) # adds the vendor name as a value to the ISBN key
I also use regular expressions in combination with the pymarc library to match to the relevant data, clean the data, and pass the data, when necessary, to basic string functions to clean the data before adding it to the dictionary. A good example of this is the title data from the 245 MARC field. In some MARC records the title data appears in the 245 field, as seen with here:
for field in r.get_fields('245'): # gets eBook title from MARC
ebook_dict[final_sub_isbns].append(field.value()) # gets title in 245
However, the title data could also be in the 245-subfield a. If no data is present in the 245 MARC field, the script looks in subfield a and then uses regular expression to get the title data from the field. The script then passes the title through string functions to remove the ‘/’ from the title and any leftover white spaces.
if field is None:
for subfield in field.get_subfields('a'): # gets title in 245 a
if subfield is None:
pass
else:
re_title = re.search(r'^(.+?)\/', subfield) # regex for title
title = title.strip('/')
title = title.strip()
ebook_dict[final_sub_isbns].append(title)
Each piece of MARC data (Vendor, Title, URL) is added as a value to the eBook dictionary. The ISBNs are set as the key:
ebook_dict.setdefault(final_sub_isbns, []) #sets the ISBN as the dictionary key ebook_dict[final_sub_isbns].append(vendor_key) # adds the vendor name as a value to the ISBN key
The other values are then matched and appended to their corresponding ISBN:
else:
re_title = re.search(r'^(.+?)\/', subfield) # regex for title
title = title.strip('/')
title = title.strip()
ebook_dict[final_sub_isbns].append(title)
else:
url = re_url.group(0)
ebook_dict[final_sub_isbns].append(url)
Having compiled the eBook dictionary, the script then uses the pickle library [23] to save the dictionary for use in the next script.
def pickle_dict():
pickle.dump(ebook_dict, open("ebook_dict.p", 'wb')) # pickle saves the eBooks dictionary so that it can be called in a seperate script. I run this to compile the dictionary and wait till I have bookstore ISBNs to run second part.
pickle_dict()
print('All Done')
I have broken this process into two scripts [26, 27]. The first script that builds the eBook dictionary can take ten to fifteen minutes to finish and in debugging the matching process, I found it easier to break these apart and deal with them separately. Pickling or saving the dictionary also allows me to extract MARC records and build my eBook dictionary in advance of receiving the ISBNs from the bookstore. Once I have the bookstore ISBNs, I can input that data into the second script and simply look for matches.
The second Python script does the matching and outputting of matched titles. The first step is to load the eBook dictionary that was built in the previous script, this is also done with the pickle library.
import pickle # imports pickle to load the dictionary
def main():
ebook_dict = pickle.load(open('ebook_dict.p', 'rb')) # loads ISBN dictionary that was built and saved with 1st script.
Once I receive the required material list from the campus bookstore, I extract all the ISBNs and use a text editor, such as Notepad ++, to remove duplicates, sort, and delete any ISBNs that do not begin with the 978 prefix and save as a text file. That file is then opened within the script, and a list is created with its ISBNs.
bookstore_list = []
def get_bookstore():
bookstore_file = 'spring_2023_NOV.txt'
lines = [line.strip() for line in open(bookstore_file, encoding = 'utf-8')]
for line in lines:
bookstore_list.append(line) # add all bookstore ISBNs to list
In the find_match function, the script uses two for loops to iterate over the key and values of the eBook dictionary and the ISBNs within the bookstore list.
def find_match():
print('Getting IUS eBook matches...')
for key, value in ebook_dict.items():
for i in bookstore_list:
The script then matches any ISBN in the bookstore list to the dictionary key (eBook MARC record ISBNs) and if a match is found, it outputs the key (ISBN) and associated dictionary values (separated by commas) in the Python console window.
if i in key: print(key + ',' + str(value)) # prints the matches in the viewing window in Python. I copy and paste this into Excel. The data is comma delimited.
Getting IUS eBook matches... 9780787980672,['EBRARYP', 'Because writing matters : improving student writing in our schools / National Writing Project and Carl Nagin.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=707687'] 9781474225199,['EBRARYP', 'Plays one / translated and introduced by Don Taylor ; with introductions by Don Taylor and J. Michael Walton.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=6159981'] 9781474225199,['EBRARYP', 'Plays one / translated and introduced by Don Taylor ; with introductions by Don Taylor and J. Michael Walton.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=6159981'] 9781474225199,['EBRARYP', 'Plays one / translated and introduced by Don Taylor ; with introductions by Don Taylor and J. Michael Walton.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=6159981'] 9781462531592,['EBRARYP', 'Building literacy with English language learners : insights from linguistics / Kristin Lems, Leah D. Miller, Tenena M. Soro.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=4844819'] 9781462531592,['EBRARYP', 'Building literacy with English language learners : insights from linguistics / Kristin Lems, Leah D. Miller, Tenena M. Soro.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=4844819'] 9781433829789,['EBRARYP', 'How to write a lot : a practical guide to productive academic writing / Paul J. Sivia, PhD.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=5525817'] 9780231191630,['EBRARYP', 'What is Japanese cinema? : a history / Yomota Inuhiko ; translated by Philip Kaffen.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=5613954'] 9780674018242,['EBRARYP', 'The Poems of Emily Dickinson : Reading Edition.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=5906829'] 9781788291552,['EBRARYP', 'Machine learning with R : expert techniques for predictive modeling / Brett Lantz.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=5752784'] 9781788295864,['EBRARYP', 'Machine learning with R : expert techniques for predictive modeling / Brett Lantz.', 'http://proxyse.uits.iu.edu/login?url=https://ebookcentral.proquest.com/lib/[pqebk.library.id]]]/detail.action?docID=5752784', 'EBRARYP',
I then take the Python console output and copy and paste the matches into an Excel file. Duplicate matches do occur for bookstore list books that have multiple ISBNs listed for a single title (print and eBook) and these can be easily removed once the data is in excel. I have tried multiple times to create an output of the ISBNs that did not match as a text file during this process but have failed to write code that works. I use Excel and its conditional formatting/highlight cell rules/duplicate values for this process of removing ISBNs that matched from those that did not match. Once I have the ISBNs that do not match to an existing library eBook, I take those, and batch search them in the GOBI platform [24] to identify which required materials could be purchased as unlimited access eBooks.

Figure 7. GOBI platform’s Alternate Formats search of unmatched ISBNs.

Figure 8. GOBI platform’s Alternate Formats search results.
Conclusions
Having this Python script to automate the identification of already licensed and owned library eBooks has helped immeasurably with this process. As reported in previous studies, existing licensed or subscribed content could make up as much as 27% of the eBooks that a library can provide for programs like this, and up to 17% can come from eBooks that were previously purchased (and reused semester to semester) for these programs [25]. Being able to accurately and quickly identify these eBooks increases the turnaround time between receiving the required materials list from the bookstore (which can vary in the timeliness of its delivery) and the notification of faculty and students about these no-cost alternatives prior to the start of the semester. Any next steps would be to make this process and these scripts more user friendly. I’d like to output the ISBNs that do not match to existing library eBooks to a text file so that I could batch search those in GOBI without any additional work. I’d also like to create a basic GUI interface that could be used by colleagues and/or libraries without any Python experience and would only require the MARC records to be used in the match process.
About the Author
Mitchell Scott is the Coordinator of Collections and Online Resources at Indiana University Southeast.
Bibliography
[1] Bell, S. (2017). What about the bookstore?: Textbook affordability programs and the academic library-bookstore relationship. College & Research Libraries News, 78(7), 375.https://www.doi.org/10.34944/dspace/98.
[2] Colvard, NB, Watson, CE, Park, H. (2018). The impact of open educational resources on various student success metrics. International Journal of Teaching and Learning in Higher Education, 30(2), 262-276.
[3] Eighmy-Brown, M, McCready, K, Riha, E. (2017). Textbook access and affordability through academic library services: A department develops strategies to meet the needs of students. Journal of Access Services, 14(3), 93-113.
[4] Rokusek, S, Cooke, R. (2019). Will library e-books help solve the textbook affordability issue? Using textbook adoption lists to target collection development. The Reference Librarian, 60(3), 169-181.
[5] Wimberly, L, Cheney, E, Ding, Y. (2020). Equitable student success via library support for textbooks.” Reference Services Review. https://www.doi.org/10.1108/RSR-03-2020-0024.
[6] Scott, R, Jallas, M, Murphy JA, Park, R, Shelly, A. (2022). Assessing the Value of Course-Assigned E-Books. Collection Management, 47(4), 253-271.
[7] Carr, PL, Cardin, JD, Shouse, DL. (2016). Aligning collections with student needs: East Carolina University’s project to acquire and promote online access to course-adopted texts.” Serials Review 42, no. 1: 1-9. https://www.doi.org/10.1080/00987913.2015.1128381.
[8] Wallace, N, Filion, S. (2018). Textbook or Not: How library eBook purchasing power aligns with curricular content trends.” The Evolution of Affordable Content Efforts in the Higher Education Environment: Programs, Case Studies, and Examples.
[9] Hoover, J, Shirkey, C, Barricella. (2020). Exploring sustainability of affordability initiatives: a library case study.” Reference Services Review. https://www.doi.org/10.1108/RSR-03-2020-0016.
[10] Sotak, D, Scott, JG. (2020). Affordable education with a little help from the library.” Reference Services Review. https://www.doi.org/10.1108/RSR-03-2020-0012.
[11] Library of Congress ISBN FAQ
[12] E-Books and ISBNs: A Position Paper and action points from the International ISBN Agency
[17] Pymarc Python Library documentation
[18] OCLC Worldshare Collection Manager
[19] My experience with Python is limited and I am a self-taught coder. As a result, there are many redundancies and complexities that exist within the code that more experienced and knowledgeable coders will uncover but it works for me.
[20] Glob Python library documentation
[21] Collections Python Library documentation
[22] Regular Expression Python Library documentation
[23] Pickle Python Library documentation
[24] EBSCO GOBI
[25] Scott, M. (2021). Shifting Priorities: A Look at a Course Adopted Text (CATs) e-Book Program and How Its Success Realigned One Library’s e-Book Collection Priorities. Collection Management, 47(4), 238-252.

Subscribe to comments: For this article | For all articles
Leave a Reply