By Alexander Dryden and Daniel G. Tracy
Introduction
Since the launch of Omeka Classic in 2008, Omeka has become the leading out-of-the box software for digital exhibits in libraries, museums, and archives, and the choice of many scholars for hosting digital humanities projects providing access to large collections of digital media. Originally developed by the Ray Rosenzweig Center for History and New Media with funding from numerous sponsors, Omeka is now part of the not-for-profit Digital Scholar as one of a number of open-source platforms supporting digital humanities research and dissemination. [1] In 2012, the Mellon foundation funded work to begin what would become Omeka S, a version of Omeka geared towards larger institutions. In particular, unlike Omeka Classic which supported a single Omeka site that could have exhibits, Omeka S supports multiple sites in the same installation, avoiding the need for multiple installations of the same software to support different needs within an organization. Additionally, Omeka S offers linked data functionality (with the “S” standing for “Semantic”) for digital content within the site, allowing just about any metadata field to become interlinkable with other items, or also other types of entities that Omeka S can represent. For example, a creator in Omeka S can have their own person-related metadata, and that creator entity can be made the value of all of the items created by that individual, enhancing browse functionality beyond exhibit and collection structures.
The University of Illinois first adopted Omeka S and encountered challenges with the back-end for authors in the course of establishing its library publishing program, the Illinois Open Publishing Network (IOPN). Omeka S was one of three platforms adopted by the program to support “long-form” publications, alongside Scalar and Pressbooks. The appearance of Omeka S at approximately the same time as the press’s development was a boon due to the fact that, unlike Omeka Classic, it allowed multiple sites, meaning one install could support different author publications. However, as the publishing team began to provide outreach workshops and recruit authors into the press’s sandbox installation and later the production instance, a key challenge became apparent: while the user-facing sites were distinct, the back end of the site did not distinguish site contents. In other words, any author for any project could see and edit any other project’s items in Omeka S (See Figure 1). The publishing team saw the need for a locally developed Omeka S module that would more completely wall off each site’s authors and resources and support more multitenant functionality (See Figure 2). We also saw a likelihood that other institutions may want a similar feature to support other use cases. This article describes the needs leading to the decision to create the module, the project requirement gathering process, and the implementation and ongoing development of Teams. [2]

Figure 1. A screen capture of a sample Omeka S user dashboard where all items from a variety of users working on a variety of projects are visible to the creator who is logged in.
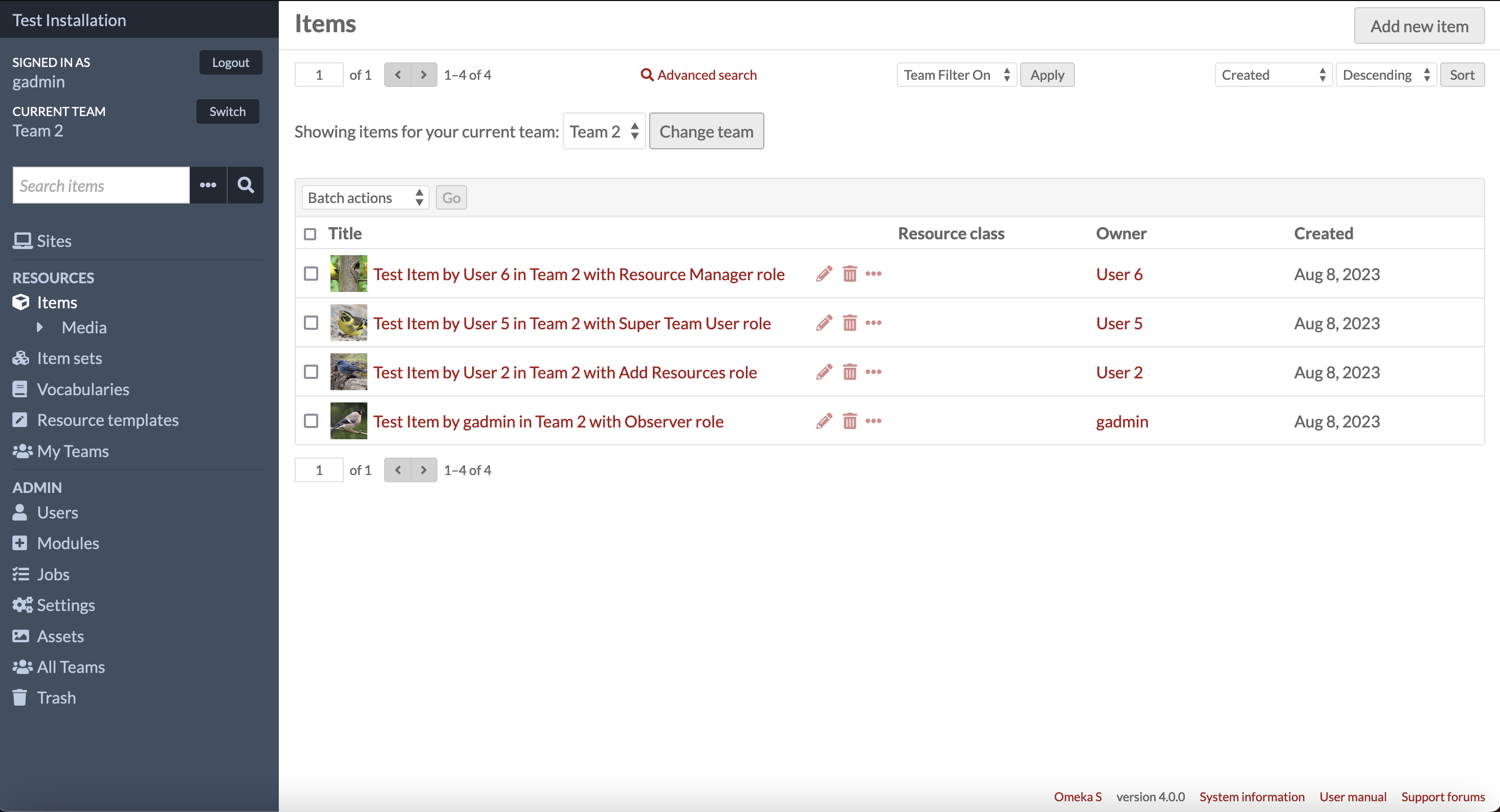
Figure 2. A screencapture of the same Omeka S user dashboard as shown in Figure 1, but with Teams activated so that only the items submitted by users as part of Team 2 are shown to the creator who is logged in and is a member of Team 2.
Challenges and Use Cases
The lack of partitioning between sites for content creators using the back end of Omeka S created a significant user experience problem because the list of items, from any particular author’s perspective, was cluttered with a large number of unrelated content with no clear way of identifying which items belonged to which sites. In addition, providing authors with sufficient permissions to edit resources created by co-authors or assistants likewise granted them editing rights to resources belonging to other publications. Both authors and press staff found the resulting back-end content management overwhelming as a result. The lack of separation of resources also created a data integrity risk, creating the possibility of any author changing items belonging to sites they did not own, whether intentionally or by accident.
The visibility of all resources for all content creators in Omeka S would not be a problem for all use cases, and indeed it is easy to imagine cases where a library, museum, or archive would want multiple sites (not only multiple exhibits on the same site) that drew from a shared pool of born digital or digitized assets from their collections. Nonetheless, the press staff anticipated that better partitioning of back end content would be helpful across a variety of institutions and scenarios.
Indeed, just as a new programmer was hired who would take up the project of developing this module, which would be called Teams, the University of Illinois Library developed its own second use case. Over the years, the library had supported a number of one-off digital exhibit projects, some in Omeka Classic and others using boutique approaches. There was continued demand, particularly from special collections and archival units, to continue this work, but creating each exhibit as a one-off solution was not sustainable. Because the publishing team was already supporting Omeka S, the programmer created a parallel installation that would be used for library digital exhibits. The separate install was used to support more standard library branding as opposed to the press branding used on the IOPN site, but it was clear that multitenancy would create similar problems. Although shared assets might work for many libraries’ multi-site work in Omeka S, the size of the library and differing needs of the units meant that sharing assets across sites would not be desirable. Sharing assets would create similar UX problems as those already mentioned, as well as introducing the possibility of units changing items in ways that would affect exhibits developed by other units. Teams would then also need to address this use case, and implementation of the centralized digital exhibits solution was deferred until the initial version of Teams was complete.
As development began and continued, the developer identified two more use cases through online discussions and external community interest in the early work on Teams. One use case was the use of Omeka S for student projects where students needed to produce individual sites and not interfere with one another’s work (that is, not course-wide collaborations). The final use case was what might be considered the most fully “multitenant” situation, involving an organization that provides access to the platform as a service for related groups and individuals. This use case first came to our attention from the Craft Council of British Columbia (CCBC), a community organization that sought to use Omeka S for its own archives but also to use it as “a community platform, where our members and their organizations can find a home for their collections, photographs, or records which they wish to share with the world.” [3]
Omeka S Access Control Scopes
Omeka S is a content management and publishing system with two discrete areas of content generation. One area, the site domain, resembles a standard content management system where users combine prose, images, and other interactive content together into web pages and navigation structures. The other area, the resources domain, includes tooling to describe cultural heritage items using linked open data schema. When building content in the site domain, users can populate pre-built content blocks with the cultural heritage items developed through the resource domain.
Omeka S has one primary access control system that manages user access within each of these domains and several ancillary access control systems that provides finer, more nuanced access control.
User-based access control systems
In the primary access control system, administrators assign users a role when their accounts are created, and the role determines the user’s privileges for all resources and all sites. A secondary access control system allows administrators to grant a user elevated privileges for a specific site. In both of these systems, the access rules are applied to an individual user to help scope what that user can do. The first system, the user’s role provides relatively coarse control because the permissions granted apply universally to all resources and sites. The second system, elevated site permissions, provides finer control by allowing administrators to elevate access for specific sites. But within the resources domain, there is no finer control system to limit which users can access which cultural heritage items. This approach is well-suited for organizations that share a pool of related cultural heritage resources and build one or more sites around those resources. But it is not well-suited for highly discrete projects, like those produced by a press, where users describe unrelated resources and construct unrelated sites because there is no way to group and isolate access to those unrelated resources from one another. Instead, since it is only the coarser of the user-based access control systems that determines how a user can interact with resources, if a user needs to have the ability to edit a colleague’s resource, they must be granted the ability to modify all resources generated for all projects.
In the terminology of access control systems, the principle of least privilege stipulates that “a security architecture should be designed so that each entity is granted the minimum system resources and authorizations that the entity needs to perform its function.” [4] In these terms, an organization using Omeka S to generate highly discrete projects would need some mechanism to limit a user from accessing resources unrelated to their project.
Site-based and resource-based access control systems
There are two additional access control systems worth mentioning that also help scope and organize sites and resources in Omeka S: the Site Item system and item set openness. The Site Items system allows any user with sufficient access to a site (granted either by their core role or through the site user system) to determine which items are “attached” to a site. This essentially controls which resources the site can access. Functionally, attaching items to a site creates a filter for queries made for items while interacting with that site. This affects which items the public sees when they browse or search the site, and what items content creators see when building components for that site’s pages.
The final access control system is called item set openness. Item sets are collections of items, and content creators can set individual item sets to be “open”, meaning that any other user with item creating or editing abilities can add items to the set, or closed, meaning that only they (or administrators) can add items to the set. This provides a modest level of access control in the item domain at the expense of needing to add collaborators to each item set individually. And this doesn’t account for our primary concern; namely, how to permit users to edit the resources created by some colleagues but not others.
Shortfalls in existing access control systems
The ability to scope certain items to a site, along with the ability to elevate a user’s access to a site, help to mitigate the drawbacks we outlined in the introduction: dealing with unwanted changes and sorting through irrelevant content. However, this only applies to a user’s interactions with the site domain and not the resource domain. When creating and managing items, users will still have an unfiltered view, and editing items made by other users is still an all-or-nothing privilege.
The mix of pre-built access control recipes through user roles and hyper-granular access control mechanisms that must be set up individually through various interfaces makes for an overall access control system with a relatively steep learning curve that requires interacting with several systems, perhaps by several people, in order to produce the desired effects. So, in addition to providing walls that would clearly separate content that belonged to different projects, our solution would also, ideally, provide a more streamlined approach to permission setting.
Gathering Project Requirements
We began planning this work in the context of the library press, but, in the spirit of free open-source software, we also wanted to support community needs if they were similar enough to be encapsulated by a design that met all our own criteria without becoming substantially more complex. In our judgment, this project would be a significant investment in time and resources to make Omeka S suitable for the library’s press. And if a relatively small additional investment could make the resource suitable for other use cases, that would make the additional investment worthwhile. So, in addition to gathering needs from press staff, we reviewed the Omeka S forums for posts that seemed to be expressing needs similar to our own.
We identified and reached out to three forum users based on this search, received feedback from two, and successfully recruited one of them to be our first beta-tester. From that, we developed an additional use case where a single Omeka S instance served as a campus level resource for class projects where each student or student group would form their own scope, or in the language we were developing for our solution, their own Team.
During this process, another use case emerged at our institution in the form of a digital exhibits strategy that leveraged Omeka S as a content platform. In this instance we determined that library units would form their own Teams. During our investigation of this use case, we determined that graduate assistants, who sometimes work for more than one library unit throughout their tenure, would need the ability to switch their Team contexts.
Institutional and Sustainability Requirements
In addition to the requirements derived from digital production workflows, we needed to make sure the design was devised as part of a software development lifecycle that the Library could support and fit the sustainability goals of IOPN.
Risks
Our major concerns about this project related to the long-term maintenance of the customization and our ability to ensure it would remain compatible with future changes made to the source code. We were aware of similar projects whose customizations became increasingly difficult to integrate with updates made to the codebase by the upstream source until the two were irreconcilable. We judged this to be a serious risk for this project in both the probability and impact of irreconcilable drift. Because the changes we proposed would alter the core business logic of the software, we felt that the likelihood of this drift was high. Additionally, because the position of the research programmer tasked with developing the module was grant funded and temporary during this development, we evaluated that any incompatible drift would be unrecoverable if the funding lapsed and the position were not extended. We therefore included a sustainability component that required that these enhancements could be able to be turned off easily and without adverse side effects. We initially judged adverse side effects to be anything that would change the public presentation of content. We have since expanded the definition to include any effect that would force administrators to recreate site filters or permissions with the Omeka native features, like site permissions.
Implementation
Luckily, Omeka S has a convenient utility for packaging and integrating additional functionality through a module manager and a method for introducing data and logic into the core code through an event system. [5] These two features allow developers to generate new pages and features and to modify the existing pages and existing behavior in the core software without directly editing the source code. As a result, the modifications can be easily removed, which is exactly the characteristic we needed.
Module code is kept in its own subdirectory where it can define its own logic and use the logic of the core software. Behaviors defined in the module are integrated with the core software through a module manager. Modules tell the module manager how their behaviors should be integrated through a configuration file. This permits modules to, for example, add additional pages and menu options to the administrative interface and control those pages.
The event system allows the module to access and alter behavior and data in the core software. There are three basic elements in the event system, summarized below from the source documentation:
- Events: PHP objects that contain information about operations being executed
- Listeners: callback functions that react to events
- Shared Event Manager: a mediating service that fires events and tells listeners when events have been fired. [6]
Server events are components that publicize information to a shared event manager when specific code is executed. Modules can listen for these events; read and modify the information publicized by the event; and execute their own operations after the event. This permits a module to, for example, add an element to an existing form or execute code during an API operation.
Once installed in its subdirectory, the module can be activated, deactivated, and configured by user administrators through the graphic user interface. This makes them ideal for our needs because it can be disentangled from the core software without expert assistance, and it can be easily shared with other institutions.
Turning Requirements into a Design
We sketched several broad types of use cases and different organizational approaches that we finally distilled into four workflow models.
Primary Workflows
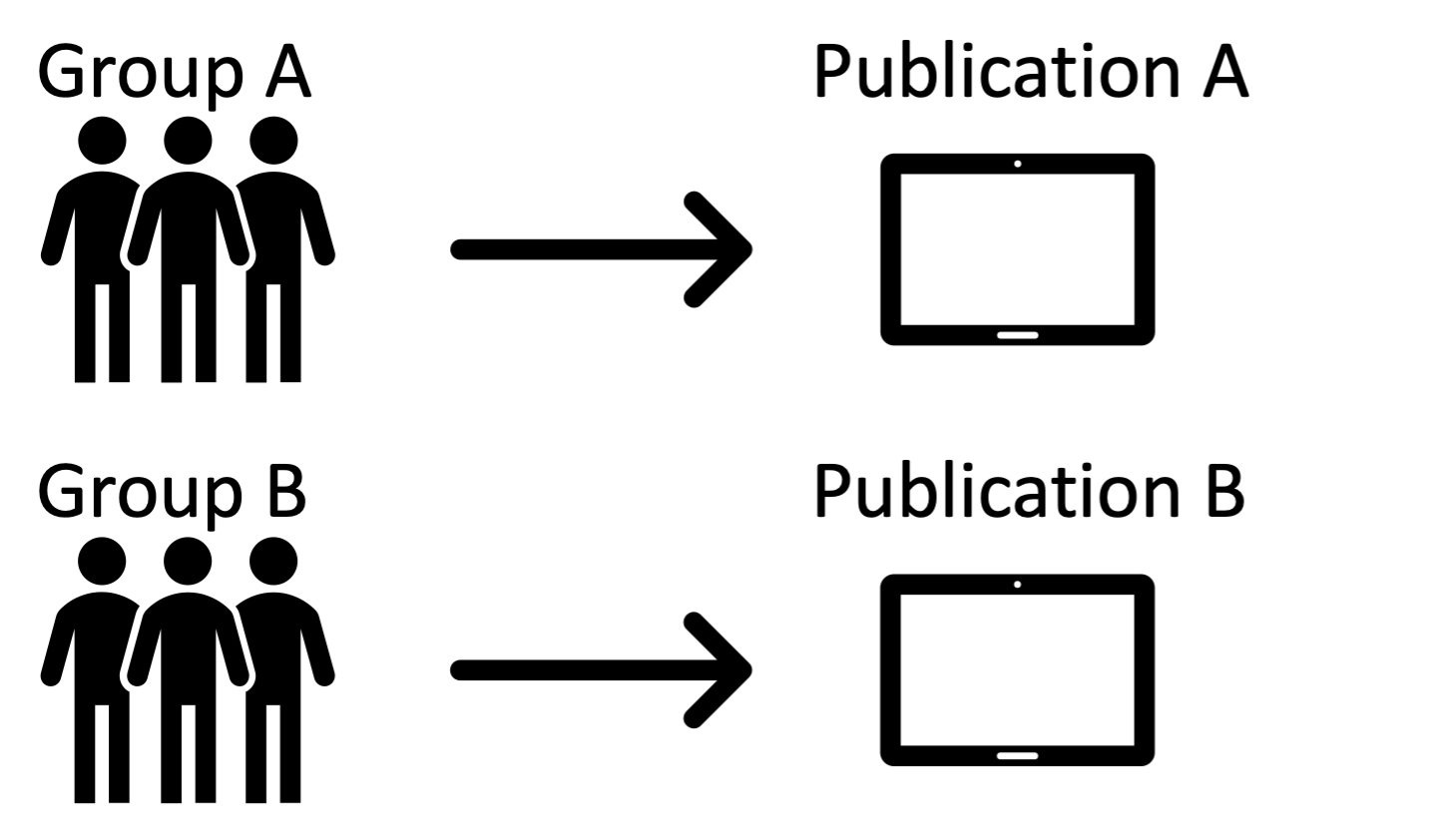
Figure 3. Workflow Model 1, featuring siloed projects. In this model, two entirely different groups produce two completely independent publications.
In Workflow Model 1 (Figure 3), one or more users form a team to work on a project whose resources and site(s) are totally independent from other projects developed on the same Omeka S instance. This would serve our main use case in IOPN where we host digital publications, as well as an additional use case we identified from the community where a university library’s Omeka S instance is a hub for individual or group student projects. The Craft Council of British Columbia describes an iteration of this workflow on their Omeka guide for members. In CCBC’s implementation, various groups form teams where they build content that populate one or more sites. [7]
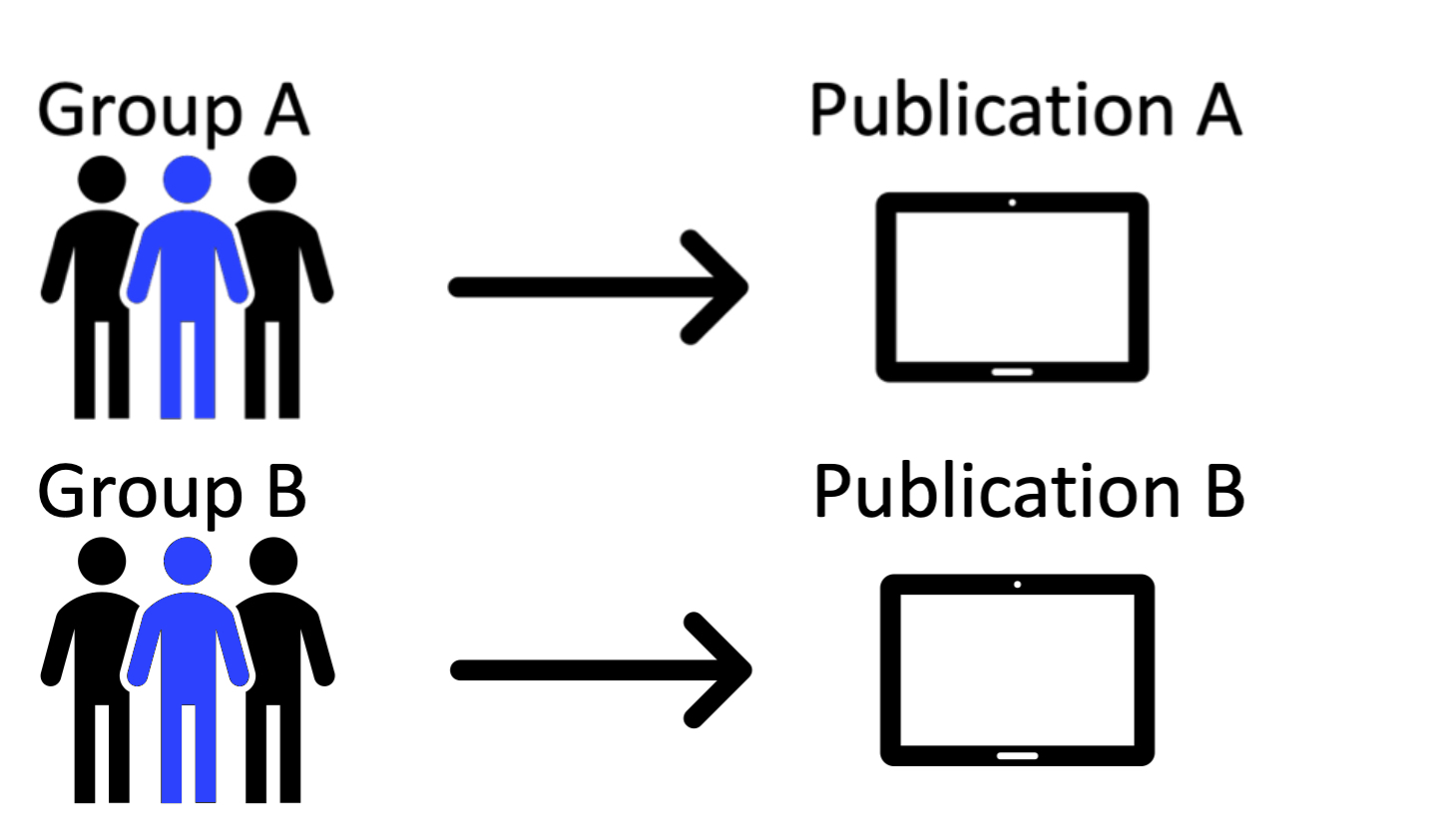
Figure 4. Workflow Model 2, featuring a user who is part of multiple teams. In this model, two different groups with one member in common produce two completely independent publications.
We also needed to account for instances where a single individual might be involved in more than one project, as shown in Workflow 2 (Figure 4). This is an edge case for the previous workflow where, for example, a student might be assigned an Omeka S project in more than one class simultaneously. The student could then toggle between their teams through a user interface, change which is their currently active team. Additionally, one author might produce more than one publication with the press throughout their career. So, we needed a way to segregate project resources and manage user privileges without forcing users to create a new account for each project. The ability to belong to and switch between multiple Teams also helps administrators with tasks like troubleshooting and pre-publication review.
Other Workflows
Those are the two workflows that we imagined we would definitely need to support. But we didn’t want to eliminate Omeka S’s facility for reuse and collaboration, and we outlined two other kinds of collaboration that seemed likely in the institutional settings we were designing for.

Figure 5. Workflow Model 3, featuring two different groups who share a group of resources but produce two otherwise different publications.
In Workflow Model 3 (Figure 5), multiple teams work with a shared set of resources and curate them into two different presentations. This might be appropriate in a classroom setting where students were set to provide an academic treatment of a pre-made collection of resources. The students could be restricted from editing any of the resources and would instead build digital exhibits around the content.
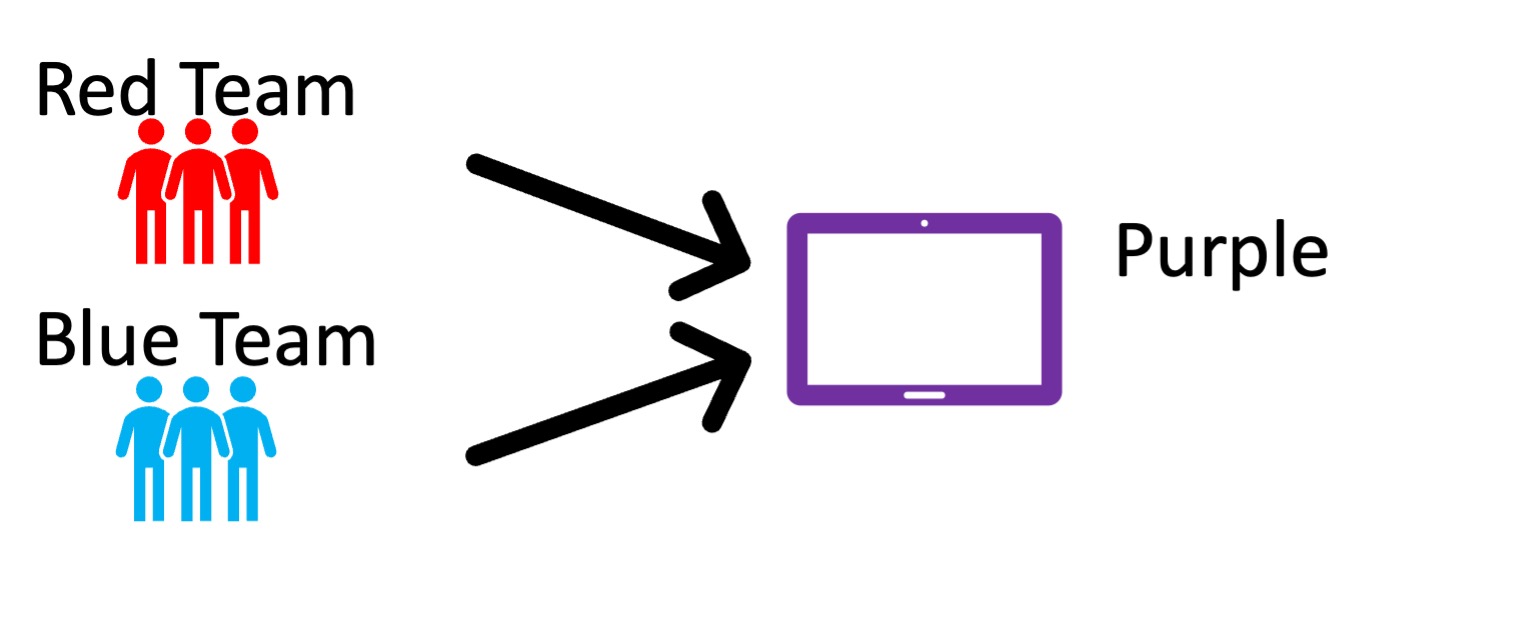
Figure 6. Workflow Model 4, featuring two different groups with separate resources but who collaborate on production of a site.
In a similar configuration, Workflow 4 (Figure 6), two teams working with distinct collections of items blend them together into a cross-discipline curation. This might be appropriate when making a discovery interface or exhibit around a large and diverse collection that requires many different subject matter experts or subject matter teams to describe items. Each subject matter team could have their items separated in the resource domain, but then all the items could still be combined into a single curation of the content or a finding tool.
Data Model
We derived the following criteria from these model workflows to determine how the data schema was designed:
- Users could be added to and removed from teams
- Users have one currently active team at a time. The active team filters the sites and resources they see at a particular moment.
- Users can change which team is currently their active team
- User could have distinct roles within their different teams
- Team Roles could be customized by administrators
- Items could be associated with multiple teams
- Sites could be associated with multiple teams
- Vocabularies and Modules would remain system-wide, shared resources
Users, resources, and sites would have a many-to-many relationship with teams through a join table, and team roles would have a one-to-many relationship with team users. A user would need one team to be designated as their active team (i.e., the one they are currently working in) and that would serve as the basis for filtering backend resources. Appendix A shows the Entity-Relationship Diagram for this model.
Controller and View Interventions
Nearly all interactions between the data layer and controller layer in Omeka S are mediated through an API that includes events at key stages. For content creators, the module would need to filter the results returned based on the current user’s team for read operations, and it would need to check the user’s current active team role for update, delete and create operations. In addition to users, sites also need to filter items based on their own context. But unlike users, sites don’t have a current team. Sites that belong to more than one team should see all the items associated with all of their teams. These filtering operations could all be accomplished through the events system by listening for the appropriate API event (See Figure 7).
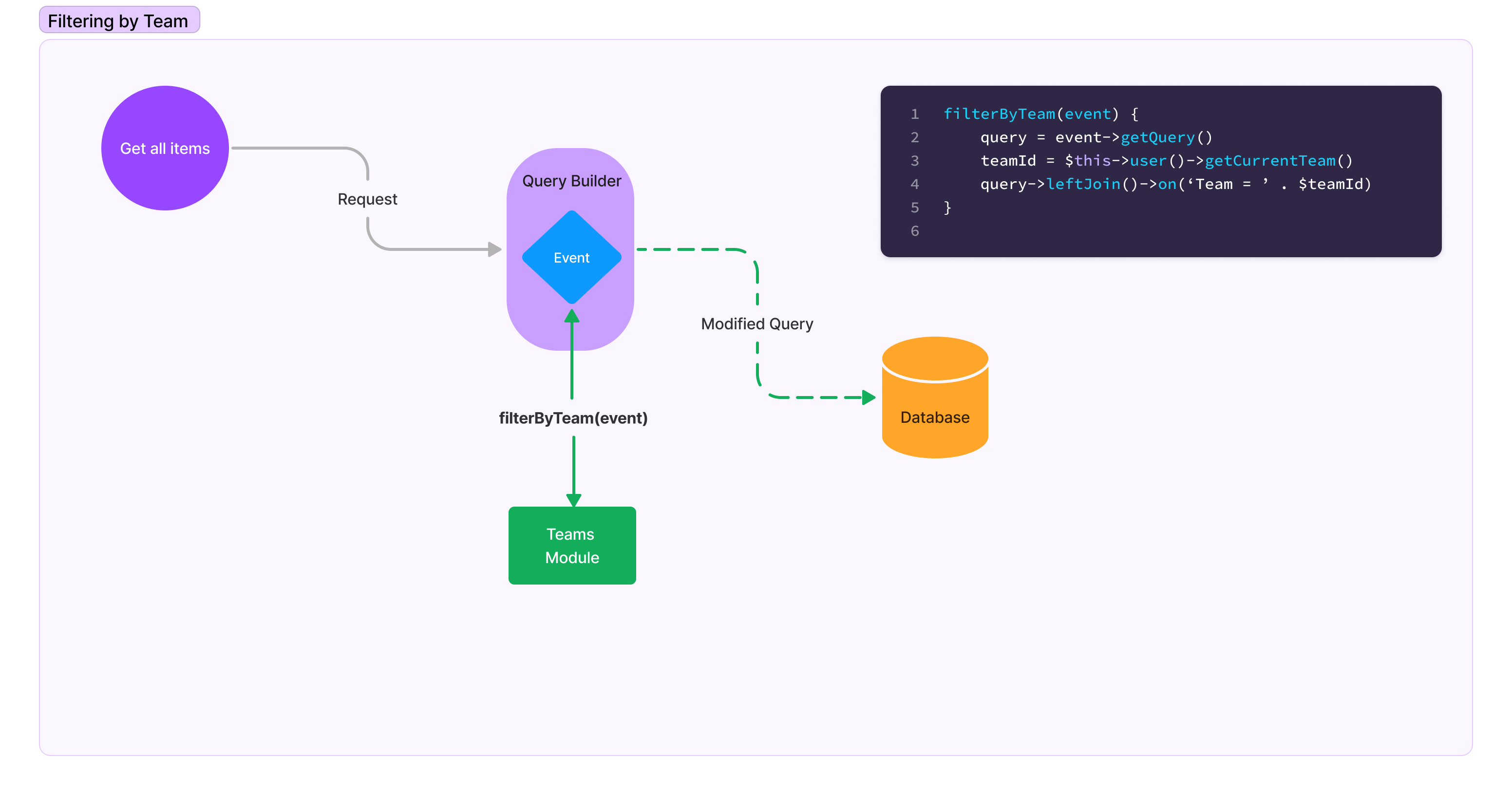
Figure 7. The Teams module listens for an event in the part of the API that builds database queries. The Teams module modifies the query so that the results are filtered by the user’s current team.
Events also help the module introduce components into the view layer as well as read and process data sent from the view layer to the controller. For example, a team toggle control needs to be added to every admin page where users see results filtered by their team, and team fields need to be added to forms (See Figure 8). Additionally, when the forms containing team elements are submitted, the Teams module needs to read and process the relevant data (see Figure 9). Where events were not available, the Omeka development team was willing to accommodate our request by adding them.

Figure 8. When the user requests a view that should have a Team component, that view triggers an event that allows the Teams module to add the component to the view. Here, the Teams module also gets the user’s current team so that it can configure the component properly.

Figure 9. When items are successfully created, a response with the item’s id is sent back to the controller. That response triggers an event that causes the Teams module to add an entry to the Team Resources table.
Accounting for Risk
We knew that the module approach would afford the ability to easily disable the scoping system. But in order to satisfy our sustainability requirements, the whole application would need to operate no worse than it would have operated had the module never been installed. So, when turned off, the public facing sites should still display the same content on pages and in searches, and users should still be able to conduct their work without additional permission interventions from administrators.
This had critical repercussions for the design. It would not be possible for this scoping system, which we began to call Teams, to inject changes into the existing access control system to permit users to do something that wasn’t already permitted by their core Omeka S role because users would then not be able to complete those tasks if the scoping system were suddenly disabled. Instead, users would need to start with enough permissions in their core Omeka S role to complete any tasks they might need to do. Then, Teams would act as a second layer of access control filter, preventing users from doing things that weren’t permitted by their team role and their current team context. We found this “deny everything unless” approach to be reasonable because it also simplified the administrative workflow.
Users would all be added as Site Managers (now called Supervisor), and then their abilities would be throttled down by the Teams module. So, if Teams had to be deactivated, we would simply be in the same situation we would have been if we had set up user accounts without Teams in the first place. Not ideal, but still functional.
Initially, we were not able to satisfy the second component, that public facing sites feature the same content and search results if the module was turned off. When we began working on this project, Omeka afforded the ability to limit which items showed up in public facing searches via an advanced search query that site administrators could define for their sites. There was no simple and reliable way to translate the team relationships into such a query.
However, relatively early in our initial use of the module, Omeka S version 3.x introduced a more robust method for associating items with sites (described above as the Site Item access control system) that persisted these associations in the database through a join table—very similar to the approach we developed through teams. The simplest way for us to respond to this within the scope of the module would have been to ignore it. So long as no item-site relationship was created, this new feature would essentially remain dormant while Teams continued to perform its function. However, we saw this as an opportunity to further mitigate the support risk by providing a way to preserve site-item relationships if teams were disabled, so long as we could keep the two associations in sync. While this posed considerable challenges, we began to anticipate a possible future where Omeka S would develop enough scoping features that our module would no longer be needed. And the best way for us to prepare for that happy eventuality was complimentary to our risk mitigation strategy because both prepared for the same condition, turning the module off.
Findings
The feedback from users who were already in the IOPN production platform when Teams appeared suggested that the module accomplished the primary goals of simplifying the user experience for content creators in a multitenant use case for Omeka S. We found that the module system in Omeka S is extremely well supported, particularly through event coverage. The Omeka development team releases many of their own modules, and this likely contributes to the exemplary support. We discovered that with such a system it is possible to make significant changes to the software’s core logic while avoiding fork-drift, even with a solo developer. However, while a well-supported module system permits this risk to be mitigated, it does not guarantee it. One unexpected source of mitigation to this risk came from supporting users outside our organization.
In practice, we have found that even limited use of the module by groups outside our organization has helped ensure that our implementation remains compatible with the upstream source. For one, this eliminates any temptation to solve a tricky problem by modifying the core software and forces you to find a solution that can work from inside a module. It also speeds up the discovery of issues through novel use cases. In one instance, an organization that was using the module noticed that items generated using the Submissions module were not added to any team. Addressing this issue, which we would likely never have discovered, helped keep the module more aligned with the core software and its ecosystem. While our motivations were more-or-less altruistic when we began thinking about supporting community needs, we found that the process of outreach and support prevented us from making time saving choices that would increase drift.
Conclusion and Future Work
Open-source communities vary widely depending on the organizational structure of the original developers and how open the developers are to contributions from the user community. Like many other projects, IOPN’s approach as a library-based press has depended upon adoption of open-source software while actively contributing to the software communities, whether through pull requests for bug fixes, reporting issues, or, as supported by the Omeka infrastructure, the development of an independent module, Teams, as a contribution to the Omeka user community. This allows the press to advance its mission without reinventing the wheel and also to positively impact the broader user community for these systems. This approach has been particularly fruitful with Omeka S because its software architecture provides great support for extensions and the maintainers expect, encourage and make a deliberate effort to accommodate community contributions.
The module has reached a stable state where it meets our needs and has entered the maintenance stage of its primary development lifecycle, which requires less developer time. Throughout the active development stage we worked with several external users who provided excellent feedback, testing, and bug reports. This demonstrated to us that supporting more users helps improve the product, but it also costs time and resources. In some cases, our relatively limited user pool would have eventually stumbled across many of the issues these external users encountered, but in many cases the external uses were exploring edge cases that we may not have ever come across. So, we came to realize that more users increases the number of issues that are uncovered and the velocity with which those issues surface. This realization caused us to be cautious about how much we promoted the module at first out of concern that more users might swamp our capacity while we were still ironing out the details. We remain interested in other use cases and users outside our organization, and now that the primary development work has concluded and freed up some capacity, we will be publicizing the module more. As it is currently configured, the module is easiest to set up and use on new installations. We anticipate that, if there is interest from users of existing installations, they will reveal needs that we have not anticipated for this particular workflow.
Appendix A
Appendix A: Simplified Entity Relationship Diagram (PDF)
Notes
[1] https://omeka.org/about/project/
[2] https://github.com/UIUCLibrary/teams
[3] https://craftarchive.ca/s/landing/page/about
[4] https://csrc.nist.gov/glossary/term/least_privilege
[5] https://omeka.org/s/docs/developer/modules/#introduction-to-modules; https://omeka.org/s/docs/developer/events/server_events/
[6] https://docs.laminas.dev/tutorials/event-manager/
[7] https://craftarchive.ca/s/intro/page/structure
Acknowledgements
Funding for early work on this project was provided through the generosity of the Mellon Foundation. The authors thank the prior members of the “Publishing Without Walls” grant team who helped inform this project, particularly Christopher Maden and Janet Swatscheno. Thanks to John Flatness of Omeka for providing technical advice and troubleshooting as well as to @Daniel-KM whose Omeka S module Group served as a template for the Teams module.
About the Authors
Alexander Dryden (adryden3@illinois.edu) is the Research Programmer for Scholarly Communication and Publishing, University of Illinois Library.
Daniel G. Tracy (dtracy@illinois.edu) is Associate Professor and Head, Scholarly Communication and Publishing, University of Illinois Library, where he leads the library-based press, the Illinois Open Publishing Network (IOPN).

Subscribe to comments: For this article | For all articles
Leave a Reply