by Kent Fitch
Motivation and goals
Our expectation of how search works changed ten years ago when Google introduced their “Hummingbird” search algorithm [1]. Our experience until then was that you needed to formulate your search query using some exact words that appear in the document you were seeking. Ten years later, we’ve been further trained by “OK Google” and continuous improvement in search algorithms to find what we need by issuing a query defining our intent rather than exactly matching words, and increasingly, by using natural language to simply ask a question.
Google’s Knowledge Graph [2] introduced in 2012 taught us to expect direct, summarised answers to queries, and now, Bing and Google are both anticipating a near future where the traditional “ten blue links” of a search result are superseded by text built by extracting information from the documents found by the search, enriched by the context provided by a knowledge graph and presented as an answer to the question inferred from the search query.
The gap in capability between the almost universally used search engines that set community expectations and libraries and related repositories has continued to grow. That gap, opened by PageRank [3] 25 years ago, is now a chasm.
To provide modern and efficient discovery services for their communities rather than risking mutual abandonment by becoming perceived as baffling backwaters of byzantine business-rules redolent of a bygone era, libraries must adopt the same core search technologies used by the commercial services: semantic search, knowledge graphs and generative AI to support summarisation and chat.
Ten years ago, even semantic search would have been an impractical goal: the technology was specialised and expensive to implement and wasn’t well advanced. Just two years ago, attempting to implement much of this capability was more like a “science project” than a routine information technology undertaking. But as quickly and surely as public expectations have changed, so has the accessibility of the technology: the use of AI has spread from university labs and tech leviathans and is now becoming commonplace, further increasing the pressure on the library community to embrace its effectiveness for the benefit of the public.
This article does not provide definitive answers to the many questions raised when introducing semantic search and chat-based question answering across a digital repository. Rather, it presents findings from a preliminary exploration in the hope of encouraging widespread experimentation with this rapidly evolving technology so that the benefits it will deliver to library communities can be expedited and shared.
The context for the technologies investigated and described in this article is a repository of newspaper articles. The main investigations were performed on a very small subset of the National Library of Australia (NLA) digitised newspaper repository. This study examined the feasibility and effectiveness of:
-
- Semantic search
- Named entity identification and disambiguation of entities described by Wikipedia
- Question answering, summarisation and a “chat” interface
A further investigation of the feasibility of scaling semantic search to the full NLA digitised newspaper repository (about 220 million articles) was also performed.
Context
The National Library of Australia (NLA) digitised newspaper repository forms the most accessed component of their Trove service [4]. It contains over 220 million newspaper articles published since 1804 in over 1,800 separate newspaper and gazette titles. During May 2023, Google Analytics recorded about 1.2M searches on Trove, and 3.8M pageviews of newspaper articles. The repository is popular with family researchers looking for information using personal names and place names (particularly in birth/death/marriage notices) and is also widely used by academics and general researchers. An indicator of Trove’s popularity is that when government budget measures threatened the ongoing sustainability of Trove in 2022, a petition calling for adequate funding received almost 34,000 signatures [5].
From the Trove newspaper corpus, 45,494 news articles from the title The Canberra Times from the year 1994 were extracted. Articles of type advertising (display and classifieds) were excluded as the intent of this prototype was to focus on the benefits of semantic searching on news rather than on “births, deaths and marriages” searches which tend to be more “known item” searches on people and places. There were many uncorrected OCR errors in the extracted text.
To evaluate the practicality of name disambiguation using Wikipedia articles, 38,359 articles about organisations and 155,781 articles about people were extracted from an August 2022 Wikipedia dump, limiting the extract to articles that contained the word “Australia” or contained at least 3,000 words. The goal was to attempt to include all Australian people and organisations, and all “prominent” (worthy of 3,000 words) people and organisations even if non-Australian. Heuristics were used to classify articles as being of interest to this trial (ie, about people or organisations, not place names).
Approach and results
Named entity identification
The news articles were processed using the Stanford NLP library [6] to identify entities of type PERSON, LOCATION, ORGANIZATION and MISC. Common non-specific entities such as “he”, “his”, “she”, “her”, “hers” were dropped. Minor processing to encourage better uniformity (particularly in the face of OCR artefacts) was performed, eg, “NSW” was changed to “NEW SOUTH WALES”, “MEL BOURNE CUP” was changed to “MELBOURNE CUP”.
Embedding creation
The text from each news article was used to create an “embedding”, which is a vector characterising the text as a point in a high-dimensional space in such a way that texts which have similar meanings have vector representations which are “close” in that multi-dimensional space.
Embeddings can be created in many ways, but those created by transformer-based large language models (LLMs) have been successfully used as a foundation for semantic search. The better the embedding represents the meaning of text, the better a semantic search using a set of those embeddings is likely to be. As well as characterising text, many models can also create embeddings for images, hence mapping images and text to a common high-dimensional space and enabling searches across both images and text. Although not the immediate focus of this experiment, the Trove newspaper repository contains millions of newspaper images (such as photos published in newspapers) and other sub-repositories in Trove contain tens of millions of other images, so an embedding model able to characterise images and text is of interest.
Although it is impossible to visualise points in a high-dimensional space, this simplification may help:
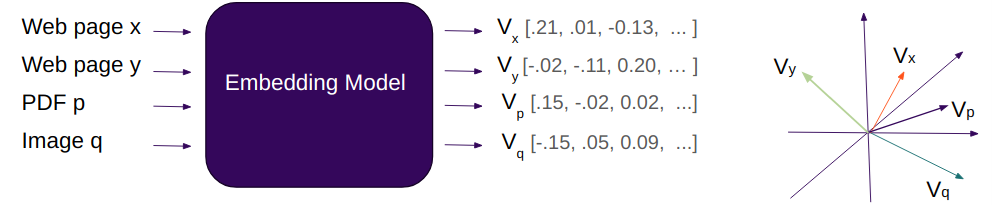
Figure 1. Simplified representation of embeddings.
Here, four input documents (three of text, one image) are each separately processed by an embedding model to produce four embedding vectors. If we just look at the first three values and treat them as coordinates in three-dimensional space, we can imagine how the four points represented by those coordinates could be compared for proximity, and how, if the embedding is successful in representing texts or images as vectors, it would be possible to find things similar to some other thing.
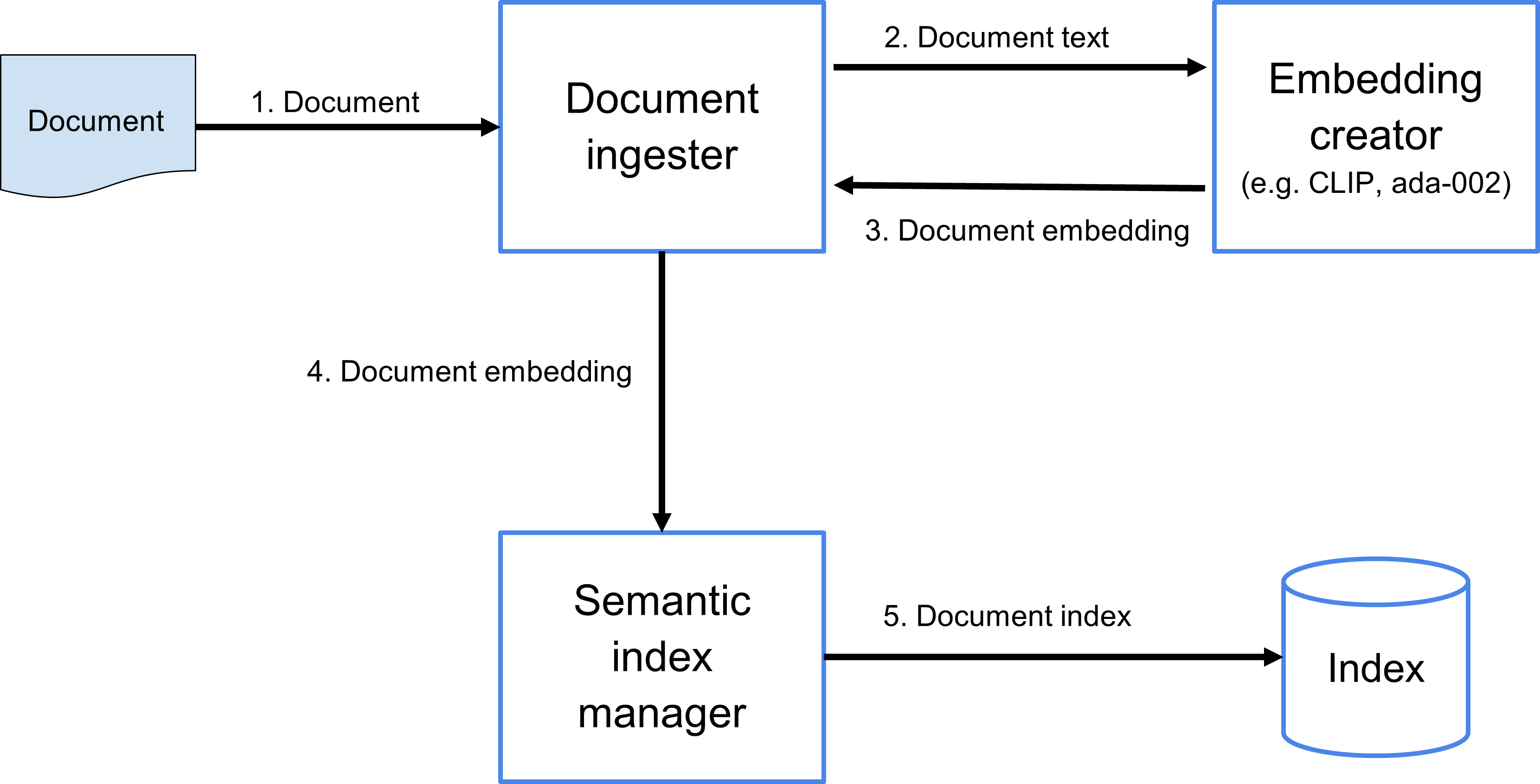
Figure 2. Searching data flow.
A semantic search engine accepts a query (a text string, or possibly an image) and creates an embedding for that query, just as it had previously created an embedding for the documents it stores. It then finds the closest document embeddings to that query embedding in the high-dimensional space of the embedding model, and returns the closest documents, ranked by the proximity of their embeddings to the query embedding.
Figure 3. Simplified representation of embeddings.
It must be noted that the language model used to create the document embeddings must be also used to create the query embeddings. For example, if OpenAI’s ada-002 was used to create the document embeddings, ada-002 must also be available and used when creating the embedding of the query to be compared to those document embeddings. For large or long-lived repositories, the ongoing availability of the language model and associated software required to create embeddings is a key driver of the choice of the embedding to be used.
Embeddings map text to a vector space of hundreds or even thousands of dimensions. A higher-dimensional space derived from a very large language model, well-trained and well-aligned with human understanding, can typically represent more subtly of meaning than a lower-dimensional space. However, more dimensions are more expensive to store, index and compare.
For the proof-of-concept, three embeddings were tried, derived from:
-
- The BERT language model – a very early transformer LLM.
- CLIP ViT L-14 [7]: maps image and text to a single vector space. Although not the “best in class” sentence transformer, CLIP ViT L-14 performs well, is quick, and importantly for this proof-of-concept was very easy to set-up using “CLIP as a service” [8].
- ada-002: a recent and highly-regarded embedding provided as a commercial cloud service by OpenAI.
Evaluation of BERT was discontinued because qualitative performance was inferior to CLIP. CLIP produces embeddings of 768 dimensions, and ada-002 produces 1,536 dimensions. Qualitatively, ada-002 embeddings are more useful for semantic search, but its extra resource requirements, cost and non-open nature raise concerns for a repository with lots of data and a long life.
Each language model has a maximum size of text it is able to process when creating an embedding. Text beyond that maximum is ignored and does not contribute to that embedding. The ada-002 embedding can accept about 6,000 words which is more than almost all newspaper articles, and even for longer articles, probably perfectly adequate (it is hard to imagine an article that buries the lede that deep).
However, CLIP, like many other embedding-generating sentence transformers, is limited to about 70 words. It is not obvious how best to process longer text. One approach is to generate and index multiple embeddings per article. For example, for an average-length news article of, say, 500 words, generate 8 embeddings and index all of them with the article and somehow at query time, combine the similarity scores for each embedding to generate an article match score. However, it is important to “break” the embedding text on sentence boundaries, as sentence transformers are trained on sentences, not arbitrary extents of text. Also, it isn’t obvious that splitting “meaning” across separate embeddings will allow that meaning to be represented by summing or otherwise combining the match scores of the component embeddings. And finally, such splitting greatly increases the size of the embedding index and will negatively affect performance.
Another approach is to somehow merge the multiple embeddings: that is, in the above example, generate perhaps 10 sentence embeddings then add the vectors together (and then “normalise” this summed vector to have a unit length required for best performance by embedding index engines).
This proof-of-concept uses a “hybrid” approach for CLIP: it generates an embedding for the first (up to) 70 words honouring sentence boundaries which is indexed separately, and also produces a summed embedding from multiple sentence embeddings from the entire text. Qualitatively, the use of the first 70 word embedding was unnecessary – summing the embeddings did not seem to “blur” or “smear” the meaning as much as was feared.
The choice of embedding model is an important decision with significant consequences discussed below.
Embedding indexing
Embeddings can be indexed and searched using one of several specialist “vector” databases (such as Pinecone, Milvus and Weaviate) or by using vector extensions to existing relational databases (such as the pgVector extension for Postgres) and document stores (such as Elastic and Lucene/Solr). As Lucene/Solr is an existing key component of NLA’s technology stack, it was chosen for this proof-of-concept and performed well and “out of the box” with the CLIP embeddings. Lucene implements “Approximate Nearest Neighbour” (ANN) search using the Hierarchical Navigable Small Worlds (HNSW) search graph [9].
The ada-002 embeddings however are longer than Lucene’s current vector limit of 1,024 dimensions, and so required a trivial source-code change to enable.
Semantic searching
The proof-of-concept Lucene/Solr index of 45,494 newspaper articles contains two separate types of indices:
-
- “traditional” free text index able to support keyword and phrase searching and ranking based on relative occurrences of search terms in the index, the document and the document’s length
- vector index able to match a query embedding against all document embeddings to generate a similarity score used for ranking
Each type of index has strengths and weaknesses. Free text indices are great for exact matches on the words in the supplied query, and for “boosting” the ranking of documents where those words are found in more important fields (perhaps a title or abstract), or are found together as a phrase. Vector indices are great for finding documents that are “like” the query – not necessarily due to word matches, but by matching the meaning of the query.
An example of a good candidate for a text search is a name search – if you search for John Smith, you are almost certainly searching for a document containing those words very close together. It is unlikely there are useful “semantics” beyond that – that is, there are probably not “John Smith”-like documents that don’t contain those words close together.
Another possible example is a single-word search, such as kamikaze: it is likely that the searcher is looking for that exact word rather than content that does not contain that word but somehow represents the “spirit” or meaning of that word.
However, train crash is less clear cut, as the searcher is possibly interested in railway accidents or derailment or level-crossing smash or train smashes into bus or any other number of other slightly broader, narrower or related concepts.
As queries get longer, they tend to convey even more “semantic intent” that is impossible to honour with simple keywords, even when attempting to automatically expand the search with keywords.
For example, a search for articles using the fall of John Major (a prominent conservative British Prime Minister during the 1990s) conveys a clear semantic intent. If a patron walked up to a librarian and asked for content using that phrase, the librarian would have a good idea about what they were after. Performing this search on Trove (limited to 1993 Canberra Times articles to enable a comparison) produces results a user familiar with Google does not expect: many results have nothing to do with “John Major” – they just happen to have each of those 5 words somewhere in the article. Perhaps worse, many directly relevant articles are not found: perhaps they use ousting or downfall or undoing or unravelling or humiliation or collapse of support rather than fall, perhaps they describe the political pressure he was under in other ways.
The proof-of-concept explores a blended keyword and semantic search. It does this by:
- Issuing a “standard” keyword and phrase text search with standard keyword ranking.
- For each of the top-10 keyword-ranked results, fetch that document’s embedding and use this to issue a semantic search to find other documents with embeddings most similar to it. The intent is to “enrich” the result candidates by including documents very similar to those best keyword results but which may not contain all the keywords.
- Creating an embedding of the original search query and issuing a semantic search to find documents with embedding most similar to it.
Each of these searches produces a ranked list of documents with a search score (in this case, generated by Lucene). The score for the first search (the “standard” keyword and phrase search) is calculated by Lucene based on its default BM25 [10] ranking using keyword repository and document frequencies with a boost applied if all keywords were found nearby (ie, a phrase-like boost). The scores for the second and third searches are also calculated by Lucene based on the distance in vector-space between the embeddings of the search embeddings and the document embeddings. The proof-of-concept then applies a separate weight to the scores produced by the three types of searches and adds the results across all three searches to generate a document result set for ranking.
The three weights are referred to by the proof-of-concept user interface as:
- Keyword boost
- Keyword-found doc similarity boost
- Query similarity boost
Hence to perform a ranking purely on keyword score, set the second and third weights to zero, and to perform a ranking purely on semantic similarity to the query, set the first and second weights to zero.

Figure 4. Search results for the fall of John Major: pure keyword results on the left, blended keyword and semantic results on the right.
It is not obvious how to set the three weights. Empirically, a search using the CLIP embeddings benefits more from a lower relative query similarity boost than a search using the ada-002 embeddings, probably because the “semantics” captured in the ada-002 embedding of both query and documents are much better. Also empirically, a search on just one word, or on a “known item” such as a person’s name often gives better results when the scoring is dominated by keyword boost (but only when that word exists in the repository – see cybersecurity counter-example below)
Ranking of results is subjective and no formal recall/precision analysis has yet been performed.
It must be noted that the vector search algorithm used by Lucene, HNSW, does not guarantee to find the “most relevant” results, that is, the documents whose embedding vectors are closest to the query vector: HNSW is an “Approximate Nearest Neighbour” algorithm that trades accuracy against resource consumption (CPU, storage, I/O). However, if reasonable care is taken with HNSW index construction parameters and query parameters, HNSW is highly accurate.
A version of the proof-of-concept is available for demonstration here: http://nla-overproof.projectcomputing.com/knnBlend
A typical search demonstrating the comparison of keyword and blended results is this search using the query the fall of John Major: http://nla-overproof.projectcomputing.com/knnBlend?set=1994&embedding=ada-002&stxt=the%20fall%20of%20John%20Major
The following table is a summary of the first 50 results of each search using the ada-002 embeddings, showing how keyword results were “demoted” (rendered as with pink background in the blended results), “promoted” (rendered with light green background), and shows results only found by the semantic search (dark green background, designated as “knn”).
For example, the first keyword result (about the war in Bosnia containing comments by John Major) was demoted to rank 48; the second keyword result (about a fall in regional bank values that includes many occurrences of the query keywords but is not at all about the intent of the query) is demoted to rank 50; the fourth keyword result is promoted to rank 1; the 6th through 17th blended results were only found by a semantic search.
Table 1. Showing how keyword results where re-ranked after blending with semantic results
| Keyword search | Blended search | ||||
|---|---|---|---|---|---|
| Rank | Article | Re-ranked to | Rank | Article | Re-ranked from |
| 1 | INTERNATIONAL Bihac still under siege By KURT SCHORK SARAJEVO, Friday: Bosnian S | 48 | 1 | Jig is up for UK Conservatives BILL MANDLE THE BRITISH local-govern ment electio | 4 |
| 2 | BUSINESS AND INVESTMENT Regional banks shed value after rates increase By MICHAE | 50 | 2 | Major problems for unpopular PM ‘There is not much point in spending money on a | 5 |
| 3 | INTERNATIONAL Major warns Tories: EU yes or a poll – By RICHARD MEARES LONDON, F | 18 | 3 | Momentum against Major The administration of Britain’s Prime Minister, John Majo | 9 |
| 4 | Jig is up for UK Conservatives BILL MANDLE THE BRITISH local-government electio | 1 | 4 | The undoing of John Major Malcolm Booker THE CONSERVATIVE lead ers in Britain, a | 13 |
| 5 | Major problems for unpopular PM ‘There is not much point in spending money on a | 2 | 5 | Major’s fortunes turn around JOHN MAJOR must be almost unable, to believe his lu | 23 |
| 6 | Brambles 313m loss due to big abnormal SYDNEY: A huge abnormal loss and poor per | 72 | 6 | [Foreign Major’s moral crusade nauseating: Lamont LONDON: A bitter attack by Nor | knn |
| 7 | Hopes now ride on future of Falcon COMMENT By PETER BREWER By axing the Capri co | 73 | 7 | Seeds sown for Conservative uprising Major facing mutiny after EU climb-down LON | knn |
| 8 | Community services the key to more jobs JOHN QUIGGIN says only a major policy re | 74 | 8 | INTERNATIONAL Conservative crisis after Budget defeat By ALAN WHEATLEY of Reuter | knn |
| 9 | Momentum against Major The administration of Britain’s Prime Minister, John Majo | 3 | 9 | Major crushes Eurorebels for now LONDON, Saturday: The Brit ish Prime Minister, | knn |
| 10 | Market hits 14-month low as base metals bear brunt MELBOURNE: The Australian sha | 75 | 10 | INTERNATIONAL MPs expelled in row over EU Key win saves Maior Bv ALAN WHFATLFY L | knn |
| 11 | BUSINESS AND INVESTMENT Steel leads BHP to record profit MELBOURNE: Steel, backe | discard | 11 | INTERNATIONAL Major humiliated In local elections LONDON: In a humiliating setba | knn |
| 12 | BUSINESS AND INVESTMENT Coal ‘rabble’ irks union Australia’s coal industry was b | discard | 12 | INTERNATIONAL Major may face leadership test within weeks By DON WOOLFORD of AAP | knn |
| 13 | The undoing of John Major Malcolm Booker THE CONSERVATIVE lead ers in Britain, a | 4 | 13 | By-election disaster kicks off Major’s dice with voters LONDON: Prime Minister J | knn |
| 14 | State Bank sale to be finalised soon SYDNEY: The sale of the State Bank of NSW h | discard | 14 | INTERNATIONAL Tories sink into a moral stew Three MPs exposed . more rattling in | knn |
| 15 | Fears for peace push DUBLIN, Sunday: A dispute in the Irish Republic’s Coalition | discard | 15 | Unravelling not due to Major alone From HUGO YOUNG in London THE SLOW disintegra | knn |
| 16 | IN BRIEF QDL expands into Victoria BRISBANE: Pharmaceutical whole- – salcr and d | discard | 16 | British Tories rally behind their leader LONDON: John Major is expected to secur | knn |
| 17 | Elated RSL wins battle for Wake’s war medals By MARION FRITH A jubilant Returned | discard | 17 | Blair rides high on eve of conference as Major founders in sea of ‘sleaze’ By AL | knn |
| 18 | IRC decision gives all workers on federal awards 11 public holidays a year By MI | discard | 18 | INTERNATIONAL Major warns Tories: EU yes or a poll – By RICHARD MEARES LONDON, F | 3 |
| 19 | HISTORY Highlights in history on May 8: 1704: British forces under Duke of Marlb | discard | 19 | INTERNATIONAL Major on the ropes as bribery claim Minister resigns By MICHAEL WH | 22 |
| 20 | AIDS patients ‘incorrectly’ diagnosed By CATRIONA BONFIGLIOLI, AAP Medical Corre | discard | 20 | INTERNATIONAL Major stakes Govt on high-risk Bill By DONALD MACINTYRE LONDON, Th | knn |
| 21 | BUSINESS AND INVESTMENT ; i, Colonial Mutual rejects State Bank sell-off claims | discard | 21 | INTERNATIONAL EU vote revolt poses poll threat to Tories By RICHARD MEARES LONDO | knn |
| 22 | INTERNATIONAL Major on the ropes as bribery claim Minister resigns By MICHAEL WH | 19 | 22 | MPs cold on heat tax LONDON, Tuesday: The Brit ish Prime Minister, John Ma jor, | knn |
| 23 | Major’s fortunes turn around JOHN MAJOR must be almost unable, to believe his lu | 5 | 23 | Fresh row adds to Tory woes BOURNEMOUTH, England, Wednesday: Britain’s ruling Co | knn |
| 24 | COLLECTABLES Dion Skinner Logos of old still capture the mind IN THE world of ad | discard | 24 | INTERNATIONAL PM fancies a return to banking The British Prime Minister, John Ma | knn |
| 25 | PM backs rate rise as recovery tool By, IAN HENDERSON Prime Minister Paul Keatin | discard | 25 | Elections Speaking in the House of Commons, Labour leader John Smith described t | knn |
| 26 | US economy like banker’s dream THE United States economy is showing signs of tur | discard | 26 | Heseltine front-runner to take over as leader The president of the British Board | knn |
| 27 | Norman struggles, six shots off pace PITTSBURGH, Pennsylvania: A disappointed Gr | discard | 27 | Cloud is cast over Major’s morals drive LONDON: Two forced re- signations from t | knn |
| 28 | Saints fall victim to resurgent Hawks MELBOURNE: Pundits proclaiming an end to H | discard | 28 | Heseltine rises from the political grave LONDON: Michael Heseltine, once the gol | knn47 |
| 29 | , . , BUSINESS AND INVESTMENT Sale of State Bank still not a sure thing SYDNEY: | discard | 29 | Avoid a security over-reaction THE ATTACK on Prince Charles has set off the pred | knn |
| 30 | B U SIN E SSL AN D INVESTMENT Bargain hunters help market rally Shares recover a | discard | 30 | WORLD BRIEFS Major hangs on as party leader LONDON: Prime Minister John Major es | knn |
| 31 | INTERNATIONAL Villagers flee enclave, rebel onslaught Serbs move on UN safe have | 76 | 31 | They said it It could only have been expected … it’s the fault of the Governme | knn |
| 32 | Fawcett quits in rift over FAL plans PERTH: David Fawcett, the man viewed by man | discard | 32 | Racist row over speech LONDON: A high-flying minister has forced Prime Minister | knn |
| 33 | Adsteam shares take a dive SYDNEY: Shares in the debt laden Adsteam group plunge | discard | 33 | RICHARD FARMER Liberals cannot merely sit back THE LIBERAL Party’s election stra | knn |
| 34 | Power plays of men and women Oleanna, a piece about sexual harassment, is meant | discard | 34 | Richard Farmer Economic news of no help to Libs AT FIRST blush an Oppo sition ma | knn |
| 35 | US turnaround leads Australian market recovery SYDNEY: The Australian stock mark | discard | 35 | All hope is not gone for Liberals Peter Cole-Adams I.F THE Liberal Party was in | knn |
| 36 | Bannister and friends remember a record OXFORD, England: After 40 years, about t | discard | 36 | Beggars ‘offend’ British leader LONDON: The British Prime Minis ter, John Major, | knn |
| 37 | BOOKS Discouraging view of the journalism scene in US WHO STOLE THE NEWS? Why we | discard | 37 | Domestic issues dominate THE ELECTIONS for the Euro pean Parliament now under wa | knn |
| 38 | 1 Head of GATT to quit this year . J From JOHN ZAROCOSTAS In Geneva PETER SUTHER | discard | 38 | UK Budget freezes spending . LONDON, Wednesday: Brit ain’s unpopular Conservativ | knn |
| 39 | Book Two Decaying belief in the dentist J UST what I need: another reason not to | discard | 39 | NZ teeters towards poll Resignation hits shaky majority WELLINGTON: New Zea land | knn |
| 40 | Rates rise ‘not justified’ By KEITH SCOTT The managing director of BHP, John Pre | discard | 40 | Saturday FORUM The conjurers around the Cabinet table FEDERAL POLITICS Ross Peak | knn |
| 41 | TJDGET ’94 Strategy depends on business investment recovery in 1994-95 Budget cl | discard | 41 | PM told to spend on the jobless By TOM CONNORS, Economics Writer The Prime Minis | knn |
| 42 | Accused MP vows to fight to e nd SYDNEY: The embattled State Liberal MP Barry Mo | discard | 42 | A good test of Downer’s mettle ALEXANDER Downer had another bad day yesterday. H | knn |
| 43 | Test tickets now prized possessions ! ROO TOUR I [NOTEBOOK! By Bevan Hannan Seat | discard | 43 | PM keeps Budget tax rise on cards By ROSS PEAKE, Political Correspondent Prime M | knn |
| 44 | Forestry protesters chip directly at PM Australian Federal Police officers remov | discard | 44 | Crystal ball starts to get a bit hazy around 1999 POLITICAL punditry is a risky | knn |
| 45 | Brave-faced Lions view the future MELBOURNE: The victim of the AFL’s five-year p | discard | 45 | Crushing swing rocks British Conservatives BRIERLEY HILL, England, Friday: The B | knn |
| 46 | Southern Cross Woden’s talent exodus leaves Stephens with shaky foundation ON TH | discard | 46 | Kohl to call Major’s bluff BONN: Chancellor Helmut Kohl and his European allies | knn |
| 47 | Magic bullets’ take their aim on disease POSSIBLE breakthrough in treating rheu | discard | 47 | A state loss is a federal gain John Black analyses the figures and concludes tha | knn |
| 48 | Loggers ready to blockade Woodchip warning to Govt By PAUL CHAMBERLIN The loggin | discard | 48 | INTERNATIONAL Bihac still under siege By KURT SCHORK SARAJEVO, Friday: Bosnian S | 1 |
| 49 | Small business confidence slips back a notch By IAN HENDERSON, Economics Writer | discard | 49 | Downer faces possible revolt on two fronts By PETER COLE-ADAMS, Political Editor | knn |
| 50 | Senior Libs consulted on Hewson’s fall By JACK WATERFORD The four most senior of | discard | 50 | BUSINESS AND INVESTMENT Regional banks shed value after rates increase By MICHAE | 2 |
The blended result is a great improvement, but it is far from perfect: blended results 33 to 44 are almost all about Australian or New Zealand rather than British politics, and results 63 and 67 are quite relevant to the search. Result 63 (“Death is another Major setback LONDON: The death of a Conservative legislator in what police call suspicious circumstances adds to the troubles of Prime Minister John Major”) ranks highly (at 21) on a “pure” semantic search, so it is being pushed down the rankings by keyword and similar-to-keyword results. Result 67 (“Harold Macmillan’s fate haunts modern Tories”) is not improved by a pure semantic search using the ada-002 embeddings, but is ranked at 34 using the CLIP embeddings. This result demands further investigation.
The value of a semantic search is particularly evident when performing a search most naturally expressed as a question or phrase rather than a set of keywords, and it does indeed seem that the ada-002 embedding (and to a lesser extent, the CLIP embedding) manages to encode a commonly understood intent behind the phrase and match it successfully with articles, for example, this search on infiltration of ASIO by communist spies which returns zero keyword matches yet many relevant semantic matches:

Figure 5. Search results for infiltration of ASIO by communist spies: there are no pure keyword results on the left, but many relevant semantic results on the right.
Another interesting example is the ability of a semantic search to find articles using current-day terminology that was not used at the time the article was written. Cybersecurity was not a term much used in 1994, and a keyword search finds zero matches, but the semantic search finds many relevant articles:

Figure 6. Search results for cybersecurity: there are no pure keyword results on the left, but many relevant semantic results on the right.
Named entity resolution
When navigating very large repositories and trying to understand the context of their contents and how they relate to other resources, being able to see the people, organisations, places and events mentioned in articles and result summaries can be very useful. People especially can be referred to in many ways, often with name variations that sometimes are contextual (eg, Joe Biden, Joseph Biden, President Biden, the President, J.R. Biden Jr (1942-), Joe, Mr Biden, Senator Biden, ..), and identifying what is a name and the “real-world” entity it refers to is both useful and non-trivial.
The proof-of-concept used the Stanford Natural Language library [6] to identify named entities which were then indexed with their containing articles. This allowed displaying names in article and result summaries (the latter as facets which can be used as search filters).
However, this is just the first step in providing a useful entity identification and context capability. It is valuable for an entity’s names (including their many variants) to be linked to a real-world entity. In the above example, it is probable, dependent on context, that Joe Biden, Senator Biden, President Biden, etc. should all be linked to the same “real world” person represented by the Wikipedia page https://en.wikipedia.org/wiki/Joe_Biden.
This linking has not been attempted in the proof-of-concept, but an experiment in trying to resolve people and organisation names to Wikipedia entities has been implemented which uses a combination of name matching and semantic similarity between the article containing the entity and Wikipedia text describing the entity to generate a similarity score between people and organisation entities identified by the Stanford Natural Language library and Wikipedia articles.
Some examples from the first semantic match on the fall of John Major search:
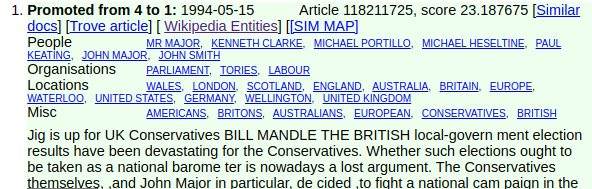
Figure 7. Entities found in a newspaper article about the fall of John Major.
The first entity listed is MR MAJOR.
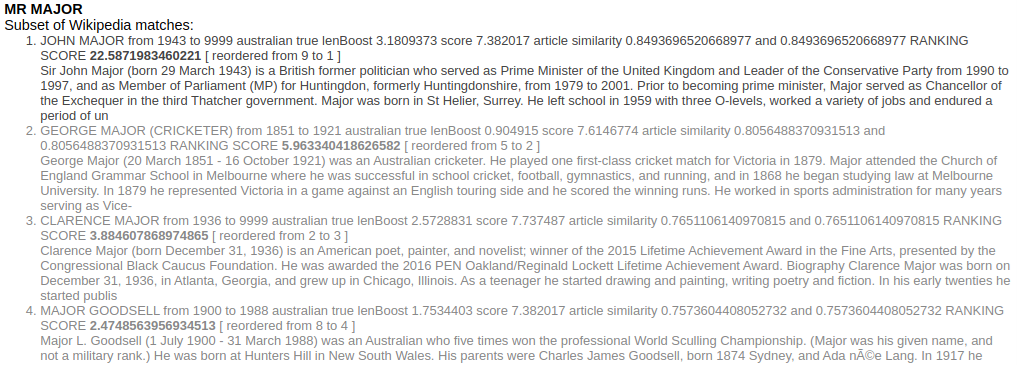
Figure 8. Wikipedia articles matching the entity MR MAJOR ranked by textual and semantic similarity.
Although not the closest name match amongst at least 10 name matches on MR MAJOR, the Wikipedia article on John Major is the closest semantic match to the article, and reasonably confidently disambiguates the name.
This article also contains a named entity for JOHN MAJOR:
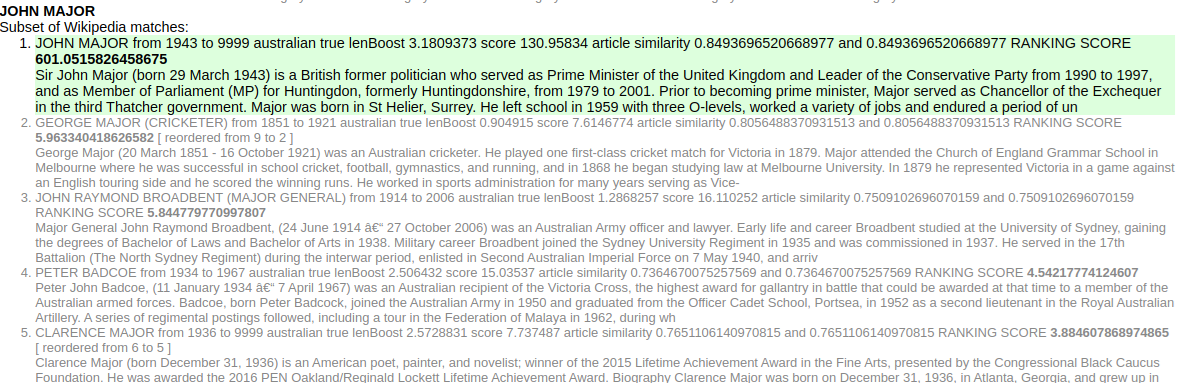
Figure 9. Wikipedia articles matching the entity JOHN MAJOR ranked by textual and semantic similarity.
Unsurprisingly, the better name match and same article/Wikipedia similarity match very confidently disambiguates this name.
The next entity is KENNETH CLARKE (in this context, another prominent conservative British politician):
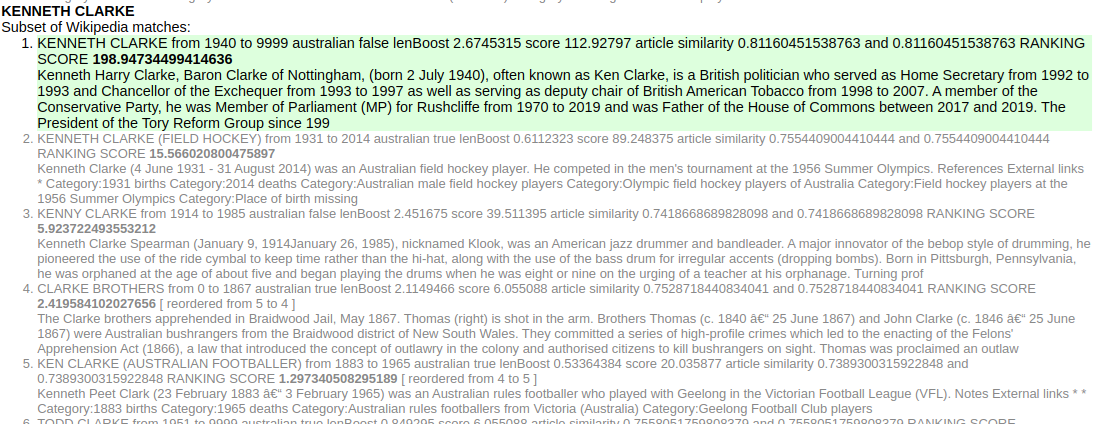
Figure 10. Wikipedia articles matching the entity KENNETH CLARKE ranked by textual and semantic similarity.
Semantic similarity confidently disambiguates this entity reference, as it also does for Michael Portillo, Michael Heseltine (both conservative British politicians) and Paul Keating (Australian Prime Minister, 1991-1996). However, it fails with JOHN SMITH:

Figure 11. Wikipedia articles matching the entity JOHN SMITH ranked by textual and semantic similarity.
The English politician is not even in the top 10, which is perhaps not surprising given the dozens of John Smiths on Wikipedia. However, this is a good illustration of the difficulties in linking named entities, particularly of common names, to Wikipedia entities.
These attempts at resolving named entities are encouraging but further work is needed to refine matching using names, contextual dates, semantic similarity and common co-appearing entities.
Scaling experiments
Although performance on this small repository of 45,494 documents is very good, the complete Trove newspaper repository contains 220 million articles. A notable characteristic of the HNSW algorithm used by many vector search engines (including Lucene/Solr) is that it is a hierarchical graph search in which most nodes (representing the embedding vectors of documents) are highly connected, typically to 16 – 128 other nodes, and the algorithm proceeds by following many promising parallel paths of increasing similarity through the graph. This causes effectively random access to the data in the graph, and as a consequence, very high IO rates unless the graph is held in memory. Even when in memory, the number of “probes” performed navigating the graph requires very high bandwidth between memory and the processor. For example, finding the “top 10” semantically-near results to a query with a HNSW graph storing about 200 million vectors, each linked with 60 nearest neighbours, requires about 45,000 “probes” distributed across the graph.
Hence, the size of the graph is of utmost importance. The maximum number of other nodes each node can be connected to has a moderate influence on the graph size, but the biggest factor is likely to be the size of the embedding vector. The ada-002 vector contains 1,536 floating point values, which equates to 6,144 bytes per vector. This uses less than 300MB for the small proof-of-concept repository, but for 220 million articles, requires over 1,300GB of memory. Even on a machine with such a large memory, the need to randomly access this memory into the processor’s memory caches suggests undesirable processing bottlenecks which will reduce query performance.
If the ada-002 vector contained vector positions (“dimensions”) which were highly correlated with each other or had near-constant values, then it would be possible to drop some dimensions whilst leaving search results unaffected. However, an analysis of the ada-002 vectors created for the newspaper and Wikipedia articles showed there was no correlation between vector positions and no near-constant values: that is, all the dimensions seem to add discriminatory value to the embedding.
However, this analysis did note that all but five of the 1,536 dimensions have almost all of their values in a narrow range between -0.1 to +0.1, whereas the five “outlier” dimensions had characteristic different narrow ranges (for example, dimension 194’s range is almost entirely -0.7 to -0.6). This suggested a low-error way to quantise the 4 byte float into a 1 byte value using six quantisations: one for each of the five outliers and one for the central “clump”, by choosing quantisation values to minimise total error.
With this approach, the 1,536 float values are quantized and stored as 1,536 bytes, and at “query time”, when calculating the vector similarity, the quantisation tables are used to “expand” each byte to a float having a value close to the original float value.
The proof-of-concept implements this approach as the “ada-002quant” embedding, and qualitatively, the results are equivalent to the unquantized values.
This approach reduces storage/memory/memory-cache-shuffling by 75%, but still requires 340MB of memory for 220M records just to represent the embeddings.
Further compression can be achieved using Product Quantization (PQ) coding [11]. With this approach, some number of vector positions, typically between 2 and 10, is represented by a single quantised value stored as typically between 4 and 16 bits.
Experimentation using the ada-002 embeddings gave good results using PQ coding on 3 vector positions and representing them with 1 byte quantisation. This required 1,536 / 3 = 512 separate PQ tables, each with 256 values, which represented 3 floats as 1 byte. Each of the 512 PQ tables were built using k-means clustering to minimise total error.
PQ coding hence reduces memory requirements by a further two-thirds, storing 512 bytes per embedding (down from the original 6,144 bytes), and allows the embeddings for 220M records to be stored in just 113GB.
The proof-of-concept implements this approach as the “ada-002pqcode” embedding, and qualitatively, the results are similar to the unquantized values.
Chatting with a newspaper repository
After the OpenAI chat API was released in March 2023, a simple chat proof-of-concept was implemented as follows:
-
- An embedding is created for the initial user chat input (exactly as it would be for a search).
- A semantic search on the newspaper repository (Canberra Times news articles from 1994) is issued to find the 8 documents with embeddings closest to that of the user input.
- Up to ~3,000 words are extracted in total from the 8 documents, in proportion to their relative similarity score and are used as context for the OpenAI chat request.
- A system prompt and the user input are added to the article context and passed to OpenAI’s chat API endpoint.
- The response is received, article references changed to hyperlinks (to the original article on Trove) and shown to the user.
- Any followup response from the user is appended to the previous inputs and sent again to OpenAI’s chat API.
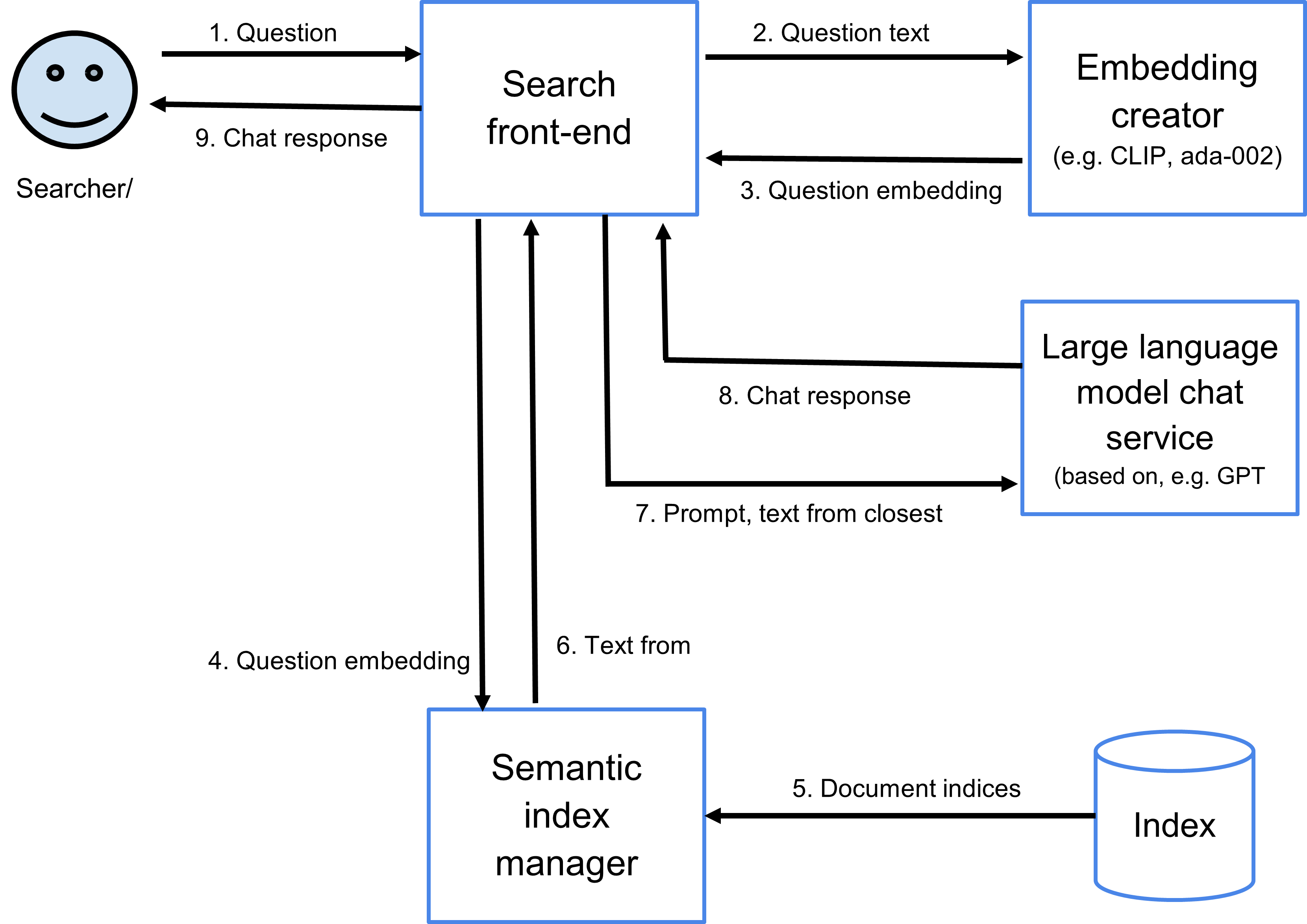
Figure 12. Chatting data flow.
As an example, a user input of “What problems did John Major have in 1994?” generates the following request to OpenAI’s chat API:
"messages":[
{"role":"system","content":"You answer questions factually based on the context provided. The context consists of newspaper articles, each within their own article tag (<article>) which starts with their article number and date of issue formatted as yyyy-mm-dd. Reference every article you used to construct your answer by starting every use of text derived from an article or articles by the source articles' sequence in the context, for example [From article 2] answer text derived from article 2... [From article 8, 3] answer text derived from articles 8 and 3"},;
{"role":"system","name":"context","content":
"<article> Article 1. Date of issue: 1994-05-07. Content: INTERNATIONAL Major humiliated In local elections LONDON: In a humiliating setback for Prime Minister John Major, Britain's ruling party yesterday suffered its worst defeat in local elections as traditional Conservative voters deserted his crisis plagued Government. Diehard Conservatives throughout Britain switched allegiance or stayed [content removed for brevity …] Norman Fowler</article>
<article> Article 2. Date of issue: 1994-02-16. Content: Momentum against Major The administration of Britain's Prime Minister, John Major, has been deeply hurt by the continuing sex scandals which have seen [content removed for brevity …] too long in the political game-to,fall into that trap</article>
<article> Article 3. Date of issue: 1994-04-01. Content: Seeds sown for Conservative uprising Major facing mutiny after EU climb-down LONDON: British Prime Minister John Major faced the growing threat of a mutiny against his leadership yesterday..
And so on for 8 articles, concluding with:
.. David Ashby, had shared a hotel bedroom in France with a male friend</article> "},
{"role":"user","content":"What problems did John Major have in 1994?"}
]
ChatGPTv3 frequently failed to cite the source article as requested, but ChatGPTv4 routinely cites correctly, resulting in output such as:
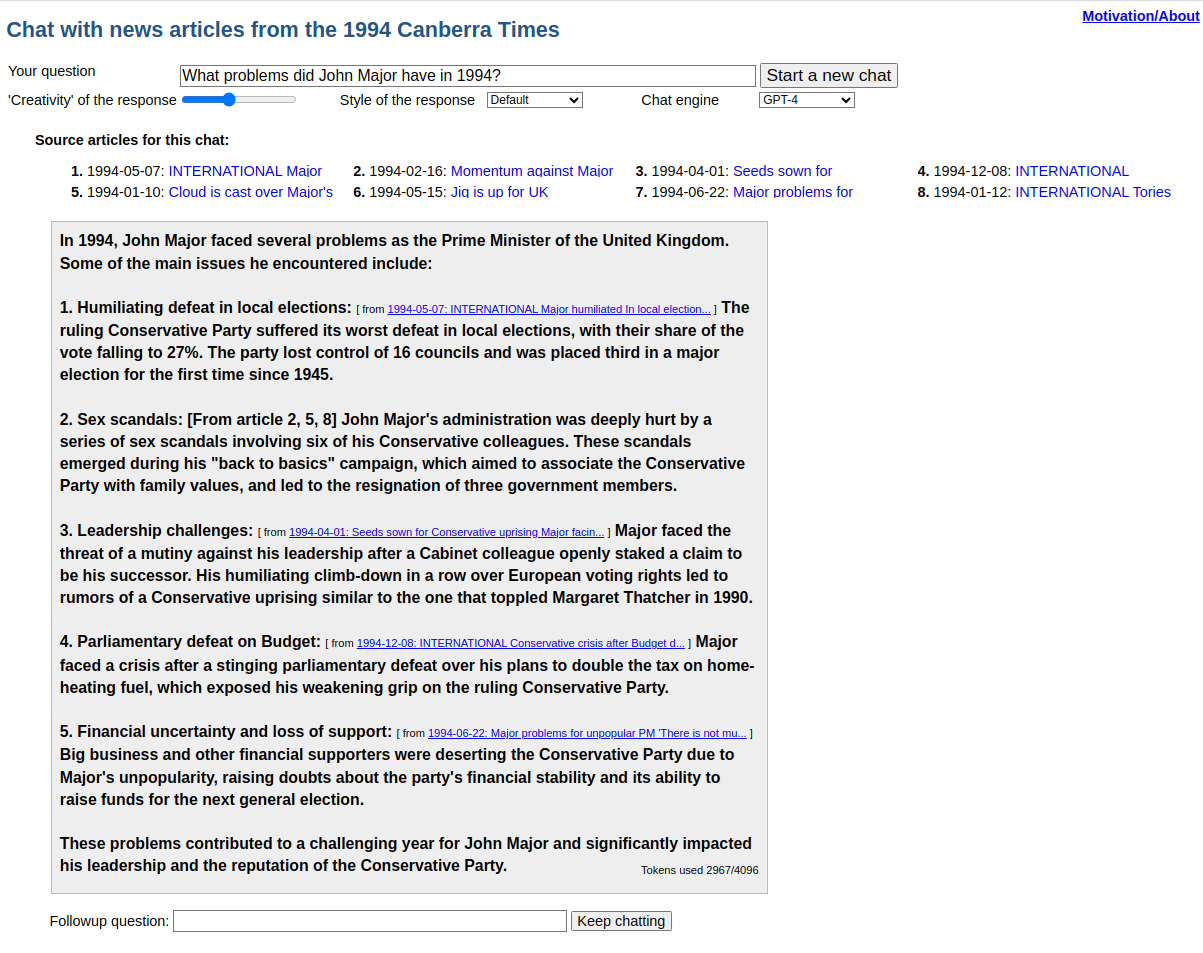
Figure 13. Response from OpenAI’s ChatGPTv4 to the query What problems did John Major have in 1994? given a context of 8 semantically-searched documents from The Canberra Times, 1994.
Followup questions are kept within the provided context:
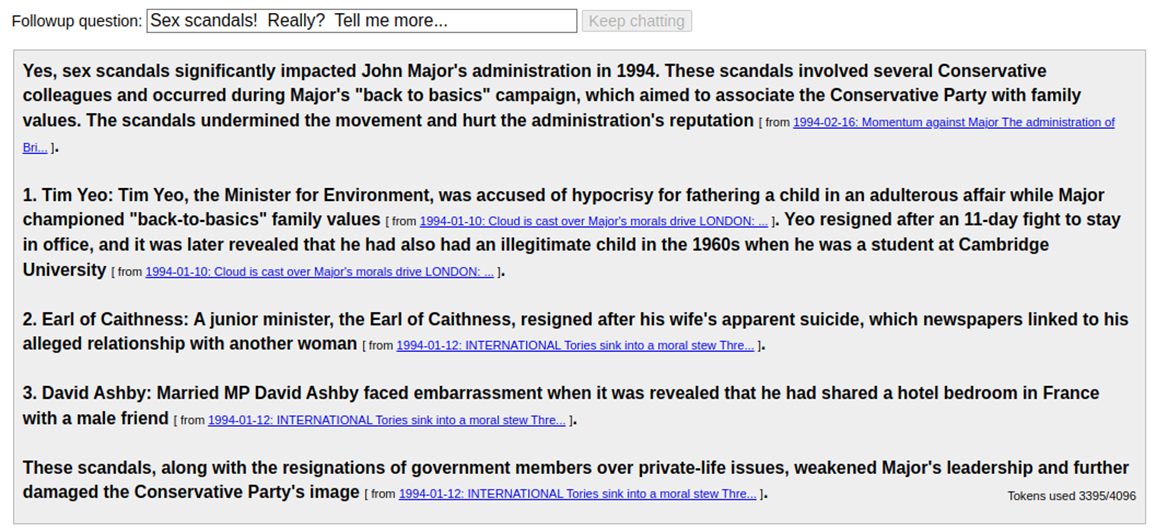
Figure 14. Response from a followup question, showing effective preservation of the original question’s context.
Chat provides an interesting way to summarise a large amount of content from different articles quickly and will be attractive for many people wanting to get an overview whilst still being able to “dig in” to the source material via the citation links to the original articles.
Further work
The proof-of-concept has merely scratched the surface of possibilities and briefly explored just some of the approaches for improving discoverability of resources held in large digital repositories.
Some of the areas identified for further investigation are listed below.
Named Entity identification and linking
Large language models have been successfully used to identify named entities and informal experiments with some newspaper articles and appropriate prompts using GPT3.5 and GPT4 are extremely encouraging, although the cost currently greatly exceeds running traditional Named Entity Recognition libraries.
It is possible that large language models, perhaps fine-tuned with content from Wikipedia, will be able to accurately identify and disambiguate people, organisations and places.
Many of the people and organisations described in newspaper articles will not be prominent enough to appear in Wikipedia. They will, however, be of great interest to some communities. How to identify and represent these, and for example, not link an unrelated “John Major” to the Wikipedia entry of the former British Prime Minister is unresolved.
Assuming reasonably accurate identification of named entities and linking to Wikipedia/Wikibase entities can be achieved, there exist great opportunities for representing content containing those entities in a broader context. For example, it would be possible to search for articles about British conservative leaders visiting Ireland without needing to specify names of people or places in Ireland, by using an equivalent of Google’s Knowledgebase (possibly based on Wikidata [12]) to find the appropriate people and places, and then using named entity indices on articles to find the intersections and finally using a semantic filter to identify those describing an appropriate named entity (British conservative leader) visiting another appropriate named entity (place in Ireland).
Appropriate embeddings
This proof-of-concept compares the CLIP ViT-L-14 and ada-002 embeddings, but there are many other options for embeddings. CLIP ViT is no longer considered state of the art, but was used because it was very easy to try and because the ability to map text and images to a single high-dimensional space is very attractive, providing as it does a simple, unified way to retrieve images as well as text.
Although ada-002 qualitatively gave better results, it has several downsides. The cost is non-trivial. NLA’s newspaper archive contains around 140 billion words, which equates to around 190 billion tokens. OpenAI has reduced the cost of embeddings dramatically, and at the time of writing (June 2023), ada-002 embeddings cost $US0.0001 per 1K tokens, giving an embedding cost of $US19,000 for the NLA newspaper repository. However, the NLA’s web archive repository contains about two magnitudes more text.
Another concern with a proprietary embedding approach is that should the vendor ever deprecate then discontinue support, the existing embeddings are unusable: incoming queries need to be converted to the same embedding model as the documents they are going to search. Similarly, a future decision to increase the price of obtaining an embedding could greatly increase search costs.
The Hugging Face Massive Text Embedding Benchmark Leaderboard [13] compares the attributes of embedding models, providing a starting point to investigate a balance between attributes such as cost, openness, speed, ability to characterise long runs of text, ability to characterise various languages, ability to characterise images, effectiveness, vector length and compressibility.
Vector search
This proof-of-concept only examined the performance of Lucene/Solr’s HNSW Approximate Nearest Neighbour search engine. This is a good “fit” for NLA’s technology stack, and it performed well and was demonstrated to scale to the size of the entire current newspaper repository. However, there may be better options, and vector search is a rapidly developing field.
The time taken and space used to construct the HNSW graph is affected by two tunable parameters:
-
- The number of “nearest” neighbours each node should be connected to (although the HNSW algorithm seeks to have somewhat diverse rather than strictly nearest but extremely similar neighbours).
- How exhaustively the algorithm should search for nearest neighbours.
Searching the HNSW graph is also affected by a parameter that specifies how exhaustively the algorithm should search for best matches.
Optimising these HNSW parameters is likely to be rewarding.
Compressing the embedding representation (to smaller storage values such as a byte rather than a float, and by reducing the number of values by techniques such as PQ coding) are likely to be necessary for large repositories. For a repository the size of NLA’s web archive (15 billion documents and counting), tradeoffs between embedding accuracy and performance seem inevitably required, at least with current hardware.
User Interface and search logic
Many searches are intended to be exact keyword searches. A searcher issuing Paul Keating Bankstown is very likely only interested in results about the named entity Paul Keating (the former Australian Prime Minister) and the named entity Bankstown (the Sydney suburb and his birthplace), and “blending in” semantic results may result in more annoyance than joy. Preprocessing the query to identify those entities will be valuable (for example, Paul Keating may be referenced in a sought article as Prime Minister Keating, PJ Keating, Mr Keating, or depending on the article’s context, just Prime Minister).
However, a search for Paul Keating immigration policy will benefit from semantic searching, at least on the immigration policy part. Perhaps a starting approach would be to attempt to identify named entities in the query and treat them as requiring a keyword match, or, if a knowledge graph is available, a known-entity match.
A last resort (admitting failure) would be to rely on a mechanism such as “Advanced Search” in many library systems, which basically puts the onus on the searcher to devise and communicate the search strategy. But for those trained by Google, such an approach is likely to be as mystifying as it is inadequate.
Where to terminate a semantic result set is another interesting problem. Unlike keyword searches which always have a hard cutoff (e.g., for an “ANDed” search, only documents with all the keywords can be returned), similarity has no obvious hard boundary: all documents are similar to all others to some degree.
Previously, “documents like this” capabilities operated on a “bag of words” approach, typically favouring rarer words. Semantic similarity offers the potential to make “documents like this” more useful.
Named entities combined with a knowledge graph will allow the search interface to suggest more “abstract” facets that are not directly contained in the text of the search result. For example, a search for train crashes may usefully present facets of country or state as higher-level groupings of place-names mentioned in the found articles. A search for Paul Keating immigration policy may usefully present facets such as political parties or factions as higher-level groupings of people mentioned in the found articles.
OCR text correction
Semantic search is more robust than keyword search in the presence of OCR errors because it relies on more than specific occurrences of keywords to create an embedding representing the meaning of text. However, as described above, many searches will still rely on exact keywords (e.g., searching for a particular person and place), and removing as many OCR errors as possible prior to creating embeddings and keyword indices, whether by crowd-sourcing (as successfully implemented by Trove [14]), by automated OCR correction (such as OverProof [15], also used by Trove) or using generative AI, may allow materially more accurate searching and summarisation.
Summarisation and “chat” interface
Moving away from the traditional search result of hyperlinks, each with a document title and brief context of found keywords, will be a big change for library systems, but following the design lead of large public search engines may minimise surprise.
At the time of writing (June 2023), Microsoft’s Bing search results show a feature search result (with section headings and summaries taken from that feature web page) followed by traditional-looking links in a left hand column, and a AI generated summary response that starts filling the right hand column and “learn more” citations used by the summary, common explanatory follow-up questions, and an invitation to “Let’s Chat”:
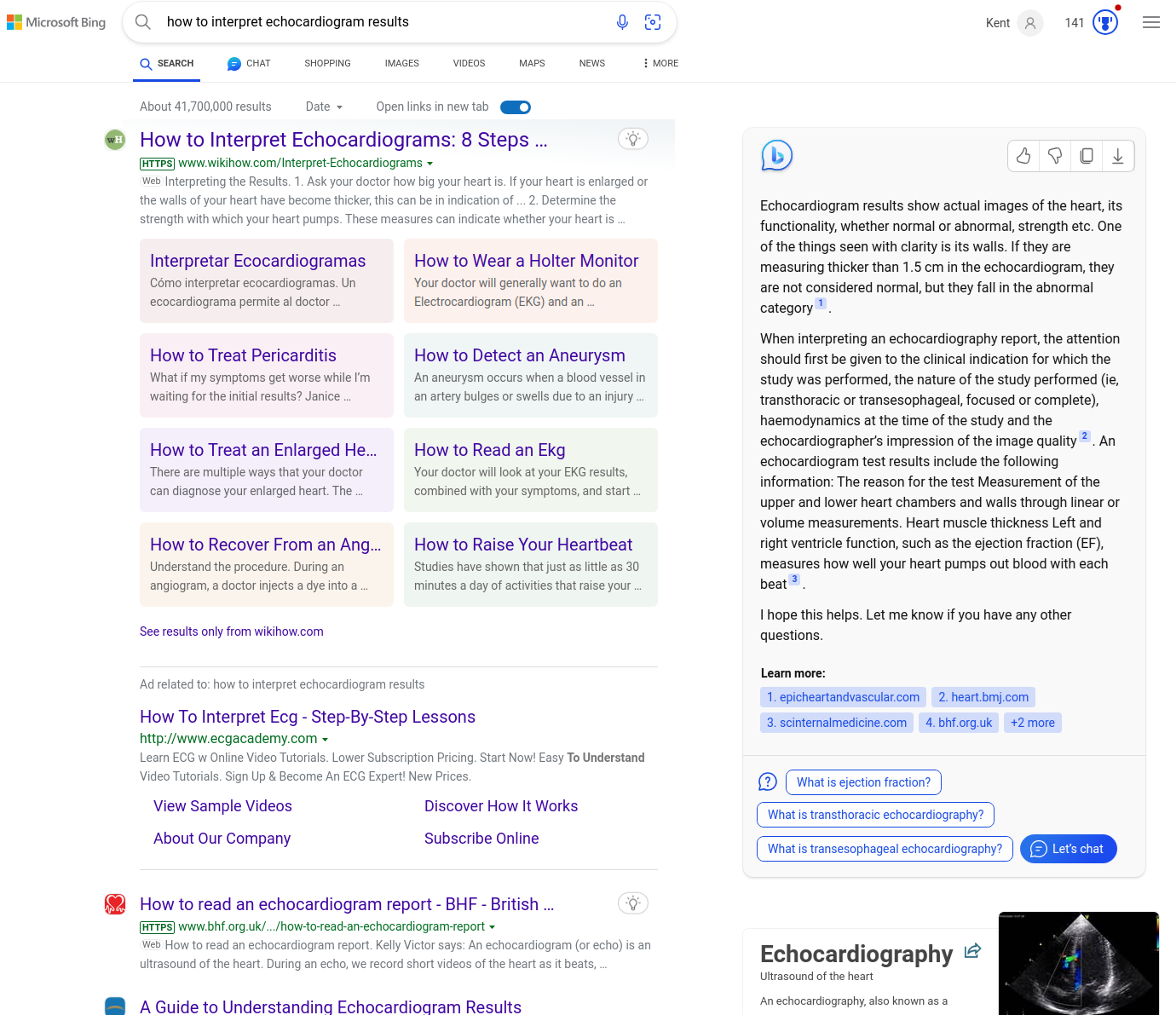
Figure 15. Bing’s AI-augmented search results as of June 2023.
(Note that the actual search results returned will be informed by many factors such as the searcher’s location, IP address, search history, cookies associated with them and their browser and its settings.)
The citations can be followed to show the “source” web page. Alternatively, “Let’s chat” or one of the “pre-canned” follow-up questions can be clicked to continue the chat:
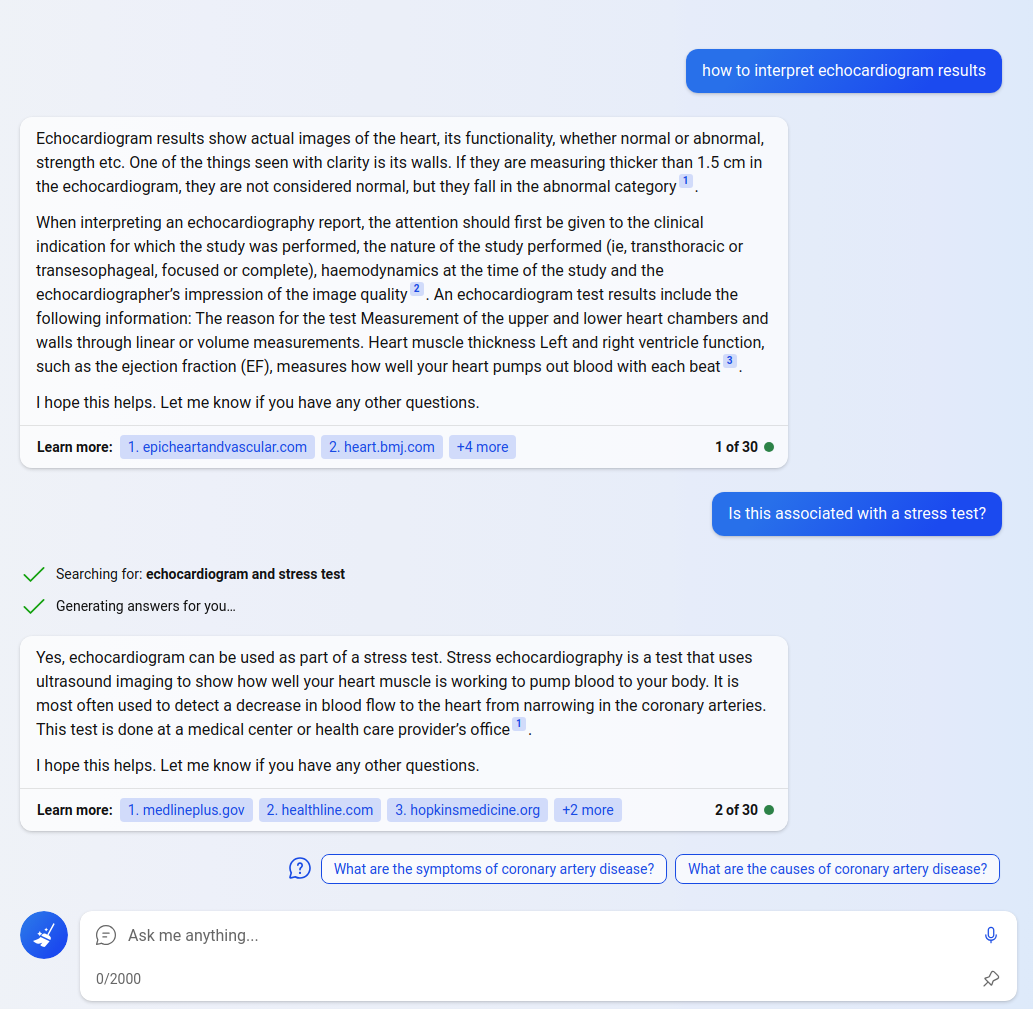
Figure 16. Follow-up chat on Bing’s AI augmented search portal.
The summarisation/chat is very effective at presenting an overview derived from multiple source documents with mechanisms to dive deeper, and this hybrid of traditional search results shown alongside summarisation/chat allows the introduction of this new capability in a gentle way that’s unlikely to disorientate people seeing it for the first time.
While the choice of which model to use for creating embeddings has long-term implications, the choice of which model to use for chat/summarisation is “tactical”, and can be relatively easily changed as technology develops. Although at the time of writing (June 2023) OpenAI’s GPT4 chat API has by far the best capabilities, it is expensive to scale (a single chat interaction with a provided context of 4,000 words generating a 500 word response costs about $US0.20) and some institutions may not be happy with resources and patron questions being supplied to a commercial service. Highly capable open-source models trained for chat are appearing, such as the Falcon-40B [16] and MPT-30B [17] models. MPT-30B appears particularly attractive because its size allows it to run comfortably on a single (very) high-end graphics processor and because it offers an 8K maximum token context, the same as the base GPT4 API. A larger context means more “source” text can be provided for the chat engine to summarise or use as a base for question-answering.
The proof-of-concept always selects chat context from the 8 best articles, and always selects text from the start of the articles. It is unlikely this naive strategy is optimal. Instead, it is probable that sometimes more, sometimes fewer articles should be selected, and that the most relevant context won’t always be confined to some fixed amount of text at the start of the article. For web pages (rather than newspaper articles) in particular, text at the start of a page is often boilerplate and hence normally irrelevant to the chat.
The proof-of-concept persists with the same context as the chat progresses, simply adding questions and the chat-engine’s response to that context. This is unlikely to be optimal: followup questions in the chat probably change the original best-choice of articles selected to provide the context.
Finally, a production service may need to ensure that the chat remains within the context provided, regardless of follow-up questions which may, adversarially, attempt to elicit responses that the hosting institution would rather not appear under its banner.
References
[1] Google Hummingbird. Wikipedia [accessed 2023 June 28] https://en.wikipedia.org/wiki/Google_Hummingbird
[2] Introducing the Knowledge Graph: things, not strings, Amit Singhal, Google [accessed 2023 June 28] https://blog.google/products/search/introducing-knowledge-graph-things-not/
[3] PageRank. Wikipedia [accessed 2023 June 28] https://en.wikipedia.org/wiki/PageRank
[4] Trove. National Library of Australia [accessed 2023 June 28] https://trove.nla.gov.au
[5] #FullyFundTrove. Change.org [accessed 2023 June 28] https://www.change.org/p/fully-fund-trove
[6] Stanford Natural Language Processing Core [accessed 2023 June 28] https://stanfordnlp.github.io/CoreNLP/
[7] CLIP ViT-L-14. Hugging Face [accessed 2023 June 28] https://huggingface.co/sentence-transformers/clip-ViT-L-14
[8] CLIP as a service. Jina [accessed 2023 June 28] https://clip-as-service.jina.ai/
[9] Hierarchical Navigable Small Worlds (HNSW) search graph. Pinecone [accessed 2023 June 28] https://www.pinecone.io/learn/hnsw/
[10] Okapi BM25. Wikipedia [accessed 2023 June 28] https://en.wikipedia.org/wiki/Okapi_BM25
[11] Product quantization. Pinecone [accessed 2023 June 28] https://www.pinecone.io/learn/product-quantization/
[12] Wikidata [accessed 2023 June 28] https://www.wikidata.org/wiki/Wikidata:Main_Page
[13] Massive Text Embedding Benchmark (MTEB) Leaderboard. Hugging Face [accessed 2023 June 28] https://huggingface.co/spaces/mteb/leaderboard
[14] ‘Singing for their supper’: Trove, Australian newspapers, and the crowd. Marie-Louise Ayres [accessed 2023 June 28] https://library.ifla.org/id/eprint/245/1/153-ayres-en.pdf
[15] Report on comparative search results following overProof correction of 10 million NLA newspaper articles. Project Computing [accessed 2023 June 28] http://nla-overproof.projectcomputing.com/
[16] Falcon-40B. Hugging Face [accessed 2023 June 28] https://huggingface.co/tiiuae/falcon-40b
[17] MPT-30B: Raising the bar for open-source foundation models. MosaicML [accessed 2023 June 28] https://www.mosaicml.com/blog/mpt-30b
About the author
Kent Fitch has worked as a computer programmer since 1980 and been a partner in Project Computing Pty Ltd since 1982. He was the system architect and lead programmer of the National Library of Australia’s Newspaper Digitisation system, then of Trove, and recently added pageRank to Trove’s huge web archive full text index. He also develop systems at University of New South Wales and for Project Computing.
He does not speak for the NLA and the work described in this article was performed independently of the NLA.
This work is licensed under a Creative Commons Attribution 3.0 United States License.

Subscribe to comments: For this article | For all articles
Leave a Reply