by Erin Wolfe
Introduction
Computational text analysis encompasses a range of methods and strategies employed by researchers to examine and derive meaningful insights from large amounts of text in a fast and systematic way. It has become an important tool across various fields, enabling researchers to uncover hidden information and gain deeper understandings from text-based materials. Applying these methods to textual corpora with a time-based component can enable users to uncover valuable insights into ways that the content changes over time. This article introduces ChronoNLP [1], a free, open source web-based application designed to specifically facilitate application of Natural Language Processing (NLP) techniques to texts of this type, by providing means for the temporal aspect to play a central role in the data analysis.
Background
ChronoNLP is an interactive web-based Python application designed by the author to provide the user with an interactive means of filtering, searching, exploring, and visualizing textual materials with a time-based component. This platform grew out of the author’s interest in “distant reading” of textual materials, a method of text analysis that treats text as data and employs computational approaches and analytical tools to uncover patterns, trends, and other features that may not be as easily revealed through traditional literary analysis. While there are a number of available very good open tools that do NLP actions [2], the intention of ChronoNLP is to provide an alternate tool for researchers to explore texts in which a time-based element can provide valuable insight into the data and data changes. Specifically, ChronoNLP is designed to allow the user a graphical means to explore and highlight various aspects of the texts using a variety of popular powerful text analysis libraries without a need for coding or command line knowledge.
The website is deployed using Streamlit, an open-source Python library that simplifies the creation of interactive web applications for data science and machine learning [3]. Streamlit allows easy integration with any Python-based library, including the various powerful NLP libraries used by ChronoNLP (which will be discussed in later sections), and its real-time data processing and rendering capabilities allow users to interactively explore and visualize the underlying data in an intuitive and user-friendly graphic interface. In addition, the Streamlit Community Cloud service can deploy web apps directly from GitHub at no cost, with code updates automatically reflected in the user interface.
ChronoNLP offers a variety of NLP models and data visualization techniques to interact with textual datasets, including filtering data based on user-defined criteria, robust keyword searching and visualization tools, a framework for side-by-side comparison of different slices of the data, and other actions. In addition, ChronoNLP provides an optional method for identifying a secondary data source component (such as a publisher or author category), which can be further used to filter and explore the data. All graphs and tables are interactive and responsive and support zooming, panning, and other features to enhance data exploration and analysis.
The data
Sample datasets
Although ChronoNLP is designed for users to upload their own corpora, there are sample datasets included that can be used to review aspects of the tool, including a (1) collection of news articles related to COVID-19 from six online newspapers published in Douglas County, Kansas, between January 2020 and January 2022 (‘Dataset 1’), [4] and (2) a collection of 757 posts from the blog of the History of Black Writing (HBW) project at the University of Kansas, published between 2011 and 2021 (‘Dataset 2’). [5]
Uploading user data
In addition to the text itself, ChronoNLP requires minimal metadata to be included [6]. The only required element is a date, ideally formatted according to the ISO 8601 standard (YYYY-MM-DD) or similar. Additionally, three optional fields may also be included: (1) a unique identifier for each item (e.g., filename or URI), (2) a label for each item (e.g., title) and (3) a grouping column (“source”) that will vary based on the type of data (e.g., author, genre, publisher). Including a source field will allow filtering and/or visualizing the data on this facet, such as comparing keyword usage between authors, relative frequency of publication by source, or other methods of grouping the dataset.
Data can be added to ChronoNLP either as (1) structured data in a csv file or (2) a zip file of individual text files along with a csv of metadata. On upload, the user has a chance to review the data and to map the csv columns to the correct values – any extraneous columns will be ignored.
Preprocessing
Once the data is ingested and verified, the full text of each article will go through a number of preprocessing steps to facilitate the subsequent analysis of the data. First, the entirety of the text is retained in full as retrieved during the initial harvest (“full text”). This is useful for searching for phrases in the unaltered text which may otherwise be missed (e.g., “the CDC”).
ChronoNLP implements spaCy 3 [7] and textblob [8] to process each text and create a cleaned version of the text, removing punctuation and stopwords [9] and converting all tokens (i.e., individual words) to lowercase. The text is analyzed for parts of speech and named entity identification, and some additional descriptive metrics are extracted. The preprocessing tasks may take several minutes, depending on the data size. The resultant processed dataset can be downloaded, allowing users to skip this step in subsequent visits.
Filtering the data
At any stage of the data review process, users can apply filters based on various facets to examine specific subsets of the data. These filtering options include specifying date ranges, selecting data sources, and excluding or including texts that contain specific terms. The resulting filtered dataset can be downloaded as a CSV file, and all subsequent NLP tasks can be applied exclusively to this subset of the data.
This ability to create on-the-fly subsets of data can help users review the texts more closely and from different angles. By comparing data from different date ranges, users can study temporal patterns and trends, seeing how language, topics, or sentiments evolve over time. Filtering by source can enable users to investigate the contributions and perspectives of specific publishers, authors, or platforms. It may help identify variations in content, biases, or writing styles, providing a more comprehensive understanding of the dataset and allowing a deeper analysis of the diverse perspectives present in the texts. Filtering based on specific terms or phrases allows users to focus their analysis on articles that are most relevant to their research questions. This functionality helps eliminate noise and irrelevant information, enabling researchers to zoom in on the key aspects they want to explore.
Overall, the filtering functionality in ChronoNLP empowers users to tailor their analysis, saving time and effort by narrowing down the dataset to specific subsets that are most pertinent to their research goals. It enhances the efficiency and effectiveness of the analysis process, facilitating more targeted and insightful interpretations of the textual materials at hand.
Functionality
Data overview
The Data Overview page provides a high-level look at the dataset, beginning with a stacked bar chart depicting the different sources’ number of items or word count over time (see figure 1).

Figure 1. Stacked bar chart showing the number of articles in Dataset 1 by source.
A tabular summary of the data is shown, including item count, average word count, shortest and longest entries, and the date range for each source (see figure 2). The TextDescriptives Python library [10] is implemented in spaCy to evaluate the readability of the corpus, using a variety of recognized tests. In this data, ChronoNLP reports the mean Flesch Reading Ease readability score, a metric that uses the average sentence length (in words) and the average word length (in syllables) to calculate a measure of readability. The result is a number from 0-100 in which a higher number reflects a text that is easier to read, with a lower score indicating one that is more difficult to read.
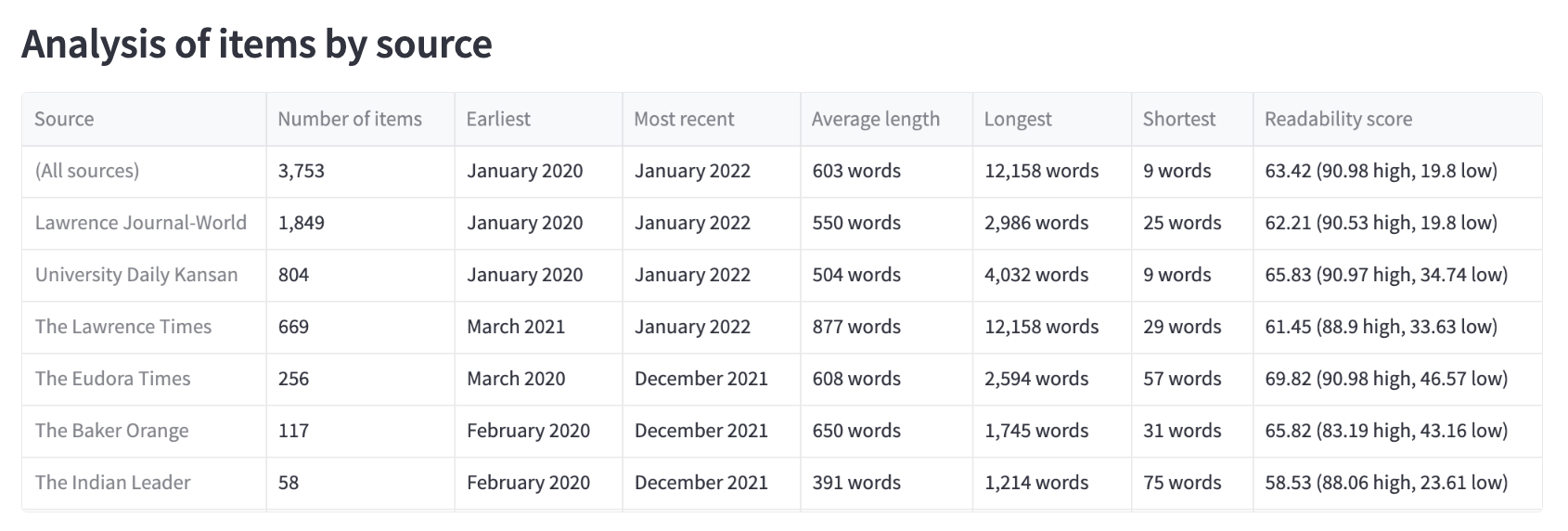
Figure 2. High level summary of Dataset 1 sources presented in a tabular format.
Parts of speech and Named Entity Recognition
Part-of-speech (POS) tagging is a natural language processing (NLP) task that involves labeling words within a text with their corresponding grammatical part of speech, such as noun, verb, adverb, etc. Named entity recognition (NER) tagging is a common NLP task that uses statistical predictions to identify and label a variety of named and numeric entities within a given text. ChronoNLP employs spaCy 3’s default model and pipeline for POS and NER tagging [11], which evaluates each word in its context and position within a sentence to automatically assign these and other linguistic labels (see figures 3 and 4).

Figure 3. Sample part-of-speech evaluation of a subset of Dataset 2, including only entries that contain the word “novel.”

Figure 4. Sample named entity recognition from a subset of Dataset 2, including only entries that contain the word “novel.”
Term frequency and Keyword Searching
One of the primary goals of ChronoNLP is to enable the visualization of word occurrences and frequency changes over time. Exploring term specific data is facilitated in two ways: (1) a user-instigated keyword search and (2) various automated keyword extraction methods. Analyzing word occurrences and frequency changes over time provides valuable insights into how language usage, trends, and topics evolve. It allows researchers and users to track the rise or decline of specific terms, identify emerging or fading concepts, and understand linguistic shifts within a given context.
Keyword search
The ChronoNLP interface allows the user to enter one or more search terms and view the usage frequency fluctuation in a variety of ways. The user can search by exact match or use wildcards to find variations (see table 1). Wildcard results can be returned as either a single combined result of all matches or as individual results for each match. Specific terms can be also excluded from the results.
| Search type | Example | Returns |
| Single term | test | All matches for exact match – “test” |
| Phrase | test case | All matches for “test case” |
| Wildcard | test* | A single count for all matches beginning with “test” (e.g., “test”, “testing”) |
| Wildcard, separated | ^*test | Individual counts for each match ending with “test” (e.g., “test”, “detest”) |
| Combination | test*, ^*virus* | (1) A single count for all matches beginning with “test”, and (2) individual counts for all matches containing the string “virus” |
Table 1. Examples of keyword searching
A count of all search terms is returned, which can be especially helpful when using wildcard searches (see figure 5).

Figure 5. Summary of search results in Dataset 1 for the search terms “test” (with no wildcard) and “mask*” (with wildcard).
The results are then visualized in a few different ways. First, a line graph showing a simple raw usage count of the term(s) over time, or as a normalized count which is weighted against the percentage of the number of items in that time frame in the dataset, to show the relative frequency (see figure 6). Data is graphed both by individual sources and as an aggregate, providing a comprehensive view of the textual patterns and trends. The results are also presented in a tabular format that can be downloaded as a csv file.

Figure 6. Graphs depicting the results for the search “test” and “mask*” in Dataset 1. Clockwise from top left: raw count of all uses, normalized count of all uses, normalized usage by source, raw count of usage by source
Search terms are also presented as a keyword-in-context table, showing all results along with n terms on the left and right, allowing the user to gain additional context of the words as used in the text (see figure 7). Separate tables calculate the 20 most frequent terms directly to the left and right of the keyword throughout the dataset, along with word clouds of the 200 most frequent terms (see figure 8).
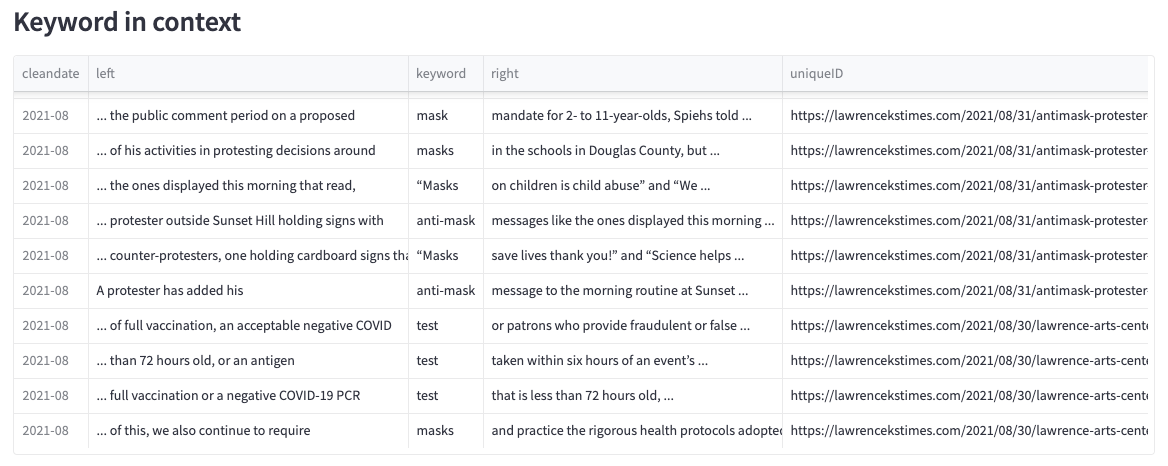
Figure 7. Sample keyword-in-context results from the search “test” and “mask*” in Dataset 1.

Figure 8. Most frequently occurring terms to the left and right of search results for the search “test” and “mask*” in Dataset 1.
If more than one keyword is searched, the user can select to view the combined results or individual results for each term (see figure 9).

Figure 9. ChronoNLP interface depicting the available options for reviewing the results for the search “test” and “^mask*” in Dataset 1. Note the carat and asterisk usage in “mask”.
Automated keywords
In addition, ChronoNLP goes beyond user-instigated searching, by providing an interface to explore computationally derived keywords. The ChronoNLP interface prompts the user to select a date range, one or more sources, number of n-grams [12] (ranging from 1-3), and the preferred method of analysis. In order to reduce noise from common or less pertinent terms, the user can also input a custom list of terms to omit from the results.
Three methods of automated keyword analysis are available for the user to highlight different aspects of the text. All methods are applied to the cleaned text to remove very common words (such as “the”, “and”, “for”) from the results. For each of these inquiries, the user can see a word cloud composed of the top 200 terms, a list of the top ten terms with frequency and/or weight, and a graph showing the top five terms’ frequency over time. Two inquiries can be run and displayed side-by-side to allow the user to easily compare two sets of results, such as the most frequent terms from two different time periods or sources.
- Term frequency is the most basic and uses NLTK’s FreqDist module to identify the most commonly used n-grams in a given set of articles.
- TF-IDF (Term Frequency-Inverse Document Frequency) analysis is an algorithmic approach to text analysis that highlights potentially significant terms that occur less frequently than others in relation to the entirety of the texts. ChronoNLP employs the Scikit-Learn library to perform TF-IDF analysis on the selected article set. [13]
- TopicRank analysis is a dimensionally-based analysis performed in spaCy using the pytextrank library that groups similar terms together and provides a count of each of these topics.
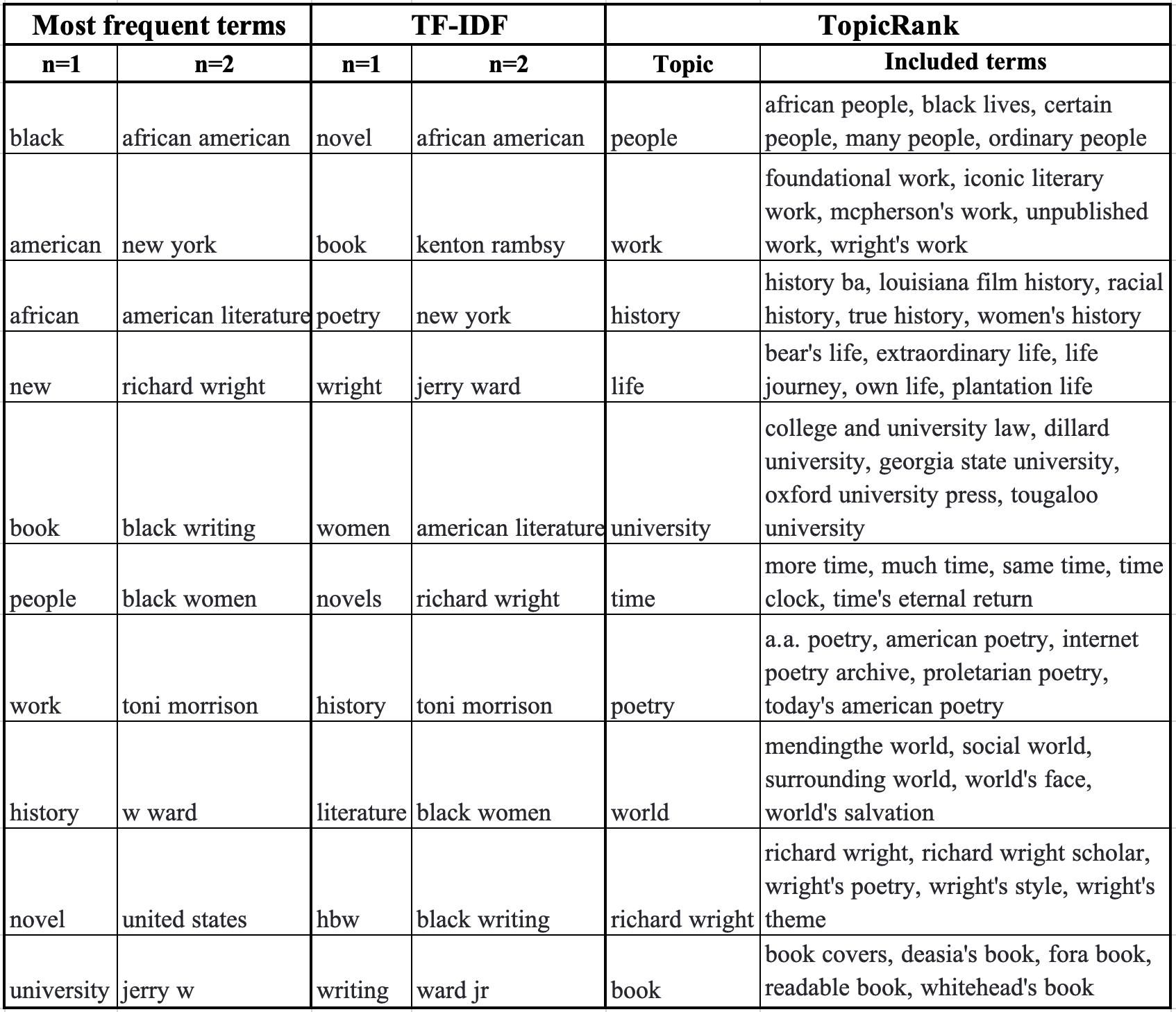
Table 2. Sample results from automated keyword extraction for Dataset 2, including Most frequent terms (n=1 and 2), TF-IDF terms (n=1 and 2), and TopicRank topics and a sample of terms related to each topic.
Topic modeling
Topic modeling is an algorithmic process that evaluates a set of documents to computationally extract patterns and structures from textual data to identify topics contained within. A statistical model analyzes and clusters the words from the document set based on their relationship. Using these clusters, the model generates a set of keywords for each topic, along with a probabilistic rate of occurrence for each keyword within that topic. Individual documents are assigned a relative proportion of each topic (to total 100%) based on the content, which enables the representation of the documents in terms of their underlying topics.
Latent Dirichlet Allocation (LDA) is a widely used method of topic modeling introduced in 2003 that is commonly used for NLP tasks [14]. LDA is an unsupervised learning method (i.e., it does not require a manually created set of training data) that works by analyzing the words in the documents, applying a probabilistic framework for capturing the relationships between words and topics, and grouping the words into a specific number of topics. Each document is then assigned to one or more of these topics based on its content, which can allow users to uncover the latent thematic structure in their textual data. ChronoNLP employs Gensim [15], an open-source library that uses modern statistical machine learning for NLP tasks, to perform LDA on a selected subset of the articles and to select the number of topics to generate.
To determine the optimal number of topics for a given set of documents, the user can use ChronoNLP to review two language model evaluation metrics: perplexity and coherence. Perplexity is a measure of how well a language model predicts unseen data, where a lower value indicates better performance. While this is a good metric for machine learning tasks, it may not be the most suitable measure for creating a human interpretable model. Coherence is a measure of how well the topics within a model make semantic sense. A higher coherence score suggests that the topics are more interpretable and clear, and it is a more appropriate metric to use when creating a model that can be visually reviewed and understood by humans. These metrics help evaluate how well the topics align with the documents and how understandable they are. By comparing these results, the user can select a number of topics for the model (between 5 and 15) to achieve the best results for their specific dataset (see figure 10).
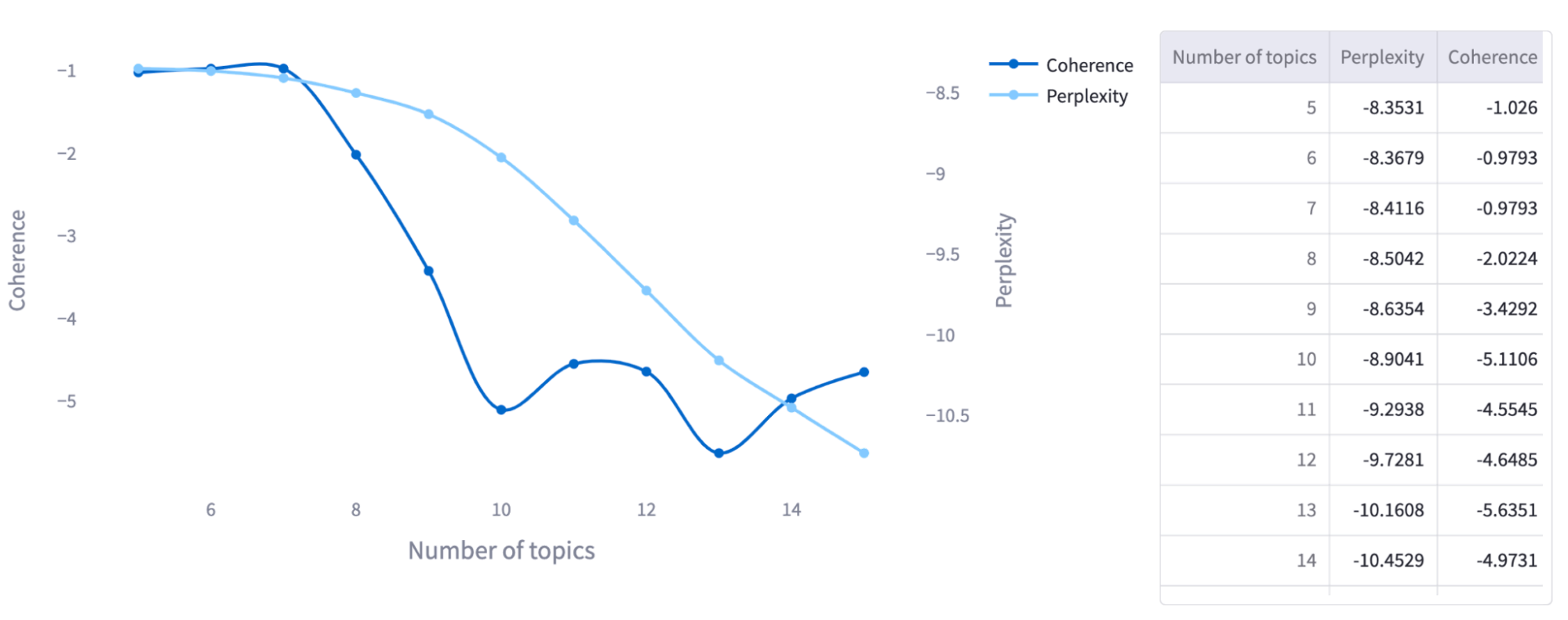
Figure 10. Results of Coherence and Perplexity evaluation for a subset of Dataset 1, including only entries that contain the word “community.” Based on the Coherence scores (the darker line), in this example, the optimal number of topics would likely be 5, 6, or 7.
Results are plotted over time, with larger bubbles representing a higher presence of the topic. Results can be plotted to show the absolute article count or relative frequency (i.e in relation to other topics present at that time) of a given topic (see figure 11).
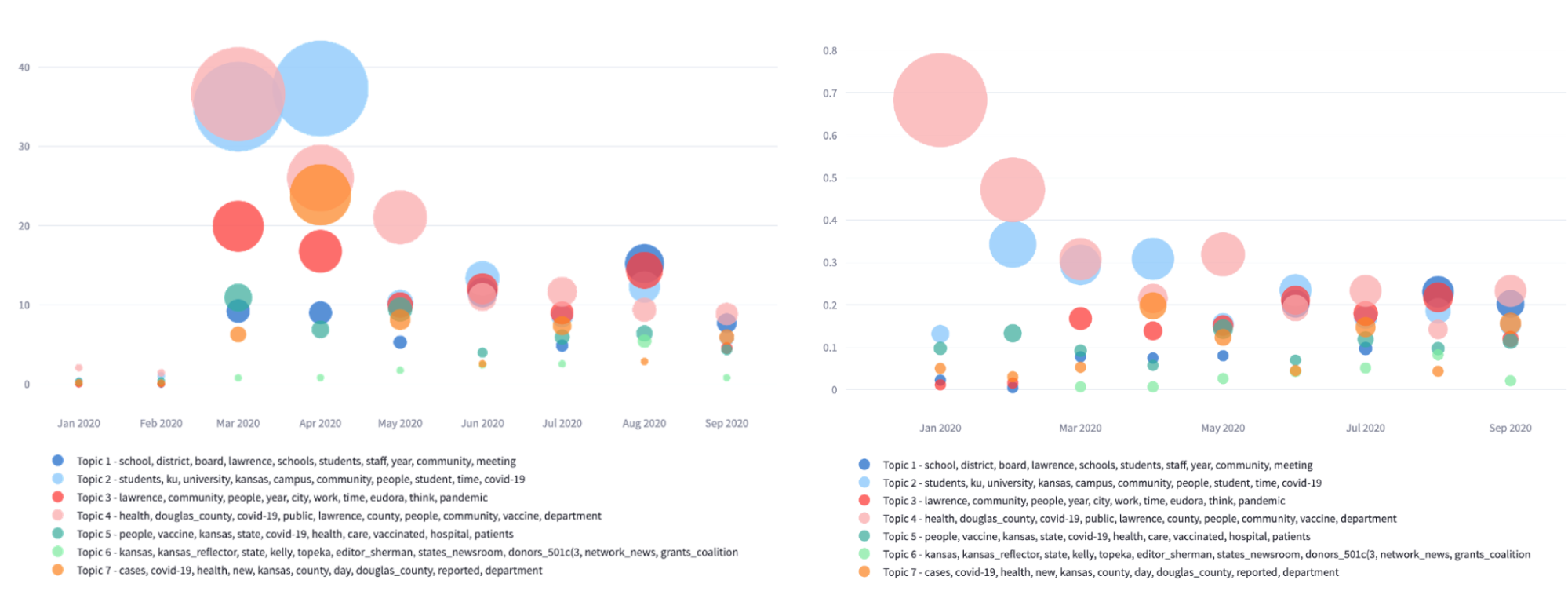
Figure 11. Results of topic model graph using 7 topics for a subset of Dataset 1, including only entries that contain the word “community,” showing both the absolute values (left) and the relative values (right).
The user can then review more specific details about each of the topics. As noted above, LDA is a topic modeling technique that clusters words into topics. LDA assigns documents to relevant topics based on the words they contain, assigning each topic a weight between 0.0 and 1.0. The sum of weights for all topics in a document is equal to 1.0, representing the distribution of topics within that document. In the ChronoNLP interface, the user can see (a) a list of the top 10 keywords and (b) a word cloud based on the top 200 keywords for a given topic, as well as the number of texts included in that topic group (see figure 12).

Figure 12. Sample of topics from a model using 7 topics for a subset of Dataset 1, including only entries that contain the word “community.”
Limitations and Future work
This project could be expanded to allow exploration of a variety of different collections that include texts with a time-based component, including literature, Twitter datasets, oral histories, or other content. Some testing has been done using some of these materials, including the plays of Shakespeare and historical speeches by U.S. Presidents, but more work remains to facilitate wider application.
The ChronoNLP interface does rely on a large number of external libraries and platforms. It will require periodically updating and migrating to newer versions of libraries or exploring alternative libraries to ensure the project remains up-to-date and compatible with the latest technologies.
At this time, the tool has been tested with relatively small datasets, and the efficiency and reliability of working with larger datasets is not known at this time. Future work will involve scalability, performance, and efficiency improvements, through code optimization, parallelization, hardware accelerators, and other means. In addition, the platform is currently limited to datasets in English. Future work could expand this through the inclusion of additional libraries and models.
Conclusion
This article has presented ChronoNLP, a web-based application that facilitates the application of Natural Language Processing (NLP) techniques to texts with a temporal component. It offers a range of functionalities that enable users to filter, search, explore, and visualize textual materials in an interactive and user-friendly manner. Integration with Streamlit enhances the accessibility and real-time data processing capabilities, empowering researchers to tailor their analysis and focus on specific subsets of the dataset that are most relevant to their research goals.
It is the author’s hope that this tool may help researchers to uncover hidden insights, track language usage over time, and gain a deeper understanding of the textual materials at hand. By eliminating the need for coding or command line knowledge, ChronoNLP makes text analysis accessible to a broader range of users and enhances the efficiency and effectiveness of the analysis process.
Data availability
All code and underlying data described in this article is hosted in the author’s public GitHub account: https://github.com/ewolfe1/chronoNLP
Notes
[1] Wolfe, E. (2023). ChronoNLP. https://chrononlp.streamlit.app/
[2] Some examples of other open NLP tools include: Sinclair, S., & Rockwell, G. (2016). Voyant Tools. http://libvoyant.unm.edu/docs/#!/guide/about; Morgan, E., & Abeysinghe, E., et al. (2019). The Distant Reader – Tool for Reading. PEARC ’19, July 28-August 1, 2019, Chicago, IL, USA. https://doi.org/10.1145/3332186.3333260; Anthony, L. (2013). Developing AntConc for a new generation of corpus linguists. Proceedings of the Corpus Linguistics Conference (CL 2013), July 22-26, 2013. Lancaster University, UK, pp. 14-16. https://www.laurenceanthony.net/research/20130722_26_cl_2013/cl_2013_paper_final.pdf
[3] Streamlit Inc. (2023). Streamlit documentation. [accessed June 15, 2023] https://docs.streamlit.io/
[4] A collection of 3,753 news articles from six online publications in Douglas County, Kansas published between January 28, 2020 and January 31, 2022. Articles were collected from the public web sites of three city publications (The Lawrence Journal-World, The Lawrence Times, and The Eudora Times) and three student university publications (The University Daily Kansan, The Baker Orange, and The Indian Leader). Articles were identified as part of a University of Kansas Libraries web archiving project identifying online content relating to COVID-19.
[5] A collection of 757 posts from the blog of the History of Black Writing (HBW) project at the University of Kansas, published between 2011 and 2021. Learn more about the HBW at https://hbw.ku.edu/.
[6] Documentation for the user on data preparation is included on the site: https://chrononlp.streamlit.app/Upload_dataset
[7] Honnibal, M., Montani, I., Van Landeghem, S., & Boyd, A. (2020). spaCy: Industrial-strength Natural Language Processing in Python. http://doi.org/10.5281/zenodo.1212303
[8] Loriah, S. (2023). TextBlob: Simplified Text Processing. https://textblob.readthedocs.io/en/dev/
[9] Stopwords are very common words that generally do not contribute to the understanding of the text, such as “a”, “the”, “would”, etc. It is a common practice in NLP tasks to remove stopwords and punctuation as part of the pre-processing of the texts to help reduce noise in the results.
[10] Hansen, L., & Enevoldsen, K. (2023). TextDescriptives: A Python package for calculating a large variety of statistics from text. arXiv preprint arXiv:2301.02057.
[11] spaCy provides four English language pre-trained pipelines (simply, a sequence of processing steps or algorithms that can be applied to text data) for performing basic NLP tasks. Each of these varies in size, processing speed, required computational resources, and suitability for a given NLP action. ChronoNLP uses the smallest of these four, “en_core_web_sm”, as it is the fastest model and well-suited for the available Streamlit resources, and it performs as well as the other larger models for the basic tasks of ChronoNLP, such as POS and NER identification. More information about the models and their functionality is available in spaCy’s documentation: https://spacy.io/models and https://spacy.io/models/en/.
[12] N-grams are simply a sequence of n words. The use of n-grams is very common in many NLP tasks. C.f. https://machinelearningknowledge.ai/generating-unigram-bigram-trigram-and-ngrams-in-nltk/
[13] Pedregosa, F., Varoquaux, G., Gramfort, A., et al. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830..
[14] C.f. Kapadia, S. (2019). Evaluate Topic Models: Latent Dirichlet Allocation (LDA). Towards Data Science. https://towardsdatascience.com/evaluate-topic-model-in-python-latent-dirichlet-allocation-lda-7d57484bb5d0
[15] Rehurek, R., & Sojka, P. (2010, May 22). Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks (pp. 45-50). Valletta, Malta: ELRA. http://doi.org/10.13140/2.1.2393.1847. See also https://radimrehurek.com/gensim/
About the author
Erin Wolfe is the Digital Initiatives Librarian at the University of Kansas, where he works with the Libraries on a variety of tasks involving the creation, description, and organization of digital materials for access and preservation, along with instruction and consultations in tools and practices for metadata management, dataset creation, digital preservation, and related topics.

Subscribe to comments: For this article | For all articles
Leave a Reply