by Dave Rodriguez and Bryan J. Brown, Florida State University Libraries
Introduction
Creating transcripts and closed-captions for digital audiovisual (AV) collections has historically been an enormous challenge for cultural heritage and academic institutions. Captions greatly enhance the accessibility and discoverability of AV materials under these organizations’ stewardship, but generating them and ensuring their accuracy and adherence to best practices is often a technical, financial, and/or administrative obstacle for many organizations.
Automatic speech recognition (ASR), also called “computer speech recognition” or “speech to text,” is a technology which translates spoken audio into a text file which can be used for accessibility purposes. While the use of ASR tools can potentially benefit library workers creating captions/transcripts in-house, their outputs are not 100% accurate nor do they meet the many other accessibility standards “out of the box.” Further, basic word-accuracy and overall performance varies significantly between tools.
This article provides an overview of key issues related to AV accessibility in academic libraries and summarizes research conducted at Florida State University Libraries. This research evaluated the performance of four ASR tools run on a selection of AV files culled from DigiNole, FSU’s institutional repository and digital library platform. This research focuses on assessing the outputs of different ASR tools using word error rate (WER) analysis. The results can be useful in determining the best tool to incorporate into an in-house captioning/transcription workflow that promotes the principles of Universal Design and centers accessibility as part of digital collections management.
Basic terminology and concepts related to AV accessibility
Before assessing the effectiveness of tools used to enhance AV accessibility, it is useful to discuss some of the key concepts and terminology related to the field: “captions,” “subtitles,” and “transcripts.” These accessibility-related terms are closely related, although sometimes incorrectly used interchangeably. Accordingly, it would benefit anyone working in this domain to have a solid understanding of their unique features and purposes as they represent distinct facets of the AV accessibility landscape.
Captionsrefer to the “text version of the speech and non-speech audio information needed to understand the content” (W3C 2022). Captions appear on-screen and in-sync with the audio of a given piece of media, reflecting spoken dialogue in addition to other significant “non-speech sounds” (Alonzo et al. 2022). This includes identifying atmospheric noises and sound effects unavailable to a hearing-impaired viewer (e.g. rumbling thunder or off-screen screeching tires) in addition to speaker identification and descriptions of diegetic and non-diegetic music (DMCP n.d.). Broadly speaking, captions are an accessibility tool that strive to provide a rich textual representation of the auditory experience for those who are unable to hear the content.

Figure 1. Image of captions displaying speech, speaker identification, and non-speech information (Wikipedia 2015).
Subtitles are often thought of as equivalent to captions, but their scope is more limited. While they also refer to on-screen text that appears in-sync with the audio track, subtitles usually only account for the spoken dialogue in a given piece of a media. A common-use case for subtitles is translation from the language being spoken into another (e.g. a film featuring actors speaking Japanese will have their dialogue translated into English in the on-screen text), where this translation will sometimes extend beyond spoken dialogue and translate important textual information on-screen as well (e.g. street signs, written documents). While there is certainly significant overlap between subtitles and captions with respect to their content, captions are created and designed as an accessibility accommodation, whereas subtitles do not necessarily serve this ultimate purpose (W3C 2022).

Figure 2. Image of subtitles displaying spoken dialogue (Wikipedia 2015).
Transcripts, according to the World Wide Web Consortium’s Web Accessibility Initiative, are defined in an identical way to captions, however there are important practical differences between the two (W3C 2021). In its most basic form, a transcript is a static text document accounting for all spoken dialogue in a piece of media in addition to other significant sonic information. The key difference between captions and transcripts is how they are formatted (see the following section for more information on caption formats) and how they, potentially, interact with the original media object. Some web-interfaces can support interactive transcripts which usually feature a display of the transcript alongside an AV file, highlighting the text as it plays. These interfaces can also allow users to click on specific phrases within the text of the transcript and jump to that point in the video, facilitating enhanced navigation of the content.
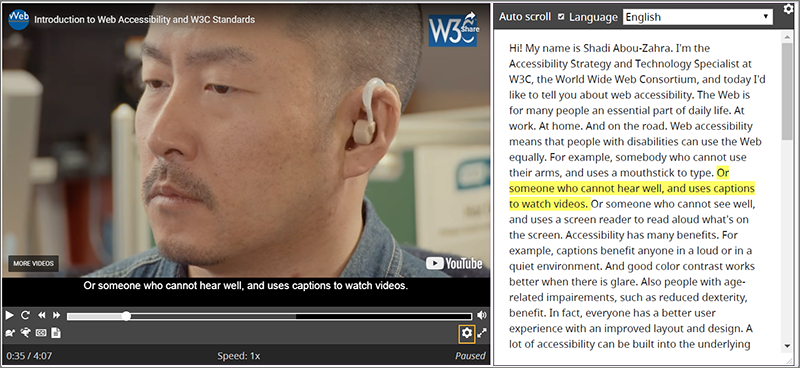
Figure 3. Image of an online media player with an interactive transcript (W3C 2021).
While transcripts can be simple, plain text documents, captions and subtitles require special formatting in order to function properly and in-sync with a media player.
Caption formats – SubRip Text vs. WebVTT
In addition to understanding the nuances between different AV accessibility features, anyone working in this area should also be aware of the technical characteristics of caption files themselves and how they interact with media players. A basic understanding of the two common caption formats discussed in this section will be useful in evaluating, editing, and ultimately implementing caption files in a production environment.
There are a variety of proprietary and open options to choose from when it comes to encoding captioning data into a machine-readable format, but the most common current formats supported by modern audio and video players are SubRip Text and WebVTT. In addition to being widely supported, both of these formats use human-readable UTF-8 text with an intuitive structure which facilitates proofreading. For these reasons, the authors have focused their research on these two formats, and find them to be the most relevant for use by libraries.
The SubRip Text format gets its name from SubRip, an application for extracting subtitles from video data (LoC 2023). SubRip outputs the subtitle and/or caption information and their timings into SubRip Text (.srt) files that can be used by media players to overlay the appropriate text on top of the original AV playback interface, as opposed to having the text data embedded in (i.e. “burned into”) the video file directly. SubRip Text’s simple format made it popular on the web, and led to many other ASR tools outputting data in the SubRip Text format as well. SubRip Text files consist of any number of blocks, each having 4 components: an identification number, a timecode range (represented by two timecodes formatted as hours:minutes:seconds,milliseconds and with a range marker ‘–>’ between them), the text of the caption/subtitle, and a blank line indicating the the block is complete.
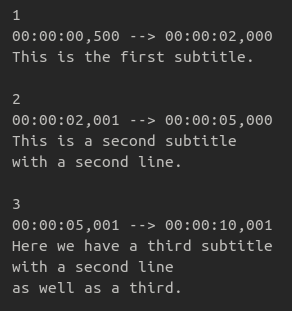
Figure 4. Image of an example SubRip Text file with three blocks.
Despite SubRip Text’s popularity and simplicity, its lack of an official specification is problematic in terms of its use as a core web technology. The World Wide Web Consortium sought to remedy this by creating a new caption format, WebVTT (Web Video Text Tracks, file extension .vtt). WebVTT is based on SubRip Text but made to be more feature-rich and rigorously defined to standardize its use on the web with the HTML5 <track> element (W3C 2019).
WebVTT is extremely similar to SubRip Text, and aside from some minor structural differences (namely, the requirement for a WEBVTT file header and the use of a period instead of a comma to separate seconds from milliseconds) it can be thought of as a functional superset of SubRip Text. In addition to having a robust official specification, WebVTT offers several new features over SubRip Text such as embedded comments and additional caption metadata and text styling options. The authors chose to focus on using WebVTT for the purposes of this project primarily due to the available documentation provided by the W3C.
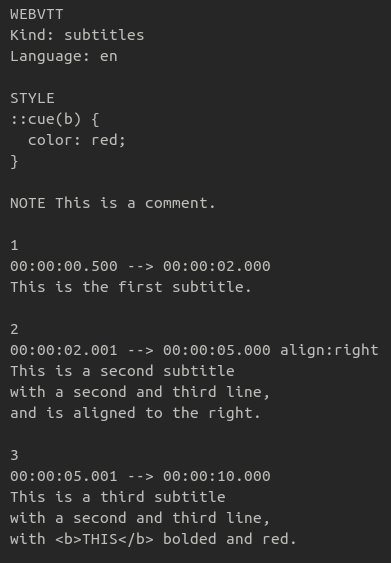
Figure 5. Image of an example WebVTT file.
The historical challenges of AV accessibility in academic libraries
Considering the many facets and technical issues at stake in AV accessibility, it is easy to see why libraries have historically struggled to meet accessibility standards and best practices. Academic libraries face the multi-pronged challenge of applying these standards to the acquisition of AV materials from outside vendors, managing their own institution’s digitized and born-digital cultural heritage collections, and, hovering over both issues, complying with accessibility-related legal mandates.
The first of these challenges relates to ensuring that AV materials purchased or licensed from third-party vendors meet accessibility standards and enable as many individuals as possible to use them for research, instruction, and other educational purposes. To this point, there is evidence that many academic vendors of streaming media do make considerable efforts to provide accessibility features like captions and interactive transcripts for some of their content (Kanopy 2023, Alexander Street Press n.d., Swank Motion Pictures 2022). However, as seen in research conducted by Anna Cox, while some vendors have made these sorts of commitments to enhancing accessibility, there is not yet evidence indicating that this is the case across all providers (Cox 2023). Cox’s research also suggests that as awareness around AV accessibility in the public consciousness increases, filmmakers, distributors, and libraries alike would do well to re-center it as a consideration.
In addition to AV media licensed or purchased from outside vendors, born-digital and digitized AV materials constitute a significant portion of academic libraries’ preservation and access efforts. These collections represent a separate set of challenges in consistently implementing captions and other accessibility features. This is evidenced by a 2022 study conducted by Federal Agencies Digital Guidelines Initiative (FADGI) of cultural heritage institutions that summarizes these challenges quite succinctly. In their survey of member organizations seeking information on AV accessibility compliance, they found that “[survey respondents] remain in flux about implementation methods and workflows due to a variety of factors including the complexity of the content, limitations on approved applications and tools, system integration, staffing levels, dedicated funding and more” (FADGI 2022). The surveyed institutions reported varying levels of resource dedication and staff time to actually implementing accessibility solutions, with some institutions indicating that this work is being done ad-hoc or only upon request. These findings reflect broader issues within the cultural heritage sector related to implementing consistent and systemic accessibility programs, an overall lack of sufficient resources, and effectively managing the technological and administrative aspects of accessibility-related labor and initiatives.
Lastly, legal realities loom over the logistical challenges related to accessibility and will often ultimately compel academic libraries to funnel staffing and resources toward compliance. Namely, Section 504 of the Rehabilitation Act of 1973 requires that any agency receiving federal funding (i.e. many colleges and universities in the United States) not exclude or deny any benefits or participation in regular activities to individuals based on disability (U.S. Department of Labor 1973). In practice, this legal mandate has recently played out in a high-profile, class-action lawsuit and settlement made by the National Association of the Deaf against Harvard University and the Massachusetts Institute of Technology, both of which hosted video content on their websites without captions and other accessibility features (McKenzie 2019). The result of this settlement saw Harvard and MIT agreeing to comply with Section 504 and adjust their policies and workflows to make the appropriate accommodations for all future video content (Harvard 2019, Schmidt 2020). As such a case demonstrates, the risk of legal action against academic libraries for hosting AV content without captions or other accessibility features is very real and palpable. This risk can be mitigated by creating policies and procedures in line with the principles of universal design, policies and procedures that proactively incorporate the caption creation process as part of existing preservation and access workflows instead of addressing it retroactively.
Universal benefits of captions to library collections and users
Despite these challenges, the positive impacts of implementing accessibility programs can arguably justify the amount of effort required to implement these policies and procedures. While captions may be primarily used for accessibility purposes and to meet legal requirements, there are also universal benefits to stewarding these text documents along with their accompanying AV materials in academic and cultural heritage collections. Some of these “value added” benefits of captions and transcripts also align with the principles of Universal Design which seek to broadly promote technology “designed to meet the needs of all people who wish to use it” and not just for the benefit of unique, minority populations (CEUD 2020).
Research has demonstrated that including captions not only serves users with auditory disabilities, but also can improve learning outcomes for nearly all users who engage with AV collections. A 2016 study demonstrated that 99% of student participants surveyed about their experiences with online video learning content found captions to be helpful in clarifying and comprehending information, spelling key terminology, and facilitated better note-taking practices (Morris et al. 2016). A similar study conducted at the University of Oregon found that a wide variety of different populations found captions to be central to their learning practices, including adult learners, first-generation students, ESL students, and students receiving academic accommodation (Linder 2016). These studies indicate that while captions may first and foremost serve users with auditory disabilities, the benefits of captions can extend to numerous other users in different ways. This benefit aligns with Principle 2 of Universal Design which highlights “flexibility of use” in facilitating different learning styles (CEUD 2020).
Another benefit for hosting institutions is that the addition of captions or transcripts creates a “full-text” version of an AV collection item. This full-text information can then be indexed by search engines which can significantly augment that object’s descriptive metadata and enhance its discoverability (Turkus and Schweikert 2019). With this greater level of discoverability comes the potential to increase use of a given AV item, enhance its value to a given researcher or field of study, and elevate the profile of the hosting repository.
These “value-added” propositions of captioning and transcription highlight the positive outcomes that high-quality captions can have on users and host institutions, in addition to furthering the professional values of Universal Design. The ability of librarians and administrators to articulate these benefits can be central to any advocacy campaign and should be held in focus alongside the ethical imperatives and legal realities discussed in the previous section.
Overview of automatic speech recognition (ASR) technology in libraries
Considering the complex challenges and clear benefits of captions to academic libraries, we can begin to explore technological avenues for addressing these issues and achieving these goals. ASR technology is one such avenue and accounts for many tools and services which take spoken language, in the form of an audio signal, and translate it into readable text (Rochester Institute of Technology 2019). The presence of ASR in online media players has grown significantly in recent years due to advances in the underlying technology, namely, the use of deep learning and other AI-adjacent techniques of development and training (Gondi and Pretap 2021). Accordingly, ASR tools are now being incorporated into major websites like YouTube, Facebook, and other social media platforms. These commercial applications reflect the explosive growth of the ASR industry that has been valued at $12.6 billion in 2023 and is estimated to reach nearly $60 billion by 2030 (Fortune Business Insights 2023).
From these figures, one may conclude that such rapid growth is at least partially due to increases in demand. Within the education sector, this became apparent with the rapid shift to online learning through video conferencing tools like Zoom due to the COVID-19 pandemic. This shift highlighted the need for quality captions and other accommodations for the deaf and other individuals with disabilities, as these individuals were now expected to rely solely on these communication channels. While the incorporation of ASR into video conferencing systems may seem like a “good enough” solution for these needs, the technology has not yet proven itself to meet accessibility standards, at least not on its own and without active human intervention for quality control (National Center for the Deaf 2020). Its shortcomings for live, synchronous communications aside, the wide availability and recent advances in ASR present opportunities for cultural heritage institutions to leverage this technology in productive ways. Incorporating ASR into preservation and access workflows can help enhance the accessibility of the enormous amounts of digital AV materials under their stewardship while also enhancing their usability, discoverability, and lowering the organization’s risk of liability.
Known cultural and ethical issues with ASR
While the potential benefits of ASR technology to academic libraries may be promising, the adoption of any new technology requires an organization to gain an awareness of its features and potential impacts, both positive and negative, to ensure that said technology is being deployed responsibly and ethically. In addition to performance issues with ASR tools “out of the box” mentioned in the previous paragraph, recent research has shown that some ASR tools and services exhibit potentially harmful biases along racial distinctions. One study evaluating 5 commercially available, “state-of-the-art” ASR tools found that the average word error rate (WER) was nearly twice as high for transcribing speech from African Americans vs. white speakers, concluding the the reason for this disparity was likely “insufficient audio data from black [sic] speakers when training the models” (Koenecke et al. 2020). These results point to deficiencies in the methods and models used to develop ASR tools, deficiencies which could possibly lead to many users being underserved and/or misrepresented while interfacing with the technology. Another study focusing on the experience of such “dialect discrimination” among 30 African American users of ASR technology found that participants expressed frustration, awkwardness, and overall dissatisfaction with the tools, in addition to feelings of anxiety, discrimination, and other negative emotional and psychological impacts (Mengesha et al. 2021).
Understanding the biases and potentially harmful shortcomings of ASR technology is especially important for academic libraries who purport to uphold professional values associated with promoting equitable access to information resources and championing diversity and inclusion (ALA 2019). In an effort to comport with these professional values, any library choosing to employ ASR technology within its workflow would do well to consciously examine how it is being utilized, regularly evaluate the potentially harmful impacts on its users or those represented in its collections, and to document and scrutinize ASR performance as part of on-going efforts to improve the technology for future generations of developers and users.
In-house ASR vs. External transcription vendor – which is preferable?
One question that has arisen during Florida State University Library’s evaluation of ASR tools is related to whether or not developing an in-house workflow for captioning and transcription is preferable to employing an external vendor to do the work. Many library professionals are often pointed to 3rd party commercial services like Rev for human-created captions and transcriptions for AV content. These options are often seen as preferable due to their relative low cost, quick turn-around time, and purported high-quality. However, there is evidence suggesting that such companies not only do not produce products meeting accessibility standards but also engage in exploitative and harmful labor practices.
Cheryl Green, a filmmaker and professional captioner, provides numerous examples from her extensive experience in both authoring captions and managing their creation as part of film distribution work where certain vendors “churn out consistently low-quality captions” riddled with typos, formatting errors, and culturally insensitive language (Green 2021). Further, vendors who subscribe to “gig-economy” models of sub-contracting a distributed network of employees to perform transcription have been publicly called out for subjecting these workers to low pay and exposing them to potentially harmful and disturbing content (Deahl 2019, Mohan 2019). Similar to being mindful of the potential impacts and wider context of using ASR tools, libraries and their leadership should be aware of whether or not their values are reflected in their choices of vendors. Additionally, they should look closely at whether the outputs of these vendors actually do meet both accessibility standards and content standards for AV media hosted by an academic institution.
Alternative options for 3rd party captions and transcriptions geared specifically toward accessibility are available, however these services are often beyond budgetary considerations for continual use. In previous accessibility-related projects at FSU Libraries, one-time grant funding was used to partner with the Georgia Institute of Technology’s Center for Inclusive Design and Innovation (CIDI) to caption a number of AV objects in FSU’s institutional repository (Rodriguez 2021). While this project was a major boon to the repository and CIDI delivered captions of exceptional quality, the cost of their services is unsustainable within FSU’s, and likely many other institutions’, regular operations budget. Ultimately, while budgetary concerns vary between different institutions, having access to reliable, high-quality ASR technology and developing an in-house workflow for remediating the outputs is something all organizations can benefit from and lessens any library’s reliance on 3rd parties in order to fulfill its goals and mission.
FSU Libraries Research
Impetus and Scope
The impetus for exploring the efficacy of ASR tools came after a member of leadership asked several librarians to attend a meeting with Aneta Kwak, Information Services and Instruction Librarian at the University of Toronto (Kwak 2022). This meeting sparked investigations into what ASR tools were currently available to FSU Libraries and to look further into the current state of the technological landscape. We also began examining how we could evaluate the outputs of ASR tools using existing standards and best practices.
The Described Media and Captioning Program (DMCP), an initiative administered by the National Association for the Deaf and funded by the U.S. Department of Education, is one resource that provides many helpful guidelines in this arena, including a succinct list of five “Elements of Quality Captioning.” These elements define quality captions as being:
- Accurate (free of grammatical errors and typos)
- Consistent (uniformity in style and presentation of all captioning features)
- Clear (a complete textual representation of the audio, including speaker identification and non-speech information)
- Readable (displayed with sufficient time to read, in-sync with the audio, and not obscuring, nor obscured by, the visual content)
- Equal (the meaning and intention of the material is preserved) (DMCP 2023)
Taken together, these elements provide an excellent baseline for evaluating captions. Individually, they also represent important, discrete components, some of which are not directly related to the outputs of an ASR tool. Some of these criteria (like “Accuracy” and “Equality”) speak to the word-content of the captions themselves and their relation to what is actually spoken. Others (like “Consistency” and “Clarity”) relate more to the formal and stylistic conventions of the captions as they appear as text on screen, while their Readability is more a question of technical features found in the caption file itself that determine when, where, and for how long on-screen the text appears.
For this reason, when evaluating ASR outputs, we chose to focus on the Accuracy and Equality of these files in relation to their original media, as assessing the fidelity of a tool’s outputs to the AV content itself, at the word-level, seemed like the most appropriate scope. Other features of ASR tools (e.g. speaker identification and audio sync) are also features that can be quantitatively assessed, however the authors agreed that focusing on word accuracy as the primary metric was the most useful way to initially evaluate the efficacy and performance of a given tool.
The selection of what tools to test was based on three criteria: 1) the tool being at the Libraries’ immediate disposal, without the need to solicit any outside services beyond established partnerships, 2) free-to-use, and 3) offering a variety of user-interfaces for consideration as part of a future workflow. After surveying the landscape in light of these criteria, we decided on four tools/services: Whisper AI, Microsoft Stream, Amazon Web Services (AWS) Transcribe, and Rev API.
Methodology
Assessment metric
In order to assess the performance of these ASR tools following the DCMP’s Accuracy and Equality elements, the authors employed word error rate (WER) analysis. WER analysis is a widely applied method of evaluating the performance of speech recognition systems, one that quantifies the discrepancies between what a tool transcribes vs. what is actually spoken. This is accomplished by applying the simple equation pictured in Figure 6.
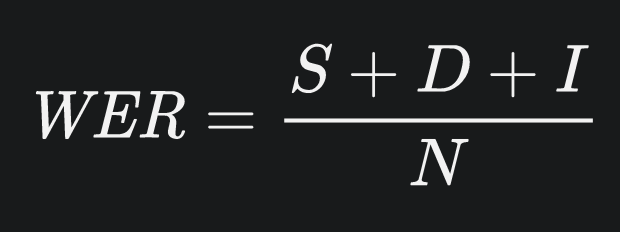
Figure 6. WER formula (Wikipedia n.d.)
Where N refers to the total word count of a given transcript and S to the number of word substitution errors (one word being substituted for another), D the number of deletion errors (number of words deleted in the transcript), and Ithe number of insertion errors (number of words not actually spoken but inserted in the transcript). The resulting value of this equation is then multiplied by 100 to be expressed as a percentage and indicates the overall error rate in each transcript. It is important to note that while WER provides a clear, useful metric for evaluating ASR performance, it is limited to word-accuracy and cannot, on its own, provide an all-encompassing assessment of caption quality as defined by the DMCP.
Test media
Twelve AV files sourced from DigiNole, FSU’s digital library and institutional repository platform, were curated to serve as test cases for each ASR tool. The intention in creating this set was to select different kinds of content that exhibited many common issues for ASR tools. These include features such as multiple speakers, overlapping speech, background noise, poor audio quality, strong accents, the use of technical terms and jargon, and the use of names and proper nouns. In addition to choosing materials based on these audio-specific qualities, various types of media were chosen to approximate the diversity of materials likely to be found in any cultural heritage repository or academic library. The resulting suite of AV materials encompassed documentaries produced for TV broadcast, oral history interviews, recorded conference presentations, archival film & audio recorded in the mid-20th century, and user-generated (non-professional) content produced by members of university clubs. The authors felt this sample set provided an adequate cross-section of materials likely to be found in similar collections and represented a broad range of levels of technical quality and production methods. All test media feature audio spoken only in the English language.
Whisper AI testing environment and language model
Of the four tools being assessed in this study, Whisper AI is the only one that was locally hosted, executed, and configurable with respect to the language model used for speech-to-text transcription. The other three tools use “outsourced” infrastructure provided by the respective vendor and offer little in terms of customizations or configuration to the transcription process. Accordingly, it is worth noting the hardware and language model configuration the authors used for testing with Whisper AI.
Tests with Whisper AI were run on the author’s library-provided 2019 Macbook Pro laptop running MacOS Catalina Version 10.15.7 on a 2.6 GHz 6-Core Intel Core i7 processor with 16GB of RAM. Considering the complexity and robustness of the language models used by Whisper, there is a chance that running the tool on different hardware would have different results. Whisper AI was downloaded and deployed (along with its dependencies) following the instructions provided by Open AI on the tool’s GitHub page (Open AI 2023).
Tests on the suite of AV materials from DigiNole were run using the “medium” language model offered by Whisper AI (ibid). A subset of these materials was later tested using the “large-v2” model that was released after the initial round of testing had already begun. See the section “Expanded results: Whisper AI large-v2 model” later in this article for a discussion of these results and a comparative analysis between the performance of the two language models.
Results
Each AV item from DigiNole was processed through each of the four ASR tools, resulting in 48 unique, unedited outputs (WebVTT files). Each of these outputs was loaded into the VLC media player with its corresponding AV item, played back and carefully reviewed to count the total number of each substitution, deletion, and insertion errors, respectively. These values were then fed into the WER equation and each tool/AV item pairing was given the appropriate WER score.
The results of calculating the WER of each tool against each AV item show that, for ten of the twelve items, Whisper AI had the lowest WER score of all the tools across all items in the test suite. Accordingly, Whisper AI is, for this set of data, the “most accurate” with respect to its transcription at the level of word-accuracy. Further, when all WER scores for each tool were averaged, Whisper AI also carried the lowest average score across all items in the test suite with an average error rate of 1.3%. AWS Transcribe had the highest average WER score of 4.5%, followed by Microsoft Stream (3.9%) and RevAPI (2.5%).
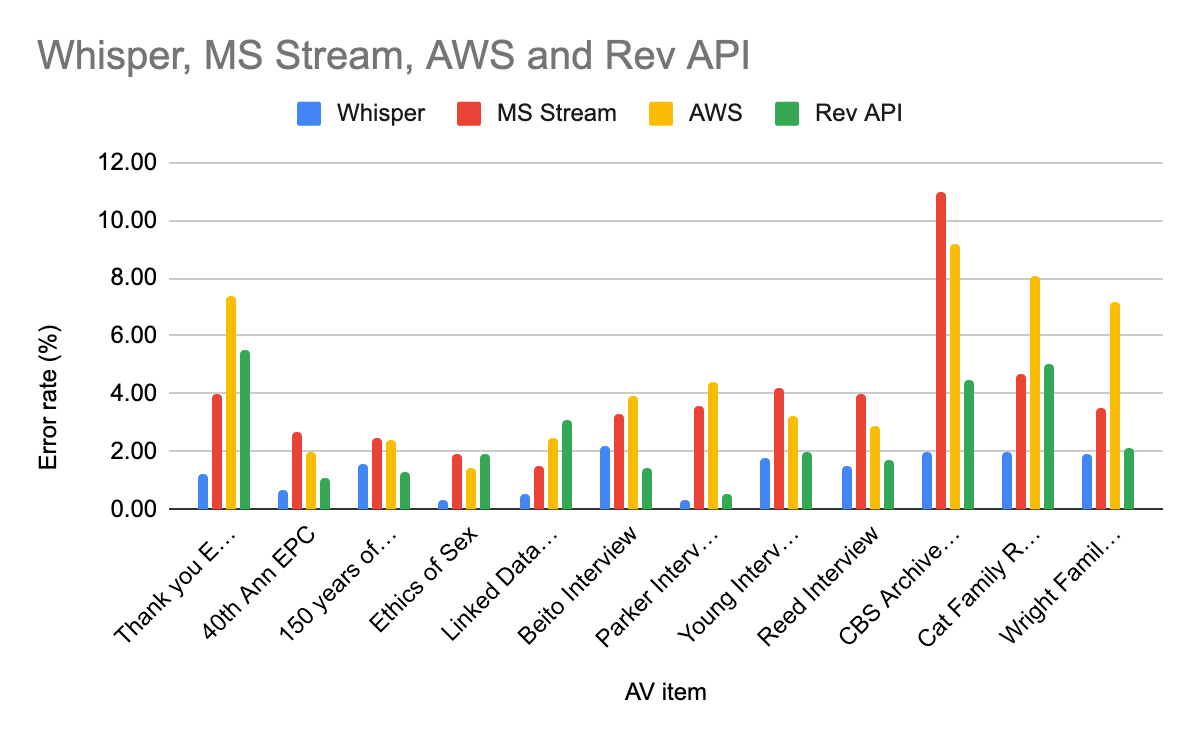
Figure 7. Graph of WER results across all items in the test suite.
| AV Item | Whisper error rate (%) | MS Stream error rate (%) | AWS error rate (%) | Rev API error rate (%) |
| Thank you EPC | 1.20 | 4.00 | 7.40 | 5.50 |
| 40th Ann EPC | 0.70 | 2.70 | 2.00 | 1.10 |
| 150 years of FSU | 1.60 | 2.50 | 2.40 | 1.30 |
| Ethics of Sex | 0.30 | 1.90 | 1.40 | 1.90 |
| Linked Data Pres | 0.50 | 1.50 | 2.50 | 3.10 |
| Beito Interview | 2.20 | 3.30 | 3.90 | 1.40 |
| Parker Interview | 0.30 | 3.60 | 4.40 | 0.50 |
| Young Interview | 1.80 | 4.20 | 3.20 | 2.00 |
| Reed Interview | 1.50 | 4.00 | 2.90 | 1.70 |
| CBS Archive Footage | 2.00 | 11.00 | 9.20 | 4.50 |
| Cat Family Records | 2.00 | 4.70 | 8.10 | 5.00 |
| Wright Family Interview | 1.90 | 3.50 | 7.20 | 2.10 |
Table 1. Chart corresponding Figure 7.
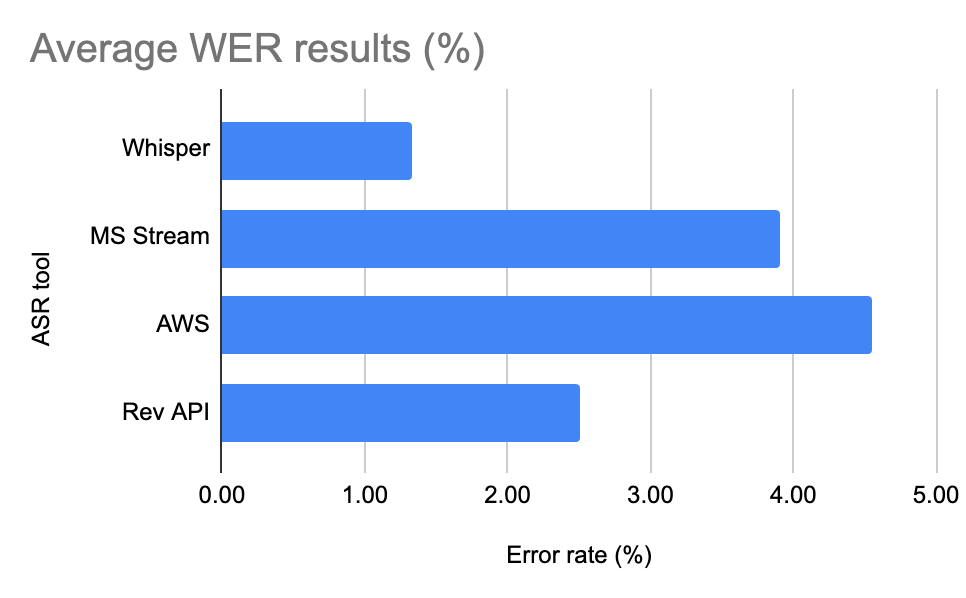
Figure 8. Graph of average WER scores for each ASR tool across all items in the test suite.
Expanded results: Whisper AI large-v2 model
Initial work on this project began in October 2022 and actual testing of tools began in November. During the intervening test period, OpenAI released a newer language model (the “large-v2” model) that purported to carry “improved performance in transcription” and other advantages to their previously released language models (Kim 2022). The authors felt that conducting a comparison between their initial results and this new large-v2 model would be valuable in producing a comprehensive evaluation of the tool, so a subset of six AV items were selected to be re-run using this newer model. The outputs of these jobs were then reviewed using the same process of WER analysis.
The WER analysis of the outputs produced using the large-v2 model demonstrate improved performance across all six items of the subset, with an average improvement of 0.43% error rate.
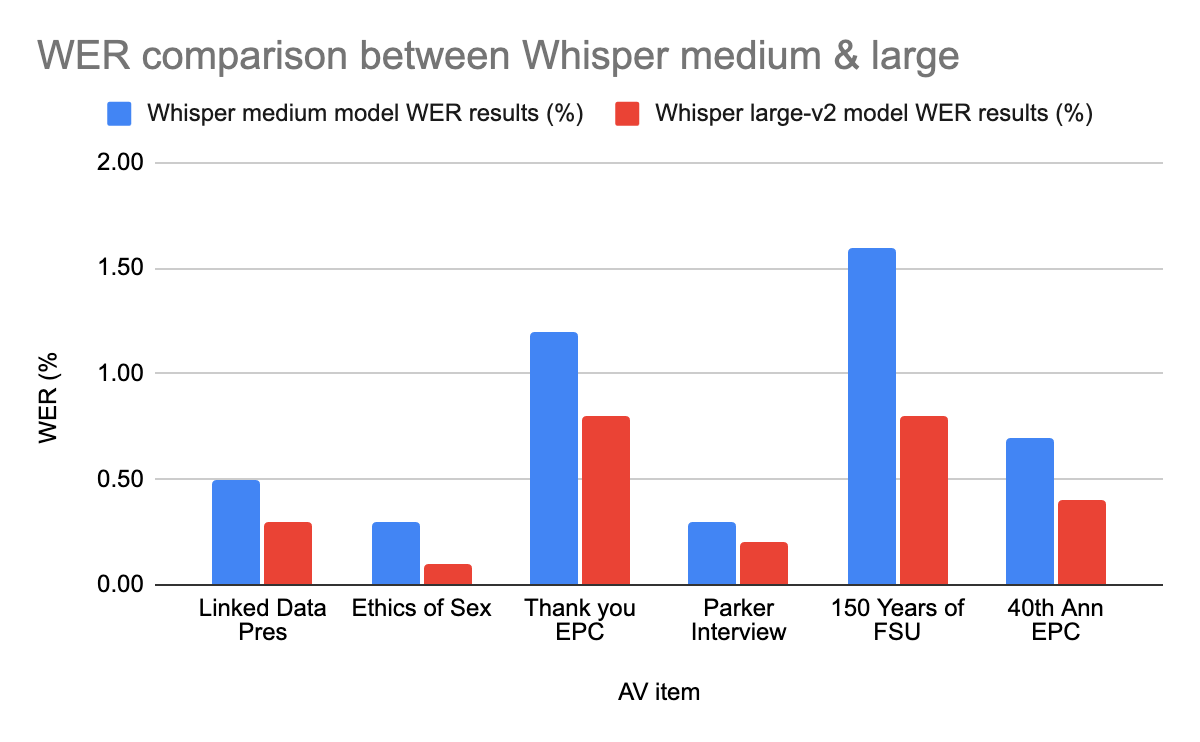
Figure 9. Graph of WER scores of six items tested using Whisper large-v2 language model.
| AV Item | Whisper medium model WER results (%) | Whisper large-v2 model WER results (%) |
| Linked Data Pres | 0.5 | 0.3 |
| Ethics of Sex | 0.3 | 0.1 |
| Thank you EPC | 1.2 | 0.8 |
| Parker Interview | 0.3 | 0.2 |
| 150 Years of FSU | 1.6 | 0.8 |
| 40th Ann EPC | 0.7 | 0.4 |
Table 2. Chart corresponding Figure 9.
Conclusions
The purposes of this experiment were to assess which of the selected ASR tools performed highest with respect to word accuracy and to determine a recommendation to include in a possible future in-house captioning workflow for the library. Based on these core criteria and the results of the WER analysis across the test suite, Whisper AI stands out as the most accurate tool and would be the recommendation of the authors, specifically use of the large-v2 language model. In addition to its high performance and WER scoring record, other features of Whisper AI also contribute to this decision. Namely, that it is a stand-alone, portable, open-source application that can be deployed in many different environments and does not require any agreements with third-party vendors. While the use of this powerful AI-driven tool offers great potential in helping libraries fulfill their missions of equitable access to information, information professionals should remain vigilant and versed in the ethical issues surrounding accessibility, the implications and limitations of AI tools, and work as active bystanders in the testing and development of these tools.
About the Authors
Dave Rodriguez is the Digital Services Librarian in the Technology and Digital Scholarship Division of Florida State University Libraries, where his role focuses on maintaining the library’s open-source digital repository systems, web presence, and cloud infrastructure. He has worked in institutions across the LAM sector for over 10 years and also specializes in the preservation and exhibition of moving-image collections.
Bryan J. Brown is a Repository Developer at Florida State University Libraries’ Technology and Digital Scholarship Division and works on the Web Development team supporting a variety of services including DigiNole, FSU’s digital repository platform, and LDbase, an NIH grant-funded repository for learning & development data.
Bibliography
Alexander Street Press [Internet]. n.d. Accessibility Statement; [cited 2023 Sept 12]. Available from: https://alexanderstreet.com/page/accessibility-statement
Alonzo O, Shin HV, and Li D. 2022. Beyond Subtitles: Captioning and Visualizing Non-speech Sounds to Improve Accessibility of User-Generated Videos.Proceedings of the 24th International ACM SIGACCESS Conference on Computers and Accessibility [Internet]. [cited 2023 Sept 12]; Available from: https://doi.org/10.1145/3517428.3544808
American Library Association (ALA) [Internet]. [updated 2019 Jan]. Core Values of Librarianship; [cited 2023 Sept 12]. Available from: https://www.ala.org/advocacy/advocacy/intfreedom/corevalues
Center for Excellence in Universal Design (CEUD). 2020. What is Universal Design?; [cited 2023 Nov 7]. Available from: https://universaldesign.ie/what-is-universal-design/
———————. (2020). The 7 Principles of Universal Design – Principle 2: Flexibility in Use; [cited 2023 Nov 7]. Available from: https://universaldesign.ie/what-is-universal-design/the-7-principles/#p2
Cox, A. 2023. Streaming Accessibility Features: A Time of Group Flow. Stream Magazine [Internet]. [cited 2023 Sept 12]; 2(1). Available from: https://www.videotrust.org/stream-magazine-vol-2-issue-01/streaming-accessibility-features
Deahl, D. [Internet]. [updated 2019 Nov 25]. Rev transcribers hate the low pay, but the disturbing recordings are even worse; [cited 2023 Sept 12]. Available from: https://www.theverge.com/2019/11/25/20979249/rev-recordings-transcriptions-low-pay-complaints-freelance-transcribers
Described and Captioned Media Program (DCMP) [Internet]. [n.d.]. Captioning Key – Elements of Quality Captioning; [cited 2023 Sept 12]. Available from: https://dcmp.org/learn/captioningkey/599
Federal Agencies Digital Guidelines Initiative (FADGI) [Internet]. 2022. Survey Results: The Current State of Accessibility Features for Audiovisual Collections Content in Five FADGI Institutions; [cited 2023 Sept 12]. Available from: https://www.digitizationguidelines.gov/guidelines/accessibilty_AV_collections.html
Fortune Business Insights. 2023. Speech and Voice Recognition Market Growth Analysis, 2030; [cited 2023 Sept 12]. Available from: https://www.fortunebusinessinsights.com/industry-reports/speech-and-voice-recognition-market-101382
Gondi S, Pratap V. 2021. Performance and Efficiency Evaluation of ASR Inference on the Edge. Sustainability [Internet]. [cited 2023 Sept 12]. 13(12392). Available from: https://doi.org/10.3390/su132212392
Green, C. 2021. Saying “Thank You” for Quality Closed Captions: A Promising Shift in Inviting Access. Canadian Journal of Disability Studies [Internet]. [cited 2023 Sept 12]; 10(2):255–268. Available from: https://doi.org/10.15353/cjds.v10i2.801
Harvard University [Internet]. 2020. Settlement Caption Requirements; [cited 2023 Sept 12]. Available from: https://accessibility.huit.harvard.edu/settlement-caption-requirements
Kanopy [Internet]. [updated 11 Sept 2023]. Displaying closed captions, subtitles, and transcripts; [cited 2023 Sept 12]. Available from: https://help.kanopy.com/en-us/4133.htm1/
Kim, JW. [Internet]. [updated 2022 Dec 8]. Whisper AI GitHub: Announcing the large-v2 model; [cited 2023 Sept 12]. Available from: https://github.com/openai/whisper/discussions/661
Koenecke A, Nam A, Lake E, Nudell J, Quartey M, Mengesha Z, Toups C, Rickford JR, Jurafsky D, and Goel S. 2020. Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences [Internet]. [cited 2023 Sept 12]; 117(14). Available from: https://doi.org/10.1073/pnas.1915768117
Kwak, A. [Internet]. [updated 2022 Oct 26]. Educause Conference Poster Session: Developing and Implementing a Closed Captioning Editing Program: Successes and Challenges; [cited 2023 Sept 12]. Available from: https://events.educause.edu/annual-conference/2022/agenda/developing-and-implementing-a-closed-captioning-editing-program-successes-and-challenges-1
Library of Congress (LoC) [Internet]. [updated 18 May 2023]. SubRip Subtitle format (SRT); [cited 2023 Sept 12]. Available from: https://loc.gov/preservation/digital/formats//fdd/fdd000569.shtml
Linder, K. 2016. Student uses and perceptions of closed captions and transcripts: Results from a national study. Corvallis (OR): Oregon State University Ecampus Research Unit. Available from: https://ecampus.oregonstate.edu/research/projects/3playmedia-student-research-study/
McKenzie, L. [Internet]. [updated 2019 Apr 7]. Legal Battle Over Captioning Continues; [cited 2023 Sept 12]. Available from: https://www.insidehighered.com/news/2019/04/08/mit-and-harvard-fail-get-out-video-captioning-court-case
Mengesha Z, Heldreth C, Lahav M, Sublewski J and Tuennerman E. 2019. “I don’t Think These Devices are Very Culturally Sensitive.”—Impact of Automated Speech Recognition Errors on African Americans. Frontiers in Artificial Intelligence [Internet]. [cited 2023 Sept 12]; Vol. 4. Available from: https://doi.org/10.3389/frai.2021.725911
Mohan, P. [Internet]. [updated 2019 Nov 13]. How yet another gig company is changing rates and hurting workers; [cited 2023 Sept 12]. Available from: https://www.fastcompany.com/90429522/yet-another-gig-company-is-changing-the-rules-for-workers
Morris KK, Frechette C, Dukes III L, Stowell N, Topping NE and Brodosi D. 2016. Closed Captioning Matters: Examining the Value of Closed Captions for All Students. Journal of Postsecondary Education & Disability [Internet]. [cited 2023 Sept 12]; 29(3): 231–38. Available from: https://search.ebscohost.com/login.aspx?direct=true&AuthType=shib&db=eue&AN=120149397&site=ehost-live&custid=s5308004
National Center for the Deaf [Internet]. [updated 2020 Oct 27]. Auto Captions and Deaf Students: Why Automatic Speech Recognition Technology Is Not the Answer (Yet); [cited 2023 Sept 12]. Available from: https://nationaldeafcenter.org/news-items/auto-captions-and-deaf-students-why-automatic-speech-recognition-technology-not-answer-yet/
Open AI [Internet]. [updated 2023 Aug 7] https://github.com/openai/whisper. Whisper AI GitHub repository; [cited 2023 Sept 12]. Available from: https://github.com/openai/whisper
Rochester Institute of Technology [Internet]. 2019. Automatic Speech Recognition; [cited 2023 Sept 12]. Available from: https://www.rit.edu/accesstechnology/automatic-speech-recognition
Rodriguez, D. 2021. Increasing accessibility of audiovisual materials in the institutional repository at Florida State University. The Journal of Academic Librarianship [Internet]. [cited 2023 Sept 12]; 47(1). Available from: https://doi.org/10.1016/j.acalib.2020.102291
Schmidt, M [Internet]. [updated 2020 Feb 18]. NAD settlement and Digital Accessibility Working Group; [cited 2023 Sept 12]. Available from: https://orgchart.mit.edu/letters/nad-settlement-and-digital-accessibility-working-group
Swank Motion Pictures [Internet]. 2022. Accessibility; [cited 2023 Sept 12]. Available from: https://swankmp.clickhelp.co/articles/#!accessibility/accessibility
Turkus B and Schweikert, A. 2019. Opening Closed Captions. No Time to Wait Conference; [cited 2023 Sept 12]. Available from: https://www.youtube.com/watch?v=4IGiYRMmsz4
U.S. Department of Labor [Internet]. 1973. Section 504, Rehabilitation Act of 1973; [cited 2023 Sept 12]. Available from: https://www.dol.gov/agencies/oasam/centers-offices/civil-rights-center/statutes/section-504-rehabilitation-act-of-1973
Wikipedia [Internet]. 2015. Example of speaker ID in SH (voices are off-screen); [cited 2023 Sept 12]. Available from: https://en.wikipedia.org/wiki/Subtitles#/media/File:Example_of_SDH_-_speaker_ID_(Charade_1963).jpg
Wikipedia [Internet]. 2015. Film with subtitles in English (quotation dashes are used to differentiate speakers); [cited 2023 Sept 12]. Available from: https://en.wikipedia.org/wiki/Subtitles#/media/File:Example_of_subtitles_(Charade,_1963).jpg
Wikipedia [Internet]. n.d. Word error rate; [cited 2023 Sept 12]. Available from: https://en.wikipedia.org/wiki/Word_error_rate
World Wide Web Consortium (W3C) [Internet]. [updated 14 July 2022]. Captions/Subtitles; [cited 2023 Sept 12]. Available from: https://www.w3.org/WAI/media/av/captions/
World Wide Web Consortium (W3C) [Internet]. [updated 12 April 2021]. Transcripts; [cited 2023 Sept 12]. Available from: https://www.w3.org/WAI/media/av/transcripts/
World Wide Web Consortium (W3C) [Internet]. [updated 4 April 2019]. WebVTT: The Web Video Text Tracks Format; [cited 2023 Sept 12]. Available from: https://www.w3.org/TR/webvtt1/

.jpg){kind=link}
.jpg){kind=link}
Subscribe to comments: For this article | For all articles
Leave a Reply