by Minyoung Chung and Phani Chaitanya Pendyala
Introduction
In May 2023, ONE Archives [1] successfully completed the data migration from Inmagic to Ex Libris’ Alma. It’s noteworthy that the metadata schema utilized in Inmagic differed from MARC 21, and the holding information was encoded as “checkin.” Exemplified in Figure 1 are instances of the checkin values, integral components of the migrated metadata from Inmagic.
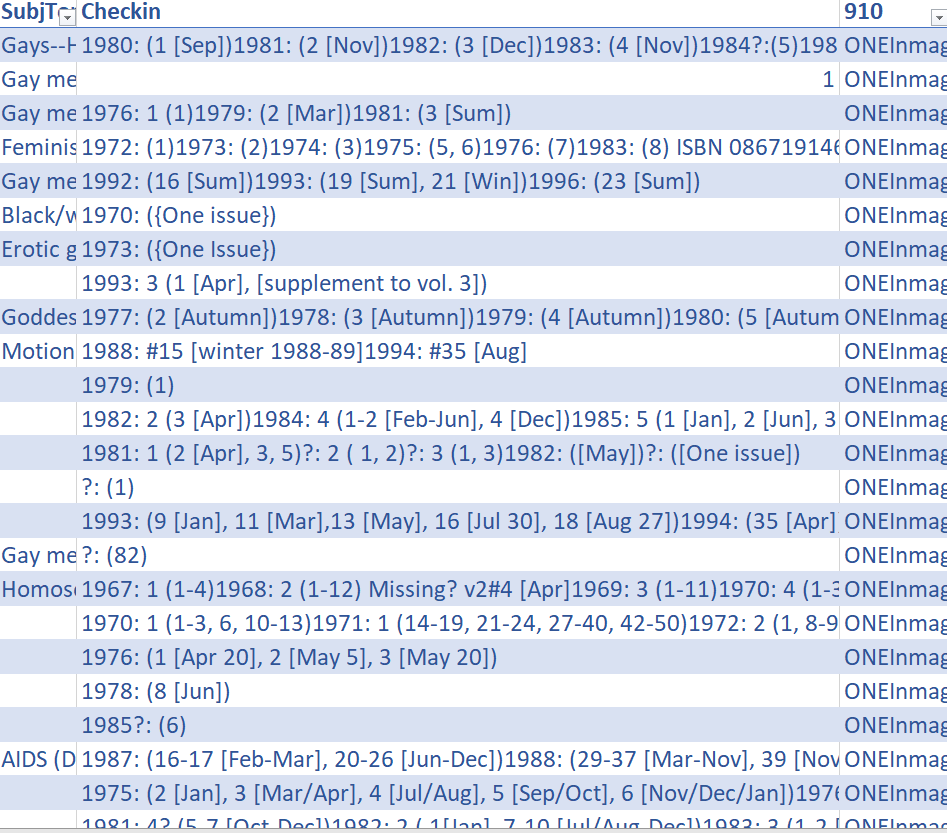
Figure 1. Examples of checkin values
Throughout the data migration, the “checkin” data was systematically mapped into the 949 $c field within bibliographic records. Additionally, this mapped information from the 949 $c field was further transposed into the 866 $a field within the holding records. This configuration not only allowed for the batch import of bibliographic records into the Alma system but also facilitated the generation of holdings information in the Alma import profile.
Context
The USC Libraries’ ONE Archives stands as the preeminent repository of Lesbian, Gay, Bisexual, Transgender, Queer (LGBTQ) materials globally. Boasting an extensive collection, ONE Archives houses millions of archival items, encompassing periodicals, books, films, videos, audio recordings, photographs, artworks, organizational records, and personal papers. Since 2010, ONE Archives has been integrated into USC Libraries.
With USC Libraries’ adoption of the ExLibris Alma Integrated Library System (ILS) in 2017, the migration process also included the transfer of records from ONE Archives. However, due to the complex nature of holdings information, particularly in specific serials and audio records, special attention was warranted. Consequently, certain records remained pending ingestion into Alma. The conclusive migration of data for these serials and audio materials was successfully executed between March and May 2023. This process necessitated extensive communication and collaboration among ONE Archives, the Technical Services & Collection Development Department, and the Integrated Library Systems Department within USC Libraries.
This paper discusses our follow-up cleanup initiative conducted between May and July 2023, right after the final data migration. Our primary focus was directed towards a thorough examination of ONE Archives serials holding records within Alma. A noteworthy issue that surfaced pertained to the presentation of summary holdings in Primo, prompting concerns about the clarity of the holding information.
The challenge centered around the difficulty in understanding the holding details within Primo, which proved to be time-consuming for myself and my fellow serials cataloger. From a technical perspective, the cleanup of holdings information to enhance clarity and comprehensibility was entirely feasible. Consequently, embarking on this cleanup project was an evident and straightforward decision. This challenge is further compounded by the inherent non-browsability of these materials, given that the serials are securely housed in the restricted and closed stacks in ONE Archives. Therefore, ensuring the accurate display of holding information through the Primo interface became imperative.
The primary objective of the project was to enhance the user-friendliness of the Primo display by presenting detailed information in a clear and understandable manner. USC Libraries employ the ANSI/NISO Z39.71 Standard in the cataloging of serials and their holdings records. Notably, Primo does not utilize the 853 (Captions and Pattern) and multiple 863 (Enumeration and Chronology) fields. Instead, Primo employs the equivalent free-text fields, specifically the 866 field. Consequently, ensuring the accuracy and well-organization of data in the 866 field is crucial for serials’ holdings records. As depicted in the Figure 2 below, for example, the input of numbers for each month and season in the 863 field initiates the automatic generation of paired coded text data in the 866 field.
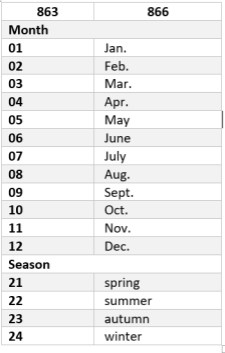
Figure 2. Example of MARC Codes for Months/Seasons and the ANSI/NISO Abbreviations in Holdings record
Approach
Our methodology involved augmenting holding records with 853 (Captions and Pattern) and multiple 863 (Enumeration and Chronology) fields. In Alma, the automatic creation of the summary field (866) was based on the information in the 853 and 863 fields. The addition of 853 and 863 fields was intended to update the 866 fields, ultimately reflecting the revised holdings information in Primo. However, we encountered a challenge due to the variability in the provided holding information for each serial, along with distinct patterns. Also, all holding information was consolidated in the 866 field (summary field) as presented in Primo (Figure 3). The incorporation of 853 and 863 fields across over 5,000 records proved to be a time-intensive process. Consequently, we chose to explore the application of regular expressions to identify the issuing pattern for 853 and the enumeration/chronology for 863.

Figure 3. Holdings information in Primo before the update
The Data
This study utilized a dataset comprising 5,254 serials holding records subjected to ingestion. To improve accessibility during the migration process, a free-text note labeled “ONEInmagicSerials” was appended to the local note 910. This deliberate step enhanced retrieval from Alma, allowing for precise searches within both Alma and Primo VE. Importantly, this approach facilitated the generation of a comprehensive Excel-based list (see Figure 4), encompassing key bibliographic information, including titles (245$a), MMS ID (001$a) [2], OCLC number (035$a), and Library of Congress Subject Headings (650$a).
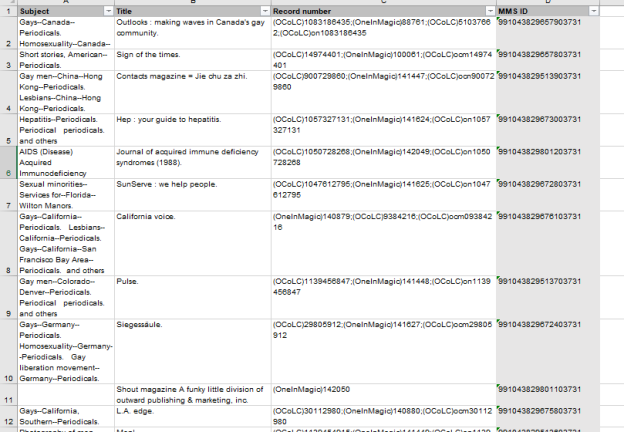
Figure 4. Examples of exported bibliographic data
Data retrieval and update via Z39.50 in MarcEdit
Although Alma offers the capability to export bibliographic, inventory, and authority records, it is important to note that Alma does not provide specific functionality for exporting holdings records in MARC21 XML or binary format. Consequently, we opted to utilize the MarcEdit-Alma integration to obtain the holdings records. Leveraging the Z39.50/SRU Client-server, we conducted batch searches for MMS IDs and subsequently downloaded the corresponding holdings records in bulk. This task takes a considerable amount of time in MarcEdit, so we have divided the files into six separate parts to manage it more efficiently.
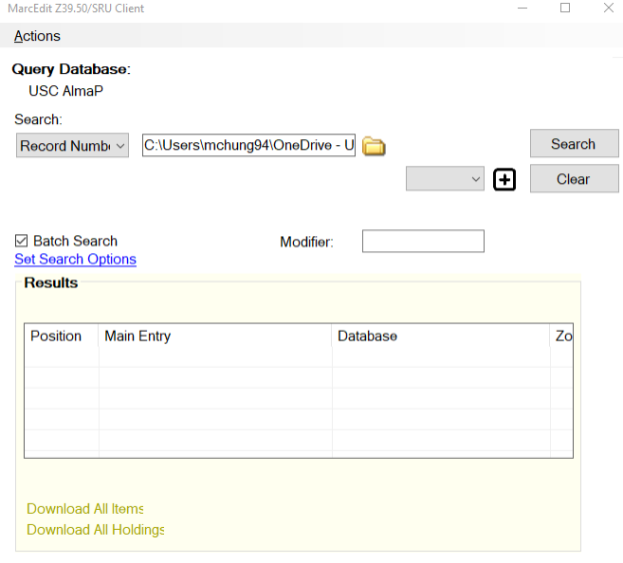
Figure 5. Batch MARC Record Retrieval using Z39.50/SRU in MarcEdit
MarcEdit was utilized for the retrieval and updating of holding records in Alma. Upon extracting all holding records, the files were saved in both binary MARC file (mrc) and mnemonic MARC text file (mrk) formats [3]. The .mrc file is employed during program execution, while the .mrk file serves as a tool for reviewing current records and extracting insights for constructing regular expressions. Moreover, the .mrk file serves as a backup to enable the restoration of records in case of errors or inadvertent mistakes.
Serials cataloging demands advanced skills and knowledge. While reviewing the holdings records, we collaborated with our senior serials cataloger to deliberate on the optimal approach for generating 853 and 863 fields. Concurrently, a meticulously coded holdings record is conducive to machine readability, affording us the opportunity to explore a semi-automated enhancement process.
=LDR 00366nx a22000851n 4500
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424100908.0
=852 8\$bONEARCHIVE$cone-mbl$xmagazine
=866 \\$a2014: (31 [Jun])2015: (1 [Dec])2016: (56 [Oct])2017: (66-67
[Sep-Oct])2018: (73-74 [Apr-May],79-80 [Oct-Nov])
=999 \\$aALMA_BIB_NUMBER
$b991043829289303731
$cALMA_HOLDINGS_NUMBER
$d221271756360003731
=LDR 00291nx a22000851n 4500
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424100909.0
=852 \\$bONEARCHIVE$cone-nwp$xnewspaper
=866 \\$a1991: 2 (9[May/Jun], 10[Jul/Aug])
=999 \\$aALMA_BIB_NUMBER
$b991043829287003731
$cALMA_HOLDINGS_NUMBER
$d221271756320003731
=LDR 01274nx a22000851n 4500
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424100910.0
=852 \\$bONEARCHIVE$cone-nwp$xnewspaper
=866 \\$a1979: 1 (6-8 [Sep-Dec])1980: 2 (1-3 [Jan-Mar], 5 [May], 10-11
[Oct-Nov], [Dec])1981: 3 (1-11 [Jan-Nov], 1{lcub}sic{rcub} s/b
12[Dec])1982: 4 (1-12 [Jan-Dec])1983: 5 (1-12 [Jan-Dec])
1984: 6 (1-12 [Jan-Dec)]1985: 7 (1-2 [Jan-Feb]); v.8
({lcub}sic s/b v.7{rcub} (3-12 [Mar-Dec])1986: 8 (1-12 [Jan-Dec])
1987: 9 (1-12 [Jan-Dec])1988: 10 (1-5 [Jan-May], 6 [Jun 3],
8 [Jul 1], 10-17 [Aug 5-Dec 2])1989: 11 (1 [Jan6], v.10
{lcub}sic s/b v.11{rcub} (2 [Feb 3], 4-7 [Mar 3-Apr 21],
9 [May 19], 11 [Jun 23], 13-14 [Jul 21-Aug 4]); v.11 {lcub}sic
s/b v.12{rcub} (1 [Sep 1], 2 [Sep 15], 4 [Oct 20], 5 [Nov 3],
6 [Nov 17], 7 [Dec 1], 8 [Dec 15])1990: 11 {lcub}sic s/b
v.12{rcub} (10 [Feb 2], 11 [Feb 16], 12 [Mar 2], 13 [Mar 16],
14 [Apr 6], 15 [Apr 20], 16 [May 4], 17 [May 18], 18 [Jun 1],
19 [Jun 15], 20 [Jul 6], 22 [Aug 3])1991: 12 [sic s/b v.13{rcub}
(12 [Mar 1], 23 [Aug 16])1992: 14 (2 [Oct 2])1993: 15 (1 [Sep 3])
1995: 16 (11 [Feb 17], 12 [Mar 3])1996: 17 (8 [Jan 19], 23 [Aug
16]); v.18 (2 [Oct 4])1997: 18 (13-14 [Mar 21-Apr 4], 16 [May 2],
24 [Sep 5])1998: 19 (23 [Aug 7])
=999 \\$aALMA_BIB_NUMBER
$b991043829282703731
$cALMA_HOLDINGS_NUMBER
$d221271756190003731
Figure 6. Examples of retrieved Holdings records in MarcEdit (in mrk format)
Implementation
In this section, we will provide a detailed explanation of the implementation of the Python-based code for automating MARC record management. This code leverages the Pymarc library and other Python modules to efficiently process MARC records and extract issue-specific information.
Importing Necessary Libraries
The code begins by importing the required Python libraries. These libraries provide essential functionalities for MARC record processing, file selection, regular expressions, and data manipulation.
# Import necessary libraries from pymarc import MARCReader, Field, Subfield from tkinter.filedialog import askopenfilename import re from copy import deepcopy
- ‘pymarc’: This library is used for working with MARC records, providing functions to read, manipulate, and create MARC records.
- ‘tkinter’: This library is employed to create a file dialog for the user to select the input MARC file.
- ‘re’: The re library is used for regular expressions, which play a crucial role in extracting issue-related information from MARC records.
- ‘deepcopy’: The deepcopy function is utilized to create a deep copy of MARC records to prevent modifying the original records.
Loading MARC Records:
The code proceeds by prompting the user to select a MARC file using the ‘askopenfilename’ function from the ‘tkinter’ library. This selected file will serve as the input for further processing.
# Load MARC records from a file filename = askopenfilename() records = readFile(filename)
Processing and Modifying MARC Records
This section focuses on the parseFile function, which iterates through the MARC records, examines their content, and extracts issue-related details. Let’s break down the steps in more detail:
Deep Copying Records
Before processing any MARC records, the code creates a deep copy of each record. This is a crucial step to ensure that the original MARC records remain unaltered. Deep copying prevents any unintended modifications to the source data, preserving its integrity.
new_record = deepcopy(record)
Parsing ‘866’ Field
The code checks if the current MARC record contains an ‘866’ field. In MARC records, the ‘866’ field is typically used to store information about issues and volumes of a publication.
if '866' in new_record:
Regular Expression Matching
The code uses regular expressions (regex) to match and extract relevant information from the ‘866’ field. In particular, it targets patterns that represent years, volumes, and issue information. Here’s a breakdown of the regex pattern:
year_pattern = r’(\d{4}):\s?(\d+)?\s*\((.*?)\)’
- (\d{4}): This group captures a four-digit year. The \d{4} pattern matches four consecutive digits, which represent the publication year of the issue.
- :\s?: This part matches a colon followed by an optional space. The colon is used to separate the year from the rest of the content.
- (\d+)?: This group captures an optional set of digits for volume information. The \d+ pattern matches one or more consecutive digits, representing the volume number.
- \s*: This part matches any additional spaces. It allows for flexibility in handling different formatting styles in the ’866’ field.
- \((.*?)\): This group captures text enclosed in parentheses, which typically represents issue information, such as issue numbers and issue months. The \((.*?)\) pattern matches any text enclosed in parentheses.
By using these groups, the regular expression effectively extracts the year, volume (if present), and issue-related information from the ‘866’ field.
Formatting Data
Once the regex matches are found, the code proceeds to format and organize the extracted data. It splits the issues into separate components, including year, volume, issue number, and issue month.
issues = breakIntoIssues(content)
issues_text = []
for issue in issues:
ret = extractIssueNumberAndMonth(issue)
if not ret:
continue
issue_number, issue_month = ret
if issue_number != "":
contain_issue_number = True
if issue_month != "":
contain_issue_month = True
issues_text.append([year, volume, issue_number, issue_month])
Splitting Issues
The ‘breakIntoIssues’ function splits the issues into a list of individual issues, typically separated by commas.
Extracting Issue Details
Within the section of code responsible for processing and formatting issue-related information, the extractIssueNumberAndMonth function is utilized to extract issue-specific details from each issue string. Here’s an in-depth look at how this function works:
The extractIssueNumberAndMonth function takes an issue string as input, which represents one of the issues extracted from the ‘866’ field of a MARC record.
- It initializes issueNumber and issueMonth as empty strings to store the extracted issue number and issue month, respectively.
- The function examines the first character of the issue string:
- If it starts with a digit (0-9), it assumes that the issue string contains both an issue number and an issue month/year. It splits the string into two parts using the first space as a delimiter. If there’s no space, it assigns the entire string to issueNumber.
- If the first character is “[“, it assumes that the entire issue string is an issue month/year in square brackets and assigns it to issueMonth.
- If neither of these conditions is met, it means that the issue string doesn’t contain relevant information, and the function returns an empty list.
- If issueMonth has been identified, it removes the square brackets (if any) and performs additional cleaning by calling the cleanIssueMonth function. This function standardizes issue months to a numerical format, such as converting “Spring” to “21.”
- Finally, the function returns a list containing [issueNumber, issueMonth] as extracted from the issue string. If either issueNumber or issueMonth is not present, the respective field in the list will be an empty string.
The extracted issue number and issue month (if available) are then used to populate the issues_text list for further organization and are eventually added to the ‘863’ fields within the MARC record.
This function plays a pivotal role in accurately extracting and formatting issue-related details, making them suitable for integration into MARC records.
Let’s consider an example issue string:
1983: 5 (7-30 [Jan 28-Dec 29])1984: 6 (1-4 [Jan 5-Jan 26], 6 [Feb 9], 11-12 [Mar 15-Mar 22])
- The extractIssueNumberAndMonth function processes each issue string individually.
- First Issue (1983: 5):
- The function encounters the first issue in the example, which is “1983: 5.”
- In the example, this issue string starts with a digit (1983), indicating the year.
- It then looks for a space to split the issue string into two parts. In this case, it finds a space between “1983:” and “5.”
- The first part, “1983,” is interpreted as the year, and the second part, “5,” is the issue number.
- These details are extracted and stored.
- Second Issue (1984: 6):
- The function proceeds to the next issue, which is “1984: 6.”
- Similar to the first issue, it recognizes the year (1984) and issue number (6).
- Again, these details are extracted and stored.
- Issue Months and Additional Details:
- In the example, there are additional details enclosed in square brackets, such as “[Jan 28-Dec 29],” “[Jan 5-Jan 26],” “[Feb 9],” and “[Mar 15-Mar 22].”
- The extracted month and date details enclosed in square brackets are now sent to the cleanIssueMonth function for processing.
- The cleanIssueMonth function removes the square brackets and further breaks down the month and date information.
- Additionally, if the extracted issue month is a season, it is replaced by a number as explained in a subsequent section.
Resulting Data Structure
The ‘issues_text’ list is structured to contain lists for each issue, each containing the year, volume, issue number, and issue month. This structured data is used to create ‘863’ fields in the MARC record.
Creating New MARC Fields
For each set of extracted issue details (year, volume, issue number, and issue month), the code creates new ‘863’ fields in the MARC record. These fields are added to the record to store the extracted information.
new_863_field = Field (
tag = '863',
indicators = [’40’ if '-' in issue_month or '-' in issue_number else '41'],
subfields = [
Subfield(code='8', value = f' 1.{i} '),
Subfield(code='a', value = f' {year} ')
]
)
- The ‘863’ field is created with appropriate indicators based on whether issue numbers and months contain hyphens, which is used to signify ranges.
- Subfields are added to store year information.
- If available, volume, issue number, and issue month subfields are added.
These ‘863’ fields effectively capture and organize the extracted issue-related data within the MARC record.
Final Organization
After processing all the matches and creating ‘863’ fields, the code also adds a ‘853’ field to the MARC record. This field is used to signify the organization of the record, including information about years, volumes, issue numbers, and issue months.
The code also appends an ‘007’ field to represent the content type of the record. These additional fields enhance the cataloging and organization of MARC records.
new_record.add_ordered_field(new_853_field) new_record.add_ordered_field(new_007_field)
By following these steps, the code efficiently processes and modifies MARC records, ensuring that issue-specific information is accurately captured and organized within the records. This automation simplifies the cataloging process and enhances the consistency and accuracy of catalog records in libraries.
Results
Upon executing the .mrc file in the code program, it appended 853 and 863 fields in .txt format. Subsequently, we accessed the .txt file using Marc Editor in MarcEdit. In the last phase of the cleanup, just before the update, it was imperative to ensure the removal of existing 866 fields. This step was necessary because new 866 fields were generated in Alma, reflecting the updated information from the newly added 853 and 863 fields. Alma facilitates the automatic generation of 866 fields for summary holding information based on the content of the linked 853 and 863 fields.
=LDR 00336cy a22000851n 4500
=007 ta
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424100048.0
=852 \\$bONEARCHIVE$cone-mag$xmagazine
=853 20$8 $a (year) $b v. $c (season)
=863 41$8 1.1 $a 1972 $b 1 $c 22
=863 41$8 1.2 $a 1973 $b 2 $c 24/21
=863 41$8 1.3 $a 1975 $b 3 $c 24
=863 41$8 1.4 $a 1976 $b 5 $c 22
=999 \\$aALMA_BIB_NUMBER
$b991003920649703731
$cALMA_HOLDINGS_NUMBER
$d221271644230003731
=LDR 00288cy a22000851n 4500
=007 ta
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424095827.0
=852 \\$bONEARCHIVE$cone-mag$xmagazine
=853 20$8 $a (year) $b (month)
=863 41$8 1.1 $a 1975 $b jan
=863 41$8 1.2 $a 1975 $b mar
=863 41$8 1.3 $a 1975 $b apr/may
=999 \\$aALMA_BIB_NUMBER
$b991003916459703731
$cALMA_HOLDINGS_NUMBER
$d221271636040003731
=LDR 00279cy a22000851n 4500
=007 ta
=008 1011252u\\\\8\\\4001uueng0000000
=005 20230424095846.0
=852 \\$bONEARCHIVE$cone-mag$xmagazine
=853 20$8 $a (year) $b v. $c no.
=863 41$8 1.1 $a 1986 $b 1 $c 3
=863 41$8 1.2 $a 1988 $b 1 $c 8
=999 \\$aALMA_BIB_NUMBER
$b991003915539703731
$cALMA_HOLDINGS_NUMBER
$d221271633800003731
Figure 7. Examples of updated holding records in MarcEdit
We identified instances where records were omitted due to incomplete information in the 866 field, specifically when the 863 fields were absent. Approximately 600 records were found to lack the necessary 863 fields. Consequently, we undertook the task of extracting these records for further attention. Samples of these instances are provided below:
=866 \\$a?: 0 (1 [?]) =866 \\$a?: (17 [?]) =866 \\$a?: 1 (6 [?], 7 [?], 12 [?]) =866 \\$a?: (3 [?])
After running the .mrc file through the code program, which added 853 and 863 fields in .txt format, the .txt file was manually inspected using MarcEditor in MarcEdit to check for any errors. In the conclusive cleanup phase, conducted just before the update, it was crucial to ensure the elimination of the existing 866 fields. This step was taken because new 866 fields were created in Alma to align with the updated 853 and 863 fields.
Consequently, the omitted records did not generate 863 fields and lacked the corresponding information. This prompted the extraction of records lacking 863 fields, totaling approximately 600 entries. Recognizing the presence of skipped holding records emphasized the necessity of collaboration with OneArchives to validate actual holding information, acknowledging the limitations observed in the migrated serials holding data.
In summary, we successfully updated 4,629 holding records out of a total of 5,254. Throughout the updating process, Alma MMS ID and Holding ID were utilized to search for and update records via the Z39.50/SRU Client-server and MarcEdit. Both identifiers are embedded in the 999 field, which is automatically created when downloading records through the MarcEdit-Alma integration.
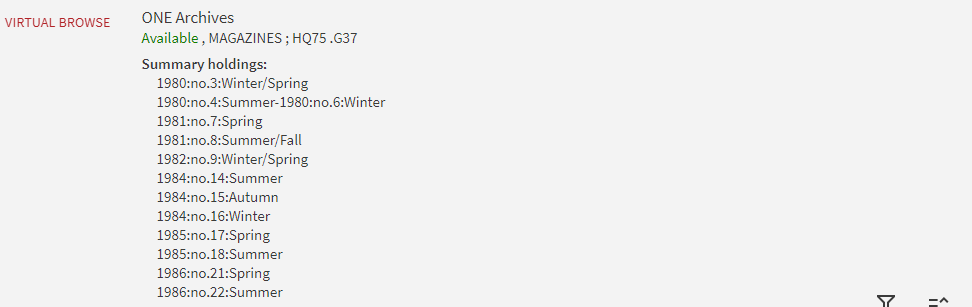
Figure 8. Holdings information in Primo after the update [4]
Discussion and Next Steps
Through this project, we have validated the capacity to identify patterns within semi-structured holding data using regular expressions, thereby elevating the quality of holding records. In our approach, we abstained from the conventional practice of cleaning up raw data, instead choosing to employ regular expressions to directly derive organized data from the unrefined dataset. This decision served a dual purpose, acting as both an experimental venture and, in hindsight, an unfortunate one.
Opting for the initial cleanup of raw data within the 866 field through OpenRefine, followed by the execution of the .mrk file in the code program, might have facilitated the formulation of simpler regular expressions and potentially yielded a more refined outcome.
The paramount goal of this project was to enhance the presentation of serial holdings, aiming for increased user efficiency in verifying holding information. We anticipate that users engaging with information in the reopened archive will find it more user-friendly and informative. In the aftermath of this project, our future endeavors include collaborating with OneArchives to address the records that were inadvertently skipped.
References/Notes
Our Codebase: https://github.com/chaitupendyala/inmagic-project
Alma Documentation: Export and Publishing. [accessed 2023 Sep 21] https://knowledge.exlibrisgroup.com/Alma/Product_Documentation/010Alma_Online_Help_(English)/040Resource_Management/075Publishing_Profiles/030Export_and_Publishing#:~:text=Alma%20supports%20the%20ability%20to,binary%20and%20Dublin%20Core%20XML.
Alma Documentation: Holding Records. [accessed 2023 Sep 21] https://knowledge.exlibrisgroup.com/Alma/Product_Materials/050Alma_FAQs/Print_Resource_Management/Holding_Records
Abrahamse, Benjamin. (2010). Batch MARC Record Retrieval using Z39.50. New England Technical Services Librarians. (NETSL) / 2010 Massachusett. https://netsl.files.wordpress.com/2013/01/abrahamsegofishnetsl2010.pdf
ANSI/NISO Z39.71-2006 (R2011) Holdings Statements for Bibliographic Items. (2011). [accessed 2023 Sept 22]. https://www.niso.org/publications/z3971-2006-r2011
MARC 21 Format for Holdings Data: Table of Contents (Network Development and MARC Standards Office, Library of Congress). [accessed 2023 Sep 26]. https://www.loc.gov/marc/holdings/
Pymarc Codebase: https://gitlab.com/pymarc/pymarc
Pymarc Documentation: https://pymarc.readthedocs.io/en/latest/
Pymarc PDF: https://pymarc.readthedocs.io/_/downloads/en/stable/pdf/
Python Regular Expression: https://docs.python.org/3/library/re.html
Reese, Terry. (2016). MarcEdit Alma Integration. https://blog.reeset.net/archives/1950
Notes
[1] ONE Archives at the USC Libraries is the world’s largest repository of Lesbian, Gay, Bisexual, Transgender, and Queer (LGBTQ) materials. Since 2010, ONE Archives has been an integral part of the University of Southern California Libraries. It is located at 909 West Adams Boulevard, Los Angeles, CA 90007. [accessed 2023 Oct. 11]. https://one.usc.edu/about
[2] MMS ID = Metadata Management System ID. In Alma, MMS ID can be 8 to 19 digits long (with the first two digits referring to the record type and the last four digits referring to a unique identifier for the institution). [accessed 2023 Oct. 17] https://knowledge.exlibrisgroup.com/Alma/Product_Documentation/010Alma_Online_Help_(English)/010Getting_Started/085_Alma_Glossary
[3] Binary is a format consisting of a series of sequential bytes, each of which is eight bits in length. The Mnemonic MARC text file is a format used by MarcEdit that is a human-readable version of the binary file.
[4] Primo permalink for the example record: https://uosc.primo.exlibrisgroup.com/permalink/01USC_INST/qk93vi/alma991003915619703731
About the Authors
Minyoung Chung is a Monographs and Special Projects Cataloging Librarian at the University of Southern California.
Phani Chaitanya Pendyala is a Computer Science Graduate Student at the University of Southern California. Alongside his studies, he serves as a student assistant at the USC Grand Library.

Subscribe to comments: For this article | For all articles
Leave a Reply