by Todd Digby, Cliff Richmond, Dustin Durden, and Julio Munoz
Introduction
As with the Integrated Library Systems, where some libraries are moving through their third or fourth generation of ILS’s, we are now starting to see these generational changes to our digital library and institutional repository systems. Generally, our migrations to new digital library systems are not as seamless and straightforward as our cousin ILS system. The University of Florida’s digital library system, first launched in 2006, presented additional complexity in our ability to easily migrate to a new modern digital library system. The system was locally developed and was not based on more common digital library systems, like DSpace or Islandora. With the system architected using an aging Microsoft SQL/IIS framework, our ability to adapt and make changes to the system became challenging, especially since the lead developer had left UF and our ability to find developers who were fluent in these technologies became increasingly difficult. A turnover of programmers and developers happened in 2020, which jump-started our decision to develop a new system using more commonly used development and technology platforms. This article will examine our experience in re-architecting our digital library system and deploying our new multi-portal, public-facing system.
Historical background
The University of Florida Digital Collections (UFDC) currently hosts local and international collections, housing over 18 million files of content, including all material types, including books, archival documents, newspapers, photographs, audio, video, museum objects, data sets, and maps, that have been published in many languages. During the 1990s, the UF Libraries began experimenting with digitization of print materials for the purposes of preservation and broader access to collections. In 1999, the UF Libraries formalized ongoing support for this digitization effort by creating the Digital Library Center. These digitization efforts were further expanded with the creation of the University of Florida Digital Collections (UFDC) system in 2006. The system was powered by the open-source SobekCM system (http://sobekrepository.org/sobekcm), which was originally developed at the University of Florida, and is run on Microsoft web and database-based servers. As the system developed, it grew in complexity to accommodate the unique characteristics of these various types of digital content and digitization workflows. The SobekCM system also powered the Digital Library of the Caribbean (dLOC, https://dloc.com), which the UF Libraries are one of the founding partners and the technical host partner of. Started in 2004, dLOC has grown to include 70 partners and associate partners in the United States, the Caribbean, Canada, and Europe.
Like many systems developed during this time period the SobekCM system is structured to power both the back-end production work, as well as serve as the public-serving front-end. Over the past decade and a half, there have been minor incremental system updates, but the interface essentially stagnated. The system served the library and the users well for the past decade, but the age of it is showing and change was needed.
Need for Change
Besides the system being developed using a technological framework that was over a decade and a half old, there were additional factors that led to the decision to undertake a major effort to re-architect and modernize the UFDC system. As the system was internally developed and not based upon other open-source digital library systems, having programmers that were knowledgeable in how the system was developed was key to being able to respond in a timely manner to resolve issues or in the development of new features. Since the original developer of the system departed UF a number of years ago, it has become increasingly difficult for new team members to be able to understand the nuances of the system. Additionally, since the system was based within the Microsoft realm, including MS-SQL, IIS, and mostly written in C#, it became difficult to find individuals who have the required skill sets. Configured to run on older Windows Server versions, there became an increasing concern that a future server OS version may render the SobekCM system inoperable. With our server infrastructure hosted by campus IT, we were not in a position to potentially be open to security vulnerabilities by having the system remain on a version no longer supported by Microsoft. In recent years the instability of the system became more and more evident with more frequent interruptions. With both the digital production or back-end tools and the public-facing system on the same instance, if one system was having an issue and needed to be restarted, it would impact the entire system, including the staff processing and making additions to the system.
Another impetus that impacted our decision was hearing from granting agencies who were reluctant to allocated grant funds to a system that looked dated and was not fully mobile friendly and accessible for users today.
Decisions – Build versus Buy/Implement Open Source
We knew we needed to move to or develop a new digital library system, but we also needed to decide if we were going to develop the system on our own or were going to implement and then migrate our existing digital collection to one of the many systems available across the digital library system landscape of both commercial and open-sources systems. Since the system was developed internally, it continued to change and accommodate new formats and varieties of digital content as they became available, unlike many other academic institutions which implemented systems that were designed around the type of materials being housed. For instance, libraries have historically implemented different digital library systems for collections like newspapers and photos, or act as their institutional repositories, which could respond to the unique search, metadata, and file types needed for those types of materials. An examination of the currently available systems led to the conclusion that it may be necessary to break up our content into unique systems or we may lose some of the customized interfaces that we had developed, such as our digital maps and aerial imagery collections where a customized coordinate-based map search system was implemented. Additionally, with two major front-end discovery views (UFDC and the Digital Library of the Caribbean) we needed a system that could replicate our existing system. With no clear available system, and a priority of library leadership to keep the collections housed within a single system, the decision was made to once again develop the system ourselves. The decision was also made to develop the new system and technological infrastructure by using open-source components and open, standards-based protocols and formats.
Designing the System
Before deciding on an architecture for our updated system, we needed to map out how we were going to stage our development efforts and what part of the system we should concentrate on first. Working within the constraints of needing to keep our existing system fully available and also not stopping the ingestion of materials. At this time, we were ingesting large grant-funded digitized collections that could not be postponed because of the deliverables that were agreed upon as part of the various grants we were involved in. Knowing that we had to keep our back-end system available for loading materials into the system, it was decided that we would first build our front-end digital library components. This decision was also made easier, given the fact that we wanted to update the system architecture to separate the component systems, such as the front and back-end systems, that would address whole system downtime issues. Additionally, in our desire to have a more stable system, we wanted to build in redundancy and fail-over as part of the initial deployment process.
As part of our environmental scan process, we examined other digital library system implementations that have large homegrown digital library systems. We met with the University of North Texas (https://digital.library.unt.edu/), who offered valuable insights and directions on the structure of their locally developed system.
Technology Stack
With the decision to focus on the public-facing system, we could continue to use the data from the existing system to feed the new front end. Using open source components gave us the opportunity to move from Windows-based servers (IIS and MS-SQL) to a Linux-based technology stack. In 2021 we were in a unique staffing situation with our digital development team, where we had an entirely new development team consisting of two front-end and two back-end developers, who had no previous experience with our existing digital library system or any prior digital library experience. This team, however, had expertise and experience with modern database and indexing toolsets and development frameworks.
The technology stack that was decided on was implementing a PostgreSQL database, with an Elasticsearch search engine, and a NGINX web server. To modernize and create a more flexible front-end, it was decided that it would be driven by APIs. With the goal to have redundancy and fail-over built into the system design, we implemented a redundant production web server environment with load balancing to meet possible system demands. For the database and search engine, we implemented redundant servers. Since we were only focusing on our front-end, we designed it in a way to continue to point at our existing files or resource server to pull the access files of our digitized materials. How the system is structured can be seen in Figure 1.
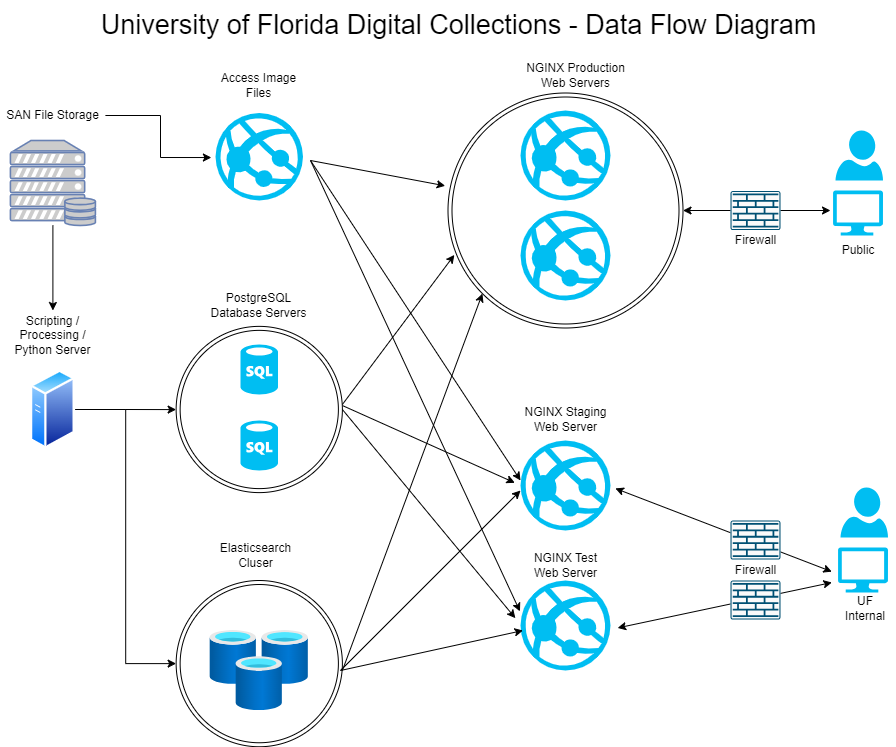
Figure 1. UFDC system architecture diagram
Development
As with any system development we needed to focus on target objectives for an initial release. To prevent feature bloat and continued refinement which may lead to a delay in release, we set out to define a minimum viable product (MVP) for initial release, with alpha and beta release stages. We needed to have a system that would replicate the main functions of our existing system, while at the same time gave us an opportunity to assess if any of our old features were still important to include. We stripped away many of the lesser used features, such as users being able to have their own bookshelf of items and the ability for users to self-submit within the front-end to our institutional repository (IR). During this development period, we made additional efforts to work with collection curators to undertake a clean-up of the ever expanding list of collections that were contained in the system. Many of these collections had limited items or may have been created but not really used or expanded as expected. Through this effort we went from having over 900 collections to under 500.
For our minimum viable product (MVP), all development had to be done while the current system continued to operate with no interruptions and back-end production could continue without interruption. As we developed our production system, we also changed how we implemented our code testing and refinements. This meant implementing a full front-end test system, where the developers could release their code only available to be accessed by those within the development team. Once code was through testing, we moved it to the staging environment. This staging environment is available to on-campus library employees to test features and functionality before it is moved to the full production servers. These test environments use the same search APIs as the production environment and also have access to the access files available, so accurate testing can happen in this staging environment.
With clear objectives defined, we also implemented an agile development framework, which set up clear staged deliverables for each team member. With a team that had limited experience working in libraries, it was decided that the library technology department leadership would attend the daily standup meetings, so that we were able to address any issues or questions from the team immediately. This streamlined the development significantly and enabled the whole team to come together. Since this system was a high priority for library leadership and the fact that we had the ability to focus on building the new system, we were able to go from initial development starting around May 2021 to being able to release the system in beta to the public at the end of November of 2021.
One of the major goals of developing the new system was to maintain the multiple portal approach to our digital collections. The system now consists of a UFDC portal interface that includes the ability to search the entire aggregate of the collections we house, and additionally includes different user interfaces into the dLOC and Florida Digital Newspaper Library (FDNL, https://newspapers.uflib.ufl.edu) subcollections (Figure 2).
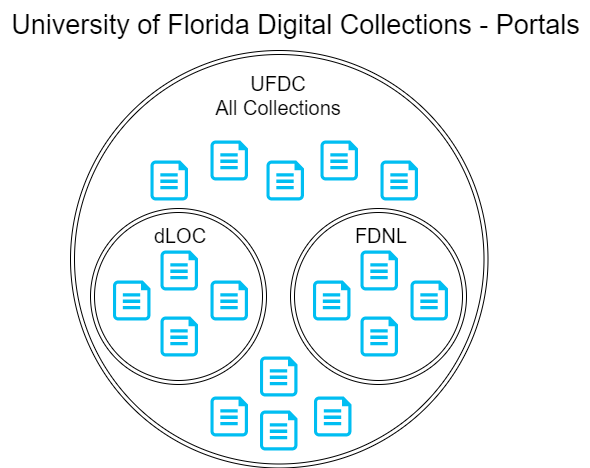
Figure 2. UFDC Collection / Portal Diagram
The multiple portal approach allowed us to develop slightly different user front-ends that are customized to the types of materials being searched/displayed and to the potential audiences that are accessing the collections. This new development not only resulted in being able to replicate our two existing collection portals, but given the flexibility built into the new system, we were able to create a new portal dedicated to our Florida Digital Newspaper Library (Figure 3).
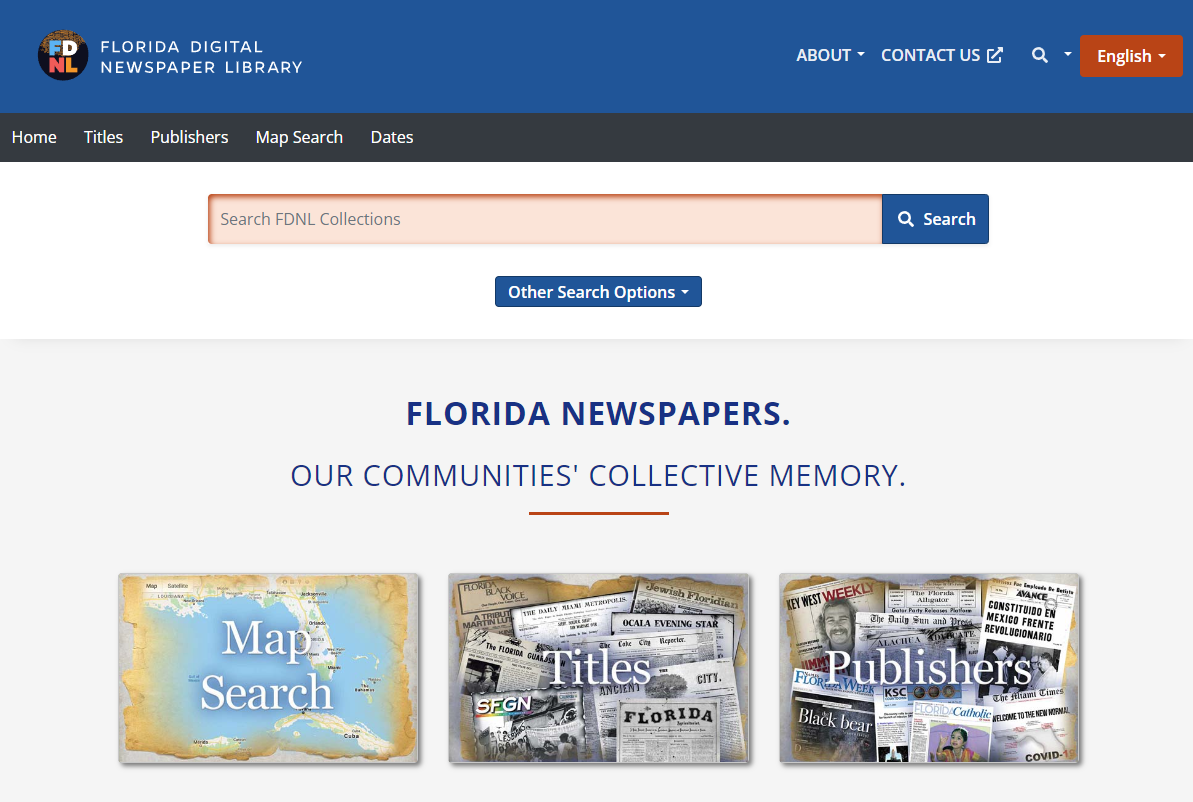
Figure 3. Florida Digital Newspaper Library portal
An example of the customizations that we were able to do within a customized portal is our Title search/browse feature within the FDNL collection. Since the newspaper titles within this collection are all limited to Florida, we decided to add a map-based county facet/limiter to our Title search section. This way if a user was interested in exploring titles only within a certain county, they could find them more easily (Figure 4).
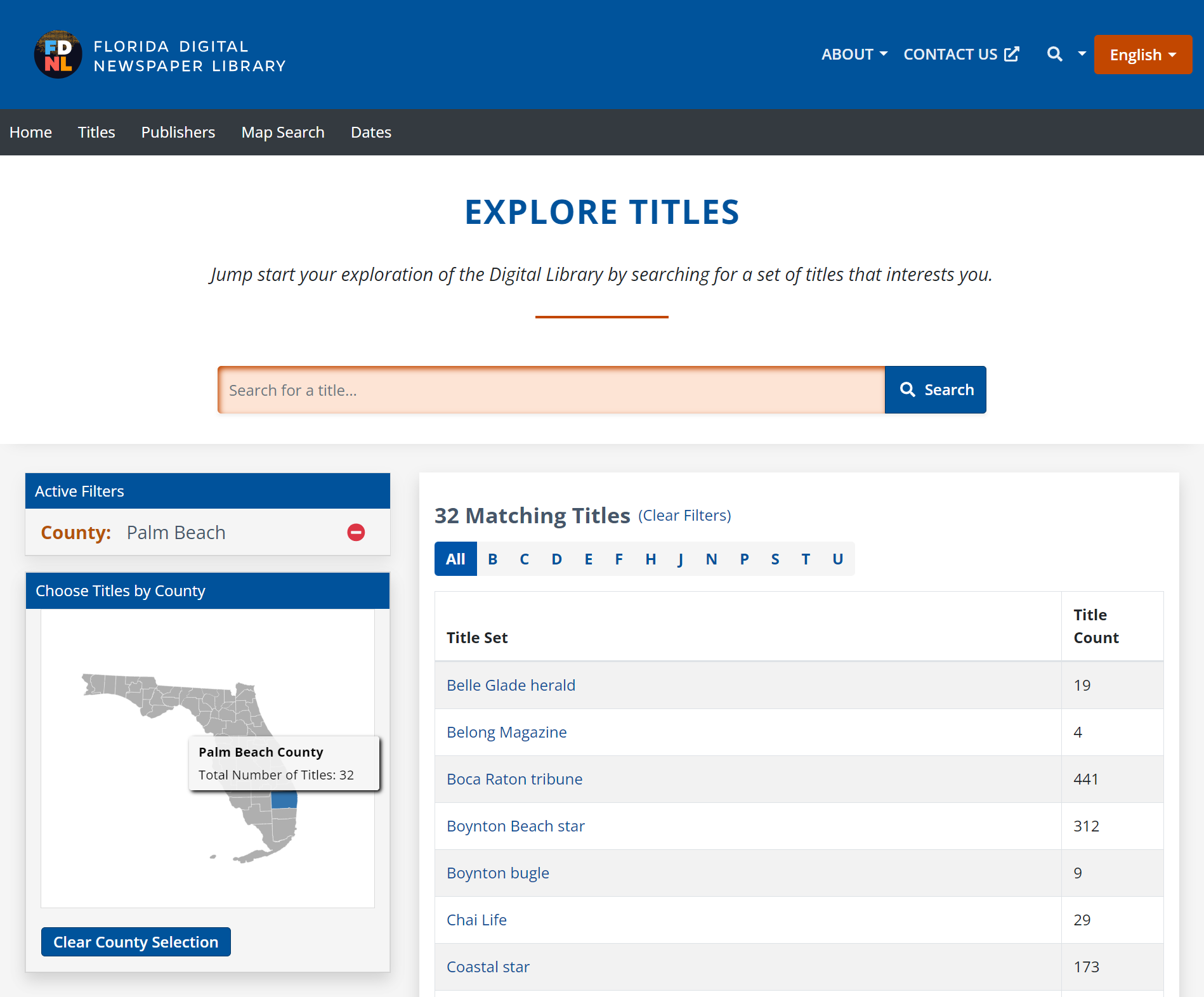
Figure 4. Newspaper Title Search by County
Ongoing Work and Next Stages
Once in beta and being used by the public, we were able to start to refine the user interface and various other search and structural changes. In order to get user-centered input, we established a Library User Resource Discovery Committee, that included a number of librarians and other library staff that worked with the public. This group met regularly and became our main vehicle for moving changes forward in the new system. Another avenue for input was to regularly examine questions that were submitted in our Ask a Librarian service to see if any of the questions related to our new digital library system. This direct input quickly helped us address many issues that were not necessarily evident to our development team. Because the new patron interface is focused on user needs, it’s the perfect way for us to best see the metadata that has highest value and impact for users, and prioritize work to best support the user experience.
As the front-end systems are in place and we are still making incremental improvements, we are now focusing on our back-end production systems. We envision this process to happen at a slower pace than our front-end system development, but we expect most of this work to be completed within the next two years. We have already developed a starting web-based production toolkit (Figure 5) environment where we can release the various component services and jobs needed by our digitization staff.
Figure 5. UFDC Toolkit
Conclusion
Although we continue to make progress and there continues to be a lengthy list of enhancement requests, we are very satisfied with what we were able to accomplish. By focusing on a user-centered design, we were able to understand how our users were using the system and make necessary changes. In addition to being able to produce a new front-end system for our digital library, this effort also enabled us to change many of our internal development and project management processes which continues to benefit both our team and the libraries as a whole.
About the Authors
Todd Digby is the Chair of Library Technology Services at the University of Florida. He leads a department that researches, develops, optimizes, and supports advanced library information systems and technology services for the University of Florida Libraries. He has over 25 years working in technology in academic libraries. He holds an Ed.D. from Hamline University and a Master of Library and Information Studies from the University of Alberta.
Cliff Richmond is the Digital Development Team supervisor within the Library Technology Services Department. Cliff received a BS and MS in Geology from the University of Pittsburgh, and a BS in Environmental Engineering from the University of Florida. He has over 35 years of information technology (IT) experience and is a Certified Information Systems Security Professional (CISSP).
Julio Munoz is a Digital Collections Front-End Web Programmer in the Digital Development Team within the Library Technology Services department. Julio received his Master of Science in Computer Information Systems from the University of Phoenix and his Bachelor of Science in Computer Engineering from Havana University. He also attended the Miami International University of Art and Design for a Bachelor of Fine Arts in Web Design and Interactive Media. Before starting at UF, Julio worked at SharpSpring in Gainesville, prior to that, he worked at Fine Art Biblio as a Web Developer in Miami, Florida, and prior to that, he oversaw the US Navy Fleet Forces Command (FFC) website. He has over 18 years of experience in web design and web development, is a Microsoft certified IT Professional, and a certified Engineer Intern by the Florida Board of Professional Engineers.
Dustin Durden is a Digital Collections Application Developer Analyst in the Digital Development Team within the Library Technology Services department. Dustin has a BA in Computer Science from the University of Florida.

Subscribe to comments: For this article | For all articles
Leave a Reply