by M Ryan Hess and Chris Markman
I. Introduction
ChatGPT and other large language models (LLMs) have sparked much curiosity recently among libraries and information professionals. As a forward-thinking library that likes to experiment with emerging tech, we were eager to explore whether these new AI systems could enhance our work.
While other libraries in 2023 tested applications for GPT-3, we wanted to push further by utilizing the more advanced GPT-4 model within ChatGPT. With patron privacy top of mind, we conducted hands-on experiments focused on SEO optimizations and developing an improved website taxonomy.
Our tests uncovered a mix of successes and failures, revealing fundamental limits around accuracy, bias, and memory. Though imperfect, we believe that with careful oversight, LLMs can augment certain workflows – acting as research assistants, content creators, data analysts and more.
In this article, we detail our Search Engine Optimization (SEO) and website taxonomy experiments to advance the conversation around AI in libraries. We share tangible lessons learned, outlining key skills information professionals will need to selectively incorporate AI into their work. While more exploration is needed, our research highlights the tremendous potential of LLMs to enhance the noble mission of organizing knowledge.
Despite several pitfalls, our experiments represent early and exciting steps toward integrating AI thoughtfully into libraries. With the right human guidance, LLMs promise to boost productivity, creativity, and problem-solving. The path ahead may be winding, but the possibilities make it well worth exploring.
II. Methodology
SEO Experiment #1 – ChatGPT SEO Plugins
This first experiment with SEO was based on an earlier success in 2023 using the free version of ChatGPT. At Palo Alto City Library (PACL) we use BiblioWeb as a content management system (CMS) and make every effort to fully leverage its SEO tools. As a result, this often means updating or reviewing HTML meta descriptions for “freshness” over time.
One workflow issue with this SEO process is that it not only takes time to do, but it is also not the most exciting task: imagine trying to summarize page content and thinking about keyword alternatives on a library website, while also trying to keep in mind various user groups or audiences at the same time. Juggling all of this can be a mentally taxing exercise.
ChatGPT happens to be a champion at this one specific task—just copy/paste the content of any webpage into the chat and in less than 5 seconds it can crunch large blocks of text into short snippets or lists of alternative keywords. At the same time, it can take that same webpage “gist” and generate hundreds if not thousands of variations depending on the context you provide. It’s a prime example of the “cognitive offload” that LLMs can provide
The Plugin Store
Based on this early success, in June of 2023, it seemed like there had to be something new that our newly acquired ChatGPT Pro account and suite of plugins could help us with.
 Figure 1. ChatGPT About Plugins
Figure 1. ChatGPT About Plugins
What we instead found was a slew of privacy and security concerns from plugin makers with zero accountability, and a cheeky “use at your own risk” message from OpenAI. Thankfully, some of these concerns were addressed in later updates to the ChatGPT plugin store in late 2023 with the inclusion of developer information links and contact details. There are sometimes, but not always, privacy policies or terms of service pages. At first glance this does seem like an improvement, but at the time of writing this article, many of these links are essentially placeholders or contain very little information.
Some of these SEO plugins could assist with ranking your site versus others in the same keyword space and search results list. However, they were asking for API keys and full access to Google Analytics. This leads to very interesting philosophical questions like “is it still considered a man-in-the-middle attack if you first ask users to opt-in?”.
Needless to say, the cost-benefit of this setup was not adding up. After browsing several options, it looked like in the few cases where these SEO tools might be useful, Google Search Console already had us covered.
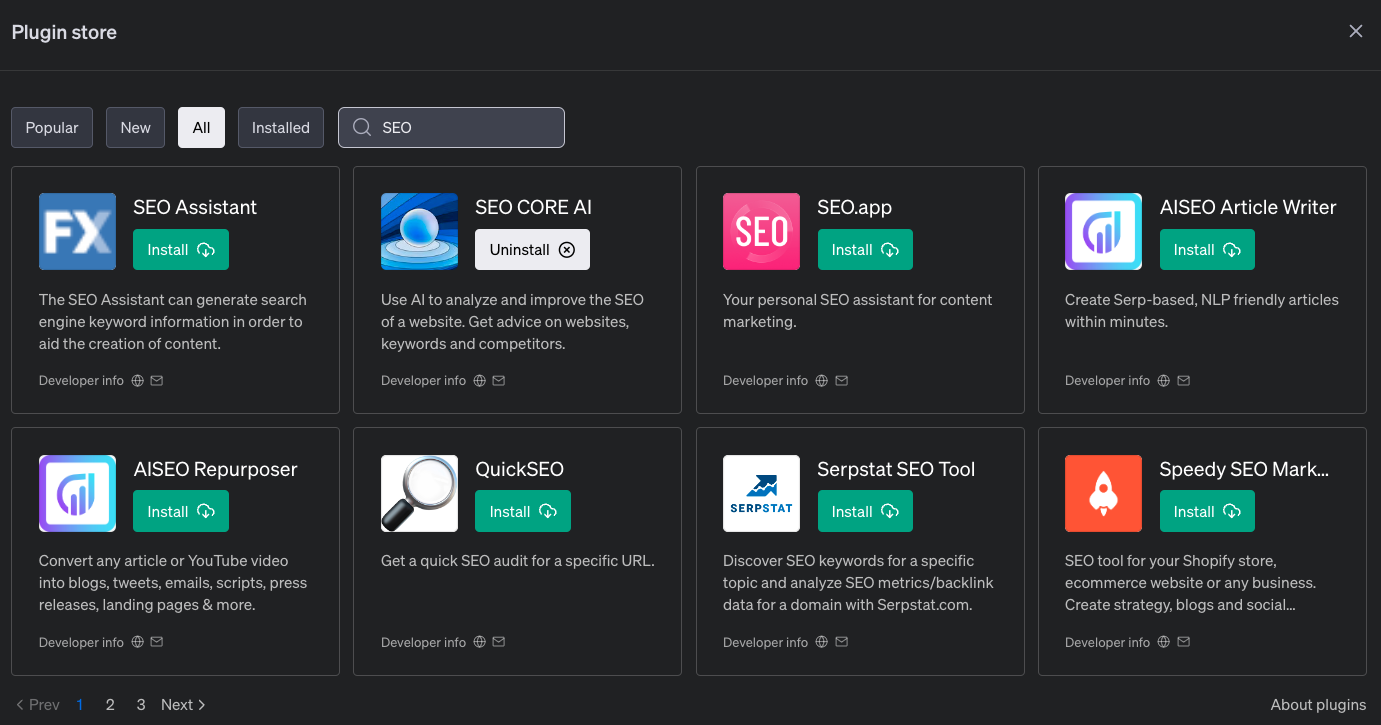 Figure 2. The ChatGPT Pro Plugin Store SEO Options with Developer info links in the fine print.
Figure 2. The ChatGPT Pro Plugin Store SEO Options with Developer info links in the fine print.
Why Reinvent the Wheel?
These plugins could be useful as part of some other automation routine, perhaps in combination with other ChatGPT plugins or features, but for data analysis and web content strategy, ChatGPT Pro already felt like overkill. Around this same time, SEO and marketing experts started to warn about the dangers of LLM generated SEO spam, which eventually lead to notable events like Quora.com’s misinformation feedback loop bleeding into Google Search Results [1] and more and more of this content creeping into top search results [2]. The moral of the story here is that while ChatGPT can help with some aspects of SEO, the overall landscape is full of landmines. Proceed with caution!
SEO Experiment #2 – Working with Sitemap.xml
While the first experiment with plugins (a feature limited to ChatGPT Pro subscribers) suggested the platform was entering Gartner Hype Cycle’s “trough of disillusionment”, our second experiment using the newly added Advanced Data Analysis option did have some positive results. Advanced Data Analysis mode is an excellent feature because it can write custom Python code tailor made for your specific use case. Like meta tags and meta descriptions in HTML, the core elements of the previous experiment, this second experiment was set up to test another basic element of SEO: your sitemap.
You might be wondering at this point, why use Python at all? It’s important to note that Python is the programming language of choice for Advanced Data Analysis mode, so this was part of the experiment itself. While this mode can assist with other coding languages, under the hood it is essentially a plugin developed by OpenAI that “graduated” from the plugin store and became embedded into the product itself. For example, if you upload a CSV file containing a data table in Advanced Data Analysis mode, it will use a Python code library to generate a graph from that data (that is, if you ask it to).
We should also note here that most modern CMS will automatically create and update sitemap.xml files(s) to encourage a good data harvest from roaming web spiders. It’s now a universal process and a very behind the scenes element of most websites, but this wasn’t always the case (and in fact wasn’t a built-in WordPress feature until WordPress 5.5 released in 2020 [3]). In fact, for many years generating this XML document was one of the quickest ways to improve your site’s SEO. Knowing this, surely, there must be something cool that ChatGPT Pro could do with this vital data. For example, being able to quickly create a visual representation of your websites’ overall architecture for discussions with stakeholders or for the purpose of onboarding is extremely useful. Analyzing a sitemap might also help you identify pages that are, for whatever reason, not being indexed. This was the initial idea that started experiment #2.
XML Surprises
As it turns out, our sitemap, which spans over 100 pages of content, is in fact an index file that points to a collection of smaller, chronologically sorted XML files. The real goal was to work with the data inside those smaller XML files, but before ChatGPT could do anything it needed to recombine this data set into a single file. This seemed easy enough for a computer to do—trivial in fact! But this is where the trouble really began.
Our process went as follows: Load the data. Test out what the new subscription-only Advanced Data Analysis feature could do. Maybe generate some interesting visualizations or see what key insights ChatGPT would be able to glean from this odd assortment of timestamps, page titles, and URLs that compose our website topography. Easy, right? We had seen from demos that Advanced Data Analysis could create Python code on the fly. It sounded magical.
What resulted from this experiment was the realization that ChatGPT Pro and its shiny new GPT-4 model, despite its potential for productivity gains, also has the potential to lead one astray. What should have been an easy task was not easy for a newbie programmer who had overestimated their Python coding skills.
Goose Games
The second problem this experiment posed, aside from this initial Dunning-Kruger effect, was that ChatGPT never suggested trying a different approach! Compare this with an in-person reference interview, or even what a Google search might provide: ChatGPT has no knowledge of the person asking the question unless you tell it, its main goal is to answer the question directly and concisely, 100% of the time. Without extra prompting, LLMs have no concept of paring down information based on expertise, the same way you might explain how to install an eBook app differently to a patron with more or less tech-savvy.
Essentially, ChatGPT is far too willing to return what it considers the “top search result” (to go back to the Google search comparison) without first asking if that initial question or search string is really going to solve your problem. This meant that each conversation about this coding problem had turned into a “wild goose chase” where subsequent questions or error messages not only overestimated the knowledge of a novice coder, but was also unable to detect how far these conversations had strayed from the original problem. The correct approach ended up being a Python script that did everything for us in one go. It looked like this:
import xml.etree.ElementTree as ET
import requests
# Function to get XML tree from a URL
def get_tree_from_url(url):
response = requests.get(url)
response.raise_for_status()
return ET.ElementTree(ET.fromstring(response.content))
# Parse the sitemap index file
sitemap_index_url = 'https://library.cityofpaloalto.org/sitemap.xml'
index_tree = get_tree_from_url(sitemap_index_url)
index_root = index_tree.getroot()
# Create a root element for the combined sitemap
combined_root = ET.Element('urlset', xmlns="http://www.sitemaps.org/schemas/sitemap/0.9")
# Iterate through the sitemap URLs
for sitemap in index_root.findall('{http://www.sitemaps.org/schemas/sitemap/0.9}sitemap'):
loc = sitemap.find('{http://www.sitemaps.org/schemas/sitemap/0.9}loc').text
tree = get_tree_from_url(loc) # Download and parse individual sitemap
root = tree.getroot()
for url in root.findall('{http://www.sitemaps.org/schemas/sitemap/0.9}url'):
combined_root.append(url)
# Write the combined sitemap to a new file
combined_tree = ET.ElementTree(combined_root)
combined_tree.write('combined_sitemap.xml')
By the way, ChatGPT wrote and provided comments for us. It was great. The initial misstep was asking how to do each individual step in isolation using methods that were already familiar rather than simply explaining the end goal to ChatGPT first and letting it recommend the best solution. As it turns out, ElementTree is a Python library that exactly solves the problem of parsing and navigating XML documents.
After several attempts to WGET and recombine these XML files using brute force, it seemed like there had to be a better way. This was not a unique problem and someone, somewhere in the history of the internet must have found an elegant solution. Indeed, they had, but getting to that point required taking a step back and first asking ChatGPT to lay out some options.
You can read the full chat transcripts in ChatGPT directly [4], but here’s a quick overview of the conversation that struck gold. Below each question are some notes about why they were asked in that specific order:
- What are some options to solve this data problem with code?
- Three options came back: Create a Python script, use a specialized command line tool, or try an XML editor.
- Before this I had already tried some command line options to no avail, and I remember enough about the quirks of XML editing software from library school homework assignments to quickly avoid that option.
- Here are some details about my local code environment, how would I do this option?
- I picked the Python option with some hesitation because I knew there would be some initial setup steps for MacOS, but I figured ChatGPT could work through any error messages.
- Sounds good, now explain how to do this step by step…please?
- This is where ChatGPT starts to really shine. Being able to ask follow-up questions based on its step-by-step instructions is much faster than sifting through help docs or forum posts.
Results of this experiment were mostly indirect benefits. Parsing our sitemap did highlight pages in our website that had not been updated in a very long time, but much like the SEO plugins, we already had a CMS that could display this same information with a few clicks. The main difference was having a 3rd party point this out automatically through a chat interface. Admittedly, this same insight could have been found through sorting by the last modified date in our CMS, but the key difference is that ChatGPT reported this information automatically through open-ended questions. More importantly, by the end of this SEO experiment, we had gained the ability to take this sitemaps data further with additional Python code tutorials and preexisting software libraries. ChatGPT’s human counterpart took on a new workflow they would have never attempted otherwise, learning how to create, edit, debug, and run Python scripts.
BiblioWeb Taxonomy Experiment
Our second project involved generating new website taxonomies for topics and genres to facilitate better relevancy in the forthcoming Personalized Promotions feature in BiblioCommons.
Personalized Promotions is a feature of BiblioCommons where marketing web content known as ‘cards’ is contextually presented to users in their catalog search results [5]. For example, if a user searches for ‘great films’ a card promoting staff recommendations would show up alongside the normal catalog search results of DVDs and streaming movies.
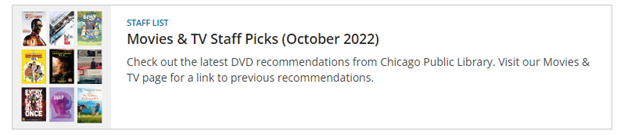 Figure 3. A staff list triggered by a catalog search as it appears inside the catalog search results in BiblioCommons.
Figure 3. A staff list triggered by a catalog search as it appears inside the catalog search results in BiblioCommons.
Our existing taxonomies were rather simple. With the release of Personalized Promotions, however, we realized more robust taxonomies would enhance the relevance of cards that were displayed to our customers.
Enter ChatGPT
We saw potential in ChatGPT Plus to help analyze catalog usage data in order to develop a taxonomy that was related to actual customer interests.
With a Plus subscription, we would have access to GPT 4’s Advanced Data Analysis mode, which provides a way to import data directly into ChatGPT for analysis. Essentially, this tool is like having a Data Analyst on staff who can help us understand patterns in the data, clean up data and even visualize the data.
Data Anonymity
It is important to point out that we anonymized all data provided to ChatGPT. This is important because any data shared with ChatGPT is also transmitted to OpenAI for the purposes of improving their products.[6] Obviously exposing personal customer data was not something any library would want, so we carefully reviewed each spreadsheet intended for use with ChatGPT to ensure no personal information was included.
Search Queries
First Attempt
Our first strategy did not go well. We first tried using search queries customers had entered into our catalog. To obtain these, we used Google Analytics, which captures such queries as part of its tracking of URLs accessed by library catalog users.
In this round, we provided ChatGPT with a CSV file with the following headers:
SEARCHTERM | PAGE VIEWS
Many of these queries were composed of known titles, author names and many stop words. Also, we found that some of the queries included search parameter strings such as ‘nw:[0 TO 180]’ or ‘formatcode:(EBOOK ) lx:[0 TO 400]’.
At first, our work with ChatGPT went well as we attempted to clean up the data, normalizing empty values in our spreadsheet and having ChatGPT remove format codes and other parameters. In fact, ChatGPT was excellent at helping us clean the data.
We then asked it to begin analyzing the remediated data and identify some categories. As the following screenshot demonstrates, ChatGPT appeared to produce a useful taxonomy.
 Figure 4. Screenshot from ChatGPT that demonstrates ChatGPT appeared to produce a useful taxonomy.
Figure 4. Screenshot from ChatGPT that demonstrates ChatGPT appeared to produce a useful taxonomy.
However as we looked closer at the distribution of searches under each of the taxonomy terms, we discovered that the vast majority fell under “Other Themes and Genres”. We attempted to force ChatGPT to break the Other category into smaller chunks but this failed and we were left with a rather unhelpful, uncategorized data category representing 93.4% of all user searches.
After many attempts at fixing the ‘Other’ problem, we realized we had hit a dead end.
| Category | Associated Search Terms | Percent of Total |
|---|---|---|
| Other Themes and Genres | 2747 | 93.4 |
| Literature & Fiction | 81 | 2.75 |
| Literature & Fiction – Book Series/Authors | 25 | 0.8 |
| Education & Children’s Content | 49 | 1.7 |
| Travel & Geography | 27 | 0.9 |
| Business & Economics | 6 | 0.2 |
| Mixed Categories | No data | No data |
Regrouping
We spent some time re-strategizing our approach with ChatGPT.
Upon reviewing the data we were submitting to ChatGPT, we could see that there were many author names and known title searches. This seemed at least a partial explanation. Since ChatGPT is not connected to the internet, there is no way to have it cross-reference a data set like books in Amazon or the Library of Congress in order to identify suitable subjects for a given author or title. In fact, ChatGPT seemed to understand this.
 Figure 5. Screenshot from ChatGPT.
Figure 5. Screenshot from ChatGPT.
As you can see from the transcript above, ChatGPT was pretty good at understanding its limitations and suggesting a solution.
We considered its recommendations and then decided that an entirely different approach might work out better. Rather than using search queries, we would just upload circulation data associated with each title and its associated subject headings.
Circulation Data
Our circulation data was drawn from book titles only and was structured as follows:
TITLE | CIRCULATION | SUBJECT 1 | SUBJECT 2 | ETC...
Each title had multiple columns for subjects, with a few items having over 20 subjects describing them.
We reduced the size of the dataset substantially. In our previous work with ChatGPT, we had begun to suspect that our massive dataset was maxing out ChatGPT’s memory and this was impacting its ability to deliver quality analysis. With that in mind, we reduced our original circulation data of 40,000 titles to only those titles with 100 or more circulations each. This brought the total to 1,992 titles.
Since an LLM like ChatGPT is really good at summarizing content, we thought providing the explicit subject headings might make it easier for ChatGPT to define a taxonomy that was both robust and relevant to our customer’s interests. It appears that we were right.
Ahead of having ChatGPT generate taxonomy terms, we wanted to make sure it understood the structure of Library of Congress Subject Headings, such that subjects broken up with hyphens were shorthand for denoting hierarchy. We also explained that the circulation data was important and that it should weight decisions on our taxonomy based on the popularity of the book, that is its circulation numbers. In fact, it recommended separating the subjects into distinct terms where hyphens indicated hierarchy.
 Figure 6. Screenshot from ChatGPT showing it recommending separating subjects into distinct terms where hyphens indicated hierarchy.
Figure 6. Screenshot from ChatGPT showing it recommending separating subjects into distinct terms where hyphens indicated hierarchy.
We were ready for takeoff, but we paused to remind ChatGPT that we were aiming for a concise list of 40 or so taxonomy terms that should represent a ‘flat’ non-hierarchical taxonomy derived from the subject terms. It confirmed it understood and then proceeded to generate the 40 terms!
The 40 terms were very much the kinds of things you would expect. Terms like Fiction, Juvenile fiction, Folklore, Biography, California, Dogs, etc. However there were some unexpected terms including Bears, Technique and Behavior, etc.
Given this, we determined that we had probably achieved the best outcome possible, and that human intervention would be required to carry this over the finish line. Therefore, we decided to expand the list to 100 items to give our human staff a good set of terms to refine. Interestingly, ChatGPT had one final curveball for us, which was that it provided a list of 84 terms, not 100 as we had asked for. But who’s counting?
The humans did meet a few weeks later to finish where ChatGPT left off and we were able to generate our genre and topics taxonomies. One particularly helpful element to this manual labor was the vector map of topics we had asked ChatGPT to generate. It turns out that when confronted with strange terms, the vector map helped us understand where this term was coming from. For example, the term mice was not really associated with other animals, but was related to Christmas stories.
III. Discussion
Based on our experience we are exploring the long term feasibility and sustainability of developing a ChatGPT plugin that would make interfacing with ILS data much easier. As we saw in the taxonomy experiment, ChatGPT has some difficulty identifying or validating simple things like book titles or author names. The ability to combine this with other plugins could also open up many new workflows and possibilities. Whether we do this through an API, or Z39.950 interface, or good ‘ol web scraping, we don’t know yet, but the scope of the idea and possibility of allowing other libraries to also share these benefits seems like a win-win situation.
A universal ILS interface for ChatGPT sounds great at first, but you might already be thinking about the privacy implications of a setup like this. There would of course be numerous drawbacks for library patrons vs an online catalog, but what we are talking about is not a complete replacement, but instead a parallel system available for PACL power users in the same way interlibrary loan services are slower than shelf browsing. For some, the pros of that setup will outweigh the cons.
Before we jump into the new set of skills that we think will help you avoid many of the issues we encountered. It’s important to mention there are several new features in the world of generative AI that were unavailable earlier this year but will likely be available when this article is published:
- Multimodal support. Very soon it will be possible to quickly move between photos (including optical character recognition and translations) and other formats and modes within ChatGPT.
- Multi-agent chat interfaces. Imagine having multiple chatbots trained to do specific tasks, all working together within the same chat interface.
- Better memory management. In the future your AI assistant will be able to recall past conversations or have access to a custom “knowledgebase” of reference documents, training material, or local practices.
New Skills
While everyone awaits the seemingly inevitable leaps in LLM utility, we invite you to consider the following four skills which our experiences suggest library organizations should develop in their staff as we move further into the AI age.
Skill #1 – Maintaining Freshness
One of the disappointing but necessary limits of ChatGPT is that out of the box, it does not have a memory of past conversations. Imagine working with an assistant who has seemingly read every book in your library but has zero short term memory. In some ways this person is smarter than you in terms of recall, but they’re very sleepy. All the time. How can you quickly get them up to speed before the clock strikes midnight and they turn back into a pumpkin? Thankfully you’re a librarian and providing “just in time” information is not a new concept. Use that skill to your advantage. This became extra important during SEO experiment #2 when trial and error was a major factor. If you tell ChatGPT you’re working in MacOS, expect different results. It’s that easy.
Skill #2 – Prompt Engineering
Without getting into why this term is misleading and problematic (one could argue it just sounded cooler than alternative options like “LLM whisperer” or “query expert”) this is the one we’re stuck with for now. It’s also a skill that is most likely to shift the most, as AI systems continue to evolve and better deduce what you were actually trying to say. Prompt engineering is also largely dependent on the domain you’re working in, so for the purpose of this article let’s focus on the general concept of design thinking. One school of thought is that “one shot” prompting is the best option—try to build up your original prompt as much as possible to get instant results. This is extremely satisfying when you get it right, and is great for sharing results with other people (or bots) but could be compared to teaching someone only how to read but not write. For best results, you will probably need to use an iterative process over time to perfect your prompting skills. The best way to increase your prompting skills is to write lots of bad prompts and analyze those results. This is an iterative process, and you are part of that feedback loop.
Skill #3 – The “Reverse Reference” Interview
Put skill #1 and #2 together and what do you get? We’re calling this “reverse reference” because in many ways a ChatGPT conversation flips the script of a normal front desk interaction at a library. The difference is that this time, you’re both the patron and the librarian. In more practical terms, think about the extra context that might change the direction of the chatbot’s response, that in a normal reference interview happens towards the end of the conversation and try to build that into the front of the conversation. So for example, asking “what does this error message mean?” can create totally different results if you don’t first tell ChatGPT a little about what you were trying to do in the first place. Think about all those times you’ve talked to a patron who asked “where is the biography section?” without mentioning they have a homework assignment about a local author. Well guess what, there’s an entire local authors section at a different library branch! Do you see how that conversation could have gone smoother? You can anticipate those needs. Words have meanings! Be precise and prosper.
Skill #4 – Data remediation
Since most data is dirty, staff using ChatGPT will benefit from learning a few of the steps involved in data remediation. While we found GPT to be quite good at identifying some data cleanup needs on its own, it is incumbent on users to prep their data before handing it off to GPT to get better results. If you do use GPT to help you remediate your data, then be sure to start a fresh chat session to restore the tokens spent in the cleanup process. Either way, understanding how to remediate data is a good skill to have, especially when using data with AI.
We recommend considering the following data issues your remediation efforts should account for:
- Bias. Look out for cultural bias in the data that could lead ChatGPT toward biased outputs.
- Corruption. Consider the impacts on quality when data is handed off from person to person, or merged between different datasets. With each touchpoint, the chances of error increase so look over the data to ensure data integrity and consistency.
- Intent. Ensure the data you are using was intended for how you want to use it and that your assumptions about that data match the findings you hope to draw from it.
- Consistency. If you are working with long-term data, understand that standards that can change over time. Again, check for consistency.
- Controlled entries. Watch out for a lack of standardized data-entry practices or free text fields. And if you are dealing with free text entries, woe be to you.
Good News
All of the caveats aside, we found using ChatGPT to be a major enabler for our team. With great ease, we could leverage expertise and skills that our team is not strong in, realizing previously unheard-of efficiencies in our work. Moreover, using ChatGPT, we were able to tackle problems that previously were beyond our ability to solve.
Essentially, we found a new super-star member in our team that could pivot between data analyst or debugger with ease. In our taxonomy project, our GPT data analyst was able to carry out critical and time-consuming tasks that would normally take hours or even days. And it did so in seconds. And when it came to checking our code, GPT offered us what felt like having a senior Python engineer on hand to guide us. Importantly, this would be a role our library would never be able to afford, so it was a game-changer in that respect.
All of this meant that barriers to entry were lowered significantly. Projects that would have been impossible suddenly looked possible. To take the taxonomy project as an example, we never would have put the time into analyzing thousands of rows of circulation data. In a team of two with far-flung responsibilities in our library, we would have scoffed at the suggestion, as we scurried off to put out fires with online resources or web content. But with ChatGPT, we needed only to dedicate a few hours of time. In fact, having gone through this exercise, we could probably do similar projects in minutes next time.
And then there is the wonder of solving highly technical problems with what feels like a very patient guru who you can confide in using plain English. In a technical sense, this is the best human computer-interaction interface imaginable. In our mind, this is the truly killer app of the technology and something we continue to be awed by. Whether it’s asking it in natural language to break down an unfamiliar area of knowledge or grappling with complicated technical issues, ChatGPT provides your team with a mentor who is patient, non-judgmental and seemingly very interested in having you succeed. As managers, we see this as especially important for removing obstacles for non-technical staff as they solve problems in their work.
IV. Conclusion
Based on our experience, we feel that library organizations need to begin developing AI skills in their staff and begin widespread application of this power into their work. However, as with the introduction of any new technology or process, the principles of change management should be applied to help staff adapt their mental models to this new paradigm. Indeed, this particular technology is so groundbreaking, and therefore disruptive, that we highly encourage managers to refresh their understanding of moving staff through the change process. You can ask ChatGPT for such a refresher or go and read the seminal work of Leon Festinger [7] on cognitive dissonance and review David Kolb’s [8] findings on adult learning. The bottom-line is that you can spare your organization lost time due to change resistance if you manage the introduction of AI into the workplace appropriately.
As part of this onboarding into AI, there should be careful attention paid to training staff on the important limitations of ChatGPT.
Hallucinations are a real issue in the world of ChatGPT. This was most encountered during the taxonomy experiment when our initial approach simply overloaded GPT by uploading far too many search terms at once, but can also be felt when any individual chat sessions went on for too long. In 2023, one needs to recognize when an LLM is not performing well, like the last sputtering of a car running out of gas.
Cost is also a factor to consider. Our experiments relied on an individual ChatGPT pro license which costs $20 per month, but the estimated cost for an enterprise solution at our library would be well over $30,000 a year! This is a hefty price to pay without more reliable outputs that could balance these costs with efficiency gains.
In sum, facts need to be scrutinized, findings analyzed, hallucinations identified and dealt with. And as we have noted previously, there are new skills one must gain to use the tool effectively.
The productivity gains are unprecedented and our experience interviewing staff who have tried GPT is that they also appreciate its potential. Even for a small library system like ours, we can see how a variety of work groups could be positively impacted by incorporating GPT into strategic areas of their jobs.
That said, as our experiments have also shown, there is still work to be done to improve and fine-tune ChatGPT for libraries. In particular, the hallucinations and untrustworthiness of its outputs greatly limits its use by novice users. And while it understands the library domain such as the structure of MARC and even the purpose of libraries, its outputs could benefit from greater access and possibly more training on library data.
We encourage libraries and particularly technically savvy library staff to begin introducing ChatGPT into their workplaces, their projects and processes as long as there is clear understanding of the issues we have outlined above. We believe now is the best time to do so, in fact. LLMs present a radical reordering of the information landscape and as information professionals, we must keep up with this rapidly changing technology. There is no better way to develop this understanding than to experiment with it here and now, developing an intimate knowledge of its shortcomings but also its potential to overhaul how libraries do their business.
References
[1] Edwards B. 2023 Sep 26. Can you melt eggs? Quora’s AI says “yes,” and Google is sharing the result. Ars Technica. https://arstechnica.com/information-technology/2023/09/can-you-melt-eggs-quoras-ai-says-yes-and-google-is-sharing-the-result/.
[2] Hays K. AI booster Paul Graham complains of rise in web content that’s “AI generated SEO bait.” Business Insider. [accessed 2023 Nov 2]. https://www.businessinsider.com/paul-graham-complains-web-content-ai-generated-seo-bait-2023-9.
[3] Building A Sitemap For A Site. 2020 Aug 9. Learn WordPress. [accessed 2023 Nov 2]. https://learn.wordpress.org/lesson-plan/building-a-sitemap-for-a-site/.
[4] ChatGPT. ChatGPT. [accessed 2023 Nov 2]. https://chat.openai.com/share/b4c46ecd-ca1f-44ec-8d25-8f04c25a6ae9.
[5] BiblioCommons. 2022. 2022 Year in Review. https://www.bibliocommons.com/news/2022-year-in-review.
[6] OpenAI. 2023. Privacy policy. openaicom. https://openai.com/policies/privacy-policy.
[7] Festinger L. 1957. A theory of cognitive dissonance. Stanford: Stanford University Press.
[8] Kolb DA, Lewis LH. 1986. Facilitating experiential learning: Observations and reflections. New Directions for Adult and Continuing Education. 1986(30):99–107. doi:https://doi.org/10.1002/ace.36719863012.
About the Authors
M Ryan Hess is Digital Initiatives Manager at Palo Alto City Library, delivering award-winning library experiences around technology and also a Lecturer at San Jose State University’s iSchool. Ryan speaks internationally on topics of digital literacy, web3 and blockchain, artificial intelligence and was the founder of Bay Area Library UX. Prior to coming to Palo Alto, he was the Digital Services Coordinator at DePaul University Library and a former market researcher at Adobe Systems. ryan.hess@cityofpaloalto.org
Chris Markman is the Digital Services Program Coordinator at Palo Alto City Library, where he oversees library technology services and IT systems. He previously served as Senior Librarian at Mitchell Park, publishing and presenting extensively on topics like information security, VR/AR, digital literacy, and the future of libraries. He holds an MS in Information Technology from Clark University and an MLIS from Simmons College. chris.markman@cityofpaloalto.org
Appendix 1: How to Prepare Your Library for the AI Future
Gartner’s hype cycle contends that technologies move up a steep curve of hype as they impress us with their novelty, only to peak soon after and collapse into the trough of disillusionment. However, long-lasting technologies, Gartner contends, eventually rise back as their utility works its way into business processes.
In 2023, we viewed library use cases of ChatGPT as falling into the trough of disillusionment. But we also see where it will eventually go and this makes us excited.
In the meantime, what should libraries do? Begin introducing ChatGPT to staff, teaching them about it and discovering its power together. For us, the easy applications in this process of introducing ChatGPT in libraries would include the following ‘safe’ use-cases.
- Drafting writing of any kind from emails, blogs, web content and even introductions to journal articles (ha ha) are great ways to save time and generate content more productively.
- Get staff involved in any kind of data manipulation possible. Use ChatGPT to both clean up data and summarize large datasets. While users must be cautious with this use-case, as we learned, using GPT with care and a critical mind can allow individuals to quickly save time and know more about library data than ever before.
- Using GPT as a learning tool. For staff that coordinate training for others, it can quickly create lesson plans and course outlines for you. For staff that need to learn a new skill, you now have a Jedi Master waiting to show you The Force.
- On the IT side, you now have a senior code engineer who can guide library staff from novice to genius when it comes to writing, debugging and learning code. Combine this with the training guides and online learning courses that are already part of your library’s collection.
- At the reference desk, LLMs can be a quick first pass for staff to consult before applying their own knowledge to a question, particularly in areas they are less familiar with. However, like with data analysis, because of hallucinations, bias and other issues with the current generation of AI, we recommend this always be used with care.
Note: Article edited on 2023 December 5 to add the Appendix.

Subscribe to comments: For this article | For all articles
Leave a Reply