by Sarah Jones, Cory Lampert, Emily Lapworth, and Seth Shaw
Introduction
This article is a case study describing the implementation of Islandora 2 [1] to create the University of Nevada, Las Vegas Special Collections and Archives Portal, a digital asset management system (DAMS) that provides a unified public interface for the discovery, access, and use of archives and special collections materials. Founded in 1957, the University of Las Vegas, Nevada (UNLV) is a public land-grant university, and UNLV Special Collections and Archives (SCA) is a division within the UNLV University Libraries. SCA documents University history, as well as the history, culture, and environment of Las Vegas, the Southern Nevada region, and the global gaming industry. As of 2023, SCA is composed of four units: Digital Collections, Public Services, Technical Services, and the Oral History Research Center. Prior to the public launch of the SCA Portal in 2021, users accessed SCA material through three separate access points: the UNLV Libraries catalog (monographs, maps, periodicals), an online database of archival collections (manuscripts, photographs, oral histories, and university archives), and Digital Collections websites (digitized collection material and digital exhibits).
Technical Services (TS) processes and manages all of SCA’s archival holdings, physical and digital. ArchivesSpace is the primary collection management tool, and is used to create finding aids for oral history interviews, and manuscript, photograph, and university archives collections. These finding aids are available for browsing and downloading via the SCA Portal. Digital Collections (DC) digitizes and provides online access to select materials via the SCA Portal, including archival photographs, manuscript materials, newspapers, oral history interview transcripts, and born-digital records. These two units have developed a deep collaboration that came about through selecting, implementing, and using this Islandora-based joint digital asset management system that brings several TS and DC workflows together in a centralized repository. These two SCA departments work closely with two departments in the Library Technologies division in order to maintain our local installations of Islandora and ArchivesSpace.
The Library Technologies division of UNLV Libraries includes the Web and Application Development Services (WADS) department and the Library Systems department. WADS is responsible for application development, front-end web development/design, and user experience. This department includes the lead developer responsible for Islandora and ArchivesSpace. The Systems department is responsible for back-end server maintenance and administration as well as backup and storage workflows and Amazon Web Services (AWS) administration.
Choosing Islandora
UNLV Libraries began digitizing materials on a small scale in the web department, with a larger and more coordinated effort beginning in 2006. Over the years, the digitization program grew through grant funding, outsourcing of collection digitization with vendor partners, and with the creation of a department (DC) dedicated to the reformatting of materials in a digitization lab, creation of digital object metadata, and management of a digital asset management system. The first system in use was the OCLC-created CONTENTdm system which provided for ingest of images and associated metadata, public display of the objects in templates, and tools for metadata creation and controlled vocabulary management. In 2014, UNLV began to focus on large-scale digitization and linked data and began to face issues with workflows, system scalability, and the absence of integrated digital preservation solutions.
UNLV Libraries leadership team charged a digital asset management system (DAMS) task force in 2014 to “provide recommendations on the best technology solutions to support the acquisition, preservation, and management of born digital archival content and the continued development and delivery of robust, unique library digital collections.” At the time, UNLV Libraries was using a locally hosted implementation of CONTENTdm to provide access to digitized items from UNLV Special Collections and Archives (SCA) – mainly images, but also PDF documents, audio clips, and video files. In 2014, SCA implemented ArchivesSpace for archival collection management and finding aid creation. At this time, researchers were faced with navigating three different websites and four different search boxes in order to find and access UNLV SCA materials, so a more unified user interface was one of SCA’s goals.
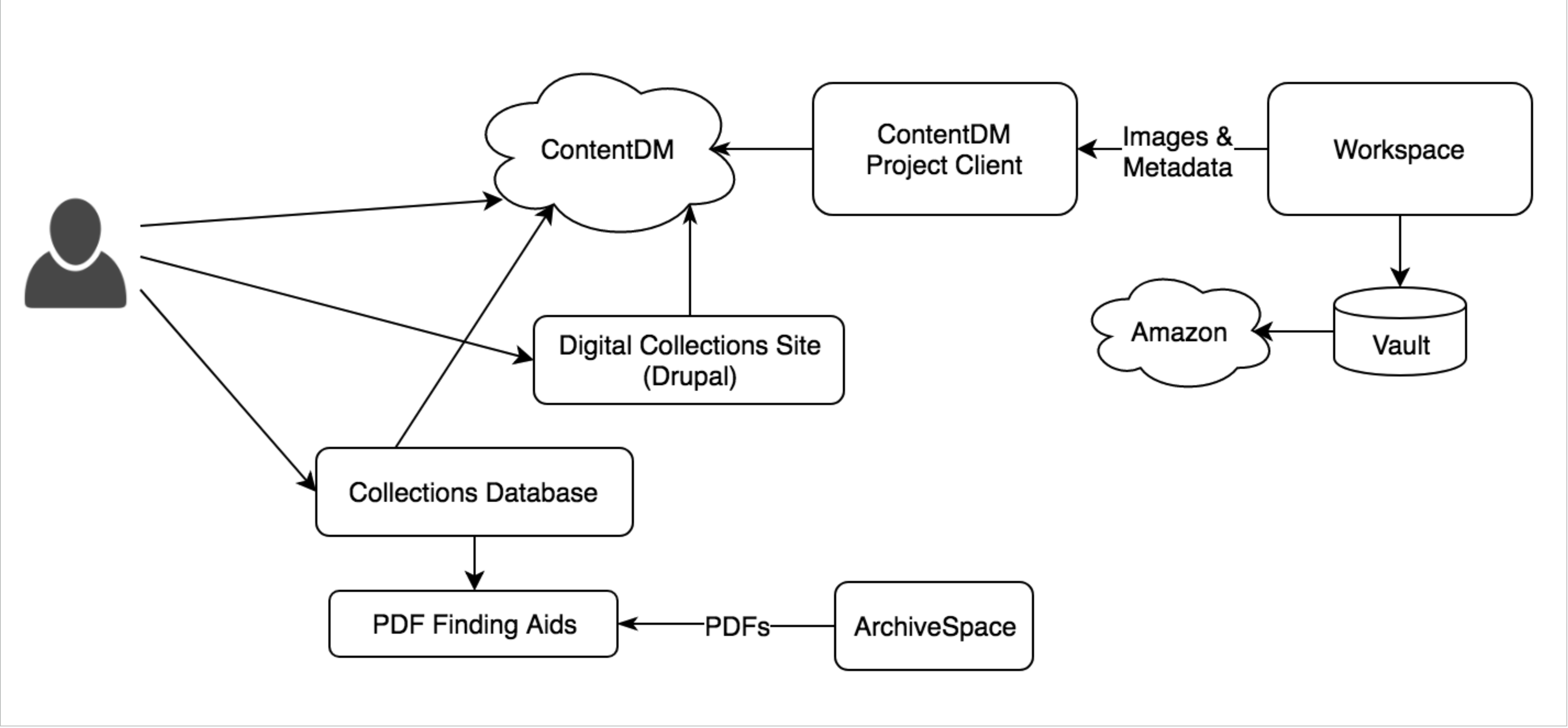 Figure 1. Digital collections and archival description system diagram pre-Islandora. The three SCA websites users encountered were: CONTENTdm (d.library.unlv.edu), the Digital Collections Drupal-based exhibits site (digital.library.unlv.edu), and the main UNLV Libraries website (library.unlv.edu). The four different search boxes that could be used to find SCA materials queried the UNLV Libraries catalog, a database of collection-level descriptions, the full text of collection finding aids, and CONTENTdm. Digital Collections used local networked server locations (Workspace and read-only Vault) to store master copies of files, which were also backed up using Amazon Web Services.
Figure 1. Digital collections and archival description system diagram pre-Islandora. The three SCA websites users encountered were: CONTENTdm (d.library.unlv.edu), the Digital Collections Drupal-based exhibits site (digital.library.unlv.edu), and the main UNLV Libraries website (library.unlv.edu). The four different search boxes that could be used to find SCA materials queried the UNLV Libraries catalog, a database of collection-level descriptions, the full text of collection finding aids, and CONTENTdm. Digital Collections used local networked server locations (Workspace and read-only Vault) to store master copies of files, which were also backed up using Amazon Web Services.
SCA was also focused on improving its stewardship of born-digital archives, therefore improving UNLV Libraries’ digital preservation practices was another important goal. The DAMS task force priorities led to adjacent work that resulted in the creation of a formal Digital Preservation Policy in 2017. In summary, the task force was looking for a DAMS that would meet all three of its main goals:
- replace CONTENTdm’s flat file data structure with a linked data model that could provide public access to digital objects and other structured data
- provide a unified search interface for digital objects, archival description (finding aids), and agent records (people and organizations connected to our collections)
- Provide functionality for born-digital archives and digital preservation
In 2015, the DAMS task force tested two hosted solutions, Preservica and Archives Direct (a service combining DuraCloud and Archivematica). While these options offered robust digital preservation and born-digital processing capabilities, they fell far short of matching the user interface and metadata management capabilities that CONTENTdm provided, which SCA did not want to lose. At the time of testing these options also did not seem to scale well in handling the large amount of digital material that SCA needed to ingest and manage. The vendor costs of hosting a large (and growing) amount of data was another concern.
In 2017, a dedicated application developer was hired to focus on SCA technology, which allowed the task force to more seriously explore open source systems. Four different potential directions for development were identified:
- A Samvera repository next to an ArchivesSpace public user interface unified by common theming, linking, and a common search interface
- An Islandora repository similarly integrated with ArchivesSpace as described above
- A full Drupal Integration using Islandora and pulling in ArchivesSpace data via the API
- An in-house built interface harvesting from both Fedora and ArchivesSpace APIs.
The decision was based on the DAMS task force’s answers to three questions:
- Should the interfaces be tightly OR loosely coupled?
- Should we focus development on an in-house solution OR contributing to and benefiting from a community-based solution?
- How important was leveraging existing technical expertise (PHP+Drupal) OR were we willing to adopt new ones (Ruby)?
The task force members choose a tightly integrated interface (instead of linking between distinct systems), a community-based project, and leveraging the developers’ existing PHP and Drupal experiences. Islandora is an open-source eco-system for the display and management of digital cultural heritage materials, with an active community of supporters and users, with Drupal as its primary interface.
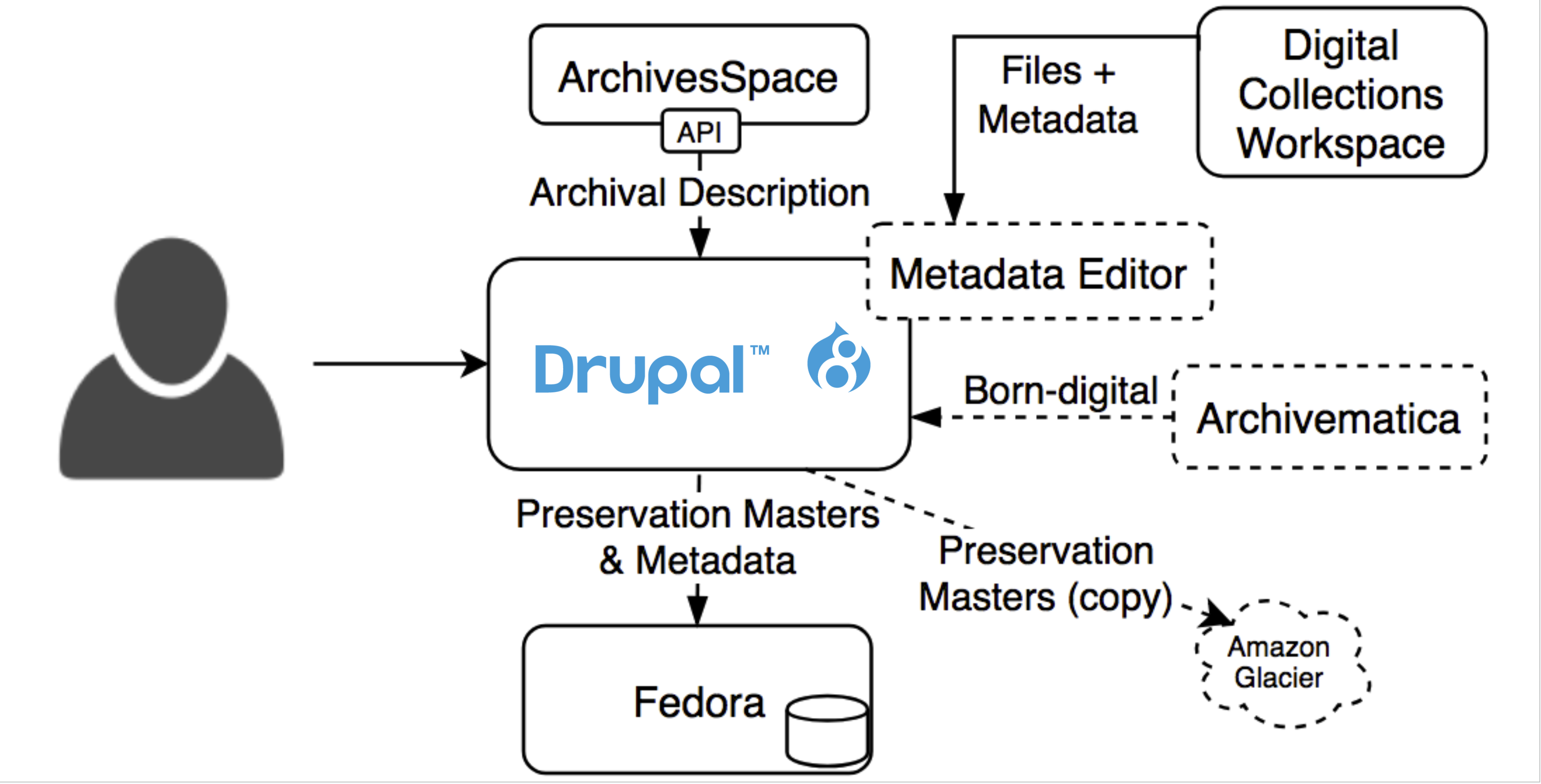 Figure 2. Planned architecture where Drupal now serves as the unified interface for Special Collections web content. Dashed lines indicate planned future projects. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CAN, 2022.
Figure 2. Planned architecture where Drupal now serves as the unified interface for Special Collections web content. Dashed lines indicate planned future projects. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CAN, 2022.
According to the product website, “Islandora is an extensible, modular, open source digital repository ecosystem focused on collaborative authorship, management, display, and preservation of digital content at scale. Islandora adheres to widely adopted best practices and open standards and frameworks used in information practice.” The product is augmented by community-developed modules that add functionality and are shared back into the community. Islandora users are supported by the Islandora Foundation, which acts as a governance structure setting priorities, and building consensus on issues of architecture and feature development.
When UNLV made this decision in 2017, the Islandora community was working on a major change from Islandora 7 to the next version (confusingly) Islandora 2.0, which was then code-named Islandora CLAW. [1] Islandora 7 was based on Drupal 7 and Fedora 3, both of which were rapidly approaching the end of their official support windows, and which used drastically different internal structures than their new versions requiring an updated conceptualization of how Islandora works and a complete rewrite of the software. In light of these circumstances, UNLV Libraries decided to help the Islandora CLAW project complete the new version rather than initially invest in Islandora 7, only to migrate away shortly thereafter. The drastic change in architecture is one of the reasons the new version was named Islandora 2 or modern Islandora.
UNLV’s contract with OCLC to host CONTENTdm had an annual renewal date, which worked as a convenient deadline for development. Based on the answers to the three guiding questions above, and with insight from the development community’s timelines on product releases, UNLV made the decision to select Islandora and aim for a launch timed with the end of the OCLC contract. This signaled a new phase of work implementing Islandora, followed by migration of all UNLV special collections data into the new system.
Implementing Islandora
Implementing this new architecture consisted of five major tasks: getting Islandora CLAW to an initial release, integrating the new Islandora into our existing Drupal-based online exhibits site, the ArchivesSpace integration, designing the user interface, and migrating existing and new collections. Much of this work was done in parallel with changes in one aspect impacting the others.
Getting an Initial Islandora CLAW Release
UNLV began working with CLAW in December of 2017. Initial work focused on the community’s deployment tooling so we would have a stable development platform for both contributing code back to the community and testing our local code. As commonly happens with pre-release software, there were multiple large design shifts that occurred over the course of 2018 which changed how derivatives and indexing actions are triggered (January) [2], inverting the relational direction of metadata records and their associated files (June) [3], and how binary files flow between Drupal and Fedora (August) [4].
The community continued active development of new features and remediating bugs as they were discovered. Then, in early 2019 the Islandora community performed a series of targeted two-week efforts, called sprints, to document and test the new system before making its initial public release in June 2019 [5]. While this was a significant milestone, developers continued to add new features and fix bugs that were discovered as we continued building our new repository site and the number of other institutions using it increased.
Integrating Islandora with the Existing Exhibits Site
UNLV Digital Collections had an existing Drupal-based exhibits site where content specialists could describe the digitized content and give historical context. This site included a locally developed integration with a self-hosted CONTENTdm instance, which is now unavailable due to CONTENTdm’s discontinued option to locally host instances. These interfaces were popular with researchers and users beginning their search process and the team asked the developer to investigate methods to preserve the user experience from the former repository using the new Drupal structures leveraged by the Islandora community. Integrating digital objects directly into the existing Drupal exhibits site allowed us to bring these components together again.
Unfortunately, automated Islandora deployments provided by the community assume a brand new Drupal instance which prevents us from using them as part of our workflows [6]. These automated deployments were useful to the community because Islandora adopted a microservices approach to indexing and derivatives which meant there were several distinct applications that needed to be installed and properly configured to work together [7]. Eventually the developer resorted to manually installing and updating the necessary components.
Theming proved to be another challenge for integrating with the existing site as several structure and styling decisions had been made with the existing content in mind which did not display well with the new data structures and content. The design and styling of the new digital object, agent, subject, and search pages went through several iterations with the stakeholders to find an acceptable solution (see the “Designing the user interface” section below).
ArchivesSpace Integration
When we began looking at integrating ArchivesSpace with our new Islandora repository, we discovered there was an existing Drupal 7 integration in use by the American Academy in Rome [8]]. We reached out to the developer and began an early collaboration to re-implement an integration for Drupal 8+ [9]. The new integration would need to first define the content models in Drupal to receive the ArchivesSpace data, establish the synchronization mechanism, and establish basic data views [10].
While most ArchivesSpace fields are relatively simple text fields, some were more complex than the field types provided by Drupal: dates, extents, and physical instances [11]. For example, the Drupal provided date fields presumed ISO dates, however ArchivesSpace dates included properties for certainty, types (e.g. bulk or inclusive), calendar, and a string-based expression.
ArchivesSpace also included a concept of relationship types, where an agent can be linked to a record using a list of possible relationships. Replicating this in Drupal natively would require creating a separate field for every relationship type, which seemed untenable. We decided to create a new field type to support this type of linked agent field. It was added to a separate Drupal module, Controlled Access Terms, as it seemed like it might be useful to the broader Islandora community outside of the ArchivesSpace module [12]. The Controlled Access Terms module also included a new Drupal field type and associated plugins for representing dates using the Library of Congress proposed extension to ISO 8601, Extended Date Time Format (EDTF) [13] which we used for digital object dates instead of the ArchivesSpace-specific date field type. Controlled Access Terms was later transferred to the Islandora Foundation’s official Github organization for community management.
Early on we decided to leverage Drupal’s new Migrate API which was intended for ingesting and updating content and provided a plugin framework for extension. We expected this would limit technical debt by leveraging existing APIs rather than coding the migration code wholly from scratch. Two critical pieces we needed were an authentication mechanism to login and maintain a session with ArchivesSpace and a Migrate API “source” plugin which could use the session to iterate over the ArchivesSpace API endpoints and expose the API fields Drupal would pull from. Further, because of the more complex nature of the ArchivesSpace data model, we needed additional plugins to assist in transforming the source data into structures Drupal could use to populate its own records. The final step of this process was to create some default migration configurations which would map the ArchivesSpace data to the target models. These consist of several configuration files which can be adapted by local site implementers.
Finally, after modeling the data and using the Drupal Migrate API, we also set up some default data views. Drupal has a powerful query and display builder called Views. These allow us to select which data related to the current item in question should be displayed and how. This allows the site builders a great deal of flexibility in deciding how to display their data. For example, when a user views a Drupal page corresponding to an ArchivesSpace resource record a view can display all the child archival objects with whichever fields are desired and provide links to archival objects’ pages.
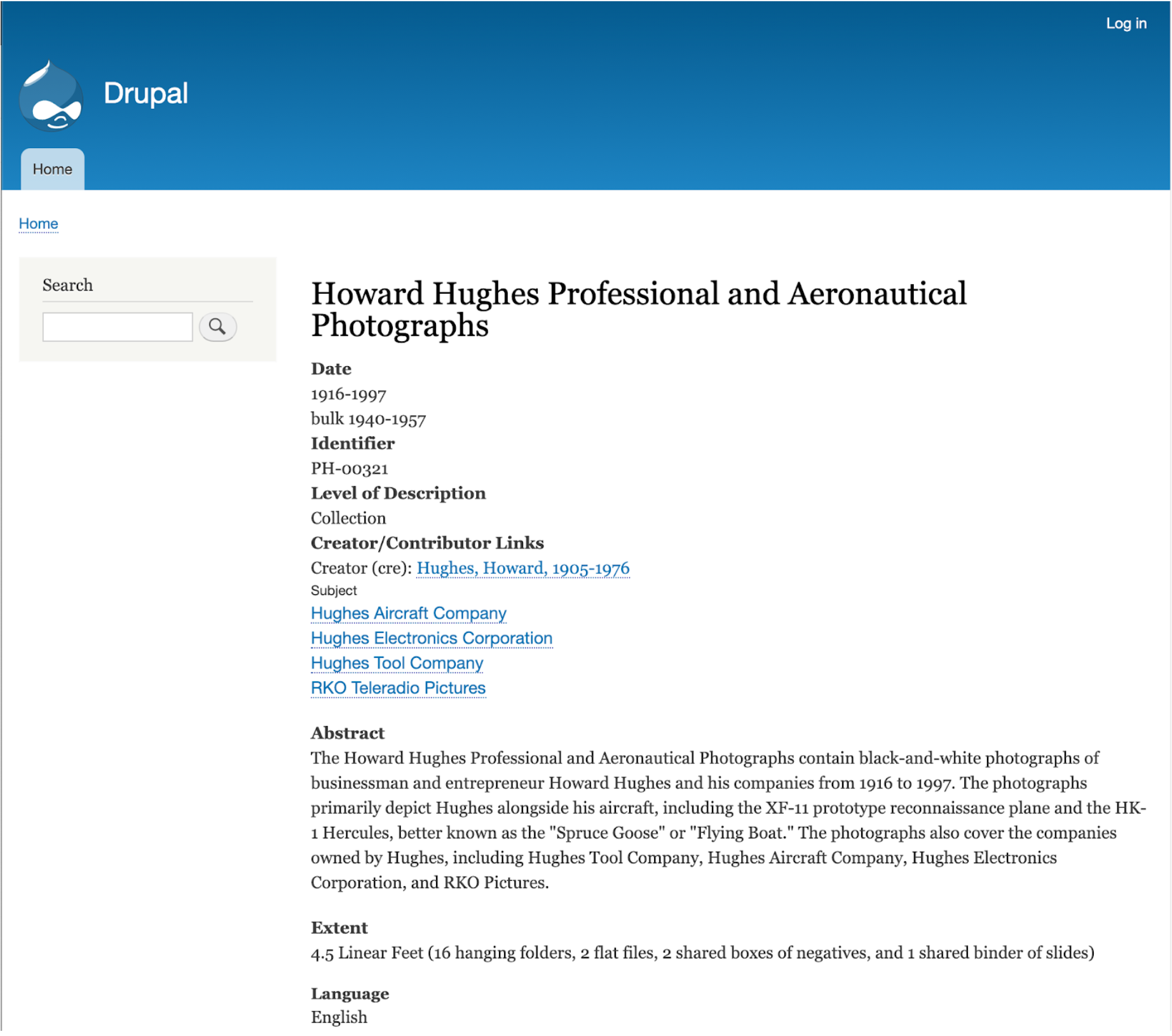 Figure 3. Screenshot of an ArchivesSpace resource record after being loaded into Drupal
Figure 3. Screenshot of an ArchivesSpace resource record after being loaded into Drupal
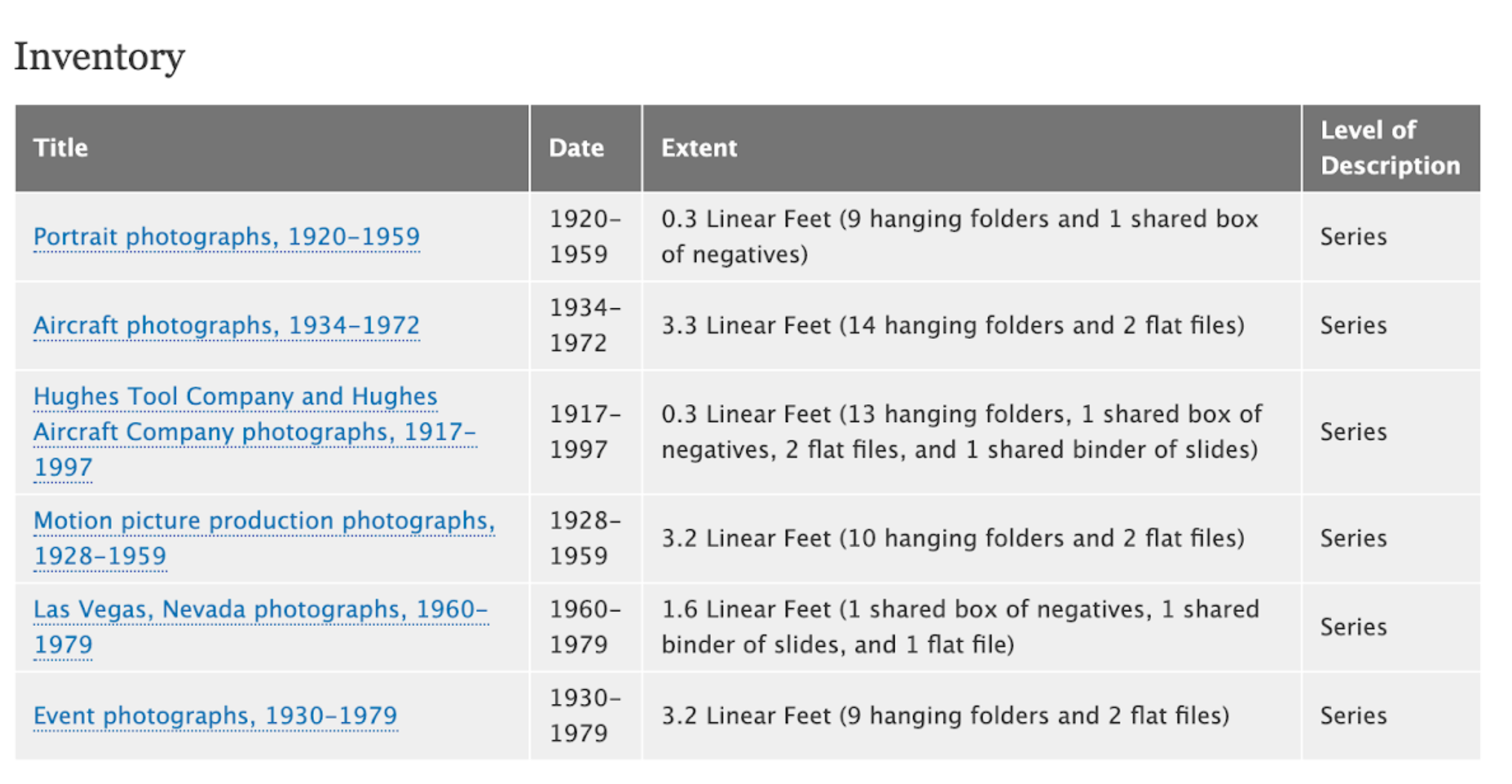 Figure 4. A view of a collection’s series powered by a Drupal view.
Figure 4. A view of a collection’s series powered by a Drupal view.
Once we were able to load our ArchivesSpace data into a Drupal site we then considered how best to link archival objects with their digital representations. ArchivesSpace can create digital object records, but does not have tooling around loading and transferring the files themselves. We decided that the simplest workflow would be to load new digital objects directly into the new Islandora and maintain the links to archival objects in Islandora instead of creating ArchivesSpace digital object records. All we needed was to include the archival object reference ID in our loading spreadsheets and have Drupal perform a lookup on that field to create the link. Once again, the Drupal Views functionality allowed us to control how we wanted related items to appear on each item’s page with a great deal of flexibility and control.
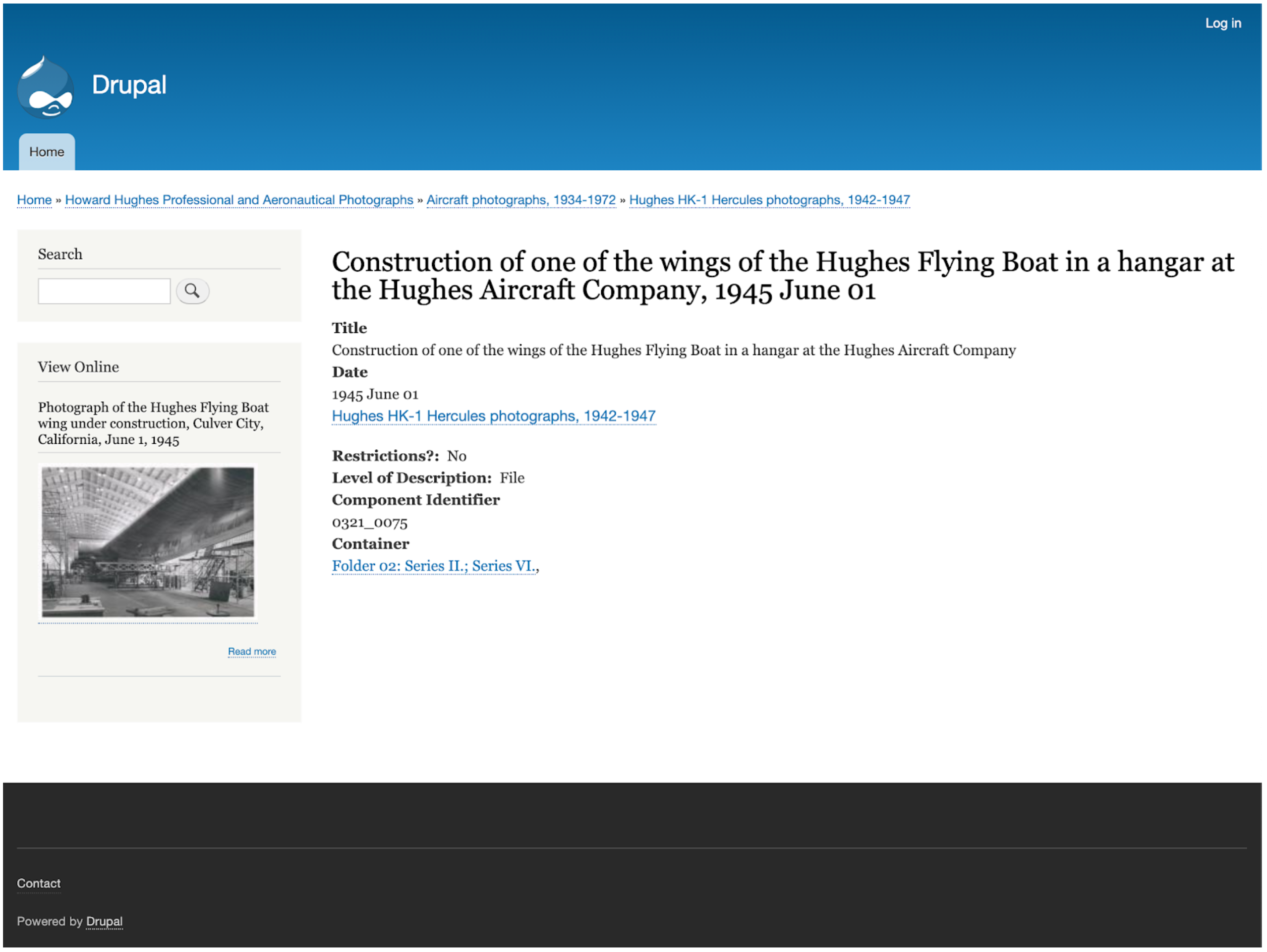 Figure 5. Screenshot of an archival object record with a thumbnail of the digital object record in a sidebar.
Figure 5. Screenshot of an archival object record with a thumbnail of the digital object record in a sidebar.
Content Migration
Once our local instance of Islandora was stable, the Digital Collections department worked with the Application Developer to migrate the digital objects in CONTENTdm. The metadata was exported from CONTENTdm and remediated by the Metadata Librarian to conform to a new, consistent application profile. Since only access copies of digital images and other files were stored in CONTENTdm, the Digital Collections Librarian created spreadsheets to match the metadata with the master files that were saved on local file servers. The metadata and file spreadsheets were sent to the developer, who used the migrate_islandora_csv module combined with custom code to ingest the content onto the development server for testing [14]. After any issues were resolved, the content was ingested onto the production servers.
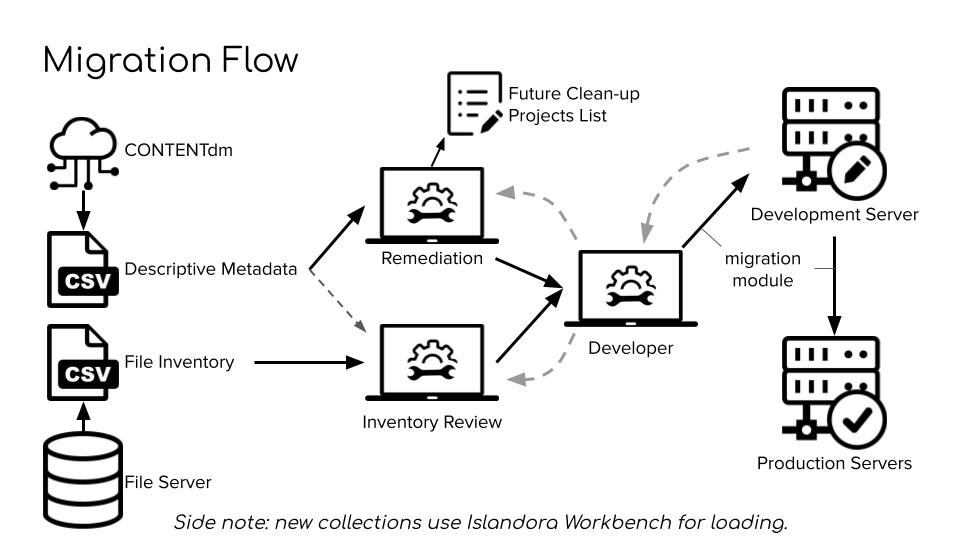 Figure 6. Migration from CONTENTdm to Islandora. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CA, 2022.
Figure 6. Migration from CONTENTdm to Islandora. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CA, 2022.
Each digital collection in CONTENTdm had its own set of metadata fields; for example, there was a field for “cuisine” in the Menus digital collection. In Islandora, all digital objects would have the same metadata fields, so the Metadata Librarian had to review all of the existing metadata in CONTENTdm and create a new unified metadata application profile, then remediate the metadata from each CONTENTdm collection to conform to the new profile. He also converted geospatial, genre, subject, and agent terms to URIs.
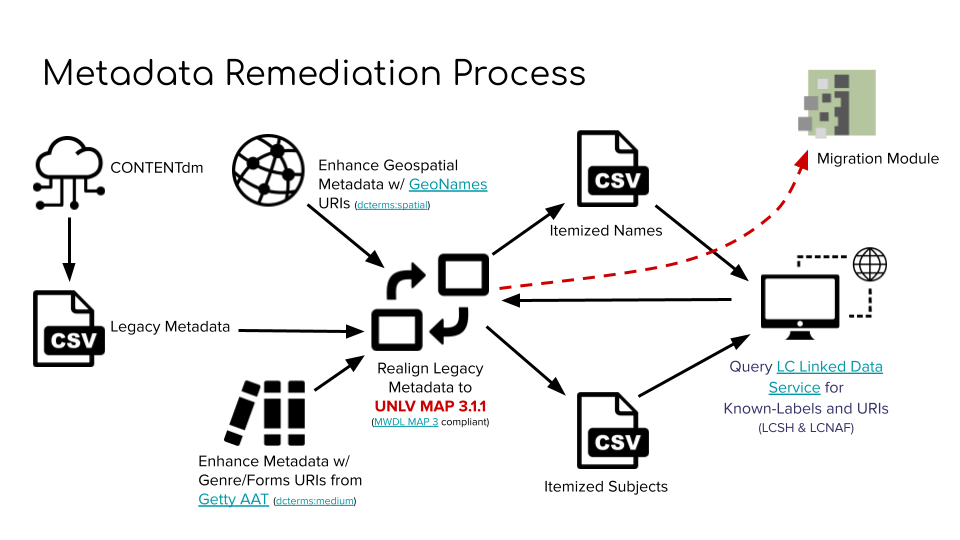 Figure 7. Digital object metadata remediation process. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CA, 2022.
Figure 7. Digital object metadata remediation process. Source: Seth Shaw, “Islandora @ the University of Nevada, Las Vegas“, IslandoraCon, Prince Edward Island, CA, 2022.
With the intention that born-digital items would eventually also be added to the Portal, and that digital preservation functionality would be built out, SCA added several new metadata fields for digital objects, and also at the file/media level. The “Digital Provenance” field uses a controlled set of statement to distinguish between different types of digital objects, including:
- “Original archival records created digitally” (born-digital archives)
- “Digitized materials: physical originals can be viewed in Special Collections and Archives reading room”
- “Digitized materials: physical originals are not available for viewing because of fragility or obsolescence” (such as digital video files created from VHS tapes)
- “Digitized materials: physical originals are not held by UNLV Special Collections and Archives” (“scan-and-return” items, i.e. digital surrogates are part of UNLV’s collections but physical originals were retained by the donor)
A “Digital Processing Note” field uses another controlled set of statements to document if the digital surrogate was edited or redacted, and if it was transcribed manually or using OCR. At the file level, Portland Common Data Model use extension URIs are used to identify the different types/versions of files, such as original, service, thumbnail, etc. SCA created a matrix that cross-references the use extension with the information in the digital provenance and digital processing note fields to assign different preservation levels at the file level, for example:
- Original born-digital files are “High Priority”
- “Priority” is assigned to the original files of digital surrogates where the original physical item is the ultimate “preservation copy”
- “Low Priority” is assigned to automatically generated derivatives like thumbnails
SCA also decided to assign Archival Resource Keys (ARKs) to all digital objects to be used as persistent identifiers and URLs. At first, ARKs were not assigned to the children of complex/compound digital objects, they were only assigned to the parent object. However, child digital objects are their own Drupal nodes and show up independently in the search results, so SCA decided to also assign ARKs to these child objects for consistency. UNLV uses California Digital Library’s EZID service to create and manage ARKs. The developer wrote a script to assign ARKs to digital objects and update information in EZID in bulk. Later on the developer further automated ARK creation by using Drupal insert “hooks” to trigger ARK minting on item ingest.
Designing the User Interface
One of the key successes of this project was the centralization of search across a wide variety of content types with one search box. With so many different types of content in UNLV’s Islandora site (digital exhibit pages, archival description, agent records, and digital objects), the team spent over a year discussing the best way to display everything to users. Stakeholders from SCA, including public services and curatorial staff, worked with WADS to create personas, inventory all content, do card sorting exercises, create mockups, conduct internal testing, and gather feedback from internal stakeholders. The personas SCA developed for users included an amateur historian, PhD candidate, undergraduate student, filmmaker, media relations consultant, art historian, and video game designer. Two SCA librarians also conducted in depth interviews with nine different types of users of UNLV’s digital collections, which also helped to inform the UI design. The team aimed to make the user interface (UI) and labels intuitive enough for first time users, but also wanted to include features and information that would be useful to expert researchers.
There is one main search bar for the site, and a set of filters to refine search results. The filter at the top of the sidebar allows users to refine by content type:
- Digital objects: digital files and their metadata.
- Archival collections: collection-level descriptions
- Archival components: descriptions of series, sub-series, files, and items within archival collections
- People: descriptions of people who are creators, contributors, or subjects of archival collections or digital objects
- Organizations: descriptions of organizations that are creators, contributors, or subjects of archival collections or digital objects
- Families: descriptions of families that are creators, contributors, or subjects of archival collections or digital objects
- Subjects: subject terms related to archival collections or digital objects
- Geographic locations: location terms related to archival collections or digital objects
- Webpages: webpages of digital exhibits
- Blog entries: blog entries related to digital exhibits
Each individual instance of each content type is its own webpage; with over 740,000 individual pages indexed, the team created a total of eleven different filters to help users refine their search results. The team also deliberated carefully over which metadata fields and thumbnails to display in the search results for each different content type.
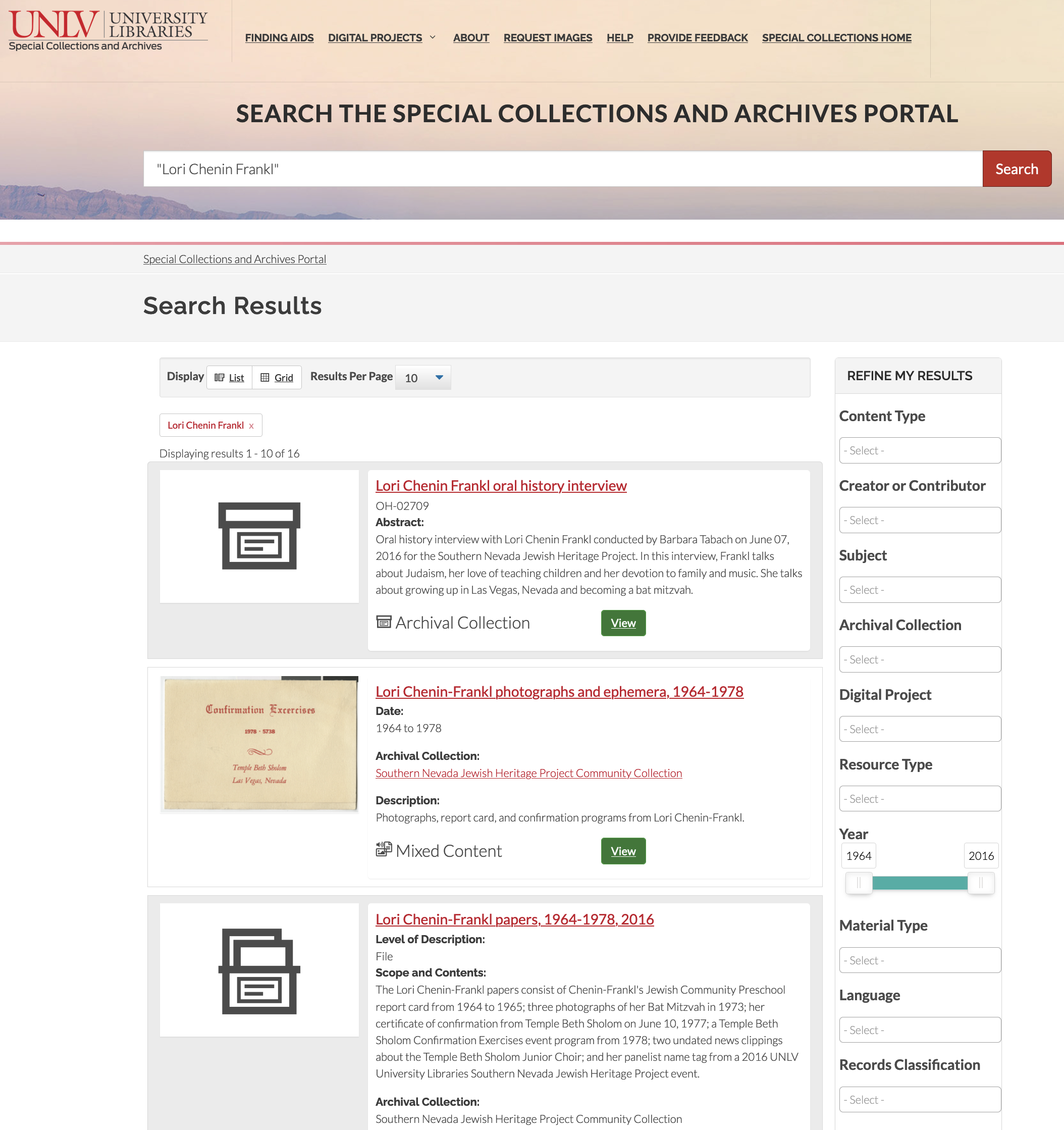 Figure 8. Search results page.
Figure 8. Search results page.
The team designed a webpage template for each content type. Archival collection pages show collection-level description, a search box to search all the digital objects and archival components within that specific collection, and an inventory of the archival components that are in the topmost level of the archival hierarchy.
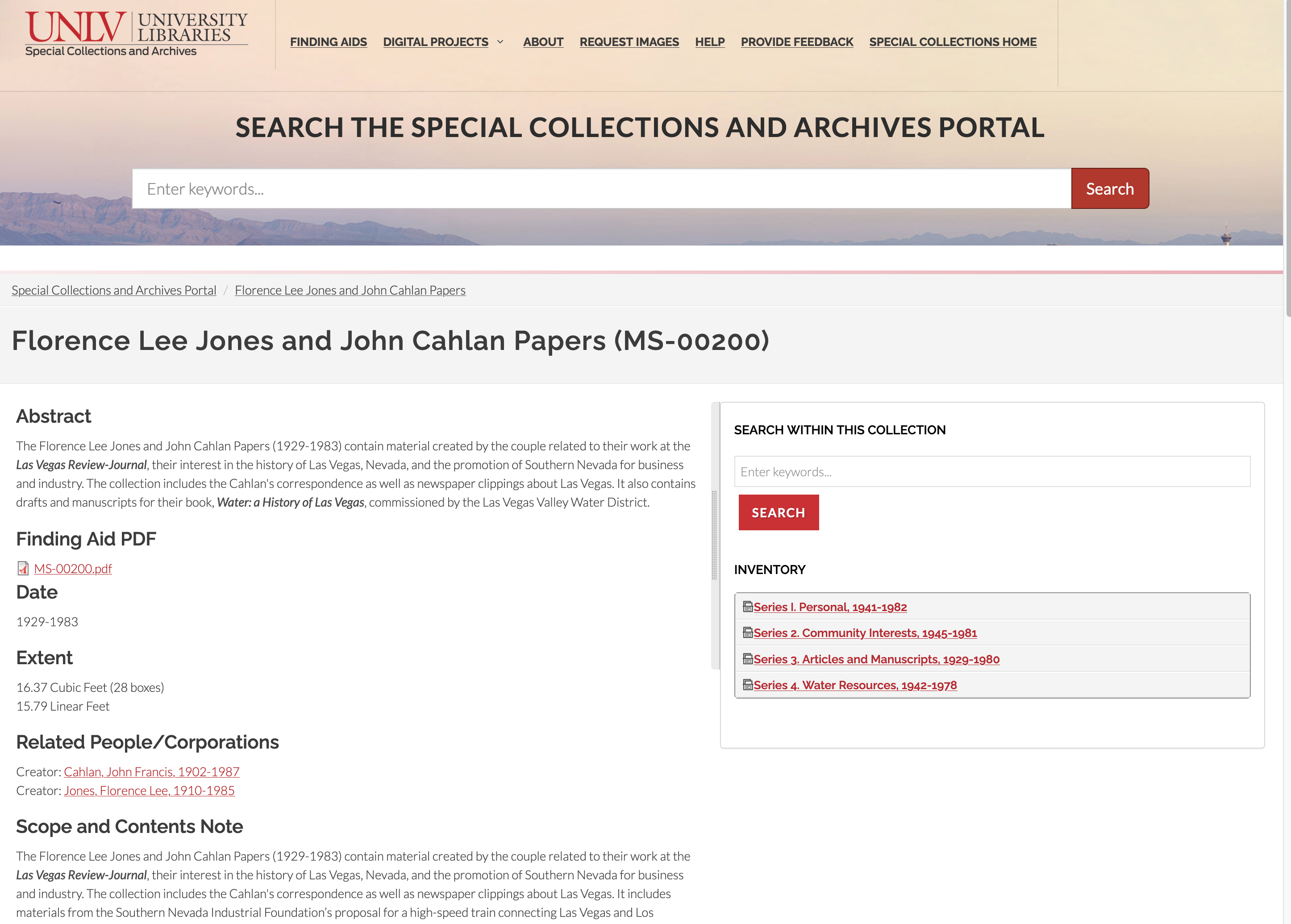 Figure 9. Archival collection page.
Figure 9. Archival collection page.
Archival component pages show component-level description, as well as the basic information needed to request the materials in the SCA reading room. The component’s hierarchical organization within the collection is shown in the breadcrumbs at the top of the page. The search box to search within the collection is also present. If the component is digitized, a link to the digital object is displayed as a thumbnail. If the component has child components or multiple child digital objects, those are displayed in an inventory under the “search within this collection” box.
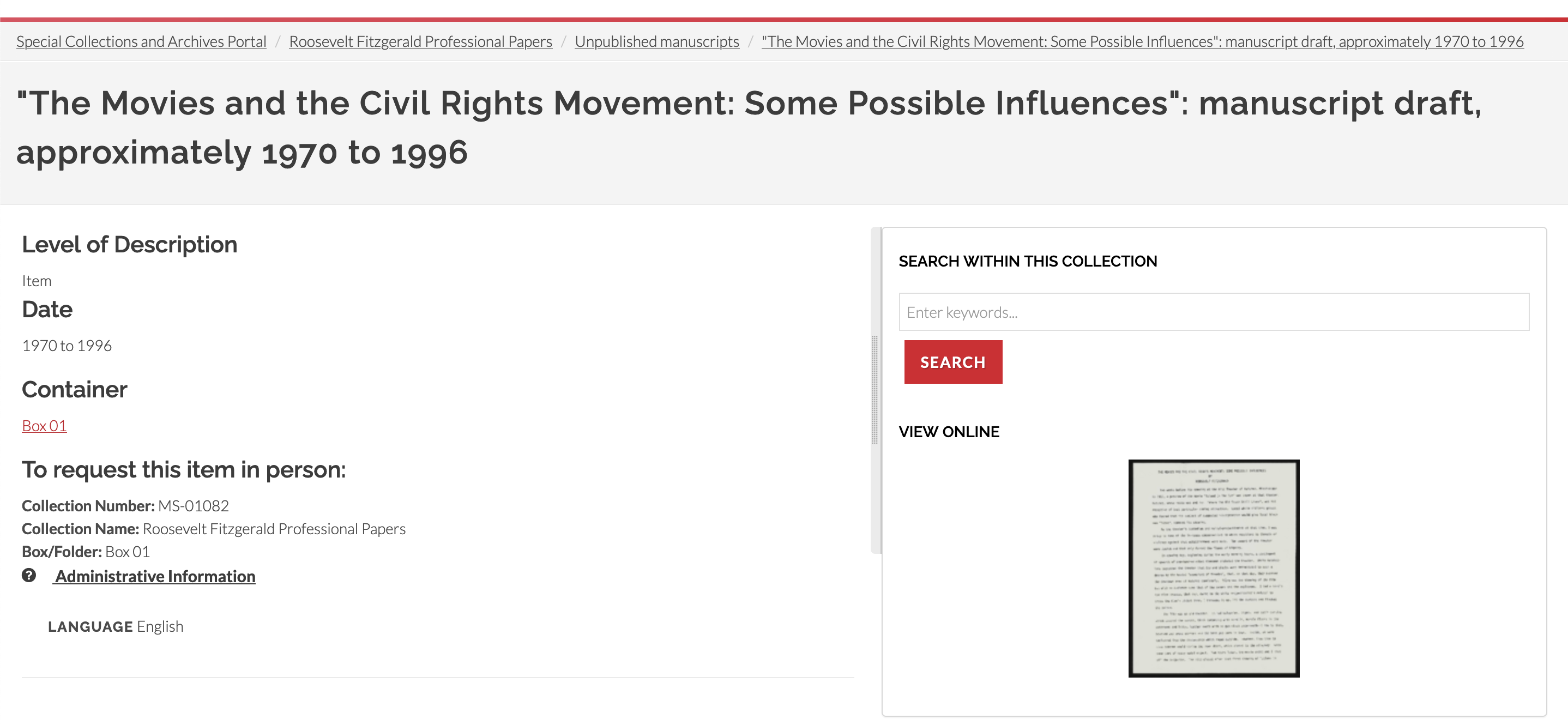 Figure 10. Archival component page.
Figure 10. Archival component page.
UNLV’s digital objects are mainly images and text documents, but also some audio and video files. There are many complex digital objects in the SCA Portal, meaning multiple digital items grouped together and described in the aggregate. A complex object could be two images of the front and back of a photograph or letter, or it could be an entire folder of photos or documents that has been digitized. There are links between parent and child records in breadcrumbs at the top of the page, in the metadata, and also below images. Digital objects are also linked to archival components when possible, and this hierarchy is part of the breadcrumbs. The most important metadata fields appear next to the digital file, with other fields placed below into different tabs.
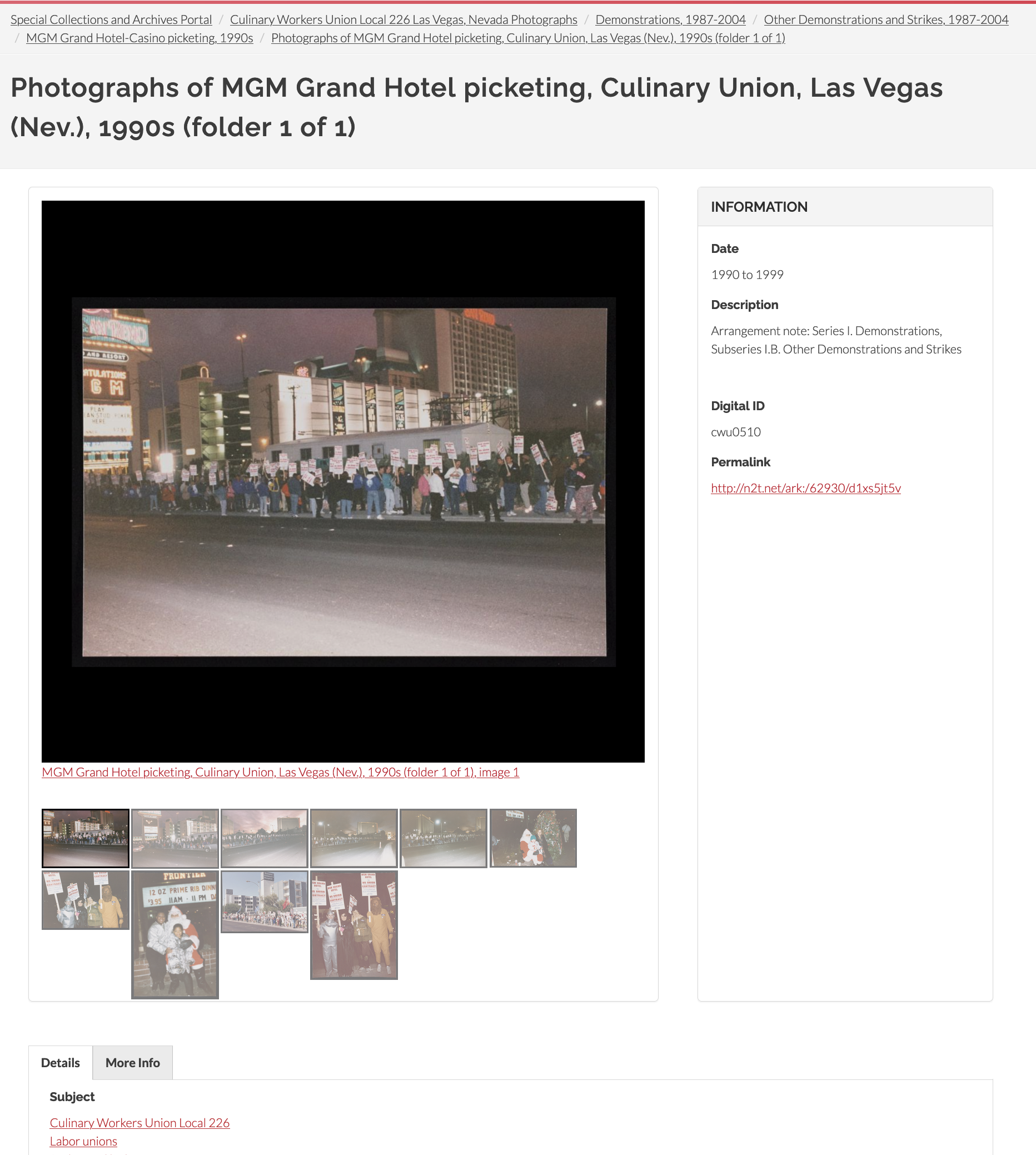 Figure 11. User interface for the parent record of a complex digital object consisting of images.
Figure 11. User interface for the parent record of a complex digital object consisting of images.
Adjusting to Islandora
UNLV’s Islandora DAMS was named the UNLV Special Collections and Archives Portal and publicly launched in August 2021. SCA had achieved its goals of replacing CONTENTdm and creating a unified search interface to improve the online user experience. Motivated by the end of UNLV’s CONTENTdm contract with OCLC, and a development timeline that was stretching longer than anticipated, the Portal was launched while it was still missing some of SCA’s desired features, including those related to digital preservation. Below, the authors discuss the reactions of users and staff to the new system, as well as challenges faced, adjustments made, and lessons learned.
Labor Disruptions
Less than a year after the public launch of the Portal, UNLV experienced a common challenge for libraries working with in-house technical development projects. They lost their lead developer to a better employment offer. With the COVID pandemic greatly disrupting labor across the country and the advent of more fully remote positions for developers, this was a challenging time for many organizations. UNLV strove to fill the gaps by asking existing staff to learn new skills, relying more on the community for troubleshooting, and through the significant work of a contract developer hired to partially fill the gap (with 20 hours/week devoted to helping maintain the system). It is hoped that with the hire of a permanent developer, additional progress can be made on Portal priorities, but for the most part the Portal has been in a holding pattern/maintenance-only mode for over a year.
Documentation and extensive cross-training were a lower priority than launching a functional product, resulting in only minimal documentation being created. Additionally, the system itself changed frequently during its development (as detailed above) making it impractical to create extensive documentation and invest in cross-training before the Portal was stable. While the original developer created basic documentation for the most important aspects of the Portal, a top priority for the new developer will be to update and enhance local documentation alongside conducting an audit of the Portal to identify and prioritize upgrades, fixes, and improvements necessary for the security, stability, and sustainability of the system. Since the original developer left, SCA and Technologies staff have learned more technical details by necessity during troubleshooting. A new lead developer will fill in the rest of the picture where the gaps in knowledge currently exist.
UNLV’s approach to adopting Islandora 2 was driven by local necessity in terms of timing and also by ambitious goals for features. Reflecting on this undertaking, the benefit it offered the developer was the chance to contribute to the community codebase and participate in the decision-making involved with the redesign of Islandora. Now, institutions that are interested in adopting Islandora 2 have the benefit of a stable version to build from, or working with a vendor experienced in Islandora 2, which reduces the amount of in-house development and support needed, compared to the scope of the project that UNLV set for itself.
User Feedback
The Web Content and User Experience Specialist led virtual usability testing of the new Portal with nine participants and wrote a report of the findings in Spring 2022. The team also set up an online form for user feedback that is linked to from the top menu of the SCA Portal. The most often cited dislikes of the Portal focused on difficulty understanding labels (definitions of what the filters would return) and difficulty understanding oral history content (how to access items by a narrator, access a transcript, or find out if an oral history had restrictions). There was feedback that one search box was preferable to the previous system and that the hierarchies were particularly useful as context. Overall, the user feedback and usability test results confirmed that UNLV had successfully launched a repository that not only met our initial launch goal of a minimally functional project, but exceeded users expectations in ease of use, speed, and the availability of content filters to find items. While the internal team was very much aware of a long list of features that were still pending development, they were encouraged by these strong results and decided to go forward with dismantling the previous repository and making a full switch to the new Portal.
Metadata Management Tools
Digital Collections (DC) metadata workflows were altered significantly by the migration from CONTENTdm to Islandora. DC initially planned to develop an application that replicated the functionality of the CONTENTdm Project Client for the SCA Portal. The Project Client software had a user-friendly GUI that made it possible for student workers to create metadata in a spreadsheet or item-level view, choose terms from locally managed lists of controlled vocabulary terms, and ingest digital objects in bulk. It also allowed staff to review metadata quality and make edits in bulk before the digital objects were published publicly online. However, due to lack of resources, this project kept getting pushed back and was eventually put on hold indefinitely. In the meantime, the team experimented with Drupal views for bulk metadata editing. Mostly this has also been put on hold as the department has adjusted workflows to take advantage of the community supported tool Islandora Workbench.
Islandora Workbench is a “command-line tool that allows creation, updating, and deletion of Islandora content from CSV data” [15]. Digital Collections staff learned to use this tool to ingest new digital objects, edit metadata, and delete and replace files (media) in bulk. There was a slight learning curve setting it up and learning how to edit the configuration files and format the CSV files, but within a couple months of using it regularly, DC librarians felt comfortable with this tool. However, DC decided that Workbench is a bit too complicated to train student workers to use. Instead, the department adjusted its workflows so that librarians are creating most of the metadata in bulk in CSV files and ingesting via Workbench, and students enhance metadata at the item level in the web interface (for example, adding subject terms). This process is rather slow and has made metadata enhancement project timelines longer than in the previous system as students cannot work on a batch of items at one time. Some of the strengths of Workbench are that it is widely used, actively maintained, and updated often; however, that can turn into a challenge when a new update causes a new error. DC Librarians rely on the Islandora community and WADS staff to help troubleshoot and solve these errors, which occur every few months.
ArchivesSpace Integration (part two)
Users and staff are generally happy with the unified interface that includes ArchivesSpace data in the SCA Portal, but several adjustments needed to be made after launch to both the user experience and staff workflows. Once a week, an automated script updates the SCA Portal with any additions, revisions, and deletions made in ArchivesSpace. Updates can also be refreshed “on demand” if there is an urgent need. Initially, the sync was only adding new archival resources and components, but any edits to existing components or removal of components were not reflected. This led to multiple versions of the same components displaying at once and changes not being reflected to the general public until the problem was resolved by Library Technologies.
Each archival component is its own webpage in the Portal, which can require many clicks to navigate the finding aid for a single collection. SCA decided to also provide access to finding aids in PDF format, which is how they were previously available to users. The PDFs are generated in ArchivesSpace and available for users to download in the Portal on the archival collection page. However, Technical Services (TS) must manually create or refresh the PDFs using the Portal staff interface.
DC and TS also created workflows to link digital objects and the archival components they are the same as or part of. DC uses a view to export a CSV file of the archival components of a collection from the Portal. This spreadsheet includes description fields such as title, date, Drupal node ID, and ArchivesSpace reference ID. DC reuses the archival description as the basis for the metadata for digitized materials, and adds the archival component node ID to the metadata to create links between the two in the Portal. TS must separately add digital object ARKs into ArchivesSpace so that digital object links are also available in the PDF version of the finding aid. After digital objects are ingested into the SCA Portal, the Digital Collections Librarian sends a spreadsheet to Technical Services of the digital objects IDs, their corresponding ARKs, and the ArchivesSpace reference IDs of the archival components that the digital objects are the same as or part of. Technical Services uses the “Digital Object Bulk Import” spreadsheet feature in ArchivesSpace to simultaneously create and link digital objects to existing archival objects. Once this task is completed, the PDF is regenerated and links appear for users to immediately go from PDF archival inventory to the corresponding digital object.
Subject headings and agent records are also synced from ArchivesSpace to the Portal. Merging the controlled vocabularies from ArchivesSpace and CONTENTdm has been a challenge for SCA. Different controlled vocabularies, subject application styles, and different teams creating subject terms led to significant duplication. While some work to merge duplicate terms has been completed, there are over 20,000 terms in SCA’s local controlled vocabularies, so further work has been postponed until a new full-time lead developer is hired and can help automate and complete these edits in bulk. In the meantime, SCA has adjusted workflows to avoid duplication so that all agent records are created only in ArchivesSpace and synced to the Portal every hour.
Missing Functionality
There are some development priorities that were on the initial functional requirements list for the system that were developed prior to launch. While the metadata functionality evolved with the community and these tasks have been partially addressed with Workbench, some needed modules are not yet prioritized in the community or UNLV has lacked the development resources to implement community work. Some of the main areas that require significant local development work include:
- Advanced search functionality
- Automating text extraction from PDFs to an indexed metadata field to improve full text search for researchers for textual digital objects and newspapers [16]
- A method to restrict content (this would enable the Portal to be used for born-digital content and embargoed or sensitive collections) [17]
- Better quality control functionality using Drupal Views (to aid in metadata enhancement)
- Integrated digital preservation workflows (such as fixity checking)
Ultimately, the DAMS replacement project was a success. We have a new linked data repository with a unified interface that simplifies the access to multiple types of special collections content. Most users find it easy and satisfying to use and approve of the design philosophy. At this point, a new phase of refining and enhancing the Portal would provide an opportunity to address some of the missing functionality and to meet the third goal of addressing born-digital access and preservation.
Reflection
At various points in this repository development work, there have been points where the team has expressed uncertainty about the stability and security of selecting an open-source, community-led software product. Following the resignation of the lead developer, there was fear about support needs and conversations about rolling back the project, looking for hosted support, or returning to a vendor product. But, with time and more experience, many of these anxieties have transformed into actionable projects and manageable strategic priorities. The advantage of encountering challenges is that there is a rich environment of learning and growth. Some of the key lessons learned in the project include how expectations have been modified, and how to manage them going forward as the team looks towards further development.
Most technical projects are managed with a goal, allocated resources, and a deadline. But working with open-source software, especially in a solo developer environment, meant that project managers, supervisors, and colleagues had to adapt to the realities of working in sometimes ambiguous or uncertain circumstances. For instance, a module may exist in the community, but when explored further it may be found that documentation is minimal, that the module requires customization to work in the local context, or that it simply is not mature enough to work reliably. In other cases, a simple upgrade or security issue that seemed straightforward ended up involving more staff members and time than initially planned. A key lesson was to understand that timeline forecasting is difficult and that using techniques like agile project management are often more suitable than strict deliverables and hard deadlines.
The team also had to learn new ways of working and adapt expectations of what “technical support” looks like. There is a significant adjustment for staff when moving from a vendor supported product to an open-source community. No longer can staff expect that if they uncover an error that a service call will be made and the issue resolved in an expected time-frame. Rather, the team had to build a new workflow that included how to report a Portal issue, who the issues should go to, what roles each member of the team played in troubleshooting, how to document errors and troubleshooting work, and how to engage in the community if outside support was required. After several months of refinement, this system is now in place and has become more comfortable, but there can still be discomfort or a feeling of insecurity for staff wondering, “what if the Portal goes down” when they are working at a public service point or in critical moments with patrons or donors.
Expectations have also changed in areas of decision-making. Philosophically, UNLV supports the open-source model; but there are times when it can be too slow or the community priorities are out of alignment with the organizational needs. We have learned that we need to find a middle road between completely vendor-provided products and services, and completely custom, built-to-order open source software development. We take the approach to try and reuse community work when possible. We see the value in working in uniform ways with the Islandora core code and modules. But some workflows may need the boost of dedicated development resources to complete development of a new function or service and the team is looking for ways to supplement our internal resources with project work and vendor solutions (such as a site audit to improve our documentation, or a vendor contract to help implement restricted materials functionality).
In the current environment, the team also noticed a shift in the power dynamic from an administrator or director setting the work plan and then the project manager setting milestones and the functional experts reporting the progress. Instead, we now work in a complex environment with shifting power dynamics encompassing the open source community, workflow owners who may or may not be able to optimally complete their work in the Portal, our users/stakeholders, staff who prioritize technical development work (but cannot do it themselves), the technology experts who have the technical expertise to solve problems, the managers responsible for evaluating job performance, and administrators – who may or may not understand the true measures of the system’s success or value. This all means that more communication is required and every person on the team needs to advocate for the system.
Future goals
The UNLV team has had a chance over the last twelve months to look back and reflect on the selection, migration, and use of the SCA Portal and despite the aforementioned challenges, the future looks bright. Currently our future tasks include:
- On-boarding a new lead developer and delving more deeply into how Islandora skills are acquired and sustained
- Designating a product owner to liaison between the stakeholders and the developer and who will manage communications and priorities
- Building relationships in the community and possibly hosting an event to bring potential collaborators to us locally
- Leveraging vendor relationships to fill gaps in large development projects
- Continuing to nurture collaborative relationships in the organization
Making our digital library more inclusive of content and merging the provision of agent information and archival information into one unified interface for our users has been a challenging but rewarding project. It is certain that new technical issues and challenges will arise as the team enters the second phase of repository development, but with the experience gained since launch, the support of the community, and the dedication to the principles that drove the initial project, the team can continue to build an innovation solution to special collections discovery and ensure a sustainable path forward.
References and Notes
[1] Islandora 2 has also been known as Islandora 2.x, Islandora 8, and modern Islandora. It was also known by its pre-release codename, Islandora CLAW. For more information, see Islandora’s Versioning Policy at https://islandora.github.io/documentation/technical-documentation/versioning/“
[2] Islandora Commit: Using Context instead of Rules https://github.com/Islandora/islandora/commit/c807bab123421b70c84d4d6127e923b8018820e9
[3] Islandora Commit: Content modeling overhaul https://github.com/Islandora/islandora/commit/a1987aecb747b0b297176fc4d34afdc22cbddb4d
[4] Islandora Commit: Flysystem https://github.com/Islandora/islandora/commit/cb8bb07238d1822370aca73e7011fdea9235c501
[5] Islandora release 1.0.0 https://github.com/Islandora/islandora/releases/tag/1.0.0
[6] At the time it was limited to an ansible playbook although the community has since added docker-based deployments.
[7] See “Architecture Diagram” in the Islandora Documentation: https://islandora.github.io/documentation/technical-documentation/diagram/
[8] Lavinia Ciuffa, “From Processing to Public Service: The Digital Humanities Center at the American Academy in Rome”, Visual Resources Association Bulletin, vol 44, no. 1 (2017). https://online.vraweb.org/index.php/vrab/article/view/40
[9] Unfortunately, the collaboration only lasted a few months before our partner turned their attention to other things.
[10] Some components of this integration are discussed in more detail in an ArchivesSpace hosted webinar available online: Seth Shaw, “Integrating ArchivesSpace with Drupal and Islandora at University of Nevada, Las Vegas Libraries”, ArchivesSpace Webinar Series, July 15, 2020. https://youtu.be/qic3SvcbAuc
[11] ArchivesSpace complex fields https://git.drupalcode.org/project/archivesspace/-/tree/8.x-1.x/src/Plugin/Field/FieldType
[12] Islandora Controlled Access Terms Module https://github.com/Islandora/controlled_access_terms
[13] The Library of Congress proposed the Extended Date/Time Format (EDTF) Specification in 2012 on which the UNLV module was based. EDTF received a new version on February 4th, 2019 and the UNLV module, now transferred to the Islandora organization, was updated accordingly. See https://www.loc.gov/standards/datetime/.
[14] Islandora migration documentation https://islandora.github.io/documentation/technical-documentation/migrate-csv/
[15] Islandora Workbench repository https://github.com/mjordan/islandora_workbench
[16] Newspapers are currently not indexed and only available as a list of titles and issues: https://special.library.unlv.edu/collections/newspapers
[17] The early version of the repository did have support for restricted content based on a module the Islandora community presumed would work. However, as the size of the repository grew we discovered performance degraded significantly, so the stakeholders decided to table that requirement until a more performant solution for restricted content could be found. See Seth Shaw, “Islandora: Performance Testing & Content Access Control”, Islandora Open Meeting, 2021-02-23. Recording available at https://youtu.be/tKQIdYjsVDo with slides available at https://seth-shaw-unlv.github.io/files/2021-02-23_Islandora_Open_Meeting_Performance_Testing_and_Content_Access_Control.pdf
About the Authors
Sarah Jones is Head of Special Collections & Archives Technical Services at the University of Nevada, Las Vegas where she leads a team in the preservation, description and access, and overall management of archival holdings in both physical and digital formats.
Cory Lampert is Professor and Head of Digital Collections at the University of Nevada, Las Vegas where she is responsible for leading a team responsible for digitization, metadata and linked data creation, and digital asset management.
Emily Lapworth is Associate Professor and Digital Collections Librarian at the University of Nevada, Las Vegas. Her work focuses on digitization, digital asset management and preservation, and increasing online access to archives and special collections materials.
Seth Shaw was the Software Engineer for Special Collections and Archives at the University of Nevada, Las Vegas where he was responsible for the maintenance and development of software applications used in the Special Collections and Archives; primarily Islandora and ArchivesSpace. He is now a Digital Library Software Engineer at Arizona State University Libraries.

Subscribe to comments: For this article | For all articles
Leave a Reply