By Andrew Weymouth
Background
The University of Idaho’s Digital Scholarship and Open Strategies (DSOS) department was established in 2008 to digitize the International Jazz Collection and has since expanded to over 130 digital collections.[1] These are constructed with CollectionBuilder, an “open source framework for creating digital collections and exhibit websites that are driven by metadata and modern static web technology”[2]. A companion framework named Oral History as Data (OHD) was developed in 2016 to visualize encoded transcriptions and allow researchers to explore oral history recordings by keywords and tags. In this paper, “tagging” refers to a custom set of subject designations that can be tailored by the transcriber depending on the recording’s content and themes.
Figure 1. CollectionBuilder browse site and CollectionBuilder template interface
Our physical workspace at the library is the Center for Digital Inquiry and Learning (CDIL), where our Digital Labs Manager, Digital Project Manager and I support the labor of a small group of student workers and fellowship recipients, generally around 2-5 a semester. Both the CollectionBuilder and OHD frameworks have been designed to be simple and accessible, only requiring someone with access to Google Sheets, Visual Studio Code and minimal software installation to create, maintain, and export digital collections.
For the process outlined in this paper, student transcribers only need access to Google Sheets to generate and edit subject tags using Google’s Apps Script extension, while the project manager needs access to Adobe Premiere and a text editor to run the Python Script to generate transcriptions, text mine the material, and to create subject tags.
The incentive for this project arose from realizing a number of oral history recordings were either untranscribed, partially transcribed or lacking in accuracy following a data migration of our digital collections away from ContentDM in the winter of 2023. Because of the volume of text that needed updating, it was worthwhile to rethink workflows for overall efficiency and accuracy.
Distant Listening
One element I wanted to focus on was the creation of subject tagging to enrich the transcripts. In addition to keyword searching, the OHD interface allows custom subject tags to be highlighted and visualized across the duration of recordings. New York University’s Weatherly A. Stephan details the importance of subject tagging oral history collections, noting how “transcription alone cannot address the perennial gap of supporting serendipitous discovery through subject-based inquiry rather than simply known-item searching.”[3]
Previous transcription practices had student workers and CDIL Fellowship recipients adding subject tags to automated transcripts as they were copy editing dialogue, using the recordings as a reference. Transcribers would tag individual recordings of collections that ranged from 20 to over 100 recordings, making their best judgments to what subjects seemed like they might be indicative of the overall collection. This approach, which I am calling linear listening, may mislead transcribers by establishing repeating themes that do not occur across the collection or missing themes that only begin to appear in later recordings.
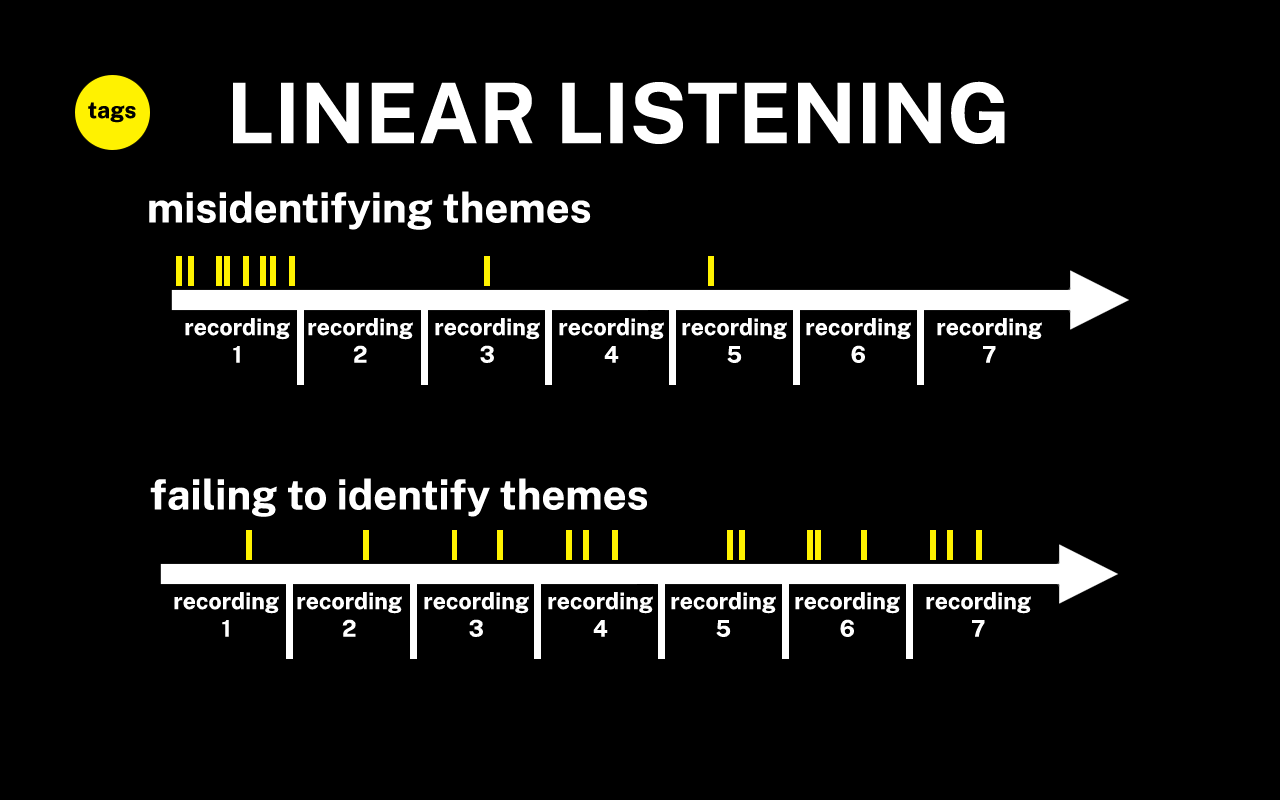
Figure 2. Challenges of Linear Listening Visualization
Our physical workspace at the library is the Center for Digital Inquiry and Learning (CDIL), where our Digital Labs Manager, Digital Project Manager and I support the labor of a small group of student workers and fellowship recipients, generally around 2-5 a semester. Both the CollectionBuilder and OHD frameworks have been designed to be simple and accessible, only requiring someone with access to Google Sheets, Visual Studio Code and minimal software installation to create, maintain, and export digital collections.
Distant listening is an alternate approach that mines combined transcripts and generates tags before the transcriber begins the copy editing process. This moniker is an adaptation of Franco Moretti’s concept of distant listening, “where distance[…] allows you to focus on units that are much smaller or much larger than the text: devices, themes, tropes—or genres and systems” [4]. By searching across collections for terms and phrases indicating subject matter, oral history project managers can produce richer, more accurate data that increases the discoverability of recordings and makes the transcription process more dynamic and pedagogically rewarding for transcribers.
This case study details my experience over the winter and spring of 2024 developing the tools independently and testing the process with two student transcribers working through 30 transcriptions, incorporating their feedback and streamlining processes. I also had a chance to iterate over this process in January 2025, this time working with the CDIL Digital Projects Manager to transcribe, tag and copy edit 100 more recordings for digital preservation.
Challenges
The time-intensive nature of transcription, subject tagging and web hosting has made oral history recordings an undervalued format in digital initiatives. As Doug Boyd, director of the Louie B. Nunn Center for Oral History at the University of Kentucky recounts in his chapter Oral History Archives, Orality and Usability (2015):
“From the archival perspective, oral history proved an exciting and enticing resource to acquire. However, the difficulties posed by time-intensive and financially draining realities of processing oral history collections resulted in an analog crisis in the late 1990s. Hundreds of oral history archives around the United States claimed large collections, but the overwhelming majority of these collections containing thousands of interviews remained unprocessed, analog, inaccessible, and unused” [5].
In Quantifying the Need: A Survey of Existing Sound Recordings in Collections in the United States (2015), created in collaboration with the Northeast Document Conservation Center, the authors highlight the scale of archival audio preservation challenges. They conclude that only 17% of audio holdings in U.S. collections have been digitized. The survey estimates that over 250 million preservation-worthy items remain undigitized. Of these, more than 80 million (32%) will require a specialized audio preservation workflow. The report goes on to detail how the National Recordings Preservation Plans states that many of these analog recordings must be digitized between 2027 and 2033 before material degradation [6].
In contrast to the digitization of archival photographs or documents, meeting accessibility standards for oral history recordings involves not only transcribing recordings but also presenting them in an intuitive, keyword navigable digital interface. OHD developer Devin Becker’s solution displays the audio at the top of the page, followed by a visualization of the recording with color valued tags, a key to the tags, a search bar for keyword queries and the transcription below. This allows researchers to follow along with the time stamped transcript as the audio plays.
Figure 3. Demonstration of Oral History as Data transcription/recording interface, keyword search functionality and tag visualization showing ability to read through audio material both chronologically and vertically
Despite this advancement in the audio player interface, the initial transcription and tagging remained a significant hurdle in developing these collections. While machine learning speech to text technology has improved considerably since the development of the OHD platform in 2016, early, no cost transcription services were often so poor that they required extensive manual correction. Fully human-driven transcription and tagging has its own challenges: it is tedious, slow moving work that, without close supervision, can result in uncontrolled vocabulary, knowledge gaps, and bias from linear listening.
Process
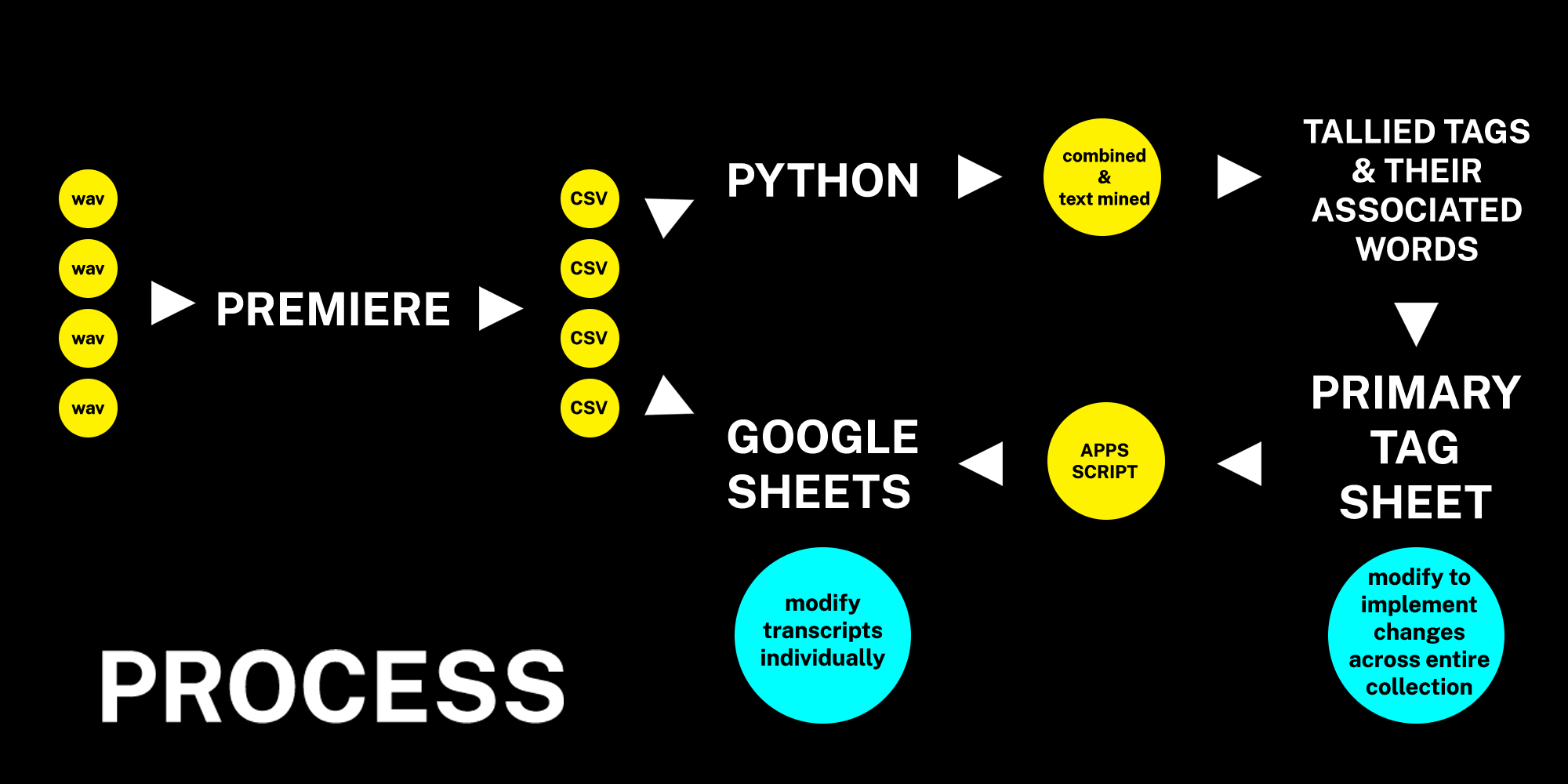
Figure 4. visualization of workflow from audio files to CSV to Python text mining and Google Sheets
Overview
To summarize the process:
- Transcription: audio is transcribed into Comma Separated Values (CSV) files using Adobe Premiere’s Speech to Text tool
- CSVs are made into individual Google Sheets, exported using an Google’s Apps Script extension and added to a folder in the Python Transcription Mining Tool
- On running the Python script, these items are combined and searched for all associated terms and phrases built into the different subject tag categories
- The tool generates a tally of these terms and phrases, which is used to create the Primary Tag Sheet in another Google Sheet
- Using an Apps Script function, all individual transcripts are linked to the Primary Tag Sheet so each transcript’s tag column is automatically generated
- New subject categories or associated terms can be added or removed from the Primary Tag Sheet and these changes can be implemented across all individual transcripts by simply re-running the code
Transcription
Moving away from services the department had been working with, I tested Adobe Premiere’s Speech to Text tool and found it uniquely well-suited for the OHD framework, with advantages including:
- Powered by Adobe Sensei, machine learning dramatically increased accuracy in differentiating speakers and transcribing dialogue, even with obscure, regional proper nouns.
- Significantly faster transcription speed, from one 1.5-hour recording every two to three business days up to twenty 1.5-hour recordings in one day.
- Costs covered by our university-wide Adobe subscription.
- Direct export to CSV UTF-8 (avoiding conversion errors necessary for OHD)
- Available non-English language packs, enabling the creation of the department’s first Spanish and French language oral history collections.
- Privacy standards with Premiere’s General Data Protection Regulation compliance, ensuring all transcription material is stored locally and not uploaded to the cloud.[7].

Figure 5. Excerpt of transcript with the header names Speaker Name, Start Time, End Time and Text below a portion of sample dialogue
That said, the tool is not perfect. While modern recordings in good audio conditions have extremely high transcription accuracy, poor quality recordings and interviews between two similar sounding people can require significant correction.
Python Text Mining
After using the web-based text mining tool Voyant to develop subject tags for previous oral history collections, I wanted to create a text mining tool from scratch using Python that would allow the targeting of specific words and phrases and create custom tagging categories. While the Natural Language Toolkit (NLTK) has many more complicated modules for text processing, such as tokenization, parts of speech tagging and fuzzy string matching, I found these approaches generated too many false positives when it was attributing areas of the transcripts to subject tags.
Instead, this text mining approach favors less automation and more transparent and customizable controls. Custom subject sections are created which contain around 50 terms or two-word phrases. Running the Python script concatenates the CSV files, minimally processes them and then searches for these terms, then tallies and prints the terms in the terminal according to word frequency.
Once the CSVs of the transcripts are generated in Premiere, they are added to a Google Drive folder that is shared with the student workers who will be copy editing the transcriptions. Using the Apps Script downloadSheetsAsCSV code (see appendix 2) is run to generate a CSV with only the dialogue column. The CSVs are then added to the “CSV” folder in the Python workspace.
The code begins by importing the Pandas library for data manipulation, String for punctuation removal, Natural Language Toolkit (NLTK) stopwords (words removed from text before processing and analysis) for each collection and Collection Counter to tally identified terms within the dialogue.
Next, the ‘preprocess_text’ function removes punctuation, converts text to lowercase and handles missing values by replacing them with an empty string. CSV file paths are constructed, and the text data is concatenated into a single string corpus. Word frequency is tallied and the 20-50 most frequent words and phrases for each subject tag section are generated when the code is run.
Below this header material in the Python file are the three subject tag categories:
- General: agriculture, animals, clothing, etc.
- Geographic: (based loosely on migration statistics from the 1910 Idaho census): Basque, Britain, Canada, China, etc.
- Custom: (example from our Rural Women’s History Project): marriage and divorce, motherhood, reproductive rights, etc.
These fifty sections have a list of fifty associated terms and phrases that the script is searching for within the combined transcription corpus. These terms were generated using ChatGPT-4 turbo with the following qualifications:
- The word or phrase is only associated with one section. For example, regarding the sections agriculture and animals, the word “pasture” would be excluded since it could refer to both the land used for grazing animals and also the act of animals grazing.
- Exclude homographs (words that are spelled the same but have different meanings). For example, “sow” refers both to an adult female pig and the agricultural act of planting seeds in the ground.
- Placenames and how certain nationalities would refer to themselves for the geographic sections. For example, “Philippines”, “Filipino”, “Tagalog…”, “Norwegian”, “Norway”, “Oslo…” or “Japanese”, “Japan”, “Tokyo”, etc.
- Terms and phrases favor informal, conversational speech.
These text mining categories and sections produce a total of 2,250 associated terms or phrases that are being identified across the combined transcript corpus before the script tallies these words to generate the output shown below:

Figure 6. Sample of identified terms from combined transcripts, tallied in descending order.
See Appendix 1 for the header script and one subject section or visit the GitHub repository to view code in full.
Apps Script Connection and Customization
Once this text mining data is produced, it can be copied and pasted into the Primary Tag Sheet in Google Sheets, located in the same folder as the transcripts for student workers to access and edit. Using the Text to Columns function, subject tag sections can be split into column A and their associated words into column B using the programmed “##” as the separator.
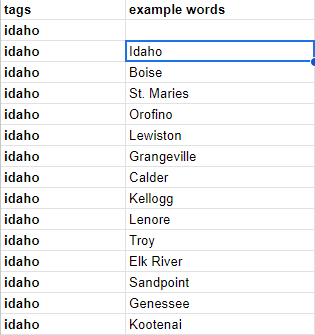
Figure 7. Example of the formatted primary tags sheet with headers reading tags in column A and associated words in column B.
After minor formatting to the individual transcript, student workers access the Apps Script extension located in the drop-down menu. Transcribers then enter the code (see Appendix 3), and make two adjustments:
- Change the sheet name of the transcript they are editing on line 6
- Change the URL of their primary tag sheet on line 13. Then save and run the code
Now the individual transcript is connected to the Primary Tag Sheet, which will automatically search the text column for these terms and phrases and fill in the tag column of the transcript with its associated subject tag.
It is important to state that this process is not intended to replace human transcribers but shifts the focus from manual tagging to copy editing.
If transcribers notice that a tag is either not applicable or missing from the Primary Tag Sheet, they are encouraged to make these additions or subtractions and rerun the Apps Script on their individual Sheets, which will automatically enact these revisions across the entire document. If transcribers notice errors that are more specific to individual transcriptions, they can paste these edits into an additions or subtractions column to the right of the tag column, so the changes aren’t written over by future runs of the Apps Script code.
Findings
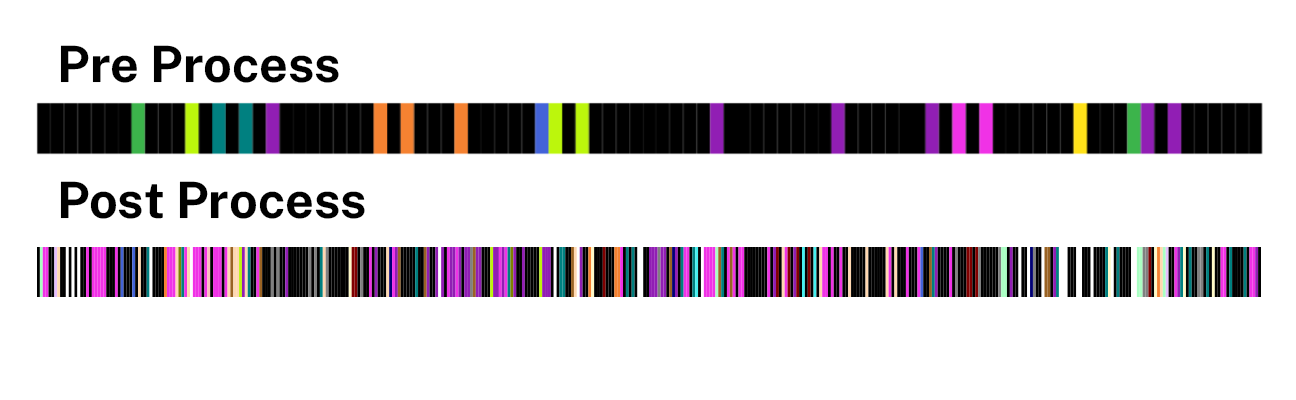
Figure 8. Example of a pre and post process tagging visualization of a recording, with the post process being dramatically more dense.
While initially testing this process, my main concerns were:
- Would transcribers find the Apps Script coding element confusing and/or anxiety-inducing?
- Due to the complexity of language, would the automated tagging generate so many false positives that correcting these items would become a drag on productivity?
Working with a student worker and a fellowship recipient, copy editing 30 transcripts over the course of two months in the summer of 2024, these factors were not an issue. Possibly helpful in this effort was weekly meetings where we checked in and tested the code, sometimes purposefully breaking it to show how those mistakes can be easily fixed and demonstrate how they can update the Primary Tags Sheet and rerun on their individual transcript sheets. Rather than simply asking student workers to transcribe recordings—work that offers little to highlight on a CV and can lead to burnout and high turnover—this process allows transcribers to engage in coding, create and modify tags, and see those changes reflected instantly through the Apps Script process.
I had the opportunity to revisit and iterate on these tools and processes for another oral history digital collection undertaken in January 2025, this time working with the Digital Projects Manager, as opposed to student transcribers. We were able to complete the process lifecycle of transcription, tagging and copy editing for 100 recordings in just over a week, increasing productivity from the summer 2024 initiative by 1233%.
Regarding the limitations of data-driven, human-edited automated tagging, program managers must communicate that automated tags are only a starting point. Tags may be incorrectly applied, missing or need to be applied more broadly to transcripts. Even when these measures are taken, the amount of detail this process accrues is easily distinguishable in the before and after OHD tagging visualization shown above (fig. 8). One could argue that the density of the data might now make it difficult for the researcher to navigate, especially on mobile devices. This continues to be a dialogue as we refine this workflow.
Conclusion
While discussing grant funding for digital initiatives, a colleague pointed out that the time-intensive nature of oral history projects often leads to their neglect. As they put it:
“Would you rather present ten oral history recordings or 500 photographs?”
This quantity-focused selection criteria ultimately poses an existential threat, leaving these materials physically vulnerable as they languish in the archives. Bicentennial and community oral history initiatives, rich in non-academic perspective, offer a uniquely biographical account of places and provide valuable contrast and context to the accepted historical record. By utilizing machine learning, Python, and Apps Script approaches, this process seeks to make digitizing these resources more efficient and accessible, promoting their preservation and availability to the public.
References and Notes
[1] Digital Collections, University of Idaho. University of Idaho Library Digital Initiatives. 2024 [cited 2024 Jul 8]. Available from: https://www.lib.uidaho.edu/digital/collections.html
[2] Home. CollectionBuilder. [accessed 2025 Feb 13]. https://collectionbuilder.github.io/
[3] Stephan W. The Platinum Rule Meets the Golden Minimum: Inclusive and Efficient Archival Description of Oral Histories. Journal of Contemporary Archival Studies. 2021;8(1). https://elischolar.library.yale.edu/jcas/vol8/iss1/11
[4] Moretti F. Conjectures on World Literature. New Left Review. 2000;(1):54–68.
[5] Boyd DA. ‘I Just Want to Click on it to Listen’: Oral history archives, orality and usability. In: The Oral History Reader. 3rd ed. Routledge; 2015.
[6] AVP. Quantifying The Need: A Survey Of Existing Sound Recordings In Collections In The United States. AVP. 2014 [accessed 2025 Feb 14]. https://www.weareavp.com/quantifying-the-need-a-survey-of-existing-sound-recordings-in-collections-in-the-united-states/
[7] Speech to text in Premiere Pro FAQ. Adobe. [cited 2024 Jul 8]. Available from: https://helpx.adobe.com/content/help/en/premiere-pro/using/speech-to-text-faq.html
About the Author
Andrew Weymouth is the Digital Initiatives Librarian at University of Idaho, specializing in static web design to curate the institution’s special collections and partner with faculty and students on fellowship projects. His work spans digital scholarship projects at the universities of Oregon and Washington and the Tacoma Northwest Room archives, including long form audio public history projects, architectural databases, oral history and network visualizations. He writes about labor, architecture, underrepresented communities and using digital methods to survey equity in archival collections.
Professional Site: aweymo.github.io/base
Appendices
Appendix 1. Excerpt of Python Text Mining Tool
import pandas as pd
import string
from nltk.corpus import stopwords
from collections import Counter
import re
# Download NLTK stopwords data
import nltk
nltk.download('stopwords')
# Define preprocess_text function
def preprocess_text(text):
if isinstance(text, str): # Check if text is a string
text = text.translate(str.maketrans('', '', string.punctuation))
text = text.lower() # Convert text to lowercase
else:
text = '' # Replace NaNs with an empty string
return text
# Load stopwords for both Spanish and English
stop_words_spanish = set(stopwords.words('spanish'))
stop_words_english = set(stopwords.words('english'))
# Combine both sets of stopwords
stop_words = stop_words_spanish.union(stop_words_english)
import os
# Directory containing CSV files
directory = "/Users/andrewweymouth/Documents/GitHub/transcript_mining_base/CSV"
# List of CSV file names
file_names = [
'example_01.csv', 'example_02.csv', 'example_03.csv'
]
# Construct file paths using os.path.join()
file_paths = [os.path.join(directory, file_name) for file_name in file_names]
# Initialize an empty list to hold the DataFrames
dfs = []
# Try reading each CSV file and print which file is being processed
for file_path in file_paths:
try:
print(f"Processing: {file_path}")
# Add quotechar and escapechar for handling CSVs with quotes
dfs.append(pd.read_csv(file_path, encoding='utf-8', quotechar='"', escapechar='\\'))
except Exception as e:
print(f"Error with file {file_path}: {e}")
# Concatenate text data from all dataframes into a single corpus
corpus = ''
for df in dfs:
text_series = df['text'].fillna('').astype(str).str.lower().str.strip() # Extract and preprocess text column
corpus += ' '.join(text_series) + ' ' # Concatenate preprocessed text with space delimiter
# Preprocess the entire corpus
cleaned_corpus = preprocess_text(corpus)
# Remove stopwords from the corpus
filtered_words = [word for word in cleaned_corpus.split() if word not in stop_words and len(word) >= 5]
# Count the frequency of each word
word_freq = Counter(filtered_words)
# Get top 100 most frequent distinctive words with occurrences
top_distinctive_words = word_freq.most_common(100)
# === General Section ===
def find_agriculture_terms(corpus):
# Define a list of agriculture-related terms
agriculture_terms = [term.lower() for term in ["harvest", "tractor", "acreage", "crop", "livestock", "farm field", "barn building", "ranch", "garden", "orchard", "dairy", "cattle", "poultry", "farming equipment", "fertilizer", "seed", "irrigation", "plow", "farmhand", "hoe", "shovel", "milking", "hay", "silage", "compost", "weeding", "crop rotation", "organic", "gmo", "sustainable", "farming", "rural", "homestead", "grain crop", "wheat", "corn maize", "soybean", "potato", "apple fruit", "berry", "honey", "apiary", "pasture", "combine harvester", "trailer", "baler", "thresher"
]]
# Initialize a Counter to tally occurrences of agriculture-related terms
agriculture_word_freq = Counter()
# Tokenize the corpus to handle multi-word expressions
tokens = re.findall(r'\b\w+\b', corpus.lower())
# Iterate over each token in the corpus
for word in tokens:
if word in agriculture_terms:
agriculture_word_freq[word] += 1
# Return the top 20 most common agriculture-related terms
return agriculture_word_freq.most_common(20)
# Call the function to find agriculture-related terms in the corpus
top_agriculture_terms = find_agriculture_terms(corpus)
# Print the top 50 agriculture-related terms
print("## agriculture")
for word, count in top_agriculture_terms:
print(f"{word}: {count}")
Appendix 2. Apps Script Code for Exporting Sheets to CSV for Text Mining
function downloadSheetsAsCSV() {
// Specify the folder ID of the folder containing the Google Sheets
var folderId = 'folder-id'; // Replace with your folder ID
var folder = DriveApp.getFolderById(folderId);
var files = folder.getFiles();
// Loop through each file in the folder
while (files.hasNext()) {
var file = files.next();
// Check if the file is a Google Sheet
if (file.getMimeType() === MimeType.GOOGLE_SHEETS) {
var spreadsheet = SpreadsheetApp.openById(file.getId());
var sheets = spreadsheet.getSheets();
// Loop through all sheets and download each as CSV
for (var i = 0; i < sheets.length; i++) {
var sheet = sheets[i];
var csv = convertSheetToCSV(sheet);
// Create a new CSV file in the same folder
var csvFile = folder.createFile(sheet.getName() + '.csv', csv, MimeType.CSV);
Logger.log('Downloaded: ' + csvFile.getName());
}
}
}
}
function convertSheetToCSV(sheet) {
var data = sheet.getDataRange().getValues();
// Find the index of the "words" column and replace it with "text"
var headerRow = data[0];
var wordsIndex = headerRow.indexOf('words'); // Locate the "words" column index
if (wordsIndex !== -1) {
headerRow[wordsIndex] = 'text'; // Change "words" to "text"
}
// Start building the CSV with the header row
var csv = 'text\n';
// Loop through rows and extract the "words" column, removing line breaks
for (var i = 1; i < data.length; i++) { // Start from 1 to skip the header row
var row = data[i];
// Extract the "words" column (index of "words" column)
var cell = row[wordsIndex];
// Remove all line breaks (carriage returns, newlines, etc.) within the "words" data
if (typeof cell === 'string') {
cell = cell.replace(/(\r\n|\n|\r)/gm, ' '); // Replace all line breaks with space
cell = cell.replace(/[^\w\s,.'"-]/g, ''); // Remove punctuation except for some valid ones
}
// Enclose the text in quotes to avoid column splitting due to commas
cell = '"' + cell + '"';
// Add the cleaned "text" to the CSV output
csv += cell + '\n';
}
return csv;
}
Appendix 3. Apps Script Code for Linking Transcript to Primary Tag Sheet
function fillTags() {
// Get the active spreadsheet
var spreadsheet = SpreadsheetApp.getActiveSpreadsheet();
// Get the transcript sheet by name
var transcriptSheet = spreadsheet.getSheetByName("your-sheeet-name");
if (!transcriptSheet) {
Logger.log("Transcript sheet not found");
return;
}
// Set the header in cell E1 to "tags"
transcriptSheet.getRange("E1").setValue("tags");
// Get the tags spreadsheet by URL
var tagsSpreadsheet = SpreadsheetApp.openByUrl("your-spreadsheet-url");
if (!tagsSpreadsheet) {
Logger.log("Tags spreadsheet not found");
return;
}
// Get the tags sheet within the tags spreadsheet
var tagsSheet = tagsSpreadsheet.getSheetByName("tags");
if (!tagsSheet) {
Logger.log("Tags sheet not found");
return;
}
// Get the range of the transcript column
var transcriptRange = transcriptSheet.getRange("D2:D" + transcriptSheet.getLastRow());
var transcriptValues = transcriptRange.getValues();
// Get the range of example words and tags in the tags sheet
var exampleWordsRange = tagsSheet.getRange("B2:B" + tagsSheet.getLastRow());
var tagsRange = tagsSheet.getRange("A2:A" + tagsSheet.getLastRow());
var exampleWordsValues = exampleWordsRange.getValues();
var tagsValues = tagsRange.getValues();
// Create a map of example words to tags
var tagsMap = {};
for (var i = 0; i < exampleWordsValues.length; i++) {
var word = exampleWordsValues[i][0].toLowerCase();
var tag = tagsValues[i][0];
tagsMap[word] = tag;
}
// Initialize an array to store the tags for each transcript entry
var transcriptTags = [];
// Loop through each transcript entry
for (var i = 0; i < transcriptValues.length; i++) {
var text = transcriptValues[i][0];
var uniqueTags = [];
if (typeof text === 'string') {
// Use regular expression to extract words and handle punctuation
var words = text.match(/\b\w+['-]?\w*|\w+['-]?\w*\b/g);
// Check each word in the transcript entry against the tags map
if (words) {
for (var j = 0; j < words.length; j++) {
var word = words[j].toLowerCase().replace(/[.,!?;:()]/g, '');
var singularWord = word.endsWith('s') ? word.slice(0, -1) : word;
if (tagsMap.hasOwnProperty(word) && !uniqueTags.includes(tagsMap[word])) {
uniqueTags.push(tagsMap[word]);
} else if (tagsMap.hasOwnProperty(singularWord) && !uniqueTags.includes(tagsMap[singularWord])) {
uniqueTags.push(tagsMap[singularWord]);
}
}
}
}
// Add the determined tags to the array
transcriptTags.push([uniqueTags.join(";")]);
}
// Get the range of the tags column in the transcript sheet, starting from E2
var tagsColumn = transcriptSheet.getRange("E2:E" + (transcriptTags.length + 1));
// Set the values in the tags column to the determined tags
tagsColumn.setValues(transcriptTags);
}

Subscribe to comments: For this article | For all articles
Leave a Reply