By Corinne Chatnik and James Gaskell
Introduction
Digitization of cultural heritage materials in academic libraries is important for increasing the access and visibility of its holdings, providing content and data for digital scholarship, and allowing for increased accessibility of library materials. The output of this work is valuable to researchers and the Union College community, but it is also resource intensive and time-consuming. Union College Schaffer Library experiences these challenges particularly in the context of a predominantly student-staffed digitization operation.
The digitization program at Schaffer Library relies heavily on undergraduate student workers for the capture and quality control of the digital archival records. Union College is a solely undergraduate institution and the student work hours are limited to a few hours per week with varying schedules. Most undergraduates do not have prior experience with digitization and this is a new skill set for them that requires significant training. Successful training is made difficult due to the differences in the students schedules resulting in ad hoc training sessions and sometimes days between each work shift. There is also currently no staff member or librarian dedicated to the digitization lab full time; instead, supervision of students is divided between two librarians and one staff member.
With these limitations, it was recognized that more QC can’t be done but better QC can be achieved with automation. To do this, a collaborative project was initiated between the library’s Digital Collections and Preservation Librarian, Corinne Chatnik and a senior Union College Computer Science student, James Gaskell, who was initially hired and trained to do digitization. Together they planned and developed a quality control automation application. By leveraging Python programming and the Openpyxl library, the aim was to create a tool that could systematically verify metadata consistency and file management accuracy, thereby reducing the burden on manual review processes.
This approach was informed by direct experience with the digitization workflow and an understanding of common error patterns observed over time. The resulting application needed to be both sophisticated enough to catch subtle errors and user-friendly enough to be integrated into the existing workflow, particularly considering the varying technical expertise of student workers and staff.
This paper details the journey in developing this quality control automation solution, from initial concept to implementation. It will explore how the application addresses specific challenges in the digitization workflow and the technical decisions that shaped its development. Moreover, how this project served as an experiential learning opportunity, allowing James to apply classroom knowledge to solve real-world problems while contributing to the library’s digital initiatives.
Background
In 1795, Union College was established in upstate New York as the first non-denominational institution (not affiliated with a religious organization) of higher education in the United States. Today, it is a small undergraduate, liberal arts college committed to the integration of arts and humanities with science and engineering. Union College has a long history evidenced by the collections held by the Schaffer Library’s Special Collections and Archives. These collections are not only valuable to the institution but to a broader audience. With the significance of these collections, Schaffer Library hopes to increase digitization. Automating the quality control aspects of the workflow will help this initiative.
The digitization program at Union College has a relatively short history. Schaffer Library began digitizing small amounts of material from Special Collections in 2008. Then a loss of funding resulted in a pause in digitization efforts. In 2014, library leadership recognized the importance of digitization for access and accessibility and plans were made to restart the program. A staff member with digital projects experience was hired to take over the digitization lab and complete all aspects of the digitization workflow. These projects were small boutique collections chosen based on faculty and librarian interests. The resources allocated for these projects were not conducive to scaling up to larger initiatives.
Taking advantage of various staff turnover, new positions were created with assembling a digital projects team in mind. An increase in technical skills and positions with digital projects responsibilities allowed Schaffer Library to start scaling up digitization efforts. This also came with the recognition that undergraduate student workers were a valuable resource in document imaging, so the library enacted plans to hire and train students for that purpose. WIth increased production, it identified some areas of the workflow that acted as bottlenecks to the process, quality control checks being one major area. This analysis served to signal to Schaffer the need to improve quality control for increased efficiency and realized for some aspects, automation was possible.
Methodology
Quality Control workflow prior to automation
To consider automating the process, the digitization and quality control workflow was scrutinized. For the existing workflow, the digital projects librarian creates a metadata spreadsheet prior to pulling material for digitization. They then share the spreadsheet and pull boxes or folders of the corresponding records for the students to scan. While scanning, students read the metadata and make sure it matches the physical document. They should be verifying metadata fields like title, date, and creator match what they can see on the record. After they scan, they enter the extent, or number of pages of the document into the metadata spreadsheet. Once they have completed the scanning portion they move on to quality control.
For quality control, students should check work scanned by other students. This is so that they are not desensitized to the records they’ve already gone through. Additionally, if they required more training, their errors would be caught by someone else. When students begin the quality check, they navigate to the folder of completed scans. Each item has its own directory with the scans inside. So, going item by item in the metadata, they search for the item identifier and match it to a directory. They then open the folder to visually confirm that filenames in the parent directory match and all those filenames match the identifier in the spreadsheet. If there is anything that doesn’t match, they enter “Fail” in the QC Pass/Fail column which is the last column of the spreadsheet.
Next, if the item is a multipage record, they make sure page count matches the Extent column in the spreadsheet. If the values are not the same, they fail the check. If the document is less than 20 pages, they should look at each page individually. For expediency, if the document is longer than 20 pages, the students are to skim through the images, taking a random sample, approximately 10% of the total page count and verifying the quality of the images. When checking the images they evaluate the color balance, making sure the color looks approximately correct, not too blue or red, for example. Next they observe the orientation, checking if images are mistakenly disorientated. Overall, students are encouraged to use their best judgment.
The role of Quality Control in the digitization workflow
Quality control is vital, not just for accuracy for descriptive metadata it also ensures that administrative and technical metadata are accurate and complete, making materials findable and usable within digital collections. Additionally, poor quality digitization (like blurry text, missing pages, or incorrect color reproduction) can lead to misinterpretation or make materials unusable for research [1].
Not only should digitization result in a high quality product, the data is vital to the success of the digital repository workflow. If some aspects of the metadata are not exact, it will cause the repository part of the workflow to fail. Each batch of digitized records is over one hundred images and filenames. It’s easy to skim hundreds of filenames and miss a transposed identifier or misread a date. Especially when the workflow for student workers ends with quality control and they don’t work with the files in the digital collections repository. In many cases, the data errors were not found until the upload process. Several data points can act as a point of failure during upload, for instance, if the system is unable to find a file through the filepath, no digital object will display with the metadata. If the digital object file is too large, that will also cause display issues. Another is if the date is not in ISO format, the date facet will not work. The upload will also fail if required fields are not filled. These quality control failures will disrupt the workflow and if not caught before upload, undoing the work to repair it is time consuming and resource intensive.
Union College’s digital repository is Archipelago, a flexible, customizable, open source repository created by Metropolitan New York Library Council’s Digital Services Team. The software is built on Drupal with custom modules and indexed with Solr [2]. For the upload process, the digital files are transferred via FTP from a OneDrive directory to an Amazon S3 server and the metadata spreadsheet is uploaded through the Archipelago interface. The metadata contains the file’s full url path in addition to the other fields. The metadata is processed through a PHP template engine called Twig and calls the files from the S3 path for display [3]. If the file path is not an exact match, the upload fails. Additionally, there are other variables that, if not correct, will cause the upload or interface functionality to fail.
Part of the responsibilities of the Digital Collections Librarian is uploading the metadata and scans to the digital repository. In doing so, Corinne was encountering these errors during the upload process. After getting several completed batches of digitized records but still encountering some of the same issues, she wrote small scripts to check on those elements. This ad hoc process was sufficient until the Digital Projects team began ramping up digitization. It was then clear that these errors needed to be caught earlier and data checking could be integrated into the workflow.
James was part of a cohort of students hired for digitization. With his background in computer science, he pretty quickly realized that some aspects of the workflow could be automated. Especially in regards to saving time by eliminating some manual processes. With his hands-on experience implementing the workflow, he understood the goal of the application and how it could fit into the workflow going forward. Together, they analyzed the workflow. Corinne’s perspective was from the digital collections repository and what was going wrong during upload and indexing. James’s perspective was rooted in the actual digitization process. Through this process, the following variables were identified that could be systematically evaluated both within the spreadsheet and by comparing the scans to the metadata.
The biggest error encountered during the upload was mismatched or missing filenames. As a result, one of the first checks is determining if the filenames listed in the metadata, have a corresponding file in the scans directory. Building on that, for Archipelago, the full file path is required for upload and rendering. Therefore, in addition to the filename, the metadata also has to have the full Amazon Web Services filepath. Both the filename to scan verification and the AWS path check are pattern matching strings which is something scripting is really useful for automating. Similarly, the number of pages in the extent field could be verified automatically. The input guidelines for that field are integer plus format; this means “x pages” with the rich text clarifying the integer represents a page count metric . So by identifying the extent field, if the “pages” string or other format string is stripped out, the integer can be isolated. Then by locating the images, it can determine the actual number of pages that belong to each object. At that point it’s just a matter of comparing two integers.

Figure 1. An excerpt of a metadata spreadsheet in Excel showing the identifier field, the AWS path to the image, and the extent field with the page numbers.
Schaffer Library’s metadata schema has required fields. So for those fields like label, type, ismemberof, and rights_statements it was just a matter of confirming a multi-character string was there.

Figure 2. An excerpt of a metadata spreadsheet in Excel showing the required metadata fields for upload. The ismemberof field holds the identifier of the parent object in Archipelago. The type field triggers Archipelago processing to use a mapped IIIF template. The label field is the same as the title but Archipelago uses it to name the digital object. Finally, rights_statements tells Archipelago which https://rightsstatements.org/ icon to display.
For the date_created field the QC check was a bit more complex. There is Apache Solr faceting functionality in archipelago for date faceting so the date needs to be formatted in YYYY-MM-DD (ISO 8601) format. An even more complex match is when the filename is derived from the analog version of the record’s physical location within the collection. For example, an item located in Box 2, Folder 1, will have an identifier represented as ZWU_SCA0319.B02.F01 and those values need to be accurate.
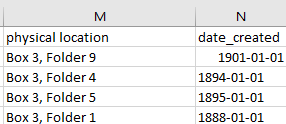
Figure 3. An excerpt of a metadata spreadsheet in Excel showing the more complex fields for the quality control check. Physical location informs the identifier and date_created needs to be in YYYY-MM-DD (ISO 8601) format for Apache solr indexing and faceting.
Finally, with hundreds of scans and different people working on different digitization workstations and software, it is possible image file settings will get changed. Archipelago doesn’t handle the display of massively large files well. This needs to be addressed prior to upload so it doesn’t overload the Archipelago system. It was determined that if the size of the image file is over 500 MB it needed to be flagged and its size reduced. Considering the metadata and image variables in this way laid the groundwork for automation.
Application Design
Technical Approach
Python was chosen as the programming language for this application because of shared knowledge, longevity, and Python’s ability to interact with Excel files, which is the format the metadata is stored in. It is also the programming language that James and Corinne have in common. This is important because when James graduates he will no longer be able to support the software. But with Corinne’s knowledge of Python, the program can be maintained and updated. Additionally, Python is the most widely taught programming language at Union College so there’s a greater chance future students can work with the application.
Python is also an attractive choice due to the vast array of packages available for data handling and I/O operations. Openpyxl is the best choice for reading and writing to Excel files. It allows for more complex formatting than most CSV handlers and it is possible to highlight and change text formatting at a cellular level [4]. This is important since some discrepancies will be more easily fixed with a manual review and these features will indicate problematic records and fields while maintaining the metadata format. The package also reads into pandas dataframes with column headings rather than Excel column references making it easier to extract and reference data. Since a user interface is provided to make the program more friendly for work study students, tkinter is valuable for providing helpful error messages, and PyQt5 to provide a rich, user-friendly experience for the main functions of the program [5].
Finally, Python supports object oriented programming. Since records in the metadata spreadsheet refer to physical holdings and digital copies of these holdings with attributes such as pagecount, permanent location and filename, it makes sense to store these records as objects. With a macro lens, sheets of a spreadsheet can be viewed as objects, and perhaps even individual spreadsheets should the scope of the project increase.
Technical Architecture
As discussed, it is imperative that the automated processes fit into the existing workflow to minimize disruption to the current digitization processes. Further, the limitations of automation are understood. Recording metadata and reviewing scanned images currently remain manual processes since the technology required to extract data or make human inferences from images is complex and inaccessible at this time. As such, James decided to split the program into three stages. All three of these functions are reliant on the same Excel spreadsheet and file system and will adopt the same object structure and add more fields at each step in the process as they become necessary.
The file structure is as follows:
- A spreadsheet contains multiple sheets. These sheets correspond to a physical box which has individualized items (the rows of the spreadsheet).
- These items represent both the physical holdings and the files in which the digital copies are stored.
- The items have attributes based on their spreadsheet data. Attributes include date created, physical location, filename, page extent etc.
Data Validation
The first function of the program is data validation which should be initiated after the metadata spreadsheet is created. At this stage the file structure is created, the spreadsheet is represented as an object with a list of files, which are also objects with attributes like page count etc. To automate work with Microsoft Excel spreadsheets, James utilized Openpyxl. Openpyxl is a Python library that can read and write to Microsoft Excel files. The program reads the spreadsheet into a dataframe using the pandas Python package. Pandas organizes each row of the excel spreadsheet into a table and has search functions that make the imported data easier to navigate [6]. The program goes through each record in the pandas dataframe and creates a file object then adds it to the spreadsheet wrapper. This allows a comparison of the physical location data entered for each object to the filename generated from that data which follows the name convention of “Box.x.Folder.y.Item.z”. This function also checks if the date is in ISO format, the international standard for representing dates, and checks the identifier and filepath columns for duplicate filenames.
Some errors and their solutions can be anticipated. Most date errors are resolved by understanding alternate date formats like Month DD, YYYY or MM/DD/YYYY. Other variables, such as naming conventions and duplicate filenames, are more complicated and will require manual intervention. Still, this will reduce the time needed to resolve the errors should they be discovered after the physical document has been scanned.
File Location and Instant Fails
At the second step, assuming the initial discrepancies have been resolved and the scanning has been completed, the program will search for the scanned documents in OneDrive. This process is one of the most time intensive and, until now, a manual process of copying the filename from the spreadsheet into the search bar of OneDrive. At this stage, the application checks if the file exists, determines if the size of the file is below the 300mb threshold, and if the number of pages in the file matches the extent recorded in the metadata spreadsheet. This all occurs with a single click of a button. Using the glob Python package it recursively scans a user-selected folder with a much lower margin for error and much more quickly than the current manual method. Glob takes a root directory, provided by the user through the UI, and the list of file objects from the sheet, then checks every subfolder for the file path [7]. If there are missing files, the item automatically fails the check, and a useful message is output to the spreadsheet to indicate to the user that the file could not be located.
Image Quality Checks
After searching the file structure, the scanned document’s existence is confirmed or denied. If the file does exist, and thus can continue with the QC process, it also stores a file path that can be used to open the document from within the Python application. This is much quicker than manually searching the file structure, opening the file and following the steps of the QC Guidelines. Further, since the Python program has the ability to edit the metadata spreadsheet the application can mark the record as pass or fail, limiting human interactions with the metadata record which could introduce sources of error.
User Interface Considerations and Design principles
Command line scripting can seem overwhelming to those unfamiliar, and since this application needs to be integrated into a workflow primarily done by students, an interface was necessary. James designed a graphical user interface (GUI) to make the program more usable to everyone who is part of the digitization workflow. The Windows operating system is the primary OS for Schaffer Library student computers and digitization workstations. With Windows as an application parameter, tkinter will suffice for less detailed error messages. tkinter is a standard Python interface package for Tk GUI. It is used to create simple interactive applications for Python scripts [8]. The application also utilizes PyQt5, because it is more feature rich than Tk and the drag and drop methods for designing the application in QtDesigner are more accessible to less experienced UI designers [9]. PyQt5 also benefits from CSS support allowing for aesthetic improvements and hover-over button information which should make the program even more user friendly. Some effort has been made in this regard but it is still in its infancy, should there be a need for further aesthetic improvements to the GUI, this could be done without much complexity by adding to, or altering, the current CSS.
The GUI is important for making sure the application is useful to as many people as possible and that it stays a sustainable part of the workflow even if the developers move on. Where possible the program can utilize existing Python GUI architectures such as EasyGUI for basic tasks like file selection. With a GUI, the program has both a front-end and back-end that are, for the most part, independent of one another. As such, the singleton design pattern can be adopted to link the two, allowing for future independent changes to be made to both whilst ensuring a clean project structure for future development. The singleton, which is considered the main program, is a class guaranteed to only have one instance [10] and bridges the front-end and back-end operations. More importantly, there is a plan to implement new features and that can be done easily in this framework. When those features are written on the backend, modifying the interface is adding another button to the GUI to trigger the new behavior. For example; initially it may appear as though a spreadsheet can also be a singleton with just one instance of the class, however, this design pattern guarantees expandability by allowing the tracking of multiple spreadsheets should the need arise due to changes in the workflow or increased system requirements. A change like this would require a change to the front end to allow the user to select a spreadsheet from a given list.
Integration with the current workflow
Implementing this application with the existing workflow will not create too large of a shift. Though the data is read into the program and transformed for analysis, the program will convert the objects back into dataframes and output them back to the original spreadsheets. To the user, the spreadsheet seemingly remains unchanged after each check except for color coded flags to indicate errors. Automatic failures due to extent and file size issues alongside files that cannot be located in OneDrive will automatically be indicated in the pass/fail column and a useful error message produced. It is important to maintain the original data format and retain Excel as the medium for data review. Though a lot of tasks are automated, some variables require human intervention and this method changes that portion of the workflow very little. For the work-study students this application requires very little additional training to adapt to the new process. Moreover, the user interface should be intuitive to use and the overall design is meant to reduce each process to a few mouse clicks.
Implementation
The first step in creating the program is implementing the Openpyxl read/write functionality. At both the read and write stages the file data is ported into rows of a pandas dataframe, so the object file structure described acts as an intermediary medium for processing. Openpyxl handily uses the column headings for dataframe fields. Furthermore, iteration over the rows of the dataframe discards unnecessary data and initializes abstract file objects for each row. At this stage the file objects have attributes; permanent location, filename, extent and date created, and the list of files is stored in the parent spreadsheet. This is also an object with a “sheetName” class variable to identify it in the full spreadsheet. Importantly, each file also has an “errors” and a “failures” dictionary which can be used at each step to identify issues with the record. The dictionaries contain date, filename, duplicate filename, extent, filesize and existence flags which are all instantiated to False. Updating these boolean flags indicates if an error has been found for the respective file for output to the spreadsheet. In order to translate these objects back into the data frame for writing, the filename can be considered a de-facto unique identifier.
Duplicates
Duplicate checks are the least complex but require the most human intervention to remediate. The duplicate check is implemented with a linear search. Since the number of records on each sheet is never more than 200 this method suffices but could be scaled up if the metadata sets grow or for other libraries with higher digitization output. If the function finds a duplicate filename within the list of files, the ‘DupFilename’ flag is set to True – this is done for each instance of the duplicate.
"""Checks for duplicate filenames in the list of files
Args:
sheet: excel sheet containing a list of files
"""
def check_duplicate_filenames(sheet):
for file in sheet.fileList:
for comp_file in sheet.fileList:
if file.fileName == comp_file.fileName and file != comp_file:
file.errors['DupFilename'] = True
sheet.errors += 1
Figure 4. Checking the spreadsheet for duplicate values in the filenames field.
Physical Location
Each filename may not match its physical location. This is the first major check conducted, primarily because at this stage, it is the cause of most failures. The file location format in the spreadsheet is plaintext which is traditionally difficult to work with. Location descriptors in the filename, such as “Box” and “Folder” are reduced to “B” and “F” respectively. Increasing the complexity further, the location names also have item descriptors “Bulletin”, “Sheet” and “Item” – when translating to filenames, bulletins are reduced to “Bull”, sheets remain “Sheet” and the item identifier is dropped entirely. Since the aim is to maintain the existing workflow, the file naming conventions cannot change and these identifiers must be accounted for when matching locations with filenames. To effectively compare the location with the filename there are two options: one is to attempt to recover the filename from the location or vice versa. The former was chosen.
The first part of the filename is computed as the most common prefix by taking the first string appearing before the period in the list of filenames in the metadata spreadsheet. Importantly, this ensures the program can be used with different collections. The William Stanley Jr. collection which was used to inform the development of this program has the prefix “ZWU_SCA0319”. Files that do not conform to this are marked as errors for manual review accounting for a rare edge case in which an item from a different collection may be grouped incorrectly. The algorithm below is an averager, using a dictionary to track the number of examples of each prefix and returning the mode prefix to the filename predictor subroutine.
"""Determines the correct prefix for the files by finding the most common from the file
Means the script can be used for different collections
Args:
List[ScanFile]: list of file objects from excel sheet
Returns:
String: most likely prefix given all the entries
"""
def find_file_prefix(fileList):
filenameDict = {} #Dictionary containing the prefixes in the document and their count
for file in fileList:
try: #ignore any funky filenames
prefix = file.fileName.split('.')[0]
if filenameDict.get(prefix) == None:
filenameDict[prefix] = 1
else:
filenameDict[prefix] += 1
return(max(filenameDict)) #Returns the most common prefix - assumes this is correct
except:
pass
Figure 5. Checking the filenames for the collection prefix.
Splitting the physical location field by commas, the program is able to discard filler words “Box” and “Folder” from physical locations thus converting the data into more usable, numeric form. The “Bulletin” and “Sheet” identifiers are retained by checking the full string for these substrings meaning item type identifiers are propagated through to the final filename prediction in format “Bxx.Fxx.Bullxx”
"""Checks that the filename matches the permanent location for each item in a given sheet
Reconstructs an expected filename from the location then compares it to what is recorded
Follows a precise naming convention. Box xx, Folder xx, Item type xx
Records the error in the file's errors dictionary if there is a discrepancy
Args:
sheet: excel sheet containing a list of files
"""
def check_location_filename(sheet):
prefix = find_file_prefix(sheet.fileList)
for file in sheet.fileList:
pred_filename = prefix
if not file.location == None:
Location = list(filter(None, file.location.translate(str.maketrans('', '', string.punctuation)).split(" ")))
#ignore any funky filenames
try:
file.fileName = file.fileName.replace(" ", "") #Removes any spaces that shouldn't be in the filename
except:
pass
if "Box" in Location:
pred_filename += ".B" + Location[1].zfill(2)
if "Folder" in Location:
pred_filename += ".F" + Location[3].zfill(2)
elif len(Location) == 4:
pred_filename += "." + Location[3].zfill(2) #Accounts for items not in folders
if "Bulletin" in Location: #Assumes .Bull. for bulletins
pred_filename += ".Bull." + Location[5].zfill(2)
elif "Sheet" in Location: #Assumes .Sheet. for sheets
pred_filename += ".Sheet." + Location[5].zfill(2)
elif len(Location) >= 6: #Assumes no identifier for Items
pred_filename += "." + Location[5].zfill(2)
if pred_filename != file.fileName:
file.errors['Filename'] = True
sheet.errors += 1
Figure 6. Checks that the filename assigned matches its permanent location value for each item.
After comparing the prediction to the filename recorded in the file object, the program can deduce if there is a mistake and, if so, flips the boolean flag for “Filename” in the error dictionary to True.
Date Format
The date formatter is designed to systematically attempt to convert from multiple expected date formats into ISO. The most common issues with formatting are years without months and days, and the use of commas rather than periods or backslashes as separators. Of course, some dates are already in the correct format so this is also accounted for.
"""Checks the date format and attempts to format the date if in unexpected form
Args:
sheet: excel sheet containing a list of files
Returns:
Boolean: True to verify the process was executed successfully
"""
def check_date_format(sheet):
spell = Speller(lang="en")
for file in sheet.fileList:
success = False
if file.date != None:
if not type(file.date) is datetime.datetime:
try:
date = (parse(file.date.rstrip()))
success = True
except:
if type(file.date) is str and not success:
success, date = attempt_format((file.date))
elif type(file.date) is int and not success:
success, date = year_to_date((file.date))
if not success: #Last ditch effort, successful if incorrect spelling in date
try:
date = (parse(spell(file.date.rstrip())))
date = date.strftime("%Y-%m-%d")
file.date = date
success = True
except:
file.errors['Date'] = True
sheet.errors += 1
else:
file.date = date.strftime("%Y-%m-%d")
else:
file.date = file.date.strftime("%Y-%m-%d")
return True
Figure 7. Checks the date format and attempts to format the date if in unexpected form.
The main formatter method uses helper functions such as the one shown below with a success flag indicating whether the returned date could be successfully converted. Since the methods use type casting and type specific operations, it is important to encapsulate them within exception handlers (in Python try, except), without this the program would crash due to the variability of formats. Should all the methods fail “Date” is added to the errors list so the record can be manually reviewed. Interestingly, a common date issue was the misspelling of written dates, again highlighting the abundance of human error. This was tackled by using the autocorrect Speller package after which we are able to convert into ISO using regular type casting.
"""Converts dates from year to year and day. E.g. 1980 to 1980-01-01
Args:
date: date in year form
Returns:
[Boolean, date]: success flag and date in ISO format
"""
def year_to_date(date):
try:
date_new = datetime.datetime(date, 1, 1)
return [True, date_new]
except:
return [False, date]
Figure 8. Converts dates written as a date range to ISO format.
File Existance, Size and Extent
The largest source of failure came from missing files within the OneDrive file structure. Since individual scans are saved as jpeg images and multi-page scans are saved as PDFs the program searches for both cases using rglob, a recursive search package that can find files within a larger file structure. The parent directory, selected by the user, is stored in the program singleton meaning the file structure can be searched by glob and the full file paths can be stored into the file object. The method uses easyGUI which in turn uses Windows File Explorer to again ensure a familiar user interface for the quality control student.
"""Opens an EasyGUI window to allow the user to select the file they want to parse
Returns:
String: filepath of the selected file
"""
def get_file():
path = easygui.diropenbox()
return path
def find_file(folder):
for path in Path(folder).rglob('*.pyc'):
print(path.name)
return True
Figure 9. Opens an EasyGUI window to allow the user to select the file they want to parse.
Since the file structure is complicated and some files are at greater depths within subfolders, there is a moderate time requirement for this step. Helpful print messages display, showing the process is in fact still running for the approximate 1 minute it takes to look for every file. If the file is found, the “exists” flag is set to true. While the program verifies the existence of each file, it also checks the file size. The size of the file in megabytes, is read into the file_size variable within the file object. If the extent falls above the preset size threshold of 300MB, the too_large variable is set to true, otherwise it is set to false.
"""Conducts the preliminary QC checks
Checks if the file exists in the file structure, if the extent is correct
and if the file size is less than 300mb
Adds the respective failures to the count and to the file's failure dictionary
Args:
sheet: excel sheet containing a list of files
parent_directory: the OneDrive parent folder to search through
"""
def check_files(sheet, parent_directory):
failures = 0
for file in sheet.fileList:
try:
for path in Path(parent_directory).rglob(file.fileName + '.[pdf jpg]*'):
file.filePath = (parent_directory + "\\" + file.fileName + ".pdf") # Can I do this using path above?
# We can't assume this will be a pdf as single pages stored as jpg
file.exists = True
# We perhaps can't assume this is correct since some don't have parent folders
if file.extent == len(os.listdir(path.parent.absolute())) - 1 or file.extent == None:
file.failures['Extent'] = False
else:
file.failures['Extent'] = True
failures += 1
if not (os.path.getsize(file.filePath) >> 20) < 300:
file.failures['Filesize'] = True
failures += 1
except:
pass
if not file.exists:
file.failures['Existence'] = True
failures += 1
sheet.failures = failures # Add number of failures to the sheet object
Figure 10. Checks if the file listed exists and the file size.
Checking page count proved to be more complex than initially anticipated. Since the files are hosted using OneDrive, to use the built-in page enumeration tools provided in Python’s PDF handling packages, the PDFs would have to be downloaded. This is not possible given the size and number of files. Fortunately the scanning software used at Union College maintains a copy of each page in jpeg form inside each subfolder. Utilizing this structure, the program is able to count the number of jpegs and compare this with the recorded value, but this process is highly tailored to the digitization process at the college and may need adapting elsewhere.
For every type of failure a helpful error message is added to the data frame along with a “fail” in the necessary column. The program tracks the failure rates for each of the three categories which can be used to evaluate the accuracy of different parts of the digitization process.
Indicating Errors
As described, there are many errors that are too complex to be remedied by the program and must be highlighted for human review. With Openpyxl we can do this literally by selecting a color, highlighting the problematic row, and overwriting the metadata spreadsheet. The program currently uses orange (Hex #EFBE7D) to indicate file naming issues, blue (Hex #8BD3E6) to indicate duplicates, and yellow (Hex #E9EC6B) to indicate date errors. These color codes are assigned but a new method of selecting colors is also being considered.
The program will likely be run more than once at each stage, allowing for errors to be manually rectified and the application run again. As a result, the first step is resetting the color of rows within the spreadsheet. The automation program is only one source of highlighting since the Digital Projects and Metadata Librarian also use various colors to convey information about records. So those messages aren’t affected; the spreadsheet only resets the colors with the precise hex values used by the program. The function that does this is shown below.
"""Removes specific highlight colors from the spreadsheet to allow the program to be run
continually after each error is rectified
Args:
ExcelFile: Excel file to remove colors on - contains the error colors dictionary
wb: Work book opened with Openpyxl
colors_to_remove: allows specification of individual colors so running spreadsheetChecks alone
(for example) doesn't remove failure highlighting
"""
def reset_colors(ExcelFile, wb, colors_to_remove):
fill_reset = openpyxl.styles.PatternFill(fill_type=None)
for sheet in ExcelFile.sheetList:
ws = wb[sheet.sheetName]
for row in ws.iter_rows():
for cell in row:
if cell.fill.start_color.index in colors_to_remove.values():
cell.fill = fill_reset
"""Highlights rows with errors and/or failures with their corresponding hex color
Since the function pulls from both the error dictionary and the failure dictionary
it can be used in both parts of the program
Args:
ExcelFile: Contains the failure/error information and the highlighting colors
Returns:
Boolean: True if the save is successful, False if not
"""
def highlight_errors(ExcelFile):
xl_file = pd.ExcelFile(ExcelFile.filePath)
wb = openpyxl.load_workbook(xl_file)
reset_colors(ExcelFile, wb, ExcelFile.errorColors)
for sheet in ExcelFile.sheetList:
dt = pd.read_excel(xl_file, sheet.sheetName)
ws = wb[sheet.sheetName]
errors = sheet.getSheetErrorDict()
errors.update(sheet.getSheetFailureDict())
colors = ExcelFile.errorColors
colors.update (ExcelFile.failColors)
for file in errors:
error_color = colors[errors[file]]
if error_color != None:
fill = openpyxl.styles.PatternFill(start_color=error_color, end_color=error_color, fill_type="solid")
for index, row in dt.iterrows():
try:
if file == dt['Filename'][index]:
for y in range(1, ws.max_column+1):
ws.cell(row=index+2, column=y).fill = fill
except:
pass
try:
wb.save(ExcelFile.filePath)
wb.close()
xl_file.close()
return True
except:
wb.close()
xl_file.close()
return False
Figure 11. Highlights rows with errors and/or failures with their corresponding hex color.
Since the failure and error dictionaries share the same keys as the color dictionaries, these can be referenced alongside one another to determine which color to highlight which record. The above function loops over each error and failure, selects the color, locates it in the workbook and fills the corresponding row. Again, exception handling is of paramount importance – if the Excel file is currently open Openpyxl does not have the permissions required to edit it. In cases throughout the program, including this, tkinter windows are used to inform the user of errors since Python’s error outputs are difficult to read for the untrained eye.
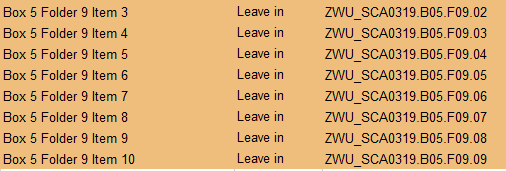
Figure 12. An unfortunate shift causing mismatched filenames has been caught and highlighted by the QC program.
In some cases no user input is required – this is mainly the case for automatically fixed dates, which are not indicated with color on the spreadsheet, and automatic fails. To ensure consistency with the current workflow the program uses the “QC Results”, “QC Initials” and “QC Comments” columns to indicate records that have failed with descriptive output messages and an AUTO flag to indicate this was an automated fail. Similar output messages are used when the file size is too large or the pagecount is incorrect. The whole record for auto fails is highlighted red for immediate visibility after opening the spreadsheet.
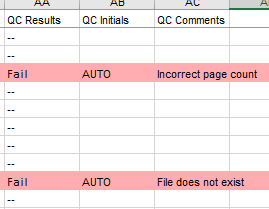
Figure 13. Two files with auto fails. One because the file cannot be located, the other for incorrect page count.
Results and Evaluation
In testing the Quality Control Automation program’s first step, the application was run on a spreadsheet where the items had already been scanned. This immediately highlighted an issue where filenames were duplicated for different records. While this led to additional labor requirements to remediate the scanned batch, it may not have been caught in the upload because technically the filename was correct and had a scanned image but it would have been inaccurate for users of the repository. Further, an unfortunate shift in cells, not obvious to the human eye, meant item n was saved with the filename for item n+1 which would cause issues when uploading items to Archipelago. If the data type was inaccurate, like a date format in a field expecting a string, the upload would have failed. If the data type was acceptable, the upload would have carried on and the metadata would display in the wrong field or not at all, leading to inaccuracies and poor presentation.
Dates can be tricky in Excel, even if entered correctly, if the format settings are off, Excel will automatically change the date pattern. Also if many people have different methods of recording the date and that can be an issue if metadata goes through many hands. The application was able to resolve 100% of dates that were in the incorrect format. While developing the program, James discovered that dates were usually in a predictable and readable format, hence the success rate, but not one that is useful for Archipelago’s SOLR index. This application can reformat the dates to the ISO 8601 standard automatically, so this feature reduces manual labor requirement for post processing.
The second stage of the automation workflow highlighted a major issue. In the spreadsheet, 32% of items were marked as scanned but could not be located in the OneDrive folder. Evidently something went wrong in the digitization workflow and could mean scans are stored incorrectly in a different directory and as a result scanned multiple times unnecessarily. Even though the solution to this issue requires manual intervention, this report still represents a massive time saving effort. Prior to this, students were taking approximately 2 minutes to attempt to find a file, enter a fail, and a note in the spreadsheet for a supervising librarian to attempt the same check for 32% of the files. In the test file this equates to 131 failures, saving time and providing invaluable insight into how the QC process can be improved outside of this automation task.
The program is able to identify files that are too large to be uploaded during this step. Again, an error that requires manual intervention once discovered but eliminates the frustration of finding this out during the upload process. It also detects discrepancies in the spreadsheet’s Extent column versus the scan’s actual number of pages. In one recorded case, this zeroed in on an item where a page had not uploaded correctly so the item needed rescanning. It may seem superfluous, but when the record is a PDF and remembering to check the number of pages while a document is open amongst the other checks, that item can fall by the wayside.
| Box | Failure Rate |
| 3 & 4 | 3.8% |
| 5 | 8.3% |
| 6 | 6.3% |
| 7 | 2.8% |
The failure rate for the second step on the test data is 36.84%. This accounts for approximately 144 automatic fails and suggests there is a problem somewhere else in the workflow. The majority of these failures are due to missing files, but a handful are due to oversized files and incorrect page counts.
Conclusion
The collaboration between the Digital Collections and Preservation Librarian and Computer Science major resulted in an application and outcomes that exceeded expectations. Not only was a solid product developed to improve and expedite parts of the digitization workflow, but the process was a valuable experiential learning opportunity for the computer science student. The librarian brought the high level workflow needs and analysis and experience with the post digitization workflow issues, while the student provided more sophisticated programming skills and hands on digitization experience. Through analysis the amount of human error in manual data entry is evident. Of course, many aspects are better handled by people and it is a risk removing the human aspect of libraries by automating everything, but using it as a tool to check over manual work is highly valuable. It was noted that it is much easier to write software to do a job after having been trained on the manual workflow. Often, computer programmers do not have extensive knowledge of the system requirements and therefore require a consultancy period. This method of development is an interesting model and can be considered in university libraries with CS students. This integration of the programmer into the original workflow highlighted the importance of fitting any new tool into the existing workflow and not trying to overhaul the entire process.
This application is able to find things that are invisible to the human eye, and provide helpful statistics such as the 2-8% failure rate for filenames and duplicates and the 36% upload failure. It helps identify where errors are created with statistics to support it. The process ensures consistency and creates a common standard for Quality Control for every collection that passes through it. Without, one wrong character could grind the process to a halt.
The implementation of this application leaves room for further technological developments. Other areas of quality control are being scrutinized for automation. This team is especially interested in some of the visual aspects of the checks like color balance, skewed images, and even cropping of images. The application itself is relatively new to the workflow but over time, Schaffer Library hopes to determine the real time cost savings in producing a system like this. It’s important to determine if the time taken to build the program was worth the quality control hours saved before more resources are put into expanding the application.
References
[1] Federal Agencies Digital Initiatives. 2023 May. Technical Guidelines for Digitizing Cultural Heritage Materials: Third Edition. U.S. National, Archives and Records Administration. https://www.digitizationguidelines.gov
[10] Gamma E, Helm R. 1994. Design patterns: Elements of reusable object-oriented software. 40th printed ed. Boston: Addison-Wesley Professional.
[4][6] Gazoni, E, Clark, C. 2024. openpyxl – A Python library to read/write Excel 2010 xlsx/xlsm files; [accessed 2025 Jan 9]. Available from: https://openpyxl.readthedocs.io/en/stable/.
[7] Python Software Foundation. 2025. glob – Unix style pathname pattern expansion; [accessed 2025 Jan 9] Available from: https://docs.Python.org/3/library/glob.html.
[5][8] Python Software Foundation. 2025. Graphical User Interfaces with Tk; [accessed 2025 Jan 9] Available from: https://docs.Python.org/3/library/tk.html.
[2] Pino, D. 2024. Archipelago Commons Intro. [accessed 2025 Jan 9] Available from: https://docs.archipelago.nyc/1.4.0/.
[9] The Qt Company. 2023. PyQt5 Reference Guide; [accessed 2025 Jan 9] Available from: https://www.riverbankcomputing.com/static/Docs/PyQt5/introduction.html.
[3] Twig Team. 2025. Twig | The flexible, fast, and secure template engine for PHP; [accessed 2025 Jan 9] Available from: https://twig.symfony.com/.
Notes
The working code referenced in this article is available at: https://github.com/schaffer-library/QualityControlAutomation
About the authors
Corinne Chatnik is the Digital Collections and Preservation Librarian at Union College in Schenectady, NY. She earned her MLIS from the University of Alabama. She was previously a professional archivist specializing in digital archiving at the New York State Archives.
Author email: chatnikc@union.edu
Author URL: https://orcid.org/0009-0004-7229-5431
James Gaskell is a Senior at Union College, majoring in Computer Science and minoring in Electrical Engineering. His main areas of study are evolutionary algorithms and software verification. He is also currently a work-study student at Union College’s Schaffer Library.
Author email: gaskellj@union.edu
Author URL: https://orcid.org/0009-0002-9361-6172

Subscribe to comments: For this article | For all articles
Leave a Reply