By Haining Wang, Joel Lee, John A. Walsh, Julia Flanders, and Benjamin Charles Germain Lee
Background
The Digital Humanities Quarterly journal (DHQ) was founded in 2005 by the Alliance of Digital Humanities Organizations (ADHO) and the Association for Computers and the Humanities (ACH) as an open-access journal of digital humanities, responding to a need for a journal that could represent the field of digital humanities to the wider academic public that was beginning to discover the field and take an interest in it. The first issue was published in 2007, and since its inception, the journal has published over 750 articles as of 2025. The journal is broadly scoped to cover the entire field of digital humanities, including relevant topics from closely adjacent fields. However, rather than reinforcing the boundaries between subdomains and the increasing specialization of the field, the journal has sought to make the many different areas of digital humanities discoverable and intelligible to one another and to a broad audience of engaged non-specialists, including both experts and novices. As an open-access journal that is often the first point of reference for readers, DHQ thus serves as a gateway through which multiple domains of digital humanities research activity can be discovered and brought into conversation. However, existing methods on the DHQ website, such as searching by keyword, title, author, or journal issue, did not succeed in fully opening the DHQ corpus of published articles to readers. Being able to identify relationships between articles plays an important role for readers in this cross-domain exploration, as it enables readers who find an article on a topic of interest to find their way to other articles on the same topic, without needing expert knowledge of the field and its many specializations, which are often difficult to clearly delineate. There are also different kinds of “relatedness” that may be useful: related methodology, related humanities research area, co-citation, and potentially others as well.
In 2022, DHQ formed a new data analytics working group which began tackling the question of how to provide article recommendations as part of a larger overhaul and expansion of DHQ’s technical infrastructure. This article describes the different approaches the group developed, and how they have been implemented within the journal’s publication platform, in conjunction with DHQ’s broader editorial team.
Methods
Recommendation Methods
Recommender systems are ubiquitous online, facilitating discoverability of content across platforms ranging from digital libraries to e-commerce to music platforms. In the context of academic papers, sites such as Semantic Scholar [3] and Google Scholar [4] offer “Related Papers” and “Recommended Articles” features to help researchers discover new papers of interest. We drew inspiration from this functionality and implemented a Python-based article recommendation system for DHQ’s diverse content and audience to enhance engagement and discovery. Rather than selecting just one method of generating recommendations, we opted for three distinct methods, each with its own tradeoffs. This section outlines our three approaches used to generate recommendations, and the principles followed when developing the recommendation system. These three methods are complementary, in that the articles recommended by each approach will often be different, encouraging distinct paths for the reader to explore.
Keyword-based approach (#1): DHQ has a controlled vocabulary, DHQ topic keywords[5], for the description of the area and subject of their papers. Each submission is assigned around three to six of these keywords by our editors. The DHQ topic keyword list is designed around concepts rather than specific terms, recognizing that there are often multiple terms for the same broad concept area. DHQ uses topic identifiers encompassing multiple related terms to identify broad concept areas for each article (e.g. “code_studies”, “cultural_heritage”) rather than trying to determine which more precise term might best apply in a specific case. For instance, the “code_studies” identifier encompasses closely related but not synonymous terms like “code studies”, “critical code studies”, and “software studies” for better description of the work. DHQ has 88 topic keywords as of 2024. To better reflect the evolving landscape of scholarship, the taxonomy expands as DHQ editors regularly review the keywords submitted by authors and assess whether new terms should be integrated into the DHQ-wide keywording system.
We used the heuristic that similar papers should share more keywords and, hence, retrieve for each paper the other DHQ articles that share the highest number of keywords. In cases where multiple articles have the same number of shared keywords, a random selection is made from those articles each time the recommendations are regenerated, and this random selection is shown in the interface (in the future, the full set of recommendations could be displayed). Given consistent annotation across articles, the resulting recommendations from this approach offer our readers a disciplinary view of relevant articles.
Term Frequency-Inverse Document Frequency (TF-IDF) Approach (#2): TF-IDF measures the importance of specific words in a document, adjusted for the overall frequency distribution of words. Using this method, we discover similarities between articles by focusing on words that are rare across the entire corpus but appear frequently within related articles. Specifically, we use the Best Matching 25 (BM25) algorithm, which evaluates the full text of articles—including titles, abstracts, and body texts—to compute similarity scores that reflect the frequency and importance of words across documents (Robertson and Zaragoza, 2009)[6]. Compared to a vanilla TF-IDF, BM25 adjusts for term frequency and document length, allowing it to handle the natural variation in document sizes and the informativeness of terms within DHQ. BM25 serves as a strong baseline in information retrieval across diverse domains. It achieved second place in the 2021 COLIEE legal retrieval competition (Rosa et al., 2021)[7] and performed robustly in climate-related IR tasks (Diggelmann et al., 2020)[8]. In addition, research demonstrates that combining BM25 with vector search (as we do with SPECTER2 below) significantly outperforms either approach alone (Formal et al., 2021)[9]. This makes it an ideal complement to our deep learning method.
Deep learning approach (#3): In addition to relying on taxonomy and surface-level similarity, we implemented a deep learning-based approach to capture semantic relationships between manuscripts. This approach uses the SPECTER2 model, created by the Allen Institute for Artificial Intelligence (Singh et al., 2022)[10]. SPECTER2 is a transformer-based language model specifically designed for scientific papers. Trained on a vast corpus of scientific literature, SPECTER2 learns relationships between papers by considering both the textual content and citation patterns, helping it to “understand” how articles relate to one another. The model encodes each paper’s title and abstract into a dense, fixed-length vector—essentially a numerical summary of the paper’s content and its conceptual “position” in the field. This summarizing vector allows us to compare papers by calculating the cosine similarity between their vectors, identifying those with the highest similarity as the most related. By focusing on these vectors, we can recommend articles that capture deeper thematic connections beyond just shared keywords or common phrases, providing readers with robust recommendations that reflect scholarly proximity. We generate SPECTER2 embeddings on titles and abstracts because SPECTER2 itself is optimized for titles and abstracts, rather than full papers. The pros and cons of the described approaches are listed in Table 1.
| DHQ Keyword-Based | TF-IDF-Based | Deep Learning-Based | |
|---|---|---|---|
| Rationale (“Papers are similar because they”) |
share more DHQ keywords. | share more representative words | share a similar position in a large body of scholarly works. |
| Materials | DHQ Keyword | Full text (only with reference stripped) | Title and abstract |
| Pros | High Explainability | Comprehensive coverage & high explainability | Fine-grained semantic similarity |
| Cons | Coarse granularity | Focuses on surface-level similarity | Not explainable |
When implementing the recommendation system, we kept three principles in mind:
- Transparency: DHQ’s practice of encoding articles in TEI format allows for easy extraction of relevant texts. DHQ uses a light customization of the TEI Guidelines, and our encoding practices and schema are publicly available and documented, together with all TEI-encoded articles, in DHQ’s GitHub repository, and we have committed the code and recommendations to the public domain under the CC0 1.0 Universal Public Domain Dedication, waiving copyright to ensure unrestricted use by the community. The system is fully open-sourced, with detailed documentation available to support reproduction, reflecting DHQ’s community-driven ethos. Additionally, the recommendations are refreshed bi-weekly to ensure they remain current. The code and related resources are available at https://github.com/Digital-Humanities-Quarterly/DHQ-similar-papers.
- Robustness: We wrote (and are still writing) more tests to make sure core functionality will work as intended. We also implemented a continuous integration pipeline using GitHub Actions to pull changes from the DHQ’s main GitHub repository to update the recommendations on a bi-weekly basis.
- Pedagogy: As mentioned, when implementing the system, we used no internal information, which allows anyone—especially humanists starting their first Python project, those interested in understanding how different generations of recommendation systems work, or those curious about how a deep learning model “compresses” a few hundred words into machine-understandable vectors—to easily plug and play with the system using only a few lines of code [Note]. Additionally, the code is well-annotated for pedagogical use and is compatible with the PEP8 standard and the Google Python Style Guide.
Integrating the Recommendations into the Digital Humanities Quarterly Website
The output of each recommendation system is a TSV file which lists all article IDs with metadata and ten different article IDs which represent the top ten related articles, in descending order (a sample TSV for the deep learning-based recommendations can be found here: https://github.com/Digital-Humanities-Quarterly/DHQ-similar-papers/blob/main/dhq-recs-zfill-spctr.tsv). These TSV files are moved back into the DHQ main journal repository so that they can be refreshed on a regular basis.
To display the recommendations, we chose to add a box at the bottom of articles that shows the top five recommended articles from each of the three recommendation systems. We use those same TSV files to retrieve information about each recommended article and display it inside the box. In addition, we include some explanatory text about the recommendations, and link to an explore page where readers can learn more about the methodology.

Figure 1. Top of an article with the “See Recommendations” Button on the toolbar
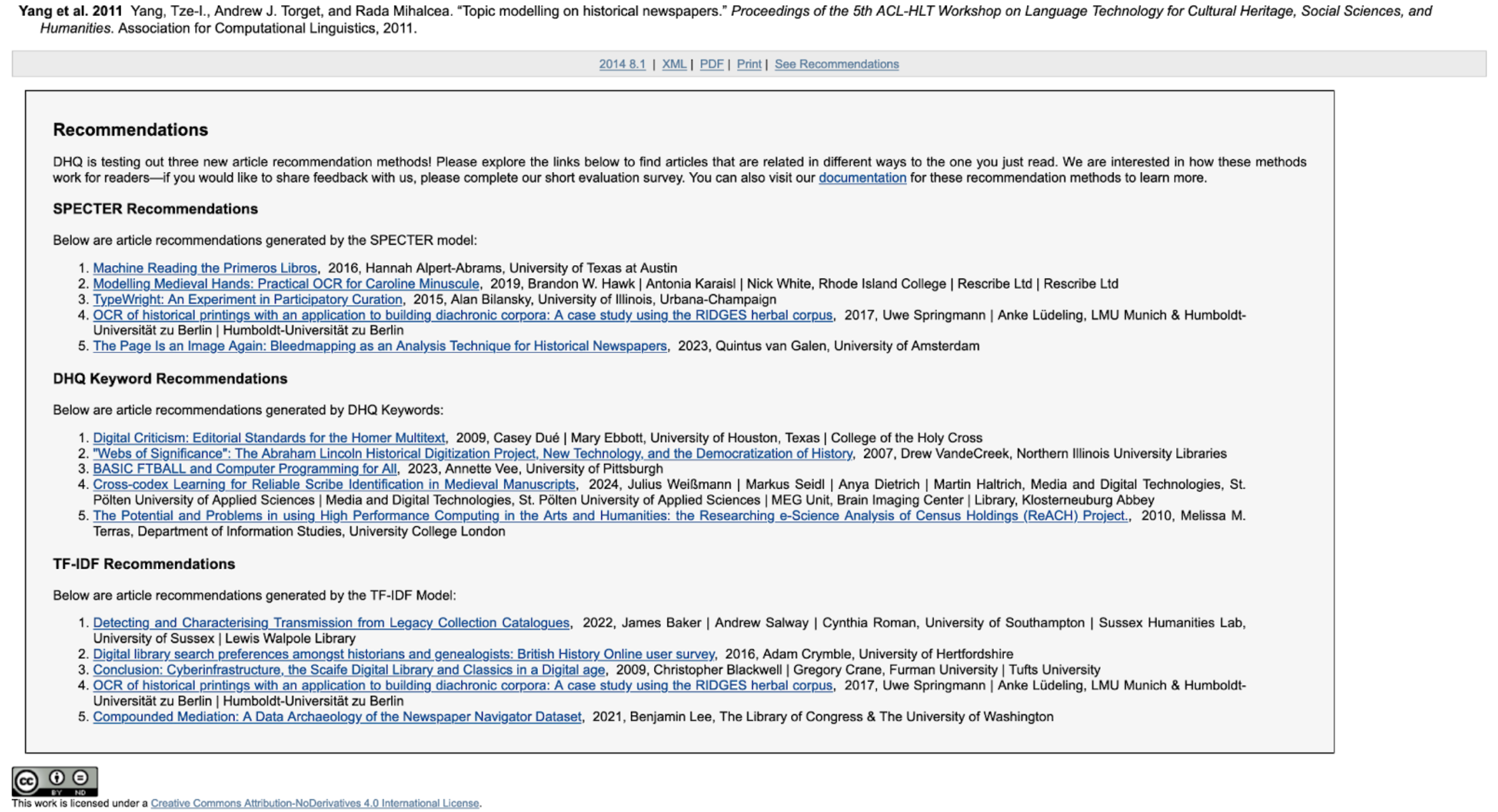
Figure 2. Recommendation box at the bottom of the article
The above figures show how this is implemented within a DHQ article: A “See Recommendations” button was placed at the top of the toolbar (Figure 1) that brings the user down to the bottom of the page with the recommendations from each of the three recommendation systems, as well as the explanatory text (Figure 2). Note that the recommendations are mostly varied from one system to another, touching on aspects of the article such as technical methodology in OCR and archival medium in historical newspapers. Recommendations in this example also range from the entirety of DHQ’s publication history. Note further that Figure 2 shows the descriptive text surrounding the recommendation methods for the end-user, which also links to a more in-depth description page for the end-user to learn more if desired.
Lastly, the development of the recommendations coincided with DHQ’s broader transition to utilizing static site generation via Apache Ant. Thus, the creation of the recommendation box and the population of recommendations for each article were integrated into the general XSLT code that generates each article page statically. This ensured that the integration of the recommendation box was a relatively seamless addition consistent with the general workflow of DHQ’s current and future update process. Now, when new articles are accepted and prepared for publication, the recommendation system can be triggered manually or rerun on a biweekly basis via Github Actions. This will generate new TSV recommendation files which include forthcoming articles, and potentially update and refresh the recommendations for existing articles. Then, the static site can be regenerated to display the recommendation box for the new articles.
Discussion & Future Work
In this article, we have detailed our efforts at Digital Humanities Quarterly to develop and deploy a paper recommender system for the over 750 papers in our corpus. We have detailed our implementation of three different and complementary recommendation methods: a keyword-based approach, a TF-IDF-based approach, and a deep learning-based approach, each of which has distinct advantages. We have also detailed the new interface for browsing the paper recommendations and contextualized it within DHQ’s new static site generation.
We have introduced this case study as a road map for other journals and libraries interested in implementing their own recommender systems. Given that Digital Humanities Quarterly operates as an open source, non-profit journal, we recognize the importance of designing systems that can be built, deployed, and maintained within shoestring budgets and limited staff time. The preprocessing scripts for the recommender system can easily be run on a laptop or the equivalent computing power. We hope that our code may be of use to other practitioners. Along these lines, if readers have questions regarding the implementation of an analogous system for another corpus, we would be more than happy to have further discussions.
We recognize the importance of evaluating the quality of the recommendations we are currently serving on the journal’s website. Accordingly, we plan to issue a survey to Digital Humanities Quarterly readers soliciting feedback surrounding these recommendations, including both Likert scale evaluations and qualitative responses. We will then incorporate the feedback and improve our recommender system. Also, we aim to continue experimenting with different approaches to generating recommendations, including adopting state-of-the-art embeddings models as they are released. Lastly, we welcome feedback from Digital Humanities Quarterly and Code4Lib readers.
Acknowledgments
We would like to thank Ash Clark in the Digital Scholarship Group at Northeastern University for eir help in reviewing and editing the XSLT code for the recommendation display on article pages. We would also like to thank former Digital Humanities Quarterly Collaborative Development Editor Hoyeol Kim for their initial work on keyword extraction and paper recommendations, as well as former Digital Humanities Quarterly General Editor Emily Edwards for their input and feedback throughout the development of the recommendations. Lastly, we would like to warmly acknowledge the work done by the Digital Humanities Quarterly Managing Editors to develop the journal’s keywording system, with particular thanks to Dave DeCamp, RB Faure, and Benjamin Grey, and also to Lindsay Day who did the initial keyword research during an internship with the Northeastern University Digital Scholarship Group.
About the Authors
Haining Wang (hw56@iu.edu) is a postdoctoral researcher at Indiana University School of Medicine and serves as a Data Analytics Editor at Digital Humanities Quarterly.
Joel Lee (joe.lee@northeastern.edu) is a data engineer in the Digital Scholarship Group at Northeastern University Library and serves as a Collaborative Development Editor at Digital Humanities Quarterly.
John A. Walsh (jawalsh@iu.edu) is the Director of the HathiTrust Research Center, an Associate Professor of Information and Library Science in the Luddy School of Informatics, Computing, and Engineering at Indiana University and serves as a General Editor of Digital Humanities Quarterly.
Julia Flanders (j.flanders@northeastern.edu) is a Professor of the Practice and the Director of the Digital Scholarship Group at Northeastern University, and serves as Editor in Chief of Digital Humanities Quarterly.
Benjamin Charles Germain Lee (bcgl@uw.edu) is an Assistant Professor in the Information School at the University of Washington and serves as a General Editor at Digital Humanities Quarterly.
Notes
[Note] For anyone who wants to make their own IR project using our approach, they can reproduce our method on the DHQ corpus (i.e., all DHQ articles publicly shared on GitHub). For those who have Python 3.10 installed (which most computers do; check by opening Terminal and typing “python -V”), they can git clone our repository (for necessary utilities), create a Python virtual environment and install necessary dependencies (for supporting libraries so we don’t need to build the wheels ourselves), and then run scripts by calling “python run_bm25_recs.py”. We have detailed instructions at: https://github.com/Digital-Humanities-Quarterly/DHQ-similar-papers?tab=readme-ov-file#reproduction.
References
[1] The Digital Humanities Quarterly website: https://dhq.digitalhumanities.org
[2] The Digital Humanities Quarterly similar papers codebase: https://github.com/Digital-Humanities-Quarterly/DHQ-similar-papers
[3] Semantic Scholar website: https://www.semanticscholar.org/
[4] Google Scholar website: https://scholar.google.com/
[5] DHQ Topic Keywords: https://github.com/Digital-Humanities-Quarterly/dhq-journal/wiki/DHQ-Topic-Keywords
[6] Stephen Robertson and Hugo Zaragoza. 2009. “The Probabilistic Relevance Framework: BM25 and Beyond.” Found. Trends Inf. Retr. 3, 4 (April 2009), 333–389. https://doi.org/10.1561/1500000019
[7] Guilherme Moraes Rosa, Ruan Chaves Rodrigues, Roberto Lotufo, and Rodrigo Nogueira. 2021. “Yes, BM25 is a Strong Baseline for Legal Case Retrieval,” ArXiv. https://arxiv.org/abs/2105.05686
[8] Thomas Diggelmann, Jordan Boyd-Graber, Jannis Bulian, Massimiliano Ciaramita, and Markus Leippold. 2020. “CLIMATE-FEVER: A Dataset for Verification of Real-World Climate Claims,” ArXiv. https://arxiv.org/abs/2012.00614
[9] Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. 2021. “SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval,” ArXiv. https://arxiv.org/abs/2109.10086
[10] Singh, Amanpreet, Mike D’Arcy, Arman Cohan, Doug Downey and Sergey Feldman. 2022. “SciRepEval: A Multi-Format Benchmark for Scientific Document Representations.” Conference on Empirical Methods in Natural Language Processing. https://aclanthology.org/2023.emnlp-main.338/

Subscribe to comments: For this article | For all articles
Leave a Reply